
严格反馈系统的事件触发学习控制
2021-11-20 09:10辛学刚时昊天
控制理论与应用 2021年10期
王 敏 ,胡 锐 ,辛学刚 ,时昊天
(1.华南理工大学自动化科学与工程学院,广东广州 510641;2.华南理工大学医学院,广东广州 510006)
1 引言
严格反馈系统是一种十分常见的非线性系统.在实际工程中,很多系统都可建模为严格反馈系统,例如机械臂[1]、移动机器人[2]、无人船[3].早期的严格反馈系统控制方案主要是针对系统完全已知或者部分参数未知情况[4–5].然而,实际系统由于外部干扰和阻尼等因素影响,通常无法精确建模.针对此问题,一些学者联合神经网络逼近原理和后推技术,提出了一些新颖的自适应神经网络控制方法,从而有效解决了存在未知动态的严格反馈系统控制问题[6–9].值得指出的是,现有的自适应神经网络控制方法学习能力较有限,对于相同或者相似的控制任务,仍需对神经网络进行重复的调整训练[10].此过程耗时严重并且在神经网络训练过程,控制系统的暂态跟踪效果较差.由此可见,如何从动力学系统的神经网络控制过程中实现未知动态的学习变得尤为重要.近年来,王聪教授等人以二阶Brunovsky系统为研究对象,提出了确定学习理论来尝试解决未知动态的学习问题[11–12].该理论证明了沿着周期轨迹的径向基函数神经网络满足持续激励条件,从而结合线性时变系统指数稳定性原理实现了神经网络权值的收敛以及对未知动态的精确逼近.结合系统解耦技术和动态面控制技术等,文献[13]将确定学习原理推广到了严格反馈系统.目前,确定学习理论研究已广泛应用于解决许多面向实际的控制与学习问题,例如预设性能控制[14]、编队控制[15–16]和故障诊断等[17].
另一方面,由于网络化控制系统可以实现资源共享,远程控制,且易于维护以及低成本等优点,控制系统逐渐趋向于数字化和网络化,例如地面站对无人船的远程操作,以及数字控制台对车间工业机器人的远程控制等.网络的共享与带宽受限容易导致网络拥塞和数据丢包,如何有效使用网络资源在控制系统设计中具有重要意义.传统的网络控制中通常采用时间触发的方式,即每次信号都是等周期的进行传送,此方案往往会产生网络资源的浪费.为了克服此缺陷,事件触发机制被提出来用于节省网络资源[18],其思想是将信号在必要的时候进行非周期的传输,以此来节省网络资源.近年来,学者们基于事件触发机制做了大量工作[19–28],在文献[19]中,将非线性滤波误差系统建模为时滞系统,实现了自适应事件触发参数与滤波参数共同设计.文献[20–21]使用了基于模型的事件触发控制方法,通过在控制器端设计一个镜像的被控对象,从而进一步地减少状态信号的传输次数,但同时会增加整个系统的计算量.在文献[22]中,对于仅输出可测的系统,利用状态观测器提出了输出反馈的事件触发控制方案.在文献[23]中,对于网络通道位于控制器到执行器端的系统,提出了3种不同的事件触发控制方案.在文献[24]中,对于非线性级联系统,通过增强学习,提出了一种分布式最优事件触发控制方案.在文献[25]中,对于含有未知系统动态的非线性纯反馈系统,提出了一种自适应神经网络事件触发控制方案.文献[26]为了进一步减少事件触发次数,提出了含有死区算子的事件触发机制.文献[27–28]中针对离散非线性严格反馈系统提出了一种新型的自适应神经网络控制框架.文献[29–32]对事件触发机制进行了扩展,提出了自触发控制方案,其触发时刻仅由系统之前的信号状态决定.值得注意的是,文献[25–28]中的神经网络缺乏好的学习能力,导致依赖估计权值设计的事件触发条件难于实施,且由于相同任务下仍需要重新调整神经网络权值增加了大量的计算负担.
基于上述原因,本文针对带有传感器到控制器端网络通道资源受限的严格反馈非线性系统,提出了一种基于确定学习的事件触发控制方法.该控制方案设计分为两个部分.在第一部分里,本文首先在本地端网络资源充足的前提下设计了严格反馈系统的自适应神经网络控制器,并在稳定的控制过程中实现系统未知动态的学习以及收敛估计权值的存储.在第二部分里,利用存储的权值设计了具有常系数的相对事件触发条件和静态事件触发控制器进行远程控制.随后,结合脉冲动力学系统原理与李雅普诺夫稳定原理验证了所提出的事件触发控制方案能够保证跟踪性能和闭环所有信号的一致最终有界.该方案的主要贡献总结如下:1)提出采用确定学习原理来解决不确定非线性系统事件触发控制问题,在系统本地网络资源充足的情况下实现了未知动态的知识获取与存储;2)利用经验知识进行事件触发控制方案设计,大大降低了控制方案的计算量;3)利用获取到的常值神经网络权值设计了一种新型的事件触发条件.该触发条件结合静态事件触发控制器,相较于现有的自适应神经网络事件触发控制方案,可以获取更好的暂态跟踪性能,更少的触发次数以及更小的计算负担.
2 问题描述
考虑如下形式的严格反馈非线性系统:

其中:xd=[xd1··· xdm]T∈Rm为该参考信号模型的状态矢量;yd∈R为该模型的输出变量.fd(·)为已知光滑非线性函数.本文假设xdi ∈R,1 ≤i≤m为回归信号且参考轨迹为回归轨迹.
本文的控制任务是在通讯资源受限的情况下,设计基于确定学习的事件触发控制方案,使得系统(1)的输出y跟踪给定的参考轨迹yd和闭环系统的所有信号保持最终一致有界.控制目标是在完成控制任务的前提下提升受控系统的暂态性能,节省网络资源和降低算法的计算量.
假设1非线性函数gi()的符号是已知的,且满足是正常数.

3 基于确定学习的事件触发控制
在本节中,首先构造自适应神经网络控制器并利用确定学习机制获取常值神经网络权值,最后构造基于经验知识的事件触发控制器.控制方案框图参见图1所示.

图1 基于确定学习的事件触发控制框图Fig.1 The control framework of the proposed eventtriggered control based on deterministic learning
3.1 闭环未知系统动态的知识获取以及存储
在本地控制测试端,即控制器在系统本地且网络资源充足的环境下,首先通过设计自适应神经网络控制器,实现闭环未知系统动态的知识获取以及存储.
第i步(1 ≤i <n) 定义误差为zi=xi-αi-1f,其中α0f=xd1.根据式(1)可以得到


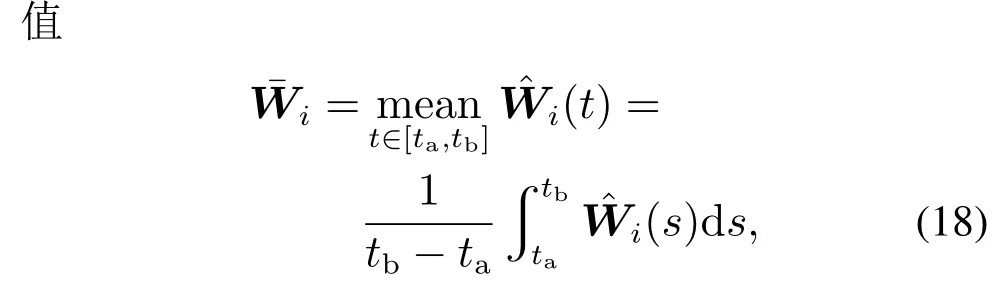
其中:tb>ta>T,[ta,tb]为系统稳态后的时间段.
3.2 利用存储的经验知识构造事件触发控制器
在远程控制阶段,即控制器不在系统本地并且考虑网络资源受限的环境下,调用存储的系统未知动态经验知识,构造新的事件触发控制器,在保证控制性能的同时降低网络带宽的占用.
第1步定义跟踪误差为ξ1=x1-xd1,根据式(1)可以得到

定义相同的未知动态H1(Z1),如式(8)所示.为了便于后续设计,记H1(Zl1):=H1(Z1).基于引理2可知:


这里Γ为正的设计参数,Li是基函数S(Zli)的利普希茨系数.
注1与现有文献[25]的事件触发条件不同,本文的触发条件式(35)中包含的权值为存储的常值权值.根据式(35)可知,μ的值可以通过给定的Γ,ci,Li和‖‖事先计算好.然而,文献[25]中事件触发条件包含的是动态变化的权值估计值且该估计依赖于过程虚拟控制变量,从而导致μ的值需要通过在线实时计算‖‖才能获得且计算过程复杂.因此,与文献[25]相比,本文所提出的事件触发条件所需的在线计算量更少,更加易于实施.此外,结合基于事件触发的神经网络学习控制器设计(33),能够在获得更好暂态跟踪性能的同时减少更多的事件触发次数.
定义动态面滤波器产生的层面误差为

根据式(20)(22)(24)(28)(30)(33)(36),可得如下基于事件触发的闭环误差系统:
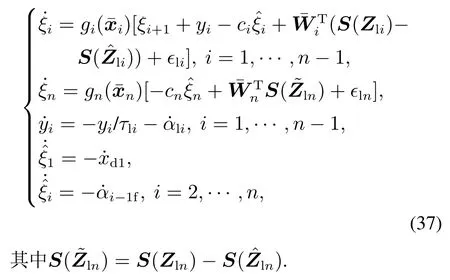
定理1对于系统(1),在假设1–2以及虚拟控制器(28),实际控制器(33)和事件触发条件(34)的作用下,对于任意给定的常数ρ以及所有满足V(0)≤ρ的初始状态,通过选择适当的设计参数,跟踪误差ξ1(t)能够收敛到零的小邻域内,闭环系统中的所有信号都是最终一致有界的,且能够排除芝诺现象.
证选取李雅普诺夫函数为




因此,所提的控制方案没有芝诺现象.
4 仿真研究
本节利用双连杆机械臂仿真来说明所提方案的有效性,机械臂模型如下所示:



图2 第1个连杆的位置跟踪效果Fig.2 Position tracking performance of the first link

图3 第2个连杆的位置跟踪效果Fig.3 Position tracking performance of the second link

图4 事件触发时间间隔Fig.4 Event interval time

图5 事件误差和阈值响应曲线Fig.5 Curves of the threshold and event error
为了进一步说明本文所提方案的有效性,与现有的自适应神经网络事件触发控制进行了仿真比较.基于文献[25],可以设计系统(52)的自适应神经网络事件触发控制器如下:
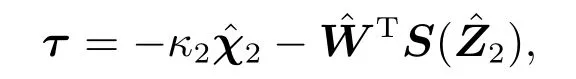
其权值更新率为
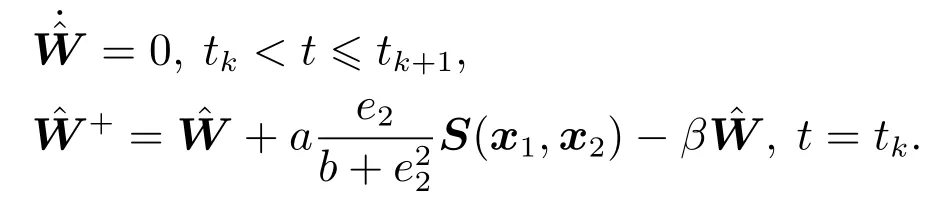
且事件触发条件为

a和b都是正常数.
在仿真对比实验中,采用相同的硬件平台、仿真时间、神经网络布点和初始状态;文献[25]所提的自适应神经网络事件触发控制方案参数选取为κ1=10,κ2=10,L=1,T=0.01,Γa=0.07,a=0.5,b=5,β=0.00001.图6–10指示了两种方案对比的仿真结果.
图6–7描述了基于确定学习的事件触发控制(deterministic learning-based event-triggered control,DLEC)和自适应神经网络事件触发控制(event-triggered adaptive neural control,EANC)的跟踪误差对比图,图8和图9描述了采用上述两种控制方案的神经网络逼近未知动态的对比图.图10描述了采用上述两种控制方案的触发次数对比图.通过比较图6和图7以及图8和图9,可以看出本文所提方案相比文献[25]所提的自适应神经网络事件触发控制方案,其跟踪速度更快,且神经网络逼近未知动态更快.图10表明了所提方案可以更大程度的减少触发次数,从而节省网络资源.表1展示了基于确定学习的事件触发方案和自适应神经网络事件触发方案[25]在触发次数、暂态时间、平均绝对误差以及CPU耗时4项性能指标方面的对比结果.由表1可知本文所提方案具有更好的跟踪性能,更少的网络资源占用以及更小的计算负担.

表1 自适应神经网络事件触发方案和基于确定学习事件触发方案性能对比Table 1 Comparison of EANC and DLEC

图6 第1个连杆的位置跟踪误差Fig.6 Position tracking error of the first link
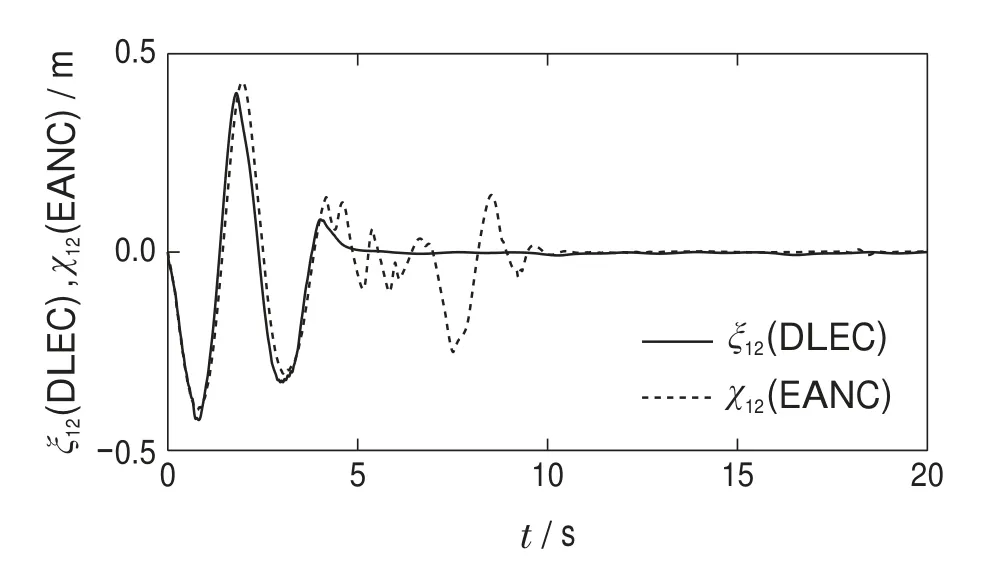
图7 第2个连杆的位置跟踪误差Fig.7 Position tracking error of the second link
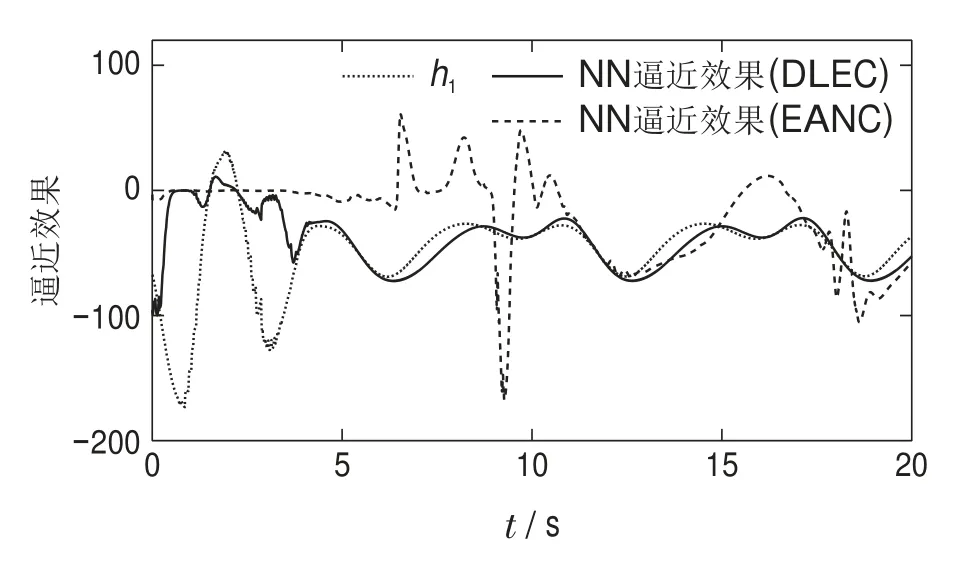
图8 神经网络对未知动态h1逼近效果Fig.8 NN’s approximation of unknown dynamics h1

图9 神经网络对未知动态h2逼近效果Fig.9 NN’s approximation of unknown dynamics h2
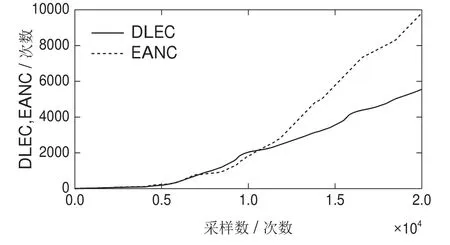
图10 累计触发次数Fig.10 Cumulative number of events
5 结论
针对严格反馈非线性系统,本文提出了基于确定学习的事件触发跟踪控制方案.通过确定学习理论,实现了系统未知动态的知识获取,并将获取的知识存储于常值神经网络.随后,基于存储的经验知识设计了易于实施的相对事件触发条件,并由此设计了新颖的事件触发控制器.该控制器能够保证跟踪误差收敛到零的小邻域内,闭环系统的所有信号都是有界的,且避免芝诺现象.仿真结果验证了此方案能够在节省网络资源的同时保证良好的跟踪效果.特别是,由于经验知识的利用,所提出方案与传统的自适应神经网络事件触发控制方案相比具有更好的跟踪效果和更少的事件触发次数.
猜你喜欢
江苏科技信息(2022年26期)2022-10-15
成都信息工程大学学报(2022年3期)2022-07-21
中国计算机报(2021年10期)2021-04-27
邮电设计技术(2021年2期)2021-03-13
山西青年(2020年18期)2020-12-07
新商务周刊(2018年24期)2018-12-07
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
科学与财富(2017年28期)2017-10-14
电子技术与软件工程(2017年7期)2017-06-05
