
基于CORDIC算法的模值计算及优化设计基于CORDIC算法的模值计算及优化设计
2021-11-04 02:42刘恒,钟俊,刘辉
龙岩学院学报 2021年5期
刘 恒,钟 俊,刘 辉
(安徽职业技术学院 安徽合肥 230011)
在数字信号处理等领域常常需要求解三角函数值以及模值。CORDIC算法是实现上述求解过程的最常用的方法。从本质上说,CORDIC算法使用了一种数学计算的逐次逼近法[1]。算法的基本运算单元只包含移位器和加法器[2]。因此它的操作简单,执行效率高。FPGA器件集成度高,速度快,是实现CORDIC算法的首选方式[3]。本文深入研究了CORDIC算法的基本原理,提出了运算单元的优化方法及硬件实现结构,并进行了Modelsim仿真。
1 CORDIC算法的基本原理
向量OA在单位圆上,辐角为α,如图1所示。
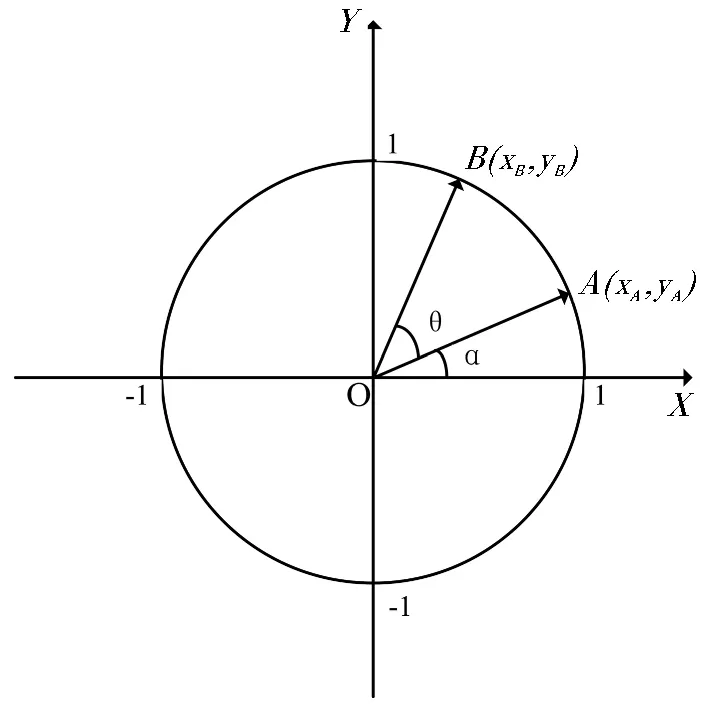
图1 矢量旋转图
A点坐标可写成三角函数形式:
(1)
将向量OA按照逆时针方向旋转角度θ至向量OB,OB辐角为α+θ,
B点坐标可写成三角函数形式:
(2)
θ是本次旋转的目标旋转角度。将式 (2) 按照三角函数公式展开:
(3)
将式 (1 ) 代入式 (3) 可得:
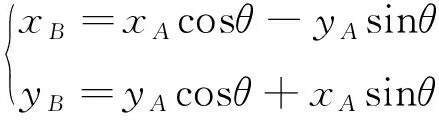
(4)
两个表达式提取公因子 cosθ, 式 (4) 可变形
(5)
式 (5) 表明,cosθ对目标向量OB辐角没有影响,只是缩短了模长。 如果去除cosθ, 这种旋转称为伪旋转,如图 2所示。由伪旋转得到的OC是在OA基础上先旋转θ角再伸长1/cosθ。向量OA⊥AC。C点坐标可写为:
(6)
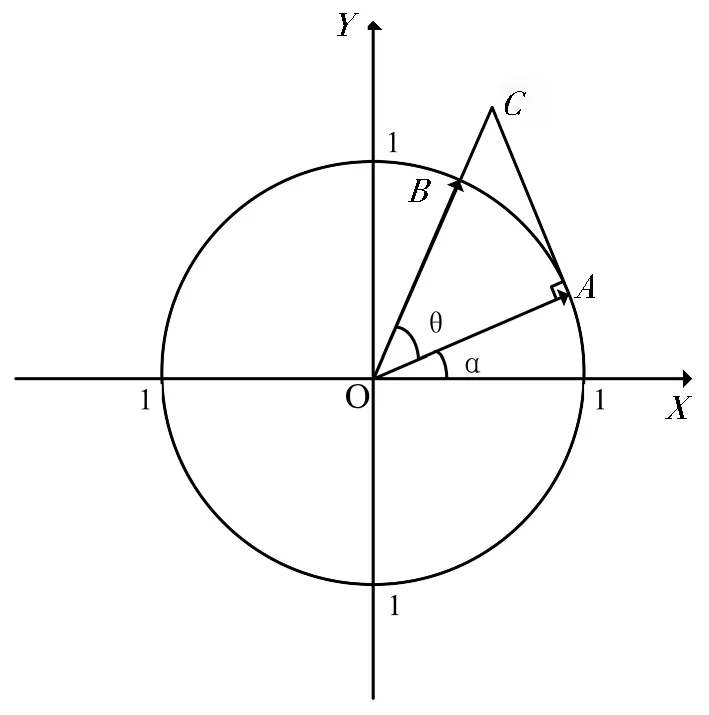
图2 变换后的矢量旋转图
比较上面两个表达式,旋转的角度不变,模值在原来基础上增大了1/cosθ。为了得到真实旋转的结果,可将伪旋转的输出乘相应的因子进行修正。
对于任意角度θ的伪旋转,可将θ拆分为一系列的特定角度的和,即:
(7)
由此可将一次旋转变成多次旋转。由式(6)可知,经过第i+1次旋转可得:
(8)
考虑到FPGA硬件实现过程,可以取特殊角度:
θi=tan-1(di2-i)
(9)
其中di∈{-1,1},根据式(9),式(8)可变形为:
(10)
根据式(10)可知,每次伪旋转的具体操作过程只包括加法、减法和移位运算。di的值由剩余旋转角度决定,假设剩余旋转角度为z,表达式为:
zi+1=zi-ditan-12-i
(11)
z初始化为θ,即z0=θ。每次迭代,对zi加或者减特定角度tan-12-i,最终使z的值为0 ,加减由di决定,即:
(12)
逆时针方向旋转,di记为+1,顺时针方向旋转,di记为-1。在迭代过程中分解为θi。剩余的角度zi随着迭代进行将收敛于零。CORDIC算法迭代的完整过程如下:
(13)
CORDIC算法可用于计算向量的模值。假设向量初始值为(x0,y0),在多次迭代之后,如果yn趋于零,则:
(14)
(15)
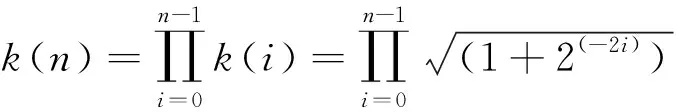
(16)
如果迭代总次数n确定,则k(n)可预先计算得到,视为已知。计算表达式(15)可以得到向量模值[4]。
2 算法优化
2.1 算法的局限性
CORDIC算法是将运算单元的运算结果反馈回输入端。运算单元包含控制单元、MUX、移位寄存器、只读存储器以及加法器[5]。随着时钟脉冲信号的推进,把当前输出传回到输入端,经过多次计算,得到最终结果。无论串行还是并行实现方式,都离不开上述CORDIC运算单元。
2.2 优化过程
之前广泛采用的优化策略主要体现在模校正和角度收敛范围等方面,这些优化并没有改变CORDIC运算单元。本文采用新的优化思路,将CORDIC算法两级运算表达式展开。原先的两级迭代合并为一级,其中di与di-1由上一次迭代产生。通过直接建立xi+1,yi+1与xi-1,yi-1之间的联系,可以减少单元结构,从根本上优化传统的CORDIC运算单元。
(17)
从表达式来看,原来的两级迭代,需要两级移位运算和两级加法运算,优化以后,需要一级移位运算和两级加法运算,这样可以一定程度上减少迭代的总时间,提高运算效率。优化后的算法一共迭代n/2次,FPGA关键路径由原先的3.1 ns 提升至2.3 ns,优化后的CORDIC 算法数据吞吐量增加了20%。
3 硬件实现
速度与功耗是影响FPGA性能的两个重要方面,在CORDIC算法的实现过程中,必须同时考虑上述两个方面。有两种方式可以实现CORDIC算法。方式一:流水线结构。采用这种结构每个时钟周期可以产生一个输出结果。具体的实现过程是用n个单元完成算法的n次迭代。采用流水线结构多个单元可以同时进行移位和加法运算,很大程度上增加了数据处理效率,运算速度较其他方式快很多。 流水线结构占据的芯片面积大,硬件功耗会随着流水线级数增加而线性增加。方式二:迭代结构[6]。一个CORDIC运算单元(如图3)重复使用n次,实现算法的n次迭代。这种实现方式占据的芯片面积小,但相比流水线结构,系统的数据处理效率低很多。本文采用迭代结构,在满足低功耗的要求同时,提升运算速度。传统的两级运算结构在优化之后,变为一级结构,如图4所示,以此作为迭代结构的基本运算单元。
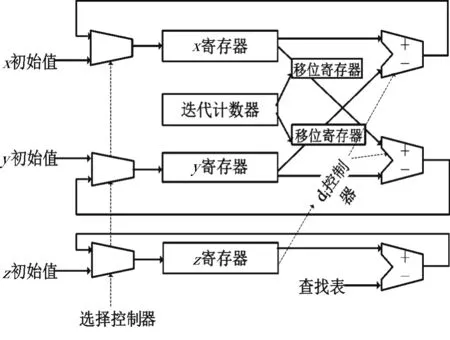
图3 CORDIC基本运算单元
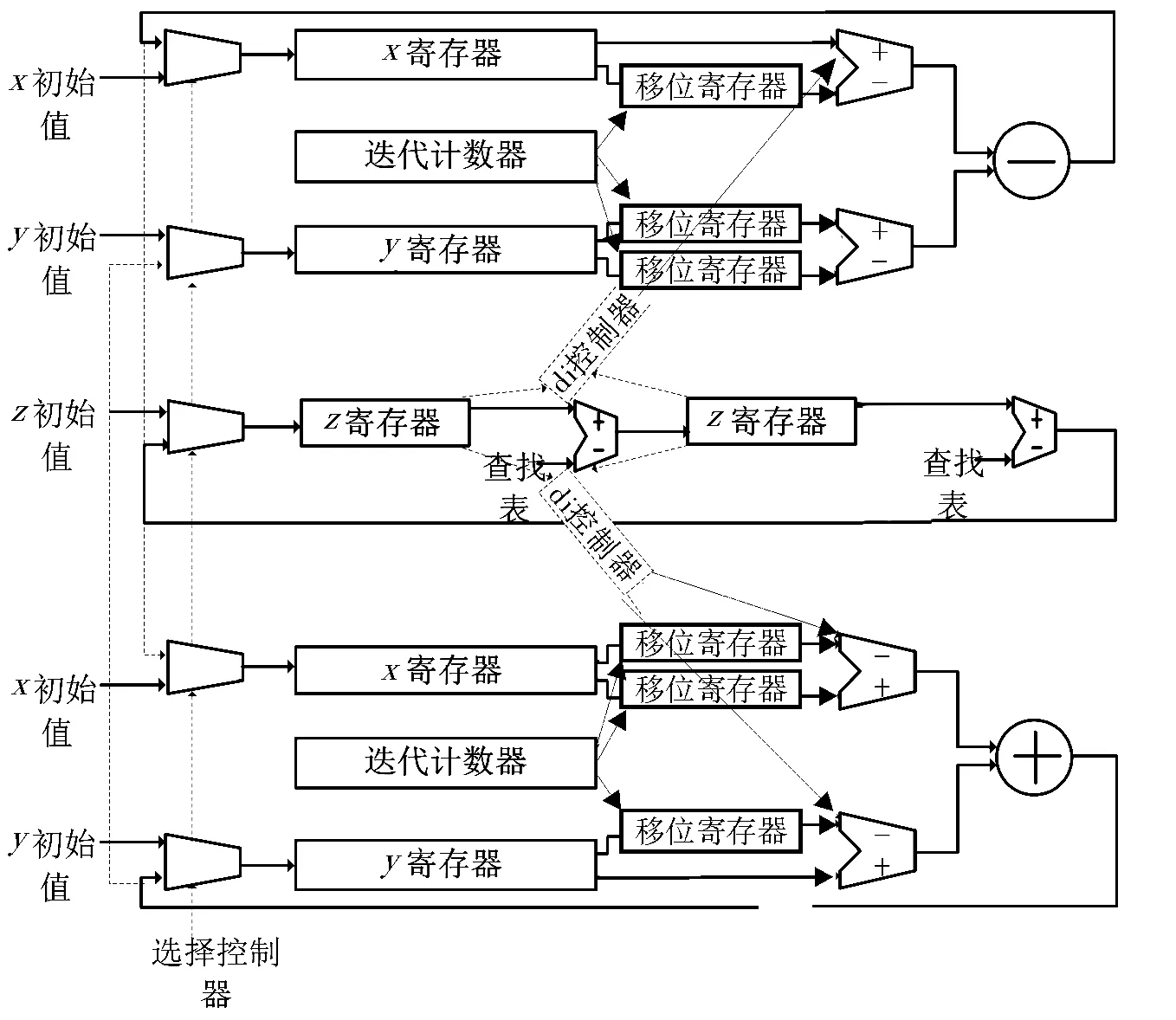
图4 优化之后的两级运算单元
4 仿真结果
采用ModelSim-Altera 10.0软件进行仿真,时钟频率50 M。用Verilog语言建模并仿真测试。在实现算法的过程中采用流水线运算结构,可以在很大程度上提高算法的执行效率,其中单次迭代采用优化后的运算单元。
CORDIC算法计算获得的正余弦函数波形图如图5所示。

图5 正余弦波形图
用CORDIC算法计算向量(123,456)的模值,理论模值为472.3。迭代部分代码如下。
if((y_out0*Precision<=y_out)||(y_out0*Precision<=-y_out))
begin
if(~ y_out[31])
begin
x_out_next<= x_out + (y_out >>> i);
y_out_next<= y_out - (x_out >>> i);
end
else
begin
x_out_next<= x_out - (y_out >>> i);
y_out_next<= y_out + (x_out >>> i);
end
end
else
begin
x_out<=x_out;
y_out<= y_out;
i <= i;
end
其中Precision为预设的计算精度。经过有限次迭代,输出向量模值473,如图6所示。采用优化后的CORDIC算法计算模值,如图7所示。

图6 CORDIC算法计算模值

图7 优化后的 CORDIC算法计算模值
在精度0.001条件下,采用两种不同方法对多组数据进行计算,比较需要时钟周期个数,如表1。在同样迭代次数(5次)情况下,对计算结果进行比较,如表2。

表1 优化前后计算速度比较向量时钟周期数优化前优化后(535,897)95(932,384)53(626,433)95(832,795)95(028,841)95表2 优化前后精度比较向量向量模值计算结果优化前优化后 (535,897)1044.410341044(932,384)1008.010071009(626,433)761.2 753 762(832,795)1150.811441151(028,841)841.5 832 842(971,693)1192.911801193
可见,采用优化后的CORDIC算法不仅计算速度快,而且计算精度高。
5 结束语
本文对CORDIC算法进行优化改进,硬件采用并行结构实现算法,可以很大程度上提高算法的数据处理速度。在不影响计算精度前提下,优化后的算法可以明显减少运算时间,具有很好的使用价值。实验结果表明算法优化后相比较于优化之前,运算时间减少了40%左右,优化后的算法具有很好的实际意义。
猜你喜欢
昆明医科大学学报(2022年4期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
初中生世界(2020年47期)2021-01-07
安顺学院学报(2020年1期)2020-04-05
数学学习与研究(2020年22期)2020-01-11
船舶标准化工程师(2019年4期)2019-07-24
现代计算机(2019年6期)2019-04-08
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
