
一种28 nm工艺下抗单粒子翻转SRAM的12T存储单元设计
2022-05-17 11:51韩源源曾晓洋
现代应用物理 2022年1期
韩源源,程 旭,韩 军,曾晓洋
(复旦大学 微电子学院,上海 201203)
辐射环境的高能粒子入射到互补金属氧化物半导体(complementary metal-oxide-semiconductor,CMOS)工艺集成电路存储区域时,会在器件的有源区产生大量自由电荷,这些自由电荷被存储节点收集,使存储单元原本的存储状态发生翻转,产生软错误,称为单粒子翻转效应(single event upset, SEU)[1-3]。静态随机存储器(static random-access memory, SRAM)是一种常见的CMOS存储器,它由2个耦合反相器和一对选通管组成。在片上系统(system on chip,SoC)中,SRAM往往占据整个芯片面积的50%以上。所以,降低SEU对SRAM的影响,可大幅提高辐射环境中电路的可靠性。
通过设计特殊结构的存储单元来提高SRAM对SEU的免疫能力是广泛应用的加固方案之一。例如Quatro-10T[4]和RSP-14T[5]单元利用冗余节点备份存储信息,当其中一个节点受SEU影响产生逻辑翻转时,对应的冗余节点不会产生翻转,最终存储单元的逻辑状态能够恢复。RHM-12T[6]和Stacked-12T[7]单元利用堆叠结构构造冗余节点,通过堆叠结构能免疫特定逻辑翻转的特性,提高单元抗SEU的能力。根据纠错码(error correcting code, ECC)构建纠错电路是提高SRAM抗SEU的另一种途径,复杂的纠错码可纠多位随机错误[8-9],为降低周期开销,一些简单的线性码牺牲纠错性能,也可纠正相邻2位错误和特定的错误[10-13]。
然而随着器件特征尺寸的减小和集成度的提高,多个存储单元会同时处于SEU的影响区域,同时电路工作电压VDD的降低会导致敏感节点的临界电荷值降低,进而发生多节点翻转(multiple node upset, MNU)和多比特翻转(multiple bit upset, MBU)[14-16]。该情形下,传统加固单元Quatro-10T,RSP-14T,RHM-12T,Stacked-12T冗余节点的临界电荷也随之降低,导致SEU的免疫力下降。同时,当单元中多个节点同时发生翻转,单元不能从翻转中恢复。
本文提出一种P型堆叠Quatro-12T (P-stacked-quatro-12T, PSQ-12T) 存储单元,在中国台湾积体电路制造股份有限公司28 nm工艺的基础上进行电路性能仿真。PSQ-12T利用堆叠结构提高了存储单元单节点翻转(single node upset, SNU)的临界电荷,使存储单元具备抗特定的MNU性能,同时单元具有更好的数据保持稳定性和读稳定性。该存储单元能在更严苛的辐射环境中降低SEU对电路的影响。
1 PSQ-12T SRAM加固存储单元结构
PSQ-12T存储单元的结构,如图1所示。
由图1可见,在28 nm工艺下,为提高堆叠结构的抗SEU性能,存储单元的MOS管全部为高阈值电压管(high threshold voltage transistor, HVT)。M1和M3,M2和M4为2对堆叠上拉管;M5和M6为上拉管;M7,M8,M9,M10为下拉管;M11和M12为传输管。写位线WBL和WBLB是新引入的位线,分别控制M4和M3。M1和M2交叉耦合,二者的漏极分别控制M5和M6的栅极。M9和M10交叉耦合,二者的漏极分别控制M7和M8的栅极。M11连接Q1与位线BL,M12连接Q2与位线BLB。
写操作阶段,先对位线BL/BLB预充电,使位线的电势上升至VDD,写位线WBL/WBLB在预充电阶段电势为0。完成预充电后,BL,WBL,BLB,WBLB接收到数据信息。例如,当Q1写入“0”,Q2写入“1”时,BL被下拉至“0”,同时对WBLB充电,使电势上升至VDD。位线和写位线接收数据信息时,WL打开选通管M11和M12,此时M3处于关闭状态,M4处于打开状态,Q4的下拉路径被切断。当BLB对Q2写入“1”后,开启M8,对Q3放电,拉低Q3节点的电势,由于Q4下拉路径被切断,此时Q4的电势将会迅速地上升至VDD,存储单元完成写操作。
读操作阶段,WBL/WBLB保持电势“0”,使M3和M4保持开启状态,形成反馈回路。在读操作初始阶段,BL/BLB被预充电至VDD。预充电完成后,WL打开选通管M11和M12,进行数据读取。如,Q1保存“0”,Q2保存“1”时,BL将被下拉,BLB保持“1”,BL与BLB之间迅速形成电势差,通过灵敏电压放大器放大后读出,存储单元完成读操作。
数据保存阶段,WBL/WBLB电势为0,BL/BLB电势为VDD,堆叠的上拉管都处于开启状态,形成反馈回路,既能增大数据保持的噪声容限,又能提高存储单元抗SEU的能力。
2 PSQ-12T存储单元抗SEU的原理分析
数据保存阶段,WBL/WBLB保持电势0,在此状态下,假设存储节点Q1和Q3存储“1”,Q2和Q4存储“0” ,如图1所示。本文分别讨论SNU和MNU的恢复机制。
2.1单节点翻转
2.1.1 单一“0-1”翻转
该情况下的敏感节点为Q2,Q4,S1。其中,S1和Q4的翻转情况一致,因此,本文只分析Q4的翻转。当Q4受到SEU影响从“0”翻转到“1”时,M2和M5被关闭,而Q1和Q3的存储状态不变,使M7处于开启状态,M6处于关闭状态。当SEU在Q4引起的脉冲电压消失后,M7能对Q4放电,使Q4重新恢复到“0”的原始状态。当Q2受到SEU影响从“0”翻转到“1”时,原本关闭的M8和M9将被开启,分别对S2和Q1放电,Q1电势立即被拉低,从而关闭M7;根据堆叠管分压原理,Q3将保持在高电势,使M1处于关闭状态,最终Q4将保持原有的存储状态“0”。当SEU在Q2引起的脉冲电压消失后,M5将拉高Q1的电势,关闭M10;M2拉高S1的电势,关闭M6,使Q2重新恢复到“0”的原始状态“0”。最终存储单元可从“0-1”翻转中恢复到原有的存储状态。
2.1.2 单一“1-0”翻转
由于存储单元存在P型堆叠管,此时敏感节点为Q1和S2。当Q1受SEU影响从“1”翻转到“0”时,M7和M10关闭,Q2和Q4将保持原有存储状态。当SEU在节点Q1处引起的脉冲电压消失后,存储单元将恢复原有存储状态。当S2受SEU影响从“1”翻转到“0”时,根据堆叠管的分压原理,Q3处于高电势,使M2保持关闭状态,对其他节点不产生影响。当SEU在节点S2处引起的脉冲电压消失后,存储单元将恢复原有存储状态。
堆叠管分压原理为:当在Q2和Q4存储“0”, Q1和Q3存储“1”时,如果S2的电势被拉低至0,则堆叠管M2处于线性工作区域,M4处于饱和工作区域,M2,M4的电流可分别表示为[17]
(1)
(2)
其中:K为MOS管的工艺参数;W为MOS管的宽度;L为MOS沟道长度;Vgs为栅源之间的电压;Vds为源漏之间的电压;Vth为阈值电压。
由式(1)和(2)可得Q3的电压为
(3)
其中:WM2为M2的沟道宽度;WM4为M4的沟道宽度。
由式(3)可知,VQ3为Vth的单调递增函数,堆叠PMOS管的Vth越大,SEU引起S2产生“1-0”翻转时,存储节点Q3所处的电势越高,VQ3是WM4/WM2的单调递减函数,堆叠管中的上堆叠管尺寸越大,下堆叠管尺寸越小,则SEU引起S2产生“1-0”翻转时,存储节点Q3所处的电势越高,堆叠管M1的Vgs越小。当堆叠管M1的Vgs小于M1的Vth时,M1不会开启,存储单元的状态不受影响。综上所述,P型堆叠管的Vth越大,或WM4/WM2越小,存储单元抗SEU的能力越强。
2.2 多节点翻转
2.2.1 处于不同势阱的Q4和S2同时发生翻转
Q4从“0”翻转到“1”时,将关闭M2和M5,不会影响其他存储节点的电势。S2从“1”翻转到“0”时,根据堆叠分压原理,Q3的电势不会低于PMOS堆叠管的Vth,由于M10处于开启状态,即使M6被打开,M6的上拉驱动仍不会强于下拉驱动,Q2处于低电势。最终,存储单元能恢复到原有的存储状态。
2.2.2 处于同一势阱的Q1和S2同时发生翻转
当Q1和S2同时从“0”翻转到“1”时,将会关闭M7和M10,Q4的存储信息受影响。而S2的电势被拉低时,堆叠管M2和M4都处于开启状态,Q3处于高电势,最终存储单元会从“0-1”翻转中恢复到原有的存储状态。
3 PSQ-12T存储单元的性能分析与对比
PSQ-12T存储单元的时序控制原理如图2所示。与常规SRAM的区别是写操作增加了写位线WBL和WBLB。在写周期的初始阶段,首先对BL和BLB进行预充电,使电势上升至VDD。完成预充电后,WL上升至VDD,打开存储单元的选通管进行写操作,同时WBL和WBLB也控制存储单元的下拉堆叠管,辅助写操作。PSQ-12T存储单元的读操作与传统SRAM一致。在读操作阶段,可不采用放大使能信号,而采用共享层次放大电路,则时序控制原理如图2所示。WEN和REN分别为写使能信号和读使能信号。如只采用全局位线策略,则可增加放大使能信号,配合灵敏放大器来加快数据读出。
将PSQ-12T存储单元的性能与标准单元6T(STD-6T),Quatro-10T[4],RHM-12T[6],RSP-14T[5]进行对比。图3为28 nm工艺下,PSQ-12T的版图信息和面积对比。其中:OD为有源区;PO为栅;CO为金属接触;M1为第一层金属。黑色实线框中为PMOS,黑色虚线框中为NMOS。PMOS的宽度为100 nm,NMOS的宽度为200 nm。试验中选择的都是HVT的MOS管。HVT的PMOS管可降低上拉驱动能力和提高存储单元的抗SEU的能力;HVT的NMOS管可降低下拉驱动能力和提高存储单元的读写稳定性。
由图3(b)可见,PSQ-12T存储单元的面积为0.95 μm2,与RHM-12T相同,是STD-6T的2.61倍,Quatro-10T的1.11倍,RSP-14T的0.762倍。面积消耗与其他12T结构存储单元接近,略大于10T结构的存储单元。
PSQ-12T存储单元的下堆叠管M3和M4由写辅助信号WBL和WBLB控制。图4为PSQ-12T存储单元写操作时有无写辅助的波形对比。其中,Q和QB为下堆叠管M3和M4由写辅助信号WBL和WBLB控制的波形;QN和QBN为下堆叠管M3和M4由GND控制的波形。由图4可见,PSQ-12T存储单元有写辅助信号时,写入持续时间由3.4 ns缩短到1.7 ns,缩短了50%。
PSQ-12T的写入延时增加是因堆叠管降低了存储单元对中间节点Q3和Q4的下拉驱动,所以可增大NMOS的尺寸来增加存储单元的写入速度。选择正常阈值的NMOS构建下拉网络可大幅度提升写速度,但也大幅降低了SRAM存储单元的保持静态噪声容限(hold static noise margin,HSNM)。表1为PSQ-12T存储单元不同尺寸NMOS管的归一化单元面积、写入持续时间和HSNM的信息。由表1可知,当下拉网络管和选通管尺寸从200 nm增大到600 nm时,归一化单元面积增加了32%;写入持续时间从1.7 ns缩短到1.15 ns,缩短了32.4%;VHSNM从370 mV增大到415 mV,增加了12%。因此,为进一步缩短PSQ-12T存储单元的写入时间,可通过增加下拉网络管和选通管的尺寸来实现,但这一做法也增加了单元面积。

表1 PSQ-12T存储单元的N-MOS管尺寸与性能关系Tab.1 Relationship between N-MOS tube size and performance of PSQ-12T memory cell
本文利用蒙特卡罗方法,仿真温度设置为27 ℃,得到PSQ-12T存储单元数据的读(RSNM)、写(WSNM)和保持阶段的静态噪声容限,并与其他单元进行对比,如图5所示。
表2、表3和表4分别为PSQ-12T存储单元HSNM,RSNM,WSNM的仿真的结果,给出了不同单元噪声容限的平均值μ,标准偏差σ和离散系数σ/μ。

表2 HSNM 的蒙特卡罗仿真结果Tab.2 The Monte Carlo simulation result of HSNM

表3 RSNM 的蒙特卡罗仿真结果Tab.3 The Monte Carlo simulation result of RSNM

表4 WSNM 的蒙特卡罗仿真结果Tab.4 The Monte Carlo simulation result of WSNM
由图5(a)可见, PSQ-12T存储单元的HSNM为0.372 V,分别是STD-6T的1.16倍、Quatro-10T的2.06倍、RHM-12T的2.18倍和RSP-14T的1.2倍。PSQ-12T存储单元的HSNM比其他单元大的原因是PSQ-12T堆叠结构阻隔了下拉NMOS管,削弱了下拉网络的驱动能力,而堆叠管的上堆叠是交叉耦合的连接方式,进一步加强了上拉锁存能力,最终上拉驱动和下拉驱动达到平衡状态。而其他单元设计时,上拉驱动远小于下拉驱动,导致单元的HSNM下降。σ/u越小说明抗工艺偏差的能力越强,由图5(b)和表2可见, PSQ-12T存储单元的σ/u为10.1%,大于标准单元和RSP-14T,与其他单元接近。这表明PSQ-12T存储单元的HSNM抗工艺偏差能力小于标准单元,但对单元的稳定性并没有过大影响。
由图5(c)可见,PSQ-12T存储单元的RSNM为0.22 V,分别是STD-6T的1.36倍、Quatro-10T的1.44倍、RHM-12T的10.85倍和RSP-14T的1.66倍。PSQ-12T存储单元的RSNM大于其他单元也是由上拉网络与下拉网络的驱动能力接近,且上拉堆叠交叉耦合的方式增强了锁存能力导致的。由图5(d)和表3可见,PSQ-12T存储单元的σ/μ为10.16%,由于RHM-12T的σ/μ太小,没有列在表3中,其他单元的该项指标在9.31%~12.15%之间。由此可见,这些单元RSNM的抗工艺偏差能力相近。
由图5(e)可见,PSQ-12T存储单元的WSNM为0.61 V,分别是STD-6T的1.79倍、Quatro-10T的0.89倍、RHM-12T的1.52倍和RSP-14T的1.56倍。PSQ-12T存储单元的WSNM仅小于Quatro-10T。PSQ-12T存储单元WSNM增加的原因是单元引入了写辅助电路,通过WBL和WBLB切断了下拉反馈,增强了上拉驱动。由表4可知, PSQ-12T的σ/μ为4.27%,与STD-6T非常接近,这表明PSQ-12T存储单元结构的WSNM抗工艺偏差能力与STD-6T相当。
图6 为PSQ-12T存储单元与其他单元的功耗对比。由图6(a)可见,PSQ-12T存储单元工作在标压下的静态功耗为1.07 nW,分别是STD-6T,Quatro-10T,RHM-12T,RSP-14T的18.3%,13.2%,18.8%,17.7%。PSQ-12T静态功耗较低有2方面原因:(1)PSQ-12T存储单元采用了堆叠结构,降低了串联电流;(2)HVT的MOS管的漏电流小于正常阈值电压MOS管的漏电流。当位线负载为50 fC,工作频率为500 MHz时,PSQ-12T存储单元的动态功耗如图6(b)所示。由图6(b)可见,PSQ-12T存储单元的动态功耗为21.6 μW,分别是STD-6T,Quatro-10T,RHM-12T,RSP-14T的96.3%,63%,79.5%,93%。动态功耗较低有2方面原因:(1)采用HVT的MOS管;(2)PSQ-12T存储单元在写过程中切断了部分反馈回路,降低了耦合电流持续时间,且减少了耦合电流的来源。
临界电荷是衡量SRAM单元的抗SEU能力的指标。临界电荷可通过仿真获得,具体方式为对敏感节点进行电流注入,注入的电流模型为双指数电流模型[18]。漏极注入的电流I(t)可表示为
(4)
其中:Qtotal为受单粒子效应影响时,器件收集的自由电荷量;t为时间;τf为电流下降指数函数的参数,设置为220 ps;τr为电流上升指数函数的参数,设置为20 ps。不引起单元存储状态变化的最大电荷Qtotal就是临界电荷Qc。为方便比较,在计算时共享临界电荷,2个敏感节点注入相同大小的电流,即2个敏感节点的Qtotal相等且同时改变,该情况下不引起单元翻转的最大电荷Qtotal为共享临界电荷Qs。
对于SNU, PSQ-12T存储单元具备Quatro-10T结构部分节点对SEU免疫的功能,同时,敏感节点产生“1-0”翻转的临界电荷大于500 fC,如表5所列,与RSP-14T一样,能降低“1-0”的翻转概率。
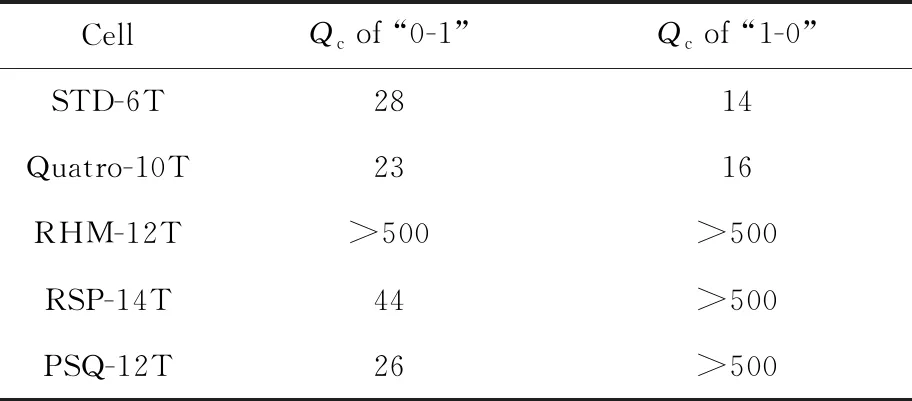
表5 不同单元发生SNU时的临界电荷Tab.5 Critical charge of different cells at SNU
对于MNU,有发生在相同和不同势阱内2种情况,如表6所列。(1) 相同势阱内发生MNU。PSQ-12T的敏感节点Q1,S2发生“1-0”翻转,Qs大于500 fC,这说明该结构能降低同一势阱里多节点发生“1-0”翻转的概率。而其他单元受类似翻转影响时,单元的临界电荷都小于500 fC。(2) 不同势阱内发生MNU。PSQ-12T存储单元有2种翻转组合:如S2点产生“1-0”翻转,同时Q4点产生“0-1”翻转;Q1点产生“1-0”翻转,同时Q2点产生“0-1”翻转。由于大部分加固结构不能从写入点Q1,Q2的多节点翻转组合中恢复,本文只对比前一种翻转组合的Qs。PSQ-12T结构单元中,S2点产生“1-0”翻转,Q4点产生“0-1”翻转时,单元的Qs大于500 fC,大于除RHM-12T外其他单元结构的Qs,所以,PSQ-12T抗不同势阱中MNU的能力也大于除RHM-12T外的其他单元。

表6 不同单元的共享临界电荷Tab.6 Sharing critical charge of MNU in different cells
对PSQ-12T存储单元的敏感节点Q1,Q3,Q4,S2进行电流注入仿真,如图7所示。由图7可见,Q1,Q3,S2分别存储“1”,在时间t为10,20,30,40 ns时分别对Q4,Q3,Q1,S2进行单节点的电流注入,Q4,Q3,Q1,S2分别产生了“0-1”,“0-1”,“1-0”,“1-0”的单节点翻转,最终存储单元能恢复到初始存储状态。当t为50 ns时,对S2和Q3同时进行电流注入,最终存储单元也能恢复到初始存储状态。
4 结论
本文设计了一种抗单粒子效应SRAM的12T存储单元PSQ-12T。该单元的面积消耗与传统12T单元相同,具备抗特定SNU和MNU的性能,数据保持稳定性和读稳定性都优于传统加固单元。PSQ-12T存储单元采用高阈值MOS管,使静态功耗和动态功耗都小于其他单元。与其他单元一样,PSQ-12T无法完全免疫一些特殊组合的MNU,但发生翻转时的临界电荷都大于500 fC。
猜你喜欢
学校教育研究(2021年20期)2021-12-14
防爆电机(2020年4期)2020-12-14
中学生数理化·八年级数学人教版(2020年4期)2020-10-29
中学生数理化(高中版.高考理化)(2020年10期)2020-10-27
初中生学习指导·提升版(2020年6期)2020-09-10
语数外学习·初中版(2020年5期)2020-09-10
新高考·高一物理(2016年7期)2017-01-23
中学生数理化·八年级数学人教版(2016年2期)2016-04-13
新高考·高一物理(2015年6期)2015-09-28
新高考·高一物理(2015年6期)2015-09-28
