
一种基于无监督主动学习的苹果品质光谱无损检测模型构建方法
2022-01-12 00:19赵小康朱启兵
光谱学与光谱分析 2022年1期
赵小康,赵 鑫,朱启兵,黄 敏
江南大学轻工过程先进控制教育部重点实验室,江苏 无锡 214122
引 言
光谱检测技术因其快速、无损等特点而广泛用于农产品、食品品质检测领域[1-5]。在利用光谱检测技术进行农产品、食品品质无损检测时,通常都需要一定数量的训练样本(包含光谱特征和理化品质指标)来构建预测模型。目前,已有多种建模方法被用于构建预测模型,例如:偏最小二乘回归模型(partial least square regression,PLSR)、支持向量回归模型(support vector regression,SVR)。在实际应用中,无论用何种建模方法构建光谱预测模型,预测模型的性能都严重依赖于训练样本的多样性和代表性。为了保证训练样本的多样性和代表性,人们往往需要获得大量的训练样本;但训练样本的品质指标(标签)多是通过破坏性理化实验获得,需要较高的时间和人力成本。相比于理化指标检验,样本的光谱信息获取较为容易。如果可以从大量的无标签样本(仅有光谱信息)中选取最有价值的样本进行标注,将有助于减少训练样本标注的盲目性,达到利用少量训练样本获得良好预测模型的目的。Kennard-Stone算法(KS)和光谱-理化值共生距离算法(SPXY)是光谱领域两种较为常见的样本选择方法。KS算法首先选择欧式距离最大的一组样本加入到训练集,然后依次选择一个样本,使已选样本与剩余样本的欧式距离最大,由于样本间的相似性通过欧式距离计算,其选择样本的空间分布易受离散点的影响,样本的代表性难以保证。而SPXY算法[2]在KS算法的基础上增加了对样本输出空间距离的考虑,因此需要获得样本的真实标签值。SPXY算法是一种有监督样本选择方法,在实际应用中仍然需要大量的理化分析,以获得样本标签值。
主动学习是近年来提出的,综合考虑样本代表性、信息性或多样性的样本选择策略,已被广泛地运用于构建有监督分类模型。例如:王立国等[6]将主动学习算法用于高光谱图像分类任务中;唐金亚等[3]利用主动学习算法研究了玉米种子纯度分类模型的更新。但目前,主动学习在农产品、食品品质预测模型中的应用还鲜有报道。本文将结合农产品、食品品质无损检测的需要,提出了一种融合层次凝聚聚类(hierarchical agglomerative clustering,HAC)和局部线性重建算法(locally linear reconstruction,LLR)的无监督主动学习方法(HAC-LLR)。HAC-LLR利用HAC聚类算法对原始光谱样本集进行聚类操作,以获得具有多样性的多个样本簇;针对不同的样本簇,通过LLR选取最具代表性的样本;最后基于选取的代表性样本及其理化指标,构建训练模型。实验结果表明,相比于已有算法,HAC-LLR方法在训练样本数量相同的前提下,可以显著提高光谱模型的预测性能。
1 基于HAC-LLR的无监督主动学习方法
根据统计学习理论,要获得一个具有良好泛化性能的预测模型,用于构建预测模型的训练样本应该能够充分刻画整体样本的概率分布,即训练样本应该具有良好的代表性和多样性。代表性是指训练样本的概率分布应该能够代表整体样本的概率分布状态;而多样性是指训练样本应该尽可能地分布在整体样本空间,以实现整体样本空间的充分表达。多样性和代表性通常会存在一定的矛盾,为了解决这一矛盾,本文提出了HAC-LLR无监督主动学习方法,该方法首先对待选样本集进行聚类分析,获得多个样本簇;在不同簇中通过局部线性重建算法选出最具代表性的样本,从而使选择的样本兼具多样性和代表性。
1.1 基于层次凝聚聚类的样本集划分
聚类算法将数据集划分到不同子集中,使得子集内的数据相似度最大,子集间的数据相似度最小,从而可以发现数据中隐藏的模式和规律。本文利用无需预先设定聚类簇数的层次凝聚聚类方法对数据集进行聚类分析。层次凝聚聚类首先对数据集进行初始化,即将每个样本初始化为单独的簇,并计算两两簇之间的距离,然后寻找相距最近的两个簇进行归并,删除合并前的簇,保留新生成的簇,重复该过程,直到所有簇都归为一个大类[7]。整个聚类过程其实是建立一棵树,聚类结果可以根据最终生成的聚类树设置距离阈值,簇间距离大于设定值的不同簇即为期望得到的聚类结果。本文中,根据光谱数据特性,簇间距离采用相似性计算,簇间聚合方式为未加权平均距离法,根据生成的聚类树及聚类结果评价指标,距离阈值设定为0.8。
1.2 基于局部线性重建算法的代表性样本选择策略
光谱数据多是高维数据,一个高维数据通常是由其低维潜在变量按照某种规则重建获得的。假设X=[X1,…,Xm]T是已知的原始高维数据集,Q=[q1,…,qm]T是与X同维的由低维潜在变量重建的数据集。LLR算法认为已知数据集X应该与重建数据集Q具有相同的邻域表示关系。即对于任意一个样本Xi,若其可以由其邻域Np(Xi)内(相邻数据点)的点线性表示为

Wij=0 ifXj∉Np(Xi)
(1)

(2)
式(2)中,μ是惩罚系数,用于调节重建误差和重构样本Q的邻域关系表示误差。本文中设置为0.1。
定义Λ为m×m的对角矩阵,如果i∈{s1,…,sk},则对角元素为Λii=1,否则Λii=0。则目标函数(2)可以重新被写成如式(3)矩阵形式
ε(Q)=Tr((Q-X)TΛ(Q-X))+μTr(QTMQ)
(3)
式(3)中,M=(I-W)T(I-W),I为单位对角阵,Tr为矩阵求迹运算。式(3)最小化,则重建结果可以表示为
Q=(μM+Λ)-1ΛX
(4)
对于原始样本点x1,…,xm和样本点重建结果q1,…,qm,重建误差可以表示如式(5)
(5)
式(5)中,重建误差只与所选择的点{s1,…,sk}有关,因此,最具代表性的点可以定义为那些能够最小化重建误差的点,即如果所选样本点确定,可以更准确地重建整个原始数据集。式(5)可以通过迭代求解策略获得,其详细计算过程见参考文献[8]。
1.3 基于HAC-LLR训练样本选择策略的光谱检测方法流程
基于HAC-LLR训练样本选择策略的光谱检测方法流程主要包括:(1)利用层次凝聚聚类对大量的无标记光谱数据集进行聚类分析,根据生成的聚类树和设定的簇间距离阈值划分出不同的数据簇;(2)针对每个数据簇,利用局部线性重建算法,选取一定数量的待标记样本(该簇样本数量占样本总数的比例乘以期望选出样本的总数k即为每个簇应选出的样本数),从所有的簇中总共选出设定的k个样本;(3)对选出的样本根据具体检测指标,进行理化分析,获得其标签值Y,构建训练集样本对(Xi,Yi)i=1,…,k;(4)利用训练集样本,训练输出模型;(5)利用模型对预测集样本进行预测。图1给出了算法的流程示意图。

图1 基于HAC-LLR训练样本选择策略的光谱检测方法流程图Fig.1 Flow chart of spectral detecting method based on HAC-LLR training samples selecting strategy
2 实验部分
实验样本是美国密歇根州立大学克拉克斯维尔园艺实验站果园提供的Golden Delicious(GD),Jonagold(JG)和Red Delicious(RD)三个品种的苹果,采收于2009年和2010年连续两个年份。样本的光谱数据通过微型Vis-SWNIR光谱仪(S400,Ocean Optics,Dunedin,FL)采集。Vis-SWNIR光谱仪的光谱范围为460~1 100 nm,光谱分辨率为1 nm,每个光谱样本有641个变量。获得光谱数据之后,使用质地分析仪(型号TA.XT2i,Stable Micro Systems,Inc.,Surrey,UK)和数字折射仪(型号PR-101,Atago Co.,Tokyo,Japan)在光谱仪测量的位置对苹果的硬度和可溶性固形物(soluble solid content,SSC)进行测量。实验设备和数据的更详细信息参见文献[9]。
表1给出了实验样本的SSC和硬度统计数据表。由表1可以看出,SSC和硬度的分布范围较大,可以充分验证模型的性能。图2为不同年份、不同种类苹果样本的平均光谱。从图中可以看出,不同年份、不同种类的苹果光谱存在着较大差异,难以用一个单一模型进行建模,需要对不同年份、不同种类的苹果构建多个模型。

表1 苹果样本的品质参数统计信息Table 1 Statistics of quality reference for apple samples
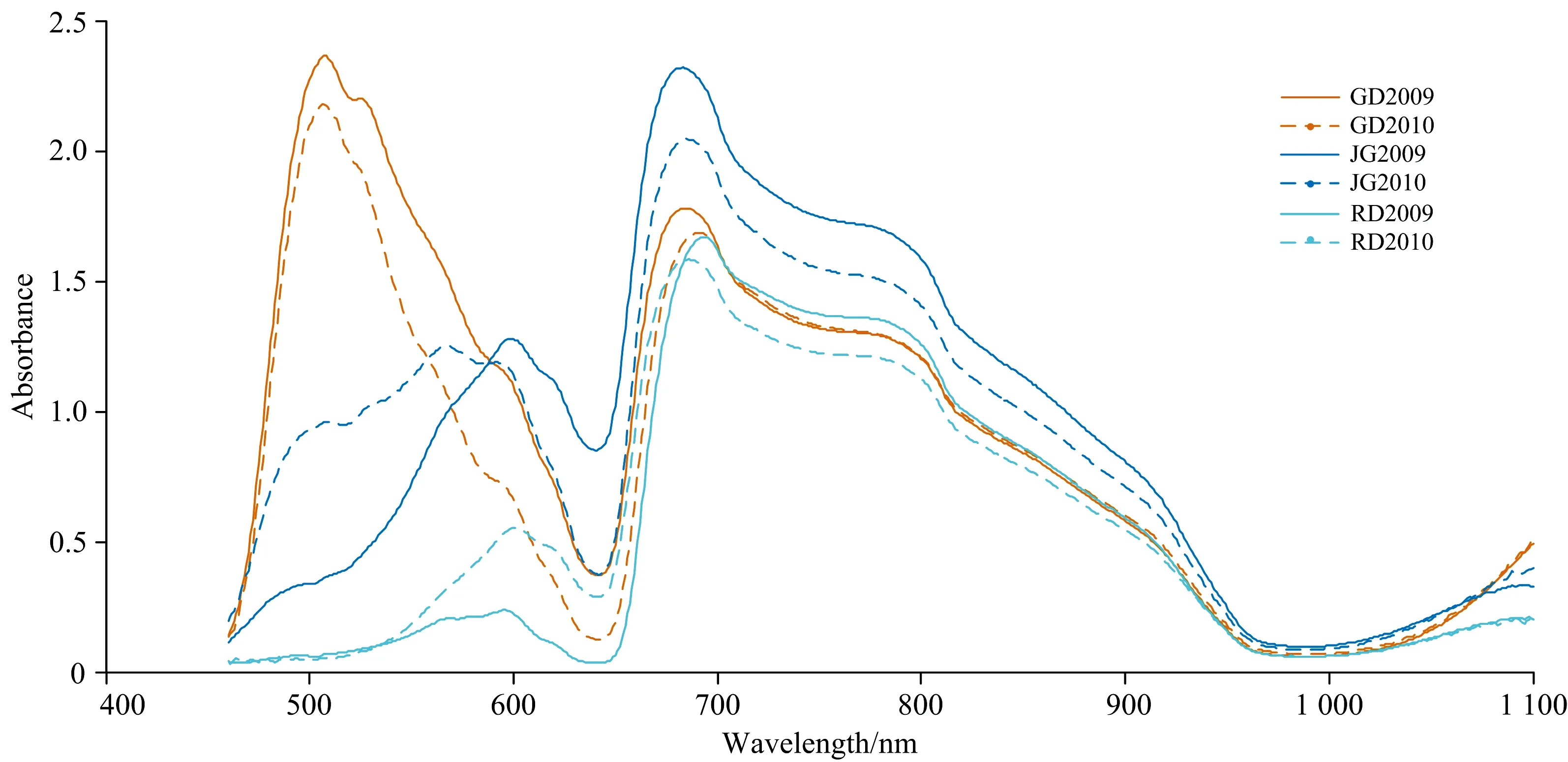
图2 连续两年采收的三种苹果的平均光谱Fig.2 The average spectra of three cultivars apple samples harvestee from two years
3 结果与讨论
3.1 基于HAC-LLR训练样本选择策略的苹果品质检测模型的建立
基于无监督主动学习算法选取一定数量的样本用于建立苹果品质检测模型。为充分验证基于无监督主动学习算法的模型性能,针对每个数据集,首先随机选取100个未标记样本作为预测集,其余未标记样本作为样本选择池。基于该样本选择池,分别利用随机采样(RS)、Kennard-Stone算法(KS)、光谱-理化值共生距离算法(SPXY)和本文提出的HAC-LLR样本选择策略,选出一定数量的样本作为训练集,用于训练PLSR模型。利用预测集均方根误差(RMSE)、相关系数(Rp)和残留预测偏差(residual prediction deviation,RPD)评估最终的模型性能。为了减少预测集样本随机选取对实验结果的影响,每次实验过程随机重复5次,5次随机实验的平均值作为最终结果。考虑到每个光谱样本有641个变量,为了避免模型的过拟合,利用竞争自适应重加权采样算法[10](competitive adaptive reweighted sampling,CARS)对原始特征进行筛选,其中,105,120,82,94,131,106,125,90,96,112,103和120个特征变量分别作为GD2009,GD2010,JG2009,JG2010,RD2009和RD2010的SSC和硬度PLSR模型的输入。PLSR模型的最佳主元数量通过10折交叉验证确定。
PLSR建模和光谱数据分析软件分别是PLS工具箱(Eigenvector Research,Inc.,Wenatchee,WA,USA)和MATLAB R2014a(The MathWorks,Inc.,Natick,MA,USA)。
3.2 基于不同样本选择算法的建模结果比较
对于不同数据集,按照与预测集1∶1,2∶1,3∶1和4∶1的比例划分,四种算法分别选取100,200,300和400个样本作为训练集,用于建立PLSR模型。图3给出了不同数据集下PLSR模型的预测结果。从图3中可以看出,随着训练集样本数量的增加,四种样本选择算法建立的模型性能都有所提高(RMSE值降低、Rp和RPD值增高)。相比于其他三种算法,本文提出的无监督主动学习算法表现出了最佳的预测性能,特别是在建模集样本数量较少的情况下。当建模集样本数量较多时,不同样本选择算法选出的样本共性较大,模型也趋于稳定,主动学习方法的优势也会逐渐减弱。同一品种不同年份的苹果样本所对应的模型性能也表现出了一定差异,进一步验证了需要对不同年份、不同品种的苹果构建多个模型的设想。另外,四种算法分别选出200个样本所建立模型的预测性能如表2、表3所示,基于HAC-LLR的SSC模型相对于基于RS,KS和SPXY的SSC模型预测结果的RMSE值分别降低了2.0%~8.6%,3.6%~7.9%和2.8%~13.2%,对于硬度模型,RMSE值相应地分别降低了2.6%~7.2%,1.2%~7.2%和2.6%~15.7%。

表2 四种算法分别选出200个2009年的样本所建立PLSR模型的预测结果Table 2 The prediction results of PLSR models based on 200 samples from 2009 selected by four algorithms respectively

表3 四种算法分别选出200个2010年的样本所建立PLSR模型的预测结果Table 3 The prediction results of PLSR models based on 200 samples from 2010 selected by four algorithms respectively

图3 不同数据集下基于不同样本选择算法的SSC (a)和硬度(b)的PLSR模型预测结果Fig.3 PLSR mdoel prediction results of SSC (a)and firmness (b)based on different sample selection algorithms under different datsets
为了比较不同算法性能的统计学意义,本文进一步利用参考文献[11]定义的曲线下面积(area under curve,AUC)作为综合性能度量指标对模型的RMSE,Rp和RPD进行分析(图4所示)。本文使用RS算法的AUC值对其他三种算法进行标准化,因此RS算法的AUC值始终为1。对于RMSE值而言,较小的AUC值代表较高的模型性能,对于Rp值和RPD值而言,较高的AUC值代表较高的模型性能。从图4可以看出,基于本文提出的HAC-LLR训练样本选择策略所建立的模型,预测无标记样本的AUC-RMSE值更低,AUC-Rp值和AUC-RPD值更高。
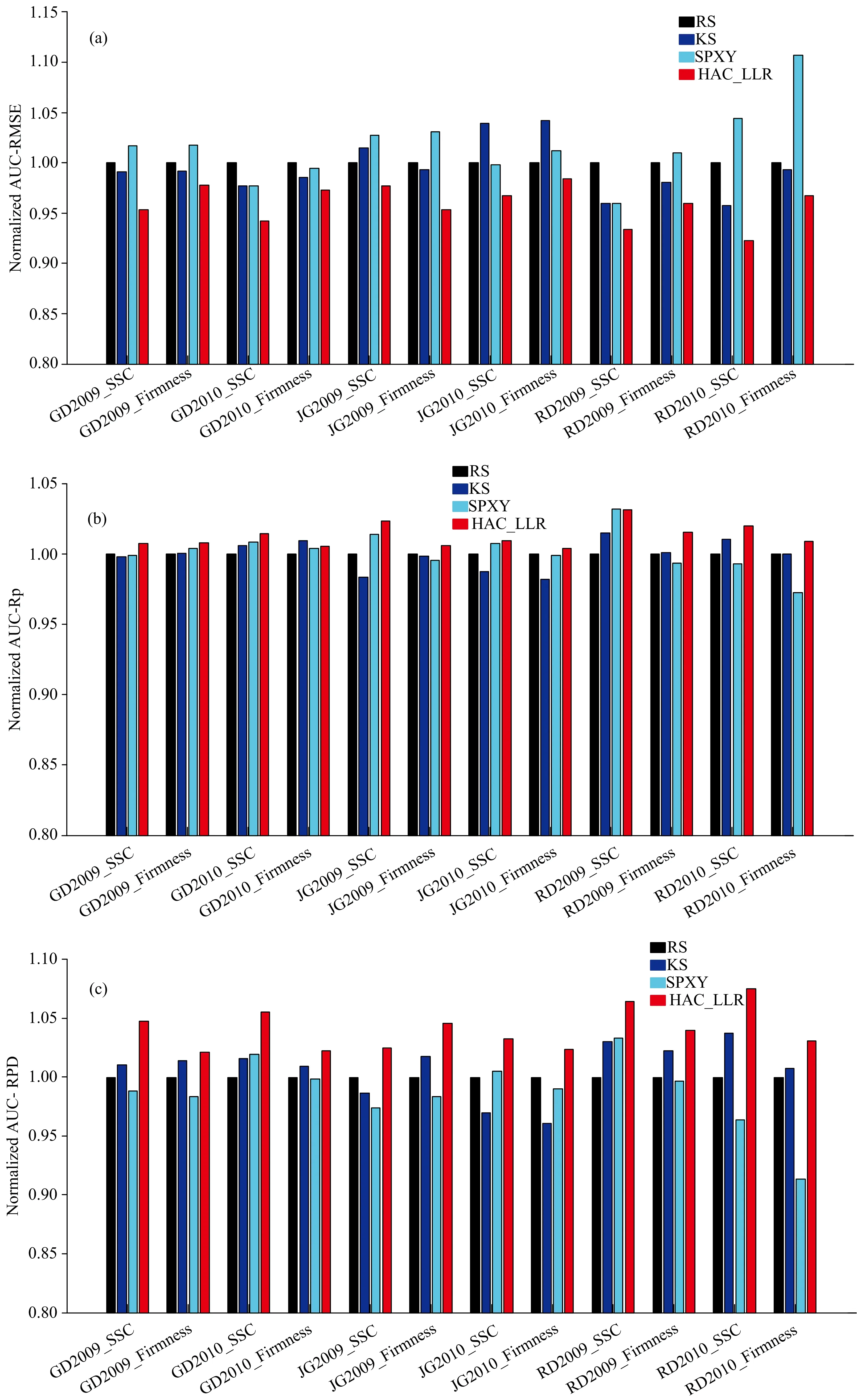
图4 不同数据集上归一化的AUC-RMSE(a),AUC-Rp(b)和AUC-RPD(c)Fig.4 Normalized AUCs of the RMSE (a),the Rp (b)and the RPD (c)on different datasets
RS算法选择的样本具有较强的随机性,相应的模型性能有很强的不确定性。KS算法考虑到了样本光谱信息的欧氏距离,由于光谱数据的高维性,欧氏距离不能很好地表征样本间的真实距离和相似性[8,12],但整体性能优于RS算法和SPXY算法。SPXY算法基于KS算法,虽然增加了对输出空间距离的考虑,即需要使用到样本真实理化标签值,属于有监督的样本选择算法,但是对输出空间的度量仅仅基于不同真实标签的差值,因此整体性能上没有表现出优势,甚至在很多数据集上不及KS算法。而本文提出的无监督主动学习方法由于综合考虑了样本的多样性和代表性,因此表现出了最佳性能。综合多个评价指标以及实验结果,验证了本文提出的无监督主动学习方法的有效性。
4 结 论
建立一个精确的且具有良好泛化能力的回归模型通常需要大量的带标记的训练集样本。然而,在样本制备过程中,采集样本的光谱数据是相对容易的,获得样本的真实标记却是费时费力且具有破坏性的。常规的光谱学实验设计中无法充分利用已知样本的信息,使得基于不同训练集的模型的性能相差较大。主动学习是一种选择最有价值的未标记样本进行标记的方法,以少量标记样本建立更好的回归模型。本文提出了一种无监督的主动学习方法,该方法融合了样本多样性和代表性两种选择标准,在连续两年采收的三个品种苹果的光谱数据集上进行了大量的实验,实验结果验证了所提出的无监督主动学习方法的有效性,为有效减少训练集样本数量、降低破坏性理化实验所带来的成本消耗、提高模型精度提供了一种解决方案。由于本文所提方法考虑的是模型构建中的训练样本选择,因此,同样适用于构建非线性模型。此外,迁移学习和主动学习都可以用于处理标记样本不足的问题,今后我们还将研究如何融合主动学习和迁移学习的思想用于减少光谱分析领域训练集样本的制备。
猜你喜欢
河北科技大学学报(社会科学版)(2022年4期)2023-01-06
北京航空航天大学学报(2022年8期)2022-08-31
空间科学学报(2021年1期)2021-05-22
闽南风(2020年6期)2020-06-23
中国现代中药(2020年2期)2020-04-29
科技创新与应用(2020年6期)2020-02-29
——勉冲·罗布斯达
文化遗产(2017年2期)2017-04-22
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
中国光学(2015年5期)2015-12-09
