
基于动态采样策略的微服务链路追踪方法①
2022-02-15 06:40颜复海李培军张泽华陈文辉许舒人
计算机系统应用 2022年1期
颜复海,李培军,张泽华,陈文辉,许舒人
1(中国科学院 软件研究所 软件工程技术研究开发中心,北京 100190)
2(中国科学院大学,北京 100490)
3(厦门物之联智能科技有限公司,厦门 361022)
1 引言
由于具备高可用性、支持动态伸缩与分布式部署等特点,微服务架构已成为云原生时代设计与构建大型分布式应用系统的主要技术架构之一.在微服务架构中,应用系统被划分为多个高内聚、功能单一、可独立部署的服务,并通过服务之间的轻量级远程调用来构建复杂的业务逻辑[1,2].
可观察性是指系统可由外部输出推断其内部状态的程度.对微服务架构而言,当服务数量庞大时,服务之间的调用关系变得复杂,使得故障分析与排查的困难程度显著上升,因此微服务架构也面临着如何提高可观察性的问题.分布式链路追踪(distributed tracing)是提升微服务架构的可观察性的关键技术之一,其通过收集应用系统处理服务请求的详细信息来为系统行为建模,以帮助开发与运维人员获得系统运行时的全局视角[3].
应用系统对一次外部请求的完整处理称为一次执行(execution).以一次执行中是否出现异常为依据可将该次执行划分为正常执行或异常执行.跟踪(trace)是对执行的记录,一个跟踪对应一次执行,其内容包含该次执行中各服务之间的调用关系以及各服务处理调用请求的详情与结果.跟踪由插桩代码生成并上报至负责汇总处理的远程进程.
出于减小对应用系统的性能影响、节约存储资源等方面的考虑,在分布式链路追踪中通过特定的采样策略来只收集一部分执行的跟踪[3–5].常见的开源链路追踪系统或框架实现的采样策略有固定采样、概率采样、限速采样、自适应采样等[6–8].以上采样策略虽然实现简单且有效避免了插桩代码对应用系统造成较大工作负载,但是存在收集过多无助于故障分析与排查等任务的正常执行的跟踪等问题[4,5].以概率采样为例,收集的跟踪当中各类执行的跟踪占比与其出现的概率一致,因此高频的正常执行的跟踪占比将远大于低频的异常执行.但是对于故障分析这一需求而言,异常执行的跟踪占比越大、跟踪数量越多则提供给系统管理人员进行故障分析等任务的信息量越大[4,5].
针对以上问题,本文提出一种动态采样策略:通过采样策略树解决如何自动调整跟踪采样率的问题;通过执行轨迹图解决如何快速准确地找到需要调整跟踪采样率的服务的问题;通过以上两种数据结构的协作提高异常执行的跟踪占比.基于以上工作,本文实现了原型系统并通过实验对动态采样策略的有效性进行了验证.
2 基于采样策略树的跟踪采样率自动调整方法
2.1 问题分析
任一执行类型的调用链路中最先处理外部请求的服务称为该类执行的入口服务.提高入口服务的跟踪采样率将会增加其对应执行类型的跟踪数量,从而消耗更多的存储资源.若要提高存储资源的利用率,那么当提升某一入口服务的跟踪采样率时就应适当减小其他部分入口服务的跟踪采样率,使得跟踪数量保持动态平衡.本文设计了一种称为采样策略树的数据结构来解决跟踪采样率的自动调整问题.
2.2 采样策略树的定义
定义1.一棵m阶的采样策略树是满足以下性质的m叉树:
1)树中任一节点至多有m个子节点;
2)除根节点外,其他节点要么没有子节点,要么子节点数大于1.
图1所示为采样策略树的树节点结构.父节点指针为指向该树节点的父节点的指针.若树节点为根节点,则父节点指针为空.子孙叶子节点计数为以当前树节点为根节点的m叉树中所有叶子节点的计数.树中只保存入口服务.标签为当前树节点保存的服务的唯一标识符.所有服务只保存在叶子节点中,因此枝干节点的标签的值为空.子节点指针集为固定容量的集合,用于保存当前节点的所有子节点的指针,其底层由一个指针哈希表和一个双向链表来实现.

图1 采样策略树的树节点结构
2.3 采样策略树的操作
采样策略树支持的操作有插入、剪枝、生成和提升等.插入操作将新服务的叶子节点插入到离根节点尽可能近的位置.剪枝操作将某一服务对应的叶子节点从树中删除.
生成操作以路径概率积作为树中服务的跟踪采样率.路径概率积的定义如下:
定义2.设叶子节点l且叶子节点的父节点不为根节点r,其到根节点的路径为s=(l,n1,n2,···,nk,r),ni为路径上的枝干节点,则该叶子节点的路径概率积为:

其中,Nx为节点x的子节点数量;若叶子节点l的父节点为根节点,则该节点的路径概率积为:

提升操作将提升树中服务的跟踪采样率,其伪代码如算法1 所示.提升操作内部包含了降级操作,遭到降级的叶子节点,其保存的服务的跟踪采样率也随之降低.

算法1.采样策略树的提升操作算法输入:叶子节点 leafNode 1.function Promote(leafNode)2.if leafNode的父节点为根节点 then 3.return 4.end if 5.grandparent:=leafNode的祖父节点6.parent:=leafNode的父节点7.从parent的子节点集合中删除leafNode 8.if grandparent的子节点数小于最大值 then 9.将leafNode 添加到 grandparent的子节点集中10.将leafNode的父节点指针指向 grandparent 11.if parent 只剩一个子节点 then 12.将parent 唯一的子节点添加到parent的父节点的子节点集合当中,删除parent//路径压缩13.else 14.更新parent的子孙叶子节点计数值15.end if 16.else 17.lruNode:=grandparent的最近最久未使用子节点18.if parent的子节点数大于2 then 19.Merge(lruNode,leafNode)20.else 21.替换lruNode 与leafNode的位置22.enf if 23.更新parent的子孙叶子节点计数值24.end if 25.end function 26.function Merge(a,b)27.在a的父节点与a 之间插入一个新的枝干节点28.将a,b的父节点指针指向新的枝干节点29.将a,b 移动到新枝干节点的子节点集合当中30.end function
图2为一棵3 阶采样策略树的发生降级的提升操作示例.一个节点的子节点以从左到右的顺序表示其最近被使用过的时间顺序,即最右边的为最近最久未被使用的子节点.需要被提升的服务为D.由于grandparent的子节点数量已达最大值3,因此需要降级该节点的最近最久未被使用的子节点C,使其与D 交换位置.
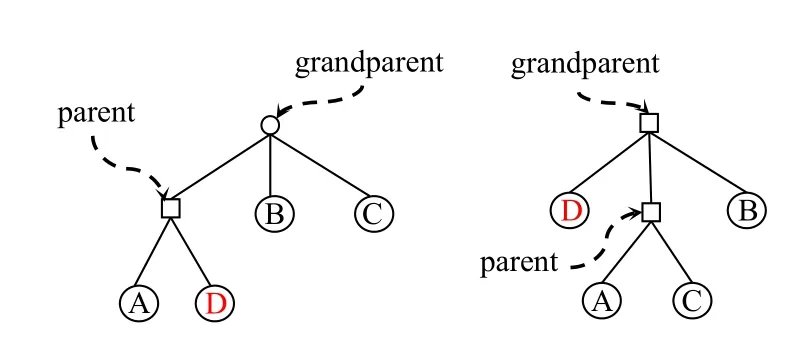
图2 发生降级的提升操作
2.4 跟踪采样率的自动调整
给定服务并找到对应的叶子节点之后,提升操作将改变该叶子节点处于树中的位置使其离根节点更近.根据路径概率积的定义可推导出:一个服务的叶子节点被提升之后,该服务根据路径概率积计算所得的跟踪采样率随之提高.提升操作可能触发降级操作,即某一服务的叶子节点被下放到树的更深处,因此被降级的叶子节点的服务的跟踪采样率会随之降低.跟踪采样率的变化方向与其是否被提升有关且执行提升操作的条件可自行设定.跟踪采样率变化的幅度与树结构的变化有关,具体数值取决于所涉及树节点的子节点数.
在提升操作中加入降级操作是为了提高存储资源的利用率.一个服务的吞吐量和跟踪采样率共同决定了以该服务作为入口服务的执行类型的跟踪数量.当吞吐量不变时,跟踪采样率与跟踪数量呈正相关.根据路径概率积的定义可推导出:采样策略树中所有服务根据路径概率积计算所得的跟踪采样率总和为1.因此,当提高其中一个服务的跟踪采样率时,必定导致树中另外一部分服务的跟踪采样率的降低,使得跟踪数量保持动态平衡,从而有效提高存储资源利用率.
3 基于流言协议的执行轨迹图全局更新算法
3.1 问题分析
入口服务中的插桩代码做出采样决策并将其写入请求上下文之后,采样决策会随着调用链路传播给该入口服务递归调用的其他服务,并且各服务根据请求上下文中的采样决策判断是否上报跟踪,因此任一服务的跟踪采样率等于其入口服务的跟踪采样率.当某一非入口服务出现异常时,要提升其跟踪采样率以提高异常执行的跟踪占比,则需找到与之对应的入口服务.针对以上问题,本文利用执行轨迹图这一数据结构来刻画服务之间的调用关系.
3.2 执行轨迹图的定义
定义3.执行轨迹图G=(V,E)是一个有向图,其中,节点集V表示服务集合,边集E表示调用关系集合,边的箭头指向被调用的服务.
图3为一个执行轨迹图示例.A为入口服务,且A 调用服务B 与服务C 来完成其本身的请求处理.图中其他服务的调用关系与之类似.

图3 执行轨迹图示例
3.3 全局更新算法
执行轨迹图的更新是一个动态的过程,即每次发现新的服务或调用关系,就把表示新服务的顶点、表示新调用关系的边添加到执行轨迹图当中.基于执行轨迹图,在给定任一服务的前提下,可通过图搜索算法快速找到该服务对应的入口服务.在实际应用中,出于容灾和性能上的考虑,需要冗余地部署跟踪收集进程,因此需要在多个跟踪收集进程之间同步执行轨迹图,使得所有执行轨迹图的副本能够反映各服务之间的实时调用关系.本文提出一种基于流言协议的执行轨迹图全局同步算法以解决上述问题.
图4为本文用到的基于流言协议的组件:种子、注册中心,以及两者的通信关系.注册中心用于种子发现,即当新的种子加入时向注册中心登记其路由信息.种子定期向注册中心发送心跳信号并获得所有其他种子的实时路由信息,以及将新调用关系封装成消息散播给其他种子.在实现中,每个跟踪收集进程都会维护一个种子,而注册中心是全局唯一的.当跟踪收集进程发现新调用关系时,会向本地的种子发起消息散播请求,将新调用关系同步给其他跟踪收集进程中的执行轨迹图.执行轨迹图的全局更新算法伪代码如算法2 所示.算法2 参照了流言协议的SIR 模型[9],即每个种子对于任一消息在任一时刻只对应以下3 种状态之一:S (susceptible),未收到该消息;I (infected),已收到该消息且正在参与该消息的散播过程;R (removed),已收到该消息且已退出该消息的散播过程.

图4 基于流言协议的组件及通信关系

算法2.执行轨迹图的全局更新算法输入:新调用关系 newRel 1.function Synchronize(newRel)2.msgID:=由snowflake 算法生成全局唯一消息ID 3.msg:=(msgID,newRel)//消息格式4.Monger(msg)5.end function 6.function Monger(msg)7.if not msg的ID 存在于LRU 缓存中 then 8.提取调用关系,更新执行轨迹图9.将msg的ID 放入LRU 缓存10.end if 11.if not 本地节点对msg 处于R 状态 then 12.peers:=随机选取n 个对等节点13.for each 对等节点peer in peers:14.以msg为参数,远程调用peer的Monger 方法15.end for 16.以概率p 转换成R 状态,否则为I 状态17.end if 18.end function
4 原型系统
4.1 系统架构
本文参考开源分布式链路追踪系统Jaeger的数据模型与架构并参照OpenTracing 规范[10]实现了原型系统,其系统架构如图5所示.插桩代码负责生成、上报跟踪以及周期性地向配置服务器拉取采样策略.代理负责为插桩代码屏蔽配置服务器和收集器的路由信息.配置服务器负责处理采样策略的拉取请求以及更新采样策略的请求并且通过策略管理器维护全局唯一的采样策略树.注册中心用于种子发现,维护所有种子的路由信息.种子用于执行全局更新算法.收集器负责收集、分析以及持久化跟踪.
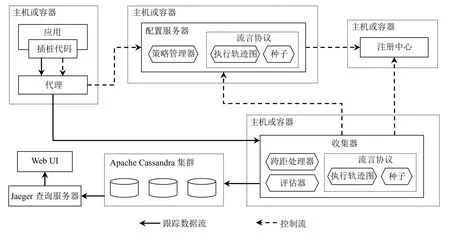
图5 原型系统的架构
4.2 跟踪收集过程
跨距(span)是跟踪的基本组成单元,一个跨距记录一个服务处理一次请求处理的详细信息以及调用关系.收集一个跟踪即收集该跟踪的所有跨距.跟踪收集的详细过程如下:
(1)当外部请求到达应用系统时,入口服务中的插桩代码将做出采样决策并将其写入请求上下文使其在调用链路中传播;
(2)所有服务中的插桩代码都将在其嵌入的服务处理请求之前分析请求上下文并创建一个跨距,且请求上下文中的采样决策会被写入跨距上下文;
(3)待请求处理完成之后,插桩代码将根据跨距上下文中的采样决策判断是否上报该跨距,若执行采样则将跨距发送至代理,再由代理上报至收集器;
(4)收集器分析跨距获得调用关系,判断是否为新调用关系,若为新调用关系则执行全局更新算法;
(5)收集器调用评估器判断该次执行是否为预先定义的执行类型,若是则向配置服务器发送请求以提升该执行的入口服务的跟踪采样率;
(6)收集器将跨距保存至数据库中.
4.3 采样策略拉取过程
插桩代码周期性地发送拉取采样策略的请求,该请求包含两个参数:服务唯一标识符和该服务从上一次发送请求到目前为止这一时间段内的每秒请求数,即QPS (request per second)值.
配置服务器为所有入口服务维护一个QPS 值的哈希表.当接收到采样策略拉取请求时,配置服务器首先会用参数中的QPS 更新该哈希表,然后通过以下等式计算采样率:
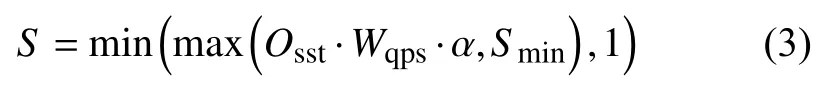
其中,Osst为采样策略树的生成操作的路径概率积计算结果,α ∈(0,+∞)为缩放因子,Smin为最小采样率,Wqps为QPS 权重函数的输出,其计算方式如下:

其中,qi表示第i个入口服务的实时QPS 值,E为入口服务数.
计算所得的采样率会被封装成概率采样为底层采样方式的采样策略作为响应返回给插桩代码,由插桩代码分析响应结果并据此更新本地的采样策略.
4.4 采样策略树与执行轨迹图的协作过程
为评估器设置评估条件作为判断HTTP 服务的某次执行是否为异常执行的依据:HTTP_STATUS_CODE≠200.
图6所示为HTTP 服务出现一次异常执行时采样策略树与执行轨迹图的协作过程.

图6 采样策略树与执行轨迹图的协作过程
(1)分析调用服务E 时由插桩代码生成的跨距,调用评估器分析其标签,发现其满足评估条件;
(2)调用执行轨迹图的查询接口,由其利用图搜索算法找到服务E的入口服务,即服务A;
(3)调用一棵2 阶采样策略树的提升操作接口,提升服务A的叶子节点并降级服务X的叶子节点以提升服务A的跟踪采样率、降低服务X的跟踪采样率.
实际上执行类型是高度可定制的,可根据不同的任务与场景为评估器设置不同的评估条件,并由插桩代码在预设的异常情况发生时为跨距设置与评估条件对应的标签名称以及标签值.
5 实验验证与分析
5.1 实验方案
本文在3 台主机上部署Kubernetes 集群、Istio 服务网格并开发与部署对应8 个执行类型的32 个HTTP微服务作为模拟云环境部署的实验环境.每台主机的操作系统为CentOS 7.9,处理器为Inter(R) Xeon(R) E5-2620 @ 2.00 GHz,内存容量为32 GB,Kubernetes 版本为1.19.0,Istio 版本为1.7.本文使用基于Python 开发的压测工具Locust 来模拟多用户的并发请求.在实验中以容器组(pod)的形式冗余部署了3 个收集器.
本文着重关注两个实验指标:任一时间段内各执行类型的跟踪占比和跟踪数.本文将比较固定采样、概率采样、限速采样、自适应采样以及动态采样的实际表现.以上各采样策略的实验参数如表1所示.
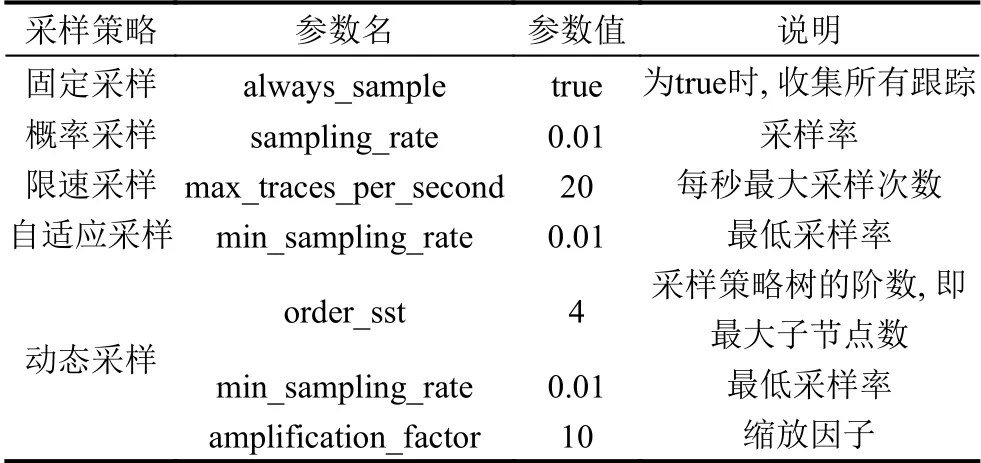
表1 实验中各采样策略的参数
在各采样策略的实验中,每隔固定长度的时间段则为某一类执行注入故障且在对下一类执行注入故障之前,修复上一类执行的故障.注入的故障类型为内部错误,具体表现形式为调用服务所返回的HTTP 状态码为500,因此在实验中设定评估条件为:HTTP 状态码不等于200.当插桩代码捕捉到该异常时会将HTTP状态码以及对应的值500 写入跨距标签.
5.2 实验结果
各采样策略的实验中跟踪占比的变化情况如图7–图11所示.图11表明在动态采样策略的实验中,对于任一时间段内被注入故障的执行类型的跟踪占比显著上升.各采样策略的实验中的跟踪数变化情况如图12所示.在动态采样的实验中,各时间段内被注入故障的执行类型的入口服务的跟踪采样率显著上升,其对应的跟踪数也显著增多,但是由于同时降低了另一部分入口服务的跟踪采样率,因此任一时间段的跟踪数相对于前一时间段没有明显地上升或下降,使得跟踪数保持动态平衡而异常执行的跟踪占比显著上升,从而提高了存储资源的利用率.

图7 固定采样实验的跟踪占比变化

图9 限速采样实验的跟踪占比变化

图10 自适应采样实验的跟踪占比变化
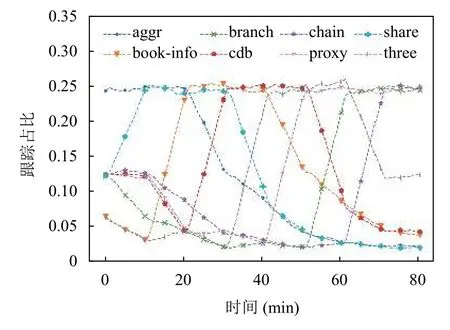
图11 动态采样实验的跟踪占比变化

图12 跟踪数随时间的变化情况
实验结果表明,动态采样有效提升了任一时间段内异常执行的跟踪占比并且高效利用了存储资源.
6 总结
针对现有开源分布式链路追踪系统或框架的采样策略存在的收集过多无助于故障分析等任务的正常执行的跟踪这一问题,本文提出一种基于动态采样策略的微服务链路追踪方法:通过基于采样策略树的跟踪采样率自动调整方法解决了跟踪采样率的自动调整问题;通过基于流言协议的执行轨迹图全局更新算法解决了如何快速准确地找到需要调整跟踪采样率的入口服务的问题.实验结果表明,本文方法在任一时间段内均有效地提升了异常执行的跟踪占比并且高效利用了存储资源.
猜你喜欢
福建中学数学(2021年1期)2021-02-28
小资CHIC!ELEGANCE(2021年44期)2021-01-11
少年文艺·开心阅读作文(2017年12期)2017-12-21
新少年(2017年9期)2017-09-06
智能计算机与应用(2016年6期)2017-05-08
课堂内外(小学版)(2017年3期)2017-04-15
新高考·高一数学(2016年3期)2016-05-19
少年科学(2015年9期)2015-10-14
中国信息化·学术版(2013年1期)2013-05-28
智能计算机与应用(2007年4期)2007-08-25
