
人体行为识别研究综述
2022-02-23 10:03裴利沈刘少博赵雪专
计算机与生活 2022年2期
裴利沈,刘少博+,赵雪专
1.河南财经政法大学 计算机与信息工程学院,郑州450046
2.郑州航空工业管理学院 智能工程学院,郑州450046
计算机视觉是由计算机科学和工程、信号处理、统计学和认知科学等多门学科交叉融合的一门综合性学科。人体行为识别是计算机视觉领域的一个热门话题,在机器人行为研究、智能人机交互、智能视频监控、仿真虚拟现实、智能安防、运动员辅助训练等方面具有很大的探索和应用价值,被国内外学者和研究人员广泛关注。
依据特征提取方式将行为识别划分为传统方式法和深度学习法。手工提取特征的传统方式法在大数据时代具有很大的局限性。卷积神经网络(convolutional neural network,CNN)在图像领域中的卓越表现,使得基于视频的行为研究看到希望。深度神经网络应用之后,弥补了一些传统方式的缺陷,在公共数据集上效果优异。
早期的静态数据集动作单一,场景简单,随着行为识别的发展,数据集趋近于真实生活场景,标签逐渐多样化,数据量也迅速增长。数据集的发展大致经历了最初的简单个体——复杂场景多个体——真实场景数据集——大型数据集——面向细粒度动作分析的层次化高质量数据集的过程,数据集的发展历程见证和加速着行为识别方式的发展。
在之前研究的基础上,本文对已有的主流人体行为识别方法进行归纳与对比,主要从传统方法、深度学习方法、数据集等方面进行介绍。首先,介绍了行为识别的研究背景,对行为识别简单概述。然后,按照发展历程重点介绍了传统方法和深度学习方法下的经典算法,阐述了识别算法的主要研究思路和改进之处,简单介绍了对受限玻尔兹曼机(restricted Boltzmann machines,RBM)和非局部神经网络(nonlocal neural networks)。其次,总结了常用数据集,对比与分析了主流的人体行为识别方法在不同数据集上的识别精度。最后,对全文进行总结,并对未来进行了预测与展望,期望方便初学者快速入门,激励研究者发现新问题与新思路。本文的突出特点是对比介绍,突出不同方式的优缺点,同时结合改进的研究方法,对行为识别算法进行新旧与经典的综合论述。
1 行为识别概述
人体行为识别的成功与否直接取决于特征提取的正确与否,特征处理以及分析理解都建立在特征提取的基础上。图1 对比了传统方法与深度学习方法下行为识别的流程。传统方式手工提取特征需要一定的相关知识,设计特征时耗费大量的人力物力;深度学习方法下,使用不同的深度特征提取网络,能够依据关注点不同适应特征变化。

图1 传统方法与深度学习方法流程对比Fig.1 Process comparison between traditional methods and deep learning methods
主流的传统方法有轮廓剪影(human silhouette)、时空兴趣点(space-time interest points)、人体关节点(human joint point)和运动轨迹(trajectories)。依照网络结构将基于深度学习行为识别划分为三大类:双流网络(two-stream network)、3D 卷积神经网络(3D convolution network)和混合网络(hybrid network)。同时,一些其他的研究思路,如基于骨架识别、受限玻尔兹曼机、非局部神经网络等也有良好的效果。
传统方法中的特征表示,可以使用整体表示方法与局部表示方法,两种方式各具特色,优缺点互补。整体表示方式主要包括轮廓剪影方式、背景剪除法等;局部表示主要包括时空兴趣点检测等。在考虑时空特征的深度学习行为识别算法中,双流网络代表性算法有Temporal Segments Networks、Temporal Relation Network、SlowFast Network等;3D 卷积神经网络代表性算法有C3D(convolutional 3D network)、P3D(pseudo-3D residual networks)等;混合网络代表性算法有CNN-LSTM(convolutional neural network-long short-term memory)、LRCN(long-term recurrent convolutional networks)、VideoLSTM等。行为识别的简单划分如图2 所示。

图2 行为识别分类Fig.2 Action recognition classification
2 基于传统方法的人体行为识别
传统行为识别方法的特点是利用手工设计特征对行为进行表征,利用统计学习的分类方法对行为进行分类识别。特征提取根据人类行为构成和表示方式的不同,可以细分为整体表示和局部表示方法。轮廓剪影方式通过构建各种描述符表达行为信息;时空兴趣点方式尝试突破二维,从三维角度强调时空域信息;人体关节点方式利用姿势估计推测关节点位置与运动信息;运动轨迹方式追踪动作轨迹。
2.1 整体特征表示
整体特征表示方法把视频帧认为一个整体,轮廓剪影、人体关节点等方式使用整体表示方法提取全局特征。提取特征时,需要对前景、噪声等进行处理。从背景中提取运动前景,一般使用背景剪除法、帧间差分、分流、人体轮廓剪影等方法,然后将获得的整个人体行为区域作为行为表征。对于噪声影响问题,可采用形态学等处理方法。
整体特征表达方法中,基于视频帧的信息描述方式有运动能量图(motion energy image,MEI)、运动历史图(motion history image,MHI)、运动网格特征矢量、运动历史体积模板(motion history volume,MHV)、形状上下文(shape context,SC)等方法。
传统方式中对于运动方式的描述至关重要。Bobick 等使用背景剪除法获取人体轮廓,并重叠轮廓特征获取图像帧的差别,从而设计出MEI 和MHI。MEI粗略描述运动的空间分布,MHI表示人体的运动方式,两者表示运动存在并且解释视频帧中人体的运动情况,可以简单阐述视频中的有效信息。此种方式的核心和基本思想是编码图像的相关运动信息。
时空体积(space-time volume,STV)表示是叠加给定序列的帧,但仍需背景剪除、对齐等。Yilmaz等使用STV 获取动作描述和动作草图,并且执行图形识别,结果表明已知运动情况阐述了潜在的运动情况。MHV、STV 等描述方式容易关注于重要区域,在一些简单背景中效果良好。
Matikainen 等经过研究,发现当背景逐渐复杂,出现遮挡、噪声等时候,轮廓特征提取变得愈发困难,其阐述了整体方法的局限性,难以解决遮盖变化、计算效率低、不能捕捉细节等问题,证明了整体方法并不是最优选择。
基于人体关节点的传统行为识别核心思想是对人体运动姿势进行捕捉,描绘出各姿势关节点的位置情况,以及同一关节点不同时间维度下的位置变化情况,从而推断出人体行为。
Fujiyoshi 等创造出经典的五关节星形图(四肢、头颅),从视频流中实时提取人体目标,将人体五关节与人体重心构成矢量,从骨架化线索中获取人类活动。使用自适应模型来应对背景改变,需要先对视频进行背景分离和预处理,最后进行运动分析。对于人体关节点特征进行提取时,需要实时目标提取,人力物力耗费较大,为了解决这一问题,可以使用深度相机、深度传感器等技术。
Yang 等利用RGBD 相机的3D 深度数据复刻3D 人体关节点进行动作识别,效果优于其他关节点特征提取识别算法。卷积神经应用后,人体关节点方式与深度学习方法进行有效结合,获得了高效高精度的识别效果。Zhang 等用OpenPose 提取关节向量的各种特征,使用最近邻(-nearest neighbor,NN)动作分类,验证深度特征算法的精进性。
基于人体关节点的方法通过关节点构建动作轮廓,在简单背景下对于大幅度动作识别效果较好,但是受限于人体关节遮挡、细粒度关节变化等问题,传统的人体关节点行为识别方式在真实场景下难以应用。
2.2 局部特征表示
局部特征表示方法将视频段落认为一个整体,在处理视角和遮挡变化等方面有更好的效果。时空兴趣点和运动轨迹使用局部表示方法获取特征。有多种局部特征描述符,如梯度直方图(histogram of oriented gradient,HOG)、运动边界直方图(motion of boundary history,MBH)、光流梯度直方图(histograms of oriented optical flow,HOF)等。
在时空域中提取时域和空域变化都明显的邻域点是时空兴趣点检测的核心,时空兴趣点检测是局部表示方法的一种典型例子,将行为信息使用兴趣点描述。时空兴趣点提取法本质是映射三维函数至一维空间,得到其局部极大值的点。此种方式相比于基于轮廓剪影方式,更适用于一些复杂背景。
Laptev不仅提出时空兴趣点,还将Harris 角点兴趣点探测器扩展至三维时空兴趣点探测器。Harris3D 检测的邻域块大小能够自适应时间和空间维度,使邻域像素值在时空域中有显著变化。
兴趣点提取的多少和稀疏情况,是使用基于时空兴趣点方法中的关键因素。Dollar等指出Laptev的方法存在短板,获取的稳定兴趣点过少,因此其团队在时空域上使用Gabor 滤波器和高斯滤波器,使得兴趣点数量过少情况得到适量改善。Wang 等提出使用稠密网格方式提取行为特征,并对于兴趣点的稀疏和密集问题做出详细论证。通常情况下,密集兴趣点效果更好,但是时空复杂度较高。Willems等使用Hessian 矩阵改善时空兴趣点方法,优先找出兴趣点所在位置,使得检索兴趣点时间复杂度大幅降低,缺点是兴趣点不够密集。
时空兴趣点不再过度依赖于背景,不需要对视频进行分割处理,因此在一些复杂的背景下识别效果比整体表示方式好,但是对于人体遮挡、兴趣点采样数量等要求较高。
运动轨迹利用光流场获取视频片段中的轨迹。基于运动轨迹的手工特征提取方法是通过追踪目标的密集采样的点获得运动轨迹,根据轨迹提取行为识别特征,分类器训练后,得到识别结果。
HOG 描述符可以展示静态的表面信息,MBH 描述符表示光流的梯度,HOF 描述符展示局部运动信息。相对于单一特征,Chen 等连接HOG、光流、重心、3D SIFT(3D scale invariant feature transform)等特征,能适应于更为复杂的场景,有更好的鲁棒性和适应性。Wang 等根据之前的对比研究发现,密集采样兴趣点比稀疏采样效果好,因此使用“密集轨迹”(dense trajectories)的方式。
基于运动轨迹的行为识别轨迹描述符可以保留运动的全面信息,关注点在于时空域变化下的目标运动,该方法的缺点也很明显,即相机运动的影响较大,HOF 记录绝对运动信息,包含相机运动轨迹,MBH 记录相对运动信息。Wang 等提出更为完善的密集轨迹方法(improved dense trajectories,IDT),通过轨迹的位移矢量来进行阈值处理,如果位移太小,则移除,只保留下来流场变化的信息,这样能够消解拍摄时运动的影响,使得HOF 和MBH 组合得到的结果进一步改善。优化后的密集轨迹算法可以适当抵消相机光流带来的影响,对轨迹增加平滑约束,获得了鲁棒性更强的轨迹。尽管IDT 已经有较好的识别效果,外界环境仍然会对其造成一定程度的影响,可以使用Fisher进行向量编码,训练比较耗时。
IDT 算法是传统手工特征提取所有方法中实际效果最理想、应用场景最多的算法。IDT 以其较好的可靠性和稳定性在深度学习应用之前广泛应用。卷积神经应用后,很多利用深度学习并结合IDT 算法进行行为识别的实验,呈现优异的效果。Li等用深度运动图进行卷积网络训练,利用密集轨迹描述运动信息,高效提取深度信息和纹理信息,能有效判别相似动作,减弱光照等影响,但是复杂度较高,识别速度较慢。表1 总结了基于传统方式的行为识别方法的对比。

表1 基于传统方法行为识别对比Table 1 Comparison of action recognition based on traditional methods
在传统人体行为识别算法中,行为特征提取依靠人工观察、手工表征。轮廓剪影方法能在简单背景中表现出良好的性能,但是灵活度低,对于遮挡、噪声等非常敏感;时空兴趣点方法不再对RGB 视频序列进行前景和后景裁剪,有丰富的兴趣点时识别效果更好,但是计算复杂度就相对提高,时间增长,对光线等敏感;人体关节点方法行为识别时不再要求高像素,但对于拍摄角度等敏感,不过由关节点发展而成的骨架,结合深度学习,在人体行为识别领域具有良好的发展势头,目前多数的电影电视特效团队拍摄时通过关节和骨架进行取样;运动轨迹方法是传统方式中信息保留较好、表征能力较强、识别效果最好的方法,但受到光流的影响。
总之,传统方法下,人体行为识别技术仍然受到物体之间的遮挡、噪声、环境的光照、相机移动、算法鲁棒性的影响。对于这些问题,有两个主要的解决途径:使用深度图像和寻找更好的描述符。
深度相机提供了改善部分问题的解决方式,但是深度图像不容易获得。微软新推出的3D 体感传感器Kinect,可以方便地获取深度和骨骼位置信息。研究人员设计的轮廓梯度方向直方图(contour-histogram of oriented gradient,CT-HOG)、边缘方向直方图特征(edge orientation histogram,EOH)、局部二值模式特征(local binary pattern,LBP)、梯度局部自相关特征(gradient local auto-correlation,GLAC)等尝试规避光照改变和物体之间遮挡等问题带来的不良影响。这些问题正在被逐步改善。
3 基于深度学习的人体行为识别
深度学习基于对数据进行表征学习,使用特征学习和分层特征提取的高效算法自动提取特征来代替人工获得特征。深度学习以其强大的学习能力、高适应性、可移植性等优点成为热门。双流网络关注时空域特征,识别准确度很高;3D 卷积网络强调连续帧之间的信息处理;结合多种网络架构的混合网络则侧重于优点结合。同时,还有一些学者从不同角度利用深度学习探索行为识别,如基于骨架的关节点识别方式、受限玻尔兹曼机、非局部神经网络等,也有不错的效果。基于双流网络的改进、对3D 卷积结构的修改和扩展、结合CNN 和LSTM 的混合网络,都是目前的研究热点。
3.1 双流网络结构
双流网络结构(two-stream)将卷积信息分为时域和空域两部分,两条网络流结构相同(CNN 和Softmax 组成)但互不干扰。从单帧RGB 图像中获取环境、物体等空间表面信息;从连续光流场中获取目标的运动信息,最终将双流的训练结果融合,得到识别结果。Two-stream 网络基本流程如图3 所示。

图3 双流结构框架Fig.3 Structure framework of two-stream
2014 年Simonyan 等在神经信息处理系统大会NIPS 上提出Two-stream 方法,分别考虑时空维度,设计思路巧妙。从流程的整个过程考虑,视频帧的分割、单帧RGB 处理、连续帧的选择与相关性描述、网络选择、双流融合方式、训练方式与规模等都可以选择不同的方案以达到更好的识别效果,也是后续双流网络完善的主要思路。
CNN 结构深度太浅,用于视频识别时模型的拟合能力受到影响,同时受限于训练的数据集规模较小,容易过拟合,导致训练效果并不是很好。卷积核尺寸、卷积步长、网络结构深度的改变产生了性能更好的VGGNet、GoogleNet 等网络结构,新的网络结构逐步替代CNN 网络。使用预训练、多GPU 并行训练等方式改善训练结果,减少内存消耗,识别效果有了很大的提升,但是会增大硬件要求,对于普适应用并不友好。
ConvNet 框架缺乏处理长时间结构的能力,一些解决办法计算开销较大,对于超长时间序列的视频,可能存在着重要信息丢失的风险。Wang和Xiong等基于分段和稀疏化思想提出时域分割网络(temporal segments networks,TSN),使用系数时间采样和视频级别监督,对长视频进行分段,随机选取短片段使用双流方法。针对数据样本量不足问题,应用交叉预训练、正则化和数据增强技术,降低了复杂性,同时消除相机运动带来的偏差影响,但比较耗时。
双流网络中的局部特征相似,容易导致识别失败,Zhou 等通过角落裁剪和多尺度结合对数据进行增强,利用残差块提取局部特征和全局特征,使用非局部CNN 提取视频级信息,表征能力更强。Wang等在卷积神经中加入高阶注意力模块,调整各部分权重,强化对局部细微变化的关注。
Feichtenhofer 等沿袭双流网络结构时,发现空间网络已然能完成大部分行为识别,时间网络并没有发挥很大的作用,于是研究将两个网络在特定卷积层进行融合,提出的时空融合架构框架如图4 所示。结果显示,在最后一个卷积层,将两个网络融合在空间流中,使用3D Conv 融合方式和3D Pooling 将其转化为时空流,保持双流持续运作,相对于截断时间流,减少了很多参数,进一步提高了识别率。对比传统的双流架构,仍增加了参数数量,加大了运算复杂度。
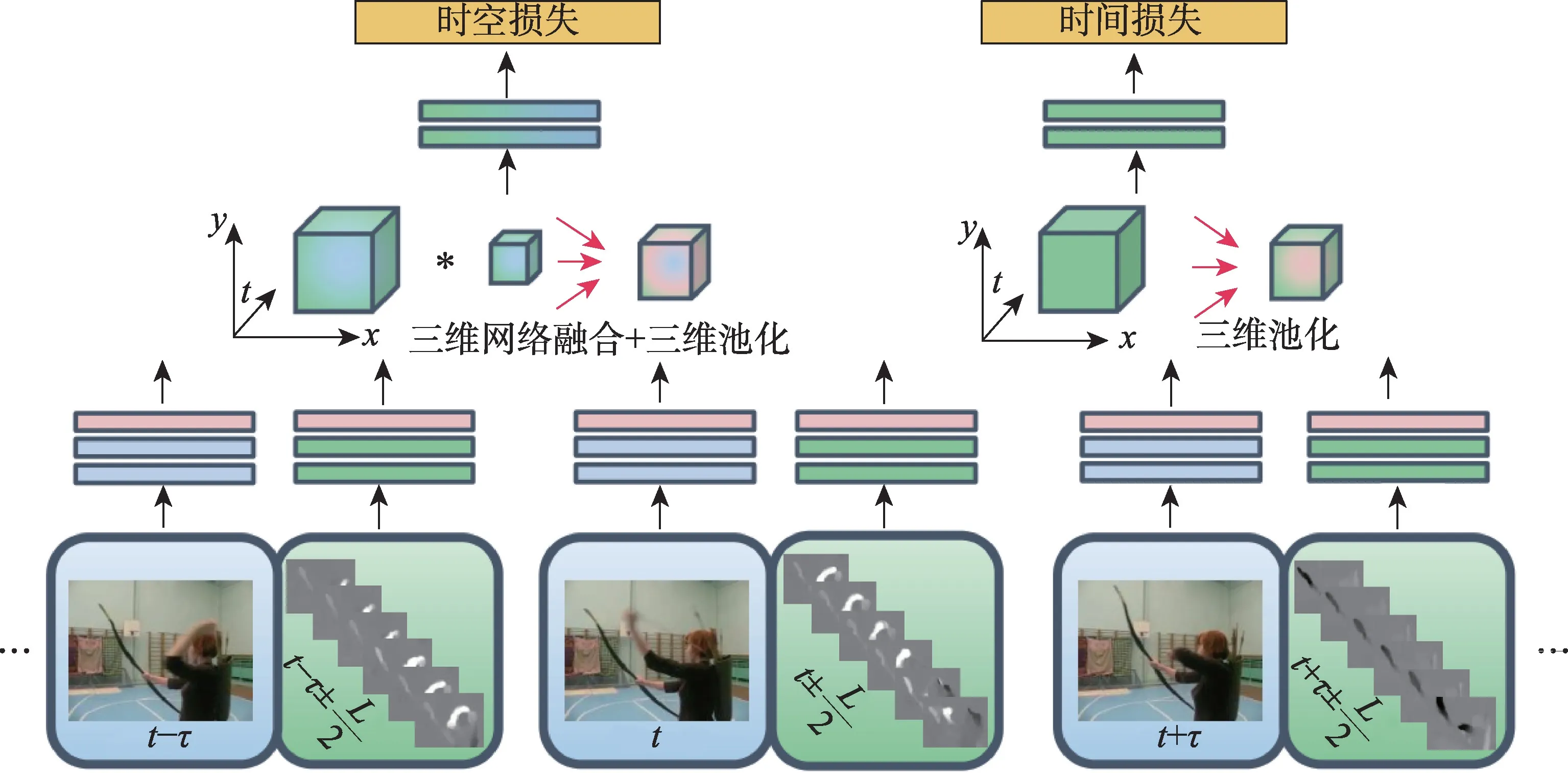
图4 时空融合架构框架Fig.4 Structure framework of spatiotemporal fusion
基础双流模型在时空交互性上的处理影响识别准确度。ResNets 具有更强的表征能力,残差结果对数据变动更为敏感,因此Feichtenhofer 等对双流网络和残差网络进行创造性的结合,提出时空残差网络模型(spatiotemporal residual networks,STResNet)。STResNet 通过残差连接进行数据交互,允许通过双流通道进行时空特性的分层学习。Pan 等提出了一种基于时空交互注意力模型的行为识别方法,在空域上设计空间注意力模型,计算帧的显著性位置,在时域上设计时间注意力模型,定位显著帧,更加关注于有效帧和帧的有效区。时空交互和注意力机制使得各种算法模型识别效果更好,但模型变得复杂难以避免,探索交互方式和高效使用是一个重要的研究方向。
由双流网络衍生出多种多流网络。Wang 等提出一种全局时空三流CNN 架构,传统的CNN 在时空域上基于局部信息进行动作识别,三流架构从单帧、光流和全局叠加运动特征中开展空间、局部时域和全局时域流分析。Bilen 等引入四流网络架构,训练RGB 和光流帧以及对应的动态图像,获得时序演变。多流网络相对于双流网络,加宽了网络模型,提高了卷积神经网络在特征提取上的充分性和有效性,但也增大了网络架构的复杂性。
以双流网络为基础的网络架构是学者研究的热点。改进网络的学习特征表示、多信息流的正确组合、针对过拟合问题的数据增强方案等都是研究人员对于双流网络改进的探索。双流网络以其强调时空特性而具有较好的准确度,但对于网络流的训练硬件要求高、速度慢、视频预处理等问题严重影响双流网络的实时应用。
3.2 3D 卷积神经网络结构
单帧RGB 的二维网络训练,容易导致连续视频帧间的运动关系被忽略,造成一些重要的视频信息丢失。Baccouche 等对卷积网络进行3D 扩展,增加时间维度,使其自动学习时间和空间特征,提升行为识别的准确度和鲁棒性。2D 卷积和3D 卷积区别如图5 所示。

图5 2D-CNN 与3D-CNN 对比Fig.5 Comparison of 2D-CNN and 3D-CNN
Ji等于2013 年提出基于3D 卷积神经网络的行为识别方式,在由叠加多个连续视频帧构成的立方体中运用3D 卷积核捕捉连续帧中的运动信息。3D卷积网络存在参数过多、数据量严重不足等问题。Sun 等将3D 卷积网络分解为2D 空间卷积和1D 时间卷积学习,提出空间时间分解卷积网络(factorized spatio-temporal convolutional networks,FCN),大大减少了参数量,但分解之后,也牺牲了一些表达能力。使用伪3D 卷积代替3D 卷积也具有不错的识别效果。
Tran 等认为基于RGB 的深层特征并不直接适合于视频序列,其团队尝试使用三维卷积实现大规模学习,通过改变3D 卷积网络中不同层的卷积核的时间深度来寻找最优的3D 卷积核尺寸,提出尺寸卷积核为3×3×3 的C3D 网络。C3D 卷积网络是3D 卷积网络的奠基石。基于ResNet 和C3D 提出Res3D 卷积网络,减少参数量,同时每秒峰值速度更小,整体上,网络性能相对于C3D 有明显的提升。
3×3×3 尺寸的卷积核计算量大,内存要求高,Li等设计出高效3D 卷积块替换3×3×3 卷积层,进而提出融合3D 卷积块的密集残差网络,降低模型复杂度,减小资源需求,缩短训练时间,且卷积块易于优化和复用。
网络训练数据量不足的问题,一直阻碍着行为识别性能的进一步提升。Carreira 等发布了一个超大的Kinetics 数据集,用于解决数据局限性问题。同时提出一种由2D-CNN Inception-V1扩张的I3D(twostream inflated 3D ConvNet)模型,将RGB 视频与堆叠的光流输入3D 卷积网络,并将双流结果融合,使得网络性能进一步提升。
3D 卷积参数量大、数据需求量大以及对光流的利用要求高等问题,限制了3D 卷积对于长时间信息的充分挖掘与使用。Diba 等尝试在不同长度视频范围内对3D 卷积核进行建模,提出了T3D(temporal 3D ConvNets)。T3D采用TTL(temporal transition layer)替换池化层,能够模拟可变的卷积核深度,避免造成不必要的损失;采用3D DenseNet 扩展了三维卷积架构DenseNet,避免从头开始训练3D 卷积网络。为了探究持续长时间输入视频对行为建模影响问题,Varol 等提出LTC(long-term temporal convolutions)网络结构,以不同时长视频作为实验输入,结果显示随着视频长度的增加,识别的准确度也相应增加。T3D 方式虽然能一定程度上在较好的参数空间内初始化网络,但是参数量的增加使得处理过程复杂耗时,在两者的取舍上需要进一步考虑。
针对3D 卷积网络训练时间长、调参难等优化问题,Zhang 等将3D 卷积核拆为时域和空域卷积神经结构,形成可交互的双流,使用残差网络,减少参数量,降低了硬件要求,提高了训练速度,可广泛运用于机器人领域。
综合论述,3D 卷积神经网络充分关注人体的运动信息,但是3D 卷积中卷积核复杂、参数量大等不利因素严重限制其发展。C3D 存在网络结构较浅、训练时间长、提取特征能力有限等问题,尽管在不同方面已经有较好的解决方法,但是没有统一的方法能够完美地处理所有问题。使用VGGNet-16、ImageNet预训练、高效和轻量化三维卷积神经、不同解决方案之间的搭配组合是其重要研究方向。
3.3 混合网络结构
不同的网络架构组件具有不同的侧重点和优点,多种结构的结合使用可以有效提取时空信息,CNN-LSTM 结构是混合网络的代表。结合方式的多样性,使得混合结构具有很大的潜力和很高的热度。
递归演进的循环网络(recurrent neural network,RNN),允许信息持久化,但其激活函数会导致“梯度消失”问题以及ReLU 函数导致的“梯度爆炸”问题,使得RNN 解决长序列问题时能力不足。Hochreiter等设计出一种带“门”结构的循环神经网络单元LSTM,避免长期依赖。LSTM 的变体在行为识别中应用非常广泛,但是导致参数增加,训练难度陡增。RNN 和LSTM 结构区别如图6 所示。

图6 RNN 与LSTM 结构区别Fig.6 Structural differences between RNN and LSTM
Andrej 等在设计网络架构时考虑时间连续性,尝试输入几个连续的帧,对神经网络的融合方式进行研究,对比晚融合、早融合以及慢融合进行实验,证明了慢融合具有最好地效果。LSTM 提取短时信息效率有限,Qi 等使用多维卷积核提取短时间特征,运用LSTM 训练长时间特征,融合多通道信息,获得上下文的长期时空信息。融合上下文特征信息的LSTM 具有更好的表征能力。
CNN-LSTM 结构主要思路为:从RGB 中获取骨架序列,每一帧都对应人体关节点的坐标位置,若干帧组成一个时间序列,使用CNN 提取空间特征,LSTM 处理序列化数据来挖掘时序信息,最后使用Softmax 分类器分类。CNN-LSTM 结构可以对时序信息进行更完整的学习。Donahue等研究LRCN 循环卷积结构,将CNN 用于图像描述板块中获取空间特征,LSTM 则获取时间特征,其在空间运动特征提取、长期依赖等方面有不错的效果,其框架图如图7所示。

图7 LRCN 框架图Fig.7 LRCN structure diagram
使用CNN 训练单帧RGB,并在视频级上进行平均预测会导致信息收集不完整,从而极易造成行为类别混淆,在细粒度或视频部分与感兴趣部分行为无关的数据集上,此种现象更为明显。Ng 等为缓解这个问题,提出了一种描述全局视频级的CNN 描述符,利用特征池和LSTM 网络学习全局描述。在时间上共享参数,在光流图上训练时间模型,达到了比较好的效果。
注意力机制的引入和后续LSTM 的优化,使得双流CNN 和LSTM 的结合能更好地融合视频的时空信息。Ma 等使用时空双流卷积网络和注意力机制提取特征向量,将其输入DU-DLSTM 模块后进行深度解析;Jie 等将基于注意力机制的长短时记忆循环卷积网络(Attention-ConvLSTM)和双流网络进行结合,更准确地学习非线性特征,分析视频数据,缩短了训练时长,提高了识别准确度。
研究者将图卷积网络(graph convolutional network,GCN)与LSTM 结合,如Kipf 等提出一个图卷积网络,使用图作为输入,经过多层特征映射,完成半监督学习。但此种方式存在一些计算量大、不支持有向图等棘手问题。
Li等使用卷积注意力网络代替注意力网络,将二维数组输入LSTM 网络,提出VideoLSTM。通过引入基于运动的注意映射和动作类标签,将VideoLSTM的注意力定位动作的时空位置。该方法更加适应视频媒体要求,提高了空间布局的相关性。
全卷积网络与多层循环网络结合、3D 卷积与GRU 结合、双流网络与膨胀3D 网络结合等都是混合网络的研究方向。其不再局限于单一的网络架构,从而降低人工特征依赖,避免复杂的预处理,提高时间信息利用率,加快识别速度。表2 整理了基于深度学习的行为识别的各种网络架构的优缺点。

表2 基于深度学习的行为识别算法比较Table 2 Comparison of deep learning based behavior recognition algorithms
经典的网络模型框架如图8 所示。双流网络中空间分支处理单帧RGB,时间分支处理堆叠的光流,注重时空信息,识别准确度高,但不同网络分离训练,速度慢;3D 卷积网络依靠卷积核计算运动特征,速度快,但识别效果与参数相关,参数多时,计算量大,硬件要求高,与2D 卷积相比,3D 卷积通过减少输入帧的空间分辨率,寻求减少内存消耗,从而易丢失信号,识别效果受到影响;CNN-LSTM 结构中CNN的平均池化结果作为LSTM 网络的输入,LSTM 获取时间特征,识别时间快,精度高。

图8 经典网络模型框架图对比Fig.8 Comparison of classical network model framework diagrams
3.4 其他优秀的人体行为识别算法
人体行为识别有多种方式,除了关注时空特征的网络架构外,一些其他的方式也有很好的识别效果。基于骨架的行为识别,特征明显,不易受到外观等因素的影响;受限波尔兹曼机利用其无监督学习能力,可以很好地把握运动特性;非局部神经网络架构能够获取更加详细的特征信息。
Wang 等在三维空间叠加关节点轨迹,并投影到正交平面上,生成正交编码图,使用卷积神经网络训练,获得识别结果,此方法创新于投影关节点轨迹,更为简单。基于人体骨架的研究并结合卷积神经网络也是深度学习中行为识别的热点。Shao 等使用层次模型表达人体局部信息,构建层次旋转和相对速度描述符,在公共数据集上具有普适性。基于骨架的行为识别容易忽略骨架数据的噪声和时序特征,比较难以识别细微的动作以及有意义的差异,使得提取的特征鲁棒性不强。为了更好地解决这些问题,基于骨架研究的学者尝试结合深度图序列、彩色图序列等提升识别准确率。一般使用CNN-LSTM进行关节点估计或者采用深度摄像机提取人体骨架序列,效果较好。
受限玻尔兹曼机(RBM)是一类具有双层结构、可通过数据集输入进行概率分布学习的生成网络模型,具有强大的无督促学习能力。在一定条件下,其通过学习数据集中复杂的规则,可以处理高维序列数据。
RBM 由于其独立的连接方式,在网络学习中计算量更小,速度更快。Taylor 等为了更好地理解视频中的数据信息,使用卷积门控RBM,顺利地学习了表达光流和图像模拟,以无督促的方式提取了运动敏感特征。Tran 等定义两个视频帧之间的减法函数,创建时空显著图,从而使用高斯RBM 从显著图上学习运动差分特征。此种方式消除了无关性的形状和背景图,进而突显运动特征。
Wang 等在CVPR2018 年提出一个自注意力模型,其并不局限于一个局部特征,而是相当于构造了一个可以维持更多信息的卷积核,从而获取较为全局的信息。研究者提出的non-local 块能够与现有的各种架构进行组合,通过non-local 操作获取远程依赖关系,提高了各种架构基准。将non-local 块置入C2D 或I3D 网络中,取得了更好的识别结果。
对于长距离空间相关性建模问题,大多数解决方案都存在计算效率较低或者感受野不足的问题,Chi 等提出基于频谱剩余学习(spectral residual learning,SRL)的快速non-local 网络结构,利用SRL 实现全局感受野,是视频分类和人体姿势估计中的重要研究方向。
表3 简单分析了两种识别方法:传统方式提取特征时设计复杂,实现简单,可应用于小样本识别项目,目前已难以适配复杂情景,不能满足高精度识别和普适性的要求。基于深度学习的行为识别效率高,鲁棒性强,更适用于大规模人体行为、群体行为、长时间序列人体动作等情景,也满足大数据时代海量数据识别的要求。

表3 行为识别方式对比Table 3 Comparison of action recognition methods
然而,深度学习方法并不是万能的,甚至带来了新的难题,例如动作标签非单一化、维数灾难、算法复杂度变大、参数增多、计算量扩大、识别准确度不稳定等。一些主要的探索为:(1)对于海量样本标签的准确、高效注入问题,弱监督或无监督网络模型逐步广泛应用,节省大量人力与时间。(2)数据样本的“维数灾难”影响识别精度,Ye 等提出SPLDA 算法可以进行特征约减,去除冗余数据信息,实现降维。(3)为了识别方法的高准确率、高实时性与强鲁棒性,现有算法尝试多视角特征融合。(4)避免耗时、高硬件需求,研究人员开发基于深度运动图、局部建模等的高效、轻量化卷积神经网络。
4 人体行为识别数据集及方法对比
为了评测行为识别中不同算法的性能,现已存在的公共数据集为研究人员提供了良好的测试基础。
数据集的完善逐渐趋近于真实生活的复杂性,可以简单分为早期数据集、真实场景数据集、大型数据集。采用双流网络、3D 卷积等架构的识别算法仍会在经典的HMDB51 和UCF101 数据集上测试。
4.1 常用数据集及比较
KTH 数据集数据量很少,是最早的一批行为数据集之一,拍摄相机固定,包含一些简单的单人行为。Weizmann 数据集包含10 个动作,每种动作9 个样本,是一些场景清晰的单人动作,为适应当时的行为识别方式,标注还包括前景的行为剪影和背景序列。KTH 数据集和Weizmann 数据集都是静态数据集。IXMAS 数据集从5 个视角拍摄,包含不同角度的13 种行为180 个视频序列。这些数据集场景单一,动作简单,人物唯一,数据量少,目前基本不会再使用,但具有划时代的意义。
真实场景数据集更贴近日常生活,也为行为识别早日应用奠定了基础。Hollywood 系列来自好莱坞电影中的动作场景。Hollywood 数据集来自32 部电影,分为8 种类别,不同的演员在不同的场景下进行相同的动作。Hollywood2是对Hollywood 数据集的扩展,从69 部电影中剪切出3 669 个视频,分为12 种行为类别和10 种场景类别,该数据集包含行为子数据集和场景子数据集。Hollywood Extended 中添加了有序的一段动作序列。
UCF 系列数据集主要从体育广播电视频道和视频网站YouTube 中截取而得,场景丰富,种类繁多。UCF-Sports包含多场景多视角变换的举重、骑马、鞍马等10 类体育运动。UCF YouTube(UCF11)对同组视频片段设置相似的特征,如背景相似、演员相同,并且增加相机运动、背景杂乱、照明阴暗变化等因素,使得此数据集在当时具有高挑战性。UCF50将UCF11 的11 种类别扩展到50 种。UCF101是对UCF50 的扩充,动作类别增加至101 种,共计13 320个视频,每组视频的动作又可分为5 类。UCF101 数据集延续了UCF11 的特征相似性和质量高差异性,一直属于挑战性较大的数据集。
Olympic Sports数据集来自视频网站YouTube,包含了16 种运动类别,每种类别约50 个视频,同时包含物体遮挡、相机运动等。此外,此数据集由机器人帮助注释标签。
HMDB51 数据集来自数字化电影和公共资源库,有51 种类别,6 849 个视频,数据集来源不唯一、拍摄视角变化、背景杂乱、外观遮挡等诸多因素,使得数据集识别具有难度。样例如图9 所示。

图9 HMDB51 和UCF101 数据集Fig.9 HMDB51 and UCF101 datasets
Sports-1M 数据集是由Google 采集视频网站YouTube 上一些视频序列而得的一个大型数据集,包含487 种运动视频,1 133 158 个视频,一些视频有多个标签且各类别在叶级层次差异较小。
ActivityNet1.3 是ActivityNet1.2 的延伸,包括日常生活中200 种类型,共计约20 000 个视频,覆盖各种复杂的人类活动。Epic-Kitchens 数据集是一个以厨房为主要场景的大型开源数据集,大多以晚饭时间为采集点,收集烹饪、食材准备、洗菜洗碗等动作。表4 对数据集进行简单对比。

表4 行为识别数据集比较Table 4 Comparison of behavior recognition datasets
Kinetics 系列主要是通过采集视频网站YouTube上的高质量视频而得。2017 年的Kinetics400 包含400类动作,每类有约400个视频。2018年Kinetics600产生,包含600 类动作类别,每类至少600 个视频序列,每个视频持续10 s左右。2019 年,Kinetics数据集再次进行扩充,共计约700 个类,数据量庞之大。
Google 发布的AVA 数据集是一个精细标签数据集,每个人物提供多个动作标签,更加以人为中心,突显原子动作。2020 年的AVA-Kinetics数据集,通过使用AVA 注释协议对Kinetics700 进行注释,其扩充AVA 数据集,结合AVA 多标签的优点和Kinetics 广泛的视觉多样性优点,是验证行为识别方法的得力助手。
FineGym 数据集是一个规模大、定义清、质量高、标注细粒度的人体动作数据集。在语义上,FineGym 定义三层类别结构:事件、组和元素类别;在时域上,采用两层结构:动作和子动作。FineGym99收集了99 类数据,FineGym288 对其扩充至288 类,提供了大约6 000 动作数据和3 万多子动作数据的精确标注,且在持续进行。
数据集的发展,经历了多维度的改变。人物个数上,向群体行为发展;场景上,趋于真实现实场景;粒度上,细粒度动作日益丰富;标签类型上,标签更加层次化、非唯一化;质量上,逐渐高质量化;来源上,不再局限于实验拍摄等。
4.2 不同方法性能比较
纵向比较不同识别算法性能的测试,一般采用相同数据集进行实验对比,根据平均精确率mAP 进行评价,也可以横向比较同一算法在不同数据集下的表现,以检验此方法是否适应更新的数据集。新数据集在数据量、标签多样化等方面具有优势,具有一定的挑战性。表5整理了较新数据集上的算法性能。

表5 各算法性能对比Table 5 Performance comparison of different algorithms
运动轨迹具有强大的鲁棒性。运动轨迹的描述符的改进可以获得RGB 中更全面的信息;改进的运动轨迹方式考虑相机运动,注重时空域下的运动信息,因此目前的网络架构多与IDT 结合,在Olympic Sports*数据集识别率也可以达到91.4%,真实场景数据集Hollywood2 上效果超过64.0%。
传统方式在大型数据集上表现出局限性。人工特征设计方式不适用于海量的视频信息,反而适合训练深度学习分类器。在Sports-1M 中,混合网络CNN+LSTM 准确率高达73.1%。目前使用深度学习的网络特征表达性能已经超过了传统人工设计的特征表达方式。
目前大多数识别算法使用的数据模态为RGB 和光流OF。两者结合能够表现目标的外观和运动信息,但是寻找特征替换光流是解决噪声等不利因素的重要研究方向。
HMDB51 和UCF101 仍是使用最广泛的两大数据集。各种经典算法都使用此数据集,目前虽然有数据量更大的新数据集,但是UCF101 在种类丰富、背景干扰、相机运动等方面变化较大,十分具有挑战性。同时,为了对比新算法相对于前期算法的识别率精进情况,新算法一般也会使用此两大数据集,如表6 所示。

表6 在HMDB51 和UCF101 上的各算法性能对比Table 6 Performance comparison of different algorithms on HMDB51 and UCF101
传统的经典机器学习算法稳定性较好。在HMDB51 和UCF101 数据集上识别准确率稳定在60%和88%左右。深度学习中由于各种网络架构差异性较大,在HMDB51 中准确率在59%和81%之间波动,在UCF101 中准确率在82%和98%之间波动。
基于深度学习的行为识别算法在识别准确率方面有了明显的改善。Two-stream 架构采用双流通道,3D 卷积网络在连续帧中使用3D 卷积核,因此获取了更好的时空混合特征。Wang 等基于双流架构,使用稀疏时间取样和视频级别的监督策略,在HMDB51和UCF101 数据集上识别精度达到69.4%和94.2%;Jie等在双流网络中加入自注意力机制,在HMDB51和UCF101 数据集中识别率达到69.8%和94.6%。
改善3D 卷积神经网络结构可以有效提高识别精度。3D 卷积具有结构复杂、优化困难、参数量大、难以训练等难题。Qiu 等将3D 结构改造为2D+1D 缓解参数问题,在UCF101 数据集上准确率达到93.7%;Carreira 等对I3D 网络架构进行预训练,在UCF101数据集上识别精度高达98.0%,在HMDB51 数据集上准确率达到80.7%;Tran 等将3D 卷积网络拆分为2D 空间卷积+1D 时间卷积,利于网络优化,在HMDB51 和UCF101 上准确度达到78.7%和97.3%。目前,将GRU、Attention 模块、Inflation 等加入3D 卷积网络中也有较好的效果。
IDT 和深度学习网络结合表现出优异的效果。IDT 能够有效捕捉目标的运动信息,深度学习网络可以适应大数据。Wang等结合双流网络和IDT,使用轨迹池深度卷积描述符TDD,在HMDB51 和UCF101数据集上识别率高达65.9%和91.5%;Varol 等使用LTC 和IDT 结合的方式,识别率比Wang 等高出1.3个百分点和1.2 个百分点。Feichtenhofer 等使用VGG-16 网络结合IDT,在HMDB51 和UCF101 数据集上识别精度高达69.2%和93.5%。
5 总结与展望
一些简单的行为识别已经在生活中应用,然而全面的大规模的应用行为识别仍然有很长的路要走。传统的行为识别特征描述符表达能力有限,难以适应大数据时代复杂的视频场景,将深度学习引入动作识别推动了行为识别的发展,但仍存在很多的挑战。(1)视频质量的复杂性:视频帧率和图像清晰度、视频是否修剪分类、视频长度不一而且视频中存在多尺度问题、多目标交叉、边界清晰性确定、类内和类间差异等问题。(2)时域信息的复杂性:环境光照变化、背景场景变化、视角切换变化、相机移动、运动方向改变、人物几何特征改变、大动作变化尺度和时间、人物变化时序维度等问题。(3)细粒度识别的复杂性:密集或者快速的动作、肢体细微差别、运动频率与次数等问题。
传统方法中,IDT 算法具有很高的可靠性,适用范围广,但时间复杂度高,运算速度慢,不适合密集数据识别。深度学习下,双流算法识别准确度高,表征能力强,但多流网络需要分开训练,实时性有待提升;3D 卷积网络注重时间维度,训练速度快,泛化性能好,但存在大量参数,不够灵活;CNN+LSTM 网络优于保存长时间序列信息,缩小计算量,可与注意力机制等结合使用,但网络结构比较复杂。要想加快生活与工业化行为识别的节奏,需要研究轻量级网络结构,实现自监督与无监督应用,从而“多快好省”地运用高效算法。
(1)注意力机制成为趋势。视频数据中,除了目标信息,还有很多无关信息,网络模型加入注意力机制,可以将有限的资源用于显著区域,加深不同尺度的卷积特征,提高识别准度。软注意力机制、混合注意力机制的Action 模块、高阶注意力等将成为热点,但是需要考虑算法的复杂性。
(2)考虑全局语境信息成为重要研究方向。在设计上卷积层是为了更好地提取局部特征,因此全局信息易被忽略。在卷积层之前,将全局语境信息融合到局部特征中,从而调整卷积,更高效地捕捉关键信息。例如,使用全局特征交互的语境门限卷积,可以依照全局信息的指引动态地改变卷积层权重,方便捕捉到有辨别力、有代表性的局部特征。
(3)多模态信息融合具有良好前景。传统的RGB信息容易受到环境差异、动态背景等的影响,存在很多噪音。转换角度来看,视频中的识别依据不只有图像、运动,还有声音等,在网络模型中将视觉特征和声学特征结合,多视角特征融合可以减少特征参数,提高识别效果。
本文对行为识别的研究做出综述,详细介绍了人体行为识别的各种行为识别网络架构,重点展现出各网络的发展情况与优缺点比较;同时整理了前期重要的数据集以及最新的数据集;最后阐述了目前的研究痛点并预测了未来的行为识别方向,希望对初学者或其他研究人员有所帮助。
猜你喜欢
现代经济信息(2022年22期)2022-11-13
中小学校长(2022年7期)2022-08-19
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
作文大王·低年级(2022年2期)2022-02-28
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
电子制作(2019年11期)2019-07-04
福建基础教育研究(2019年6期)2019-05-28
动漫星空(兴趣英语)(2018年9期)2018-10-30
