
基于机器学习组合模型的电商商品销量预测①
2022-02-15 06:41韩亚娟
计算机系统应用 2022年1期
韩亚娟,高 欣
(上海大学 管理学院,上海 200444)
销量预测是企业供应链的各个层次中必不可少的环节[1].近年来,电子商务以及电商物流在互联网时代背景下蓬勃发展,使交付周期缩短、客户期望增加.电商企业为了赢得持续竞争优势,在有限资源下,销量预测变得更加重要[2].与此同时,电商企业也能从消费者行为中获得大量数据,数据成为企业未来发展的核心竞争力,海量的数据对于企业来说是其独特的优势和资源[3].如何有效地利用数据、精确地对销量进行预测,成为了电商企业关注的焦点.随着大数据和机器学习的快速发展,合适的算法技术,将为企业建立预测方案提供关键的技术支持.
许多学者专家在销量预测方面做了系统的研究.在传统的销量预测方法中,大多采用了如线性模型、指数平滑等统计方法.如陈日进[4]在销售预测中比较了指数平滑与时间序列分解法,指出指数平滑法受季节性、周期性制约.Papacharalampous 等人[5]评估了各种统计方法在时间序列的可预测性,并在性能上做了比较,体现出这些方法在需求基本稳定市场中的良好表现.但是这种情况并不适用于现在的预测,因为需求还依赖于除时间外的其他因素,而这些因素并不能有效地用过去的需求量来表示.例如,Uber 或滴滴出行等按需乘车服务不能仅依靠时间序列来估计其需求,它们必须考虑其他因素,如天气条件(湿度、温度等)、一天中的时间段或一周中的某一天[6].而传统的统计预测方法通过外推历史趋势和季节波动来预测未来,所以它们通常很难利用对需求产生重大影响的特征进行预测[1].
因此,包括机器学习和深度神经网络在内的人工智能的新方法因其增强预测性能和建模非线性模式的能力而受到关注[7].由于深度神经网络在机器视觉、自然语言处理等方面的良好表现,人们开始将其运用于销量预测.如WaveNet[8]、长短期记忆人工神经网络(long short-term memory,LSTM)[9]等.虽然与传统的预测方法相比,深度神经网络有更好的预测表现,但是其预测结果的可解释行较差.所以预测的结果所能带给企业的实际价值是有限的.与之相对的是,一些学者在研究中展现了随机森林(random forest,RF)杰出的可解释性水平、良好的精度和适当的计算时间[10,11].随机森林也被视为预测性分析约定俗成的工具,因为它让管理者了解模型背后的原因,并了解其如何影响最终的结果.此外,运用迭代与梯度提升思想的梯度提升树(gradient boosting decision tree,GBDT)算法在生产与服务性需求预测中表现出比一般模型更好的性能与稳定性[12].在基于梯度提升的基础上,极限梯度提升(extreme gradient boosting,XGBoost)算法在工业实践中有着优秀的准确性,在销售预测的研究中验证了其良好的精度[13].
在输出预测模型的过程中,学术研究人员和商业实践者经常遇到一个重要问题:是选择合适的建模方法进行预测,还是将这些不同的方法组合成一个单一的预测模型? Lean 等人对候选模型的选择策略与组合策略做了研究,结果发现组合模型的预测效果一般优于个体预测模型,且非线性组合的预测精度会优于线性组合模型[14].因此,为进一步优化预测的结果,本文将着眼于电商商品的特点,分析影响电商商品的特征因素,从而构建新的特征集,使用RF、GBDT、XGBoost算法建立组合预测模型,对电商商品销量进行预测.
1 相关理论
1.1 RF
RF是一种基于决策树的回归模型学习算法[15].每棵树使用随机选择的特征子集来生长,然后计算在每个树的最后一个节点处获得的预测的平均值,弥补了单个决策树所表现出的偏差低但方差非常大的不足,是一种强大而且不复杂的算法.
1.2 GBDT
GBDT是一种由迭代思想而来的决策树算法[16],通过集成基学习器,即CART 回归树形成强学习器来预测结果.对于一个包含n个样本的数据集D={(xi,yi)}(|D|=n,xi∈R,yi∈R),算法具体步骤如下:
(1)初始化学习器:

其中,初始常数C一般设置为样本真实值均值,L(·)为所选择的损失函数.
(2)迭代模型,其中迭代次数m=1,2,···,M:
1)对于每一个样本i=1,2,···,n,计算负梯度,即残差rim:
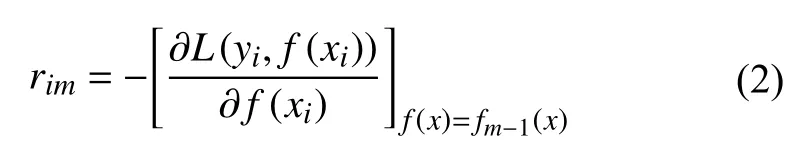
2)将得到的残差更新为样本真实值,并将数据(xi,rim) 作为第m棵树的训练数据,其对应的叶子节点为Rjm,j=1,2,···,J.J为回归树的叶子节点数.
3)对叶子区域j=1,2,···,J计算最优的拟合值:

4)更新强学习器:

其中,I为指示函数,当x∈Rjm时值为1,否则为0.
(3)得到最终的强学习器预测值为:

1.3 XGBoost
XGBoost是由陈天奇等人提出的集成提升树学习模型[17].它高效地实现了GBDT,并进行了算法和工程上的许多改进,已经在大量的数据挖掘竞赛中被广泛地认可,具有高效、灵活且鲁棒性强等优点.对于一个包含n个 样本的数据集D={(xi,yi)}(|D|=n,xi∈R,yi∈R),算法具体步骤如下:
(1)定义目标函数,由损失函数与正则项两部分组成:
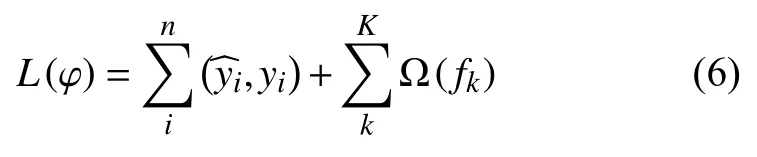
正则项部分如式(7)所示:
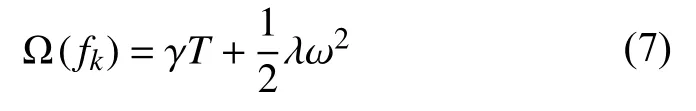
其中,K表示共有K棵树,fk表示第k棵树模型,T表示每棵树的叶子结点数量,ω 表示每棵树的叶子结点的权重值,γ和λ为系数,需要在训练中进行调参.
(2)模型策略,与GBDT 相同,目标函数的求解也是基于迭代思想,对于第t次迭代:
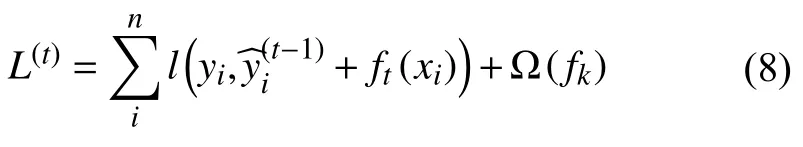
利用泰勒公式对式(8)进行展开,得到:

2 基于组合算法的电商商品销售预测模型
2.1 预测模型框架
本文旨在建立一个销售预测模型来预测一段时期的电商销量.为此,将用组合机器学习模型对电商商品的数据进行建模和预测.总体的研究框架如图1所示,主要包括两个部分:数据集处理和组合预测模型构建.

图1 预测流程图
第1 部分:数据集处理.对原始数据进行缺失值和异常值的数据预处理以及重新对样本组织与特征构建的过程.
第2 部分:组合预测模型构建.对处理过的数据集分别用RF、GBDT、XGBoost 模型训练后,组合基础模型的预测结果,并在此基础上利用各个商品的补少补多成本对组合预测的结果赋权,得到最后的预测输出.
2.2 数据集处理
数据集处理的目的是挖掘有效的特征.预测结果的上限由数据和特征所决定,而模型和算法只能不断逼近这个上限.当算法难以突破瓶颈时,优秀的组合特征通常可以达到良好的预测效果.在本节中,将对数据集进行预处理,并构建新的模型特征集.
2.2.1 数据来源及预测特点介绍
阿里巴巴旗下电商拥有海量的买家和卖家交易场景下的数据.本文研究的数据集来源于天池平台,由全国仓数据、区域仓数据和商品成本数据组成.数据集的基本信息如下:
(1)全国仓数据:包含了从2014.10.10–2015.12.27共442 天963 种商品的210 549 条销售数据.其中,商品的分类特征有4 个,如类目ID、品牌ID 等,商品的用户行为特征有25 个,如浏览人数、加购物车人数、成交人数等,以及日期、商品ID、仓库CODE 特征,一共32 维特征.
(2)区域仓数据:和全国仓没有本质区别,涵盖了从2014.10.10–2015.12.27的相同963 种商品的864 772条区域仓的销售数据.
(3)商品成本数据:记录每个商品在全国和区域仓的缺货和库存管理成本,即商品的补少成本a和补多成本b,用于计算总成本.
电商零售的所有工作都是让正确的产品在正确的时间正确的地点满足正确的消费者.而在多年的电商平台实践中得知,商品销量受众多主客观因素影响.总的来说,电商销量预测问题有以下的特点:
(1)快速变化的用户需求.消费者需求会随着地点、时间、特殊事件、个人偏好等各种各样因素而改变,有时一个热点就会导致商品销量的激增或暴跌.这就产生了高度非平稳的销量时间序列.
(2)集中库存.为了针对消费者需求的快速变化,品牌电商平台会建设或租赁大型仓库对各类商品集中库存以提供对不确定性的缓冲,这使电商销量预测一般具有固定的时间周期.
(3)成千上万的产品.不同消费者的消费偏好是不同的,为了尽可能满足所有用户需求,大型电商平台会在各种垂直品类间部署不同类型的大量商品,就产生了成千上万的时间序列.
2.2.2 数据预处理
此数据集经过了脱敏处理,和商品的实际销售量、成交金额等有一些差距,但是对整体的数据特性没有影响.但由于数据来源于真实场景,原始数据的完整性、稳定性等有所缺失,会对模型性能造成一定的影响,为此,需要对数据进行预处理以匹配模型的需求.
(1)缺失值处理
有些商品信息在数据收集的过程中,由于商品的预售或团购等活动,存在一段时间内只有商品的用户行为特征而没有销量信息的情况.此外,后台日志记录的缺失也造成部分商品没有用户行为特征的现象.鉴于不同类型商品的销售周期、用户行为偏好都各不相同,本文统一对缺失值进行补“0”处理,既保证了数据的完整性,也符合电商商品的实际情况.
(2)异常值处理
图2展示了所有商品销量按天进行统计的结果.
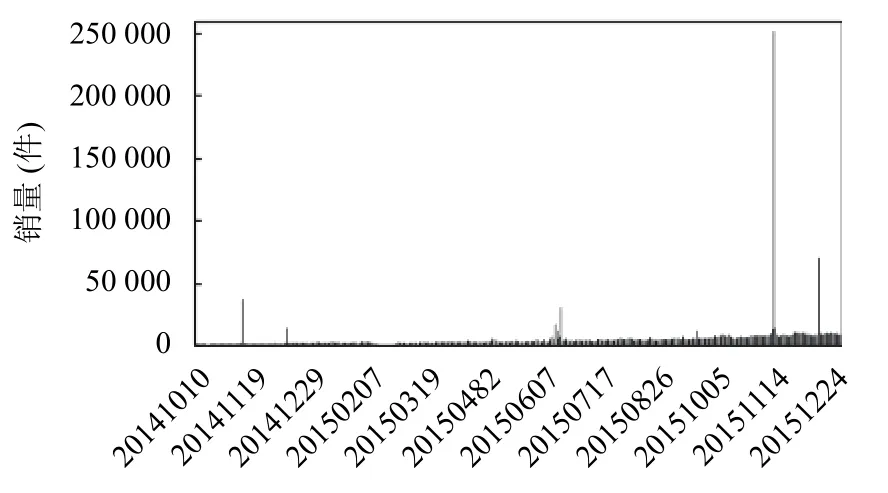
图2 销量直方图
(1)本数据集的商品销量在该时间序列内较为平稳,没有表现出明显的季节性和周期性波动.可以理解为本数据集所选取的商品具有全面性,销量在时间维度上的变化互相抵消并呈现总体上升的趋势.
(2)商品销量具有若干突出的局部峰值,这种表现在2015.11.11 尤为明显.结合店商品台的活动可知,峰值出现的日期均为平台促销活动“618”“双11”“双12”当天.因此本文将这几日的数据识别为异常值并予以删除.
2.2.3 样本组织与特征工程
目前,商品销量预测周期多以周销量为最小预测单元[18,19],考虑到电商商品的需求量大、物流过程复杂等特点,本文以两周作为一个预测单元重新对原始数据进行样本组织,并在此基础上构建新特征集和标签.
时间滑窗法能消除数据噪音并扩展训练集[20].如图3所示,样本重组织是利用了时间滑窗的方法,以两周为一个滑窗单元,在原始时间序列上按时间逆序进行滑动窗口操作.
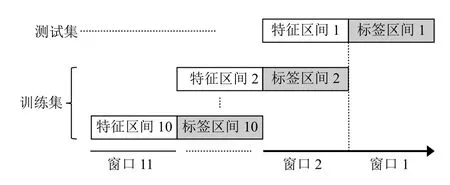
图3 时间滑窗法
由于数据的预测价值会随着离最终预测时间距离的增大而衰减[19],本文将全国仓和区域仓数据合并,进行了11 次前向滑窗,加和每个窗口后两周内各个商品的非聚划算支付件数,即总销量作为标签,使用窗口1,2 内数据作为测试集,其余为训练集.
商家信誉、商品性价比与商品历史数据在较大程度影响了商品的销量[21,22].结合以上因素,本文特征集的构建方法如下:统计窗口前N=1,2,3,5,7,9,11,14 天内25 维用户行为数据的总和与平均值为用户行为特征;以商品分类特征做聚合,统计各类特征的销量平均值、总和、标准差为商品分类特征;统计窗口内的部分转化率为商品比率特征.在利用时间滑窗法数据集处理并进行样本组织和特征构建后.共产生11 个时间窗口,424 维特征,46 938 条数据.新特征集结果如表1所示.

表1 商品特征表
2.3 构建组合销售预测模型
考虑到实际销量的影响因素较多,本文在原始数据的基础上扩展特征集,从而使新数据集获得了更多可以被算法学习的信息.如果采用单一模型预测,可能面临精度下降或是过拟合的风险.Dietterich 指出,模型结合可能会从统计、计算和表示3 个方面带来好处[23].因此,本文利用不同算法的结构差异构建组合销售预测模型,在提升精度的同时减少单个模型过拟合的风险.具体的步骤如下.
步骤1.基础模型训练.将重新构建样本与特征后的训练集,分别用随机森林、GBDT、XGBoost 模型训练,输入测试集特征集进行预测,得到每个基础模型的预测值,如式(10)所示.

步骤2.组合预测.对于电商平台来说,商品销量预测结果与实际销量差异直接决定了使用补少还是补多成本计算成本,而不同商品的补少补多成本不同.因此,本文将补少补多成本加入销量预测模型建模.
基于每个商品的补多补少成本,本文提出一种成本厌恶偏向性组合预测方法,具体如下:对于每一个商品,若该商品的补少成本ai小于补多成本bi,说明预测结果比真实值大时会承担更多的成本风险,则将3 个模型中的最小预测值做作为组合预测结果,使模型有预测少的偏向性;反之,则将3 个模型中最大值作为预测结果,使模型有预测多的偏向性,如式(11)所示.
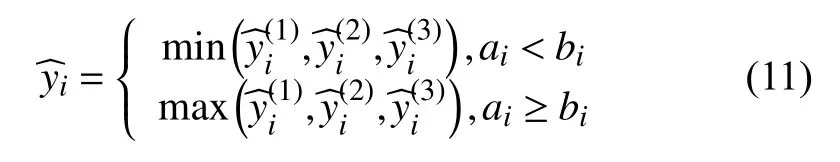
步骤3.预测赋权.在组合预测的基础上,为了进一步提升预测结果对成本厌恶偏向性,本文对每个样本进行赋权.如图4所示,由于Sigmoid 函数有着良好的单调递增等性质,常被用作神经网络的激活函数.

图4 Sigmoid 函数
本文以式(12)的Sigmoid 函数为基础构建赋权函数.在定义域大于0 时,该函数取值范围为(0.5,1).由第2.2.2 节的分析可知,商品整体销量较为平稳,故赋予样本的权重值不应过大,在式(12)基础上加0.5 构建赋权函数,如式(13)所示.显然,补少补多成本间较大与较小的比值始终大于1,由此计算出的权重值域为(S(1)+0.5,1.5),即约 (1.23,1.5),满足权重值的稳定性要求.

步骤4.在计算出每个样本的权重值后,对式(11)中成本厌恶偏向性组合预测结果进行赋值,最终的预测结果如式(14)所示.
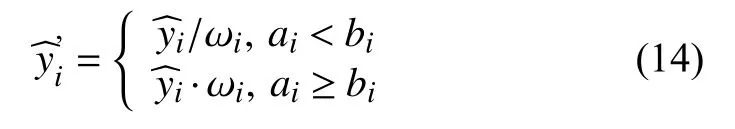
3 结果分析
3.1 评价指标
误差度量通过将预测值与实际值进行比较来度量模型的质量.一般地,对于预测问题,有均方误差、平均绝对误差等指标.
由于原始数据中给出了每个商品的补多成本ai,补少成本bi,因此本文选用预测的总成本作为评价指标,与传统指标无本质差别,且使结果更直观具有实际价值.
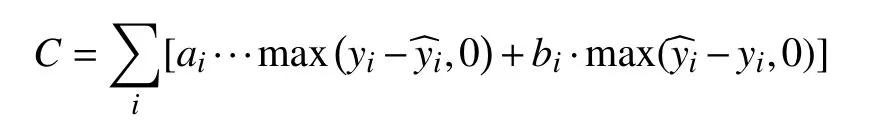
3.2 结果分析
为了评价组合模型的预测能力,本文使用了RF、GBDT、XGBoost 三个基础模型,加入特征工程的模型,以及组合预测模型对实验数据进行预测,使用总成本作为评价指标,结果如表2所示.

表2 各模型下的预测总成本
由表2可知:
(1)特征工程能提升预测准确性.加入特征工程后的模型与基础模型相比,总成本都有所下降.说明2.2 节中的特征构建流程从原始数据中增加了有效特征,并帮助提升了模型准确性.
(2)组合预测模型有较好的预测准确性.加入特征工程后的组合模型预测为127.43 万元,相比于加入特征工程后的基础模型约下降了42–52 万元.其中,式(13)的预测赋权贡献了约22 万元的成本下降,式(11)的组合方法贡献了20–30 万元的成本下降.这展现了组合模型相较于基础模型的优越性和预测赋权方法的有效性.
4 结语
为了更准确预测电商商品的销量,本文提出了基于机器学习的组合预测模型.通过数据的预处理重新组织样本,从用户行为、商品分类和商品比率3 个方面构建了424 维新特征集,并有效地使用了商品成本数据,在本文提出的成本厌恶偏向性组合模型的基础上对预测结果赋权,得到最终的预测结果.该方法在实现了对平台数据的精细化运用的基础上,降低了总体仓储成本,对电商平台提前了解商品销量情况,合理制定库存水平有着重要的意义.
猜你喜欢
今日农业(2022年13期)2022-11-10
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
汽车与安全(2021年5期)2021-09-03
汽车与安全(2019年2期)2019-06-11
中学生数理化·高一版(2017年2期)2017-04-25
汽车生活(2017年1期)2017-03-16
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
