
数字经济助力长三角区域一体化发展
2022-02-01 02:25张平原刘晴晴
统计科学与实践 2022年11期
□张平原 高 策 刘晴晴
长江三角洲区域(以下简称长三角区域)包括上海市、江苏省、浙江省和安徽省,是我国经济发展程度最高、创新能力最强的区域之一。目前,长三角区域由于内部协调性不足、机制体制障碍等问题,与世界先进区域相比,创新性和联动性仍是短板。数字经济发展速度快、辐射范围广、影响程度深,正成为推动生产、生活和社会治理变革,重组世界资源要素、重塑世界产业结构、改变世界竞争格局的主要力量之一。因此,分析数字经济和长三角区域一体化发展的关系,找出怎样发展数字经济才能更好助力长三角区域一体化发展,对加快实现长三角区域一体化目标具有重要的现实意义。
|研究目标
1.构建数字经济和长三角区域一体化发展的指标体系。本文基于以往研究成果,首先建立数字经济和长三角区域一体化指标体系,以求客观反映数字经济和长三角区域一体化发展情况。其中,数字经济指标体系包括数字化产业、数字化社会和数字化服务等3 个一级指标,16 个二级指标;长三角区域一体化指标体系包括经济发展测度、科技创新测度、交流服务测度和生态保护测度等4 个一级指标,22 个二级指标。
2.本文着重分析数字经济对长三角区域一体化发展的影响,探索长三角区域一体化发展影响因素,根据研究结果为数字经济推动长三角区域一体化正向作用最大化提供理论向导,以实现高效率推动长三角区域一体化发展。
|指标构建与测算
面板熵值法是对截面熵值法的改进。设共有r 年,n个地区(省级),m个指标;xijk表示第i年,第j 地区,第k 个指标的值。步骤如下:
原始数据归一化。
正向指标:

逆向指标:

逆向指标是正向指标的相反数。
xmax,k表示第k 个指标在n 个地区、r 年中的最大值,xmin,k表示第k个指标在n 个地区、r 年中的最小值。标准化处理后x′ijk取值范围为[0,1],其含义为xijk在n 个地区、r年中的相对大小。由于标准化后会出现0 值,因此对标准化后的数据平移:

计算第k 项指标权重:

计算第k 项指标的熵值:

计算第k 项指标的差异系数:

对差异系数归一化,计算第k项的权重:

计算最终的统计测度:

(一)数字经济指标体系的构建
目前国际上暂时没有一套确定的统一标准,大多都以定性描述为常用方法,本文参考了王庆喜、武谨、胡安的相关结果,主要从数字化产业、数字化社会、数字化服务三个方面构建数字经济指标体系(表1)。数字化产业从邮政电信两个方面反映数字经济产业发展;数字化社会从数字经济带动社会就业方面进行描述;数字化服务根据互联网通信相关服务反映数字化经济的推广覆盖程度。

表1 数字经济指标体系
本研究运用了面板熵值法,利用stata.15 工具,首先计算每项指标的权重,然后根据每项指标权重计算得出最终的数字化统计测度。
将有关数字经济测度的指标数据导入stata 程序,通过br 指令查看数据,id 代表地区分类,其中1表示长三角区域分类标签,2 代表上海市分类标签,3 代表江苏省分类标签,4 代表浙江省分类标签,5代表安徽省分类标签;area 代表地区指标;year代表年份;v1 代 表GDP(亿元);v2 代表人数(万人);v3 代表邮政业务量(万件);v4 代表电信业务量(万元);v5 代表邮政业务量占GDP 比重;v6 代表电信业务量占GDP 比重;v7 代表城镇就业人员(万人);v8 代表邮政从业人员(万人);v9 代表邮政从业人员占就业人员比重;v10代表科技机构数(个);v11 代表科技活动人口(人);v12 代表每千人移动电话用户数(部);v13 代表互联网用户数(万户);v14 代表每千人互联网用户数(户);v15 代表互联网宽带数(万户);v16 代表每千人互联网宽带数(户)。
由图1 分析可知,obs 代表观测值,本研究一共有10 个观测值,vars 代表变量,本研究一共有19个变量。此外,图1 的下半部分表格展示了数据名称和数据对应的存储类型。由图1 分析可知,id 变量为类别类型,area 变量为字符串类型,year 变量为数值类型,v1-v16变量为双精度类型。

图1 数字经济测度数据变量标签(stata 程序)
stata 程序中的sum 命令语句,展示了变量名称和变量的观测值,由图2 可知一共19 个变量,每个变量有10 个观测值,Mean 代表观测值的平均数,Std.Dev.代表观测值的标准差,Min 代表观测值中的最小值,Max 代表观测值中的最大值。
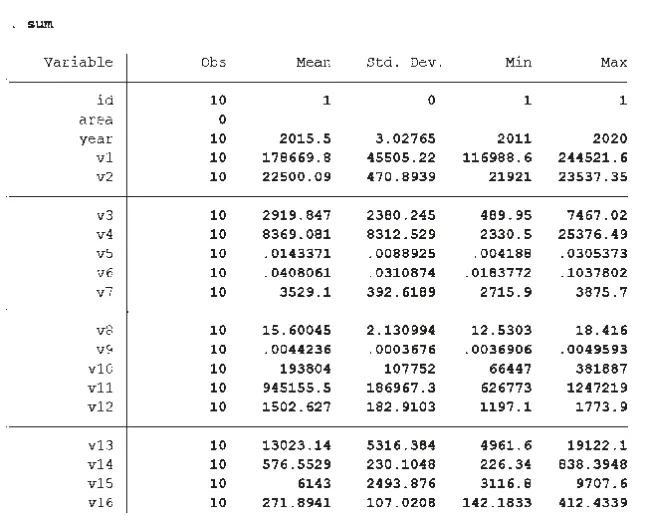
图2 数字经济测度数据描述性统计(stata 程序)
根据熵值法,通过stata 程序分别求出v1-v16 指标的近似权重;可知,v1 的权重w1 为0.0519;v2的权重w2 为0.0597;v3 的权重w3为0.0814;v4 的权重w4 为0.1350;v5 的权重w5 为0.0685;v6 的权重w6 为0.1368;v7的权重w7 为0.0296;v8 的权重w8 为0.0531;v9 的权重w9 为0.0287;v10 的权重w10 为0.0654;v11 的权重w11为 0.0355;v12的权重w12 为0.0352;v13 的权重w13 为0.0438;v14的权重w14 为0.0437;v15 的权 重w15 为0.0653;v16的权重w16 为0.0664。于是,得到长三角区域数字经济测度最终指标,同理,通过stata 程序,通过熵值法计算出上海市、江苏省、浙江省、安徽省有关数字经济测度评价的指标权重,并结合权重计算出最终数字经济测度(表2)。

表2 2011—2020 年长三角区域及分地区数字经济测度
(二)长三角区域一体化指标体系的构建
本文参考引用了 《长江经济带城市协同发展能力指数研究报告》中的指标体系,利用熵值法建立2011—2020 年长三角一体化指标体系测度(表3)。

表3 长三角一体化测度指标体系
计算长三角区域一体化测度。根据二级指标通过熵值法计算权重,来计算对应一级指标的测度。将有关长三角区域一体化的二级指标数据导入stata 程序,通过br 指令查看数据,id 代表地区分类;area 代表地区指标;year 代表年份;t1 代表GDP (亿元);t2 代表人数(万人);t3 代表人均GDP(万元);t4 代表社会消费品零售额(亿元);t5 代表工业增加值(亿元);t6 代表服务 业增 加值(亿元);t7 代表一般公共预算收入(亿元);t8 代表财政科技支出额(亿元);t9 代表合作发明专利申请数量(项);t10 代表从事科技活动人员数(人);t11 代表有研发活动的规上工业企业数(个);t12 代表科技研发(R&D)投入强度(万元);t13 代表国家高速公路里程(万公里);t14 代表互联网用户数(万人);t15 代表铁路客运(万人);t16 代表铁路货运(万吨);t17 代表客运量(万人);t18 代表发电量(亿千瓦小时);t19 代表单位GDP 耗电量;t20 代表工业用电量(亿千瓦小时);t21 代表绿化覆盖面积(公顷);t22 代表公园个数(个)。t18、t19、t20 为负向指标,其余指标皆为正向指标。
通过熵值法求出t1-t22 指标占区域一体化指标测度的近似权重,结合指标数据和近似权重,可以求出长三角区域一体化指标测度结果。同理,采用同样的方法,得到2011—2020 年上海市、江苏省、浙江省、安徽省区域一体化指标的测度 (表4)。

表4 2011—2020 年长三角区域及分地区一体化测度
|模型建立与实证分析
(一)控制变量选择
对于控制变量,本研究选用了GDP(亿元)、人口(万人)、财政支出(亿元)、中小学数量(所)、医疗卫生机构数(所)、工业污染治理(亿元)6 个指标作为该模型的控制变量。
对长三角区域一体化的影响因素除了本文所重点考察的数字经济指标外,GDP(亿元)、人口(万人)、财政支出(亿元)、中小学数量(所)、医疗卫生机构数(所)、工业污染治理(亿元)对长三角区域一体化程度会存在一些影响。
(二)控制变量处理
控制变量数值过大,直接计算十分不方便,故本研究通过对数处理法来处理控制变量。
(三)建模过程
通过xtset 命令将数据设置为面板数据,id 代表地区编号,表示其为区域变量,year 代表年份,将其设置为数值,表示为时间变量,显示面板数据的结构,该数据为强平衡面板数据。
由图3 可以看出,面板数据一共有5 个不同的id 编号,即有5 组不同类别,时间从2011-2020 年,共10 年。

图3 面板数据描述(stata 程序)
图4 显示了面板数据的组内、组间与整体统计指标,其中overall表示整体统计指标的平均数、标准差、最小值、最大值;between 表示组间统计指标的平均数、标准差、最小值;within 表示组内统计指标的平均数、标准差、最小值。

图4 面板数据组内、组间与整体统计指标(stata 程序)
接下来,我们对面板数据进行回归,回归结果如图5。
由图5 可以知道,Number of obs 是样本容量,一共有50 个观测值,Number of groups 是组别容量,一共有5 组数据,分组变量是id。F 是模型的F 检验值,用来计算P>F,模型的P>F 值=0,表示模型设定没有问题。模型的拟合优度即R2值越大,表示模型和实际值的拟合度就越高,模型越好。由图8 可知,组内R2为0.9528,组间R2为0.9178,整体R2为0.9520,表示回归较为显著,模型拟合效果较好。且P 值=0,进一步肯定了模型的回归效果。假如设置95%置信水平,由回归系数的P 值,可以看出x4的P 值为0.219,大于0.05,回归系数不显著,因此我们在后续处理时需要剔除该变量作为控制变量。

图5 面板回归结果(stata 程序)
剔除控制变量x4 后,我们对数据进行固定效应回归模型,得到回归结果。
最终可以得到回归方程为:

|结论与对策建议
(一)结论
从以上回归分析模型结果可知,数字经济明显正向影响长三角区域一体化发展,在保持其他条件不变的情况下,数字经济每增长一个单位,长三角区域一体化将增长0.2 个单位,说明数字经济发展可以显著推动长三角区域一体化发展。数字经济的发展推动城市在市场、政策、基础设施、生态环境等方面协同发展,而数字经济包含的新的生产设施、产业运营、科技创新等对城市的发展起着重要作用。因此,数字经济可以更高效地发挥城市的作用,促进区域一体化发展,真正实现先富带动后富发展。
在控制变量方面,人口与区域一体化呈负向的影响关系,由于区域中各城市人口分布不均,导致周围城市的发展远落后于中心城市。人口是影响城市发展的一个重要因素,小城市一定要采取相关措施,减少人口迁徙,避免阻碍区域一体化发展。除了人口,其余变量GDP、中小学数量、医疗卫生机构数、工业污染治理均发挥正向作用。学校是为区域一体化提供人才储备的地方,新型的数字经济产业需要人才,因此学校数量分布密集的城市,区域一体化发展会更好。
(二)对策建议
1.夯实基础,推进数字基础设施建设。发展数字经济主要抓手在数字基础设施建设。要推动新一代信息基础设施建设,加快建成高速、一体、融合、智能、绿色、可控的智能化综合性数字信息基础设施;有序推进基础设施智能升级,稳步构建智能高效的融合基础设施,提升基础设施网络化、智能化、服务化、协同化水平,筑牢长三角区域发展数字经济的基础。
2.立足产业,促进数字经济融合发展。加快物联网、大数据、人工智能的深度融合发展,围绕数字产业项目,持续推动传统产业全方位、全链条数字化转型。创新发展数字农业,纵深发展数字工业,大力发展数字商务,优化服务管理体系、服务模式,提升服务品质与效益。数字化改造传统产业同时,积极培育新产业、新业态、新模式,凸显数字经济对传统经济的倍增作用。
3.人才为本,完善数字人才引培机制。创新是引领发展的第一动力,人才是发展的第一资源。长三角区域城市要共商数字人才引进政策,共建区域就业和数字人才网,创新高层次和急需紧缺数字人才等群体职称评定与聘任方式,切实提高数字人才待遇和社会地位。加大数字人才政策的宣传,促进政策落地执行,吸引更多数字人才集聚长三角区域。
4.生态优先,坚持绿色发展生命线。坚定不移走生态优先,绿色发展之路。加强生态保护,加大环境治理,夯实绿色发展之基,努力建成绿色美丽长三角。合力保护重要生态空间,切实加强生态环境分区管治,强化生态红线区域保护和修复;共同保护重要生态系统,强化省际统筹;推动跨界水体环境治理,促进跨界水体水质明显改善;联合开展大气污染综合防治,强化能源消费总量和强度 “双控”,推动大气主要污染物排放总量持续下降,切实改善区域空气质量。
猜你喜欢
数学物理学报(2022年3期)2022-05-25
数学物理学报(2022年2期)2022-04-26
华东经济管理(2021年7期)2021-07-08
华中师范大学学报(自然科学版)(2021年2期)2021-04-10
经济与管理(2020年4期)2020-12-28
当代陕西(2020年17期)2020-10-28
诗歌月刊(2019年7期)2019-08-29
人大建设(2018年5期)2018-08-16
统计科学与实践(2016年4期)2016-03-01
统计科学与实践(2016年3期)2016-03-01
