
基于RISC-V向量指令的稀疏矩阵向量乘法实现与优化*
2022-01-24 02:20赵银亮
计算机工程与科学 2022年1期
顾 越,赵银亮
(西安交通大学计算机学院,陕西 西安 710049)
1 引言
随着云计算与物联网浪潮的兴起,人们对可定制、低功耗和高性价比CPU的需求日渐增加。最初由加州大学伯克利分校研究人员开发的开源指令集架构RISC-V,凭借其可伸缩、可扩展和模块化的特性[1 - 3],在相关领域的影响力逐渐扩大。该指令集由整数基本指令和多个拓展指令集组成[4],拓展指令集中包括了用于向量处理的V指令集——RV32V。RV32V目前仍在GitHub上开发[5],最新稳定版本为v0.9。与传统SIMD向量架构不同的地方在于,RISC-V向量指令集具有向量寄存器可配置的特性,解决了向量计算中向量长度不可知的问题[6,7]。
向量计算中的稀疏矩阵与向量乘法SpMV(Sparse Matrix-Vector multiplication),常用于科学计算和工程应用问题中的大规模稀疏线性系统求解[8],其实现与优化一直是高性能计算领域的研究重点。因稀疏矩阵具有非零元素占比少的特性,研究人员常采用压缩存储格式来提高存储效率,又因非零元素分布和硬件设备的多样性,其存储格式也具有多样性[9]。如COO(COOrdinate list format)[10]格式以行坐标、列坐标和值组成的三元组对稀疏矩阵中非零元素进行存储,简单直观灵活,但不利于计算和向量化。另一种常用的存储格式CSR(Compress Sparse Row format)格式,将所有非零元素的值和列索引按行顺序存储在2个单独的数组中,第3个数组保留指向这些数组中每一行的起始位置的指针。它的主要优点是对任何类型的矩阵元素分布都有很好的压缩比,其主要缺点为数据局部性差,存在写冲突、负载不均衡等问题[11]。ELLPACK(format used by ELLPACK system)格式可在GPU和矢量体系结构中高效运算,但需要付出额外的存储代价[12]。它以m*k的矩阵存储数据,其中k的大小取决于每行非零元素个数中的最大值。面对不规则矩阵时,其存储和计算效率都会退化。HYB(HYBrid format)格式[13]结合了ELLPACK格式和COO格式,对每行中超过阈值的非零元素使用COO格式存储,以减少ELLPACK格式中零元素的填充,兼顾计算效率的同时节约了存储空间。
SELLPACK(Sliced ELLPACK format)[14]格式是基于ELLPACK格式的改进。通过将矩阵行向量按照其非零元素数量排序,以固定行数对矩阵分片,对得到的矩阵块分别使用ELLPACK格式存储,提高了存储不规则矩阵的效率和吞吐量。更进一步地,SELL-C-σ(Sliced ELLPACK format with parameterC,σ)格式[15]通过限制排序窗口避免了重新排列整个矩阵的高昂代价,同时充分利用了矩阵相邻行与被乘向量x相乘时,对向量x访问的局部性。针对Intel 公司设计的异构众核处理器Xeon Phi,Liu等人[16]提出了ESB(ELLPACK Sparse Block)格式,该格式引入了位数组编码和列分块技术,以降低带宽需求,进一步提高了向量访问的局部性。而Liu 等人[17]提出的CSR5存储格式,易于从传统的CSR格式转换得到,对输入稀疏矩阵的非零元素分布不敏感。通过采用一种改进的分段求和算法实现了基于CSR5的SpMV算法,在跨平台测试中得到了较高的吞吐量。
RISC-V向量指令集作为向量指令家族中的新晋成员,方兴未艾。相关研究尚处于起步阶段,基于RISC-V向量指令实现和优化SpMV算法的工作还未有报道,开展此项工作具有重要意义。
本文基于RISC-V向量指令集RV32V,利用其向量寄存器可配置及寻址特性,实现了基于CSR、ELLPACK和HYB压缩格式的SpMV算法,比较了在稀疏矩阵非零元素不同分布情况下各个算法的计算与存储效率的变化。同时,针对极度稀疏矩阵每行非零元素数量波动较大的情况,通过压缩非零元素密度低的行向量的存储、调整HYB分割阈值等手段,改进了HYB存储格式并实现了对应的SpMV算法,显著改善了计算效率和存储效率。
2 稀疏矩阵存储格式
2.1 CSR格式
CSR格式是一种比较标准的稀疏矩阵存储格式,使用3类数据来表示:数值val、列号col和行偏移row。其中,数值val为非零元素的值,列号col为非零元素的列号,行偏移row表示某行的第1个非零元素在数值val中的起始偏移位置。对于如式(1)所示的矩阵A,采用CSR格式存储的结果如式(2)所示:

(1)
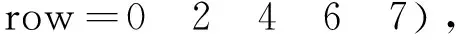

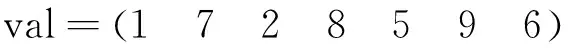
(2)
CSR格式的主要优点是对规则与不规则稀疏矩阵的存储都具有稳定良好的压缩比,主要缺点是基于此实现的SpMV算法存在数据访问局部性差、写冲突和负载不均衡等问题。
2.2 ELLPACK格式
ELLPACK格式是一种易于向量化的稀疏矩阵存储格式,使用2个和原始矩阵行数相同的矩阵来表示:第1个矩阵val存的是数值,第2个矩阵col存的是列号,行号用自身所在的行来表示。对于行中存在的零元素,可以在val矩阵中填充零元素、在col矩阵中填充11来表示。对于如式(1)所示的矩阵A,采用ELLPACK格式存储的结果如式(3)所示:
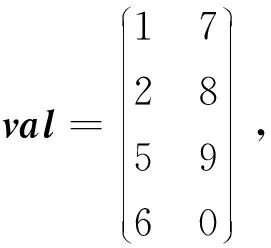
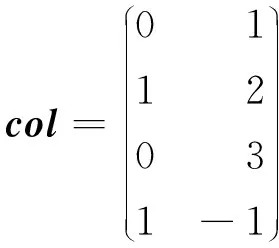
(3)
当矩阵中某行的非零元素个数很多时,ELLPACK格式的存储效率将急剧下降。
2.3 HYB格式
HYB格式对ELLPACK格式的缺点进行改进,采用COO格式与ELLPACK格式混合的方式对稀疏矩阵压缩存储。对每行元素个数小于阈值的部分采用ELLPACK格式,超过阈值的部分采用COO格式。其中,ELLPACK格式如上所述,需要数值矩阵val和列号矩阵col存储,而COO格式使用coo_r、coo_c和coo_v分别存储元素的行号、列号和值。对于如式(4)所示的矩阵B,采用HYB格式存储的结果如式(5)所示:
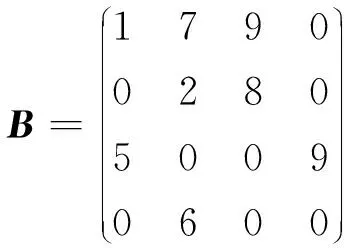
(4)
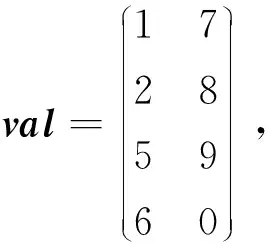

coo_r=(0),
coo_c=(2),
coo_v=(9)
(5)
矩阵B中第1行第3列的元素值为9,行号为0,列号为2,分别存储于coo_v、coo_r和coo_c中。因此,当每行非零元素数量相差较大时,采用HYB格式可节约存储空间,提高存储效率。
3 SpMV描述、实现与优化
3.1 SpMV描述
SpMV可用式(6)描述:
y=A*x
(6)
其中,A为m*n维的稀疏矩阵,x为n* 1维的乘数向量,y为m* 1维的结果向量。
为了更好地描述稀疏矩阵,假设矩阵中每行元素数量呈正态分布,正态分布标准差为σ,均值为μ。
为了表征稀疏矩阵中非零元素的分布特征,使用空行率、稠密度和波动度3个指标,其定义如式(7)~式(9)所示:
空行率=矩阵全零行数/矩阵总行数
(7)
稠密度=非零元素数/矩阵元素总数
(8)
波动度=标准差σ/均值μ
(9)
为了表征基于某特定压缩存储格式的SpMV算法性能,使用压缩率和加速比2个指标,其定义如式(10)和式(11)所示:
压缩率=压缩后数据大小/原始矩阵大小
(10)
加速比=基于该压缩格式的SpMV执行时间/非压缩的SpMV执行时间
(11)
压缩率与压缩效率成反比,压缩率越小,说明该压缩存储格式的压缩效率越高。
其中,非压缩的SpMV伪代码如下所示:
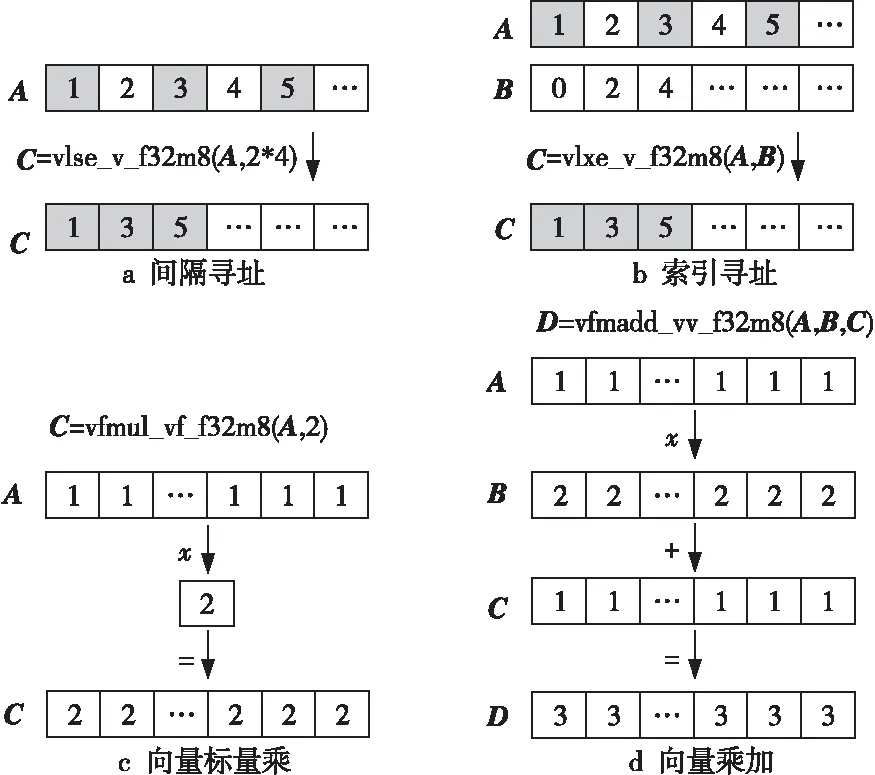
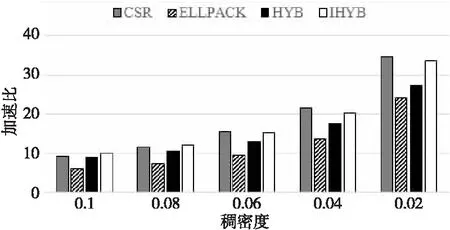
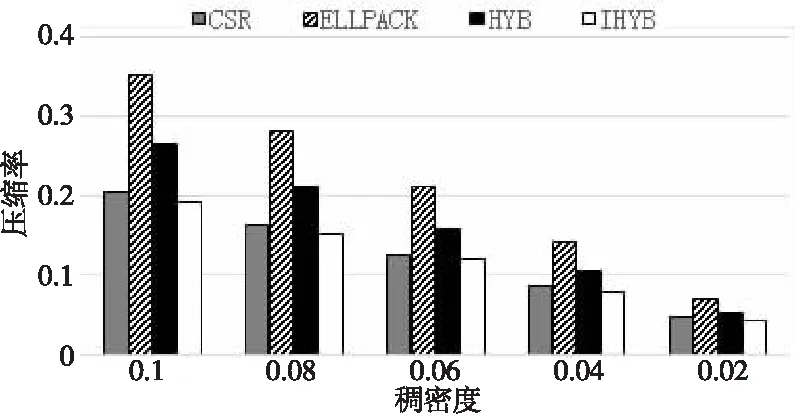
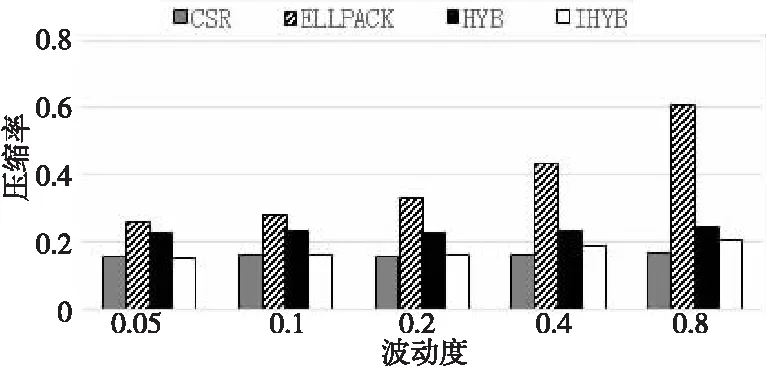
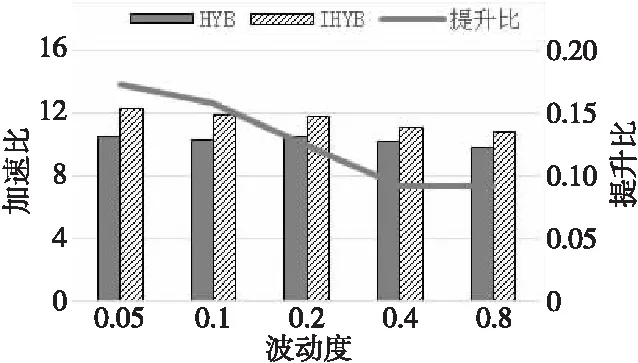
for(inti= 0;i for(intj=0;j y[i]+=A[i*m+j] *x[j]; } } 加速比与计算效率成正比,加速比越大,说明所执行的算法计算效率越高。 RISC-V指令集采用模块化的方式组织,使用一个英文字母表示一个模块。其中向量指令部分使用“V”表示,32位的RISC-V向量模块简记为RV32V。对于32位的RISC-V向量架构,在执行向量乘操作的for循环时,可以用设置向量寄存器组的操作作为循环判断条件,每次循环后将当前剩余向量长度减去设置结果,发挥向量寄存器可配置的特性,避免了传统SIMD指令面对计算向量长度非架构所支持的向量数的整数倍时,需要对剩余尾向量进行额外的循环操作的缺点。例如,对于传统的拥有固定128位向量寄存器的处理器而言,在处理包含41个32位整型元素的向量时,每次循环能够处理的元素个数为4。10次循环之后,需要额外循环处理剩余的1个元素。而在RV32V体系结构中,向量寄存器长度可通过类似vsetvl_e32m8的接口灵活配置,开始待处理向量较长时,使用大的向量寄存器位数,最后向量长度不足时,将向量寄存器长度设置为合适值,充分简化了代码编写,提高了程序效率。 在实现矩阵运算时,常用的向量操作包括间隔向量寻址、索引向量寻址、向量乘加和向量标量乘等,如图1所示。 Figure 1 Vector operations of RV32V图1 RV32V向量操作示意图 基于RV32V,充分利用RISC-V向量寄存器可配置和寻址的特点,本文分别实现CSR、ELLPACK和HYB存储格式的SpMV算法。向量化SpMV算法实现总体可分为索引计算、乘数加载、向量相乘、结果回写和指针偏移这几个步骤,下面结合伪代码分别描述各压缩格式的RISC-V向量化SpMV实现。 基于CSR格式的RISC-V向量化SpMV伪代码如下所示: 输入行偏移指针row_p;row_p数组长度m;坐标指针col_idx;值指针val;向量指针x。 输出结果向量指针y。 1:vfloat32m8_tvec_a,vec_b,vec_c; 2:vuint32m8_tindex; 3:float *a=val,*b=x,*c=y; 4:whilevl=vsetvl_e32m8(col)do 5:vec_a=*(vfloat32m8_t *)a; 6:index=*(vuint32m8_t *)col_idx; 7:index=vfmul_vf_f32m8(index,4); 8:vec_b=vlxe_v_f32m8(b,index); 9:vec_c=*(vfloat32m8_t *)c; 10:vec_c=vfmadd_vv_f32m8(vec_a,vec_b,vec_c) 11: *(vfloat32m8_t *) c=vec_c; 12:c+=vl;a+=vl;b+=vl; 13:col_idx+=vl;col-=vl; 14:endwhile 15:returny. 首先对列号col_idx数组进行顺序寻址,计算出索引,如第6、7行所示;然后根据计算出的索引,在乘数向量x中进行索引寻址,加载第1个向量乘数,并对数值val数组顺序寻址,加载第2个向量乘数,如第8、9行所示;最后2个向量乘数中各元素依次相乘,结果回写暂存,如第10、11行所示。进行指针偏移准备下一轮计算,如第12、13行所示。依次循环往复直到计算完成。 基于ELLPACK格式的RISC-V向量化SpMV伪代码如下所示: 输入坐标指针col_idx;值指针val;值矩阵长度m;值矩阵宽度col;向量指针x。 输出结果向量指针y。 1:vfloat32m8_tvec_a,vec_b,vec_c; 2:vuint32m8_tindex; 3:float *a=val,*b=x,*c=y; 4:fori=0 tocoldo 5:num=m;a=val+i*col; 6:b=x;c=y+i*col; 7:col_idx=col_idx+i*col; 8:whilevl=vsetvl_e32m8(num)do 9:vec_a=*(vfloat32m8_t *)a; 10:index=vlse_v_f32m8(col_idx,col*4); 11:index=vfmul_vf_f32m8(index,4); 12:vec_b=vlxe_v_f32m8(b,index); 13:vec_c=*(vfloat32m8_t *)c; 14:vec_c=vfmadd_vv_f32m8(vec_a,vec_b,vec_c); 15: *(vfloat32m8_t *)c=vec_c; 16:c+=vl;a+=vl;b+=vl; 17:col_idx+=vl;num-=vl; 18:endwhile 19:endfor 20:returny. 向量化计算过程中,首先对列号col数组间隔寻址,间隔为每行字节数,按列顺序获取向量,如第10行。对得到的向量值做向量标量乘法,转化为字节数,计算出索引,如第11行;然后根据计算出的索引,在乘数向量x中进行索引寻址,加载第1个向量乘数,如第12行;接着对数值val数组顺序寻址,加载第2个向量乘数,如第13行;最后向量元素依次相乘,如第14行,结果回写暂存,如第15行。指针偏移准备下一轮计算,如第16、17行,依次循环往复直到计算完成。 对基于HYB格式的向量化SpMV可以分为ELLPACK和COO 2部分,其中ELLPACK部分与上述基于ELLPACK格式的RISC-V向量化过程相同,COO部分的向量化过程与CSR格式的类似。 基于HYB格式的RISC-V向量化SpMV伪代码(COO部分)如下所示: 输入行坐标指针col_r;列坐标指针coo_c;值指针val;长度num;向量指针x。 输出结果向量指针y。 1:whilevl=vsetvl_e32m8(num)do 2:vec_a=*(vfloat32m8_t *)a; 3:index=*(vuint32m8_t *)coo_c; 4:index=vfmul_vf_f32m8(index,4); 5:vec_b=vlxe_v_f32m8(b,index); 6:vec_c=*(vfloat32m8_t *)c; 7:vec_c=vfmadd_vv_f32m8(vec_a,vec_b,vec_c); 8: *(vfloat32m8_t *) c=vec_c; 9:c+=vl;a+=vl;b+=vl; 10:col_index+=vl;num-=vl; 11:endwhile 12:returny. 首先对列号col数组顺序寻址,如第3行,得到的向量值做向量标量乘法,如第4行,计算出索引;然后在乘数向量x中进行索引寻址,加载第1个向量乘数,如第5行;接着对数值val数组顺序寻址,加载第2个向量乘数,如第6行;最后向量元素依次相乘,如第7行,结果回写暂存,如第8行。指针偏移准备下一轮计算,如第9、10行。依次循环往复直到计算完成。 HYB格式使用ELLPACK格式和COO格式混合的方式,以更紧凑的方式存储拥有非零元素密度大的行的稀疏矩阵,提升了存储效率。图2给出了矩阵C的HYB格式存储结果。将第1行和第2行的元素5存储为COO格式,使所需的存储空间从60(6*5*2)个整型大小降低到54(6*4*2+6)个整型大小。 Figure 2 Storage diagram based on HYB format图2 基于HYB格式的存储示意图 但是,行之间非零元素相差很大的情况不仅表现在拥有非零元素密度大的行,同时也体现在拥有非零元素密度小的行。基于这一点,本文提出改进的HYB格式IHYB(Improved HYB format)。IHYB格式对非零元素密度低于IHYB分割阈值的行也使用COO格式存储。此时ELLPACK格式所存储元素的行号不能用自身所在的行来表示,于是引入bitarray数组记录ELLPACK格式中每行元素在原始矩阵中的行号。对于HYB格式,在假设完全填充的ELLPACK格式计算速度比COO格式快3倍的情况下,通过经验法则选择数值K作为ELLPACK和COO之间的分割值,使得矩阵中具有K个以上非零元素数的行数不少于M/3,其中M是矩阵总行数[13]。而对于IHYB格式,参照类似规则,阈值的确定使用迭代算法1。 算法1确定IHYB分割阈值的算法 输入:稀疏矩阵每行非零元素数。 输出:IHYB分割阈值。 Step1对稀疏矩阵每行元素数中的非零值从小到大排序,找到2/3分位点作为HYB阈值。 Step2将HYB阈值/4作为IHYB分割阈值。 Step3去除非零元素数低于IHYB分割阈值的行,按照Step 1更新HYB阈值。 Step4将更新后的HYB阈值/4作为最终的IHYB分割阈值。 如HYB使用的经验参数,IHYB阈值中使用的参数2/3,1/4等,也是通过经验法则确定。阈值的两步迭代求解操作开销包括对稀疏矩阵的2次遍历(统计每行非零元素数时)和每行非零元素数大小的排序。矩阵遍历可以在压缩存储格式的转换过程中完成,并不增加额外开销。假设稀疏矩阵有m行k列,排序的复杂度为m*logm,一般而言不会超过矩阵元素数m*k,可以忽略。因此,通常来说,阈值求解过程的开销并不会影响算法性能。 图3给出了图2中矩阵C的IHYB格式存储结果。第6行的元素1也存储为COO格式,同时bitarray数组指示了矩阵value中每行元素的行号,使所需的存储空间从HYB的54(6*4*2+6)个整型大小进一步降低到45(4*4*2+4+9)个整型大小。 Figure 3 Storage diagram based on IHYB format图3 基于IHYB格式的存储示意图 本文实验使用Spike模拟器[18]环境,其中DCache设置大小为32 KB,ICache大小为32 KB,L2 Cache大小为128 KB,CPU主频1 GHz,内存使用4 GB。限定矩阵规模为4 KB,矩阵每行非零元素个数满足正态分布,以空行率、稠密度和波动度控制稀疏矩阵非零元素分布特性,以压缩率和加速比衡量算法的空间效率和时间效率。 固定空行率为0.3,波动度为0,改变稠密度观察稀疏矩阵稠密度对SpMV算法性能的影响。随着稠密度增加,非零元素数量也增加,各算法所需存储空间增加,计算时间增多,因此,加速比减小,压缩率升高。整体上由加速比衡量的计算效率由高到低为CSR、IHYB、HYB和ELLPACK,如图4所示。由压缩率衡量的存储效率由高到低为IHYB、CSR、HYB和ELLPACK,如图5所示。由图4可知,当稠密度超过0.08时,CSR的计算效率降低,IHYB的加速比反超CSR。原因在于CSR的段累加求和部分难以被向量化,当非零元素数量较多时,计算效率受到影响开始下降。得益于较高的压缩效率和较好的向量化程度,IHYB的加速比表现优异。而ELLPACK中存储了大量零元素,导致整体计算效率较低。 Figure 4 Effect of density on speedup图4 稠密度对加速比的影响 Figure 5 Effect of density on compressibility图5 稠密度对压缩率的影响 固定空行率为0.3,稠密度为0.08,改变波动度观察稀疏矩阵波动度对SpMV算法性能的影响。图6和图7别显示了波动度对加速比和压缩率的影响。随着波动度增大,IHYB、HYB和ELLPACK的压缩率不同程度增大,加速比不同程度减小,而CSR的压缩率和加速比基本保持稳定。由图6可知,随着波动度增大,ELLPACK的加速比迅速降低。原因在于波动度的增大导致ELLPACK格式压缩率迅速升高,存储效率降低,这点由图7也可以看出。存储的无效零元素大量增加,进一步导致ELLPACK格式的计算效率下降,加速比走低。与ELLPACK格式不同的是,其他3种格式压缩率较为稳定。由图7可知,CSR的压缩率最为稳定,基本不受波动度影响,HYB和IHYB的压缩率随着波动度增大缓慢增加,并且IHYB在压缩效果上好于HYB格式。波动度低于0.2时,IHYB的存储效率表现甚至好于CSR。由图6可知,很大程度得益于此,在波动度低于0.2时,IHYB的计算效率也高于CSR。 Figure 6 Effect of volatility on speedup图6 波动度对加速比的影响 Figure 7 Effect of volatility on compressibility图7 波动度对压缩率的影响 图8和图9分别进行了HYB格式和基于HYB格式改进的IHYB在不同波动度下,加速比和压缩率的对比。平均而言,相比HYB格式,IHYB格式在加速比上提升了13%,压缩率上降低了6%。压缩率的降低趋势和加速比的提升趋势一致,从而体现了压缩效率的提高导致计算效率随之提高的规律。 Figure 8 Comparison of speedup between HYB and IHYB图8 HYB和IHYB的加速比对比 Figure 9 Comparison of compressibility between HYB and IHYB图9 HYB和IHYB的压缩率对比 SpMV算法在科学计算中占有重要地位,实现并优化基于RISC-V向量指令的SpMV算法也具有重要价值。本文首次利用RISC-V向量寄存器可配置性和向量寻址模式,结合CSR、ELLPACK和HYB存储格式的特点,实现了对应的SpMV算法。在仿真环境下比较了各SpMV算法面对不同非零元素分布的稀疏矩阵,表现出的计算效率和存储效率差异。同时,针对HYB格式,提出了更为紧凑、稳定的改进格式IHYB。实验显示,在非零元素分布变化时,基于IHYB格式实现的SpMV表现出更为优异的存储效率和计算效率。但是,目前实现的算法都是基于单个RISC-V核心的。面对更为复杂的RISC-V多核处理器或异构计算环境,如何充分发掘算法中的并行性,提高并行度,将是一个更为复杂深刻的挑战和命题。3.2 RISC-V向量指令集RV32V
3.3 基于RV32V与传统压缩格式的SpMV实现
3.4 基于 HYB格式的改进


4 算法测试与分析
4.1 稠密度的影响
4.2 波动度的影响


5 结束语
猜你喜欢
建材发展导向(2021年19期)2021-12-06临床骨科杂志(2020年1期)2020-12-12软件学报(2020年6期)2020-09-23科学与财富(2018年26期)2018-10-24科技信息·中旬刊(2018年4期)2018-10-21航空维修与工程(2018年8期)2018-09-10广东第二课堂·小学(2017年9期)2017-09-28科教导刊·电子版(2016年23期)2016-10-31探测与控制学报(2015年4期)2015-12-15科技视界(2014年25期)2014-04-27
