
基于人工智能的网络时空数据挖掘方法
2022-05-10 01:30姜滟稳
南京工程学院学报(自然科学版) 2022年1期
姜滟稳
(芜湖职业技术学院, 安徽 芜湖 241000)
网络时空数据是指广泛存储在互联网与时空内的数据,其在网络中存在某种直接或间接的联系.相比常规的时空数据,网络时空数据大多存储在服务器中,用户从计算机终端通过Web传输端口、标准化数据传输接口或URL等渠道调用与获取.大多数数据均是以文本的形式存储在空间内,文本内容可以是结构式文本,也可以是非常规结构式文本.为了进一步实现对网络时空数据的挖掘,可将数据按照结构与网络存储位置进行划分[1]:1) 结构类型数据包括KML数据、XML数据和JSON数据,非结构类型数据包括图像、影音视频、论坛信息、微博数据,非结构类型数据需要通过进一步分解语义才能实现对数据的分类;2) 通过划分位置显著性的方式,对网络时空数据的空间位置进行定位,可定位到具体空间位置的数据属于显著性数据,反之属于隐性数据[2].这些数据在网络中存储的方式呈现异象化,大多来源于群体的认知终端,包括技术研究机构、网络媒体平台等,只有掌握了数据在网络时空中的赋存规律,才能掌握群体的需求方向与兴趣点.本文利用微分进化算法设计一种针对网络时空数据的挖掘方法,掌握网络赋存大规模数据的规律,为社会产业发展、技术研究提供参考.
1 基于人工智能的网络时空数据挖掘方法设计
1.1 网络时空数据获取
在对网络时空数据挖掘前,需要在网络环境中对海量网络时空数据进行获取.本文引入网络爬虫技术,对网络环境中各类应用程序进行自动化浏览,并针对具体应用中所需的专题数据进行抓取[3].在网络环境中,从各个网站初始网页的URL开始抓取,并从相应页面当中对新的URL进行抽取,将其放入到任务列表中,直到所有数据都已被抓取过.
图1为利用网络爬虫对网络时空数据获取的流程示意图.由图1可见,在进行获取的过程中主要有网站页面下载、页面综合解析、获取任务调度和地理空间编码四个阶段:

图1 网络时空数据获取流程示意图
1) 利用C#和Python编程对需要进行挖掘的网站网页中的时空信息进行下载,引入Selenium提供的网络请求模拟模块向被挖掘的服务器发出相应的请求,在获取到响应结果后完成对网络时空数据资源的下载[4],Selenium在实际应用中能够对下载错误以及重复下载等影响挖掘质量的因素作出相应操作,可确保下载的数据资源为后续挖掘所需的资源;
2) 对下载的数据资源进行预处理和提取,通过网络爬虫直接获取的网络时空数据通常表现为非结构或半结构化特点,在使用前需要对其进行结构化处理,根据网络环境中各个网站的基本结构,利用HtmlAgility技术为其制定相应的数据抽取规则,从而更加准确地获取目标数据[5];
3) 对多余数据去重和过滤,为每一个子线程提供一个爬虫任务,从而将一个较大的获取任务划分为多个互不影响的子任务,并为各个子任务分配对应的代理服务器,以此避免在网络中部分网站存在的爬虫技术对数据获取造成的干扰;
4) 对时空文本数据进行地理编码处理,结合位置信息本身具备的显著性,通过信息自带的坐标,实现数据空间化处理.
1.2 制定网络时空数据关联规则
与一般挖掘相比,网络时空数据挖掘预期本质上的区别在于处理的对象为时空数据,在数据内不仅包含一般数据信息的特征属性,还包含时间属性和空间属性.因此,在对网络时空数据挖掘前,需要明确其关联规则[6].在传统关联规则的基础上,引入时间和空间两个不同属性,将时空关联规则定义为:在某一时刻i、某一地点x发生了某一事件T1,在相同时刻或之后的一段时间范围内,该地点x或另外一定空间范围内,必定会发生另外一个事件T2.时空数据关联规则制定的难点在于需要对时间谓词和空间谓词进行提取,并将二者概念化,从而构建一个时空数据关联规则挖掘表.时空数据的关联规则与一般关联规则同样存在评价指标,即支持度和置信度.
1) 支持度的计算公式为:
(1)
式中:A为某一属性集合;B为另一属性集合;s为时空数据关联规则当中的支持度评价指标;GE为地理事件;D为网络时空数据库.
由式(1)可知,时空数据关联规则中的支持度能够实现对属性A和属性B的时空时间发生概率的描述.
2) 置信度计算公式为:
(2)
式中:c为时空数据关联规则的置信度评价指标;X为属性A集合和属性B集合的合集.
由式(2)可知,置信度为在网络时空数据库中属性A发生情况后的时空事件支持属性B发生的概率.
在实际应用中,根据挖掘需要,设定置信度和支持度指标参数阈值,完成对网络时空数据关联规则制定.
1.3 基于人工智能的挖掘数据筛选及候选集确定
由于在网络环境中时空数据包含时间数据和空间数据,数据量庞大.若挖掘候选集较多,会严重影响到本文挖掘方法的运行效率.微分进化算法是通过在种群个体之间的变异交叉得到新种群,新种群与原种群进行优胜劣汰竞争,得到新一代种群,在多参数的条件下,具有寻优速度快、收敛速度快的优点.
为进一步提高网络时空数据挖掘的效率,本文引入人工智能技术的微分进化算法对数据挖掘候选集进行筛选.在上位机输入挖掘数据筛选的条件,通过微分进化算法在更短的时间内从海量网络时空数据中提取关键词,并将该关键词作为切入点找出相应的时空数据信息[7].筛选条件为:结合网络时空数据挖掘特性,假设在某一时空数据集中存在一个频繁出现的数据集,则该数据集中所有子集可称之为使其频繁的数据集.当某一时空数据属于频繁出现的数据集,则频繁数据集当中会包含项目子集的个数减1.在实际应用中,若存在某一网络时空数据在挖掘过程中将成为某一个相对应维度的数据集当中的元素,这一元素即为筛选出的挖掘数据.在进行筛选的过程中,为了确保筛选的精度,可结合微分进化算法对筛选流程进行迭代训练,划分已知明确符合筛选条件的时空数据作为训练样本,在每个训练样本上完成对筛选条件的训练,再将其引入到分类器中完成融合,直到输出的所有网络时空数据均满足制定的筛选条件后,完成迭代训练,并将此时得到的程序带入到真实网络时空数据挖掘环境中,将不需要挖掘的时空数据剔除,实现对挖掘数据的筛选.具体的流程如图2所示.

图2 时空数据筛选流程图
完成对网络时空数据集的筛选后,需对特定某一类别中数据特征出现的概率进行计算,公式为:
(3)
式中:P为特定某一类别中数据特征出现的概率;λ为具体某一特征对应的网络时空数据;n为在网络环境中所有时空数据的特征.
根据式(3)计算得出每一个类别数据特征的出现概率,在关联规则的基础上,若频繁出现某一特征类别下的对应网络时空数据,则其挖掘价值会随之降低.为了能够避免这一问题产生,在挖掘过程中执行关联规则时,需要结合特定网络时空数据的实际特点对候选集的权重进行合理分配,以此进一步提高对网络时空数据挖掘的价值.
1.4 基于用户偏好的挖掘数据知识可视化
在进行网络时空数据挖掘时,以网络时空中的各类资源作为处理对象,将利用微分进化算法筛选后的数据保存在数据存储库中[8].引入用户偏好概念,利用挖掘技术提取不同用户感兴趣的模式和知识,并将其与时空数据对比,找出在时空数据中新的知识.图3为基于用户偏好的挖掘数据知识可视化示意图.
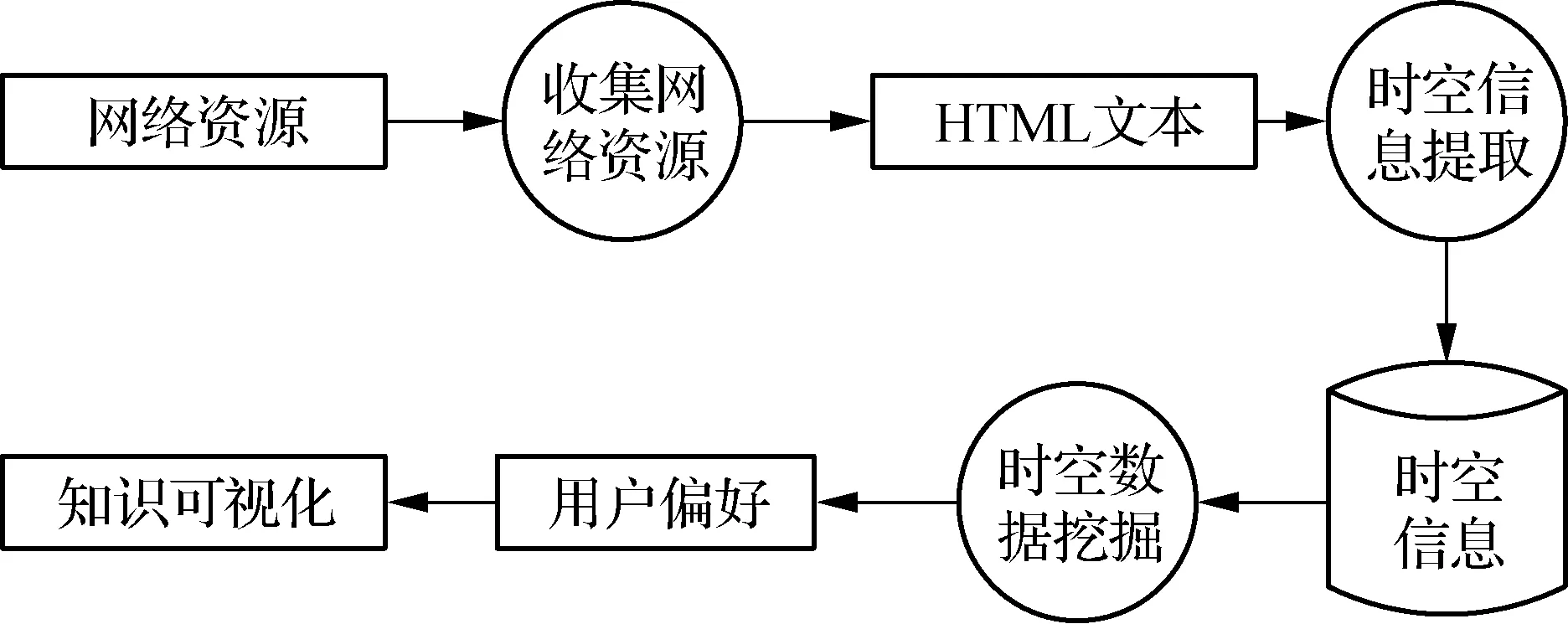
图3 基于用户偏好的挖掘数据知识可视化示意图
对筛选的数据挖掘候选集进行时空信息抽取为数据挖掘的重要步骤.时空信息的抽取可分为时间层面上的信息抽取和空间上的信息抽取.在网络时空数据资源中包含了事件信息,其主要由网站内容和用户使用记录构成.网络环境中用户的访问记录通常是以结构化的数据格式存储,在获取这一类时间信息时相对简单.在网络环境中网页作为一种特殊的文本形式能够从网页当中获取更多的时间信息,并借助其相应的文本结构实现对时间信息的抽取.将网络环境文本信息中的时间提取作为挖掘的分支,对绝对时间和相对时间获取,绝对时间是指具体的年、月、日等,相对时间是指昨天、明天等;绝对时间信息可直接解析获取,而相对时间信息需要进行简单推理和分析获取.空间信息分为源位置和目标位置两类.源位置表示为网络环境中特定网页服务器的具体地理位置或用户的IP地址;目标位置是指网络环境特定网页中描述的地理信息,例如报道信息当中的具体地点、具体城市名称等.
实现对各类网络时空数据的挖掘后,结合不同用户的偏好情况,为其进行挖掘数据知识的可视化展现.将超链接结构作为基础结构,假设某一挖掘目标为T,则目标服务地理范围可看作是地区l的几何圆中心,其半径为:
Radium(T,l)=Links(T,l)/Page(T)
(4)
式中:Page(T)为某一地区l所连接的挖掘目标网站T的所有页面数;Links(T,l)为挖掘目标网站T被引用的所有链接数.
利用式(4)确定图形半径后,所得出的圆即为基于用户偏好的挖掘数据知识可视化图像.用户可直接通过生成的图像对其所需网络时空数据以及相对应的潜在知识信息进行分析,实现对网络时空数据知识的直观分析.
2 试验论证分析
2.1 试验准备
为验证本文方法在实际应用中是否能够提高网络时空数据的利用率,将本文挖掘方法与传统基于Weka的挖掘方法应用到相同的试验环境中进行对比试验.
为确保最终得出的试验结果真实、有效,选择以某网络时空分布管理服务中心的空间作为两种挖掘方法的主要应用环境.在试验空间环境中,随机设置70个监测点,针对该网站发布的多组数据,每隔60 min完成更新,并对其与挖掘目标相关的数据进行获取.利用两种挖掘方法对相同数据测试集进行挖掘,该数据集为管理服务中心存储整理得到的结构化数据,对比挖掘结果的召回率.召回率为在目标集合中包含的真数据集合占总数据集合中所包含真数据集合的比例,召回率越高说明挖掘到的网络时空数据对于用户的利用价值越高,反之同理.召回率的计算公式为:
R=A′/A
(5)
式中:R为挖掘结果数据的召回率;A′为数据测试集中包含的真实数据集合;A为数据测试集中包含的数据量.
当数据测试集中数据量为1 000、5 000、10 000、15 000、20 000 MB时,运用两种挖掘方法对数据的召回率进行计算,完成两种不同数据挖掘方法对比试验的设计.
2.2 试验结果与分析
当两种挖掘方法均完成相应的挖掘任务后,将两种挖掘方法得出的结果代入到式(5)中,计算得出其相应的召回率,结果如表1所示.

表1 两种挖掘方法挖掘结果召回率对比表
由表1结果和试验过程可知,本文提出的基于人工智能的网络时空数据挖掘方法在实际应用中能够实现对网络时空数据更高的召回率,其数值均超过了0.850,说明挖掘结果当中的网络时空数据利用价值较高;传统挖掘方法得出的挖掘结果召回率在0.245~0.364,召回率偏低说明挖掘结果当中的网络时空数据利用价值偏低.
为进一步验证本文方法的性能,测试两种挖掘方法挖掘任务完成的准确率,重复进行5次,得到结果如图4所示.

图4 不同方法挖掘数据的准确率结果对比
由图4可见,本文设计的数据挖掘方法在挖掘时空网络数据时具有较高的准确率,平均为95.02%,传统数据挖掘方法的准确率平均为88.58%,表明本文设计的数据挖掘方法能够提供较为准确的挖掘结果,更具有利用价值.
在试验过程中,本文针对网络时空数据的特点制定更加理想的关联规则,在挖掘时按照该关联规则能够通过调节置信度和支持度指标实现对挖掘深度的调节,从而确保挖掘后的数据能够充分满足用户的需要.在实际应用中,本文提出的挖掘方法能够根据用户偏好,为其找出更符合其查询要求的数据,并进一步提高数据的利用价值.
3 结语
本文基于人工智能技术的应用设计了一种针对网络时空数据的挖掘方法,通过对比试验证明了此方法在实际应用中的价值更高、实用性更强,具有一定的可行性.后期将集成多源网络空间数据,利用GIS技术的空间解析能力,对数据进行可视化处理,从而进一步挖掘网络时空数据的隐藏市场价值.
猜你喜欢
四川党的建设(2022年8期)2022-04-28
新世纪智能(数学备考)(2021年9期)2021-11-24
大众投资指南(2021年35期)2021-02-16
小学生学习指导(低年级)(2020年11期)2020-12-14
当代陕西(2019年15期)2019-09-02
作文大王·低年级(2018年10期)2018-12-06
学苑创造·A版(2018年11期)2018-02-01
电力与能源(2017年6期)2017-05-14
读者(2017年5期)2017-02-15
小猕猴智力画刊(2016年5期)2016-05-14
