
基于组合权重TOPSIS的Kubernetes调度算法①
2022-02-15 06:40张文辉王子辰
计算机系统应用 2022年1期
张文辉,王子辰
(桂林电子科技大学 计算机与信息安全学院,桂林 541004)
1 概述
近几年,随着云计算技术的发展,在云上部署应用服务有利于降低成本和提高效率,但却引出了资源利用率低、部署和重启应用服务等待时间长等问题,而Docker 作为容器技术的代表,为应用程序提供了更加轻量级和易于部署的解决方案,如今已是云计算领域的热点.
Kubernetes是容器编排技术的代表,是Google 公司Borg 项目的一个开源版本,它基于Docker 容器技术,目的是实现资源管理的自动化,以及跨多个数据中心的资源利用率最大化.Kubernetes 具有完备的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、可扩展的资源调度机制等[1].在Kubernetes 集群中,以Pod 作为资源调度的基本单位,而Pod中可以容纳多个容器,集群根据其生命周期进行管理,满足了产品内运行程序的需求,Kubernetes 已成为大规模容器化应用程序部署的事实标准[2].近年来,大多数互联网公司的相关技术人员相继把Kubernetes 运行在重要业务上,同时越来越多的微服务也使用Kubernetes 进行部署和管理.
Kubernetes 资源调度是其核心的模块,不合理的资源调度策略会造成云平台整体资源利用率低,用户的部署请求得不到快速响应,服务质量下降,同时也提高服务商的软硬件设施成本.
Kubernetes 调度策略首先根据用户提交的Pod 应用的最小资源需求过滤掉不符合要求的节点,其次以节点剩余CPU和内存的资源利用率为评分指标,对候选节点评分,选择得分最高的节点进行部署.该策略存在两处不足:(1)只考虑了CPU和内存两种资源指标,无法满足各异的应用需求;(2)采用相同权重计算候选节点得分,易造成资源使用的过度倾斜.
关于Kubernetes 资源调度问题,已经有学者在优化节点负载、提高集群资源利用率和减少资源成本等方面做了大量研究.Menouer 等[3]在Docker Swarm中利用TOPSIS 多属性决策方法结合Spread和Bin Packing原理优化了多个资源指标下容器的调度问题;El Haj Ahmed等[4]通过容器应用的时间线和执行的历史信息来优化容器应用的部署;Imdoukh 等[5]提出了一种基于多目标遗传算法进行优化的调度算法MOGAS (manyobjective genetic algorithm scheduler),该调度算法与基于蚁群算法优化的调度算法相比较效果更佳;Zhang等[6]通过结合蚁群算法和粒子群优化算法改进了Kubernetes 调度模型,不仅减少了总的资源成本和节点最大负载,也使得应用部署更加平衡;孔德瑾等[7]提出一种基于资源利用率进行指标权重自学习的调度机制,提升了集群资源均衡度和资源综合利用率;Li等[8]提出BDI (balanced-disk-IO-priority)算法来动态调度容器应用以改善节点间磁盘I/O 平衡,提出BCDI(balanced-CPU-disk-IO-priority)算法动态调度容器应用以解决单节点CPU和磁盘I/O 负载不平衡的问题;吴双艳[9]通过灰色预测算法对资源负载进行预测,对容器云平台弹性伸缩系统优化来提高服务质量;Dua 等[10]提出一种可供选择的任务调度算法,为特定类型任务打上标签,并基于标签将任务迁移实现集群负载均衡;Zheng 等[11]提出一种基于Docker 集群的自定义Kubernetes 调度器调度策略,使用优化的预选算法模型和优选算法模型改进Kubernetes 默认调度策略,提高集群调度的公平性和调度效率.
虽然国内外学者针对Kubernetes 资源调度的研究已经取得了较多的成果,但在异构环境下兼顾资源指标权重和资源指标本身都有些欠缺.针对此问题,本文主要在崔广章等[12]、龚坤等[13]的基础上,选择CPU、内存、带宽、磁盘容量和IO 速率的实时资源利用率作为评价指标,并将基于层次分析法和熵权法得到的组合权重应用到TOPSIS 多属性决策算法中,致力于将Pod 应用部署到最合适的节点上.
2 Kubernetes 默认调度策略
Kubernetes Scheduler是Kubernetes 集群的调度器,用于将用户创建的Pod 按照特定的调度算法和调度策略绑定到集群中某个合适节点上.其调度过程可以分为两个阶段,分别是预选和优选阶段.
预选阶段主要是根据用户提交Pod 应用的最小资源需求过滤掉不满足需求的节点,Kubernetes 也提供了多种预选策略供用户选择,如PodFitsResources、PodsFitsPorts 等.
优选阶段主要是在预选阶段的基础上,采集剩下节点上CPU和内存的空闲利用率进行评分,选择评分最高的节点作为部署节点,最后将Pod 应用绑定到该节点上.同样的,Kubernetes 也提供了几种优选策略:
1)LeastRequestedPriority,该策略用于从候选节点中选出资源消耗最小的节点,即CPU和内存空闲资源越多,评分越高,其计算公式如下:

2)BalancedResourceAllocation,该策略用于从候选节点中选出CPU和内存使用率最均衡的节点,即CPU和内存使用率越接近,评分越高,其计算公式如下:

上述两种策略,均只考虑了CPU和内存,且策略中CPU和内存利用率是由Pod 应用的需求来衡量调度的优先级的,无法准确反映节点实际资源使用情况,也会影响节点的整体资源均衡性.
3)SelectorSpreading,该策略将相同标签选择器选取的Pod 应用尽可能散开部署到多个节点上,节点上该标签选择器匹配的Pod 应用数目越少,则该节点的评分越高,使用标签选择器的资源对象有:Service,Replication Controller,ReplicaSet 等.
此外,调度策略还包括NodePerferAvoidPods,InterPodAffinity,NodeAffinity,TaintToleration 等.
上述公式中,Scpu和Smem分别表示节点上总的CPU和内存容量,而Ncpu和Nmem分别表示节点上已被使用的CPU和内存的容量加上将要部署的Pod 应用的CPU和内存的容量之和.
3 组合权重的TOPSIS 调度策略
由于Kubernetes 默认调度算法仅仅考虑CPU和内存,没有考虑到带宽、IO 速率、磁盘容量等资源的需求,无法对带宽敏感型、IO 速率敏感型等Pod 应用进行合理的资源调度,同时两个评分指标都采用相同权重,无法满足Pod 应用各异的资源需求,当Pod 应用部署的数量逐步增加时,可能会造成其他指标如带宽、IO 速率等资源过度浪费.
在评价指标方面,考虑到评价指标应该有效且有代表性,因此本文选择CPU、内存、带宽、磁盘容量、IO 速率作为评价指标.
在权重方面,本文利用熵权法[14]对层次分析法[15]得到的主观权重进一步优化,有效避免了层次分析法权重的主观性和熵权法权重的客观性.
最后将组合权重应用到TOPSIS[16]多属性决策方法中,来计算Pod 应用调度方案解和理想最优解及最劣解之间的距离,通过理想贴合度的大小排序,为Pod 应用选择最合适的节点进行部署.
3.1 资源信息获取
本文主要采集两种资源信息:
(1)节点当前的各个资源指标的资源利用率.
(2)已部署的Pod 应用在节点上占用的资源份额.
通过在集群中每个节点上部署Proxy 监控代理,用于采集上述两种资源信息,具体流程如图1所示.首先准备两个数据库,分别用于存储监控节点的资源利用率和Pod的CPU、内存、带宽、磁盘、IO 速率占用率信息.在控制器模块逐个分析节点Node 标识和Pod 应用标识,控制器可获取到Proxy 代理的IP、端口,向Proxy 代理发送监控命令,之后采集实验需要的监控信息存放到对应的数据库中.

图1 采集资源利用率
3.2 层次分析法求权重
层次分析法是一种使人们的思维过程和主观判断实现规划化的方法,可以使因素的不确定性得到很大程度降低,不仅简化了系统分析与计算工作,而且有助于决策者保持其思维过程和决策过程原则的一致性,是一种确定权重的科学方法,其计算步骤如下:
Step 1.构造资源指标判断矩阵
假设集群中有m个资源指标,通过两两比较确定指标重要程度,进而得出判断矩阵A=(aij)m×m,i=1,2,…,m;j=1,2,…,m,重要程度的定义如表1所示.

表1 相对重要程度表

矩阵中,m表示资源指标的个数,aij表示相对于第j个资源指标,第i个资源指标的重要程度,且aii=1.
本文以5 种资源指标CPU,内存,带宽,磁盘,IO速率为基础,给出判断矩阵如下,选取理由如表2所示.

表2 部分指标对比结果

Step 2.一致性检验
判断矩阵客观反映了不同资源指标之间的相对重要性,但是并不能保证每个判断矩阵都是一致的.例如,指标A1比指标A2重要,指标A2比指标A3重要,那么指标A3比指标A1重要就不合理,因此需要通过计算一致性检验CI(consistency index)和一致性比例CR(consistency ratio)来衡量判断矩阵是否完全一致,具体计算公式如下:
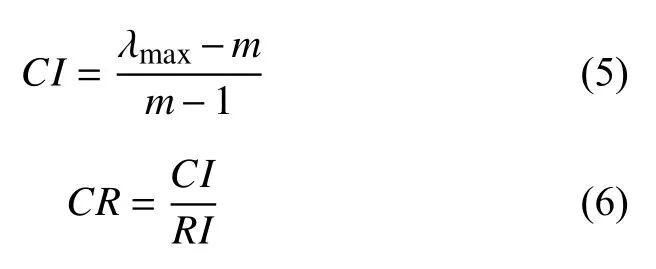
其中,λmax为判断矩阵的最大特征根,m为矩阵的阶数,RI为平均一致性指标,其取值如表3所示.若CR<0.1,则通过一致性检验,否则判断矩阵需要修正.

表3 平均随机一致性指标
Step 3.计算资源指标权重
本文选择常用特征值法来计算权重,只需要计算符合A·W=λmax·W的特征向量,然后Wλmax将归一化,即可得到权重wAj,具体权重信息如表4所示.

表4 AHP 资源指标权重
3.3 熵权法求权重
熵权法基本思路是根据指标变异性的大小来确定客观权重.该方法可以深刻反映出指标的区分能力,若某个指标的信息熵越小,表明指标值的变异程度越大,提供的信息量越多,在综合评价中所能起到的作用也越大,其权重也就越大.其计算步骤如下.
Step 1.数据预处理
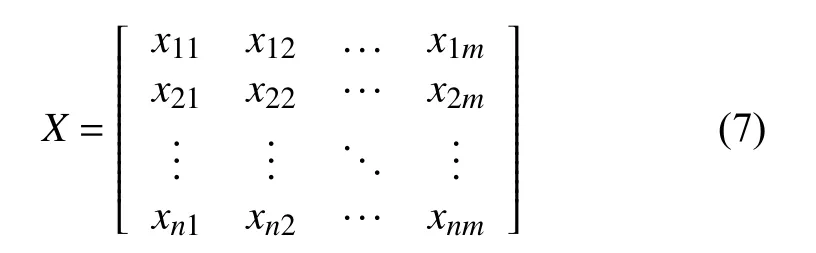
假设集群中有n个节点,m个资源指标,通过监控代理Proxy 采集到的资源利用率的实时数据,构造矩阵xij表示第i个节点上第j个资源指标的资源利用率.
Step 2.资源指标归一化处理
考虑到每个资源指标的计量单位不同,有必要在计算综合资源指标前,进行标准化处理,即把资源指标的绝对值转化为相对值.
正向型资源指标归一化,用于处理效益型决策参数,这类决策参数的特点是值越大效果越好,其计算公式如下:

负向型资源指标归一化,用于处理成本型决策参数,这类决策参数的特点是值越小效果越好,其计算公式如下:

Step 3.计算第j个资源指标下第i个节点的值所占该资源指标的比重Pij,i=1,2,…,n;j=1,2,…,m.
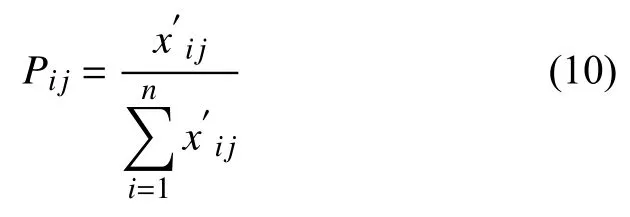
Step 4.计算第j个资源指标的熵值ej,j=1,2,…,m.

其中,k=1/In(n)>0,满足ej≥0.
Step 5.计算资源指标的差异系数dj,j=1,2,…,m.

Step 6.计算各指标的权重wEj,j=1,2,…,m.
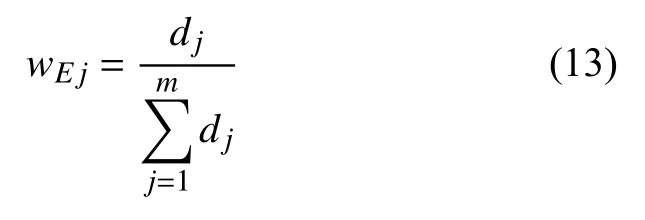
3.4 计算组合权重
将熵权法得到的权重与层次分析法得到的权重结合,用于避免层次分析法的主观影响和熵权法的客观影响,其计算公式如下:
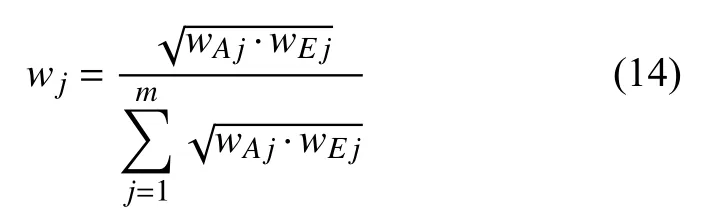
其中,wj为第j个资源指标的组合权重,wAj和wEj分别表示通过层次分析法和熵权法得到的第j个资源指标的权重.
以表4得到的AHP 权重为基础,监控代理Proxy采集到的某个时间段的5 种资源指标的实时利用率如表5所示,根据表5的数据计算出熵权权重,最后根据式(14)计算得到组合权重,具体权重信息如表6所示.

表5 资源实时利用率 (%)
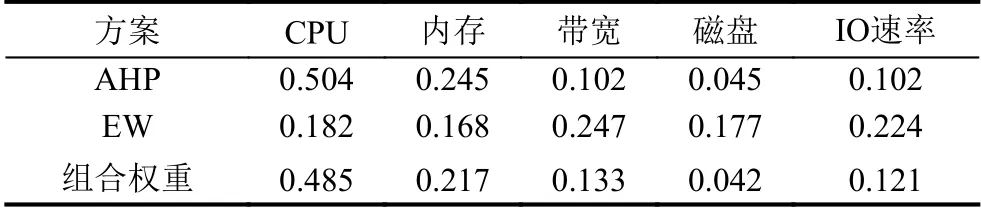
表6 详细权重信息
3.5 TOPSIS 确定最优节点
逼近理想解排序方法(TOPSIS)是一种有效的多属性决策方案,通过从归一化的数据矩阵中构造出决策问题的正负理想解,计算出方案与正负理想解的距离,最终得到贴合度作为评价方案的优劣依据.其计算步骤如下.
Step 1.构造决策矩阵
假设集群中有n个节点,m个资源指标,通过监控代理Proxy 采集到的资源利用率的实时数据加上Pod部署所占用的资源利用率,构造决策矩阵i=1,2,…,n;j=1,2,…,m.

其中,xij表示第i个节点上第j个资源指标的资源利用率.
Step 2.归一化决策矩阵
采用极差标准化方法对决策矩阵进行归一化处理,目的是消除决策参数不同量纲之间的影响.
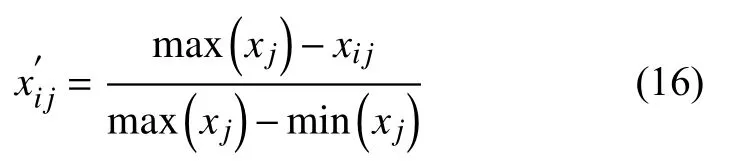
Step 3.构造加权决策矩阵
各异的Pod 应用对节点资源指标的需求敏感程度不同.大体上可以分为内存倾向型、CPU 倾向型、IO速率倾向型,带宽倾向型等等,若是每个资源指标都采用相同权重,无法满足各异需求的Pod 应用,因此有必要分别为节点的资源指标设置不同的权重.
基于此,在考虑资源指标的差异性,和避免了层次分析法人为的主观影响和熵权法带来的客观影响下,本文通过结合层次分析法与熵权法得到组合权重,并应用到决策矩阵中,构造了加权决策矩阵i=1,2,…,n;j=1,2,…,m.

其中,wj是第j个资源指标的组合权重.
Step 4.计算正负理想解

其中,Z+表示加权决策矩阵的正理想解,由所有候选节点上每种资源指标参数的最大值构成;Z-表示加权决策矩阵的负理想解,由所有候选节点上每种资源指标参数的最小值构成.
Step 5.计算每个候选节点到正、负理想解的距离
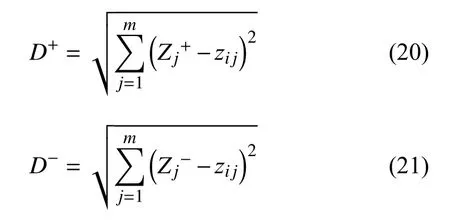
其中,D+和D-分别代表各候选节点到正负理想解的欧式距离.
Step 6.计算每个候选节点与最优候选节点的相对贴合度Si

其中,相对贴合度Si越大,说明该候选节点越适合当前需要部署的Pod 应用.
以表5和表6的数据为基础,结合TOPSIS 多属性决策算法可以得到相对贴合度S,如表7所示,可以看出节点1的相对贴合度S 最大,因此将Pod 应用部署到节点1 最合适.

表7 相对贴合度
4 实验验证与分析
为测试本文提出的Kubernetes 调度算法的性能,进行实验验证.所有实验均由PyCharm 2020.2 编程实现,并基于平台:Windows 10,Intel(R) Core(TM) i7-8565U CPU 1.80 GHz,16 GB 内存.
4.1 实验环境
在仿真环境下,模拟一个包含60 个节点的Kubernetes 集群,集群中节点分为3 种类型,每种类型20 个来模拟异构的环境,节点具体信息如表8所示.

表8 节点资源信息
同样的,鉴于容器应用资源多样化的需求,本文按照CPU 敏感型、内存敏感型、带宽敏感型、存储敏感型、IO 速率敏感型以及无倾向类型6 类容器应用构造了Pod 资源需求,表9为部分Pod 资源需求.

表9 部分Pod 资源需求表
4.2 实验评价指标
假设Kubernetes 集群中有n个节点,每个节点上有m种资源.资源的实时利用率是通过监控代理Proxy 采集获取得到的.U(i,j) 表示节点i上资源j的资源利用率;Uavg(i) 表示节点i上各个资源利用率总和的平均值;S(i) 表示节点i上各个资源利用率的标准差,即资源失衡度;Savg表示所有节点的平均资源失衡度.Savg的值越小,代表集群中各个资源的利用率越平衡,就不容易出现资源倾斜,如此就可以部署更多的Pod 应用,具体计算公式如下:

4.3 实验结果和分析
在上述Kubernetes 集群中,分别采用Kubernetes的LeastRequestedPriority (LRP)策略与BalancedResource-Allocation (BRA)策略和本文提出的组合权重TOPSIS调度算法(CWT),从资源平衡度、CPU、内存、带宽、IO 速率角度来对比3 种算法的表现.
1)集群资源失衡度
集群失衡度变化曲线如图3所示,当Pod 数量小于1 200 时,此时集群负荷相对较低,LRP和BRA 策略与CWT 算法的资源失衡度相差不大,但随着部署的Pod 应用数量越来越多,可以很明显的发现CWT 算法开始发挥作用,它的资源失衡度明显好于LRA 策略.
在集群资源整体快达到饱和时,CWT 算法优于BRA 策略.这是由于CWT 算法不仅考虑了集群节点的5 种资源指标,还分别考虑了各个资源指标的权重情况,这就降低了集群中单个节点出现单个资源用尽而其他资源大量剩余的可能.尤其是在集群资源整体饱和的情况下,CWT 算法的资源失衡度比LRA 策略整体下降18%,比BRA 策略整体下降7.7%,这说明CWT 算法在集群资源饱和的情况下可有效的调节集群资源平衡度.
2)CPU、内存资源利用率
图3和图4反映了在Pod 应用数量为7 200 时,CWT 算法、LRP 策略和BRA 策略下各个节点的CPU和内存资源利用率的情况.在BRA 策略下,CPU 资源利用率和内存资源利用率好于CWT 算法,且远远好于LRP 策略,这是由于BRA 策略会选取CPU和内存资源使用率最接近的节点进行部署.而在LRP策略下,有3 个节点CPU 资源已经饱和,1 个节点的内存资源已经饱和,饱和率达到6.7%,这意味着这4 个节点上所有Pod 应用的处在资源受到限制的环境,严重影响了集群的整体健康.在CWT 算法下,CPU和内存的资源利用率波动比BRA 策略稍微大一些,这是由于CWT 算法综合考虑了5 种资源指标,相较于BRA策略只考虑CPU和内存两种资源指标,CWT 算法则考虑的更加全面,更加能适应实际生产环境的需求.

图2 集群资源失衡度变化
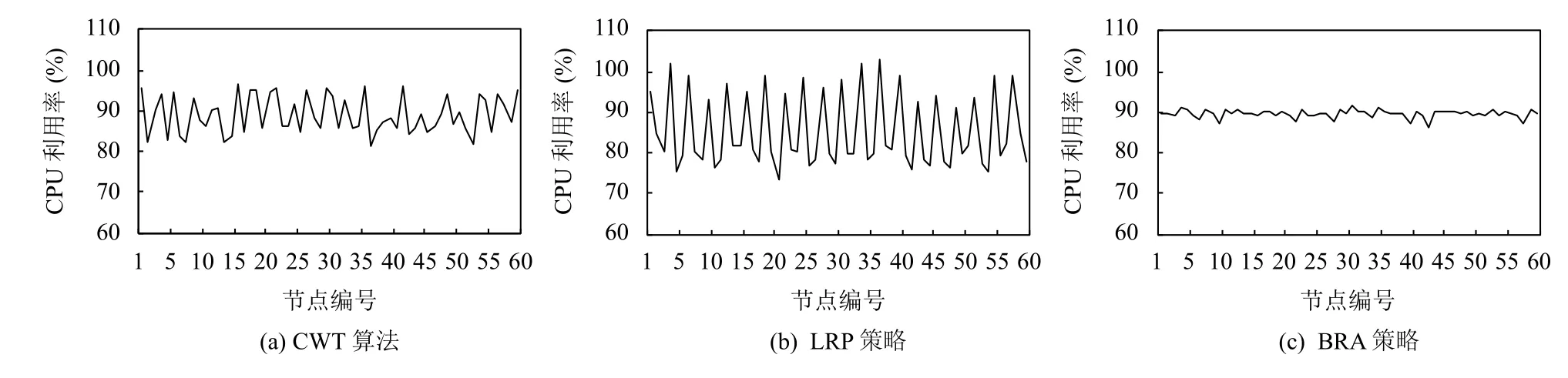
图3 不同策略下的CPU 利用率

图4 不同策略下的内存利用率
3)带宽、IO 速率资源利用率
图5和图6反映了在Pod 应用数量为7 200 时,CWT 算法、LRP 策略和BRA 策略下各个节点的带宽和IO 速率资源利用率的情况.由于LRP 策略与BRA策略只考虑CPU和内存,未考虑带宽和IO 速率等因素,随着Pod 应用数量增加,在这两种策略下资源失衡度上升,集群中部分节点出现资源倾斜,尤其是带宽和IO 资源利用率,很明显可以看出集群中节点之间利用率波动较大.

图5 不同策略下的带宽利用率

图6 不同策略下的IO 利用率
在LRP 策略下,带宽利用率最大的节点与利用率最小的节点相差48%,IO 资源利用率最大的节点与利用率最小的节点相差24%,而在BRA 策略带宽利用率最大的节点与利用率最小的节点相差47%,IO 资源利用率最大的节点与利用率最小的节点相差41%,甚至有多个节点的带宽和IO 资源利用率已超过100%,这说明这些节点的带宽和IO 资源已经完全饱和,LRP 策略下饱和率达到25%,BRA 策略下饱和度达到18.3%.若是带宽和IO 速率敏感型的Pod 应用被部署在这些带宽和IO 资源饱和的节点上,会带来网络和IO 读写的拥堵.
在CWT 算法下,全部节点的带宽和IO 资源利用率都在75%到95%的区间内震荡,没有出现带宽资源利用率超过100%的情况,相较于LRP 策略和BRA 策略,CWT 算法更加保障了集群的带宽稳定.
5 结论与展望
本文针对Kubernetes 默认调度算法仅考虑CPU、内存两种资源指标,且对需求各异的Pod 应用采用相同权重的调度策略进行了改进,通过增加带宽、磁盘、IO 速率3 项指标,结合层次分析法与熵权法得到每个资源指标的组合权重,并应用到TOPSIS 多属性决策方法中,为Pod 应用选择合适的节点进行部署,有效提高了集群整体的资源平衡度,避免了集群中节点上单个资源耗尽而其他资源尚有剩余的情况,通过实验验证,证明了组合权重TOPSIS 调度算法的有效性和合理性.下一阶段将考虑集群的动态调度与多租户情况相结合,使得集群资源调度更加高效,集群资源更加平衡,集群资源利用率更高.
猜你喜欢
农业工程学报(2022年11期)2022-08-22
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
智能制造(2020年11期)2020-02-08
妇女生活(2018年7期)2018-07-14
证券市场红周刊(2018年3期)2018-05-14
智富时代(2018年1期)2018-03-26
智富时代(2018年1期)2018-03-26
环球时报(2017-06-27)2017-06-27
知识就是力量(2017年2期)2017-01-21
