
基于YOLOv5算法的观影人数检测模型探索
2022-03-05 05:50张明
现代电影技术 2022年2期
张 明
(中央宣传部电影数字节目管理中心,北京 100866)
1 研究背景
农村电影放映工程自2004年实施以来,一直是丰富广大农民群众精神文化生活的关键抓手,为推进我国公共文化服务均等化下沉做出了重要贡献。随着技术水平不断提升和快速发展,农村电影放映工程的技术平台也在不断优化完善中。在建立“点派接评”闭环技术管理模式中,尤为重要的一点是如何进一步获取观影规模等反映基层放映实际情况的有效数据。这些数据如何高效及时地获取十分关键,是支撑国家及相关行政管理部门监督管理的重要参照数据基础。
城市院线放映能够通过销售票务的方式统计观影人数,为避免“偷票房”等问题的出现,目前也有一些具有针对性的解决方案。《基于智能视频分析的影院观影人数准确统计系统研究和实践》提出了一种基于视频监控和智能视频分析的观影人数统计系统。该系统在影院的每个影厅里安装近红外视频监控系统,视频采集设备在电影放映过程中不断采集观众区域图像,通过一定的算法判断影厅座位是否被占用,从而评估本场次观影人数。技术上采用了一种基于改进Canny算子及灰度投影的座椅标定算法,其中,算子部分采用了双边滤波,对比传统的二维高斯滤波,双边滤波的好处是在保留了滤波效果的同时也保留了其高频部分,即图片的细节。在Canny算子检测边缘的基础上,《一种基于Hough变换的红外图像座椅定位方法》一文提出另外一种座椅定位方法。从整体图像上看,影院的座椅排列形状可以拟合成某种曲线方程,经过Hough变换检测出每排座椅后,选取每排座椅形成一维数组,将该数组进行傅里叶变换。然后采用差分的方法找到跳变沿,从而确定影院座椅两侧边缘。此方法使用座椅的空间分布规律和单个座椅的形状特性,有效地提高了红外图像中对比度差、边缘模糊等识别命中率的问题,验证了Hough变换较强的抗干扰性和鲁棒性。《基于SNMP 的影院观影人数清点系统》则未采用影厅内采集信息进行计算的方式,而是将摄像头安装在出入口。采集到的视频数据经过动态白平衡、降噪等简单的视频预处理后,一方面作为boost级联分类器输入,另一方面作为样本训练的输入。boost级联分类器等多种机器学习算法,能动态地学习人体头部与肩部正上方或斜上方(人体头肩图像)的二维图像特征,并通过远程平台动态地更新视觉识别库,不断提高识别的准确率。级联分类器从每一帧的视频中识别出人体头肩图像,生成识别结果后经过形状判定与运动检测输出人流数据。
相比于城市影院,农村电影放映观影人数存在一定的不确定性:农村电影放映是国家公益性文化活动,并无售票环节,因此没有业务环节可直接进行人数统计。目前主要通过放映员填报现场观影人数、观众填写问卷调查、第三方调查等方式进行观影人数的监测,许多地区要求放映员每场放映拍摄现场照片,管理人员查看照片人工点人数作为人次抽查或复核的依据,为掌握观影人数情况提供了一定支撑。但这些方式均带来一定的工作量,增加了人工成本。考虑到观影场地是开放的,并不具备通过检测座位是否占用的形式统计人数;观影时间是自由的,观众的流动性比较大,观影过程中的人数也会出现反复波动,以上方式也难以有效统计观影人数随时间变化的情况。
为提高观影人数统计的效率,本文引入一种YOLO 目标检测技术,对放映员拍摄的现场照片进行人群数量检测,探索通过这一方式建立流动放映观影人数自动化检测的技术模型。
2 目标检测
目标检测 (Object Detection),也叫目标提取,是一种基于目标几何和统计特征的图像分割与统计技术,其可以看成图像分类与定位的结合。给定一张图片或者一段视频,目标检测系统要能够识别出图片的目标并给出其位置。已有的研究表明,可靠的目标检测算法是实现对复杂场景进行自动分析与理解的基础。因此,图像目标检测是计算机视觉领域的基础任务,其性能的好坏会直接影响后续的目标跟踪、动作识别、行为理解等中高层任务的性能,进而决定了人脸检测、行为描述、交通场景物体识别、基于内容的互联网图像检索等后续AI应用的性能。
目标检测领域的研究最早可以追溯到1991年提出的人脸检测算法,近几年来,随着计算机硬件不断提升、深度学习技术的发展与各种高质量的目标检测数据集的提出,涌现出越来越多优秀的目标检测算法。目标检测算法的发展大致分为两个阶段:第一阶段集中在2000年前后,这期间所提出的方法大多基于滑动窗口和人工特征提取,普遍存在计算复杂度高和在复杂场景下鲁棒性差的缺陷。为了使算法能够满足实际需要,研究者们不得不寻找更加精巧的计算方法对模型进行加速,同时设计更加多元化的检测算法以弥补手工特征表达能力上的缺陷。第二阶段是2014年至今,利用深度学习技术自动的抽取输入图像中的隐藏特征,从而对样本进行更高精度的分类和预测。比较流行的算法可以分为两类,一是“两步走(Two-stage)”的目标检测:先在独立的网络分支上生成候选区,再对候选区进行分类和回归,代表算法有R-CNN、SPP-net、Fast R-CNN、Faster R-CNN 等;另一类是采用一个网络一步到位,即仅使用一个卷积神经网络 (简称CNN)直接检测出目标物体的类别与位置,代表算法有SSD、YOLO 等。本文选择YOLO 算法进行观影人群的检测。相比传统的目标检测算法,基于深度学习的目标检测算法速度快、准确性强,还具有在复杂条件下鲁棒性强的优势(图1)。

图1 两类目标检测算法
简要来讲,目前有四种方法来实现人群计数,这四种方法也是逐级演进的:
(1)检测器:用一个移动窗口检测器来识别图像中的人,并计算出数量。这种方法比较适合于人脸检测,而在人群拥挤或者遮挡过多的场景中效果不佳。
(2)回归方法:使用滑动窗口检测器效率较低,而且并不十分有效。可以考虑采用基于回归的算法:首先从图片中裁剪补丁,然后再针对每个补丁提取低级别的特征。
(3)基于密度估计的方法:此方法主要分两个步骤:第一步是先提取低级的特征,比如边缘特征、前景特征、纹理和梯度特征等;第二步是学习一个回归模型,例如高斯过程回归、线性回归等,最终获得一个低级特征到人群数的映射关系。
(4)基于CNN 的方法:使用CNN 构建一个“端到端”的回归模型,待检测的图片经过此模型后直接输出结果。CNN 是目前比较流行的检测算法,其在回归或分类任务中效果显著,YOLO 就是利用的此种检测原理。
3 YOLO 简介
YOLO (You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,之前的物体检测方法均是基于先产生候选区再检测的方法,虽然有相对较高的检测准确率,但运行速度较慢。YOLO 创造性的将物体检测任务直接当作回归问题来处理,根据它的英文名字就可得知:只需看一眼,就知道待检测目标是否存在以及它的位置。YOLO将识别与定位合二为一,具有体积小、检测速度快、准确度高等优点,在目标检测领域得到了广泛的应用,目前YOLO 已发展到了v5版本。
3.1 YOLO 的发展[5]
YOLOv1于2015 年提出。YOLOv1 将输入的图片划分成7×7=49个网格,每个网格预测出2个边界框,最终获得98个边界框。由于网格设置比较稀疏,且每个网格只预测2个边界框,其总体预测精度不高,对小物体的检测效果较差。
YOLOv1的优点是检测速度快,缺点是定位方面不够准确,并且召回率较低。2016 年提出的YOLOv2提出了几种改进策略,在v1 的基础上提升了定位准确度,改善召回率并能有效提高模型的m AP (Mean Average Precision,平均精度均值)。
YOLOv3的模型进行了更加复杂的设计,能够通过改变模型结构的大小来权衡速度与精度。其中有两个值得一提的亮点,一个是使用残差模型,进一步加深了网络结构;另一个亮点是借鉴了FPN(Feature Pyramid Networks,多尺度特征检测)的思想,在不同尺度提取的特征图上独立进行检测。
2020年2月YOLO 之父Joseph Redmon宣布退出计算机视觉研究领域。2020年4月23日,Alexey Bochkovskiy 发表了一篇名为YOLOv4:Optimal Speed and Accuracy of Object Detection的文章。v4在原有基础上采用了很多优化策略,例如在数据处理、主干网络、网络训练、激活函数、损失函数等方面都有不同程度的优化。v4在COCO 数据集上的AP (Average Precision,平均精度)和FPS(Frames Per Second,每秒传输帧数)分别提高了10%和12%,并得到了Joseph Redmon的官方认可。
同年6 月25 日,Ultralytics发布了YOLOv5的第一个正式版本,尽管v5的开发者没有明确地将其与v4进行比较,但开发者在报告中称v5能在Tesla P100上实现140 FPS 的快速检测;相较而言v4的基准结果是在50 FPS 速度下得到的,但是v5的大小仅有27 MB,对比使用darknet架构的v4有244 MB。这说明v5在保持了准确度的水平上,比v4小近90%,并且有着非常快的运算速度。
回顾YOLO 系列的发展,可以看出YOLO后期没有提出新颖的想法,但是更加重视应用的落地(图2)。

图2 YOLO 的发展
3.2 网络结构
目前,YOLOv5 的目标检测网络共有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 四个模型。
YOLOv5s是YOLOv5系列中深度最小且特征图的宽度也最小的网络,其速度最快,AP 最低。其他三种网络模型都是在此基础上,不断加深、加宽网络,AP 也不断提升,但速度的消耗也在不断增加(图3,表1)。本文采取第一种网络模型进行目标检测。

图3 Yolov5不同网络结构性能图 (基于COCO 数据集)

表1 Yolov5不同网络结构性能参数对比表
4 实验及结果
4.1 实验环境
本实验采用Colaboratory 平台进行实验,Colaboratory (简称“Colab”) 是由Google Research团队开发的一种托管式Jupyter笔记本服务,用户可以通过浏览器编写和执行Python代码,并且还能够使用GPU 计算资源。Colab运用NVIDIA Pascal GPU 架构提供统一的平台,适用于PCLe的NVIDIA Tesla P100使混合型工作负载HPC数据中心能在节省成本的同时大幅提升吞吐量。
4.2 数据集
数据集在目标检测领域中的地位十分重要,选择适配的数据集可以有效测试和评估算法的性能,并且能够推动相关领域的研究发展。目前应用最为广泛的数据集有:PASCAL VOC2007、PASCAL VOC2012、微软COCO、Image Net和OICOD等。
2005年首次发布的PASCAL VOC 数据集发展到现在更新了多个版本,目前流行的版本是PASCAL VOC2007和PASCAL VOC2012,其主要用于图像分类与识别、目标检测任务等;微软COCO 数据集是一种基于日常复杂场景的常见目标数据库,于2015年首次发布,该数据集是图像分割领域最大的数据集,极大推动了该领域的发展,具有小目标物体多、单幅图片目标多等特点;Image Net数据集于2010年发布,增加了分类和图像的数量,提高了目标检测任务的训练和评估标准。但是正因为如此,此数据集训练的计算量花销大,目标检测难度增加;OICOD 数据集提供了更多的类、图像、边界框、实例分割分支和大量的注释过程,并且为目标实例提供了人工确认的标签,它是在Open Image V4基础上提出的最大的公共使用数据集。
虽然公开的数据集功能强大,图片丰富,并且极大地节省了素材收集与人工标注的成本,但是基于具体的问题分析是不通用的,尤其是针对某一特定的目标进行检测,仍需自主收集样本并进行针对性的标注。本文收集了不同场景下、不同规模的人群样本约2400张,并采用LabelImg工具进行样本图片手动标注 (图4),工具能够自动生成配套的xml或者txt格式的标注信息。
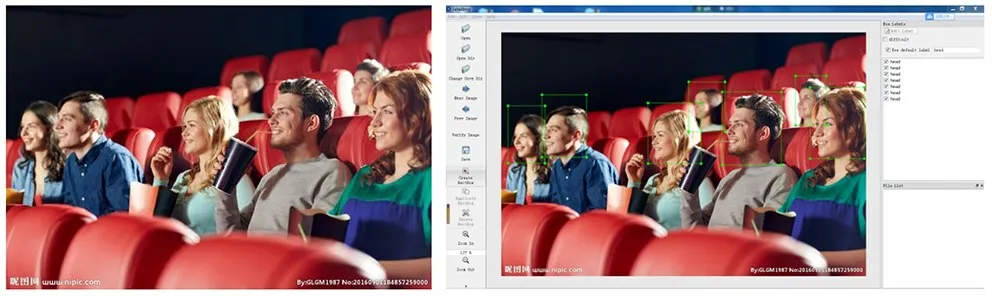
图4 使用LabelImg进行图片标注
4.3 训练
本实验共使用2400张标注图片进行训练,训练时间花费3小时左右,训练后生成权重数据weights文件及训练日志result.csv(图5)。
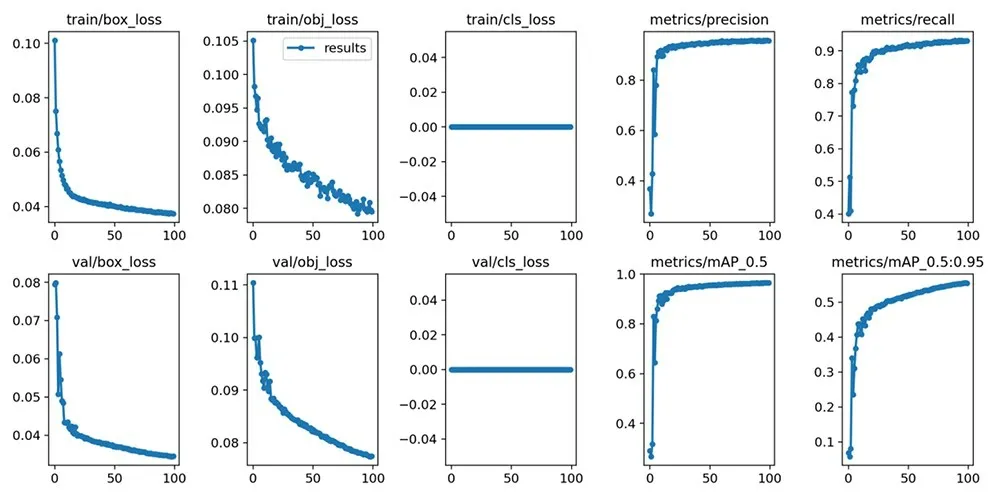
图5 训练日志可视化呈现
这里简介训练日志中几个比较重要的指标,train表示训练集,val表示验证集:
box_loss:回归损失函数均值,越小检测方框越准;
obj_loss:目标检测损失函数均值,越小目标检测越准;
cls_loss:标注物体的分类准确率,因本实验中只有一种目标分类 (head),不存在误分类的问题,因此数值为0;
metrics/precision:精度,又称为查准率,旨在判断在预测模型是正值的结果中预测对的比例;
metrics/recall:召回率,又称为查全率,旨在判断在真实值是正值的结果中预测对的比例;
metrics/m AP_0.5:用precision和recall作为两轴作图后围成的面积作为AP,m 表示样本平均值,0.5表示阈值大于0.5的平均m AP。
显而易见,能够精准地、快速地识别并定位物体是检测模型最基本的指标。在实际应用中评估目标检测模型的性能时,一般结合平均精确度均值m AP和检测速度FPS 两者来判断。m AP 值越大,表明该模型的精度越高,检测速度FPS则代表了目标检测模型的计算性能。
4.4 实验结果及分析
实验选择了不同场景下的放映观影照片作为待识别目标,经人工识别的比对结果可知,本实验结果数量级比较准确。由于照片清晰度、拍照光线、人物遮挡等问题,结果比实际数量偏低,此模型还需要进一步调整参数以及进行偏移量补偿函数。

表2 实验结果
5 结论与展望
本文通过对目标检测算法的分析,采用YOLOv5算法实现了观影人群数量自动化检测的实验模型,选取的检测图片实验结果符合预期。但是基于农村电影放映场地条件制约,可能存在着回传照片清晰度差、观影人群流动性、人群前后遮挡等问题,在这些场景的照片识别结果还有一定的误差,尤其是图片边缘的识别性还有诸多不足。后续会加大训练集的复杂度及覆盖度,通过训练日志进一步调优参数,并且加入偏移量补偿函数等工作,以提升实验模型的适用范围。
由于观众在观影过程中会进行移动,这会导致不同时间点的检测结果误差,因此可以考虑在后续的工作中加入时间投票机制,随机或者定时抽取图片进行检测,将结果进行适当的数据清理后绘制图表,也能对评估观影人数的趋势进行更为直观的展现。❖
①人工识别有一定的主观性,数据存在误差。
②检测结果head后面的数字表示可信度,数值越大表示准确率越高。
猜你喜欢
小天使·三年级语数英综合(2022年4期)2022-04-28
阅读与作文(英语初中版)(2019年8期)2019-08-27
初中生世界·九年级(2018年12期)2018-12-22
汽车导报(2017年5期)2017-08-03
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
求学·理科版(2017年1期)2017-03-02
中学生数理化·高二版(2016年4期)2016-05-14
读者(2015年9期)2015-05-04
