
基于图卷积多标签学习的复合人脸表情识别①
2022-02-15 06:41武中华
计算机系统应用 2022年1期
武中华
(江苏大学 计算机科学与通信工程学院,镇江 212013)
在现实生活中,人脸表情是仅次于语气之后必不可少的情感交流手段[1].人脸表情识别能让计算机有效表达人类的情感信息,是人工智能领域中的重要组成部分.人脸表情识别是将人脸表情图像识别为不同的表情类型,如愤怒、高兴、悲伤、惊讶、厌恶和恐惧等等[2].近年来,随着人工智能研究领域的不断发展,人脸表情识别也因其重要性而受到广泛关注.
目前,人脸表情识别方法划分为3 个主要步骤,分别是预处理,人脸表情特征提取和人脸表情分类.在人脸表情特征提取中,根据特征提取方式不同分为手工特征和学习型特征,前者是通过手工设计的算法进行提取,后者是通过深度学习模型进行提取.对于手工特征,可以进一步分为基于纹理的特征,如局部二值模式(local binary pattern,LBP)、Gabor 小波变换;基于几何的特征,如尺度不变特征变换(scale-invariant feature transform,SIFT)和基于多种手工特征得到的混合特征.而大多数学习型特征都是基于神经网络自动进行学习[3,4],如卷积神经网络(convolutional neural network,CNN),深度神经网络(deep neural network,DNN),循环神经网络(recurrent neural network,RNN)和生成对抗网络(generative adversarial network,GAN).人脸表情分类的方法则有支持向量机(support vector machine,SVM)、隐马尔科夫模型(hidden Markov model,HMM)、K 最近邻算法(K-nearest neighbor,KNN)和混合分类器模型等等[5,6].
传统的人脸表情识别仅限于识别6 种基本人脸表情,即愤怒、高兴、悲伤、惊讶、厌恶和恐惧.然而,现实生活中人类情感变化非常复杂,表现出来的人脸表情类别大大高于早期定义的6 种基本表情[7].复合人脸表情的提出为人脸表情识别开辟了一个新的领域,可以将计算机视觉和人工智能的研究提高到一个新的高度.复合人脸表情通常是来自于没有任何控制条件下的真实场景,而大部分公开的自然环境下的人脸表情数据集只包含基本表情,而少数包含复合人脸表情的数据集也缺乏足够的训练数据.近年来,有一些基于复合人脸表情识别的研究,Benitez-Quiroz 等人[8]提出了利用检测表情中的面部运动单元(action unit,AU)来识别复合人脸表情,然而此方法需要显著提升表情中AU的检测性能才能有效识别复合人脸表情.Li 等人[9]改进了基础的深度卷积神经网络(deep convolutional neural network,DCNN)提出一种新的模型(deep locality-preserving CNN,DLP-CNN)来进行复合人脸表情识别,该方法大大增强了识别能力.但是,复合人脸表情数据集训练样本的不足,人工标注费时费力,因此,目前的研究还是主要集中在基本人脸表情的识别.
单标签学习中,每个样本只属于一个标签且标签之间两两互斥,而在多标签学习中,一个样本可以对应多个标签,且各个标签之间通常具有一定的联系[10].在现实生活中,数据的复杂性导致单标签学习已经无法满足研究方法的要求,因为真实的对象往往具有多义性,所以多标签学习逐渐得到了广泛的关注.运用面部动作编码系统(facial action coding system,FACS)[7]对所有人脸表情中出现的人脸面部运动单元(AU)进行研究发现,复合人脸表情一般是由两种基本人脸表情组合而成的,如惊喜(happily surprised),其是由高兴(happily)和惊讶(surprised)两个基本表情组合而成,所以复合人脸表情识别可以视为一个多标签分类问题.
现实世界中的诸多问题都是用图的形式来表示,近年来,由于图卷积网络能够解决图的卷积问题得到了巨大的发展[11,12].Wang 等人[13]利用图卷积进行零样本图像识别时,考虑到可见类别和不可见类别之间的关系,转移从可见类别中学习到的知识来描述不可见类别,大幅度提高了零样本识别的性能.Chen 等人[14]通过构建知识图来捕获标签间的依赖关系,将图卷积应用在多标签图像识别上,也取得了巨大的成功.Zhang等人[15]利用上下文信息来构建情感关系图,再利用图卷积网络来学习情感关系以推理情绪状态,获得不错的效果.Li 等人[16]在人脸面部单元识别中,先利用先验知识构造了AU 关系图,再使用GGNN 在图上进行信息传播来得到AU的特征,最后进行AU 识别.表明了人脸面部单元识别中使用图神经网络的有效性.
我们将复合人脸表情识别视为多标签分类问题,通过复合人脸表情类别之间的联系来构建人脸表情类别关系知识图,为了更好的获得表情之间的关系,我们提出了一种基于图卷积网络多标签学习的复合人脸表情识别方(graph convolution network in multi-label learning for compound facial expression recognition,GCN-ML-CFER),来更好的实现对复合人脸表情的识别.
1 基于图卷积多标签学习的复合人脸表情识别
图1所示为整体的网络结构,基于图卷积多标签学习的复合人脸表情识别模型(GCN-ML-CFER)主要分为3 个部分:1)以VGG19 网络模型为骨架,再利用提供的人脸面部关键点来对感兴趣区域(region of interest,ROI)[16,17]进行学习,最后提取人脸表情的特征.2)通过面部动作编码系统(FACS)对所有人脸表情中出现的人脸面部运动单元(AU)进行分析,得到人脸表情类别之间的关系.再通过数据驱动的方式,挖掘人脸表情类别的标签在数据集中的共现模式,使用条件概率的形式对标签的依赖性关系进行建模,得到人脸表情类别关系图,图卷积网络作用在关系图上进行分类器学习.3)通过提取的人脸表情特征与学习到的分类器进行复合人脸表情预测.

图1 GCN-ML-CFER 模型框架
1.1 人脸表情特征提取模块
面部动作编码系统(FACS)根据人脸解剖学的特点用人脸面部运动单元(AU)的变化来描绘不同的表情这种描述方式几乎可以表现所有的面部表情,是目前标准的表情划分参照体系.人脸表情的发生是基于人脸面部运动单元(AU)的变化,所以为了获得更加显著的人脸表情特征,我们利用提供的人脸面部关键点来对感兴趣区域进行特征提取,这种全局和局部特征的结合,可以很好的表示人脸的表情.
我们选择VGG19 作为我们的骨架网络,如图1(a)所示,通过VGG19 我们可以得到人脸面部表情的全局特征图F.接着我们根据提供的5 个人脸面部关键点置,缩放映射到全局特征图的关键点位置,以此位置为中心,划分出感兴趣区域,使用ROI 网络来对这5 个感兴趣区域进行特征提取,从而得到局部的人脸表情特征.
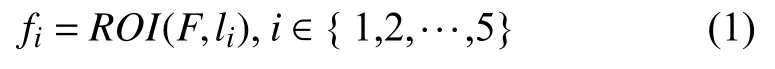
其中,l为提供的人脸面部关键点,ROI为区域特征提取网络,f为从感兴趣区域提取到的特征.将连接起来的全局和局部特征作为我们从人脸表情图像中提取得到的表情特征.

其中,g为特征连接,X为最后的维度为600的人脸表情特征.
1.2 表情类别知识图构造
考虑到复合表情之间具有一定的相关性,捕获和利用这些相关性可以提升复合表情的分类性能.拓扑结构的图拥有对于复杂系统的强表现力,同时具有很强的推理能力,因此将人脸表情类别之间的关系构造成图的形式,可以很好的进行复合人脸表情识别.
我们用V来表示图中节点的集合,具体来说,每种基本表情类别分别对应图的一个节点,即v∈V,图中的每个节点表示为标签的词嵌入.词嵌入是一种将文本中的词转表示数字向量的方法,向量中的每一个维度可视为对应特定的语义信息,在词嵌入空间中,语义相关和相近的概念词向量也彼此接近.
图中节点间的关系我们用边E来表示,如惊喜(happily surprised)这个复合表情,它在图中体现为高兴(happily)代表的节点和惊讶(surprised)代表的节点通过边来进行连接.根据面部动作编码系统(FACS)和复合表情的标签,我们初步可以得到哪些基本表情之间是有关系的,也就是图中哪些节点是通过边相连的.同时,我们再通过数据驱动的方式来进一步表示图中节点间关系的强度,即通过挖掘数据集中不同复合表情的数量,来对图中相连节点之间关系进行调整.
我们以条件概率的形式对节点间关系的强度进行建模.即P(Lj|Li),它表示的是出现标签Li时出现标签Lj的概率,需要注意的是,P(Lj|Li) 不等于P(Li|Lj).
复合表情可以视为基本表情的标签对.首先我们对训练集中的所有复合表情进行计数,得到矩阵M∈RC×C,其中,C为基本表情的个数,Mij表示基本表情标签Li和Lj一同出现的次数,也就是,这两个基本表情组成的复合表情出现的次数.
再利用Pij=Mij/Ni得到条件概率矩阵P∈RC×C,其中Ni表示基本表情标签Li在数据集中出现的次数,Pij=P(Lj|Li).
在图卷积后,节点的特征为节点自身特征与相邻节点特征的加权和,对于图卷积可能导致的过渡平滑问题,即节点特征可能变得相似,以至于不同类别的节点可能变的难以区分,为了缓解这个问题,我们对条件概率矩阵进行一定的改进,首先对于可能出现的噪声边通过阈值t来进行限制.

接着,在更新节点特征时,有一个固定的权重对节点本身的特征,而相邻节点的特征由其分布决定,最后邻接矩阵A表示为:
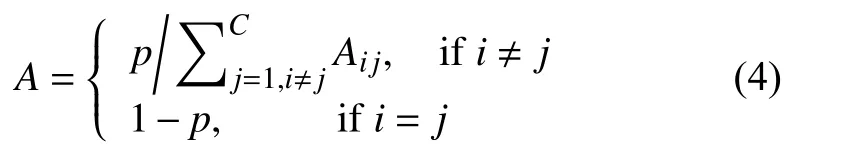
其中,A是邻接矩阵,而p是分配给节点本身和其相邻节点的权重,当p趋近于1 时,节点本身的特征将不会着重考虑,主要使用其相邻节点的特征.当p趋近于0 时,其相邻节点的特征将不会着重考虑,主要考虑节点本身的特征.
1.3 图卷积模块的分类器学习
图卷积在学习过程中能够融合图结构信息,可以将来自相邻节点的有效信息集成到节点自身当中,因此,我们使用图卷积从表情类别知识图中学习表情类别分类器,如图1(b)和图1(c)所示.给定的图是一个具有C个节点且每个节点的特征维度为d,从而得到图的特征矩阵H0 ∈RC×d.其中节点的初始特征为相对应表情标签的词向量表示.表情类别知识图用邻接矩阵A∈RC×C表示.我们采用简单的传播规则进行图卷积.
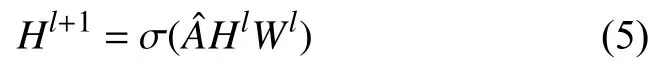
其中,σ为ReLU 激活函数,是对邻接矩阵A进行归一化后的矩阵,Hl是第l层的节点特征表示,首层的节点特征表示为H(0),通过图卷积将图的节点特征矩阵更新为Hl+1 ∈RC×d′,可以通过多层的图卷积来学习和建模节点间复杂的关系,Wl是第l层待学习的权重参数,最后通过图卷积后的输出为Z∈RC×D,D与人脸表情特征X的维度相同.
Z∈RC×D
经过图卷积模块得到的就是我们学习到的分类器,将其应用到人脸表情特征上,就可以得到表情类别预测的分数:

人脸表情图像的标签为y∈RC,其中yi={0,1} 表示人脸表情类别标签i是否出现在图像中.整个网络用传统的多标签分类损失进行训练:
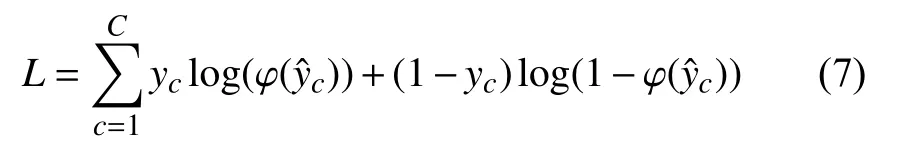
其中,φ是S igmoid 函数.
2 基于图卷积多标签学习的复合人脸表情识别方法
本文在2 个数据集上进行复合人脸表情识别实验.
RAF-DB[9].是目前最大公开可用的真实情感人脸数据集,它拥有15 339 张7 种基本表情图像和3 954 张11种复合人脸表情图像.本文使用11 种复合人脸表情,采用数据集提供的3 162 张训练集图像和792 张测试图像.
EmotioNet[8].是自然环境下大型人脸表情数据集,它拥有2 478 张带有人脸表情标签的图像,由于我们工作集中在复合人脸表情识别上,同时选择有明确基本表情组成的复合人脸表情类别,最后我们从中获取了1220 张复合人脸表情图像,其中训练集图像为980 个,测试集图像为240 个.
在实验设置方面,首先,我们采用4 层图卷积网络,每层维度为350,400,500,600.表情类别知识图构造中,我们选择的是300 维度的GloVe[18]词向量作为每个节点的初始化,图中边的构造中,我们的参数设置为p=0.3,t=0.2.在人脸表情特征提取模块,我们采用LeakyReLU=0.2 激活函数,预训练的VGG19为主干网络,在训练过程中,输入人脸表情图像大小归一化到为100×100,最后得到的图像特征维度为600,与最后图卷积后的节点维度一致.采用SGD 优化算法,momentum为0.9,学习率初始化设置为0.01,每30 个epoch 学习率衰减10 倍.整个网络构建使用的是Python 3.6,CUDA10.2,PyTorch 1.3.1.
2.1 特征提取模型选择
为了选择合适的特征提取模型,在RAF-DB 这个数据集上,对几个目前流行的深度学习模型的识别准确率进行了对比,即baseDCNN[9],ResNet18,ResNet34,ResNet50,ResNet101[19]和VGG19[20].其中,baseDCNN是RAF-DB 数据库中基准方法DLP-CNN的特征提取模型,DLP-CNN 能够提高对学习到的特征的识别能力,可以比拟于其它最优的方法.所有的模型都是用RAF-DB的训练集数据进行训练,在测试集上进行测试,结果如表1所示,我们使用的模型除了baseDCNN外,其它都是经过ImageNet[21]预训练过后的模型.从表中可以看出,其它模型的识别率相对VGG19 来说,VGG19的结果最好,因此,后续的试验以VGG19 作为选择的特征提取模型.

表1 不同模型的识别准确率比较 (%)
2.2 卷积层数的选择
我们展现了不同卷积层数对模型识别率的影响,对于3 层图卷积网络,输出的维度分别是,400,500,600,对于4 层图卷积,输出维度为350,450,550,600,对于5 层图卷积,输出维度为350,400,450,500,600.通过图2中的结果展示,随着图卷积数目的增加,复合表情识别率先上升后下降,在使用4 层图卷积的情形下识别率最高.可能的原因是,在使用更多的图卷积层时,节点之间的多次传播导致了过平滑,使得节点间的区分性降低,导致识别率的降低,而我们为了缓解过平滑,在知识图的构造过程中,设置了t来限制节点之间边的连接,设置p来分配给节点本身和其相邻节点的权重,一定程度缓解了使用更多的图卷积层而出现的过平滑,所以才会出现随着图卷积层数的变化,复合表情识别率也出现了先上升后下降的变化,而且变化幅度不大.

图2 两个数据集下不同GCN 层数的准确率
2.3 不同词向量选择的影响
在表情类别知识图构造中,运用词向量来对图中节点进行初始化,我们调查了几个不同的词向量表示,包括GloVe,GoogleNew[22]和FastText[23]3 个词向量表示.图3展示了这3 种词向量对实验结果的影响,对比于其它的词向量,GloVe 词向量下模型的识别率相对较高.我们发现,3 种不同的词向量下实验结果差别不是很大,表明我们模型的识别率受词向量的影响较小.同时运用更加合理准确的词向量能够得到更好的结果,原因可能是从丰富语料中学习到的词向量包含了丰富的语义信息,我们的模型能够利用这种有效的语义信息来提升对复合人脸表情识别的准确率.

图3 两个数据集下不同词向量的准确率
2.4 t 取值分析
在表情类别知识图构造中,邻接矩阵中的t是一个阈值,来决定图中两个节点是否进行连接.t∈{0,0.1,0.2,···,0.9,1},其结果如图4所示.我们发现,当t取值为0 时,表示所有的节点进行连接,随着t值的增加,减少了一些干扰的边,使得识别的准确率不断的增加,然而,当太多的边删减之后,节点之间的关系不能很好的学习到,导致准确在不断的下降.我们从图中发现在RAF-DB 数据集中,t=0.2 时,复合表情的识别率最好,而在EmotioNet 数据集中,t=0.4 时,复合表情的识别率最好.出现此类情况的原因可能是,不同的数据集所拥有的的复合表情的数目不同,而根据数据驱动而构造的知识图也因此受到影响,导致不同数据集下合适的t值是不同的.

图4 两个数据集下不同t 值的准确率
2.5 p 取值分析
在表情类别知识图构造中,邻接矩阵中的p是分配给节点本身和其相邻节点的权重.为了发现不同p值构造的知识图对复合表情识别的影响,我们应用p∈{0,0.1,0.2,···,0.9,1},结果如图5所示,我们能发现当p=0.3时,它能取得最好的结果.如果p值太小,图中节点不能从邻接节点中学习到有效的信息,如果p值太大,它将不会保持自身的特征,导致出现过平滑现象.

图5 两个数据集下不同p 值的准确率
2.6 ROI 网络的影响
我们根据RAF-DB 数据集提供的5 个人脸面部关键点位置,划分出感兴趣区域,使用ROI 网络来对这5 个感兴趣区域进行特征提取,将得到的局部的人脸表情特征和全局人脸特征进行结合得到最后的人脸表情特征.为了验证ROI 网络的有效性,我们从模型中移除ROI 网络,直接进行复合人脸表情识别,我们将缺失了ROI 网络的模型称为GCN-ML-CFER-ROI.由于EmotioNet 数据集中没有提供准确的人脸面部关键点位置,所在RAF-DB 数据集中进行比较.对比结果如表2所示.我们发现,在RAF-DB 数据集中,ROI 网络的使用提升了复合人脸表情的识别率,提升了大约1.3%左右,原因很可能是通过ROI 网络,我们提取到了更有效的人脸表情特征,从而使得整个模型的复合人脸表情准确率得到了提升.

表2 RAF-DB 数据集中ROI 网络影响下的准确率 (%)
2.7 与其它方法比较
实验与目前的主流研究方法作对比.表1给出了对比方法的准确率结果.表1中的对比方法是在单标签学习基础上进行的,复合人脸表情图像对应复合人脸表情类别,即一张人脸表情图像对应一个标签.表3中是我们提出的基于图卷积多标签的复合人脸表情识别模型GCN-ML-CFER的准确率结果.从表3中可以明显看出多标签学习下对复合人脸表情识别的准确率明显高于单标签学习下的准确率.
表3给出了在多标签学习中,我们模型在不同主干网络下的准确率结果,从中可以看出:将我们模型的提取人脸表情特征的主干网络替换,整个模型的复合人脸表情识别率都高于对应的原先的模型.其中提升效果最好的为VGG19 方法,相较于单独使用预训练过后的VGG19 模型,在RAF-DB 数据集中识别效果高出了4.92%,在EmotioNet 数据集中高出了4.16%,实现了在这两个数据集下最好的识别效果,证明了图卷积模块可以获取表情类别之间的关系,来更好的辅助复合人脸表情识别.
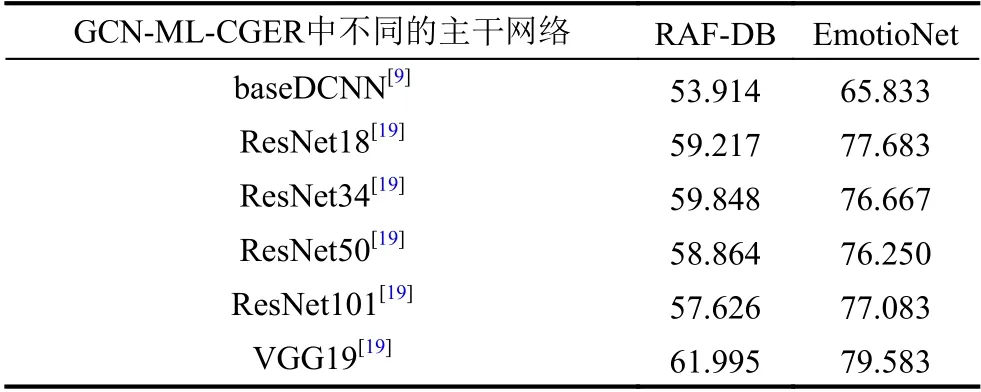
表3 模型在不同主干网络下的准确率比较结果 (%)
图6给出了我们模型在两个数据集上最好识别率下的混淆矩阵.在RAF-DB 数据集下的混淆矩阵中发现,fearfully angry和fearfully surprised复合表情的识别率较高,而sadly angry和sadly surprised复合表情的识别率较低.在EmotioNet 数据集下的混下矩阵中,fearfully surprised和happily disgusted的识别率较高,而angrily disgusted和sadly angry的识别率较低.可能原因一方面在于,数据集中复合表情的样本数目不平衡所致,数据集中复合表情的样本数目越多,学习到的对应的表情特征越准确,另一方面,构成复合表情的基本表情一起出现的概率越高,图卷积通过语义空间学习的表情类别分类器越准确,最后有效的提升相应复合表情的识别率.
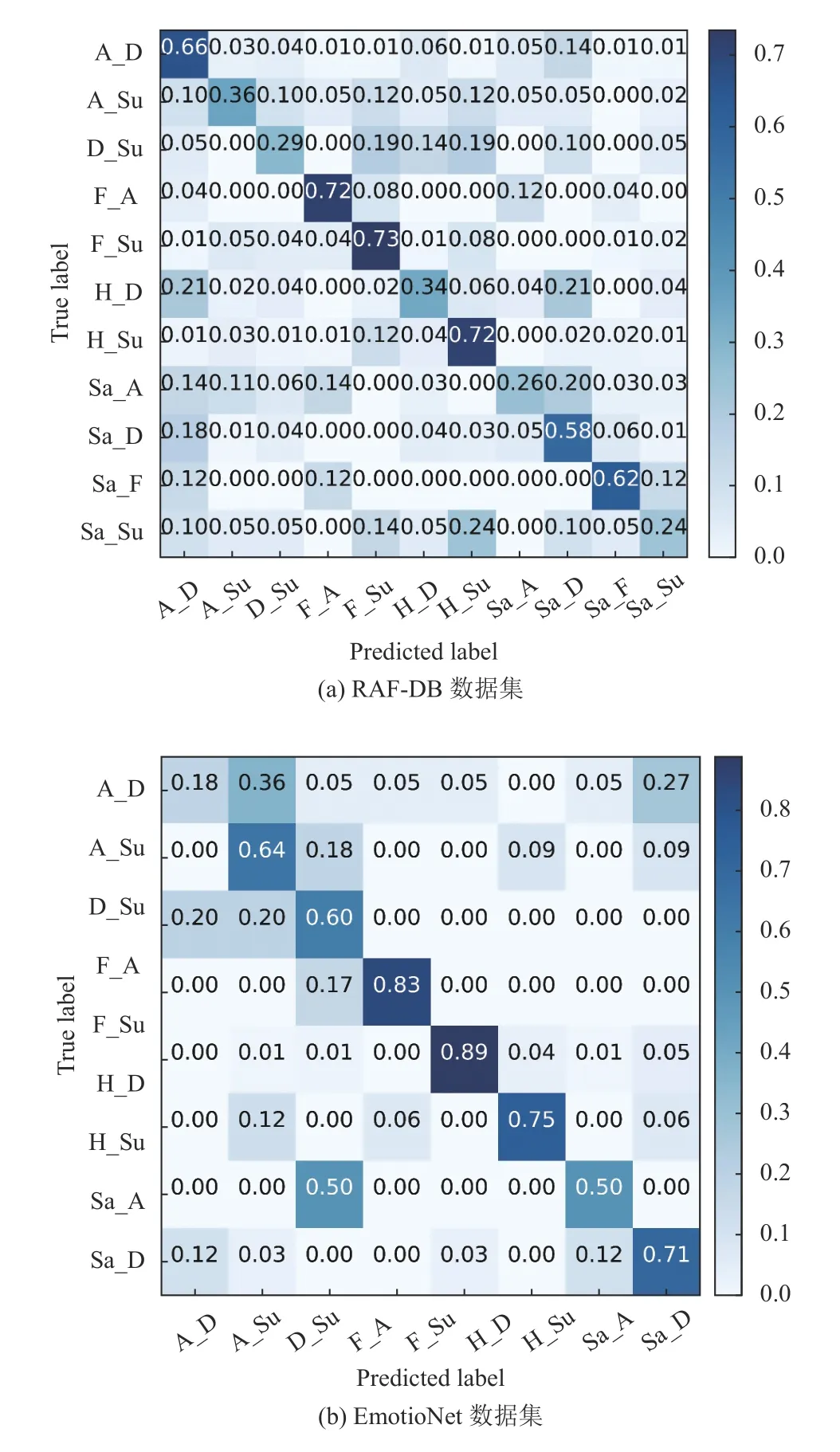
图6 GCN-ML-CFER 模型在两个数据集下的混淆矩阵
3 总结与展望
对于复合人脸表情识别,本文提出了一种基于图卷积多标签学习的复合人脸表情识别方法.针对表情类别之间的关联性,本文将基本表情类别作为图中的节点,利用先验知识和数据驱动方法,构建了表情类别知识图,再通过图卷积网络来有效提取知识图中的关系信息,以提高复合人脸表情识别的性能.在RAF-DB和EmotioNet 这两个数据集上进行了大量实验,实验结果表明:所提出的方法在复合人脸表情识别上达到了很好的效果.由于本文主要是对复合人脸表情进行识别,对所有表情混合进行识别没有深入考虑,同时,图中节点特征的初始化使用的是词向量,需要进一步研究是否有更合适的方式,从而更加有效的提升人脸表情识别的准确率.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
奥秘(2021年5期)2021-06-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小雪花·初中高分作文(2017年9期)2018-05-21
中国新通信(2017年9期)2017-05-27
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
