
用户行为序列个性化推荐研究综述
2022-05-10 08:45汪菁瑶吴国栋范维成涂立静李景霞
小型微型计算机系统 2022年5期
汪菁瑶,吴国栋,范维成,涂立静,李景霞
(安徽农业大学 信息与计算机学院,合肥 230036)
1 引 言
在信息过载的数字经济时代,用户不得不从海量的信息中寻找自己感兴趣的物品,如何快速且精准地从繁杂的数据中获取有价值的信息已然成为当前社会所关注的热点话题.推荐系统的目的在于帮助用户从海量的数据中,挖掘出用户感兴趣的目标数据.目前,推荐系统在很多领域得到成功应用,包括电子商务(如Amazon、eBay、Netflix、阿里巴巴等)、信息检索(如iGoogle、MyYahoo、百度等)、社交网络(Facebook、Twitter、腾讯等)、位置服务(如Foursauare、Yelp、大众点评等)、新闻推送(如Google News、GroupLens、今日头条等)等各个领域,并取得了良好效果[1].
在现实生活中,用户从进入到离开平台,通常会先后与多个物品产生交互,按照交互发生的先后顺序记录用户对每个物品的行为,这些行为所排列成的序列称为用户行为序列,现实生活中有大量以序列形式存在着的事物[2].传统的推荐系统主要是基于协同过滤算法和基于内容的推荐,他们大多根据用户和物品之间显性或隐性的交互来建模,得到用户的偏好,倾向于利用用户的历史交互来了解用户的静态偏好.然而,序列中前后不同的交互之间可能存在一定的依赖关系[3],且用户的偏好是动态的,其下一个行为不仅取决于静态的长期偏好,而且在很大程度上还取决于用户的短期偏好.另一方面,序列是由一组按照时间排序的随机变量组成,反映用户偏好的变化趋势,现有研究大多忽略了用户交互之间的顺序性,会导致对用户偏好的建模不准确.与协同过滤和基于内容的传统推荐方法不同,用户行为序列推荐考虑交互过程中的时序信息,利用数据之间的关联信息,有效捕获用户的偏好,提高推荐效果.近年来,序列推荐在学术研究和实际应用中日渐流行起来,每年计算机领域的相关顶级会议(如AAAI,WWW,SIGIR,CIKM等)中都能看到与序列推荐的相关研究,国内外很多公司(如阿里巴巴,YouTube,美团等)也对用户行为序列推荐系统开展了研究[4,5].同样,序列推荐也应用于多种领域,如音乐推荐[6],电影推荐[7],新闻推荐[8]等等.
用户偏好往往随时间变化而变化,本文对现有的序列推荐研究进行较为全面地归纳,整体框架如图1所示.将序列推荐分成3种:用户短期偏好序列推荐、用户长期偏好序列推荐和用户长短期偏好序列推荐.
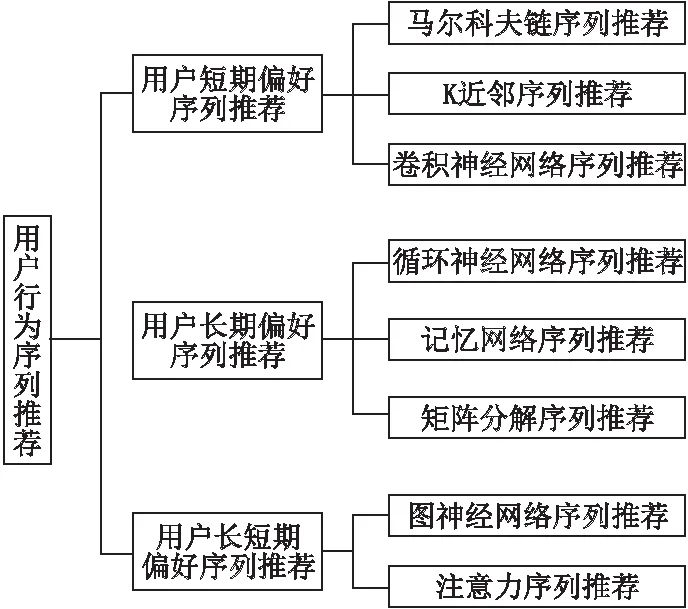
图1 用户行为序列推荐框架图
2 用户行为序列推荐概述
2.1 用户行为序列相关定义
2.1.1 用户及用户属性
用户是推荐系统研究的对象,是产生行为以及接受推荐结果的主体.通常用u表示一个用户,用户集表示为U={u1,u2,…,u|U|},|U|表示用户的数量.当用户注册登录时,每个用户通常都有一个唯一的身份信息(Identity Document,ID),且每个用户都有一组与其相关的属性,如年龄、性别等,这些属性能够让用户得到更好的推荐.当然,在序列推荐中,用户也可以在匿名状态下进行操作.
2.1.2 物品及物品属性
物品在推荐系统中作为被推荐的对象,是承受行为以及作为推荐结果的实体.通常用v表示一个物品,物品集表示为V={v1,v2,…,v|V|},|V|表示物品的数量.一般来说,不同的物品对应不同的属性,如对于音乐平台来说,物品对应的风格不同的乐曲,而在一些电商平台,物品对应的往往是一件商品.
2.1.3 用户—物品交互及交互属性
用户和物品之间的交互是序列中最基本的构成,可以将用户—物品的交互表示为一个三元组
2.2 用户行为序列推荐
用户行为序列推荐是以一组用户和物品的交互行为作为输入,通常是有序且带有时间戳的,通过对交互序列中复杂的依赖关系建模,预测用户后续可能会产生的交互,输出形式一般是排名前n项的物品列表,排名可以通过概率、绝对值或者相对排序来确定,大多数情况采用softmax函数生成输出.
序列推荐可通过式(1)所示的公式表示,其中,Su为用户行为序列,fRec表示用户行为序列的推荐算法,yu输出表示推荐给用户u的物品列表.
yu=fRec(Su)
(1)
用户行为序列推荐有两种代表性的任务:下个物品(Next-item)推荐和下个篮子(Next-basket)推荐.下个物品推荐中,只有一个推荐物品,这个物品可以是一首歌、一部电影或一个地点;但下个篮子推荐中则包含多个物品.
2.3 长期偏好与短期偏好
用户的偏好可以分成两种,分别是长期偏好和短期偏好.序列推荐中既存在像传统推荐算法一样捕捉到用户的长期偏好,同时也有对用户的短期偏好进行建模,近年来,随着深度学习技术的发展,越来越多的新技术应用到序列推荐中,能够同时考虑到用户的短期偏好和长期偏好,提高了推荐的性能.
用户的长期偏好通常是不易改变的,代表着用户的长期兴趣,一般包含在整个用户行为序列中,通过建模用户对物品的交互历史序列,尽可能地考虑用户行为序列的全局信息,因而能够捕获到用户的长期偏好[9].用户的短期偏好是随时间不断变化的,用户的短期偏好代表的是用户当前兴趣,通常由用户近期的交互行为所反映,通过建模包含当前交互的短序列或者会话,获得用户的短期偏好,这里会话是指一个时间段内发生的一组用户交互行为.
以线上购物场景为例,根据用户与物品的历史交互分析出用户可能是电子产品爱好者,因为他先后购买或点击了不同的电子产品,如手机、电脑等,可以推断该用户长期以来都对电子产品有着浓厚的兴趣,代表着用户的长期偏好.而若用户最近的交互是书籍,这代表着用户最近的兴趣可能是阅读,代表着用户的短期偏好.综合考虑用户的长期和短期偏好,可能会给用户推荐电子书籍阅读器,更符合该用户的兴趣.因此,结合两种类型的用户偏好为用户进行推荐,可以得到更好的推荐效果.
3 用户短期偏好序列推荐研究
3.1 马尔科夫链序列推荐
早期的序列推荐主要是依靠马尔科夫链(Markov Chain,MC),使用马尔科夫链对序列中的用户—物品交互数据进行建模,通过转移概率预测下一次交互.一阶马尔科夫链中,观测变量v的取值仅依赖于其对应的状态变量V,同时,t时刻的行为仅依赖于t-1时刻的行为,与此前的t-2个行为无关,即在推荐系统中的下一个交互仅由当前交互决定,不依赖于历史交互.
2005年Shani等人[10]首次将马尔科夫链应用在推荐系统当中,但是没有能充分利用用户的上下文信息.针对这个问题,Hosseinzadeh等人[11]将用户行为建模为隐马尔可夫链(Hidden Markov Model ,HMM)以捕捉用户偏好的变化,并将用户的当前上下文信息建模为模型中的隐变量.同样,Le等人[12]也是将用户行为建模为隐马尔科夫链,不同的是后者考虑了用户动态偏重排放(Dynamic User-Biased Emissions)等因素,例如不同用户在购买服装时都会考虑到季节,但是在每个季节所选择的服饰品牌是不同的.He等人[13]和Feng等人[14]使用一阶马尔科夫链,只考虑最后一次交互行为,而He等人在文献[15]中采用高阶马尔科夫链,考虑了最后几次的用户交互行为.虽然在高阶马尔科夫链中考虑了更多的历史交互的依赖关系,但还是无法在一个相对较长的序列中捕捉更多的行为之间的依赖关系,即无法体现用户的长期偏好,除此之外,处理稀疏数据表现也不好[16].
近年来,考虑到用户的偏好是多样的,Eskandanian等人[17]提出了一个基于HMM的推荐框架,该框架关注用户行为序列中用户偏好开始发生变化的首次交互位置且考虑用户偏好的多样性,使用HMM检测用户偏好变更点,并根据变更点对用户行为序列进行分割,不同片段代表用户的不同偏好,通过矩阵分解将这种检测方法集成到推荐模型中.同样,Shao等人[18]认为用户的历史行为序列中包含多种偏好,将分解用户历史行为序列看成马尔科夫决策过程,提出自适应分解用户偏好来构建序列推荐模型.
3.2 K近邻序列推荐
K近邻算法(K-Nearest Neighbor ,KNN)[19]简单,高效,可解释性强,被广泛应用在序列推荐当中[20,21].从原理上看,K近邻算法首先从序列数据中找出与当前交互或会话最相似的K个交互或会话.然后,根据相似度计算每个候选交互的得分,表示当前交互与历史交互的相似性,根据相似性的大小对用户进行推荐,相似度越高的物品,越有可能推荐给用户.
Linden等人[22]在2003年提出了一种算法,通过计算序列中物品之间的相似度,找到与用户当前购买物品最近邻域中的物品.K近邻相关算法会损失部分可用信息的重要部分,因此文献[21]融合了基于用户和基于物品的两种最近邻算法的优点,提出了统一最近邻协同过滤算法(K Unified Nearest Neigh,KUNN).但是该类算法[23]均只考虑序列中的最后一个交互,也就是只考虑到了用户的短期偏好.
相比之下,基于会话的K近邻推荐应运而生,计算当前会话序列与历史会话序列的相似度,得到K个邻居会话序列的集合.与基于物品的K近邻算法相比,基于会话的K近邻算法考虑的是整个会话序列,而不仅仅只是一个当前交互,因此可以获得更多的信息,进行更准确的推荐.基于会话的KNN推荐也衍生出很多变体,若仅仅只考虑最后一次交互物品的最近邻域,不考虑物品在序列中的位置和序列中的其他信息,忽视序列的历史交互,会影响推荐效果,为了解决这个问题,Garg等人[24]提出了一种序列和时间感知领域(Sequence and Time Aware Neighborhood,STAN)算法,该算法添加了序列的顺序和时间信息,当前一个会话中,离当前交互越近的交互权重应该越高,其中p(i,s)表示物品i在会话s中的位置,l(s)为会话长度,如公式(2)所示:
(2)
不同会话中,越早产生的会话权重应该越低,公式见式(3):
(3)
得到的邻域会话n中,i*是同时存在邻域会话和当前会话中的物品,与当前会话距离越近的物品,权重越高,见式(4):
(4)
此外,现有的循环神经网络不能直接捕获推荐场景中用户购买每件物品的次数,Hu等人[25]提出一种基于物品购买频率的KNN算法,充分利用率物品频率信息.RAC等人[26]对简单的基于KNN的推荐进行扩展,添加了语义因子,通过语义层的属性更好的适应用户偏好的变化.
3.3 卷积神经网络序列推荐
卷积神经网络(Convolutional Neural Networks,CNN)通常用于处理时间序列数据,其中典型的结构由卷积层、池化层和前馈全连接层组成,它适合于捕捉序列中局部信息的依赖关系.在序列推荐中,基于卷积神经网络的模型可以很好地捕捉会话中的局部特征,并且还可以在输入层加入时间信息.
Tang等人[27]提出一种卷积序列嵌入推荐模型(Convolutional Sequence Embedding Recommendation Model,Caser),结构如图2所示,模型由3个部分组成,分别是嵌入层、卷积层和全连接层,从序列中提取若干个连续项作为输入嵌入到神经网络中,使用水平卷积层和垂直卷积层捕获序列的局部特征,再通过全连接层得到更高级别的特征.卷积神经网络对当前序列的特征进行提取,模型没有直接从左到右单向结构来处理数据,而是整个将作为结构化的信息交给CNN来进行特征提取.
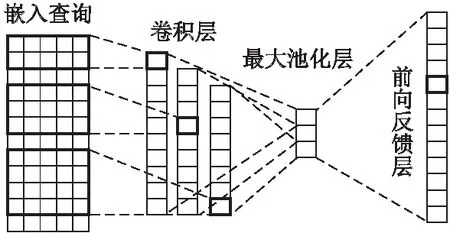
图2 Caser结构图
Yuan等人[28]对Caser模型进行了改进,Caser模型属于浅层网络,难以捕获复杂的关系以及对长期依赖建模,且在生成下一个物品时,Caser模型只考虑了最后一个物品的条件概率分布.针对该问题,Hsu等人[29]提出一种网络结构在用户嵌入层和水平卷积层与Caser模型非常相似,但没有加入垂直卷积层.文献[30]中进而设计三维卷积神经网络模型(3 Dimensional Convolutional Neural Network,3D-CNN),用一个嵌入矩阵来串联物品身份信息、名称和类别,使用三维卷积神经网络针对序列推荐中的用户—物品交互数据以及内容特征更好地进行建模.2019年,文献[31]提出一种2D卷积序列推荐(2D Convolutional Networkfor Sequential Recommendation ,CosRec),将序列中的物品编码成一个三维张量,使用二维卷积滤波器学习序列的局部特征.Yuan等人[32]继续进一步扩展,提出一个可以捕获物品高阶表示的模型,名为间隙填充推荐(Gap-filling based Recommender,GRec),主要结构是用层叠的空洞卷积(Dilated Convolutional)来扩大表示范围,并且使用剩余块结构优化深度网络,GRec模型利用基于间隙填充的编码器-解码器框架和掩码卷积操作,同时考虑过去和未来的数据,而不存在3D-CNN中的数据泄漏问题,但是GRec模型中使用的数据增强和自回归训练是训练序列数据常用的两种方法,这两种方法只考虑过去的用户行为,存在局限性.
表1归纳了本文中用户短期偏好序列推荐中的主要研究,从针对问题和主要优点方面进行了小结.

表1 用户短期偏好的序列推荐主要研究
4 用户长期偏好序列推荐研究
4.1 循环神经网络序列推荐
循环神经网络(Recurrent Neural Network,RNN)是一类用于处理序列数据的神经网络,在建模序列依赖关系方面具有独特优势,使得它在序列推荐中占据了主导地位,大量的关于序列推荐的建模都是基于循环神经网络的.但是RNN需要在很长的时间序列的各个时刻重复应用相同操作来构建非常深的计算图,并且模型参数共享,在经过很多阶段传播以后会出现梯度消失或爆炸问题,使得推荐时难以捕获序列之间的长期依赖关系.因而引入了门控循环神经网络,包括基于长短期记忆(Long Short-Term Memory,LSTM)和基于门控循环单元(Gated Recurrent Unit,GRU)的网络,以更好地模拟长期序列数据.文献[33,34]中使用RNN框架从用户的历史行为序列中学习用户的长期兴趣.有实验证明,考虑用户的长期兴趣对于个性化推荐是非常有价值的,例如,Quadrana等人[35]提出的层次化循环神经网络(Hierarchical RNN,HRNN)模型在某些场景下,如用户明确表示的情况时,比文献[36]提出的模型效果高出3.5%.
LSTM算法在建模用户序列数据时有很好的效果[37],GRU算法是LSTM的改进算法,它的结构更加简单,后来研究人员多将GRU应用在序列推荐中.文献[36]提出了一种基于GRU的序列推荐模型(GRU For Recommendation,GRU4Rec),是早期提出将RNN运用在序列推荐上的模型之一,与其他门控RNN的主要区别在于,单个门控单元同时控制遗忘因子和更新状态单元的决定,用于预测会话中的下一个用户动作,传统的推荐方法只能处理较短的序列数据,而不能处理较长的用户历史序列,很难获取用户的长期偏好,而GRU4Rec模型的在门控循环单元的帮助下对用户序列进行建模,图3显示了网络的总体框架,其输入是一组用户行为序列,将序列中的物品经过独热编码,输入嵌入层进行降维,然后通过多个GRU层和前向传播层,输出层通过softmax等函数计算每个物品的点击概率.
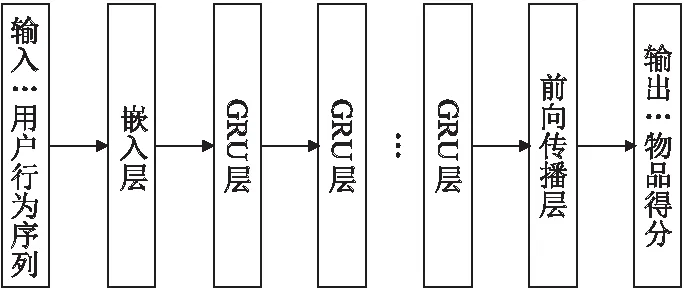
图3 GRU4Rec结构图
在GRU4REC的基础上,学者们提出了各种优化方案.Hidasi等人[38]考虑了用户行为序列中的更多信息,诸如图像、文本,并设计了新的基于RNN的网络模型,称为并行循环神经网络(Parallel RNN,P-RNN)来利用这些信息,实验效果也有了明显提升.2016年,Tan等人[39]针对GRU4REC提出了模型改进方案,主要体现在序列预处理的数据增强,以及嵌入Dropout方法增强训练过程,减少过拟合.Hidasi等人又在文献[40]中对GRU4REC算法中提到的采样和损失函数进行优化;而Bogina等人[41]将用户在序列中物品的停留时间长短考虑进去,停留时间越长,表示用户对该物品越感兴趣.Jannach等人[42]提出将KNN算法与GRU4REC模型结合,以提高推荐的效果.而文献[35]的贡献在于提出一种层次化的RNN模型,捕获会话内和会话间的依赖关系,相比之前的工作,可以刻画会话序列中用户个人的兴趣变化,达到用户个性化的会话序列推荐.
除了对GRU4REC模型的优化以外,还有基于GRU算法的变体.文献[43]中提出一种分层时序卷积网络(Hierarchical Temporal Convolutional Networks,HierTCN),从跨会话数据中动态学习以预测用户将选择的下一个物品,模型有两个部分组成:高层模型使用GRU来捕获用户在不同会话中不断变化的长期兴趣,而低层模型使用时间卷积网络实现,利用会话之间的长期依赖和短期互动,以预测下一次互动.
就仅基于RNN的序列推荐而言,当用户序列数据较少或者没有的时候,每一层只有固定的输入矩阵和转移矩阵,不能感知序列中上下文信息的变化推荐效果会变差,针对这一局限性,可以通过建模用户的上下文信息来解决.Song等人[44]提出一种增强循环神经网络(Augmented RNN,ARNN)模型,通过提取高阶的用户上下文偏好,以增强现有的RNN序列推荐模型.文献[45]中提出上下文感知循环神经网络模型(Context-aware RNN,CA-RNN),建模丰富的上下文信息,引入了上下文感知的输入矩阵和上下文感知的转移矩阵,使RNN每一层的矩阵参数随着输入上下文和转移上下文的不同而变化.类似的,Twardowski等人[46]认为时间也是一种上下文信息,将时间信息与物品信息相结合进行推荐.文献[47]提出预测用户未来行为轨迹的循环推荐网络(Recurrent Recommender Networks ,RRN),是通过RNN构建自回归模型来实现的,以适应用户的动态性.
Kumar等人[48]提出了循环注意力深度语义结构模型(Recurrent Attention Deep Semantic Structured Model ,RA-DSSM),利用双向LSTM有效获取序列中包含的信息.与RA-DSSM模型类似,文献[49]提出名为CHAMELEON的模型,其同样依赖RNN作为模型的基本组成,但是与RA-DSSM不同的是,RA-DSSM中不使用任何关于用户或物品的上下文信息,只依赖用户物品交互存在一定的局限性,限制模型在冷启动场景中推荐的准确性,CHAMELEON中添加了多种类型的边信息,包括文本上下文信息,如最近流行度等;还有用户上下文信息,如时间、位置等以缓解冷启动问题,而且CHAMELEON支持在线学习,训练过程中模拟流场景(Streaming Scenario).
而Dai等人[50]首次将时序点过程(Temporal Point Process)与RNN相结合,时序点过程有助于保留序列的时间信息和动态变化,不断地迭代更新用户和物品的嵌入表示.2018年,Vass∅y等人[51]提出时序分层循环神经网络(Temporal Hierarchical RNN ,THRNN),使用RNN分别对会话内和会话间关系建模,而利用时序点过程对交互时间预测.
4.2 记忆网络序列推荐
用户行为序列推荐中的记忆网络(Memory Network)推荐通过引入外部存储器捕获序列中的交互与下一个交互之间的依赖关系,利用记忆组件保存场景信息,以实现长期记忆的功能.
记忆网络比起RNN更适合建模长期序列,记忆向量的存储避免了直接存储长期行为序列,缓解存储压力,且记忆网络的读操作相较于GRU结合注意力的模型来说减小了计算压力.简单地将用户的历史序列信息嵌入到单个向量中,可能会丢失用户历史序列与长期偏好之间的相关信息.Chen等人[52]提出了一种用于序列推荐的记忆增强神经网络(Memory-Augmented Neural Network,MANN),结构如图4所示,该模型通过外部存储矩阵(Memory Matrix)存储用户历史行为序列,并进行有选择的读取用户历史交互,生成用户表征,避免对所有的历史序列进行操作,根据用户历史行为序列对于当前物品的重要性来选择历史交互物品,即计算历史交互物品的权重,权重与历史交互物品嵌入表示相乘以表示用户嵌入表示.从记忆网络中得到的用户嵌入表示与用户固有的属性嵌入表示进行合并得到最终的用户嵌入表示,将用户嵌入表示和物品嵌入表示输入预测网络,以预测用户购买当前物品的概率.
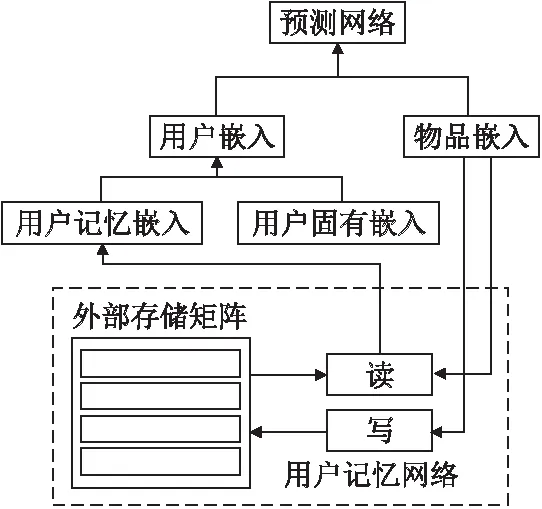
图4 MANN结构图
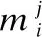
(5)
Wang等人[55]提出了一种基于会话的协同推荐机制(Collaborative Session-based Recommendation Machine,CSRM),CSRM由两个并行模块组成:内记忆编码器和外记忆编码器,分别建模当前会话序列和邻域会话序列,通过门控机制选择性的组合来自两个编码器的信息,以获得最终表示.对于过长序列,在提取用户长期偏好时,响应时间长且复杂度高,Tan等人[56]设计了一种基于记忆的动态注意力网络(Dynamic Memory-based Attention Network,DMAN),将长序列分割成多个子序列,使用记忆矩阵确定用户的长期偏好,对记忆进行更新,抛弃时间过久的记忆.
4.3 矩阵分解序列推荐算法
矩阵分解(Matrix Factorization,MF)试图将用户物品交互矩阵分解为两个低秩矩阵,从矩阵中获得用户和物品的隐向量表示,可以捕获用户全局兴趣.Rendle等人[57]通过矩阵分解处理隐反馈数据,并使用贝叶斯个性化排序来处理数据,随机梯度下降(Stochastic Gradient Descent,SGD)优化目标函数.文献[58]将矩阵分解和马尔科夫链结合提出分解个性化马尔科夫链(Factorizing Personalized Markov Chains,FPMC),FPMC是一个具有代表性的下一篮子推荐算法,对于一阶的马尔科夫链,用户的交互表示为一个三维张量,如图5所示,从中捕获一个物品到另一个物品的转换概率.每个用户都对应一个转移矩阵,来融合个性化和序列两个方面的信息,得到转移矩阵后,当给出上一次的购买物品时,可以预测下一次购买物品的概率.
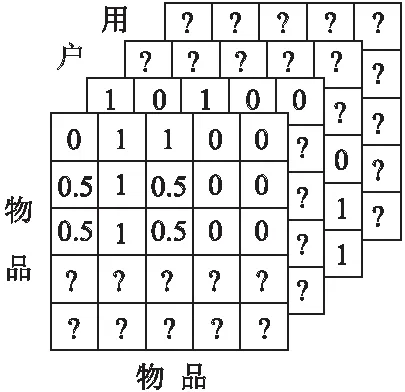
图5 三维张量图
除了上面介绍矩阵分解个性化马尔可夫链模型,还有很多其他的变体.例如,Liang等人[59]提出把矩阵分解和词嵌入(Word-embedding)的思想结合起来,提出了一个协因子分解模型(Co-Factorization ,CoFactor),通过分解用户—物品交互矩阵和具有共享物品潜在因素的物品-物品共现矩阵以获取用户的偏好和转移矩阵.Cheng等人[60]扩展了文献[59]的工作,设计了一种称为FPMC-LR的新的矩阵分解方法,通过添加约束来限制用户在一个局部区域的移动,利用局部区域的信息,大大降低了计算成本,而且还丢弃了噪声信息以提高推荐效果.其他一些类似研究[61,62]利用矩阵分解模型来了解偏好从一个地点类别到另一个地点类别的转变,从而提供地点推荐.
尽管FPMC模型取得了成功,但是随着数据量的增加,数据稀疏的问题没有得到解决,且存在大量的长尾分布数据,为缓解这些问题,因子物品相似性模型(Factored Item Similarity Models,FISM)[63]通过学习物品之间的相似矩阵来进行推荐,将两个未被同时购买物品通过第3个物品关联起来.在FISM模型基础上,文献[64]将FISM模型与高阶马尔可夫链相融合来完成序列推荐任务,提出了一种基于物品相似性的因式序列预测模型(Factorized Sequential Prediction with Item Similarity ModeLs,Fossil),与传统的矩阵分解和FPMC模型相比,该方法在稀疏数据集上表现得更好,模型的基本表示如公式(6)所示:
(6)
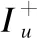
(7)
在实际的流场景中进行推荐存在一定的挑战性,具有数据量大和高速性的特点,且用户行为存在不确定性.2019年,Guo等人[65]设计了基于流式会话的推荐模型(Streaming Session-based Recommendation Machine ,SSRM),SSRM是一种基于矩阵分解的注意力模型,以应对流场景中的挑战,将矩阵分解引入到基于循环神经网络的会话编码器中,以建模用户的长期偏好.
表2归纳了本文中用户长期偏好序列推荐中的主要研究,从针对问题和主要优点方面进行了小结.

表2 用户长期偏好的序列推荐主要研究
5 用户长短期偏好序列推荐
5.1 图神经网络序列推荐
近年来,随着图神经网络(Graph Neural Networks,GNN)的快速发展,图神经网络[66]也被应用于序列推荐中,利用GNN建模和捕获用户—物品交互的复杂转换关系.通常,利用有向图构建序列数据,将图中的每个节点看成一次交互,同时将每个序列映射到一条路径中,然后在图上学习得到用户和物品的嵌入表示.Wu等人[67]首次将GNN使用在序列推荐中,提出基于会话的图神经网络推荐(Session-based Recommendation with GNN ,SR-GNN),模型整体框架如图6所示,将会话序列建模成图结构数据,使用GNN提取物品的嵌入向量,在经过注意力层后将长期偏好和短期偏好组合,预测点击下一个物品的可能性.
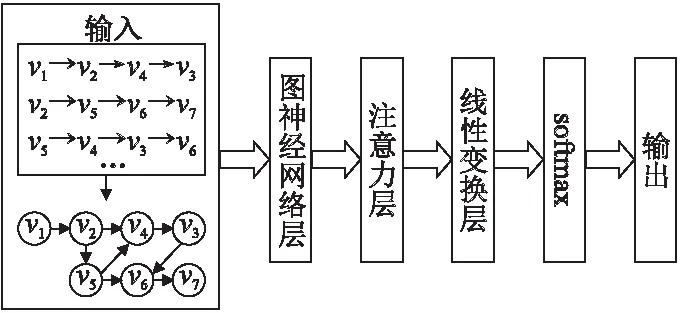
图6 SR-GNN结构图
与SR-GNN等模型相比,Wang等人[68]提出一种全局上下文增强的图神经网络(Global Context Enhanced Graph Neural Networks,GCE-GNN),分别从当前会话图和全局图中学习两个层次的物品嵌入向量,考虑了全局信息的影响,利用近邻节点进行图构建,并在具体的建模时通过合理的设计来最大化利用相关物品的信息,降低噪声物品的影响.与GCE-GNN模型不同,Qiu等人[69]提出全图神经网络(Full Graph Neural Network,FGNN)模型为每个会话序列构建一个会话图,并且提出多重加权图注意层网络来计算会话序列中物品之间的信息流,获得物品的嵌入表示.基于图神经网络的序列推荐存在信息丢失问题,Chen等人[70]提出的一种处理信息丢失(Lossless Edge-order Preserving Aggregation and Shortcut Graph Attention for Session-based Recommendation,LESSR)的模型针对这一问题进行了优化,首先,从会话序列到图的有损编码以及聚合消息传递期间不变的排列,会忽略有关会话转换的一些顺序信息;其次,由于层数的限制,无法捕捉会话中的长期依赖性.为了解决第一个问题,提出了一种无损编码方案和基于GRU的边缘顺序保留聚合层,该层专门设计用于处理无损编码图.为了解决第2个问题,提出了一个捷径图关注层,该层通过沿捷径连接传播信息来有效地捕获远程依赖关系.通过将两种类型的层组合在一起,能够缓解信息丢失问题并且在3个公共数据集上胜过最新模型.
Song等人[71]提出一种基于动态图神经网络的序列推荐,同时建模用户的动态兴趣和用户的社交关系,将两者结合起来,通过图注意力网络来捕捉社交关系对用户的动态影响,得到的向量和用户向量拼接得到最后的用户向量,最后得到下一个可能的物品的概率分布进行推荐.而动态图注意神经网络(Dynamic Graph Attention Networks,DGAN)[72]构建了一个动态注意模块来捕获全局信息,并进一步提出了一个递归神经模块来学习局部动态表示,通过堆叠多个动态图注意力模块,可以更好地利用每个序列的丰富上下文信息.Kumar等人[73]考虑到静态图的局限性,即无法建模用户节点或物品节点的变化,提出一种融合用户-物品动态嵌入表示的模型(JOINT DYNAMIC USER-ITEM EMBEDDING MODEL ,JODIE),JODIE将用户和物品的表示分为静态嵌入和动态嵌入,静态嵌入表示用户和物品的长期属性,而动态嵌入表示了用户随时间不断变化的属性,根据用户的交互序列动态更新嵌入表示,建模用户和物品的动态属性.
利用社交信息是提高推荐质量的一种重要方法,现有方法忽略了跨用户交互之间的时间关系,基于此Li等人[74]提出社交时间激励网络(Social Temporal Excitation Networks ,STEN),引入时序点过程,通过利用时间信息对相关跨用户交互的影响进行建模,构建社交异质图从社交关系结构和交互中提取用户和物品的节点表示.Chen等人[75]同样引入时序点过程用于缓解时间信息丢失问题,设计了一种动态表示学习模型序列推荐(Dynamic Representation Learning model for Sequential Recommendation ,DRL-SRe),将整个时间轴分割成等长的时间片,对于每个时间片,构建用户-物品交互图以获得更好的动态用户和物品的嵌入表示.
5.2 注意力机制序列推荐
注意力机制最早起源于Bahdanau等人[76]的研究,并将其应用于机器翻译任务中,它可以捕获语言中的长期依赖,并提供更流畅的翻译,强调输入的各部分对输出的影响程度不一样,即关注输入句子不同部分对输出词的重要性,在序列推荐系统中广泛使用的注意力机制已经也显示出巨大的成功.在此基础上,提出了将普通注意力(Vanilla Attention)作为循环神经网络的解码器,在序列推荐中得到了广泛的应用[77].另一方面,机器翻译模型Transformer[78]中的自注意力机制(Self-attention Mechanism)也被应用在序列推荐中,Transformer模型由两部分组成,分别是多头自注意力(Multi-head Self-attention)和全链接前馈网络(Fully Connected Feed-forward Network)部分,与普通注意力机制相比,自注意力不包括循环神经网络结构,但在推荐中的效果好于普通注意力机制.
5.2.1 普通注意力机制序列推荐
Li等人[79]提出的神经注意力推荐模型(Neural Attentive Recommendation Machine,NARM),原理是构建一个编码器-解码器框架,作者认为在之前的序列推荐中没有强调用户主要目的,所以将RNN与普通注意力结合,以捕获序列中的用户主要目的,NARM模型的框架如图7所示,其中输入x=[x1,x2,…,xt-1,xt]为用户点击会话,xi(1≤i≤t)为m个物品中用户所点击物品项的索引,输出y=[y1,y2,…,ym-1,ym]为用户可能点击的下一个物品项排名列表,yj(1≤j≤m)对应的是物品j的得分,编码器将输入的点击序列x转化成高维隐藏表示h=[h1,h2,…,ht-1,ht],其与t时刻的注意力信号αt一起输入会话特征生成器中,注意力信号决定在t时刻应该强调或者忽略那个物品,然后构建当前会话表示ct,并在t时刻输入解码器,通过解码器中的矩阵,并使用激活函数得到输出排名.
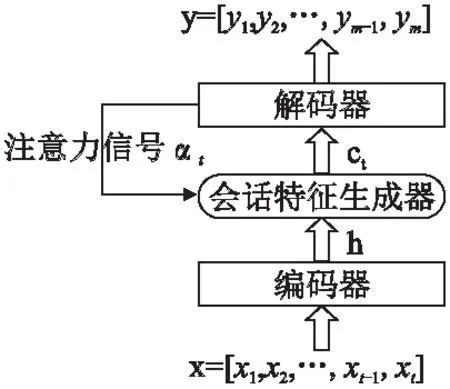
图7 NARM结构图
文献[80]对NARM模型进行了改进,调整了NARM模型的框架,增加了序列的上下文信息等优化方法,提高了模型的性能.Liu等人[77]设计了短期注意力记忆优先(ShortTerm AttentionMemory Priority,STAMP)模型,提出一种新的注意机制,根据会话序列的上下文计算注意力权重,同时捕捉用户的长期偏好和短期偏好.STAMP模型中需要分别获取用户的长期偏好和短期偏好,ms为用户点击序列的平均值,mt为用户的最后一次点击,表示用户的当前兴趣,如公式(8)、公式(9)所示.
(8)
mt=xt
(9)
而用户的长期偏好是通过简单的前馈神经网络(Feed-forward Neural Network,FNN)得到的,向FNN中输入ms和mt,得到每个物品的注意力,物品xi的注意力系数αi计算公式如式(10)所示,进而可以计算出用户的长期偏好mα,如公式(11)所示:
αi=W0σ(W1xi+W2mt+W3ms+ba)
(10)
(11)
其中W0为权重向量,W1,W2,W3为权重矩阵,ba为偏置向量,σ(·)为sigmoid函数.分别将ma和mt输入多层感知机(Multilayer Perceptron,MLP)中进行处理,以达到提取特征的目的,得到的隐表示向量分别为hs,ht.对于每个候选物品,计算得分公式如公式(12)所示:
(12)
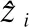
Wang等人[81]提出基于注意力的事务上下文嵌入模型(Attention based Transaction Embedding Model,ATEM)中将注意力机制整合到浅层的网络中,构建没有严格序列关系的上下文表示,由于注意力机制的有效性,该模型能够关注更多相关的物品,而较少关注不相关的物品.NARM[79]、STAMP[80]和ATEM[81]将普通的注意机制与RNN或多层神经网络结合起来,目的是在给定的会话中捕捉用户的主要目的.
除此之外,Ren等人[82]考虑到重复消费的问题,提出了基于重复消费的网络模型(Repeat Consumption with Neural Networks,RepeatNet),将重复探索机制与注意力机制融入到RNN中.Yu等人在文献[83]中提出一种多注意力排序模型,从多个角度将个体和联合级别的交互统一到偏好推理模型中,而Ying等人[84]提出了两层的注意力网络,第1层是根据历史购买的物品表示来学习用户的长期偏好,第2层通过耦合用户的长期和短期偏好来输出最终的用户表示.Wu等人[85]提出基于会话的上下文感知注意力网络(Session-based Recommendation with Context Aware Attention Network,SR-CAAN),通过将序列预测与会话外部上下文感知方法相结合,增强了对用户偏好进行建模的能力,将外部知识与知识图谱(Knowledge Graph)相结合,通过使用注意力机制来获取会话的外部上下文,每个会话都作为会话外部上下文的组合呈现.
5.2.2 自注意力机制序列推荐
文献[86]中设计了一种基于自注意力的序列推荐模型(Self-Attention based Sequential Model,SASRec),在每个时间步自适应地为之前的物品赋予权重.Zhang等人[87]利用自注意力机制从用户的历史交互中推断出物品与物品之间的关系,有了自注意力机制,用户交互序列中每个物品的权重就能更好地代表用户的兴趣,模型最后使用度量学习框架进行训练,既考虑了短期特征又考虑了长期特征.
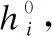
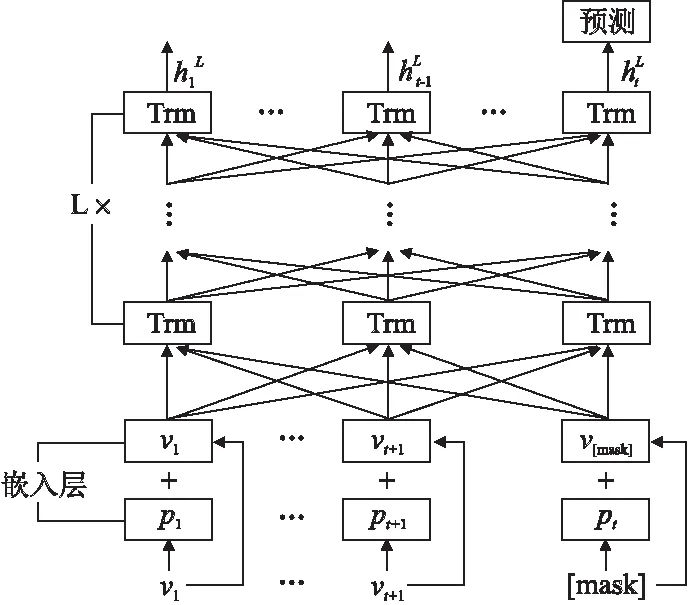
图8 BERT4Rec结构图
文献[90]中提出一种序列深度匹配模型(Sequential Deep Matching,SDM),通过多头注意力机制在用户近期行为序列中捕获短期偏好;把用户长期行为序列中的所有物品对应的属性集合划分为不同的类,如ID集,物品店铺集,物品品种集,对于不同的集,都经过一层注意力机制进行建模,例如,每个用户对不同类别的书籍偏好程度不同,以此捕获用户的长期偏好.Wu等人[91]认为很多序列推荐的处理时间信息上,基于RNN,CNN,Transformer的模型虽然效果不错,但是缺少个性化,为解决这种问题,提出了一种个性化的基于Transformer的序列推荐模型,考虑到用户嵌入在序列建模中的重要性,并且使用的正则化技术是SSE(Stochastic Shared Embedding),SSE的主要思想是在SGD过程中随机地用另一个具有一定概率的嵌入来代替现在的嵌入,从而达到正则化嵌入层的效果,提高推荐结果的准确率.文献[92]是阿里巴巴公司和北京大学联合提出的基于自注意力机制的用户异构行为建模框架,其命名为ATRank(Attention-Based Rank),同时考虑用户异构行为和时序,使用自注意力机制缓解RNN、CNN的局限性,提升推荐效果.Zhang等人[93]提出一种基于特征集深自注意力网络(Feature-level Deeper Self Attention Network,FDSA),分别对物品级序列和特征级序列应用自注意力块,对物品转换模式和特征转换模式分别进行建模,将两个块的输出拼接起来进行预测推荐.此外,Huang等人[94]设计的上下文自注意力网络(Contextual Self-Attention Network ,CSAN)也考虑到用户异构行为,使用自注意力机制捕获多种用户行为.
表3归纳了本文中用户长短期偏好序列推荐中的主要研究,从针对问题和主要优点方面进行了小结.

表3 用户长短期偏好的序列推荐主要研究
6 用户行为序列推荐研究存在的主要问题
6.1 冷启动和数据稀疏问题
冷启动问题即用户冷启动、物品冷启动和系统冷启动,而数据稀疏是缺少可用信息,这两个问题都是序列推荐长期要面对的问题,大多数现有的序列推荐算法[95-97]都忽略了这两个问题,其有效实现都依赖于对序列数据相对严格的要求,例如,丢弃小于最小阈值的序列等.用户的行为序列是将用户与物品之间的交互作为一组历史信息,交互中可用的用户和物品信息有限,Lv等人[90]利用序列中不同类型的边信息构建算法,如物品ID,品牌和店铺等,更好地模拟用户的长期偏好,这种方法也只能部分缓解这两个问题.
6.2 噪声信息干扰问题
一般来说,序列越长包含的信息量越多,同时与交互无关的噪声信息也越多,甚至在捕获用户长期偏好时,可能会被长序列中的噪声所淹没.如何对含噪声的序列进行建模,是序列推荐所面临的主要问题之一.目前的研究强调序列中的每个物品都与邻域的物品存在依赖关系,这种严格的规定,会影响推荐的效果,低估了依赖关系建模时噪声信息的影响,在现实生活中也是不现实的,因为用户的行为是不确定的.序列中会包含一些不相关的物品,这些物品会导致错误的依赖关系.受到注意力机制的启发,Ying等人[84]提出两层注意力网络,使用注意力为不同的物品不同的权重,更加强调相关物品,减少噪声物品的影响.另一个处理含噪声序列的方法是记忆网络,外部记忆网络有强大的存储能力,Chen等人[50]提出的记忆增强神经网络,使用一个内存矩阵存储之前状态,更好的模拟用户行为,提高推荐性能.
6.3 可解释性问题
大多数基于深度学习的序列推荐模型都缺乏可解释性,它们的决策过程是一个超出人类直接理解范畴的高维隐空间.如果缺乏推荐的原因,用户会对推荐结果产生怀疑,从而使推荐效果变差.另一方面,增强可解释性可以加强使用者对模型的理解[98],如不同的超参数等因素是如何影响模型的输出,从而增强对整个推荐过程的控制.Peake等人[99]用矩阵分解在模型的输出上训练关联规则,以获得更好的可解释性.这类通过设计单独的方法来试图解释推荐产生的结果,没有直接将可解释性与边信息联系起来,而用户与物品的交互中,通常还包含一些辅助信息,如文本评论、社交关系等,这些信息都可以加强推荐的可解释性,但是却没有得到充分的利用.
6.4 嵌入方法过于简单
在以往的研究中,序列推荐大多采用自然语言处理的嵌入方法,通过嵌入方法以表示物品、用户或序列的信息,例如,Greenstein等人[100]使用词嵌入方法GloVe[101]和Word2Vec[102]得到物品嵌入表示.其中存在着一些问题,首先,利用物品之间的关系来学习物品的表示,然而交互物品之间的依赖关系是不断发生变化的,自然语言处理中的单词及其连接关系是相对固定的.其次,嵌入模型的预训练是相对复杂;而且序列推荐中的行为比单词要复杂的多,包含更多的信息,简单的嵌入方法无法很好处理复杂用户行为序列.最后,对于通过嵌入方法学习到的用户表示而言,是通过相对静态的方式学习得到,难以体现出用户偏好的动态性.在这些情况下,序列推荐需要设计更先进、更特殊的嵌入方法.
6.5 未充分利用用户间协同信息
现有模型大都没有明确的利用不同用户之间的协同信息,也就是说,大多模型都侧重于编码每个用户自己的交互序列,训练和测试过程中对序列的编码都在一个序列内,忽略了不同用户序列之间的高阶连通性,然而在现实生活中,用户的偏好会受到好友的影响.同时,物品的语义信息也会随着一阶或者更高阶的相关性变化而变化,用户的兴趣也是动态的,这些模型也忽略了高阶协同信息在不同时刻的动态影响,推荐效果会受到影响.
7 用户行为序列推荐未来主要研究方向
7.1 上下文感知用户行为序列推荐
时间、天气、地点、季节、一天中的时间和地点等上下文因素可能会对用户的最终选择产生重大影响.上下文信息可以从序列中显式提取,也可以隐藏在用户的交互历史中.识别上下文是序列推荐中重要的参数之一,它在更好地帮助理解用户的需求和兴趣,在做出正确的预测方面发挥着重要作用.线上购物环境下,用户的购物目的或者当前心情等这些上下文因素是不能直接观察到的,必须从用户最近的行为中去分析,并最终基于用户和整个社区的行为模式[103,104].对于新用户和匿名用户,考虑上下文信息尤其重要.总的来说,上下文感知用户行为序列推荐根据历史交互数据做出上下文适应的推荐,了解用户的兴趣和目的.
7.2 动态图神经网络用户行为序列推荐
受图神经网络在各种领域里成功应用的启发,研究人员也不断提出基于图神经网络的用户行为序列推荐[67,69],将用户和物品关联起来构成一个图结构,通过GNN捕获复杂的交互关系,并相应生成物品的嵌入向量,这是传统序列推荐难以做到的.同时,时间在多方面影响着用户的兴趣偏好[105],用户偏好会随时间而发生动态变化,随着交互物品的变化而变化,且会受到其他用户的影响,为克服这些挑战,可以将用户行为序列和动态协同信息建模到一个框架中,通过动态图结构将不同的用户序列连接起来,比起传统的静态图,动态图包含更多的时间和顺序信息,利用这些信息探索用户和物品的交互行为以提取用户偏好,将序列推荐的下一项预测任务转化为动态图中用户节点与物品节点之间的链接预测.
7.3 跨域用户行为序列推荐
通常用户购买的物品来自多个领域,而仅仅不是单一领域[106].例如,用户阅读了《哈利波特》的书籍,他可能会对《哈利波特》的电影产生兴趣,以及用户可能因此购买哈利波特的周边产品,这些都是属于不同领域,且这些不同领域之间也存在着密切的联系,虽然不同领域物品之间的关系也要比单一领域要复杂很多,但是考虑多领域交互可以缓解单邻域数据稀疏的问题.跨领域推荐的主要问题就是如何利用源领域的数据在目标领域产生理想的推荐,从序列数据中提取出属于不同领域的特征.然而,单独针对某一领域设计推荐模型的研究较少,大多数的算法都是假设其模型适用于所有领域,在实际应用中却暴露出很多不足.未来的研究可以考虑研究不同领域中序列数据的特征,设计更好的序列推荐模型.如,Zhuang等人[107]利用用户来自不同领域的行为序列数据,挖掘其特征以提高推荐性能.Ma等人[108]通过识别同一账户下不同的用户行为,将用户在两个域上的行为在每个时间戳上同步共享,从不同领域获得相同时间段的用户行为数据,提出同时生成两个域的推荐.但是利用另一个域的用户行为信息时同时也包含噪声数据,因此跨域推荐中依旧存在着很多挑战.
7.4 注意力机制多兴趣用户行为序列推荐
用户的兴趣越来越趋向于多样化且易变,若仅仅只预测一类物品或一种偏好,用户的选择会受到局限,一些相对比较小众的物品就很难被发现.序列中可能存在多个兴趣倾向,基于深度学习的方法[109]通过对用户行为序列进行计算,为每个用户生成一个低维度的嵌入表示,但是单一的嵌入表示缺乏表现力,并不能反映用户在一个时间段内的多重兴趣.可以通过注意力机制对用户潜在的多重兴趣建模,捕获用户的多种兴趣,注意力机制还能有选择地保留和利用那些与下一次交互预测真正相关的交互信息,以达到减少噪声的目的,同时增加了模型的可解释性.如SDM[90]模型通过一个多头自注意力模块对用户行为序列进行编码,以捕获多种类型的兴趣;Zhou等人[5]提出用注意力机制使用户在不同的物品上有不同的表示,以捕捉用户多样的兴趣,但是这种方式需要重新计算每个物品的用户表示,使得其只能适用于排序阶段.Pi等人[110]通过记忆网络从长序列数据中捕获用户的多样兴趣,使用记忆网络比起注意力机制更为复杂,且不易捕获用户的长期兴趣.
8 结束语
用户行为序列在大多数情况下都是存在时间上的先后关系的,且用户的偏好会随时间的变化而变化,通过研究用户行为序列推荐领域内的进展,本文阐述了序列推荐中的相关概念,从时间维度将该领域内的主要工作划分为3个子领域,分别为长期偏好序列推荐、短期偏好序列推荐和长短期偏好序列推荐,深入分析了序列推荐中存在的冷启动问题、数据稀疏和可解释性差等问题,最后展望了序列推荐未来的发展方向以及面临的挑战,希望能为推进该领域的进步提供一定的帮助.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
数理化解题研究·综合版(2021年11期)2021-12-22
小学教学研究(2021年5期)2021-09-29
课程教育研究(2021年27期)2021-04-13
初中生世界·九年级(2020年2期)2020-04-10
读与写·教育教学版(2017年10期)2017-11-10
软件(2017年6期)2017-09-23
南都周刊(2015年4期)2015-09-10
