
关键姿态映射下视频动态帧目标定位方法
2022-04-19 00:45陈战胜
计算机仿真 2022年3期
范 洁,谢 鑫,陈战胜
(北京联合大学应用科技学院,北京 100101)
1 引言
现阶段计算机智能监控技术[1]的快速发展,视频序列中目标检测定位已成为现下图像处理领域的关键技术之一。随着科技的发展,人们想要获得的信息越来越多且信息的详细度要求更高,因此如何加强目标个体定位技术,以满足社会现实需求成为现下研究领域中较为重要的课题[2]。
相关领域专家得到的较好成果如下:文献[4]提出了一种基于扩展卡尔曼滤波(EKF)的目标定位算法。根据视频平台锁定跟踪目标的特性,对同一目标进行多次测量。依据组合姿态信息结合地球椭球模型,确定目标的视轴指向,建立状态方程和测量方程,最后利用扩展卡尔曼滤波实现视频目标定位。但是该方法的视频目标姿态映射效果较差,应用过程较为复杂,导致目标定位结果存在较大误差。文献[5]针对目标快速运动、遮挡等复杂视频场景中,目标跟踪鲁棒性差和跟踪精度低的问题,提出一种基于多层卷积特征的自适应决策融合目标识别跟踪算法。首先提取卷积神经网络(CNN)中帧图像的多层卷积特征,改善网络单层特征表征目标信息不全面的缺陷,增强算法的泛化能力;同时使用多层特征计算帧图像相关性响应,提高算法的目标姿态跟踪精度;最后该方法使用自适应决策融合算法将所有相应中目标位置决策动态融合以定位目标。融合算法综合考虑生成响应的各跟踪器历史决策信息和当前决策信息,以保证算法的鲁棒性。该方法的视频目标姿态跟踪效果较好,但是存在复杂度高、定位精度不理想问题。
虽然上述两种传统方法能够对视频动态帧中目标进行定位,但在实际操作过程中,都具有定位精度不够理想且未有效消除噪声干扰导致定位不精准。基于此,提出新的关键姿态映射下视频动态帧目标定位方法。根据核密度估计理论建立非参数模型。获取连续多帧微分法确定像素点和背景模型的概率分布,使方法在一定程度上克服了诸如光、振动等因素的干扰,并且定位精度更高。
2 基于高斯密度估计的视频关键姿态背景模型
2.1 核密度估计
核密度估计[6]在一般情况下作为数学估计方面的数理统计工具,在图像领域中该方法不用图像背景的特征分布形式,也能在核函数统计结果中选取出合适的数据矩阵,并且求解出矩阵中每个不同的概率分布,然后根据结果构建出数据样本以及空间中的分布模型。
在目标区域的个体划分和提取特征过程中,由于存在外界非自然环境影响和自然噪声干扰,取得结果不够精准。而常规方法往往忽略了先验知识步骤,导致在样本足够的情况下,核密度估计无法逐步收敛。因此本文首先设定先验知识,使所提方法在视频通用性方面更有效地提取动态目标。
假设存在某一维空间,并且空间数据点有n个,用R=(x1,x2,…,xn)表示,在R集合中取独立分布随机变量,而对应变量是一个完全满足于分布密度函数的条件变量p(x),那么在任意x(x∈R)的核密度估计为

(1)
式(1)中K(·)为核函数,而n和h则分别表示数据点数量与光滑参数[7],以每个采样点为中心的局部函数加权平均效应为数据块的估计概率密度函数值。在实际计算的过程中,K(·)都会选择以零为中心点,且具有部分支撑点的概率密度函数取值,核函数具体取值如下表1:


(2)
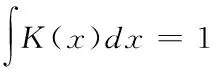
这样根据式(2)便可得知核密度估计,是由视频序列中每个像素进行加权平均处理后得知概率密度分布[8]的,而高斯函数则可以表述出样本概率的具体分布密度,从而可以确定函数的平滑、连续和最小密度,以便对小样本产生良好估计效果。那么式(2)可以进一步写为

(3)
2.2 核函数带宽和方差的选择
在实际应用中,核函数的带宽取值是非常重要的,因为该取值会直接影响计算的最后结果以及图像显著性区域检测的精准度。样本密度分布曲线可能有较大波动,如果带宽取值过大,那么便会呈现出一种平滑现象。因此,需要获得任意连续帧样本绝对差和平均值:
其中,连续帧样本中值m=median(|xi-xi+1|),假设xi服从高斯分布N(μ,ς2),那么(xi-xi+1)同样服从于N(0,2ς2)的高斯分布,根据正态分布的对称性及中位数的定义得Pr(N(0,2ς2)>m)=0.25,因此标准差可得
参数曲线被分为四个调整区域,它们分别是:高光、亮调、暗调、阴影。我们可以通过曲线区域下方的三个三角形滑块控制这四个区域覆盖的影调范围。向左移动第一个三角,即缩小阴影区域,扩大暗调区域;其他区域以此类推。当我们将鼠标移动到曲线上方,当前的可调整区间则会被高亮显示出来。单击并拖动鼠标即可对对应区域进行更改。

(4)
2.3 视频关键姿态背景模型的构建
在同一特定图像序列中,背景图像通常是相同的。因此,在实际应用中,像素值较长、较为稳定则为背景像素。如果像素的当前值与背景值匹配,可以改变阈值,达到提取背景信息的目的。
通过对每个像素点的概率进行研究,利用上述公式确定的模型计算帧中像素点的概率分布P(x),如果分布概率p小于默认阈值T,则将像素分类为前一个风景点,否则,程序可以隔离背景并识别剪辑中的动态目标。阈值通常是根据实验列中使用的视频序列来确定的,因此有

(5)
由于视频序列中的场景是不断变化的,为了适应视频序列的变化,保证目标提取的准确性,需要不断更新背景模型,在核密度模型中。一般情况下,使用当前帧图像代替原始帧图像作为新的样本,使背景更新方法便于对背景样本中采集的透视像素进行分类。其中连续帧差分[9]计算求解的结果将会作为下一次更新视频序列的前提。若在下次计算的过程中,活动点是固定的目标动态,那么视频像素将不会发生改变,而原始的像素样本就需要在保持原有位置的基础上对其进行改变,用来当作背景板的样例。
假设It-1,It-2,It是固定时间t-2,t-1,t中的动态图像,那么针对三帧图像同步进行的运算式就有

(6)
在三个消解帧中提供运动像素,分析两帧之间的差异,并从第一帧中提取活动帧的运动区域。如果运动目标存在,且在短时间内出现,则可以有效避免将背景像素作为前像素进行检测,减少误识区域。它可以减小目标的运动和跟踪区域。
(7)
根据上式结果,对前景图像目标没有变化的视频帧进行统计,并在一定基础上设置阈值th,当实际的统计数值高于指定阈值时,那么就可以认为前景视频动态图像的像素是一直保持在静止状态的,这样就可以将其重新投放到新的背景中,根据检测出来的显著性区域M、M1以及M2即可获取出新的视频关键姿态背景模型

(8)
3 关键姿态映射下视频动态帧目标定位
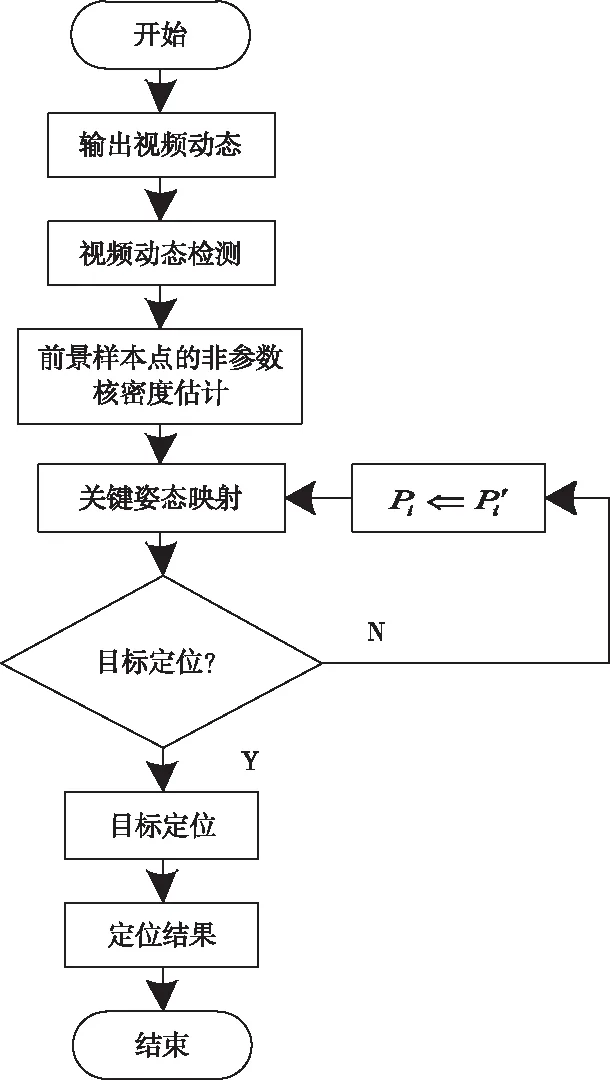
图1 目标定位流程图
假设如果m维空间同时拥有着n个数据点(x1,x2,…,xn),并且其中任意一个姿态数据点都可以将其看作为视频目标中心点,那么就可以将数据点xi出的密度指标判定为

(9)
结合上式的计算结果,根据减法聚类算法[10]思想,当计算求解出所有数据点的密度指标后,便可选取出其中一个密度指标最高的节点来作为第一个关键姿态,本文设定xc1为该目标中心,而Pc1则是其对应的核函数密度指标,这样任意数据点xi的指标便可根据下式做出对应的改变
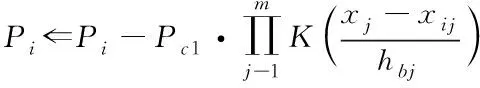
(10)
这里hbj(j=1,2,…,m)为常数,一般情况下hbj=ηhaj,其中将η描述为大于1的正常数值,防止出现距离较近的两个目标中心。
当视频动态中数据点的核密度指标[11]出现变动后,将其中密度指标最大取值设定为待定位视频中目标个体,在此期间利用不断的迭代获得最优目标中心,Pi<ε·Pc1(0<ε≤1)为迭代终止指令。
在对视频动态目标进行定位的过程中,目标实际核密度取值在一定范围内是与图像数据点以及密集程度成正比的,根据这一特征点,便可用于描述视频目标的带宽参数。
假设通过计算获取出第一个目标中心点的数据点取值为x1时,与其相互对应的带宽值[12]便可标记为h1i,而Pc1则描述为数据点的密度取值,这样当第i个用于描述视频目标的带宽取值hij即可变换为hij=(pi/Pc1)·h1i。
4 实验结果与分析
4.1 实验样本采集
为验证论文方法的应用效果,设计实验。本次实验采用某时间段的交通视频监控图像作为实验测试样本,视频样本采集室内环境如图2所示。图3为视频样本中随机抽取的视频图像样本。

图2 实验样本采集环境

图3 实验样本
4.2 图像样本训练
为验证所提方法分析的视频序列像素点噪声概率密度的有效性,对样本视频图像进行两次训练,验证该步骤是否能够降低视频目标噪声。本次处理的视频帧数为30fps,实验迭代次数为25次,训练结果如图4所示。

图4 样本训练结果
依据图4实验结果可知,经过两次样本训练,视频图像的目标噪声得到了有效降低,说明所提方法的为所提方法分析的视频序列像素点噪声概率密度具有降低图像噪声效果,为方法的应用性验证提供依据与条件。
4.3 不同方法的视频目标定位
为验证提出方法的视频图像目标定位性能,设计不同方法动态帧目标定位精度对比实验。本次实验的样本视频图像中包括多目标,如行人、骑行人、行驶车辆,且存在多处交通危险点,利用该样本图像进行实验结果的验证具有可靠性。将文献[4]提出的基于扩展卡尔曼滤波(EKF)的目标定位算法、文献[5]提出的基于多层卷积特征的自适应决策融合目标识别跟踪算法作为实验的对照组,与提出方法进行对比分析,动态帧目标定位精度对比结果如图5所示。

图5 不同方法视频目标定位精度对比
由图5实验结果可以看出,文献[4]方法定位识别出的视频图像点为两处,但是这两个目标点仅有一个是交通异常点,另外一个目标为正常行驶车辆,说明该方法的视频目标定位精度偏低。与该方法相比,文献[5]方法定出出的视频图像目标更多,但是此时间点的交通状况的关键点没有进行定位,即交通事故点,说明该方法的定位应用效果不理想。所提方法的视频图像目标定位效果为图4的(c),从该结果中可以看出,所提方法的目标定位更为全面,对该监控视频中的交通事故、骑行危险者以及肢体冲突均完成的定位,具有较好的定位效果。这是因为所提反复噶采用高斯密度估计法构建了视频动态图像关键姿态背景模型,可以高精度提取动态个体目标关键姿态特征轮廓,以更高的准确度实现视频图像目标的定位。
5 结论
现阶段视频目标个体定位问题也成为了现下领域中较为重要的研究课题之一,但传统目标定位方法无法满足于当前基本需求,基于此本文在关键姿态映射的基础上,提出新的视频动态帧目标定位方法,采用高斯密度估计方法建立视频动态图像的背景模型,对视频序列中像素点的种质素值进行概率密度分析,提取动态目标,选择第一个目标中心,改变样本点的密度估计,达到实现目标位置的目的。实验结果表明该方法有效地解决了传统定位方法存在的问题,具有良好的定位效果。
猜你喜欢
卫星应用(2022年7期)2022-09-05
小哥白尼(军事科学)(2022年2期)2022-05-25
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
环球慈善(2019年6期)2019-09-25
红领巾·萌芽(2019年8期)2019-08-27
CHIP新电脑(2016年3期)2016-03-10
诗选刊(2015年4期)2015-10-26
电影新作(2014年5期)2014-02-27
阅读(中年级)(2009年11期)2009-04-14
