
矿区土壤重金属Cd高光谱建模与模型适应性分析
2021-11-30 12:33陈弘扬周鹏飞庄红娟张世文
安徽工程大学学报 2021年5期
兰 淼,杨 斌,宋 强,陈弘扬,周鹏飞,庄红娟,方 兵,张世文*
(1.安徽理工大学 地球与环境学院,安徽 淮南 232001;2.安徽理工大学 空间信息与测绘工程学院,安徽 淮南 232001)
土壤重金属的侵袭与累积是一种十分普遍的现象,人类活动将重金属带到土壤中,致使土壤中重金属含量明显高于背景值,并且造成现存或潜在的土壤质量退化、生态环境恶化的现象,而矿区土壤在常年矿产开采加工以及运输过程中更易受到重金属污染。镉(Cd)在自然界中普遍存在,其含量的增加可能会导致铝、铜、锌、锰、铅等元素的高环境风险,通过潜在的地表或地下水的浸出,或通过这些元素更高的生物可给性;Cd的毒性较大,且难以自然降解、清除,容易累积在土壤中;此外重金属Cd可通过植物根部吸收,对生态系统及人体健康构成威胁,因此,监测矿区土壤中Cd的含量势在必行。
传统重金属检测大多采用野外采样-室内分析的方法,耗时耗财,无法较好地获取空间上重金属的污染情况。近年来高光谱以其动态、高效等优势已广泛应用于环境、地质、土壤等多个领域,为快速获取土壤理化信息提供了新的思路。国内外学者在土壤反射率与土壤参数之间运用多种方法建立了数学估算模型。Kemper等对Aznalcollar受污染的土壤利用可见-近红外光谱实现对6种金属元素的回归分析预测;解宪丽等选择江西贵溪铜冶炼厂污染区,分析了9种重金属元素与可见-近红外光谱之间的相关性;龚绍琦等利用光谱一阶微分变换,采用逐步回归方法建立了3种重金属预测模型并得到较高精度;Meng Xiangtian等利用14张高光谱图像采用离散小波变换对原始反射率和光谱一阶微分进行分解重构,采用随机森林、支持向量机和BP神经网络算法,建立区域尺度有机碳预测模型;Shen Qiang等对湖北大冶铁矿采用间接反演的方法实现复垦土壤重金属Cu的空间分布;陈元鹏等采用偏最小二乘与粒子群算法相结合的方法,对工矿复垦区土壤重金属反演,主要障碍因子Cd取得较高精度;Hong Yongsheng等利用连续小波变换结合随机森林模型反演土壤有机碳,并得到局地尺度上土壤有机碳空间分布模式;Wei Lifei等采用稳定竞争自适应加权采样算法结合逐次投影算法解决光谱数据冗余,使用重组青蛙跳跃算法优化后的径向基神经网络模型得到较高预测精度,以上都说明高光谱对重金属预测具有可行性。
前人在土壤重金属估测方面做了大量的研究并取得了较好的预测结果,但多集中于重金属含量的估测,并未分析模型在不同浓度下的预测能力。研究针对矿山开采过程中造成或潜在造成的土壤重金属Cd污染,以粤北南岭某矿区为例,通过传统检测方法测定研究区土壤Cd含量;利用ASD Field Spec 4型便携式高光谱仪进行土壤反射率测定,分析不同光谱指标与Cd含量的相关性;筛选敏感波段,采用偏最小二乘和随机森林建立矿区土壤重金属Cd含量估算模型,分析不同Cd含量区间对建模精度的影响,探讨利用高光谱遥感技术快速检测土壤Cd含量的可行性,为矿区土壤重金属高光谱反演提供方法和理论支持。
1 研究区概况与研究方法
1.1 研究区概况
研究区位于广东省韶关市境内(112°50′~114°45′E,23°5′~25°31′N),位置及采样点如图1所示。该区域地处五岭山脉南麓,北江中上游地区,全境在大地构造上处于华厦活化陆台的湘粤褶皱带。韶关市属中亚热带湿润型季风气候区,年平均气温18.8~21.6 ℃,年均降雨1 400~2 400 mm,地形以山地丘陵为主,河谷盆地分布其中。平原、台地面积约占20%,境内河流主要属珠江水系北江流域,以浈江为干流,自北向南贯穿全境。地势北高南低,土壤类型以红壤为主。韶关市作为“中国有色金属之乡”,有“中国锌都”称号,境内矿产资源丰富。该地区的开采历史最早可追溯到千年之前,近年来由于大量私人和小集体不合理的开采,使得废弃后的矿窿成为了地下水的主要污染源,富含重金属的裸露山体,经雨水的冲刷,不断析出酸性水,最终对土壤造成污染。

图1 研究区位置及采样点图
1.2 样品采集与处理
研究土样采自广东省韶关市某金属矿区。2020年7月通过GPS精确定位采样点,共采集样本点73个。对每个采样点,按梅花形收集5个子集,再混和成一个组合样本。将采集的土壤自然风干,去除砾石及动植物残体后,将土样平均分为两份,一份用于测定土壤重金属Cd含量,一份用于采集高光谱数据。其中,土壤重金属Cd含量采用王水提取-电感耦合等离子体质谱法(ICP-MS)测定,土壤光谱反射率采集使用美国ASD(Analytical Spectral Devices)公司生产的Field Spec 4便携式地物光谱仪。该仪器的光谱测量范围是350~2 500 nm,包含了可见光-近红外全部范围,两次采样的间隔为1 nm,共有2 150个波段。由于光谱容易受到外界光线的影响,因此实验选在无光的暗室中进行,光源为12 V、50 W的灯泡,数据使用25°裸光纤镜头获取。实验前将仪器先通电预热半小时,实验过程中将土壤样本均匀平铺在直径100 mm、高20 mm的玻璃盛样皿中,使用黑色绒布为背景垫在盛样皿下方。光源与样本的直线距离为60 cm,与水平方向夹角45°。镜头位于样品正上方10 cm,与样品垂直。为保证数据的准确性,测试之前去除辐射强度中暗电流的影响,然后以白板进行定标,为防止测量过程中其他因素影响数据准确性,每测量10个样本进行一次白板校正。每个样本采集20条光谱曲线,剔除噪声较大的曲线,取平均值作为该土样的实际反射光谱数据。
1.3 光谱预处理
光谱数据获取过程中,由于外界环境的影响以及光谱仪在不同波段对能量响应上的差异,会导致光谱曲线存在一些噪声。噪声主要来自高频随机噪声、基线漂移、样本不均匀、光线散射等,因此,对光谱数据进行预处理就显得尤为必要。实践表明,对光谱曲线进行平滑,可以去除信号内的少量噪声,得到平滑的光谱波形。如果噪声的频率较高且量值不大,用平滑的方法可在一定程度上降低噪声。研究采用卷积平滑(Savitzky-Golay)方法对光谱曲线进行平滑,将得到的结果作为原始数据。
研究表明,通过不同的数学变换可以减少土壤母质、成土条件、质地、表面粗糙度、微聚体、湿度等土壤本身属性的影响及大气温度、湿度、组分和电磁特性等外界因素干扰,有效地消除了基线和背景干扰,提高了部分波段的分辨率和灵敏度,使重叠样本得到分离,进一步提取了原始数据中差异不显著的光谱信息,使得光谱特征更加明显。研究主要对土壤反射率(Reflectance,R)进行以下变换:倒数变换(Reciprocal Transform,RT)、对数变换(Logarithm Transform,LT)、一阶微分(Frist Derivative,FD)、二阶微分(Second Derivative,SD)、归一化变换(Normalization Transform,NT)、倒数对数变换(吸光率,Absorbance Transformr,AT)、倒数对数一阶微分(ATFD)及倒数对数二阶微分(ATSD)。
(1)微分技术。光谱微分技术是一种在遥感数据处理中特别有应用前景的分析方法。光谱微分技术对不同的背景、噪声有去除作用,特别是比较容易去除以“加”的形式混入光谱信号中的噪声,还可以消除基线和其他背景的干扰,分辨重叠峰,提高分辨率和灵敏度。一般认为,可用一阶微分处理去除部分线性或接近线性的背景干扰,二阶微分可消除平方项噪声的影响,因而其在实际应用中较为有效,其公式如下:


λ
为每个波段的波长;R
(λ
)和R
(λ
-1)分别为波长λ
和λ
-1处的光谱反射率;R
(λ
)和R
(λ
-1)分别为波长λ
和λ
-1处的一阶微分光谱;R
(λ
)为波长λ
处的二阶微分光谱;Δλ
为波长λ
-到λ
的间隔,视波段波长而定,波长λ
-2到λ
的间隔及波长λ
+2到λ
的间隔为2Δλ
。(2)初等变换。采用初等函数对光谱数据进行变化处理叫做初等变换,也称简单变换。实际应用表明,初等变换一般不能有效提高变换后光谱数据与研究对象间的相关性,但为研究组合变换方法提供了基础,可根据具体问题,通过对比试验获取最佳组合变换方法。
1.4 模型建立与精度检验
经过以上数据预处理,从73个土壤样本中随机选择52个作为建模样本,21个作为检验样本用来检验模型精度。
(1)偏最小二乘算法。偏最小二乘(Partial Least Squares Regression,PLSR)是一种基于主成分分析的多变量建模方法,通过将光谱数据进行分解,去除其中无效的噪声干扰,同时分解重金属含量数据,消除其中无用信息。在分解光谱数据的同时考虑了重金属含量数据的影响,将数据分解与回归并为一步。在计算每一个主成分前将光谱数据的得分矩阵与重金属含量数据的得分矩阵交换,使得光谱数据主成分直接与重金属含量数据关联。
(2)随机森林算法。随机森林(Random Forest Regression,RF)是Breiman 2001年提出的一种利用多棵决策树对样本进行训练并预测的机器学习算法,是众多决策树的集合。采用Bootsrap重抽样方法随机抽样构建不同的分类模型,再用它们构成一个多分类模型系统,以多数投票法确定最终分类结果。对异常值和噪声具有较高的容忍度,通过引入“随机性”来处理“过拟合”,因此具有较高的泛化能力。
(3)精度检验。模型的验证主要选用决定系数(Coefficient of Determination,R)和均方根误差(Root Mean Squard Error,RMSE),计算公式如下:



2 结果与分析
2.1 土壤Cd的经典统计学分析
对本次测定的73个土样的重金属Cd含量进行统计如表1所示。将检测结果与国家相关标准及广东省背景值对比,发现超过72.6%的土壤样点Cd含量高于农用地土壤污染风险管控标准,含量最大值点位超过背景值145倍。研究区Cd含量最大值达到4.95 mg/kg,最小值为0.04 mg/kg,平均值为1.11 mg/kg。从土样的平均值来看,Cd含量超过背景值30倍。根据单因子指数法测算,该区域Cd的污染指数为重度污染。Cd含量变异系数为101.14%,通常认定变异系数反应离散程度,且当100%<变异系数时,为强变异性,可能是由于采样点受采矿区扰动程度不同,土壤Cd含量差异较大。因此,该地区应加强土壤重金属动态监测,为发现并控制土壤重金属污染提供依据。

表1 土壤样本Cd含量描述性统计
2.2 土壤光谱特征分析

图2 不同Cd含量土壤光谱曲线和连续统去除光谱曲线
2.3 土壤Cd与光谱反射率的相关性分析
Cd含量与不同数学变换后的相关系数图如图3所示。由图3可知,由于土壤中Cd含量较低,Cd含量与土壤光谱总体相关性较低,但都表现出与土壤光谱相似的相关性,分别在700~800 nm、1 380~1 410 nm、1 550~1 600 nm、1 800~1 950 nm、2 320~2 360 nm范围内有较强的相关性。Cd含量与原始光谱绝大部分呈负相关,在可见光部分相关性先降低再升高,在900 nm附近逐渐趋于稳定,在1 900 nm附近相关性降低后逐渐升高,并在2 212 nm附近达到显著相关。LT、RT相关性与R相似,均在400~560 nm范围内降低后逐渐升高并趋于稳定。R、RT、AT、NT相关系数最大值均出现在可见光波段,说明在进行微分变换之前,在可见光波段的土壤Cd含量探测能力要比近红外波段强。经微分变换之后的4种光谱指标与土壤Cd含量相关性明显提高,相关性在正负之间波动很大,且近红外波段的相关性高于可见光波段,部分波段达到了0.01的极显著水平。FD与Cd含量相关性最高的波段为1 943 nm(r
=-0.
496),SD与Cd含量相关性最高值略低于FD但总体相差不大,最高的波段为1 945 nm(r
=-0.
467)。ATFD与ATSD的相关性没有FD和SD那么突出,变化趋势与FD和SD相似,均在正负之间波动,相关性最高的波段分别为758 nm(r
=0.
466)和2 387nm(r
=-0.
487)。综上所述,在9种微分指标中一阶微分变化与Cd含量相关性最好,为最优光谱指标。
图3 Cd含量与土壤光谱的相关系数图
2.4 土壤Cd含量高光谱模型分析
选择与土壤Cd含量相关性较大的波段作为自变量,采用偏最小二乘模型和随机森林方法,分别建立9种光谱指标(R、RT、LT、FD、SD、NT、AT、ATFD、ATSD)的矿区土壤重金属预测模型,模型的预测能力和稳定性由R
和RMSE
检验,结果如表2所示。
表2 不同土壤反射率变换形式模型回归结果
从模型的回归效果看,两种模型的预测能力差异较大,偏最小二乘的R
介于0.
14~0.
61,RMSE
介于0.
69~1.
11;随机森林的R
介于0.
13~0.
86,RMSE
介于0.
40~1.
09。不同预处理变换方法对模型的预测结果有较大的影响,与相关性结果类似,经过初等变换的光谱曲线预测能力较差,所建立模型的R
均小于0.
50,只能较为粗略地估计Cd含量的高低,无法准确预测含量值;经过微分变换的光谱曲线预测能力有较高的提升,所建立模型的R
最大值超过0.
80,能够较为准确地预测土壤Cd含量。拟合效果最好的是FD-RF所建立的模型,R
为0.
85,RMSE
为0.
40,NT变换效果最差。基于FD-RF法建立的高光谱模型的预测值与实际值的散点图如图4所示。由图4可见,样本点与1∶1的线很近,说明用此方法建模预测能力高,对土壤Cd含量具有较好的解释能力。
图4 基于FD-RF法土壤Cd含量实测值与预测值散点图
2.5 模型适应性分析
为探究Cd浓度对模型预测能力的影响,以最优反演模型为建模手段,建立不同浓度区间的Cd含量预测模型。将73个样本分为7个浓度区间(Cd~Cd),相邻两个区间的浓度平均值相差约0.20 mg/kg,为排除样本个数与Cd浓度值大小对模型精度评价的影响,每个浓度区间选择40个样本,将同一浓度区间的样本按照8:2的比例随机分成建模集与验证集,同时以R
与RMSE
作为最终的评价指标,研究结果如表3所示。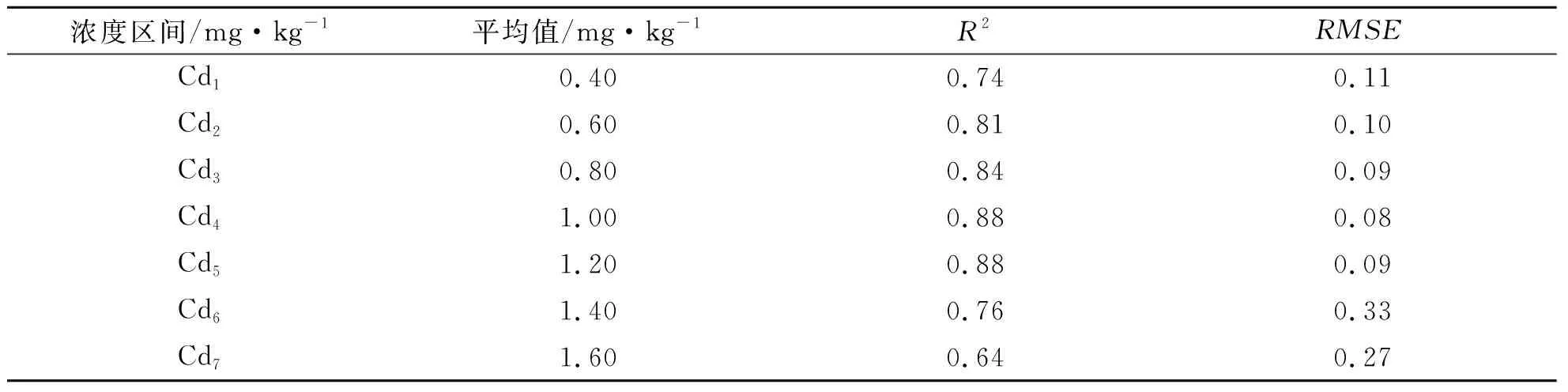
表3 不同Cd浓度区间回归模型统计
从模型的回归效果看,模型对不同Cd浓度的预测能力不同,其中预测能力较高的浓度区间为Cd~Cd,平均值为0.80~1.20 mg/kg,R
均超过0.
80,RMSE
均小于0.10 mg/kg;预测能力较差的浓度区间为Cd,平均值为1.60 mg/kg,R
=0.
64,只能粗略地估计Cd含量值高低。综上所述,当样本浓度平均值变化小于20%时,模型的预测能力较为稳定;当样本浓度平均值变化介于20%~40%时,模型的预测能力下降,当超过40%时,只能粗略估计含量高低,无法准确预测。3 讨论
矿区土壤环境复杂,常年的煤炭开采活动对土壤重金属的空间分布产生较大的影响,不同的土地利用方式使得土壤重金属Cd在一定的区域内发生变异性较大的现象,过高的Cd含量可能对人体造成潜在的危险,因此快速监测土壤Cd含量对于矿区土壤治理具有重要意义。高光谱遥感近年来以其快速、无损、低成本等特点已广泛应用于土壤属性预测。研究以广东省韶关市某矿区为研究对象,利用偏最小二乘与随机森林算法实现土壤Cd含量预测,并对模型进行了适应性分析。
由于Cd在土壤中含量较低,导致土壤光谱反射率与Cd含量的相关性较低。经过不同的光谱变换可以有效放大波光谱中差异不显著的信息,并去除外界因素引起的噪声,进而提升土壤光谱反射率与Cd含量的相关性,但总体上均没有超过0.5。本研究中,与偏最小二乘相比,随机森林具有更好的预测能力,这可能是由于光谱信息与土壤Cd含量之间不仅存在着线性关系,还存在非线性关系,这与陈亦凡的相关研究结果相近。土壤光谱特征是土壤系统与外部环境交互的综合反映,不同的成土母质、粒径大小、有机质含量高低都会影响土壤光谱曲线的形状。在实际模型验证中发现,某些含量较低的样本的预测浓度存在虚高现象,这可能是由于Cd含量较低,其光谱特征被其他土壤成分掩盖,这与彭杰等的研究结果较为一致。通过对比Cd含量在不同浓度下的预测能力可以发现,所建立的模型在不同浓度区间的预测能力不同。在Cd~Cd区间范围内的预测能力较高,在Cd的预测能力最低,与全样本相比,当样本浓度平均值变化小于20%时,模型的预测能力较为稳定;当样本浓度平均值变化超过40%时,模型的参数需要重新调整。这可能是由于当Cd浓度变化过大时,土壤理化性质差异性也变大,影响模型预测精度。近年来,随着不同国家与地区建立的不同尺度的土壤高光谱数据库,积累了大量的土壤光谱基础数据,这为研究提高模型预测适用性提供了数据基础。研究通过偏最小二乘和随机森林算法实现了矿区土壤Cd含量预测,并将样本分成不同的浓度区间,探讨了浓度变化对模型的影响。该思路为今后检测土壤属性参数提供了理论支持。
4 结论
基于本研究实验数据,采用偏最小二乘和随机森林方法建立广东某矿区的土壤重金属Cd含量的高光谱反演模型,重点研究了不同Cd含量下光谱曲线差异以及不同光谱处理方法对建模精度的差异,探究了不同Cd浓度区间对建模精度的影响,明确了运用微分处理方法可以有效提升模型预测精度。结果表明:
(1)Cd含量与光谱反射率呈负相关,Cd含量增加会导致反射率下降,但不会影响特征波段与吸收峰的位置。通过对原始光谱数据进行不同方式的处理,可以有效地去除噪声的影响,提高相关性。其中一阶微分效果最佳,在1 406 nm处达到最大值,相关系数r
=-0.
503。(2)基于不同回归方法建立回归模型,预测效果最佳的模型为FD-RF,模型的预测值与实测值的R
=0.
83、RMSE
=0.
40,对于理化性质差异较大的土壤,非线性模型的预测能力优于线性模型。当样本浓度平均值变化小于20%时,模型的预测能力较为稳定;当样本浓度平均值变化介于20%~40%时,模型的预测能力下降,当样本浓度平均值变化超过40%时,只能粗略估计含量高低,无法准确预测。猜你喜欢
农业工程学报(2022年8期)2022-08-08
农业灾害研究(2022年2期)2022-05-31
科学24小时(2019年6期)2019-09-05
都市生活(2019年6期)2019-08-07
商情(2019年9期)2019-04-01
饮食与健康·下旬刊(2019年9期)2019-03-08
饮食与健康·下旬刊(2018年3期)2018-04-11
成长·读写月刊(2018年1期)2018-01-15
光学仪器(2016年6期)2017-04-24
考试周刊(2016年44期)2016-06-21
