
长文本匹配LTM-B模型①
2022-05-10 02:29蔡林杰
计算机系统应用 2022年2期
刘 龙,刘 新,蔡林杰,唐 朝
(湘潭大学 计算机学院·网络空间安全学院,湘潭 411105)
文本匹配[1]是自然语言处理(NLP)[2]中一项基础任务,旨在研究两个文本之间的语义匹配关系.长文本匹配是文本匹配的一个重要子方向,主要应用于文本聚类[3]、新闻推荐[4]、搜索引擎[5]、文本去重[6]、机器翻译[7]等领域.在文本聚类方面,两篇文档的相似度判断是必不可少的工作.在新闻个性化推荐中,系统可以根据用户近期阅读的新闻类型来向用户推送相关系列的新闻.对于搜索引擎来说,精准地查找到与用户搜索内容相关的文档是极其重要的.文本去重可以抽象为文本与文本的相似度匹配问题,而机器翻译可以理解为两种语言之间的匹配.可想而知,对长文本匹配任务的研究是一项具有重要意义的工作.
过去关于长文本匹配的工作比较少,其原因在于:第一,长文本匹配相关语料相对来说较为匮乏,缺少权威的数据集;第二,文档的篇幅很大,篇章结构较为复杂,语义信息的提取存在一定难度;第三,采用的文本表示方法处于较浅层次,难以满足文档语义复杂性的要求.
BERT 预训练模型[8]是NLP 领域近年来最具突破性的一项技术,它可以很好地融合文本的多层次特征,能够获得文本的深层双向表示,是一种动态的文本表示方法,解决了一词多义的问题.因此,本文将基于BERT模型对长文本匹配展开深入研究.BERT 模型最多支持输入510 个字符,这对于文档级别的文本来说远远不够,那么就需要将文档灵活地转变成可被BERT 模型处理的形式,主要有3 类方法:一是截断法,主要包括截取文档头部分段、截取文档尾部分段、截取文档头尾部分分段3 种方式,截断法总共截取510 个字符,但对于超长文档,必然丢失大量文本信息;二是分段法,采用“字符-分段-文档”的分层思想,将整个文档拆分成多个固定长度的分段,每个分段的字符数不超过510,再通过BERT 模型计算每个分段的向量表示,最后池化得到文档向量,该方法没有考虑分段的先后顺序和相互联系,容易丢失部分语义信息;三是压缩法,一般而言,文档中每一段的第一句为关键句,将这些关键句抽取出来重新组成文档,若超过510 字符,则采用截断法,此方法可能丢失一些关键的文本信息.针对以上问题,本文改进分段法,提出一种基于BERT的长文本匹配模型LTM-B,该模型建立在孪生网络的基本框架上,考虑到数据集中每个文档的字符数,首先将文档拆分成4 个分段,经过BERT 模型处理产生4 个文本向量,由此组成文档矩阵,再利用双向长短时记忆网络(BiLSTM)[9]模型得到位置矩阵,然后将文档矩阵和位置矩阵求和送入Transformer 编码器[10]进行特征提取,最后在匹配层使两个文档矩阵交互,并让两个文档矩阵进行池化、拼接操作,经由全连接层分类输出两篇文档之间的匹配关系.实验结果表明,相较于其他方法,本文提出的LTM-B 模型有着更好的效果.
1 相关技术
孪生网络[11]包含两个结构相同、权重共享的子网络,子网络各自接收一个输入,将其映射至高维特征空间,并输出对应的表示,然后通过计算两个表示的距离得到两个输入之间的语义关系.
Transformer 模型是谷歌在2017年推出的一种NLP模型[10],它由编码器-解码器结构组成.模型使用了自注意力机制,没有采用循环神经网络(RNN)[12]的顺序结构,能够并行化训练,拥有非常优秀的特征提取能力.
BERT 模型是谷歌在2018年推出基于Transformer的预训练模型[8],在NLP 领域的多个方向大幅刷新了纪录,BERT 模型作为Word2Vec[13]的替代者,它的网络架构使用了多层带有Attention 机制[14]的Transformer结构,相较于Word2Vec的浅层神经网络,BERT 模型是深层且动态的,可以解决一次多义的问题,对于词和句的向量化处理有突出的贡献.
2 长文本匹配模型LTM-B
目前,大多数长文本匹配方法要么采用像Word2Vec这样的静态浅层网络作为文本表示方式,存在一词多义问题,要么采用了动态的文本表示方式却丢失了许多语义信息.
因此,本文提出了一种基于BERT的长文本匹配模型LTM-B,其结构如图1所示,它以孪生网络为基础,拥有输入层、表示层和匹配层.在输入层,文档分段后通过BERT 模型得到文档矩阵,并利用BiLSTM模型产生位置矩阵,将两个矩阵之和送入表示层;表示层为Transformer 编码器,能够对文档矩阵进行深层次特征提取;匹配层对两个文档进行交互,并将池化后的两个文档向量拼接输入至全连接层,最终分类输出两个文档之间的匹配关系.
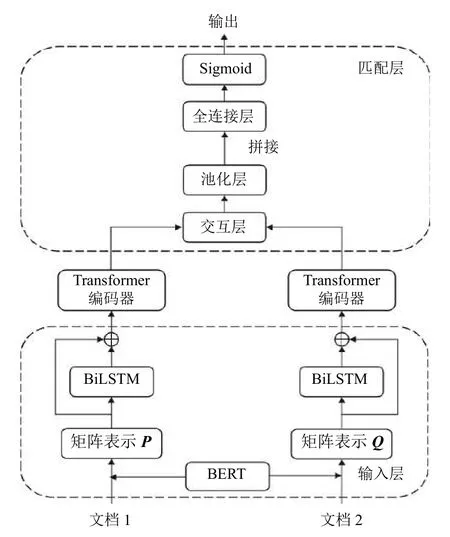
图1 LTM-B 模型结构
2.1 输入层
模型的输入层是将文档转化成矩阵表示,先对文档进行分段处理.而数据集中单篇文档大多集中在700–2 000 个字符之间,并考虑到BERT 模型的输入序列最多不能超过510 个字符,本文将文档前2 040 个字符截取下来,分成4 段,每段最多为510 个字符.若文档未能达到4 段,则按照4 段处理,例如单个文档的字符数为723,那么第1 段为510 个字符,第2 段为213 个字符,第3 段和第4 段为空,即设为全零向量.
本文使用的是BERT-Base 中文模型,该模型拥有12 层Transformer 编码器,隐藏层的维度是768,自注意头的个数为12.因此,通过BERT 模型可以分别得到两个文档的矩阵表示P4×768和Q4×768.BERT 模型实现文本向量化的过程如图2所示.
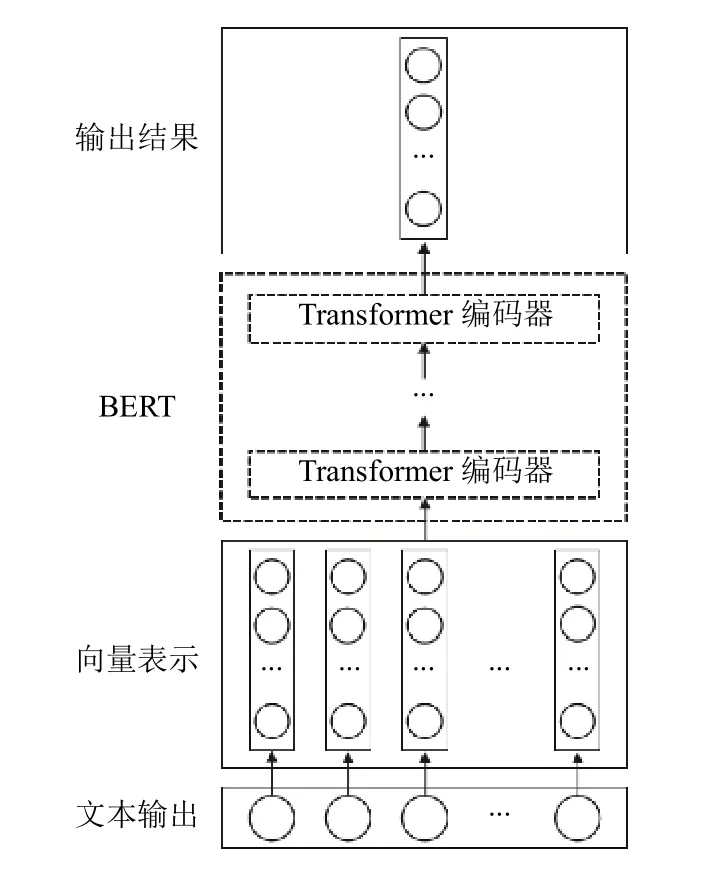
图2 文本向量化过程
在得到两个矩阵表示后,考虑到Transformer 编码器不能获取位置信息,本文使用BiLSTM 模型来得到位置矩阵,将文档矩阵和位置矩阵相加得到文档的输入矩阵表示,其公式如下:
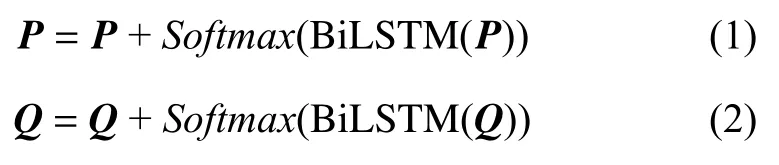
2.2 表示层
两篇文档经过输入层后产生各自的文档矩阵表示,再通过表示层对文档进行特征提取,表示层的权重矩阵是共享的.
模型的表示层采用Transformer 编码器,每一个Transformer 编码器都有两层子结构:自注意力层和前馈神经网络(FNN)层[15].每层结构后都会进行残差连接和层归一化处理,从而保证每层的输出数据更加平滑,Transformer 编码器结构图如图3所示.
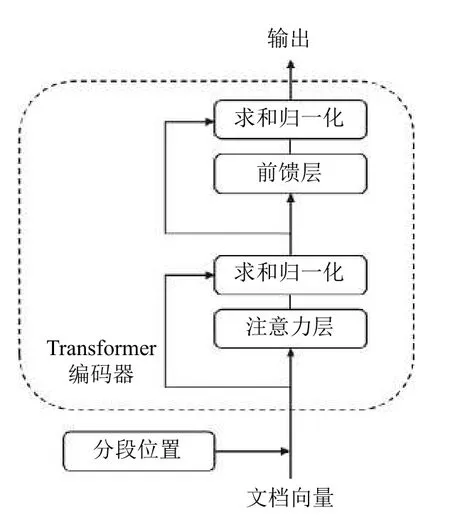
图3 Transformer 编码器结构
本文使用多个Transformer 编码器作为表示层来对矩阵做特征提取,从而增强文档的矩阵表示,单个Transformer 编码器计算过程如下步骤.
(1)文档矩阵:通过输入层产生的文档矩阵表示X,矩阵X的维度是4×768.
(2)计算矩阵Q、K、V:通过模型的参数WQ、WK、WV结合矩阵输入X来进行计算:


(3)计算单头自注意力层的输出矩阵Z:首先计算字符在上下文中的意义以及字符之间的相互影响QK,之后进行缩放和归一化处理,dK默认值为64,最后加权求和得到单头注意力层输出矩阵Z:
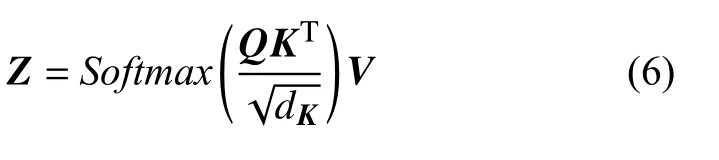
(4)计算融合所有注意力头信息的矩阵Zsum:Transformer 编码器模型使用了m个注意力头,通过第3 步可以得到m个不同的Z矩阵,将它们拼接并乘以附加的权重矩阵WO可得到Zsum,Zsum的维度为4×768.公式中Concat(Zi)表示为m个注意力头输出矩阵的拼接:

(5)通过残差连接和层归一化得到Za:将注意力层输出结果的Zsum和输入矩阵X相加后做层归一化(LayerNorm)得到Za直接作为前馈层的输入,Za的维度是4×768:
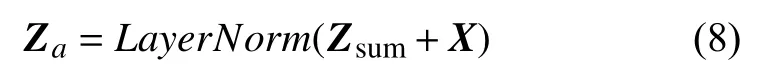
(6)前馈层即前馈神经网络层:首先对Za进行两次线性转换,然后使用激活函数处理得到输出Zh,Zh的维度是4×768:

(7)通过残差连接和层归一化得到Zout:将前馈层得到的结果Zh和输入Za相加后做层归一化处理得到Transformer 编码器的输出Zout,Zout的维度是4×768:

表示层通过Transformer 编码器来对文档进行特征提取,不同的分段具有不同的注意力权重,能够体现分段之间的相互联系,其输出矩阵可以更好地表示文档特征.
2.3 匹配层
使用表示层将文档特征提取后,需要对两篇文档进行语义匹配计算,本文模型的匹配层主要包括交互层和全连接层.
交互层主要是让两篇文档分别获取相互之间的注意力,这对于文档之间语义匹配度的判断是非常有必要的.参考缩放点积注意力机制,交互层对表示层输出的文档矩阵P4×768和文档矩阵Q4×768进行如下处理:
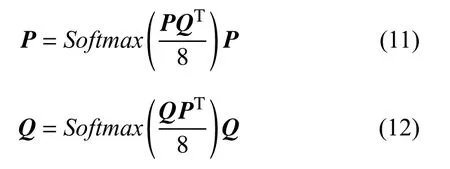
表示层考虑的是文档内部分段之间的相互影响,而交互层考虑的是两篇文档之间的影响.
通过交互层获得交互信息后,下一步是对文档全局特征进行整合,本文采用的是最大池化(max pooling),得到两个文档的特征向量p和q,二者都为768 维;
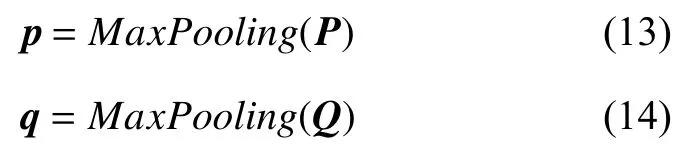
将最大池化后的文档向量p、q和|p–q|进行拼接,其中|p–q|可以有效反映两个文档之间的差异,从而得到一个2 304 维的组合向量c;
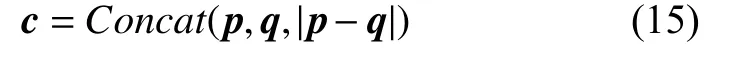
最后通过全连接层和激活函数的处理,将组合向量c映射输出为(0,1)的数值,该数值D越大说明两个文档之间的距离越大,相似度越低,公式如下:

2.4 损失函数
损失函数(loss function)是用于评价模型的输出值与实际值不一样的程度,也可用于修正模型的权重矩阵,最后通过最小化损失函数来达到模型最好效果.当Sigmoid 函数作激活函数使用时,通常使用的损失函数是交叉熵损失函数(cross-entropy loss function),公式如下:

其中,x表示样本,y表示实际值,a表示模型的输出值,n表示样本的数量.
3 实验
3.1 数据集
本文实验使用的数据集来自清华大学的THUCNews新闻文本分类数据集,THUCNews 数据集是根据新浪新闻2005–2011年间的历史数据筛选过滤生成,包含74 万篇新闻文档,均为UTF-8 纯文本格式.此数据集在原始新浪新闻分类体系的基础上,重新整合划分出14 个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐.
实验选取THUCNews 数据集的部分数据来构造长文本匹配数据集,数据集共有10 000 个文档对,以6:2:2 切分为训练集、测试集和验证集.在THUCNews数据集的14 个类别文档中抽取某一类中的两篇文档作为一个同类文档对,标注距离为0,抽取5 000 对;再抽取非同类中的两篇文档作为一个异类文档对,标注距离为1,同样抽取5 000 对.数据集中数据的分布如表1所示.
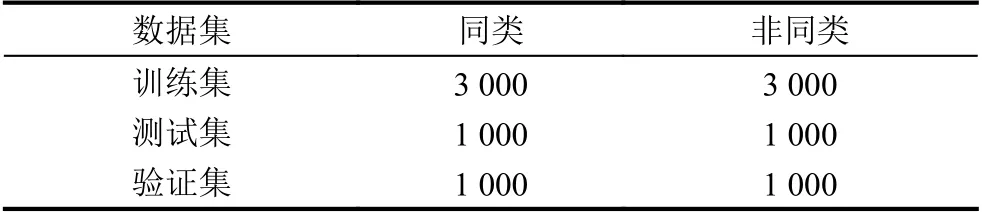
表1 数据集分布
3.2 评价标准
实验使用的评价标准是准确率A(accuracy)和F1 值,F1 值由精确率P(precision)和召回率R(recall)计算得到.准确率A定义为正确分类的样本数与总样本数之比,精确率P表示为预测为正的样本数与真正的正样本数的比例,召回率R表示为样本正例中预测正确的比例.A、P、R、F1 值的计算如以下公式所示,其中,TP表示“实际是正类,预测是正类”,FP表示“实际是负类,预测是正类”,FN表示为“实际是正类,预测是负类”,TN表示为“实际是负类,预测是负类”.

3.3 模型参数设置
本文提出的LTM-B 模型涉及到的超参数有许多,主要的超参数包括Transformer 编码器的层数、注意力头的个数、批大小,下面通过控制变量法来设置这3 个超参数.
Transformer 编码器的层数设置关系到表示层的复杂程度,通常层数越多,训练时间越长,模型耗时越多.因此,找到层数少且效果好的模型是非常有必要的.本次实验为二分类实验,较为简单,可以设置Transformer编码器的层数为1、2、3、4,实验结果如图4所示.

图4 F1 值随编码器层数变化图
注意力头个数的增加可以提高表示层的性能,但个数过多可能导致模型过拟合,本次实验设置注意力头的个数为4、8、12、16,实验结果如图5所示.

图5 F1 值随注意力头个数变化图
批大小关系着模型训练的效果,批次太小不利于收敛,批次太大容易陷入局部最小值,分别设为64、128、256、512 进行实验,其结果如图6所示.
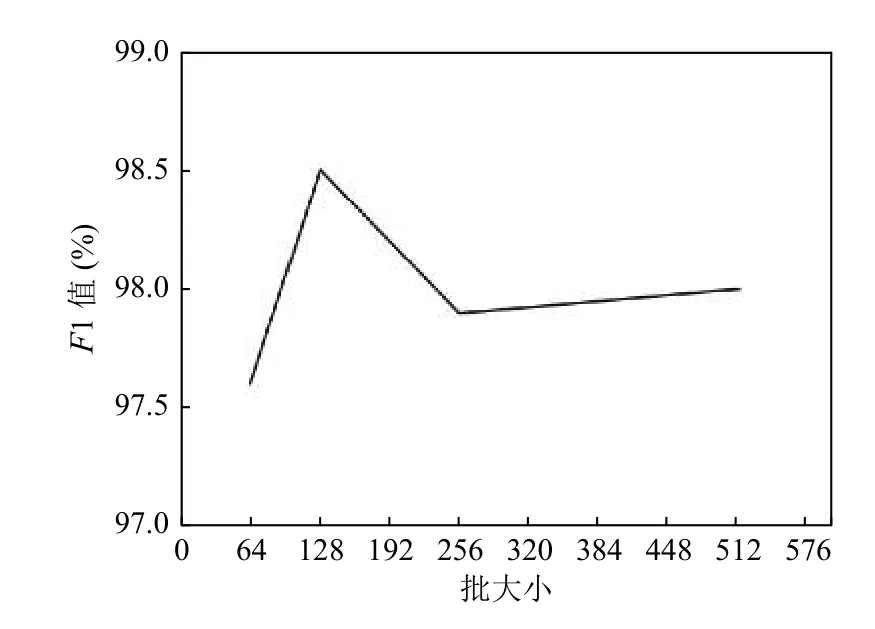
图6 F1 值随批大小变化图
综上所述,我们将Transformer 编码器层数设置为2,注意力头的个数设置为12,批大小设定为128.
3.4 实验对比
为验证本文提出的LTM-B 模型的效果,本文设置了6 组对比实验,实验方法如下所示:
(1)BERT+截断法:截取文档前510 个字符,两篇文档分别经过BERT 模型处理得到文档向量,两个向量经过拼接送入全连接层分类输出匹配结果,计算结果靠近0 则划分成同类,计算结果接近1 则为异类;
(2)Word2Vec+截断法:截取文档前510 个字符,采用Word2Vec 模型结合jieba 分词来得到文档的矩阵表示,后然后通过最大池化得到文档向量,再将两个文档向量拼接后经过全连接层分类输出匹配结果;
(3)分段法:将文档分成多个分段,每个分段510 字符,每个分段分别使用BERT 模型处理成向量表示,组成文档的矩阵表示,然后直接简单地将两个文档矩阵输入到匹配层得到结果;
(4)压缩法:将文档中每个段落的第一句抽出组成一个新文本,文本若超过510 字符,则只截取前510 字符,将此文本通过BERT 模型处理成文本向量,然后对两个文本向量依次经过拼接等操作输出结果;
(5)分段法+BiLSTM:文档截取前4 段,每段510 字符,然后使用BERT 模型处理得到文档矩阵表示,再由BiLSTM 实现特征提取,后经过匹配层得到结果;
(6)分段法+Transformer:相对本文提出的LTMB 模型,该方法的输入层缺少位置矩阵.
实验结果如表2所示.

表2 模型对比实验(%)
3.5 实验结论
由方法1、2 可知,BERT 模型的文本表示能力比Word2Vec 模型更加优秀;由方法1、3、4 可知,截断法比分段法和压缩法效果都差一点,主要是因为截断法丢失了更多的文本信息;由方法3、5、6 可知,增加表示层能够提取更多的文本特征,且Transformer 编码器在特征提取方面要优于BiLSTM;由方法6、7 可知,加入位置信息确实能够提升模型的匹配效果.本文提出的LTM-B 模型在长文本拥有更好的表现,其原因在于:
(1)BERT 模型是一种深层动态的文本表示方法,融合文本的多层次特征,很好地解决了一词多义问题;
(2)输入层采用“字符-分段-文档”的分层思想,最大程度保留了文本信息,并利用BiLSTM 产生位置信息,解决了Transformer 编码器不能获取文本时序特征的问题;
(3)表示层利用了Transformer 编码器强悍的特征提取能力,能够捕获更多的文本特征;
(4)匹配层添加了交互层,使得两篇文档能够进行信息交互,这有利于加强模型的匹配效果.
4 结论
本文紧紧围绕BERT 模型对长文本匹配问题进行深入研究,剖析3 种常用方法后提出LTM-B 模型.该模型以孪生网络为基础,在输入层对文档进行分段,利用BERT 模型得到文档矩阵,并通过BiLSTM 生成位置矩阵,两个矩阵求和后送入由Transformer 编码器构成的表示层做特征提取,最后在匹配层进行交互、池化、拼接后输入到全连接层通过激活函数分类输出匹配结果.实验证明,本文提出的LTM-B 模型在长文本匹配问题上具有不俗的表现.
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
雷达学报(2018年5期)2018-12-05
小学生学习指导(低年级)(2018年11期)2018-12-03
中学生数理化(高中版.高一使用)(2018年1期)2018-02-10
