
基于轻量化SSD 的菜品识别
2021-12-01 05:26姚华莹彭亚雄陆安江
智能计算机与应用 2021年8期
姚华莹,彭亚雄,陆安江
(贵州大学 大数据与信息工程学院,贵阳 550025)
0 引言
近年来,人工智能被研究人员广泛关注并设计研究出大量的人工智能产品[1]。深度学习中的图像识别技术取得的丰硕成果让人们的生活方式更加智能化、高效化。菜品智能识别可以部署在智能餐厅,用于菜品价格自动结算,安装在移动设备实时检测当前食物的卡路里等详细信息等[2-4],目标检测算法可以实现这一效果。卷积神经网络通过输入的图像数据进行训练,像人类的大脑一样学习图像特征[5],准确的分类出菜品。目标检测算法分为双阶段检测和单阶段检测。其中,双阶段检测算法中具有代表性的是R-CNN[6]和Faster-R-CNN[7]算法,这类双阶段算法检测精度高,但检测速度较慢。另一类单阶段检测算法YOLO[8](You Only Look Once),是继R-CNN 之后,为解决目标检测速度问题而提出的另一个框架,在定位边界框的同时获取类别概率,牺牲了一部分检测精度以达到更快的检测速度;由Liu 在ECCV 上提出的多尺度单发射击检测算法[9](Single Shot MultiBox Detector,SSD)在不同尺度的特征图中多步提取特征。与R-CNN 相比,SSD速度更快;与YOLO 相比,SSD 在检测精度mAP 上有更好的性能,在不降低检测精度的同时保证了检测速度。由于以上目标检测模型包含大量的卷积计算,有大量参数,仅能运行在高性能图像处理器上,不利于移植到数据处理弱的平台。
为此,本文基于优秀的轻量型神经网络MobileNetV2[10]对SSD 网络进行改进,构建轻量型的菜品识别模型。使用注意力机制[11]和混洗通道[12]构建注意力逆残差结构提高检测准确率。设计回归定位损失函数,加快模型收敛速度。根据菜品数据集特点设置回归预测层,提升模型检测速度。通过使用数据集Chinesefood 对模型训练,验证了本文提出的Att_Mobilenetv2_SSDLite 目标检测网络检测效果更佳。
1 SSD 目标检测模型原理
单阶段检测是基于回归的算法(例如YOLO、SSD 等),把提取候选区域框和特征提取融合在同一网络中,同时实现候选区域选择和分类。检测网络由基础网络层和回归预测层两部分组成。基础网络层用于提取输入图像特征,基础网络很大程度上能影响检测的精度、速度以及检测网络体积;回归预测层用于生成预测框及分类目标。SSD 采用基于金字塔特征层的检测方式,在不同尺度的特征图上进行位置回归和分类。如图1 所示。SSD 模型结构的前端是用于提取图像特征的基础网络层,后端是用于回归预测的附加层。

图1 SSD 网络结构Fig.1 Network architecture of SSD
基础网络层使用了VGG-16[13]网络的前5 层卷积层,并将VGG-16 网络中原有的全连接层FC6 和FC7 改为卷积层Conv6 和Conv7,提取基本特征;在后端附加4 个尺度大小不同的卷积层,用于高级特征提取。表1 为SSD 网络参数,整个网络包含6 个特征预测层,前端浅层特征图分辨率高,用于预测小目标;后端深层特征图分辨率低,用来预测较大的目标。
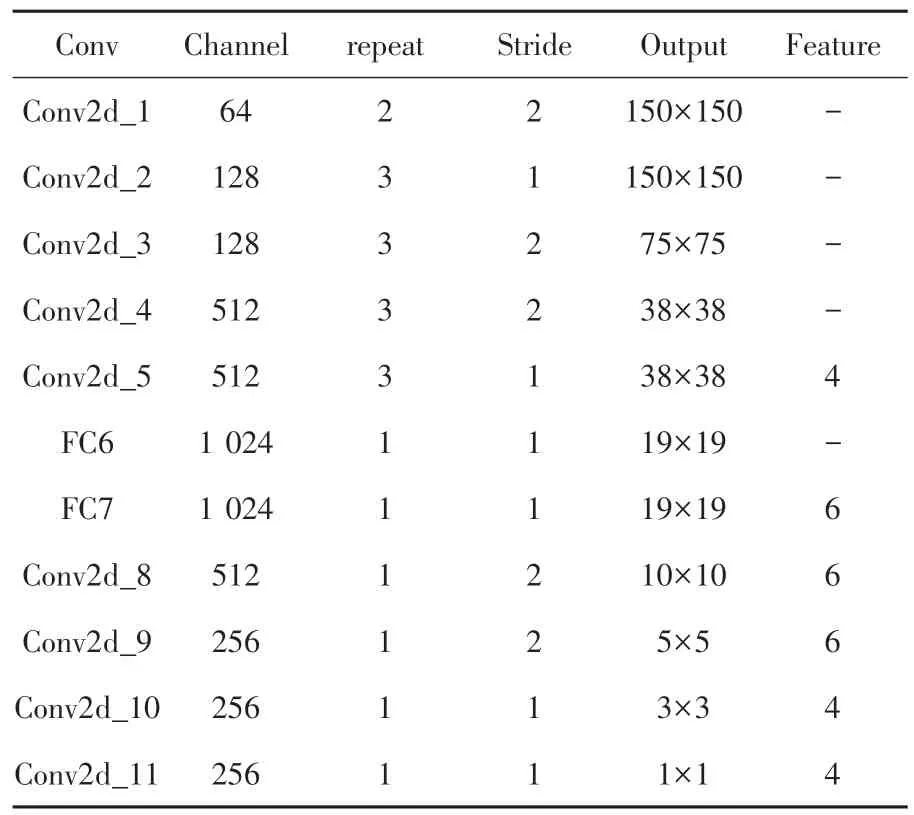
表1 SSD 网络参数Tab.1 SSD network parameters
SSD 网络在基础网络中使用了VGG-16,而VGG-16 使用了大量的传统卷积,导致模型体积庞大,参数量多,这些弊端导致其难以部署在计算力和存储空间受限的设备中。为了解决这一问题,本文基于MobileNetV2 轻量型卷积网络替换VGG-16 网络,对SSD 进行轻量化改进,针对菜品目标检测的特点,修改SSD 网络层结构,获得针对菜品识别的目标检测网络Att_Mobilenetv2_SSDLite。
2 MobileNetV2 模型
MobileNetV2 网络是Google 团队对MobileNetV1的进一步调整,沿用了深度可分离卷积,减少卷积计算量,同时借鉴ResNet 中的残差结构,设计了逆残差结构,提高网络对低维空间的特征提取能力[14]。
2.1 深度可分离卷积
深度可分离卷积[15](Depthwise sparable convol⁃ution),将传统卷积分为一个深度卷积和一个点卷积。首先进行深度卷积,即对每个输入的通道,分别用单个卷积核进行相对应的卷积计算后,用1×1 的卷积核对深度卷积结果进行线性组合,构建新的特征,这个过程为点卷积。如果不考虑偏置参数,深度分离后的卷积参数运算量为:

标准卷积计算量为:
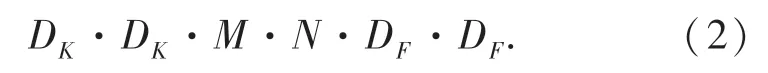
其中:DK·DK为卷积核尺寸;DF·DF为输入图像尺寸;M和N分别是输入通道数量和输出通道数量。传统卷积的计算量是深度可分离卷积的1/M +1/K2,当卷积核大小为3×3 时,计算量相比传统卷积减少了9 倍多,能明显提升运算速度及检测效率。
2.2 逆残差结构
残差结构是先对输入图像降维、卷积、再升维,如图2(a)所示。文献[16]中先使用1×1 的卷积,将输入通道压缩至原来的1/4,然后再用3×3 的卷积进行计算,最后使用1×1 的卷积对通道数目还原。残差结构通过旁干分支,将前端特征与通过一系列卷积处理后的特征进行融合,可以提高整个网络的特征提取能力。如图2(b)所示,MobileNetV2的逆残差结构与残差结构相反,对输入图像升维、通过深度可分离卷积、降维。先使用了1×1 卷积,将输入通道数目扩大至原来的6 倍,再经过深度可分离卷积处理,最后通过1×1 卷积恢复通道数目。对输入通道数目扩展是一个升维的过程,这样做的好处是,可以提取低维特征图上的有效特征,使用了深度可分离卷积后计算量也不会增加[17]。与ResNet的残差结构一样,最后会将主干分支与旁干分支特征融合。

图2 残差结构与逆残差结构对比Fig.2 Comparison of residual structure and inverse residual structure
2.3 MobileNetV2 结构
MobileNetV2 的网络结构参数见表2,共包含19个层。其中,在7 个不同尺度的特征图上会重复逆残差结构(Inverted Residual)1~4 次不等,Conv2 为普通卷积,在通过所有的逆残差块后,特征图经过一个卷积层和平均池化层(Avgpool)可以得到k个类别的分类。

表2 MobileNetV2 网络参数Tab.2 MobileNetV2 network parameters
3 Att_Mobilenetv2_SSDLite 模型
Att_Mobilenetv2_SSDLite 目标检测算法网络结构如图3 所示。将SSD 的基础卷积层替换为改进后的MobileNetV2,在逆残差结构中增加通道注意力机制和混洗通道加强特征融合,然后对区域候选框进行重构。分别在网络的Conv11、Conv13 _2、Conv14_2、Conv15_2、Conv16_2 这5 个尺寸不同的特征层中生成预测框,预测框的数量由8 732减少为2 254;最后通过非极大值抑制,去除置信度低于0.5的边框线条,得到检测结果。

图3 Att_Mobilenetv2_SSDLite 网络结构Fig.3 Network architecture of Att_Mobilenetv2_SSDLite
Att_Mobilenetv2_SSDLite 使用深度可分离卷积,替换原SSD 网络中额外增加层的标准卷积层,极大减少了运算量。基础网络使用MobileNetV2,轻量型的基础网络对SSD 网络的检测精度、检测速度和模型体积上都有良好的影响。
Att_Mobilenetv2_SSDLite 网络模型参数见表3。基础网络层保留了MobileNetV2 的Conv1~Conv11,使用Att-Inverted Residual 逆残差结构,缩减残差结构的重复次数,去掉最后用于分类的全连接层和池化层;额外添加3 个卷积层作回归预测层。

表3 Att_Mobilenetv2_SSDLite 网络参数Tab.3 network parameters of Att_Mobilenetv2_SSDLite
3.1 逆残差结构优化
如图4 所示,本文采用的注意力逆残差结构(Attention Inverted Residual)与ResNet 相反,在主干分支先对输入通道使用1×1 的卷积进行扩张,在高维度上再使用深度卷积,而后再次经过1×1 的卷积;在残差结构旁干分支中使用注意力算法,融合主干分支和旁干分支两类特征,最后将学习到的特征,通过混洗通道打乱重组,破除固定通道间特征无法学习的障碍,进一步提高网络的特征提取能力。

图4 Att_InvertedResidual 结构Fig.4 Att_InvertedResidual structure
旁干分支中,先对输入通道进行全局池化压缩操作(Squeeze),经过压缩处理后的二位特征通道将变成不同值的实数,表示其在特征通道中响应的全局分布;然后经过FC 全连接层、ReLU、FC、Sigmoid的激活操作(Excitation),得到每个实数对应的权重;最后再经过加权操作(Reweight),分别给每个通道特征乘上权重,将权值赋给对应通道。通过注意力加权操作后,网络将重点关注权值更大的通道特征,有利于提取特征。
在逆残差结构的最后,用混洗通道操作(shuffle channel)打乱重组通道特征,是基于通道分组卷积实现的混洗通道卷积,将输入通道特征分为g组,每组分别与对应的卷积核卷积,卷积计算量降为原有的1/g,然后对g组通道打乱重组。原本封闭固定的通道在打乱重组后特征得到了交流,解决了由固定分组导致特征融合效果差的问题。
在本文提出的Att_MobileNetV2_SSDLite 模型中,将基础网络MobileNetV2 的逆残差结构替换为Att-InvertedResidual 结构。实验证明,本文的残差结构可以在减少卷积层数量的同时保证特征提取能力。
3.2 回归定位损失函数优化
特征层中提取到的预测框,通过最后的非极大值抑制,得到置信度较高的预测框,再经过损失函数处理后,最终输出检测结果。SSD 的损失函数包含预测框定位回归损失(SmoothL1 损失函数[18])和类别置信度分类损失(Softmax损失函数)。
在回归过程中,对预测框和默认框重合程度的度量标准是交并比[9](IOU),表示预测框和默认框重合部分占预测框和默认框总面积的比例,用公式表示为:

但这种简单的面积交并比,并不能很好的反应预测框和默认框的重叠情况。例如:A∩B =0 时IOU =0,这时IOU无法反向传递梯度,不能指导训练参数改变;并且当A∩B≠0 时,预测框和默认框有多种重叠形式,同样不能指导梯度传递。为此,本文考虑预测框与默认框的重叠程度,对IOU的计算方式做部分改进。将预测框与默认框两中心点欧式距离作为惩罚项,与预测框和默认框重叠面积的最小矩形对角线做比,用公式表示为:

其中,d2(A,B)表示预测框A中心点与默认框B中心点的欧式距离,c2表示预测框A与默认框B最小覆盖的矩形面积的对角线距离。用左上和右下两点坐标表示定位框位置,预测框记:A =(x1,y1,x2,y2);默认框记:;预测框A与默认框B最小覆盖的矩形C记:。
预测框面积S与默认框面积S′分别记为:

重叠面积SO为:
——针对江苏省连云港市第二人民医院腐败案暴露出的问题和搞“团团伙伙”的严重危害性,江苏省连云港市委常委、纪委书记、监委主任刘海涛撰文称,要坚持惩前毖后、治病救人的原则,把严管和厚爱结合起来,系统运用“四种形态”;对于违反政治纪律和政治规矩的苗头性倾向性问题,早发现早提醒早处置,将问题解决在未发之际,持续建设风清气正的政治生态。(《中国纪检监察报》11月2日)

得到IOU为:
预测框与默认框最小覆盖矩形对角线Cl为:
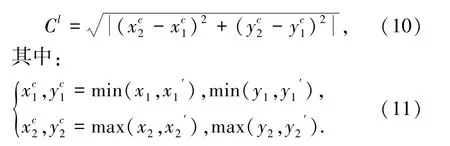
预测框A与默认框B中心点分别为:

欧式距离为:

最后可以得到预测框回归损失函数为:

3.3 预测候选框
预测候选框[9]是在特征图上,按一定纵横比(aspect retios)生成的可能包含预测目标的预测候选框,浅层分辨率高的特征图主要检测小目标,深层分辨率小的特征图检测大目标。预测候选框通过非极大值抑制算法后,输出与目标最为匹配的检测框。表4 与表5 分别列出了SSD 与本文算法Att_Mobilenetv2_SSDLite 在不同尺度特征图上对应的预测候选框数量。本文主要检测目标为菜品,菜品目标通常是图片中占比最大的目标,故本文在设置默认候选框时,关注更深层的特征图的默认候选框。

表4 SSD 与Att_Mobilenetv2_SSDLite 网络参数Tab.4 SSD and Att_Mobilenetv2_SSDLite network parameters
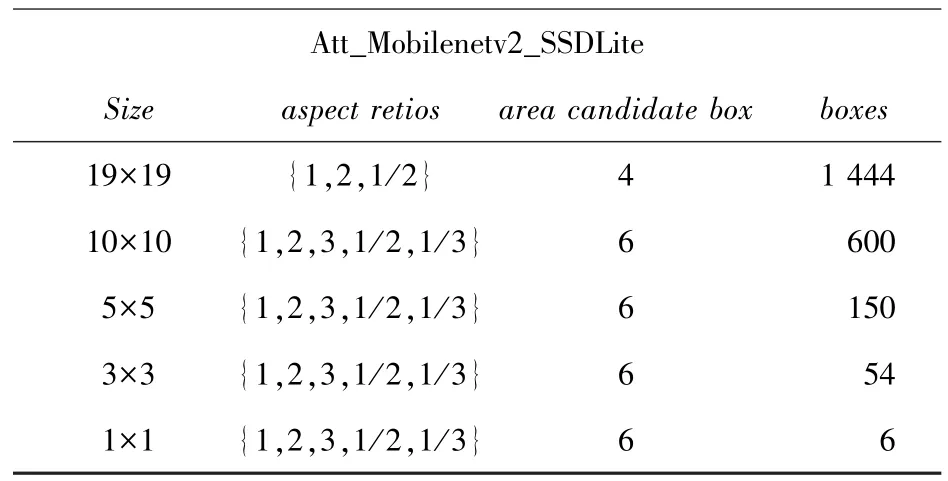
表5 Att_Mobilenetv2_SSDLite 网络参数Tab.5 Att_Mobilenetv2_SSDLite network parameters
第k个默认候选框的大小Sk计算方式为:

特征图上的每个像素点都会生成4 个或6 个默认候选框,本文提出的Att_Mobilenetv2_SSDLite 网络生成2 254 个默认候选框,主要舍弃了用于检测小目标的预测框。
4 实验结果与分析
本文针对菜品识别设计了Att_Mobilenetv2_SSDLite 网络,使用改进后的Att_MobileNetV2 作基础网络提取特征,额外增加3 个卷积层作为回归预测层。为了减小模型体积和提高检测速度,类别置信度与定位回归预测中均使用可分离卷积代替传统卷积。针对IOU不能很好反应预测框与默认框之间的重叠效果,设计了LMIOU回归损失函数,替换SmoothL1 损失函数。
4.1 实验环境与数据
实验环境为pytorch1.7、python3.7,AMD Ryzen 7 4800H 处理器,NVIDIA RTX 2060 6G,在windows 环境下运行,使用数据集格式为PASCAL VOC。数据集为自建中餐菜品数据集Chinesefood,选取中餐菜品数据集release_data 中的20 类菜品,每个菜品1 067张图片,数据集共包含21 340 张图片;使用LabelImg 标准软件生成VOC 格式数据集,按照80%、10%、10%的比例划分训练数据、验证数据和测试数据。Batchsize设为32,初始学习率设为0.001,动量为0.9,每迭代50 次降低学习率为上一阶段0.5。
4.2 评价指标
实验评价指标为检测速度(fps)、平均准确率(Average Precision,mAP)和平均召回率(Average Recall,AR)。fps表示每秒检测图片数量,值越高表示检测速度越快;mAP表示不同阈值条件下的平均准确率,值越高表示检测效果越好;AR表示平均召回率,值越高表示漏检率越低。

式中,TP表示正样本中预测正确部分;FP表示正样本中预测错误部分;FN表示负样本中预测错误部分。
4.3 实验结果
对比实验设计,使用不同数量回归预测层的网络进行对比,寻找最合适数量的回归预测层;针对本文提出的改进点进行控制变量组合训练,探索改进点对网络整体提升能力。训练过程使用自建的中餐菜品数据集Chinesefood,并对输入的图像随机翻转、裁剪以及颜色随机调整。
4.3.1 不同数量回归预测层对比
本文设计了分别有4、5、6 个回归预测层的SSD模型。表6 列出了不同层结构的网络在菜品数据集上的表现,其中features_number表示该模型包含回归预测层的个数。
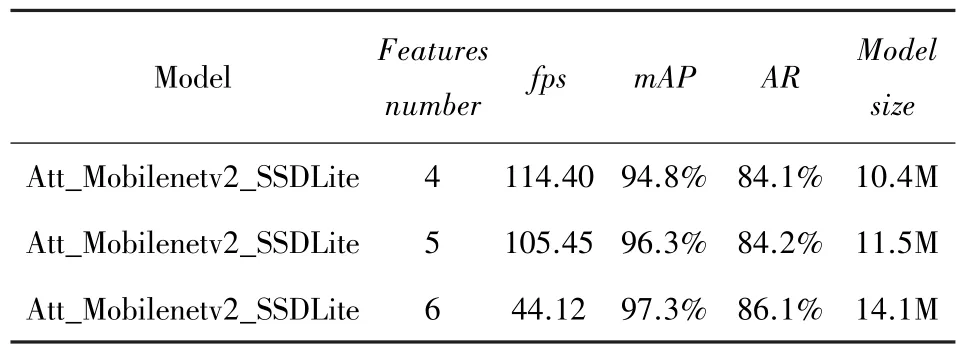
表6 不同数量预测层模型检测对比Tab.6 Comparison of model detection with different numbers of prediction layers
回归预测层数量越多,模型检测准确率越高,但是模型计算量随之增加,导致检测速度下降,每增加一层,准确率大约提升1%,模型体积增大1~2 M,见表5。回归预测层数量为4 时,检测速度最快,模型体积也最小,但检测准确率与召回率最低;回归预测层数量为6 时,准确率和召回率最高,但检测速度大幅下降,模型体积也增大。图5 为不同数量特征层的检测效果。本文使用5 个回归预测层的模型表现最好,保证了速度和准确率,模型体积也控制在合适范围。

图5 不同数量预测层检测效果Fig.5 The detection effect of different numbers of prediction layers
4.3.2 模型优化效果
实验中分别比较了注意力逆残差块(Att-InvertedResidual)、深度可分离卷积(SperableConv2d)和回归定位损失函数(LMIOU)对模型的增益效果。从表7 结果可见,注意力逆残差块提升准确率约0.9%,深度可分离卷积可减小模型体积约24.6 M,回归定位损失可提高准确率1.6%,召回率1.2%。

表7 不同结构对比Tab.7 Comparison of different structural
图6 对比了使用LMIOU和SmoothL1 分别作为回归定位损失的损失变化图。实验表明,LMIOU损失函数对IOU 计算方式的调整,能更全面的了解预测框与默认框的重叠关系,加快模型收敛,损失值下降更快,提升网络识别准确率。

图6 不同损失函数对比Fig.6 Comparison of different loss functions
4.3.3 不同模型效果比较
从表8 可以看出,对比其它的目标检测模型,本文设计的模型相比SSD300、Tiny YOLO 和Mobilenetv1_SSD,准确率相似,但模型体积最小,检测速度也最优越。对比Tiny SSD300,本文的模型虽然体积略大,但准确率和速度都远远大于Tiny SSD300。图7 对比了不同模型对菜品的检测效果,综合模型体积、准确率和速度,本文的模型相比SSD 和YOLO 具有更好的效果。

图7 不同目标检测模型检测效果Fig.7 The detection effect of different target detection models
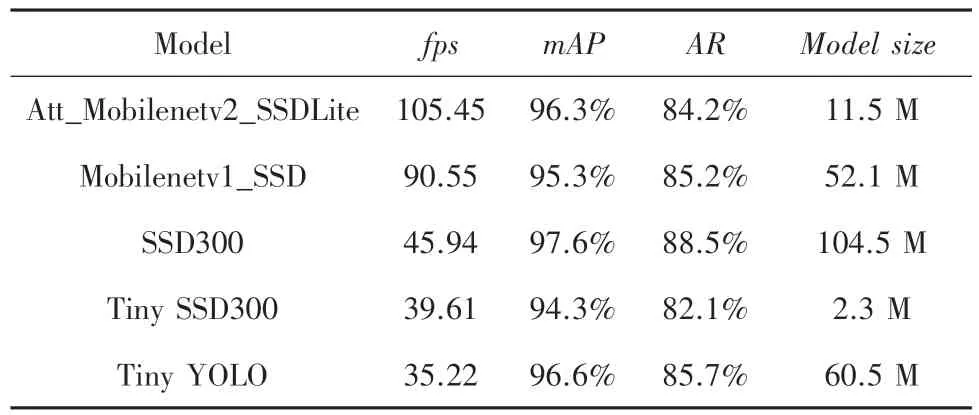
表8 不同模型检测对比Tab.8 Comparison of different models
5 结束语
本文针对菜品识别设计了基于SSD 的轻量型目标检测网络Att_Mobilenetv2_SSDLite 模型,该模型采用MobileNetV2 作为基础网络,缩小模型体积提升检测速度。对原MobileNetV2 模型中的逆残差结构做调整,使用注意力机制和混洗通道增强特征提取能力。考虑预测框与默认框位置重叠因素设计回归损失函数,加快模型收敛。重新规划回归预测层数量,重点关注图片中大目标,提高检测准确率。通过与其他目标检测网络对比,本文提出的模型更加适合识别菜品,并且适合部署在存储能力弱的其他平台。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
