
基于PCA-BO-XGBoost的矿井回采工作面瓦斯涌出量预测
2022-04-28 04:24王媛彬李媛媛李瑜杰
西安科技大学学报 2022年2期
王媛彬,李媛媛,韩 骞,李瑜杰,周 冲
(西安科技大学 电气与控制工程学院,陕西 西安 710054)
0 引 言
煤炭是中国重要的能源[1],随着人类对煤炭资源的开采和使用,浅部地区的煤炭资源逐渐减少[2],埋深地下千米的煤炭将会成为往后开采的重要目标[3]。然而面对煤层瓦斯赋存环境更加复杂、瓦斯复合灾害更加严重以及开采难度更高的局面,准确预测深部矿井的瓦斯涌出量成为亟需解决的问题[4]。
在煤矿的开采过程中,回采工作面是矿井瓦斯涌出的主要来源,最易发生安全事故,尤其是工作面的隅角处通风效果差、温度和湿度较高,容易积聚瓦斯,被看作是瓦斯的重点防治区域。而瓦斯防治的首要目标是将瓦斯浓度控制在安全合理的范围以下,所以精准地预测瓦斯涌出量并实时根据瓦斯浓度采取相应的抽采措施,能够有效降低事故发生概率、减少人员伤亡和财产损失。因此,对回采工作面瓦斯涌出量预测方法的研究具有重要的意义。为此,众多学者对瓦斯预测进行深入的研究,旨在减少甚至是避免瓦斯事故的发生,为煤矿安全生产起理论指导作用[5]。
传统的煤矿瓦斯涌出量预测方法有分源预测法、矿山统计法等[6-7]。随着计算机技术的发展,在瓦斯涌出量预测方面,出现一些新的预测方法。如:灰色系统[8]、BP神经网络方法[9]、支持向量机方法[10]等。徐刚等人提出基于因子分析法和BP神经网络的预测方法对工作面瓦斯涌出量进行研究[11]。刘鹏等人针对CART决策树稳定性差的问题,对CART决策树进行改进,提出一种结合支持向量机的增强CRAT回归算法,并将该方法应用于瓦斯涌出量用预测,取得较好的效果[12]。肖鹏等人为提高瓦斯涌出量预测的精度,提出将小波包分解方法和极限学习机相结合,建立小波-极限学习机的瓦斯涌出量预测模型,为瓦斯涌出量时变序列的预测提供了新的思路[13]。温廷新等人将BP神经网络、粒子群优化算法(PSO)以及AdaBoost迭代算法相结合建立一种瓦斯涌出量分源预测模型,经实验分析该模型的平均相对误差要小于BP神经网络预测模型[14]。丰盛成等人为了准确预测回采工作面的瓦斯涌出量,提出PCA-PSO-LSSVM的瓦斯涌出量预测模型[15]。代巍等人将变分模态分解(VMD)方法、差分进化(DE)算法以及相关向量机(RVM)相结合,提出基于VMD-DE-RVM的瓦斯涌出量区间预测方法,获得较高的预测结果[16]。李树刚等人构建因子分析与BP神经网络相结合的瓦斯涌出量预测模型,实现对煤矿井下瓦斯涌出量的预测[17]。
综上所述,大量学者对瓦斯涌出量进行研究,在预测精度和效率方面都有所提高。但是仍存在以下两方面不足:一方面是煤矿井下环境较复杂且影响瓦斯涌出量的因素具有非线性的特点,使得预测精度的提高受到一定限制。另一方面是BP神经网络本身存在收敛速度慢和易陷入局部最优解等问题,导致预测精度不高。因此有必要在前人研究的基础上继续探索新的预测方法对瓦斯涌出量进行预测。针对瓦斯涌出量的因素具有非线性的特点,文中利用主成分分析法(principal component analysis,PCA)进行原始数据降维,提取瓦斯涌出量数据的特征信息;针对神经网络精度欠佳的问题,建立极端梯度提升(extreme gradient boosting,XGBoost)瓦斯涌出量预测模型;针对XGBoost模型中超参数难以确定的问题,将贝叶斯优化(bayesian optimization,BO)算法引入XGBoost中,建立BO-XGBoost预测模型,并且与随机搜索和网格搜索所建立的模型进行对比分析,验证贝叶斯优化模型在泛化性能和预测精度上具有优势。最后将PCA和BO-XGBoost相结合,建立PCA-BO-XGBoost的瓦斯涌出量预测模型。
1 主成分降维
主成分分析法(principal components analysis,PCA)的基本思想是通过对存在线性关系的特征变量经过线性变换组合成少数几个特征变量,变换后的特征变量叫做主成分。每个主成分都是通过对原始变量线性组合得来的,且各主成分之间是没有相关性的,虽然主成分的数量要少于原始的变量特征,但是主成分包含了原始数据的大多数信息,因此可以做到简约数据的作用,尤其是对较高维度的数据。假设有n个数据样本,每个数据样本都有m维的特征,则可以建立m×n阶的数据矩阵为
(1)
其中 矩阵X的每一列可表示为
(2)
对m×n阶矩阵X做线性变化
(3)
式中F1,F2,…,Fm依次为第1主成分,第2主成分, …,第m主成分。同时,还必须满足以下3个条件。
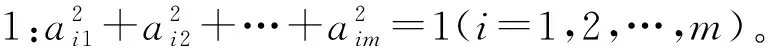
条件2:Fi和Fj(i≠j;i,j=1,2,…,m)之间相互独立,并且两者之间的协方差等于0。
条件3:Var(F1)>Var(F2)>…>Var(Fm)。
笔者利用主成分分析法对瓦斯涌出量数据进行降维处理,具体步骤如下。
1)对瓦斯涌出量的数据进行中心化处理。
2)计算样本的协方差矩阵。
3)计算协方差矩阵的特征值和特征向量。
4)选择主成分的个数,论文按照累计贡献率超过85%的选取原则选择主成分。
5)根据计算出的特征向量写出主成分的表达式。
2 预测模型的构建
2.1 XGBoost算法原理
XGBoost是一种由多个弱学习器叠加训练而成的集成算法[18],弱学习器一般指分类和回归树。XGBoost中每棵树拟合的是前一棵树与真实值之间的残差,依次迭代直至达到停止条件,最后对所有树的拟合结果累计求和值,得到最终的预测结果。
令数据集D=(xi,yi)(|D|=n,xi∈Rm,yi∈R),m表示特征维数,n表示样本数量。假设某个模型由K棵树组成,则
(4)

XGBoost算法的目标函数由训练误差项与约束正则项2部分组成
(5)

(6)
式中T为子树叶子节点的个数;ω为叶子节点的分数组成的集合;γ和λ为系数。

(7)
式(7)表示,模型的输出结果等于前t-1次的输出结果加上第t棵树的输出结果。于是,在第t次时,目标函数可以写成
(8)
目标函数经过二阶泰勒展开后近似结果为
(9)
式中gi为误差函数的一阶导数;hi为误差函数的二阶导数。
在使用XGBoost模型进行预测的过程中,如果训练数据太多,需要先进行数据筛选或通过降维方法来剔除无效数据,减少特征数量,否则模型容易过度拟合;相反,如果变量太少,容易产生欠拟合现象。因此,数据样本的多少对预测结果的精度至关重要。
2.2 贝叶斯优化
贝叶斯优化算法(bayesian optimization algorithm,BOA)是基于概率学中“贝叶斯理论”的一种黑盒优化算法。BOA在运行某一组超参数时,会考虑前一组超参数的优化结果,以此可以更有效地得到最优的参数解。有2个核心部分,分别是先验函数(prior function,PF)和采集函数(acquisition function,AC)。文中的先验函数采用高斯过程,采集函数采用概率提升(probability of improvement,PI)函数来提高模型的泛化能力。贝叶斯优化流程如图1所示。
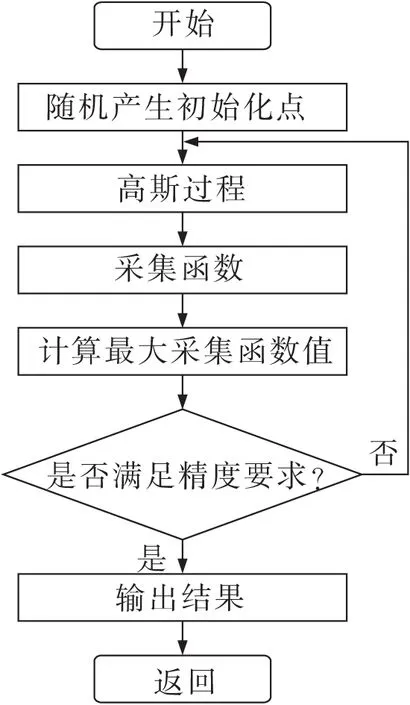
图1 贝叶斯优化流程Fig.1 Bayesian optimization flow
2.3 瓦斯涌出量预测流程
建立基于PCA-BO-XGBoost的瓦斯涌出量预测模型具体的算法步骤如下。
1)瓦斯涌出量数据的预处理。利用公式(1)~(3)对11种影响瓦斯涌出量的因素进行降维处理,并把降维后的数据分为训练集和测试集。
2)确定预测模型中的超参数值。设置XGBoost模型中待确定的超参数寻优范围,在此基础上笔者采用BAO对超参数进行寻优以确定最佳的超参数。
3)训练XGBoost预测模型。根据上一步骤中寻优的结果,设置XGBoost模型中超参数的值,同时将训练集数据输入到XGBoost模型中,以此得到训练好的瓦斯涌出量预测模型。
4)瓦斯涌出量预测。根据第3)步得到的预测模型,将测试集数据输入到该模型,得出预测的结果,并对该结果进行分析和评价。
基于PCA-BO-XGBoost的瓦斯涌出量预测流程如图2所示。

图2 基于PCA-BO-XGBoost瓦斯涌出量预测流程Fig.2 Flow of gas emission prediction based on PCA-BO-XGBoost
3 实验及分析
3.1 瓦斯涌出量数据降维
实验数据采用黄陵二号矿的历史样本数据,随机采样130组样本构成测试集,其中每个样本包括了11种瓦斯涌出量影响因素。瓦斯涌出量的影响因素众多,例如开采煤层瓦斯含量、开采技术、地面大气压变化等,文中采取最主要的2种因素,即地质因素和开采技术因素,其中地质因素包括煤层埋藏深度、煤层厚度、煤层瓦斯含量、煤层倾角、邻近层瓦斯含量和煤层间距;开采技术因素包括日进度、日产量、采高、工作面采出率和工作面长度。部分原始数据见表1。煤层埋藏深度X1(m)、煤层厚度X2(m)、煤层瓦斯含量X3(m3/t)、日进度X4(m/d)、日产量X5(t/d)、煤层倾角X6(°)、邻近层瓦斯含量X7(m3/t)、煤层间距X8(m)、采高X9(m)、工作面采出率X10(%)、以及工作面长度X11(m),预测的目标为绝对瓦斯涌出量Y(m3/min)。

表1 瓦斯涌出量影响因素部分数据Table 1 Partial data of influencing factors of gas emission
表2是选取不同数量的影响因素进行预测后产生的结果与原始数据之间的误差对比。可以看出,影响因素减少,模型预测精度会随之降低。对于11种瓦斯涌出量影响因素本身存在的数据重复、冗余问题,进行相关性分析,得到各因素之间的相关系数矩阵见表3。表3展示了瓦斯涌出量的影响因素间的相关性大小,不同因素间存在相关性大小不同,如果直接使用上述数据对瓦斯涌出量进行预测势必会增加预测模型的复杂度。因此,需要对原始数据预处理,从而达到精简影响因素的目的。主成分分析法作为数据降维最常用的方法之一,在瓦斯涌出量预测领域中运用比较广泛。与其他算法相比,PCA在数据处理上降维效果明显,且处理时间较短,实用性较强。因此,笔者利用主成分分析法对11个影响工作面瓦斯涌出量的因素进行数据降维,得到的主成分对不同的影响因素分配不同的权重系数,选择满足要求的主成分个数,即预测模型的输入变量,并将这些输入变量继续作为后续工作中学习器的输入。降维后的结果如图3所示,各成分累计的方差贡献率见表4。
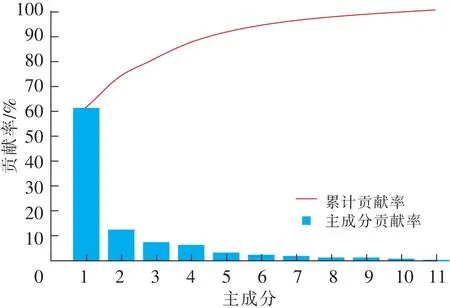
图3 主成分分析法的数据降维Fig.3 Data dimensionality reduction diagram of PCA

表2 预测误差结果对比Table 2 Comparison of prediction errors
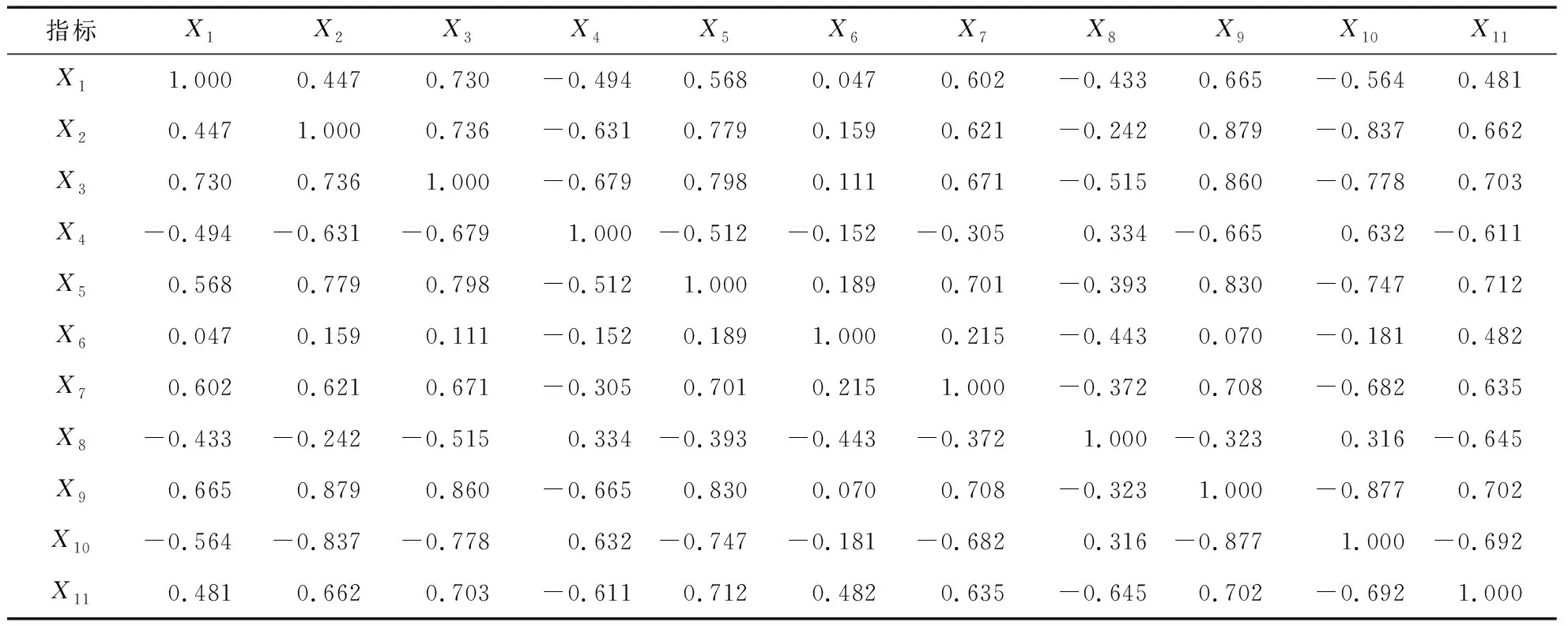
表3 样本的相关系数矩阵Table 3 Correlation coefficient matrix of samples
当主成分贡献率累计值达到85%以上,能够保证降维后的变量包含充分的原始信息。为了更充分地保证信息量,笔者在85%的基础上选取贡献率达到90%的主成分进行后续分析。由表4可知,前5个主成分的累计方差贡献率分别为61.307%,73.970%,81.277%,87.878%,91.541%,前5个主成分的累计方差贡献率超过90%,实验结果表明PCA对数据降维有明显效果,能够减少各因素之间的相关性所带来的影响,减少计算。因此,选取前5个主成分进行后续分析,各主成分的系数见表5,F1~F5为降维后的5个主成分。
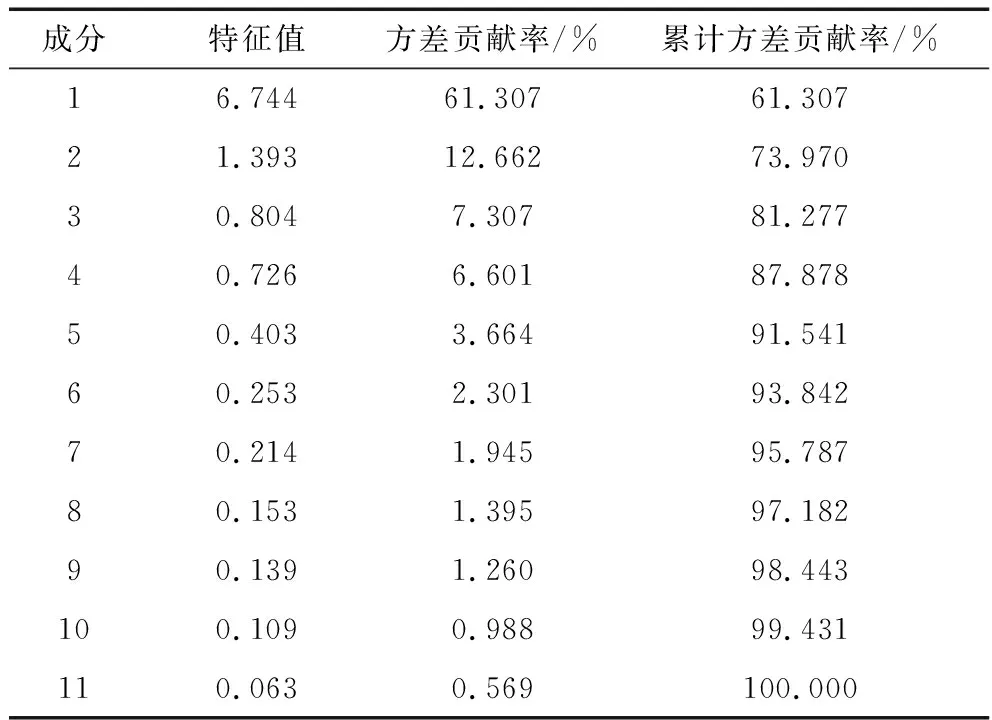
表4 各成分累计的方差贡献率Table 4 Accumulated variance contribution rate of each component
根据表5可以得到5个主成分的表达式,其公式如下

表5 主成分系数Table 5 Principal component coefficients
F1=0.723X1+0.857X2+0.918X3+-0.719X4+0.876X5+0.277X6+0.781X7+-0.543X8+0.932X9+-0.889X10+0.848X11
(10)
F2=-0.104X1+-0.216X2+-0.102X3+0.069X4+-0.084X5+0.829X6+-0.009X7+-0.636X8+-0.262X9+0.165X100.354X11
(11)
F3=-0.550X1+0.348X2+-0.176X3+-0.146X4+0.059X5+0.326X6+-0.129X7+0.386X8+0.065X9+-0.193X10+0.109X11
(12)
F4=-0.039X1+0.031X2+-0.099X3+0.619X4+0.187X5+0.103X6+0.510X7+0.145X8+0.017X9+-0.043X10+-0.033X11
(13)
F5=0.359X1+-0.074X2+-0.057X3+-0.134X4+-0.169X5+0.313X6+0.084X7+0.305X8+-0.009X9+-0.051X10+-0.135X11
(14)
5个主成分是对11个瓦斯涌出量影响因素进行线性变换得到,不会改变原始影响因素的客观存在。
3.2 XGBoost超参数寻优
XGBoost模型中含有大量需要设置的超参数,最主要的3类超参数分别是:常规的超参数、提升器超参数以及任务参数。一般情况下,常规的超参数和任务参数采用默认值,所以只需要对提升器超参数进行适当调整,达到优化模型性能的目的。由于XGBoost模型中的超参数较多,如果对所有参数进行优化,会给计算机带来巨大挑战,增加寻优时间。根据文献[19-20]的建议和实际情况,最终选择7个超参数作为待寻优的目标,设定的7个超参数取值范围见表6,其余超参数均保持默认值不变。

表6 XGBoost模型超参数设定范围及含义Table 6 XGBoost model hyperparameter setting range and meaning
为证明贝叶斯算法在预测模型中的优越性,笔者分别利用网格搜索、随机搜索和BOA对XGBoost模型的7个超参数进行寻优对比。综合考虑后选用均方误差和寻优时间作为寻优的评价指标,3种寻优算法的寻优结果见表7,算法性能对比结果见表8。
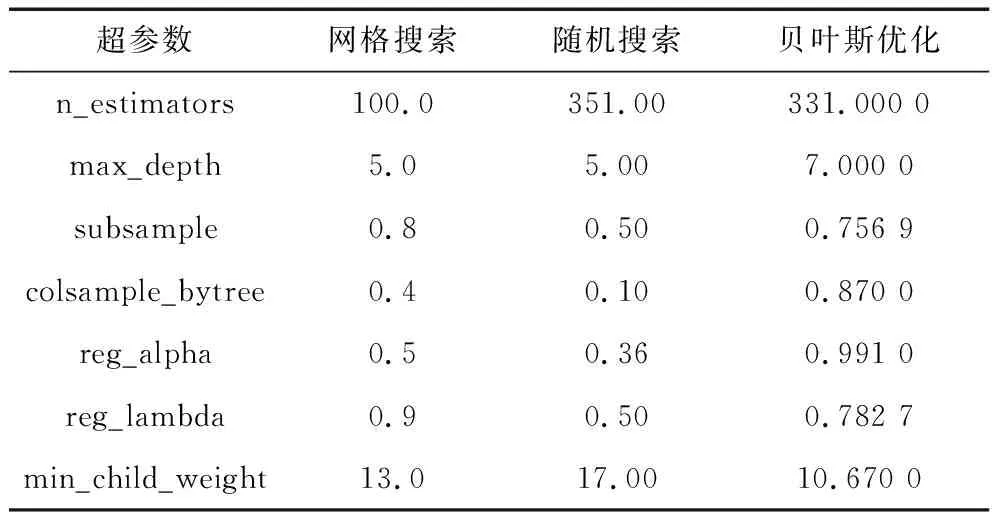
表7 3种寻优算法寻优结果Table 7 Results of three optimization algorithms
对表7的寻优结果进行分析,由不同寻优算法所得到的参数值相差甚大,这是随机搜索和网格搜索算法在寻优过程中陷入局部最优所导致的。结合表7和表8可知,相较于其他2种搜索算法,BOA在时间和均方误差方面上具有很大的优势,寻优时间为7.87 s,明显小于网格搜索和随机搜索,BOA的均方误差为0.009 16,同样在3种算法内达到最小。

表8 3种寻优算法性能对比Table 8 Performance comparison of three optimization algorithms
3.3 基于PCA-BO-XGBoost预测模型对瓦斯涌出量预测
由3.1小节中的PCA对130组瓦斯涌出量影响因素进行数据降维,得到的部分结果见表9。其中,F1~F5是经过PCA降维得到的5个主成分,Y代表瓦斯涌出量。将130组数据分为训练集(前100组)和测试集(后30组)输入到建立的PCA-BO-XGBoost预测模型中进行训练和预测。

表9 主成分分析法降维后的主成分数据Table 9 Principal component data after dimensionality reduction by PCA
为验证文中所建立的模型性能,分别建立PCA-XGBoost、PCA-BP以及PCA-SVM这3种预测模型与提出的预测模型进行对比,可以得到4种算法的预测趋势与原始数据的对比结果以及预测算法产生的误差如图4、图5所示。
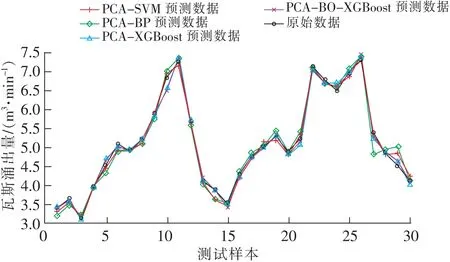
图4 4种预测算法与实际结果对比Fig.4 Comparison of results by four prediction algorithms and actual results

图5 4种预测算法预测误差Fig.5 Prediction errors of four prediction algorithms
从图4可以看出4种预测模型均与原始的样本数据保持大致相同的趋势,结合图5的预测误差结果进行分析,PCA-BO-XGBoost瓦斯涌出量预测模型的误差较低且总体变换趋势较为平缓。
为进一步验证PCA-BO-XGBoost模型的优越性,选取平均绝对误差和均方根误差2个评价指标进行误差对比,其结果见表10。结合表10进行分析可知,PCA-BO-XGBoost预测模型的平均绝对误差为0.070 3,是4种预测模型中最小的,与PCA-XGBoost预测模型、PCA-SVM预测模型以及PCA-BP预测模型相比,平均绝对误差分别降低1.29%,2.86%,6.27%。PCA-BO-XGBoost预测模型的均方根误差是0.095 7,与PCA-XGBoost预测模型、PCA-SVM预测模型以及PCA-BP预测模型相比,均方根误差分别降低0.92%,2.17%,8.88%。

表10 4种算法预测误差结果Table 10 Prediction errors of the four algorithms
分析上述试验结果,PCA-XGBoost模型的预测曲线要好于PCA-BP和PCA-SVM模型的预测曲线,证明XGBoost在精度提高方面更具优势。在此基础上,采用贝叶斯优化PCA-XGBoost中的超参数进一步减小了XGBoost的预测误差,对模型的预测性能有较好的提升作用,所以PCA-BO-XGBoost 预测精度要高于未经过优化的PCA-XGBoost预测精度。综上所述,建立的PCA-BO-XGBoost得到的预测变化趋势与实际变化最接近,不仅更加符合实际的变化情况,且具有更高的预测精度和泛化能力。
4 结 论
1)针对瓦斯涌出量影响因素过多的问题,利用主成分分析法对原始数据降维,有效减小输入数据的复杂度和各影响因素之间的重复、冗余,达到提高预测精度的目的。
2)选择BOA对XGBoost模型中的超参数寻优,同时与经典的寻优算法网格搜索,随机搜索进行对比实验,结果表明:BOA耗费时间最少,且优化后的预测模型均方误差达到最低。因此,建立了PCA-BO-XGBoost瓦斯涌出量预测模型。
3)通过仿真实验来验证瓦斯涌出量预测模型的性能,并利用PCA-SVM模型、PCA-BP模型和PCA-XGBoost模型进行预测结果的对比分析,该算法将平均绝对误差分别降低了1.29%,2.86%,6.27%,均方根误差降低了0.92%,2.17%,8.88%。实验结果表明,文中算法能够明显提升预测精度和效率,对矿井的安全生产实践提供一定的理论参考和指导,具有现实意义。
猜你喜欢
车主之友(2022年4期)2022-08-27
煤炭科学技术(2022年2期)2022-03-26
汽车实用技术(2022年4期)2022-03-07
煤矿现代化(2022年1期)2022-01-20
科学与生活(2021年25期)2021-12-02
今日农业(2021年17期)2021-11-26
海峡姐妹(2019年12期)2020-01-14
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
大陆桥视野·下(2016年5期)2016-07-05
