
融合启发式和Boosting 的子图匹配基数估计方法
2022-03-13 09:18侯文哲
计算机与生活 2022年3期
侯文哲,赵 翔
国防科技大学 信息系统工程重点实验室,长沙410000
随着网络大数据的迅速发展,社交关系、知识表示等领域大放异彩。图数据库作为一种描述关系数据的天然模型,已成为当前海量网络数据管理的解决范式。因此,图数据管理技术也成为当前的研究热点。近年,以子图匹配为代表的图数据上基础操作的性能得到了巨大提升。但是,一个完善的高吞吐的图数据库系统还应具备自适应的任务调度能力;为了实现这个目标,图数据库系统需要对系统中的任务进行代价估计——特别是对中间结果基数的尽可能准确估计,从而优化多任务执行的序列与配置。本研究以子图匹配任务为例,研究针对该任务的基数估计的有效方法。
子图匹配是图数据库管理、查询等各项工作中的基础操作。为提高子图匹配操作的执行效率,现有研究对其执行过程进行了有效的剪枝、索引构建等优化,但精确的子图匹配问题仍然是一个NP 完全问题,随着待匹配结点的增多,匹配将难以在有效的时间内完成。若能在匹配执行之前就能够尽可能准确地估算匹配结果的基数,便可帮助实现对匹配执行过程和多个匹配任务的整体优化,对于提升图数据库管理系统的效率和吞吐量意义重大。
当前,在关系型数据库管理系统领域,学者已经提出一些机器学习的方法和传统的非机器学习方法来对查询结果的数据库查询任务的基数进行预测,而这些方法往往基于数据库的连接过程,无法直接应用到以图为结构的图数据库匹配的基数估计工作中。另一方面,现有的用于子图匹配基数估计的部分研究依赖于离线统计的方法,无法充分利用图数据中的结构信息,且没有一个适用于多结点查询图匹配基数估计的框架。
鉴于此,本研究旨在设计一个通用方法来实现多结点查询图的预测框架,并通过对图数据的结构信息建模、编码,应用Boosting 学习的思想,实现鲁棒的多结点子图在大规模数据图中匹配基数的预测工作。具体地,提出BoostCard 方法,它首先针对数据图中结点的邻居信息建模,将结点分类并构建相应索引,然后对不同类型结点之间能否连成一边的概率进行预测,并基于上述信息,对多结点子图的匹配基数进行预测,最后运用机器学习的方法对匹配结果的基数进行补偿。
简言之,文章的主要贡献是将图数据的结构信息建模到子图匹配结果的基数估计工作中,并根据Boosting 学习思想,提出适用于多结点子图的匹配结果预测方法(Boosting cardinality estimator,BoostCard)。
1 相关工作
在社交、电商、零售、物联网等行业快速发展的Web 2.0 环境中,图数据库因为它的对联系建模等天然优势,弥补了传统关系型数据库在复杂关系运算方面的短板。对于图数据库,找到一种准确、有效的代价预测方法,将能够实现数据管理系统的优化,提高执行效率。以代价估计为依据寻找最佳执行策略的方法已经在各大传统关系型数据库系统中得到应用。在图数据库的数据管理操作中,子图同构查询是重要的基础查询形式,也是数据管理的基础操作,在实际执行查询前,若能够预先估计出这些基础操作的查询结果基数,也将极大地提升图数据库的查询性能。然而,目前提出的方法普遍对图数据库的结构要求较为特化,还没有一个泛用、完善的图数据库数据管理操作代价估计的解决方案。
1.1 子图同构算法
子图同构问题,简单来说就是在给定的数据图中查找与模式图相同的子结构,一般分为精确匹配和近似匹配。本研究针对精确匹配展开讨论,匹配过程中要求数据图的匹配结果与模式图完全一致。
图)定义三元组(,,)表示一个图,其中表示图中结点的集合;表示边的集合,∈×;是该图的属性映射函数,将边或结点映射到一个或一组属性。
(子图匹配)已知数据图=(,,)和模式图=(V,E,L),精确子图匹配要求在模式图和数据子图=(,,)之间建立一个双射函数:

如图1,模式图在数据图中存在两个匹配的子图,即=[(,),(,),(,),(,)]和=[(,),(,),(,),(,)]。
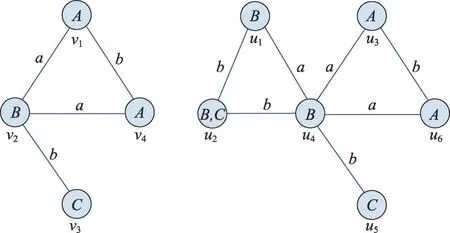
图1 精确匹配示例Fig.1 Sample of exact subisomorphism
从算法的角度,精确匹配分为无索引的匹配和基于索引的匹配,无索引的精确匹配利用图中的语义和结构信息缩小匹配范围。1976 年提出的Ullmann算法针对结点的度、映射规则、结点邻接关系提出一系列剪枝规则,在小规模图匹配问题中简单有效。在Ullmann 算法的基础上,Sansone 等人提出VF2 算法,通过标签中的语义信息对匹配的预选集进行过滤,并通过预选结点在未匹配结点中的入度和出度进行一步预先判断,进一步缩小了搜索空间。
近年来的改进算法将更复杂的路径和子图结构引入剪枝过程,进一步缩小了搜索空间,以实现更大规模的匹配问题求解。随着图数据规模的继续扩大,基于索引的匹配技术应运而生,这些技术通过数据图中的有效特征构建索引,能够快速缩小子图范围,再基于备选子图展开精确匹配。这些特征既能实现图索引构建,又很大程度上表达了图的结构信息,对包含图数据的结构特征构建也能起到极大的帮助作用。
而在最终的匹配过程中,子图匹配问题仍然是NP 完全问题(non-deterministic polynomial complete problem),在多项式的时间开销内对匹配结果的基数进行粗略估计将为查询操作的优化提供重要依据。
1.2 启发式预测方法
图数据库系统进行查询时使用连接运算扩大对图中各边的搜索和匹配。一些图数据库系统将预先加入索引的图数据子模式作为基本单位进行连接。Maduko 等人针对上述过程,提出了一种图数据摘要技术,并通过建立的图数据摘要,使用有索引的频繁子结构描述查询子图数据的特征,进行启发式的查询子图基数估计。
对子图匹配问题的代价预估技术,在资源描述框架中也已经提出了一系列可行的实现模型,但这些方法对图数据的构成结构有较高的要求,解决问题较为特化,在所有结点均表示一个实体的非资源描述框架的图数据中难以达到预期,不能实现普通图数据库的匹配代价预测。
针对上述问题,Paradies 等人为非资源描述框架下的图数据提出一种专门的子图匹配基数估计的方法,该方法基于统计学理论,运用数据图中的基础统计数据预测两结点及其相连的边在单张大规模数据图中的匹配结果的基数,并通过关系依赖使算法在多属性图的环境中更加稳定有效。但是方法只对两个结点及其相连的边有效,无法直接应用于存在多结点的完整模式图匹配中。
1.3 关系型数据的智能化估计
近几年来,很多学者为提升数据库查询性能预测的普适性,尤其是为解决存在复杂谓词和连接时传统方法误差较大的问题,提出了一些基于深度学习的解决方案。Kipf 等人提出Learned Cardinalities方法,对数据库表、连接操作、谓词逻辑分别进行编码,以实现数据库查询输入的向量化转化表示。
最新的结构化查询语言(structured query language,SQL)查询性能预测研究通过SQL 查询执行计划实现了更为灵活的端到端预测来适应各种不同结构的查询。SQL 查询语句可以通过执行优化器表示为查询执行计划的形式,它们将SQL 查询细化成对数据库系统中的原子性操作,并构建成树状结构来表示具体执行过程。
结合执行计划的树状结构特点,一些学者通过构建相应的表示模型来执行逐级预测。Sun、Li 为执行计划树的结点构建一个结点表示网络来预测到每个结点为止的开销及基数,并作为高一级运算的输入向上传递;对于有谓词限定数据,该方法采取简单的数理计算获取预测值。Marcus 等人针对执行计划中不同的操作构建不同输入结构的神经网络作为神经单元,并将这些神经单元依据查询计划的结构连接成树,仅通过查询计划中的参数和低一级的预测结果作为输入实现预测。
2 问题定义
定义2 引用了关于子图匹配问题的定义,拟解决的问题是尽可能准确预测子图匹配的基数。
(子图匹配基数)对于给定的数据图=(,,)以及模式图=(V,E,L),模式图可能与的任意子图=(,,)建立双射函数满足子图匹配的要求,将所有满足要求的函数集合记作F,该集合中元素的个数|F|即为数据图与模式图的子图匹配基数。
在大规模的数据图中,执行子图匹配任务往往会面临时空开销大,无法在足够短的时间内给出结果。本文研究子图匹配基数的预测方法,输入拟执行子图匹配的模式图与数据图。在不进行实际的子图匹配操作的前提下,输出一个该组图数据的子图匹配基数的预测值。
3 BoostCard 方法
BoostCard 是一种在整张模式图上游走,依经过的每一边估计匹配结果基数的方法,这个过程中会利用对各个结点的局部结构信息生成对应的结点表示,并以此提高每一跳预测的准确度。在这一预测框架下,为了能够实现对模式图全局信息的掌握,预测补偿机制以提升学习的形式加入到方法中,对结点的表示向量进行学习,获得针对不同模式图的补偿强度来优化预测结果。
3.1 基本思路
模式图对于数据图的匹配过程被视为一个连接操作的执行过程。模式图中的结点的匹配顺序由深度优先遍历产生:(,,,),首先将中的结点分为两个集合,即已匹配集V和待匹配集V。初始条件下,所有结点均于待匹配集V中,随着未匹配的结点加入匹配,模式图中的结点依匹配顺序由待匹配集转移到已匹配集中。如图2 所示的子图匹配过程中,在前三个结点已经完成匹配的情况下,V={,,},V={}。匹配的过程可以看作模式图的子图在数据图的约束下添加一个满足条件的结点及其与中一点之间相连的边,匹配完成后V={,,,},V=∅。
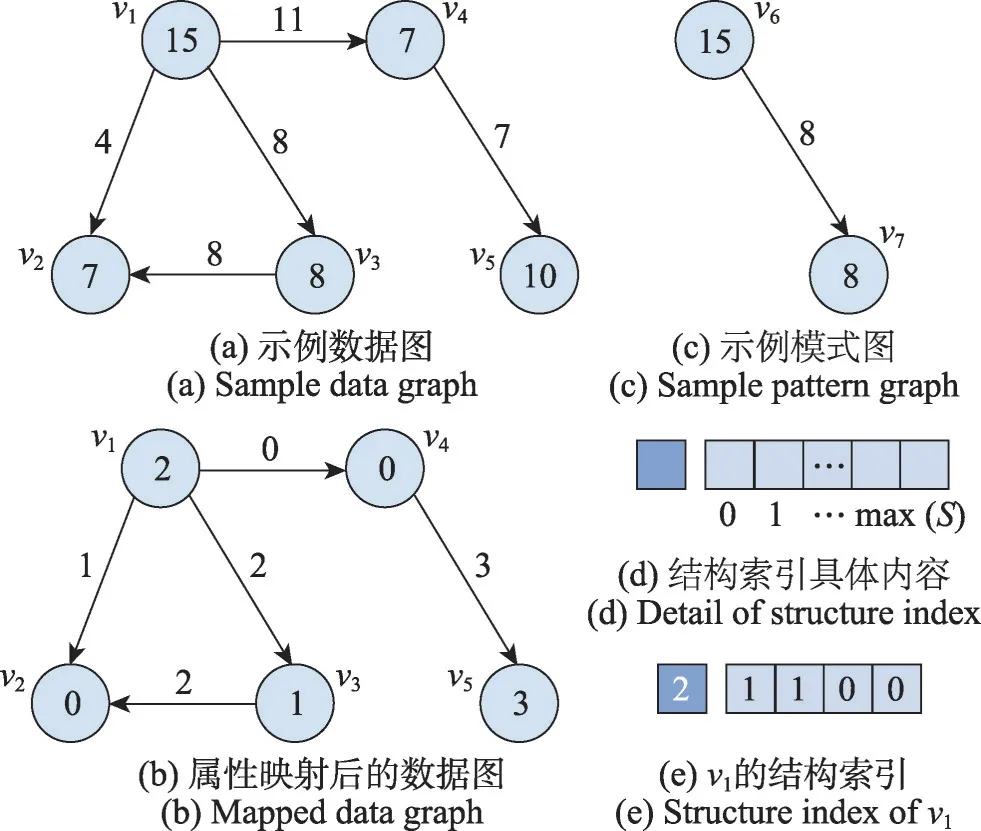
图2 结构信息获取Fig.2 Structural information acquirement
BoostCard的基本预测过程在算法1中给出描述。
预测框架

BoostCard 预测主要由四部分组成:结构索引、结点连接预测、多结点预测框架、预测补偿器。
预测执行过程如下:(1)通过结构索引将数据图中所有结点分类分组,并构建简单索引实现快速访问。(2)在构建的结构索引的基础上,通过结点连接预测过程,对数据图中任意两类结点之间连成一边的概率进行预测。(3)多结点预测器依照匹配过程,预测模式图在数据图中出现的次数,即匹配结果的基数。预测器对模式图的子图的匹配基数进行预测,并依照匹配顺序添加新的待匹配结点以更新,直到所有中结点全部添加到中,此时所得到的预测结果即为模式图的匹配基数估计值。(4)根据建立的结构索引,可以通过预测补偿器获取模式图的统计向量表示作为依据,结合提升学习的思想对预测结果进行补偿。
接下来,分别对模型的每个部分进行讨论。
3.2 结构索引
结构索引的目的在于对数据图中出现的结点的结构信息建模。这些结构信息主要基于每个结点及其相邻的结点的属性信息构建而成。
属性映射函数将各结点的属性映射到自然数集中:
:→
其中,为数据图中属性集,⊂ℤ,为自然数集的子集;∈,可作为结点属性的唯一表示。
结构索引的构成由图2(d)所示,对于数据图中的结点v,其中,l∈,为结点v的整数映射,为表示v的邻居结点信息的二值向量:

对于数据图的结点v,若其存在属性映射到整数集后取值为的邻居,则取值为1,不存在上述邻居结点则取值为0,在图2(a)所示的数据图中,结点的结构索引向量如图2(e)所示。图中结点和边的属性映射到整数域中,图2(b)展示了经属性映射的数据图。结点自身的属性映射为2,其邻居结点含有被映射为0、1 的属性;在图示的数据图中,结点属性只有4 种取值,的长度为4。综上,的结构索引向量中取值为2,为(1,1,0,0)。结构索引将数据图中的各个结点的结构信息表示成一个标量与一个向量组成的元组作为结点v的结构标识d∈×{0,1}。拥有同样结构标识的结点即被视为同种类型的结点。 D={∈|d=}表示有同一类结构标识的结点。
3.3 结点连接预测
结点连接预测的作用是针对数据图,统计不同类型的结点之间能够连成拥有某属性的一边的概率。
结点连接预测同样将数据图中的边的属性映射到整数集:
:→S
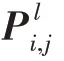

其中,分母表示数据图中d类型的结点到d类型的结点可能的组合的个数;分子表示这些组合中两点之间存在一条属性映射到的边的组合数。
至此,对于一个匹配查询的模式图,首先以两结点及其间一边构成的图为例,将两结点分别分类到对应的结点类型中,即可通过数据图中这两种结点的数目以及其间可连成一边的概率预测匹配结果的基数。

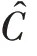
如图2(c)所示的模式图中,结点对应数据图的结构标识为(2,(0,1,0,0)),这与中结点的结构标识(2,(1,1,0,0))是不同的,然而模式图显然可以在数据图中成功匹配。
预测乘子multiplier

匹配概率match_prob
输入:数据图中目标结点,模式图中待匹配结点。
输出:匹配到的概率。

3.4 多结点预测器
BoostCard 预测器根据匹配顺序添加结点实现预测:


新加入的结点对于其所在模式图的结构信息未必与数据图中的对应结点完全相同,但是其结构信息却可以以不同的概率对应到中不同种类的结点中。
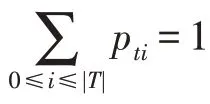

其中,⊕为按位异或操作,两个序列中对应位置的元素相同则取值为1,否则取值为0。
至此已实现了多结点模式图的匹配基数估计。
3.5 预测补偿
由于上述预测过程是一个使用预测值生成新的预测值的过程,未免会有误差累积的问题。为了补偿这种累计误差,引入预测补偿器实现模式图的嵌入表示和累计误差的补偿,得到最终预测结果。
将定义为模式图中所有结构标识的集合。对预测结果补偿时,首先将模式图嵌入表示为长度为||的向量:

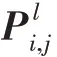
由公式向量的每一个元素分别对应一个结构标识。

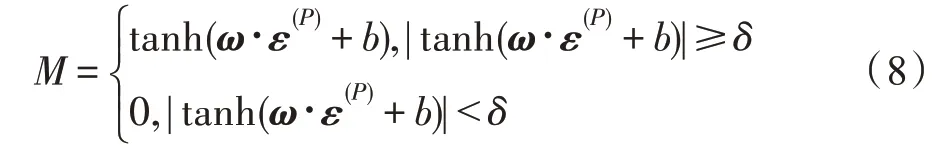
式中,∈[0,1],为补偿阈值,用以控制发生错误补偿的情况,该值为超参数,取值越大,对错误补偿的抑制越强。和为模型参数,下面通过训练获取对于特定数据图的上述参数。
根据上述预测过程,能够得到任意一组模式图在给定数据图中的匹配基数估计值。同时,也可以通过实际执行精确匹配来确定其真实的匹配基数。对于实际值大于预测值的模式图,将其标签标记为1,即M=1,对于实际值小于预测值的模式图,将其标签标记为-1,即M=-1。


其图像如图3 所示。
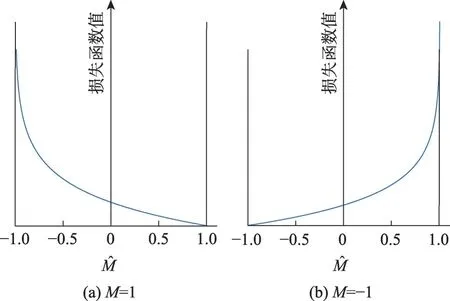
图3 损失函数Fig.3 Loss function
4 实验
BoostCard 方法主要应用于模式图在单张大规模数据图中的匹配结果基数的预测。本章展开实验来评估BoostCard 方法对匹配基数的预测能力。
4.1 实验内容
实验采用经典的大规模图数据Yeast 数据集、Human 数据集和Facebook 数据集以及使用graphGen工具人工生成的数据图作为测试数据。在上述数据集中随机生成结点数分别为2、3、4、5 以及10 的子图作为匹配的查询集。在本实验中,所有生成的模式图均为无环的树状图。
对于获取的数据集,采用VF2 算法执行匹配过程,记录每组查询图在相应的数据图中的匹配结果数作为匹配数据的真实值。在实际匹配的过程中,认为模式图中结点的属性应与数据图中被匹配结点的属性完全相同。
通过获得的上述数据训练BoostCard 预测模型。分别使用传统的统计方法以及BoostCard 预测方法对数据的匹配结果进行预测,比较执行结果。
传统统计方法通过式(10)计算结点的选择度:
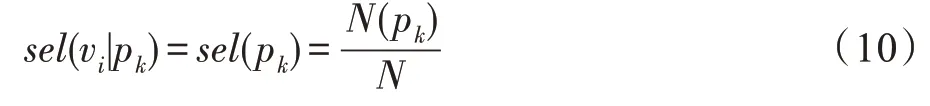
并通过式(9)计算一条边在数据图中的预测基数。
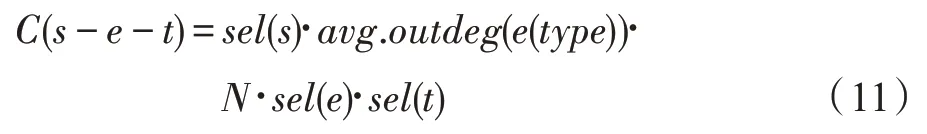
在多结点的预测过程中,预测按照结点游走的顺序进行,每加入一个结点,将已经预测的部分看作一个新的结点,与下一个待匹配结点形成一个新的短路径,直到所有结点完成匹配。该方法将作为本文的基准方法。
将每组模式图随机分为5 组,进行五折交叉验证,并取平均值作为一次实验结果,实验重复5 次,得到5 组结果,最终输出5 次实验结果的平均值。为了在训练及预测中,使输出值更加均匀,对匹配基数做对数处理,这样也更能表现匹配基数的数量级。接下来,将每个查询结果对应的数据图与模式图作为预测模型的输入,执行匹配基数估计。
为了评估预测的准确度,实验采用两个评价指标:平均平方误差()、决定系数()。决定系数通常用来衡量回归任务的拟合程度。其计算方式如式(12)所示,越大,表示模型的拟合程度越强。当值为负时,表示模型无法解释拟合中的变异,即模型不适用于相应数据的拟合,实验中以“—”表示。

4.2 实验结果
通过预测结果与匹配实际值的对数均方误差评估预测的准确率。预测值如表1 所示,由图4给出。在结点较多的情况下,由于匹配基数的增大,匹配结果真值的方差随之增大,通过进行评估反映得预测准确度的精度会有所下降,但由于同一组实验中的不同方法采用的是相同的数据集,值的大小仍可用以比较两种方法的准确度。在给定的数据集中,传统预测方法在仅有两个结点的模式图中优于BoostCard 方法,其主要原因是BoostCard 方法中的结构索引等结构信息对单边的预测会造成一定的影响,对统计信息直接应用的传统方法在单边预测的情况下反而更加准确。但是,在传统的方法中,随着结点数的增加,预测结果的分布很快变得不可控,在超过3 个结点的查询集中甚至出现值为负的情况,预测结果与实际值难以成正线性关系,难以满足实际需求,而在一定的范围内,BoostCard 方法在多结点数据中仍能提供较稳定的估计值。

表1 预测r2 值Table 1 Estimated r2 values
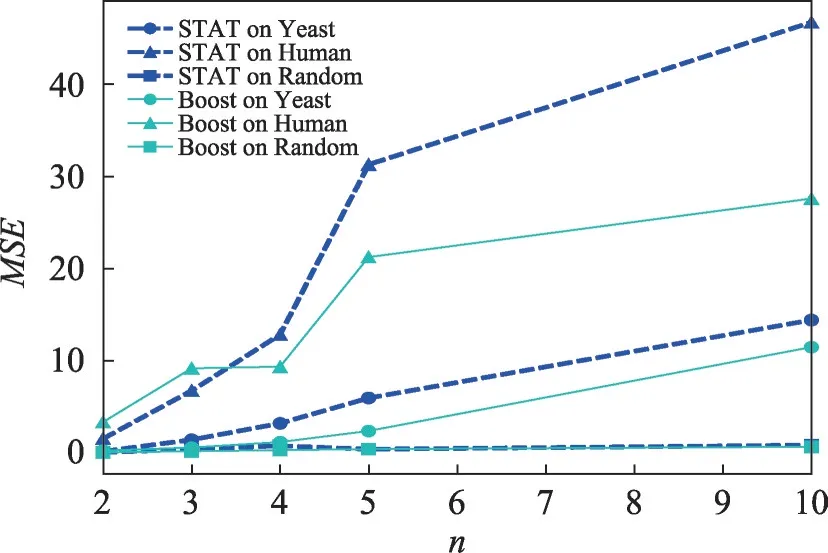
图4 估计均方误差Fig.4 Estimation of mean-square error
4.3 预测补偿准确率
本节通过调整阈值对预测补偿器的执行效果进行评估。在BoostCard 预测方法中,在进行初步的基于概率的技术预测后,模型会通过机器学习方法对结果进行补偿性预测,如3.5 节所述,这个过程可以看作一个分类问题。当实际值大于初步预测值时,预测补偿因子>0,反之,<0。为了避免错误方向的补偿,采用阈值来限制补偿的执行。当且仅当预测补偿因子的绝对值||>时,执行预测补偿。
实验针对Human 及Facebook 数据集展开,研究的不同取值对正确执行补偿的影响,通过设置不同的值研究补偿结果。在实验中,如下定义准确率()并以此为评估依据:
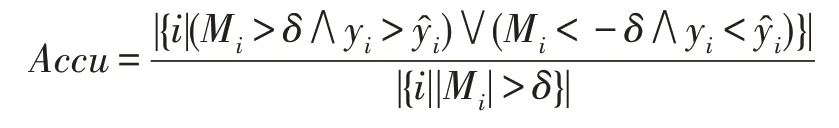
评估结果如表2 所示。

表2 预测补偿器准确率Table 2 Accuracy of estimation compensation
图5 展示了Human 数据集中,对含有5 个结点的模式图集进行预测时,准确率与执行率随阈值取值变化的影响。图像显示,随着增大补偿预测的准确率有所升高,但是可执行的补偿越来越少。阈值减小,将允许更多的预测结果执行预测补偿,但有可能导致最终预测更加偏离真实值。

图5 预测补偿准确率与正确执行数Fig.5 Accuracy and recall of estimation compensation
5 结束语
子图匹配的基数估计任务在图数据相关领域的研究工作,尤其是图数据库执行效率优化方面发挥着重要作用。本文从统计学的角度结合集成学习的思想对图数据中的结构邻域信息进行建模并实现子图匹配基数的预测。文章提出的BoostCard 方法能够运用图数据中结点邻域的结构信息来提升预测过程的拓扑信息的利用率,在结点数目有限的模式图中给出较高的预测准确度,实现了一种通用的匹配基数估计架构。为了提高预测模型对全局信息的应用,BoostCard 方法通过全局的结构索引信息对预测结果进行进一步补偿,并提供一个可调节的阈值控制补偿力度,以应对不同特征的数据集。相对于传统的预测方法,BoostCard 方法能够在结点较多的模式图的匹配任务中实现更加稳定的表现。
BoostCard 方法同样可以应用到各种索引编码中,以表示模式图中更加丰富、细化的结构特征。文章采取的结构索引实质上相当于一个星形特征的索引,现有的子图匹配索引技术提供了链状、树状、环状等多种结构特征。这些结构特征将为提升学习提供更全面的学习依据,这也是未来工作中有待进一步考虑的问题。
猜你喜欢
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
小型微型计算机系统(2021年10期)2021-02-28
计算机与数字工程(2019年10期)2019-11-12
文萃报·周五版(2019年13期)2019-09-10
计算机与数字工程(2019年3期)2019-03-26
现代计算机(2019年2期)2019-03-02
小学生必读(中年级版)(2018年6期)2018-09-05
劳动保护(2015年6期)2015-06-16
数理化学习·教育理论版(2009年6期)2009-07-31
