
基于识别图模型的多足机器人导航数据提取信息方法 ①
2022-01-14 03:05朱茂飞张春鹏
佳木斯大学学报(自然科学版) 2022年1期
刘 罡, 朱茂飞, 张春鹏, 钟 华
(合肥学院先进制造工程学院, 安徽 合肥 230601)
0 引 言
从传感器数据中学习行为模式的问题出现在许多应用中,包括智能环境[1,6],监控[7,9],人类机器人交互[4,5],以及残疾人辅助技术。研究的热点之一是使用来自传感器的数据,来学习识别机器人在固定的时间段内从事的活动[3,4]。这项研究的目标是将机器人活动的一天分为日常活动,如“工作”、“访问”,并识别和标记重要的地方“教室”、“学生公寓”、“物品站”。
1 分层活动模型
活动模型的基本概念如图1所示。模型中的每个圆圈表示一个对象,如北斗定位系统读数、活动或重要的位置。
北斗定位系统读数是模型的输入。每个活动节点代表某个区域内的一组连续的北斗定位系统读数。标准的动态贝叶斯网络或隐马尔可夫模型只有有限的支持。
活动是为空间分段的北斗定位系统轨迹中的每个节点估计的,如图1所示。区分两大类活动,导航活动和重要活动。与导航相关的活动包括自主行走、乘坐交通工具(节省机器人自身动力需要)。重要的活动通常在机器人停留在某个位置时执行,例如送物品、休息、取物品/装物品,或者当机器人切换移动模式时,例如上交通工具/下交通工具。
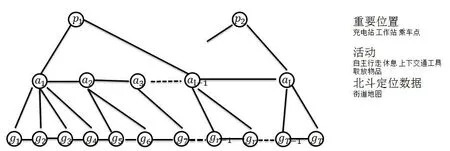
图1 基于位置的活动识别的概念层次
重要位置是在机器人的活动中起重要作用的地方。这些地方包括机器人的充电站和工作站,机器人通常使用的交通工具乘坐点等等。
2 条件随机场
研究目标是设计概率时间模型并从北斗导航读数序列中提取高级活动。一种方法是使用生成模型,如隐马尔可夫模型[7,8,2]或动态贝叶斯网络。然而,诸如条件随机场(CRF)之类的判别模型被证明在诸如自然语言处理和计算机视觉等领域优于生成技术。
使用识别图模型中的分层条件随机场。条件随机场中的节点代表一系列观测值(如北斗定位系统读数),表示为x =
(1)
其中Z(x)=Σy∏c∈Cφc(xc,yc)是归一化函数。Фc(xc,yc)由特征函数fc()的对数线性组合来描述,如公式(2):
(2)

(3)
(4)
2.1 参数学习
参数学习的目标是确定公式(4)中使用的特征函数的权重。权重的确定是为了最大化标记训练数据的条件似然p(y|x)。
2.1.1 在学习算法的推导过程中,将式(4)改写为公式(5),(6):
(5)
(6)
其中w和f分别是条件随机场中所有集团的权重和特征函数“叠加”后得到的向量。为了避免过度拟合,将目标函数梯度定义如公式(7)-(10):

(7)
(8)
(9)
(10)
2.2 最大伪似然估计
条件似然性的以下近似如公式(11):
(11)
其中MB(yi)是变量yi的马尔科夫毯,包含条件随机场图中yi的近邻(学习过程中每个节点的值是已知的)。伪似然可以重写为公式(12):
(12)
其中f(yi,MB(yi))是涉及变量yi的局部特征计数,Z(MB(yi),w) =Σyi‘exp{wT· f(yi‘,MB(yi‘))}是局部归一化函数。目标函数变成公式(13),(14):
(13)
(14)
梯度可以计算为公式(15):
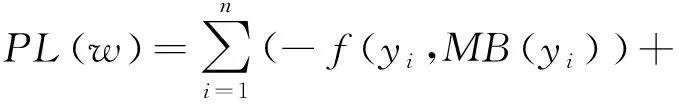
(15)
3 活动识别的条件随机场
3.1 从北斗到街景
构建了一个考虑北斗定位系统读数之间空间关系的条件随机场,结构如图2所示。观察到的实心节点对应于北斗定位系统读数,其中下标t表示时间指数,白色节点代表街景斑块st,对应于第3章中的隐藏状态y。北斗定位系统读数gt一定距离内的街景斑块上的每个st的值。图2中的线条定义了条件随机场的团结构。通过以下特征函数定义:
测量小集团(图2中的蓝色):北斗定位系统噪声和地图不确定性由小集团考虑,其特征测量北斗定位系统测量值与其关联的斑块中心之间的平方距离如公式(16):
(16)
其中gt是第t个北斗定位系统读数的位置。st表示gt附近的一个街区的中心。σ用于控制距离的比例。

图2 条件随机场将北斗定位系统测量与街景斑块相关联
一致性小集团(图2中的黄色):时间一致性由四个节点小集团保证。特征函数比较北斗定位系统读数和相关斑块之间的矢量如公式(17):
fcons(gt,gt+1,st,st+1)=
(17)
st和st+1是连续两次关联的街景斑块的中心。
平滑小集团(图2中的灰色):使用二进制特征来测试连续的斑块是在同一条街景上、相邻的街景上还是在同一个方向上。以下二元特征检查街景和方向是否相同如公式(18):
fsmooth(st,st+1)=δ(st.street,st+1.street)·
δ(st.direction,st+1.direction)
(18)
其中,δ(u,v)是指示函数,如果u = v,则等于1,否则等于0。
3.2 推断重要地点的活动和类型
一旦北斗定位系统轨迹被分割,系统就会生成一个新的条件随机场,其中包含从北斗定位系统轨迹中提取的每个片段的隐藏活动节点。该条件随机场由图3所示的两个较低级别组成。

图3 标识活动和场所的条件随机场
在一个地方发生的活动强烈地表明了这个地方的类型。例如,在工作站,机器人主要是工作,而在充电站,机器人主要是充电。图3中的节点p1,a1和aN-2形成了这样一个团。该模型计算每个地方发生的不同活动。在实验中,将计数离散为四类:计数= 0,计数= 1,2 ≤计数≤ 3,计数≥ 4。对于地点类型、活动类型和频率类别的每个组合,都有一个指示特征。
3.3 位置检测和标记算法
表1总结了构建的条件随机场的算法。该算法将北斗定位系统轨迹作为输入。

表1 检测重要地点并推断活动和地点类型的算法
4 实验结果
从三个不同的机器人那里收集了北斗定位系统数据,每个机器人大约七d的数据。每个机器人的数据由大约800个北斗定位系统测量组成,导致大约200个片段。手动标记所有活动和重要位置。使用遗漏交叉验证进行评估,使用最大伪似然进行学习,这需要(在3.0 GHz的PC上)大约5min来收敛到训练数据。图4(a)是将北斗定位系统轨迹捕捉到街道地图的方法所实现的质量。图4(b)显示了两种方法实现的假阳性和假阴性率。模型相比阈值法表现得更好:它只产生4个假阳性和3个假阴性。

图4 (a)街道地图(线)上的北斗定位轨迹(灰色圆圈)和相关的网格单元(黑色圆圈);(b)提取的重要位置的准确性。
表2显示了重要活动的活动估计结果。如果在没有发生重大活动时检测到重大活动,则该实例被视为假阳性(FP),如果发生重大活动但被标记为非重大活动(如行走),则该实例被视为假阴性(FN)。

表2 交叉验证数据的活动混淆矩阵
表3提供了不同评估的活动推断准确性。只显示重要的活动,该系统实现了80%以上的导航活动的准确性,如自主行走,或交通工具。前两行提供了表2所示混淆矩阵的准确度值。方法在估计重要活动时达到了85%以上的准确率,无论有没有街道地图。表4所示的混淆矩阵总结了在检测和标记重要位置方面所取得的结果。该方法在标记用于测试的机器人的充电站和工作地点时没有错误。位置检测和标记的总体准确率为95%。无论是否使用街道地图,地点检测结果都是相同的。

表3 活动评估

表4 地点混淆矩阵
5 结 语
与现有技术相比,使用一致的框架来进行低级推理和提取机器人的重要位置。通过迭代构建一个分层的条件随机场来实现的,其中上层是基于下层的映射推理生成的。在模型中使用伪似然的判别学习和使用循环信念传播的推理可以非常有效地执行。基于北斗定位系统数据的实验表明不仅能够了解机器人的重要位置,它还可以推断出低级别的活动,如走路、工作或上车。未来将在模型中添加更多类型的传感器,包括由可穿戴多传感器收集的数据,如3轴加速度、音频信号。使用这些传感器提供的附加信息,系统将能够执行极其细粒度的活动识别。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
小学生学习指导·低年级(2021年6期)2021-09-10
学生天地(2020年1期)2020-08-25
中学生数理化(高中版.高考理化)(2020年2期)2020-04-21
小学生(看图说画)(2019年12期)2019-12-21
当代陕西(2019年18期)2019-10-17
幼儿智力世界(2017年5期)2017-07-12
儿童故事画报(2016年5期)2017-02-07
太空探索(2016年12期)2016-07-18
太空探索(2016年3期)2016-07-12
