
基于可信预测值的协同过滤推荐算法
2022-02-18 04:00于程远袁徽鹏
江西师范大学学报(自然科学版) 2022年6期
邓 泓,吴 祎,于程远*,袁徽鹏
(1.江西农业大学软件学院,江西 南昌 330045;2.江西农业大学计算机与信息工程学院,江西 南昌 330049)
0 引言
随着信息化的快速发展,爆炸式增长的数据容易造成信息过载和信息迷失等问题,因此在海量数据中挖掘出用户感兴趣的内容逐渐成为热门的研究方向.一方面,用户利用分类目录和搜索引擎的方式主动寻找需要的信息;另一方面,通过分析用户信息并运用一定技术挖掘出用户潜在的感兴趣内容,再将该兴趣内容推荐给用户,即为推荐算法[1].
推荐算法自提出以来就受到了广泛关注,研究者将推荐算法分为基于内容推荐、基于协同过滤推荐和混合推荐[2],其中协同过滤算法根据用户的历史相关信息,挖掘用户的偏好并进行推荐,再细分为基于记忆和基于模型的方法[3].
基于模型的方法运用数据挖掘和机器学习方法训练模型,通过训练后的模型计算用户对项目的评分,以此作为预测评分.常见的模型方法有矩阵分解、聚类[4]和神经网络.
基于记忆的方法利用用户对项目的评分信息计算相似度,再通过相似集合预测未评分项目的潜在评分.根据集合种类分为基于项目和基于用户的协同过滤,本文主要研究基于用户的方法,该方法假设具有共同行为的相似用户之间非共同行为也具有相似性,根据相似度寻找相似用户集合,为目标用户推荐相似用户偏好的项目.基于记忆的协同过滤方法因具有易实现、跨领域性和可解释性等特点,而成为推荐系统的主要研究方法,但同时该方法也存在冷启动、精度低、稀疏性和扩展性等问题,其中精度低是常见的问题之一.在推荐系统中,精度问题是指因评分数据稀疏、用户概貌注入攻击等而导致推荐过程产生误差,从而准确度降低的问题.该问题可以通过挖掘用户或项目潜在关系、融合附加信息的方式来缓解,从而提高推荐精度.提高推荐精度具体表现在对协同过滤过程的优化,包括优化计算相似度、优化寻找最近邻和优化预测评分值等.
计算相似性是在推荐算法中的关键步骤[5],用户相似度用于选择邻居集合并作为权重因子应用在预测计算中,因此优化相似度是提高精度的核心方法,也是学者研究的重点.
L. Candillier等[6]将杰卡德相似度作为权重,与皮尔逊相似度进行乘积融合得到加权相似度(WPCC),实验结果表明运用融合相似度能够显著提高准确度.S. Manochandar等[7]引入改进的接近-影响-流行度相似度(MPIP)方法,对接近度、影响力、流行度的权重进行归一化.S. Bag等[8]应用评分值改进杰卡德系数,并结合均方差提出了相关杰卡德均值平方偏差(RJMSD)度量方法.Jin Qibing等[9]设计了一种联合局部和全局的相似度算法(CLAG),使用离散化的奇异性作为局部相似度,融合共同评分和用户评分习惯作为全局相似度.Jiang Shan等[10]采用次一拟范数相似度度量方法(SOQN),运用0~1间的小数作为范数值,充分利用评分值并弱化用户间的差异性,实验结果表明新方法具有更好的性能.Cai Wei等[11]提出倒数最近邻算法(RNN),考虑用户邻居的对称性,提高互为邻居用户的相似度.孙晓寒等[12]利用评分值将用户评分项目集划分为不同的项目子空间,综合子空间的评分支持度得到用户相似度(RRS).滕少华等[13]运用混合模型改进相似度,提出了一种混合用户多兴趣推荐算法.
在计算相似度后,一般运用KNN(k-nearest neighbor)方法设置最近邻,即选择相似度最高的k个用户作为最邻居集合,但是这种选取邻居的方式具有片面性,在k个邻居中可能存在邻居相似度不高或相似度计算不准确的情况,导致对推荐结果的准确性产生负面影响,为了解决该问题,可以考虑加入阈值或可信度等其他因素优化选取最近邻过程.
C. Kaleli[14]考虑用户评分的不确定性,设计了一种基于熵的邻居选择方法(EUCF),该方法计算用户评级分布的信息熵和皮尔逊相似度,将最近邻选择作为在固定熵差容量下最大化相似度的0-1背包问题.Zhang Ziyang等[15]设计2层邻居选择方案,首先根据相似度和共同项目数进行第1层邻居选择,再利用融合时间的动态信任选取第2层邻居用户.Li Zepeng等[16]提出快速邻居搜索方法(FUNS),将用户评分项目分为3个项目子空间,根据共同评级项目和邻居传递在子空间中选择近邻用户,结合子空间并集作为邻居集合.贾东艳等[17]设计双重邻居选取策略,从目标项目评分的用户中选取相似度大于平均相似度的用户为兴趣相似用户,将兴趣用户的预测准确率作为信任度,取信任度最高用户为邻居用户.
为提高算法精度,除了在计算相似度、选取邻域集中挖掘用户和项目的潜在关系,也能够在评分预测中引入附加信息,进而提高预测值的准确度.
Chen Yicheng等[18]运用多重时间衰减函数捕捉用户的偏好变化,将衰减值与评分值融合计算衰减预测值,并结合加权基线估计得到最终预测值.S. Manochandar等[7]组合基于用户和基于项目的预测值,并考虑目标用户和目标项目的评分偏差.孔麟等[19]引入用户间交互信息的信任度,运用自适应模型计算相似度和信任度的加权平均值.
此外,基于模型的方法具有准确性和拓展性的优势,在训练不同模型中充分利用有效信息也能够提高预测准确度.Feng Chenjiao等[20]提出了一种新型融合概率矩阵分解方法,在矩阵分解中结合多因素相似度和评分矩阵,实验结果表明该融合方法能有效地提高预测精度.Pan Yiteng等[21]对评分和信任数据进行训练,设计了一种相关去噪自动编码器模型,将用户分为评分者、信任者和受托人,并在隐藏层中结合具有多个角色的用户特征.N.A. Noulapeu等[22]将矩阵分解与神经网络相结合,利用双重正则化矩阵分解提取用户和项目潜在因子,并在多层感知机中融合潜在因子,以缓解在矩阵分解中线性点积的限制,提高推荐质量.
针对在推荐算法中的精度问题,在基于记忆的协同过滤中主要考虑对计算相似度、选择邻居和预测评分过程进行优化,以提高推荐结果的准确度,但在协同过滤方法产生的推荐中,仅根据预测值大小进行排名推荐,未考虑评分值的可信度.因此,本文对推荐产生这一过程进行优化,在产生推荐中引入评分结果的可信度,提出了一种基于可信预测值的协同过滤算法(RPCF),根据在邻居集合中对推荐项目评级的邻居数确定可信度,与预测评分值融合构成可信预测值,采用可信预测值进行推荐.
本文的主要贡献如下:
1)考虑预测值的可信度,引入可信预测值的概念,提出基于可信预测值的协同过滤算法.
2)将本文提出的算法与其他提高精度算法进行实验比较,实验结果表明RPCF方法提高预测质量和算法鲁棒性.
3)为评估RPCF方法的其他性能,衡量了该方法的其他指标,如多样性和可拓展性.
1 基于可信预测值的协同过滤框架
1.1 计算相似度
常用的相似度方法有余弦相似度、修正余弦相似度和皮尔逊相似度,本文采用余弦相似度计算用户相似度.
用户对项目不同的评分构成了用户评分向量,评分向量越接近则2个用户越相似,运用评分向量的余弦值表示用户相似度,其计算公式为
其中Ru,i、Rv,i分别表示用户u、v对项目i的真实评分,Iu、Iv分别为用户u、v的评分项目集,Iuv为用户u、v的共同评分项目集.
1.2 寻找最近邻
在计算用户相似度后,选取相似值最高的用户集合作为最近邻集合,用Un表示.设置最近邻用户数为K,即K=|Un|.
1.3 预测评分
在用户的最近邻集合中,根据最近邻用户的评级项目与相似值的加权计算用户对未评分项目的预测评分值,并对相似度进行归一化,预测值计算公式为
(1)
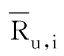
1.4 产生推荐
传统的协同过滤方法在计算预测评分之后,根据预测评分值最高的项目产生推荐,但未考虑预测值的可信度.对于仅有1个最近邻用户评分过的项目,即N=1的情况,设该项目为i1,评分过项目i1的邻居用户为v1,则目标用户对项目i1的评分值为
此时对项目i1的预测评分值为邻居用户v1对项目i1的评分值,若该值为4或5,则按传统方法根据预测评分值最大的项目进行推荐,项目i1极大概率地会推荐给目标用户.在这种情况下,仅根据单个邻居用户的较大评分就能够产生推荐,推荐结果的可信度较低,受邻居用户影响较大,导致推荐准确度降低.
因此,本文提出基于可信度的协同过滤方法,不直接使用传统方法的预测值进行推荐,而是在预测评分和产生推荐过程中考虑预测值的可信度r,根据融合可信度的预测值产生推荐列表.其中r与N相关,对目标项目评价的最近邻居数越多,即N越大,对该项目计算预测值的可信度越高,N越小,其可信度越低.因而设置r的值是与N呈正相关的函数,利用softsign函数计算可信度,计算公式为
r=(N+x)/(1+(N+x)),
(2)
其中x为参数,可信度r取值为(0,1).将考虑可信度的预测值称为可信预测值,其计算公式为
2 实验设计与分析
2.1 数据集
实验数据集采用MovieLens 1M电影评分数据集,包括6 040个用户对3 706个项目的1 000 209个评分值,数据集的稀疏度为95.53%,每次实验随机划分训练集和测试集,其中训练集占70%,测试集占30%.
2.2 评价指标
评价指标运用在预测准确度中的平均绝对误差(MA),MA衡量在测试集中真实值与预测值之间的偏差,其计算公式为

评价分类准确度指标采用精度(pr),精度是推荐结果列表中推荐正确项目的比值,其计算公式为
其中Utest表示在测试集中的用户集合,Ir为推荐的项目列表,Iu表示为测试集用户的评分项目集.
考虑推荐结果的多样性,本文也将覆盖率作为评价指标.覆盖率(cr)可定义为推荐项目数量在总项目数中的占比,其计算公式为

2.3 预测准确度比较和算法鲁棒性分析
为验证本文基于可信预测值推荐算法的有效性,采用WPCC[6]、NHSM[23]、MLCF[24]、JMSD[25]、RJMSD[8]、MPIP[7]、RNN[11]、SOQN[10]、CLAG[9]和RRS[12]作为对比方法,其中RNN运用余弦相似度方法计算相似度.在该节中讨论衡量算法的预测准确度,设置邻居用户数k从5增至50,步长为5,在式(2)中参数x设置为8,根据可信预测值最高的前10个项目产生推荐,比较不同邻居用户下的MA值,结果如图1所示.

图1 不同方法的MA值比较
由图1可知:RPCF算法的预测准确度有显著提高,如当k=50时,RPCF算法的平均绝对误差为0.542 1,次最优的RJMSD方法为0.878 9.对比其他方法,本文方法的MA值更小.
随着邻居的增加,对比方法的MA值呈先降后升的趋势,这是因为过多邻居选取存在相似度不高或计算不准确的问题.不同于其他方法,RPCF的MA值先降低后趋于稳定,这是因为该方法将对待推荐项目评分的邻居数作为可信度,使得更倾向于对多个邻居用户评级的项目进行推荐.这能够降低不准确邻居带来的影响,使推荐结果具有更强的鲁棒性,从而获得更好的预测质量.
从图1可以看出:当k≤15时,RPCF方法的MA值略低于RRS和MPIP方法;当k>15时,RPCF方法的MA值最小.在MovieLens 1M数据集中,比较图1中的其他方法,除RPCF方法外,准确度较高的方法有MPIP、MLCF和RJMSD.当k≤35时,3种方法中MPIP的MA值低于MLCF和RJMSD的MA值,预测精度更高;当k>35时,RJMSD平均绝对误差最小,其次是MLCF的平均绝对误差.对于增加相似值的MLCF和RNN方法,MLCF性能优于RNN.CLAG和RJACC在k<25时的平均绝对误差较低,随着邻居数的增加,MA大幅增加,这表明2种方法受邻居影响更大,导致准确度降低.此外,JMSD和NHSM的预测准确度大体相近.
2.4 分类准确度比较
为验证RPCF算法的分类准确度,采用精度作为衡量指标.精度与推荐项目数L和用户邻居数k相关,因此,设置L=10,k从5增至50;k=20,L从5增至40,进行2组精度实验对比,结果如图2和图3所示.
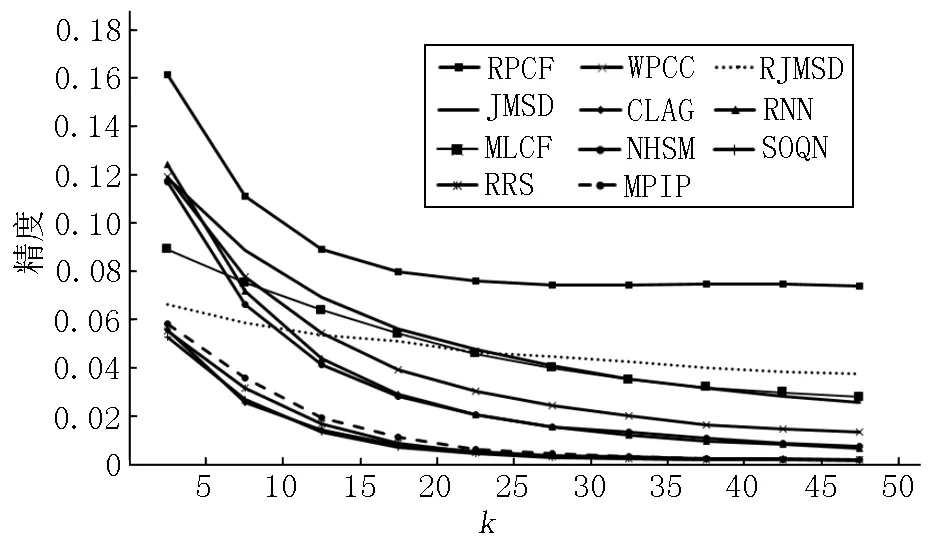
图2 不同邻居用户数的精度比较

图3 不同推荐项目数的精度比较
由图2可知:在不同的邻居用户中,RPCF的精度明显高于其他方法,比对比方法平均提高了0.034 7~0.077 4.除RPCF外,精度较高的方法有RJMSD、JMSD以及MLCF,当k<25时,JMSD精度最高,当k>25时,RJMSD精度最高.随着最近邻用户数的增加,推荐结果的精度逐渐下降,其原因是受不准确邻居的影响.而RPCF算法的精度在邻居数为25时逐渐平缓,趋于稳定.因为RPCF将邻居数N作为可信度对推荐列表进行优化,缓解了邻居选取不准确的影响,使推荐结果具有鲁棒性,提供了更好的推荐质量.
由图3可知:在不同的推荐项目数中,本文方法在大多数情况下获得了更高的精度.当L≤25时,RPCF精度最高,优于其他所有方法;当L>25时,RPCF略低于RJMSD和JMSD方法.如当L=30时,RPCF的精度值为0.043 64,JMSD和RJMSD的精度值分别为0.044 54和0.044 90,当N=5时RPCF的精度值为0.120 69,JMSD的精度值为0.06447,RJMSD的精度值为0.058 354.由于在测试数据集中可进行推荐的高质量项目数量有限,所以算法的推荐精度随着推荐项目数的增加呈下降趋势.如图3所示,在推荐项目数小于10时RPCF精度显著高于其他方法,这说明在MovieLens 1M数据集中RPCF方法能够快速准确地对高质量项目进行推荐.但是随着推荐项目数的进一步增加,RPCF的精度大幅下降,这是因为在数据集中可进行推荐的高质量项目数量大幅减少,使得RPCF算法对低质量项目进行推荐.当推荐项目数大于25时,RPCF算法的精度逐渐接近其他算法的精度.
因此,通过比较图2和图3的精度大小表明RPCF提供了显著更好的性能,进一步验证了本文算法的有效性和稳定性.
2.5 覆盖率比较
在该节中衡量RPCF算法推荐结果的多样性,将覆盖率作为评价指标,更改推荐项目数,参数与2.4节设置一致,比较各方法在不同推荐数下的覆盖率,结果如图4所示.

图4 不同推荐项目数的覆盖率比较
由图4可知:随着推荐项目数的增加,覆盖率也在不断增加,其中覆盖率较高的方法有RNN和MLCF.RPCF的覆盖率在L=10时高于SOQN、RRS和MPIP的覆盖率,随着推荐数的增加覆盖率逐渐超过JMSD、CLAG和NHSM的覆盖率,除此外RPCF方法的覆盖率低于其余方法的覆盖率.该方法将邻居数与预测值结合产生推荐列表,使得推荐结果趋于热门项目,因此覆盖率降低,推荐多样性较差.
2.6 拓展性分析
为评估本文算法的拓展性,选取2.3节准确度最高的4种优化相似度方法,即MPIP、RJMSD、MLCF和RRS,将其与RPCF融合,优化推荐项目列表,融合后的方法记为MPIP_RP、RJMSD_RP、MLCF_RP和RRS_RP.设置邻居用户数从5增至50,步长为5,比较这4种方法运用可信度优化前后的MA值,结果如图5所示.
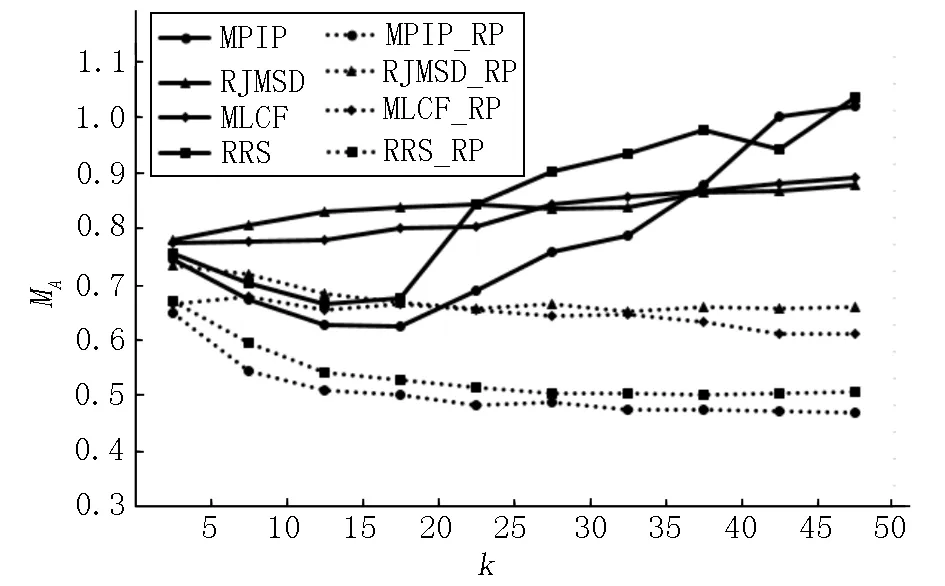
图5 不同方法融合RPCF的MA值比较
由图5可知:融合后的MPIP_RP、RJMSD_RP、MLCF_RP和RRS_RP准确度都高于MPIP、RJMSD、MLCF和RRS的准确度,MA各自降低了0.278 3、0.163 0、0.181 2和0.307 0,这说明RPCF算法具有一定的可拓展性,可考虑与其他优化方法结合.
2.7 与其他方法比较
在该节中将邻居选择方法作为对比方法,包括EUCF[14]、FUNS[16]和TBCF[26],其中EUCF方法的背包容量设置为0.01,FUNS利用AC_PCC计算相似度,TBCF选择余弦相似度,相似度阈值为0.34.将邻居选择方法与RPCF方法结合,记为EUCF_RP、FUNS_RP和TBCF_RP,比较不同方法的MA、精度和覆盖率,结果如表1所示.
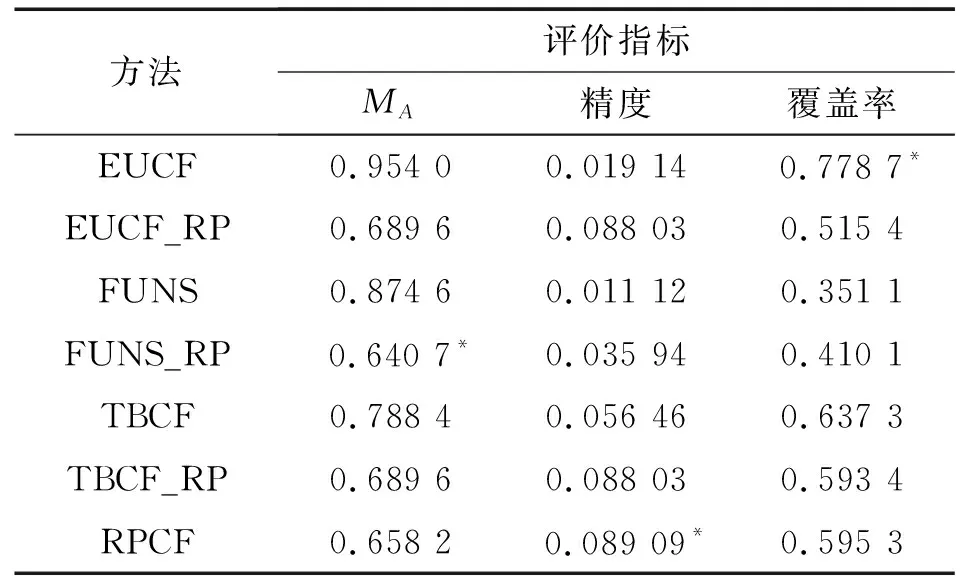
表1 不同方法的评价指标比较
由表1可以看出:本文提出的RPCF在预测准确度上优于3种邻居选择方法,但在覆盖率上却低于EUCF和TBCF方法.比较3种方法结合RPCF前后的评价指标,MA和精度都有大幅改善,FUNS_RP方法的覆盖率增加,这进一步表明本文算法的可拓展性.
3 结束语
针对在协同过滤算法中推荐精度较低、预测质量较差的问题,本文在产生推荐过程中进行优化,将对推荐项目评级的邻居数作为可信度,结合传统预测值,提出了基于可信预测值的协同过滤算法.通过MovieLens数据集的几组实验比较表明:本文提出的算法能够提高推荐系统的准确率和算法的鲁棒性,相比较其他提高精度方法具有更好的性能.
此外,本文算法利用用户邻居数量评估可信度,使推荐列表更倾向于多个邻居用户评级的项目.这虽然可以降低邻居选取不准确问题的影响,提高算法的鲁棒性和精度,但同时也让推荐结果趋于热门项目,导致算法缺少多样性和新颖性.可以考虑融入惩罚系数降低热门项目的影响,或将可信预测值与填充方法相结合,填充邻居用户的评分集.在未来的工作中,将研究算法的拓展性,设计综合本文方法与其他优化相似度方法,以进一步提高算法的精度,同时尝试分析融合其他因素作为可信度,以达到在提高准确度的同时增强结果的多样性.
猜你喜欢
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
电子产品世界(2021年6期)2021-02-10
建筑科技(2018年6期)2018-08-30
中国经济周刊(2018年5期)2018-02-01
中国经济周刊(2017年43期)2017-11-23
中国交通信息化(2016年5期)2016-06-06
天津冶金(2014年4期)2014-02-28
数据(2009年2期)2009-04-08
