
多模型融合的海量网络流量并行异常检测方法
2022-03-22 08:36牛勇钢
中国民航大学学报 2022年1期
韩 萍,张 寒,方 澄,牛勇钢
(中国民航大学电子信息与自动化学院,天津 300300)
互联网行业的快速发展在给人们带来便利的同时,也带来了网络安全隐患。当前,网络攻击呈现体系化趋势,具有攻击范围广、命中率高、潜伏时间长等特点。大数据时代网络攻击问题变得更加突出,由于数据量愈加庞大,网络安全监测愈加困难。如何从海量网络流量数据中实时、高效、准确地挖掘出异常网络数据,并快速定位攻击数据和采取应急防御措施是亟待解决的问题[1]。异常检测作为大数据挖掘的常用技术之一,可用于识别定位离群或异常数据,并从异常数据中挖掘有价值的信息[2]。在海量网络流量数据中,研究针对大规模网络流量数据的实时、高效异常检测方法具有重要意义。
根据不同特征的处理方式,网络流量异常检测方法可分为:基于数据本身特征或行为的检测方法、基于数据统计的检测方法、基于数据聚类分析的检测方法和基于数据邻近度的检测方法。基于数据本身特征或行为的检测方法是通过在网络流量数据中查找、匹配出与异常流量数据特征相关性更强的数据,从而检测出异常网络流量数据,但其仅能检测出已有流量数据的攻击类型,局限性较大。基于数据统计的检测方法依托数学统计分析出异常数据,该方法对单个离群点检测准确率较高,但在多维数据条件下其精度很难达到应用要求。基于数据聚类分析的检测方法则将数据量少的簇或不能聚类的数据看作异常点,在海量网络流量条件下,算法复杂度和误判率较高[3]。基于数据邻近度的检测方法对参数较敏感,花费时间较长,对于海量网络流量数据的处理代价较大,且难以处理局部密度变化较小的异常信息。
综上,单一的异常检测方法已不能满足海量数据的检测需求,多模型融合的异常检测方法已成为该领域的研究热点。Ke 等[4]将遗传算法和BP 算法进行融合,但计算耗时长。Kuang 等[5]将主成分分析(PCA,principal component analysis)算法和支持向量机(SVM,support vector machines)算法进行融合,虽然提高了异常检测准确率和召回率等检测指标,但串行的计算方法在处理海量数据时效率低下。Hadoop 的流行使得分布式架构成为处理海量数据的新方法。文献[6-7]利用MapReduce 模型实现了算法的并行性,提高了检测效率,但不能有效处理频繁迭代的计算。冯贵兰等[8]利用Spark 平台实现了KNN 算法的并行异常检测。李水芳等[9]基于Spark 平台实现网络流量的并行聚类分析,弥补了MapReduce 计算结构的缺陷,但其对于持续、快速到达的流式数据难以进行检测处理,不适合实时在线检测。
针对上述问题,利用机器学习和大数据技术提出一种多模型融合的流式并行异常检测方法。首先,根据网络流量特征训练生成多个异常检测算法模型,然后通过模型融合提高算法准确度[10],再将模型并行化,可在保证算法精度的基础上对海量流式数据进行分布式处理。其次,通过不断积累异常数据,从中提取异常网络流量数据的共有特征,建立异常网络流量黑名单,使用在线分析引擎工具对实时网络流量数据进行在线实时特征匹配,快速匹配出异常数据,显著提高了流式数据异常检测的效率。最后,以KDD CUP99 作为实例数据对算法模型的准确率和有效性进行验证,实验结果表明,该方法可显著提高实时网络流数据异常检测的准确率,同时还可提高大规模数据异常检测的效率。
1 相关工作背景
1.1 异常检测方法
机器学习异常检测方法种类较多,为了能够对网络流量数据进行全面检测,可选用以下算法。
1)主成分分析算法
主成分分析算法通过寻找违背数据间相关性的数据点来确定该点是否为异常数据[11]。网络流量数据的属性值类别众多,且各属性间存在一定的关联,由PCA 原理可知,该算法不仅可将原始高维空间数据映射到低维空间,并保留数据集中对方差影响最大的属性特征,还可通过某个数据点的方差大小来判断其是否为异常离群点,因此可将PCA 算法作为融合模型选择之一。
2)孤立森林算法
孤立森林(IF,isolation forest)算法通过判断样本点的离群度来检测出异常值,当样本点距离正常值越远,则越可能是离群点[12]。在网络流量的异常检测中,IF 算法对离群点有较好的检测效果,但当离群点数据与正常数据掺杂在一起时,IF 算法的检测效果就会大打折扣[13]。由于IF 算法在全局数据的检测性能较好,故而选择将其作为融合模型选择之一。
3)局部异常因子算法
局部异常因子(LOF,local outlier factor)算法是通过计算数据样本点的局部可达密度来反映样本中某个数据点的异常程度[14]。LOF 算法仅依赖于局部可达密度,对于全局数据特征的利用率较低,有很大的检测局限性。但由于已经将IF 算法进行融合,两种算法的互补可进一步提高对全局和局部离群点的检测。
对以上3 种算法的融合,可对离群数据全面检测。
4)逻辑回归算法
异常检测在实际应用环境下需要人工进行再次验证,并根据实际情况进行阈值设置,使实际应用满足准确率和效率的双重需求[15]。逻辑回归(LR,logistic regression)算法可将判别结果映射为对异常检测的概率估计,方便调整检测结果阈值和对特征重要性进行选择排序,因此可以将LR 算法作为融合模型的最终输出。
单一模型不能满足算法精度的要求,实际应用中多采用模型融合的方法来提高检测的准确率和稳定性。Stacking 算法是一种常见的融合算法,其可将几个简单模型进行融合,从而集中各单模型的优势,达到提升准确性和鲁棒性的目的。
1.2 海量流式处理架构
在实际网络环境下,流量数据来源广泛、规模庞大且产生速度快,因而对数据的实时高效收集、发送及处理分析要求更高。网络流量数据的实时流处理包括3 层,如图1 所示。

图1 海量数据处理架构Fig.1 Massive data processing architecture
1)数据收集层
采用Apache Kafka 作为海量网络流量的数据收集端。Kafka[16]是一个分布式、高吞吐量、高实时性的发布-订阅服务系统,具有实时性强、基于磁盘的数据存储、可拓展性强等优点,可实现数据信息的实时流式收集和处理。
使用Kafka 集群对数据流进行分类接收和发送,同时根据数据量大小考虑横向增减Kafka 节点,可满足生产环境网络流量的数据接收需求,避免造成数据的阻塞、丢失或冗余。
2)数据处理层
使用Spark Streaming 接收Kafka 发送的流式数据,对接收到的流式数据进行实时批处理,提高海量网络流量数据的处理能力。
Spark Streaming 作为Spark 中的一个内置库,同样具有Spark 计算框架的优势:①基于系统内存进行计算,减少数据与存储磁盘间的通信,提高计算速度;②计算的基本数据结构是抽象弹性分布式数据集[17](RDD,resilient distributed datasets),具有容错机制,并支持数据并行处理,可对数据进行持久化和分区;③RDD 提供了大量的Transformation 和Action 操作来支持常见的数据运算,相比MapReduce 只有Map 和Reduce 操作,Spark Streaming 具有更丰富的算法实现选择性。由此可见,使用Spark Streaming 处理架构可满足海量网络流量数据的实时处理需求。
3)数据存储层
随着网络流量内容的不断丰富,属性特征不断增多,传统的数据库强调数据完整性和一致性,不能满足实际生产管理中实时应用的需要,而非关系型数据库又不能对复杂表进行关联和查询,因而两者都不能满足多维查询、高效分析的需求。Kylin 是一个具有预计算能力的分布式数据仓库,基于Hadoop 部署,能进行多维关联分析,可以达到数据查询的亚秒级响应。
Kylin 有两个关键技术:Cube 模型预计算和交互式查询。Cube 模型是所有数据维度的组合,是由一张事实表和一张或多张维表构成的星型数据存储结构。事实表用于存储所有的数据维度和各维度数据值,维表用于存放某一特定维度的元数据。通过选取满足自身需求的数据维度,建立Cube 模型预先进行数据分析计算[18],并通过SQL 语句实现对Cube 的交互式查询和定位。相比于Hive 等数据仓库,Kylin 可以提升网络流量分析的精确定位和快速查询等能力。
2 实时流式并行异常检测算法实现
2.1 算法实现流程
传统串行的机器学习算法处理大规模数据时,处理速度会降低。针对此问题,采用Kafka 和Spark Streaming 为主体的大数据实时处理框架,实现多模型融合的实时流量并行异常检测,并建立异常流量黑名单,使用黑名单匹配可以极大地提高检测的效率和准确率。算法实现流程如图2 所示,包括本地训练和模型实时预测两大部分。
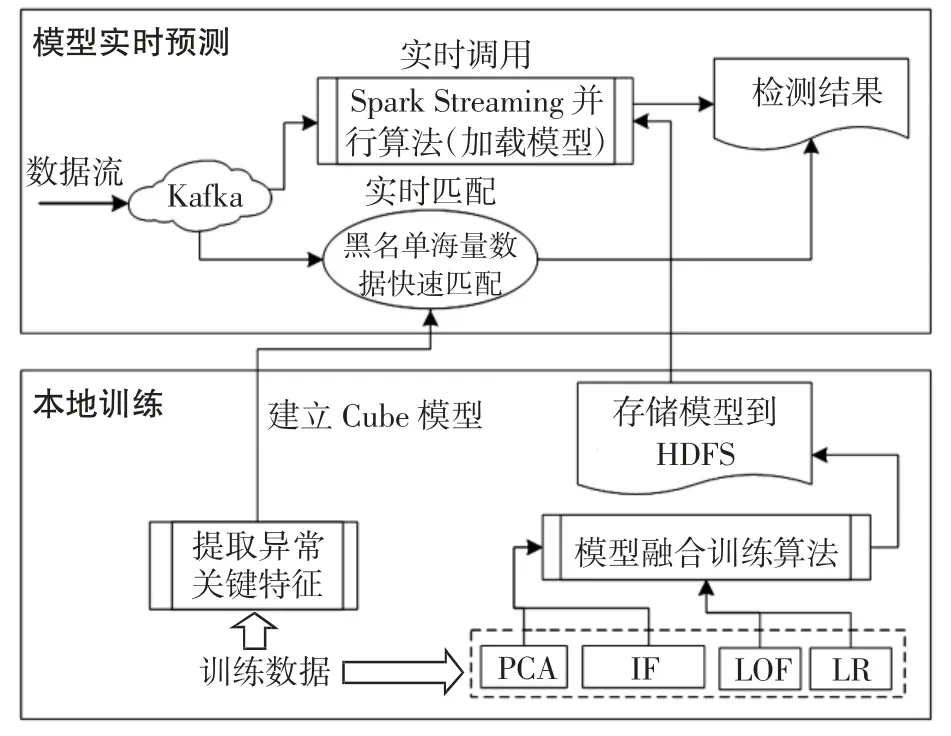
图2 实时流式并行异常检测流程Fig.2 Flow chart of real-time streaming parallel anomaly detection
本地训练主要是建立Cube 模型和模型融合训练,前者需进行特征提取,利用算法识别结果提取关键特征,生成黑名单。模型融合训练首先分别对PCA、IF、LOF和LR 算法模型进行单独预训练,然后使用融合算法将单一模型进行融合,最后将融合模型保存到分布式文件存储系统(HDFS,hadoop distributed file system)中。
模型实时预测包括黑名单数据匹配和Spark Streaming 实时预测计算。Spark Streaming 接收由Kafka 发送的数据,同时调用保存的融合模型对数据对象进行实时并行异常检测,最后将计算结果保存到HDFS。
在采用模型检测的同时,将已知异常数据当作初始黑名单库,使用关联匹配方法检测出异常数据。通过分析数据相关性,提取异常流量数据的关键特征,建立Cube 模型。数据分析平台实时接收来自Kafka 的数据,与黑名单数据进行关联匹配,将匹配度高的流量数据作为疑似恶意流量数据,并进行人工验证,不断扩充黑名单样本,提高异常匹配的准确率。
2.2 模型融合提升过程
为保证算法的普适性,提升整体性能,需将单模型进行融合。本地训练过程采用Stacking 算法对多个单模型进行融合,如图3 所示,主要分为两个阶段[19]。
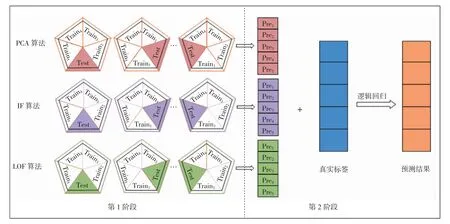
图3 Stacking 算法模型融合训练过程Fig.3 Model fusion training process of Stacking algorithm
第1 阶段训练单一的异常检测模型,再通过五折交叉验证进行模型融合。首先将数据集划分为5 个训练子集Traini,i=1,2,…,5,选取Train1作为测试集(Test),Train2、Train3、Train4、Train5作为训练集对PCA 算法模型进行训练,Test 对基础模型做测试,得到预测结果Pre1,然后选取Train2作为Test,Train1和Train3、Train4、Train5作为训练集对PCA 算法模型进行训练,Test 对基础模型做测试,得到预测结果Pre2,以此类推,最终得到5 次PCA 模型完整的预测结果Prei,i=1,2,…,5。同理,对IF 算法模型和LOF 算法模型重复上述操作进行训练,得到相应的预测结果。
第2 阶段通过LR 算法对上层融合结果进行概率估计。LR 算法是一种广义上的线性回归分析预测模型,利用回归分析方法对数据中有强依赖关系的数据特征进行提取,其基本数学表达式为
y(x)=w1x1+w2x2+…+wnxn+b (1)式中,xi表示第i 个样本特征,如果样本有n 个特征,构成特征向量x=[x1,x2,…,xn]T;wi为xi的对应参数,构成一个n 维的向量w=[x1,x2,…,xn]T。通过方程求解得到w和b,即

将第1 阶段得到的训练集预测结果与真实标签组成矩阵向量,得到一个(PrePCA,PreIF,PreLOF,Label)特征矩阵,经过LR 算法进行预测,并通过Logit 函数预测结果的概率值。对式(1)做Logit 变换,可得

式中z=w1x1+w2x2+…+wnxn+b,对式(3)左右两边各取对数,得到

从而得到当y 分别取值为1 或0 时的概率p,即

至此,可对检测结果阈值进行调整,当p(y=1)大于既定阈值时,可判断为正常值,否则判定为异常值。
通过调节单一异常检测模型参数及实验对比发现,当IF 模型的n_estimators 设定为100、max_samples设定为256 时,模型结果达到相对最优值;当LOF 模型的leaf_size 设定为30、n_neighbors 设定为80 时,模型达到最优值。将PCA、IF、LOF 算法模型和融合后的模型分别提取出模型文件保存。
2.3 流式并行计算算法设计与实现
利用Kafka 和Spark Streaming 分布式架构实现数据和算法模型的流式并行计算。当Spark Streaming 收到Kafka 发来的网络流量数据时,首先对数据集进行缓存,将海量流量数据划分为m 个子集Data1,Data2,…,Datam,通过Spark Streaming 分布式装载到RDD 中,对RDD 进行内存缓存。然后对RDD 进行分区,由于每个RDD 均由若干个分区组成,将所有的RDD 分为m 个分区,这些分区数据分布在各节点中。各节点使用算法模型对每个数据对象进行计算,把本地预训练的模型保存到集群的HDFS 中,通过Spark 的广播机制进行分发,广播流程如图4 所示,使每个计算节点都存有一个只读、可执行的模型。然后在每个分区中初始化一个模型计算器,加载分发得到的算法模型,通过逻辑回归计算每个数据的异常概率分数。最后将模型预测得到的结果返回给用户。数据在经过模型预测计算后,得到取值范围为(0,1)的异常分数,通过设置阈值评估预测异常数据,并将检测结果保存为数组形式存储在HDFS 中。

图4 Spark 广播模型Fig.4 Spark broadcast model
在单一模型训练和多模型融合阶段,均采用Python语言进行实现,而Spark Streaming 获取数据和广播模型均使用Scala 语言,因此在具体实现过程中,会面临不同开发语言之间的调用问题。代码实现主要利用SavedModelBundle 函数和Broadcast 函数,其中:Saved ModelBundle 函数用于加载Python 编写的训练模型;Broadcast 函数用于广播。检测算法实现流程如下:
步骤1配置调用Python 模型的依赖库,保证Python 可以跨语言平台运行;
步骤2配置Kafka 的生产者和消费者模型,保证数据的实时流式传输;
步骤3调用Scala 中的上下文接口Streaming Context,使得Spark Streaming 可以接收到来自Kafka消费者的数据;
步骤4使用Scala 的SavedModelBundle 函数加载训练好的Python 模型文件,然后利用Spark Streaming的分布式计算特性,使用Broadcast 函数将模型文件分发到各个计算节点;
步骤5各个计算节点借助模型文件,对来自Kafka的实时流式数据进行预测,最后将预测结果转换成数据列表的形式返回到用户端。
2.4 黑名单海量数据快速匹配
黑名单检测异常流量方法的关键是建立黑名单数据库,需对Cube 模型进行设计。Cube 模型的大小和预计算时间取决于数据的维度,数据维度越高,Cube模型越大,预计算时间越长,因而需对所有数据进行关联挖掘统计,找出与异常数据相关性最大的强关联规则。
以KDD CUP99 作为实例数据集,该数据集属性种类繁多,分为TCP 连接基本特征、TCP 连接内容特征、基于时间的网络流量统计特征和基于主机的网络流量统计特征。关联规则相关性的强弱通过支持度和置信度来进行判断,支持度是表示数据项集中同时含有特征项和数据异常的概率;置信度是在先决特征项条件下,关联结果数据异常发生的概率。通过线性回归算法挖掘数据之间的相关性,产生频繁项集{X1,X2,X3,…,Xn},将初始化线性回归模型作为特征提取容器,将异常流量标签作为提取目标,扫描训练集全局数据,提取相关性最强的属性信息,得到10 个关键特征如表1 所示。
然后,计算异常流量数据的支持度,设置支持度的最小阈值为3%,可进一步得到频繁项集为{protocal_type,flag,serror_rate,srv_serror_rate,rerror_rate,srv_rerror_rate,same_srv_rate};设置置信度的最小阈值为30%,可得关联性更强的频繁项集{protocal_type,flag,rerror_rate,srv_rerror_rate,same_srv_rate},该项集作为最终的强关联规则。
使用提取到的强关联规则设计Cube 模型所需的数据表单,从而建立黑名单库。将全局数据用作事实表,按照特征分类,设计两张维表,分别为TCP 连接基本特征维表(维表1)和基于时间的网络流量统计特征维表(维表2),每张维表包含相应的流量表单数据。事实表与各个维表构成星型结构的Cube 模型关联关系,如图5 所示。将设计好的Cube 模型经过MapReduce 引擎执行设定的计算程序,并存储在Kylin 分析平台的数据库中。

图5 Cube 模型表单设计Fig.5 Design of Cube model form

表1 提取出的异常关键特征Tab.1 Key anomaly features obtained
当海量网络流量数据经由Kafka 发送至分析系统中,系统会实时筛选出符合黑名单强关联规则的网络流量数据,相比并行检测算法,黑名单检测异常数据效率更高。检测出的数据经过人工进一步验证,若确定为异常数据,则扩充至黑名单,不断丰富黑名单数据内容,并及时优化强关联规则,提高检测网络流量数据的准确率。
3 实验结果分析
3.1 实验环境
实验测试环境在5 台服务器上搭建,每台服务器的基础环境配置相同,搭建了CDH 版本的Hadoop 集群。单台服务器的硬件参数如表2 所示,集群平台的安装版本信息如表3 所示。

表2 单台服务器硬件参数Tab.2 Hardware parameters of single server
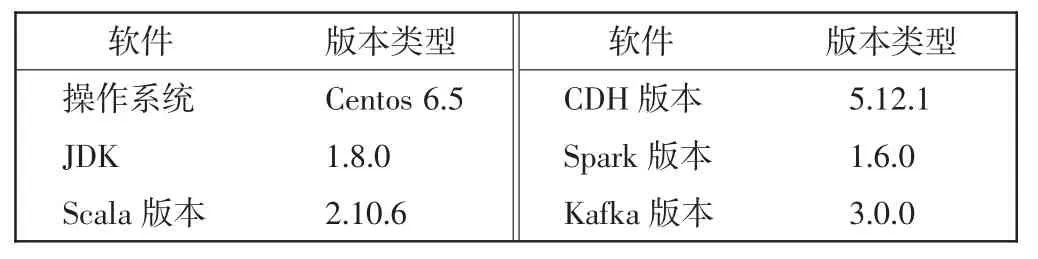
表3 集群平台组件版本Tab.3 Version of cluster platform component
3.2 异常检测算法性能测试
3.2.1 数据概要和预处理
使用KDD CUP99 数据集作为网络流量入侵检测数据集。该数据集是从模拟的美国空军局域网上采集9 个星期的网络连接数据,并提供训练集和测试集。训练集中共有101 384 条数据,其中异常数据4 107 条;测试集中共有62 970 条数据,其中异常数据2 377条。首先,将所有数据进行预处理,并对训练集和测试集进行二分类,然后使用训练集得到训练模型。为充分测试算法并行度,将测试数据集按一定比例划分为大小不同的3 组,并分别在原有数据规模的基础上进行10 倍采样复制扩充。测试子集分别表示为Test1、Test2和Test3,数据量分布如表4 所示。最后通过不同的测试子集对多种模型进行多组实验测试。使用不同规模的测试子集模拟实时产生的数据流,测试网络流量实时检测流程,判断网络行为是否异常。
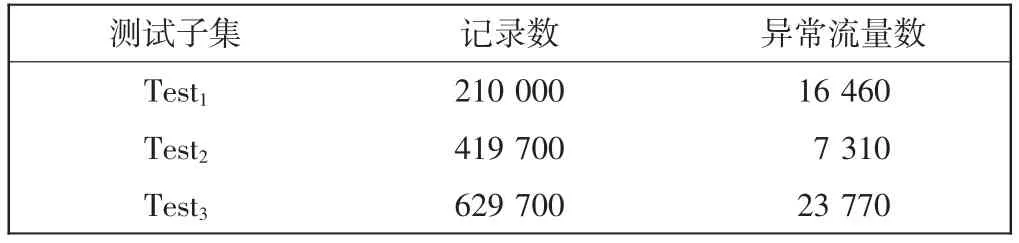
表4 实验数据集信息Tab.4 Information of experimental data set 条
3.2.2 算法有效性测试
在实验中选取准确率和召回率作为机器学习异常检测算法有效性的评价指标。

通过实验验证模型融合后算法的有效性,分别使用不同测试子集对单模型和融合模型预测的准确率和召回率进行对比,实验结果如表5 所示。
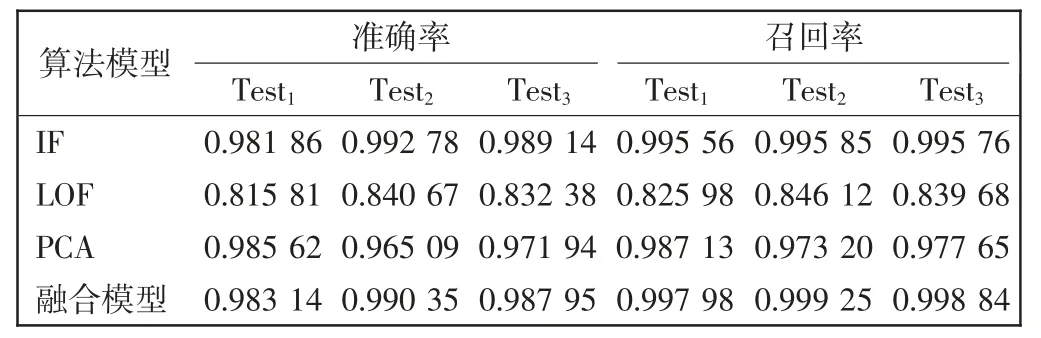
表5 不同模型性能对比Tab.5 Comparison of the performance of different models
从表5 可以看出,对于同一算法模型,不同测试集的准确率和召回率均有差别,IF 算法模型在所有单独模型中表现最好,稳定性最高。LOF 算法模型表现最差,准确率和召回率都比其他模型降低0.15 左右,原因是LOF 算法模型在局部检测表现更好,而异常流量在数据中的占比很小,对于边缘分布的数据更容易出现误判。而融合模型结合了以上各单模型的优点,在网络流量的测试中,其综合检测性能优于单模型。
针对Test3数据集,融合模型比单模型中综合表现最好的IF 模型在召回率上提升0.003 08。IF 模型检测出1 688 条异常数据,60 523 条正常数据,误判759 条数据;融合模型检测出1 950 条异常数据,60 336 条正常数据,误判684 条数据。在实际的生产环境中,特别是在网络流量异常检测中,更希望在保持准确率的前提下,识别出更多的异常数据。通过多次实验对比验证,融合模型比其他单模型稳定性更高,误判率更低。
3.2.3 算法并行化测试
为了评价融合模型在集群表现上的优劣,选择集群规模为1,分别测试4 个计算节点,在计算节点逐渐增加的情况下,考查融合模型完成检测任务的时间,并分析融合模型在不同数据规模下的可拓展性。通过Kafka 接收数据,使用Spark Streaming 实时流处理数据进行异常检测预测计算,实验结果如图6 所示。
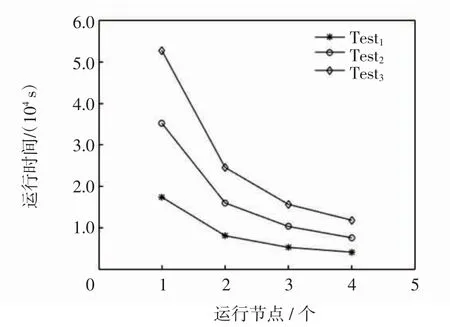
图6 可拓展性实验结果Fig.6 Experimental results of scalability
从图6 中可以看出,随着Spark Streaming 集群中计算节点的增加,3 个不同规模测试子集运行时间呈现明显的指数下降趋势,数据集规模越大,并行算法计算时间下降更加明显,这是由于Spark Streaming 是基于内存计算,大大减少了各节点之间磁盘通信和数据传递开销,使整个集群的运行效率更加稳定。实验结果表明,融合模型在大数据集上有很好的可拓展性,可应对现网网络流量数据的快速增长。
3.2.4 黑名单匹配测试
该部分实验主要是对黑名单检测的时间效率和准确率进行测试。首先对查询效率进行测试,将不同的测试子集分别存储在Kylin 和Hive 中,当搜索相同内容时,Kylin 与Hive 进行匹配查询的时间结果对比如表6 所示。
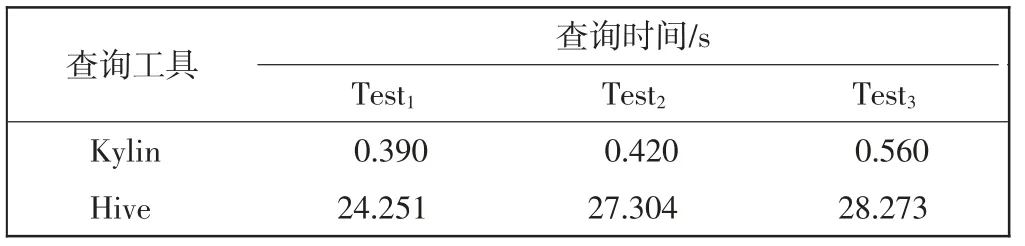
表6 查询时间对比Tab.6 Comparison of query time
通过表6 可以看出,与Hive 查询效率相比,使用Kylin 查询可以极大减少查询等待时间,查询速度提升明显。
然后对黑名单匹配部分和Spark Streaming 模型检测部分的检测时间进行测试。使用Kafka 分别读取Test1、Test2和Test3产生实时数据流,黑名单匹配部分所耗时间包括预计算时间和结果查询等待时间,Spark Streaming 模型检测部分使用4 个计算节点,3 个不同测试子集的检测时间对比,如表7 所示。
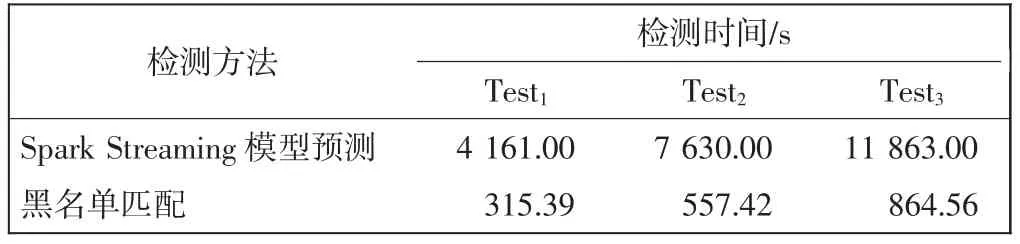
表7 检测时间对比Tab.7 Comparison of detection time
从表7 可以看出,黑名单匹配方法检测效率更高,是Spark Streaming 模型计算效率的10 倍以上。
最后,使用黑名单匹配方法对Test3测试子集进行准确率测试。从匹配结果得知,在23 770 条异常数据中可以检测出10 530 条疑似异常,其中9 530 条验证为异常数据,检测准确率为90.5%。综上所述,所有实验可以看出,黑名单匹配方法有较高的检测效率和漏检率,因此需要不断优化黑名单,以提高检测准确率。
4 结语
针对网络流量数据的异常攻击检测问题,实现了海量数据的流式并行异常检测算法。该方法使用Stacking 融合算法对IF、LOF、PCA 和LR 算法模型进行了融合,并借助分布式集群进行了大数据实验,测试了模型的有效性。借助Kylin 平台建立了Cube 模型以存储流量黑名单,实现了对异常流量数据的精准检测。经过实验测试,结果表明,融合模型在实际网络环境下具有很高的可行性和有效性,可达到网络流量异常检测准确率和效率双提升的目的。
虽然该融合模型提高了异常检测的准确率,但在模型融合的过程中,会经过多次交叉验证,从而增加了模型的训练时间,当Spark Streaming 使用该模型进行分发、预测训练时,会造成内存使用过大、数据阻塞等现象,后续工作将针对此问题进行改进研究。
猜你喜欢
好日子(2022年6期)2022-08-17
舰船科学技术(2022年10期)2022-06-17
好日子(2022年3期)2022-06-01
计算机应用与软件(2022年2期)2022-02-19
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
环境(2018年2期)2018-03-17
儿童故事画报(2016年7期)2017-02-08
