
基于深度学习的文本到图像生成方法综述
2022-05-19 13:25王宇昊
计算机工程与应用 2022年10期
王宇昊,何 彧,王 铸
1.贵州天衍炬恒科技有限公司,贵阳 550081 2.北京大学 地球与空间科学学院,北京 100871 3.贵州师范大学 地理与环境科学学院,贵阳 550025
目标视觉信息的传统描述方法是根据目标属性进行表达,目标特征的区别需要从对象类型编码到向量表达实现[1-2],2014年具有代表性的方法被提出,包括零样本识别方法[3]和有条件图像生成方法[4]。这类方法的特点是具有较强的属性表达辨别力和泛化力,但需要特定领域的知识信息表达支撑,从而导致属性获取过程较为复杂。相比之下,自然语言提供了较为通用、灵活、直观的方式来描述时空视觉对象,文本生成图像方法主要采用自然语言与图像集特征的映射方式,根据自然语言描述生成对应并具有足够视觉细节的图像,且在语义上与文本的描述保持一致,利用语言属性智能化实现视觉图像的通用性表达。
近些年,随着深度学习理论技术的蓬勃发展,计算机视觉和图像自动化处理技术的研究已获得显著的创新和应用的突破。2014年,由Goodfellow等人[5]首次提出生成式对抗网络(generative adversarial networks,GAN),作为一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。2017年后,基于生成对抗网络的深度机器学习方法,已经被广泛地使用在文本描述到图像生成的技术中,并形成目标属性描述的高度区分和可泛化特点[6]。通过使用文本描述生成一个直观的可视化图像,可以引用与当前对象、属性信息、空间位置和关联关系等密集语义信息,为支持复杂多样的场景实现奠定良好基础,例如文本建模[7-8]、智能人机交互[9]、视觉障碍者协助、智能问答[10-11]、机器翻译[12-13]等方面。
在该综述中,将深入到图像合成中的定向研究领域,聚焦到机器学习技术在文本到图像生成(text-to-image,T2I)技术中的应用。主要目的是描述基于深度学习技术的文本到图像生成的基本原理方法,从文本生成图像方法的主流技术开展分析讨论,主要包括直接方法、分层体系结构法、注意力机制法、周期一致法、自适应非条件模型法和附加监督法。同时,总结归纳图像生成的各项质量评估指标,并综合讨论图像生成方法和评估方法的特点、优势及局限性。最后讨论该研究领域面临的挑战和未来的发展方向,为该领域的基础研究和场景应用提供辅助参考。
本文的主要贡献如下:
(1)综述了关于深度学习文本到图像生成研究的最新进展,包含许多已有综述中没有出现的最新的重要参考文献,该综述有利于研究者快速熟悉和掌握文本到图像生成领域。
(2)对深度学习文本到图像生成方法分类总结,介绍各类型具有代表性的方法,并讨论这些方法的构建思路、模型特点、优势及局限性,有助于该领域研究者更好理解文本到图像生成领域的相关技术。
(3)对生成图像的质量评估指标进行总结归纳,分析各类评估方法的技术原理及特点,讨论未来的发展方向。
(4)对文本到图像生成领域面临的各项机遇和挑战总结讨论,并论述在模型方法、评价指标、技术改进及方法拓展等方面的挑战和未来的发展方向,有助于启发并开展更有价值的研究工作。
1 生成式对抗网络
掌握生成式对抗网络(GAN)运行机制是实现基于深度学习的文本到生成图像技术的基础,GAN是在卷积神经网络基础上拓展的一种深度学习模型,也是近年来复杂分布上无监督学习最具前景的方法之一。作为全新的非监督式架构模型,框架通过主要的两个模块,即生成模型(generative model,GM)和判别模型(discriminative model,DM)的互相博弈学习过程中达到纳什平衡,最终实现逼近真实的最佳输出结果。生成模型是根据目标预测的隐含信息,随机产生观测数据;判别模型需要输入相关变量,通过特定应用模型实施目标预测。图1描述了GAN网络的主要结构。
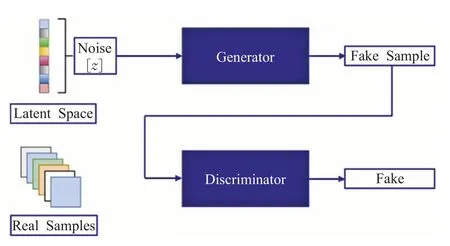
图1 生成对抗网络(GAN)结构图Fig.1 Structure diagram of GAN
在原始GAN中,无法控制要生成的内容,因为输出仅依赖于随机噪声。可以将条件输入c添加到随机噪声z中,将生成图像由G(c,z)定义,称为条件GAN(conditional generative adversarial networks,CGAN)[14],通常条件输入矢量c与噪声矢量z直接连接,并且将得到的矢量原样本作为发生器的输入,与原始GAN一样。条件包括图像类、对象属性以及嵌入图像的文本描述或图片。与其他的生成模型开展比较,例如PixelRNN(pixel recurrent neural network)[15]、AVB(auto-encoding variational Bayes)[16]、GSNs(generative stochastic networks)[17]、BM(Boltzmann machines)[18]等,GAN的优势在于:(1)应用方向传播,替代传统的马尔科夫链预测;(2)模型训练采用权值纠正,不用做隐变量推断;(3)模型支持偏微分运算,构建生成网络G和判别网络D与神经网络相结合做深度生成模型;(4)模型参数更新通过判别网络反向传播实现,代替传统的样本数据纠正方式。
2 文本到图像生成方法
文本到图像生成方法旨在通过机器学习或深度学习的方法,根据文本描述的信息自动生成满足用户所需的虚拟图像。这类算法在简单的语义结构下能够表现较好的成果,但当文本描述的目标信息或场景相对复杂时,图像生成的过程将受到不同程度的影响,最终导致图像结果不理想,包括分辨率低、目标错误、边界混淆、布局错乱等情况。这使得文本到图像生成技术成为具有挑战性的研究课题,同时具备较高的研究价值。因此研究者们为突破原有的方法局限,从不同场景、适应条件、模型结构、处理算法等方面开展创新研究。目前将具有代表性的基于深度学习的文本到图像生成方法总结归纳如图2所示。

图2 文本到图像生成方法归纳Fig.2 Method induction of text-to-image generation
2.1 直接图像法
早期图像生成方法主要以变分自编码器(variational autoencoders,VAEs)[16]为主,考虑概率统计分布,是基于最大化数据的最小可能性实现图像生成的方法。直接图像法都遵循在模型中使用一个生成器和一个判别器的原理,并且其结构是直接的构成,没有分支结果组成,许多最早的GAN模型属于这类型。
生成式对抗网络可以扩展为条件模型,成为条件生成对抗网络(CGAN)[14],即生成器和鉴别器将以一些额外信息为条件,y可以作为任何一种辅助信息,如类别标签或其他模式数据。可以通过将y作为额外的输入层同时输入鉴别器和生成器执行调节。在生成器中,先验输入噪声p z(z)和y能够在隐藏表示中组合,并且对抗训练框架对隐藏组合的表达具有较高灵活性。在鉴别器中,x和y分别作为输入和鉴别函数,目标函数表达如下:
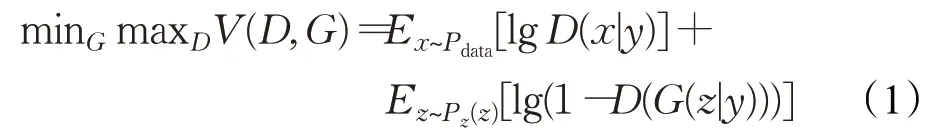
为了提供更多的辅助信息并允许半监督学习,可以向判别器添加额外的辅助分类器,以便在原始任务以及附加任务上优化模型。添加辅助分类器允许使用预先训练的模型,并且在ACGAN(auxiliary classifier GANs)[19]中的实验证明,这种方法可以帮助生成更清晰的图像以及减轻模式崩溃问题,辅助分类器能够应用在文本到图像合成技术中。采用跨模态方式实现信息域转换,以StackGAN(stacked generative adversarial networks)为基础增加条件自编码模块[20],共用生成器实现特征增强,缓解直接图像法易出现的模式崩塌情况。
为解决图像生成细粒度的属性识别问题,Reed等人[6]提出文本生成图像方法,图像生成将来自整个句子预先训练的编码器所嵌入的内容,实现端到端与属性细粒度和类别特定的图像相结合,应用的模型是对CGAN的改进,用文本内嵌的φ代替类标签y。在GAN-INTCLS[21]方法中,构建匹配感知鉴别器如图3所示,将三种不同的图像对作为鉴别器的输入。该方法不仅让生成器和鉴别器关注真实的图像,而且将其与输入文本匹配鉴别。对比之前采用的GAN方法,其首次提出利用GAN来实现句子描述合成图像,替代了利用类标签作为条件合成图像的方式,并且通过简单的插值方法来生成大量新文本描述数据,解决由于文本数量较少所限制合成效果的问题。
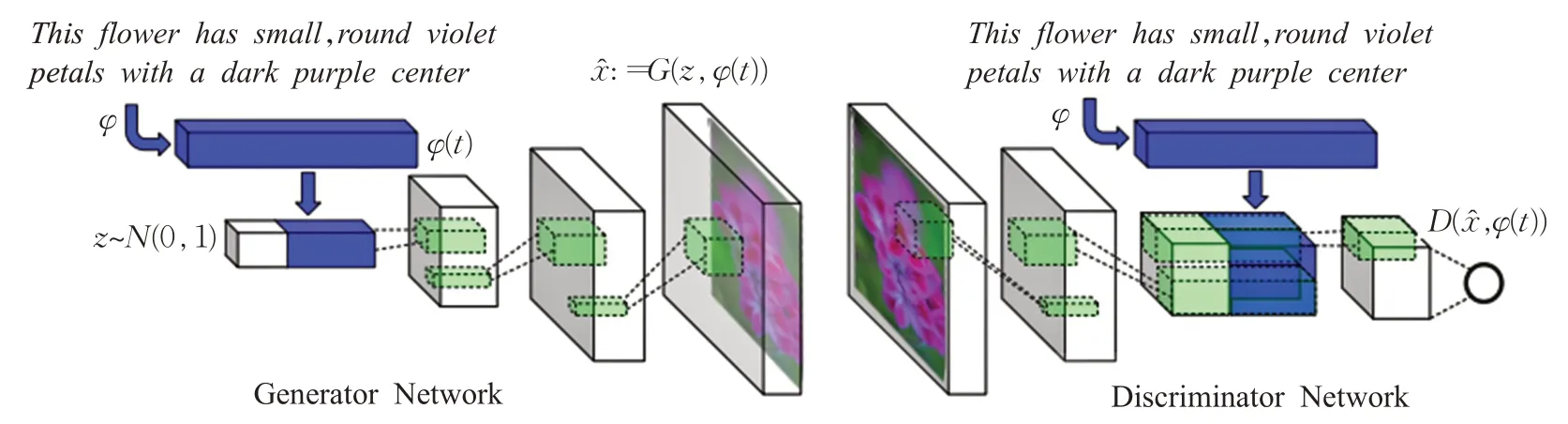
图3 GAN-INT-CLS模型结构图Fig.3 Architecture diagram of GAN-INT-CLS
Dash等人提出了分类器生成对抗网络(text conditioned auxiliary classifier GAN,TAC-GAN)[22],该网络建立在ACGAN基础上,通过将生成的图像设置在文本描述上代替类标签。该模型在生成网络中输入的向量为噪声向量和包含文本描述的嵌入式表达向量,鉴别器在ACGAN的基础上将分类前接收的文本信息作为模型输入,使用Skip-Thought向量从图像标题中生成文本嵌入,并结合该模型的特点引入额外的辅助分类损失函数,达到与ACGAN模型相似的风格效果,即生成图像具有可鉴别性和多样性特征,通过文本描述之间插入,可以相同的风格合成内容不同的图像。
综上所述,直接图像法引入了条件模型,提供了更多的辅助信息,支持半监督学习,并不断改进图像生成细粒度的相关问题。该类方法的另一个特点是引入额外信息作为向量,通常包括噪声信息、文本补充信息、辅助分类信息等内容。但该方法缺点是依赖监督辅助条件的选择,依赖条件与应用场景的符合程度将决定图像生成的质量及布局等信息表达。此外,该模型主要学习数据分布模式,存在易于崩溃的缺陷,例如生成器对相似但不同的描述会生成相同的图像。另一个挑战是模型将重点关注全局句子向量,有用的细粒度图像特征和单词级文本信息将容易被忽视。
2.2 分层体系结构法
分层体系结构法与直接法相反,算法在其模型中分别由两个生成器和两个鉴别器构成,不同的生成器具有不同的功能。核心思想是将图像分成“样式和结构”和“前景和背景”两部分,两个生成器之间的关系支持并联或串联,目的是相互结合逐步生成精细图像,能够更好地识别异构上下文的模式。
考虑到简单地增加更多的采样层来提高分辨率,会导致模型不稳定或者生成真实度低的图片,其主要问题在于生成器的生成图像分布和真实图片的分布没有交叉重叠提取特征。Zhang等人[23]提出了StackGAN方法,StackGAN文本特征处理架构如图4所示。该模型对CGAN进行改进,主要解决CGAN不能生成高清图的问题。该方法提出构建两个GAN的结构,分别解决目标物体的形状和颜色以及分辨率增强问题。该方法采用条件增强技术,即从独立的高斯分布N(μ(Φt)Σ(Φt))中随机采样得到隐含变量并放入生成器,通过产生更多的条件变量提高生成图片的多样性和模型稳定性。
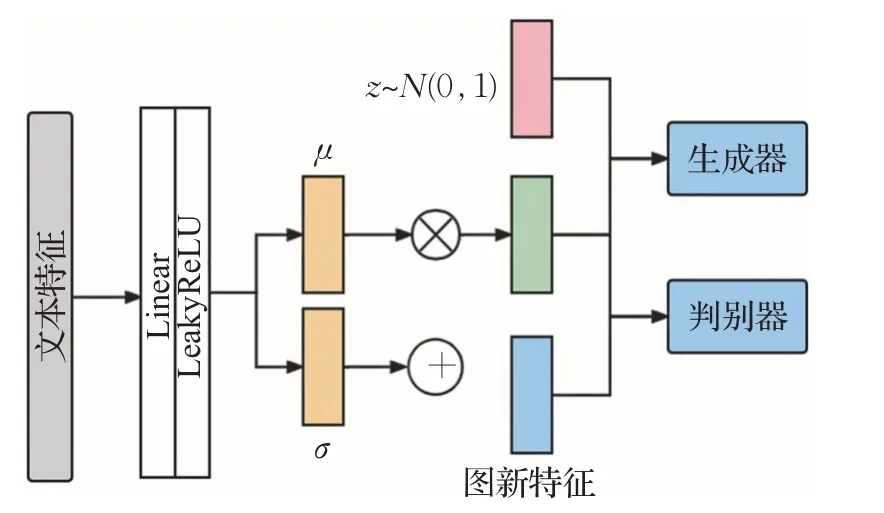
图4 StackGAN文本特征处理架构Fig.4 Architecture of StackGAN text feature processing
现有的文本到图像生成方法采用的样本可以大致反映文字描述的含义,但没有包含必要的细节描述和形象的目标对象内在关系。为解决该问题,Zhang等人提出StackGAN++(stacked generative adversarial networks++)方法[24],主要采用树状结构,框架如图5所示。通过多个生成器生成不同尺度的图像,每个尺度对应一个鉴别器,生成了多尺度图像分布。其特点是构建一个两阶段生成对抗网络体系结构,不同于StackGAN采用两阶段独立训练模式,StackGAN++可以采用端到端(end-toend,E2E)的训练方式。该方法引入颜色一致性正则化(color regulation,CR),对生成模拟图像的色彩信息进行限制,其目的是尽量减少不同尺度像素的均值和协方差之间的差异,整体效果是提高训练的稳定性,且提升生成的图像质量。为解决低分辨率特征图卷积时依赖局部特征,不利于捕获文本向量远距离信息的问题,通过文本描述生成图像任务和解耦表征并分层生成图像[25],利用单词级注意力模块细化图像并微调嵌入词,能够很好地表达形状和颜色特征。
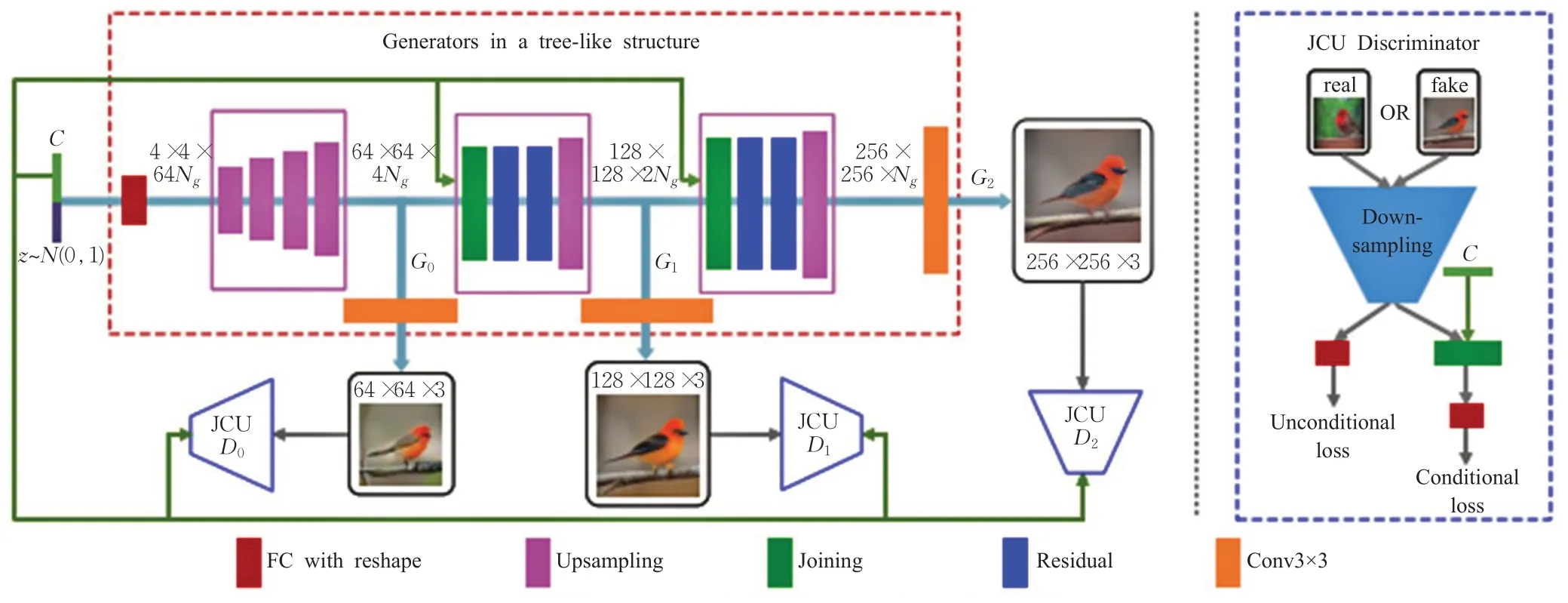
图5 StackGAN++条件合成模型架构图Fig.5 Architecture diagram of StackGAN++model with conditional composite
在此基础上,为了进一步满足对多个生成网络的构建需求,HDGAN(hierarchical-nested GAN)[26]伴随层次嵌套对抗性目标,在多尺度中间层上采用了分层嵌套的判别器来生成512×512图像。模型架构如图6所示,并对比其他不同结构模型,HDGAN通过采用一种可扩展的单流生成器架构(extensile single-stream generator architecture,ESGA)使联合判别器更好地开展训练,生成高分辨率图像。并使用多用途的对抗性损失(multipurpose adversarial loss,MAL)使低分辨率层的判别器关注全局特征,高分辨率的判别器聚焦于局部的细粒度特征,更有效地使用图像和文本信息提升生成图像保真度。
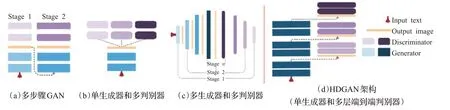
图6 HDGAN模型架构图Fig.6 Architecture diagram of HDGAN
为减少图像卷积过程中导致的特征信息损失,并增强语义一致性、图像保真度和类不变性,可以让生成器采用感知损失来增强语义相似度信息,在生成器上定义感知损失可获得不同的图像,通过多用途鉴别器以提升语义保真度和完整性。Gao等人[27]提出了感知金字塔对抗网络(perceptual pyramid adversarial networks,PPAN),通过金字塔框架[28]以对抗的方式直接合成文本条件下的多尺度图像。通过设计一个金字塔发生器和三个独立的鉴别器代替多阶段GAN,在前馈过程中合成和正则化多尺度的真实感图像。在每个金字塔层,PPAN以粗分辨率特征作为输入,合成高分辨率图像,并使用卷积向上采样到更精细的层次。
目前文本到图像生成的GAN都采用堆叠结构作为主干,通常利用跨模态注意机制来融合文本和图像特征,并引入额外的卷积神经网络来确保文本和图像的语义一致性。为实现一个简单且有效的文本图像模型,DFGAN(deep fusion GAN)[29]作为一种创新的文本图像融合模块被提出,多尺度全局特征根据多个步骤自适应的融合提取,以满足低空间分辨率的特征图像获取,并包含生成图像的整体语义结构。受ResNet(residual network)[30]的启发,采用身份和权重加法及快捷连接作为融合方法,总体有效提升细节构成,可以使生成器在不引入额外网络的情况下合成更真实且文本图像语义一致的图像。与现有的文本图像模型相比,该方法更简单且有效地合成与真实文本描述相匹配的图像。在研究中通常以动物或花卉作为对象,以人物图像为研究对象值得深入探索。充分结合人物姿势、体态、外貌、纹理特征,构建人物画像,通过自适应归一化方式实现像素级映射,并构建多模式操作网络生成颜色和细节更细腻的人物图像[31]。构建谱归一化的SN-StackGAN(spectrum normalization StackGAN)[32]模型约束判别器各层网络,并结合感知损失函数,加快判别器收敛速度并增强网络稳定性,并提高图像分辨率。
综上所述,分成体系结构法采用多个联级的生成器和鉴别器结构,能够有效地实现关键信息分离,实现针对性的精细化处理,增强语义一致性优势。并且在模型构建中会包含必要的细节描述和形象目标对象的内在关系等信息,可有效增强图像信息的表达能力。但该类方法会采用交叉重叠的网络模型,导致特征信息被重复提取,使信息处理量增大,计算资源和时间占用过大。并且存在对多任务处理或多尺度小目标处理难度较大等不同程度的问题,将会导致生成图像的质量下降,减少所生成图像的多样性。当文本描述的场景或对象相对复杂时,该问题会更加严重。
2.3 注意力机制法
注意力机制可以利用人类视觉机制进行直观解释,例如人类的视觉系统倾向于关注图像中辅助判断的部分信息,并忽略掉不相关的信息[33]。注意力模型现在是解决多任务最先进的模型[34],能够在主要任务上提高性能,并且被广泛用于提高神经网络的可解释性。注意力机制模块如图7所示,该机制能够通过加权重要的部分而忽略不重要的部分,使网络重点关注输入层,并且在提升语言分析和计算机视觉上拥有举足轻重的意义。该技术除了构建全局句子向量外,还支持卷积神经网络根据相关单词合成的细粒度。
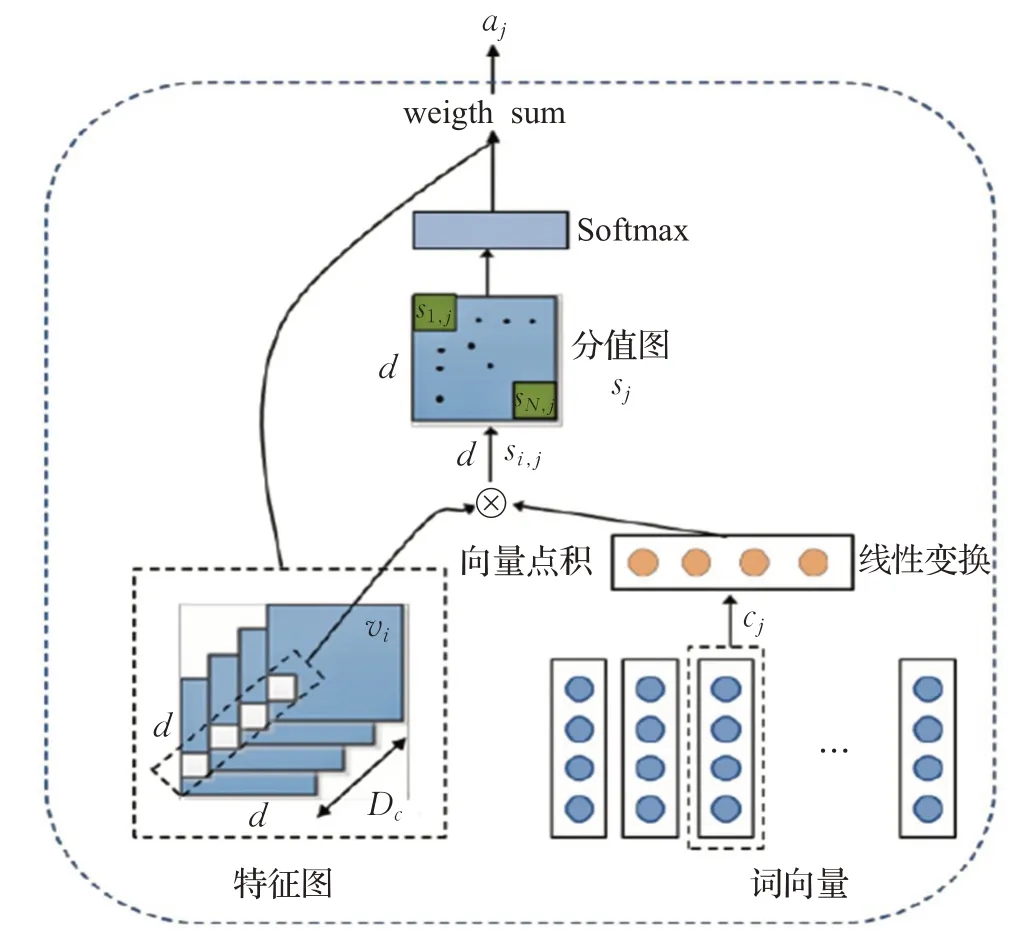
图7 注意力机制模块示意图Fig.7 Schematic diagram of attention mechanism module
注意力机制允许网络根据相关单词合成细粒度的细节以及全局句子向量,在生成过程中使网络关注图像子区域最相关的单词。AttnGAN(attentional GAN)[35]建立在StackGAN++[24]的基础上,将注意力纳入多级精炼管道,通过深度注意力多尺度相似模型(deep attentional multimodal similarity model,DAMSM)的损失计算,评估基于句子和单词级信息计算生成的图像与输入文本之间的相似度。Huang等人[36]扩展了基于网格的注意力机制算法,简称为RIG(realistic image generation)方法,在对象网格区域和词短语之间增加了一种机制,其中对象网格区域由辅助包围框定义。在句子和单词特征的基础上,应用部分词性标注技术提取短语特征。若构建标题匹配模型,根据先验知识确定候选标题,可利用多标题注意力的特点构建GAN生成特征图像,突显文本描述的主要图像特征[37]。
由于训练数据集受限,存在难以涵盖所有领域的图像信息,描述语句存在词语缺失以及语义信息不足等问题,使生成图像无法得到较好效果。并且关键词与非关键词的分离问题将很大程度影响模型的稳定性与准确性。语义增强生成对抗网络(semantics-enhanced GAN,SEGAN)[38]模型能用于高细粒度的文本到图像的生成技术中,很好地解决以上问题,其模型结构如图8所示。相对于传统的基于端到端并加入注意力机制的图像描述生成方法,该模型解决了图像描述生成语句语义信息不足的问题,并针对生成语句词汇不足的情况进行了补充,从而能够更准确地描述图像数据的语义含义。注意力竞争模块(attention competition module,ACM)和注意力生成网络(attention generation network,AGN)用于提取文本特性和图像特性,ACM包括一个新的注意正则化术语和DAMSM损失,能够使文本编码器提取AGN的可视化重要关键字。该算法将图像级的语义一致性融入生成对抗网络(GAN)的训练中,可以使生成的图像信息和特征多样化。在AGN中,由ACM预先训练的文本编码器提供语义向量对视觉上重要的词进行编码,构建了自适应注意权重来区分关键字和不重要的词,然后SEGAN生成器根据这些关键字合成图像子区域,该算法总体提升了模型的稳定性和准确性。
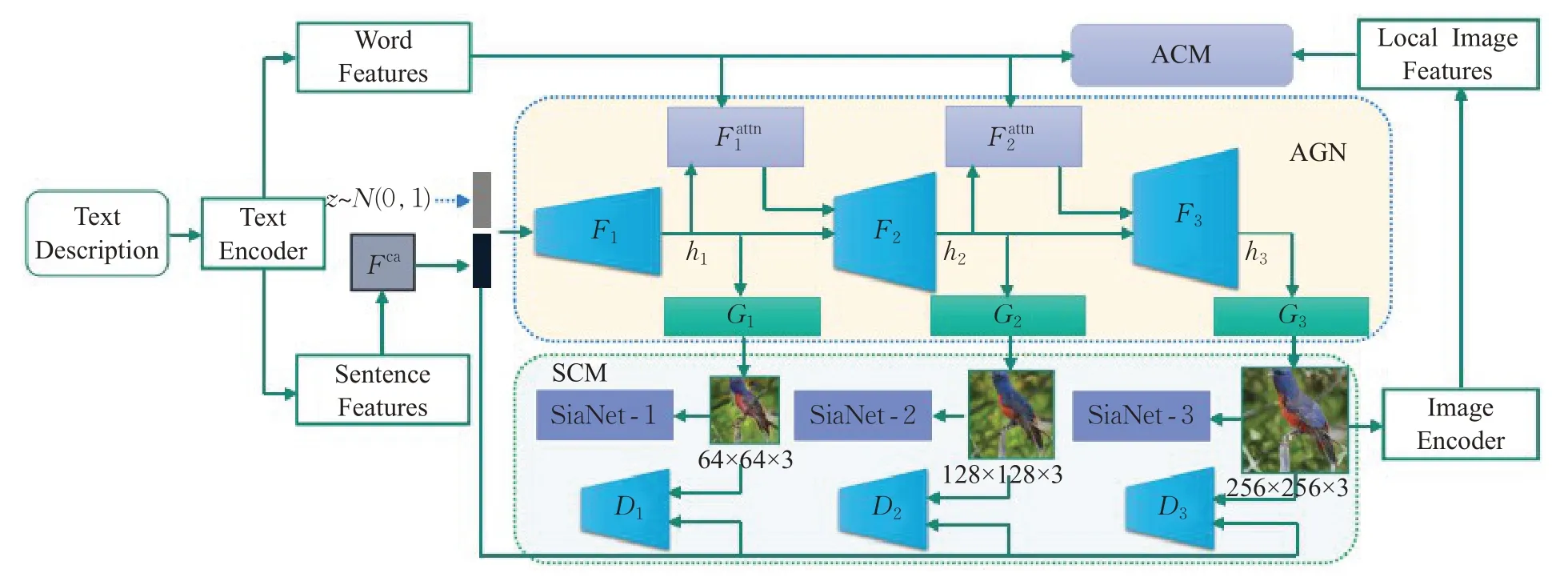
图8 SEGAN模型架构图Fig.8 Architecture diagram of SEGAN
在图像生成中由于文字的修改可能会使模型重新调整参数或训练,创建一个能够支持文字描述修改的监督反馈模型有助于模型改进,一种可控的文本生成图像的对抗生成网络(control GAN)[39]能够支持模型的动态反馈,通过自然语言描述控制图片生成的过程,合成高质量图片。该方法整合空间注意力模块能够分离不同的视觉属性,如类别、纹理和颜色等信息,并且让模型专注于最相关的单词所对应的子区域,结合细粒度的监督梯度反馈,提供精细的纹理训练信息,并利用单词和图像子区域之间的相关性来分解不同的视觉属性。
跨模态网络是带有对比损失的级联结构,这个损失是建立在判别器端两个树状的结构之间的对比损失,该结构有利于提取文本描述中的语义共同点,当网络的各个分支处理不同的文本输入生成图像时,模型参数采用共享模式。在文本描述中出现的同义词会导致图像生成差异,为能够实现同语义不同词的高层次表达以及文字表达的多样性特点,语义解纠缠生成对抗网络模型(semantics disentangling GAN,SDGAN)[40]如图9所示。整个模型是跨模态生成网络,可以看作主要由Siamese注意力机制和语义条件下的批度归一化(semantic conditions batch normalization,SCBN)[41]相结合,其中使用Siamese注意力机制在判别器中学习高层次的语义一致性,使用SCBN来发现不同形式的底层语义。该方法采用基于对比损失的方法来最小化或最大化每个分支中计算的特征之间的距离,从而学习语义上有意义的特征表达。该方法从文本中提取出语义的通用性表达,但存在忽略细粒度的语义多样性问题。在此基础上,通过SEGAN训练了一个复式架构并利用地面真实图像进行语义对齐,最小化生成的图像和对应的地面真实图像之间的特征距离。为了有效解决简单样本和难度样本的平衡问题,基于滑动损失[42]提出了聚焦损失,以适应具备相对重要性的简单样本和难度样本对。Text-SeGAN[43](text-semantics-enhanced GAN)模型以条件GAN为基础,改进了鉴别器的一个辅助功能,使模型生成的图片不受特定种类的限制,并结合小批量(mini-batch)特征技术,在语义上匹配文本输入时解决了模式崩溃(mode collapse,MC)问题。为弥补细节信息表达的不足,采用跨模态数据,通过多尺度特征融合算法[44],构建目标对象驱动细粒度语义,结合布局特点生成逼真图像,充分考虑细粒度信息,包括结构、位置、轮廓、纹理等。
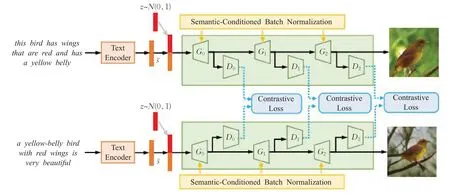
图9 SDGAN模型架构图Fig.9 Architecture diagram of SDGAN
综上所述,注意力机制法具备减少外部信息依赖,关注特征内部固有信息的特点,并考虑不同维度信息如通道、空间、时间、类别等,充分解决卷积神经网络多任务和单词合成的细粒度问题,拥有少参数并行处理方式的高效性及支持文字描述动态修改的灵活性。但该方法难以捕捉位置信息,即没法学习序列中的顺序关系,需要通过引入位置向量解决这类问题。由于目标图像中的像元都需要捕捉全局的上下文信息,这导致了自注意力机制模块会有较大的计算复杂度和存储量,并且存在信息捕捉的高效稀疏化问题有待解决。
2.4 周期一致性法
通常从给定的文本描述中合成图像包含在文本中明确描述的信息(例如颜色和构图等)以及风格,但在文本描述中一般很难精确地描述图像构建信息,例如位置、数量、大小等。之前的相关研究仅关注于从内容生成图像的过程,未着重考虑学习图像的风格表示。
为使模型能够使用文本描述内容信息,在生成图像时使用所需的样式风格,并生成与文本源密切相关的信息图像,同时达到通过推断文本源信息来控制样式的目的,相关课题已开展研究。例如Lao等人[45]受到对抗推理方法启发,提出双重对抗网络(dual adversarial inference GAN,DAI-GAN),通过无监督方式分离图像信息。该方法主要的目标是学习潜在的空间和风格的表达,空间中被分离的两个变量分别代表内容和风格。风格在模型中的整合信息最终取决于它的模式表现,例如文本中高频出现的风格信息拥有共享文本之间的共性,而低频出现的风格不作为内容描述,其风格由图像形态表示。周期一致性法解决了两个重要的问题:第一是在隐变量上加入先验知识,能够产生更高采样质量和更高采样多样性的图像,并充分考虑文本描述信息表达。第二是实现不同反馈网络模型的灵活接入,增强网络的动态处理能力。一些相关研究已经开展,例如PPGN(plug&play generative networks)[46]模型算法提出了基于条件网络的反馈,可以作为条件图像合成的分类器。该方法提出了一个统一的概率解释AM(activation maximization)理论,构建生成模型(即插即用生成模型)。其主要思想是迭代地找到潜在代码,让生成器产生一个图像,使反馈网络中的特定特征激活最大化(例如分类评分或RNN的隐藏向量)。在该框架中,通过插入不同的反馈网络,可以重新使用预先训练的生成器,从而提高模型接入的灵活性并提升结果质量。
为灵活接入附件网络实现图像的精准表达,受到CycleGAN(cycle-consistent GAN)[47]模型的启发,通过重新定义图像生成的循环网络架构,使模型具备文本到图像的精准语义表达能力,并通过附加语义网络,使训练该网络从合成图像中生成语义相似的文本描述。MirrorGAN[48]作为一个新的模型结构被提出,属于监督学习,并引入注意力机制。该模型结合了“全局到局部”的注意力机制和保留语义的Text-to-Image-to-Text框架,能够产生文本或句子层次的嵌入信息;平衡局部文字注意力和全局句子注意力以增强生成图像的多样性和语义连续性;对生成的图像再次描述生成对应文本描述信息。该方法通过一个“全局—局部”协作注意模型,无缝嵌入级联生成器中,以保持跨域语义一致性并平滑生成过程。此外,还提出了一种基于交叉熵(cross entropy,CE)的文本语义重建损失来监督生成器,以生成视觉真实和语义一致的图像。
在文本到图像的生成方法中,普遍存在由粗到细(coarse-to-fine,C2F)的研究思路,即先生成低分辨率的初始图像,再优化得到高分辨率的精确图像。为了解决普遍存在的两个问题:(1)生成的图像结果严重依赖于初始图像的质量;(2)文本句子的词语描述起决定作用,优化过程效果受限,图像信息未被充分利用到单词的重要性权重。动态记忆生成对抗网络(dynamic memory GAN,DM-GAN)[49]用于文本到图像的生成技术中,基于动态记忆的图像细化阶段通过动态存储、键寻址、值读取和响应,实现模糊图像细化、信息检索、寻址和特征读取,以细化低质量图像的视觉特征,其模型架构如图10所示。采用响应操作控制图像特征的融合和内存读取,通过记忆门内容突出重要的词语信息,并利用响应门自适应地融合从记忆门中读取的信息和响应步骤中的图像特征,进而从文本描述中准确生成输出图像。
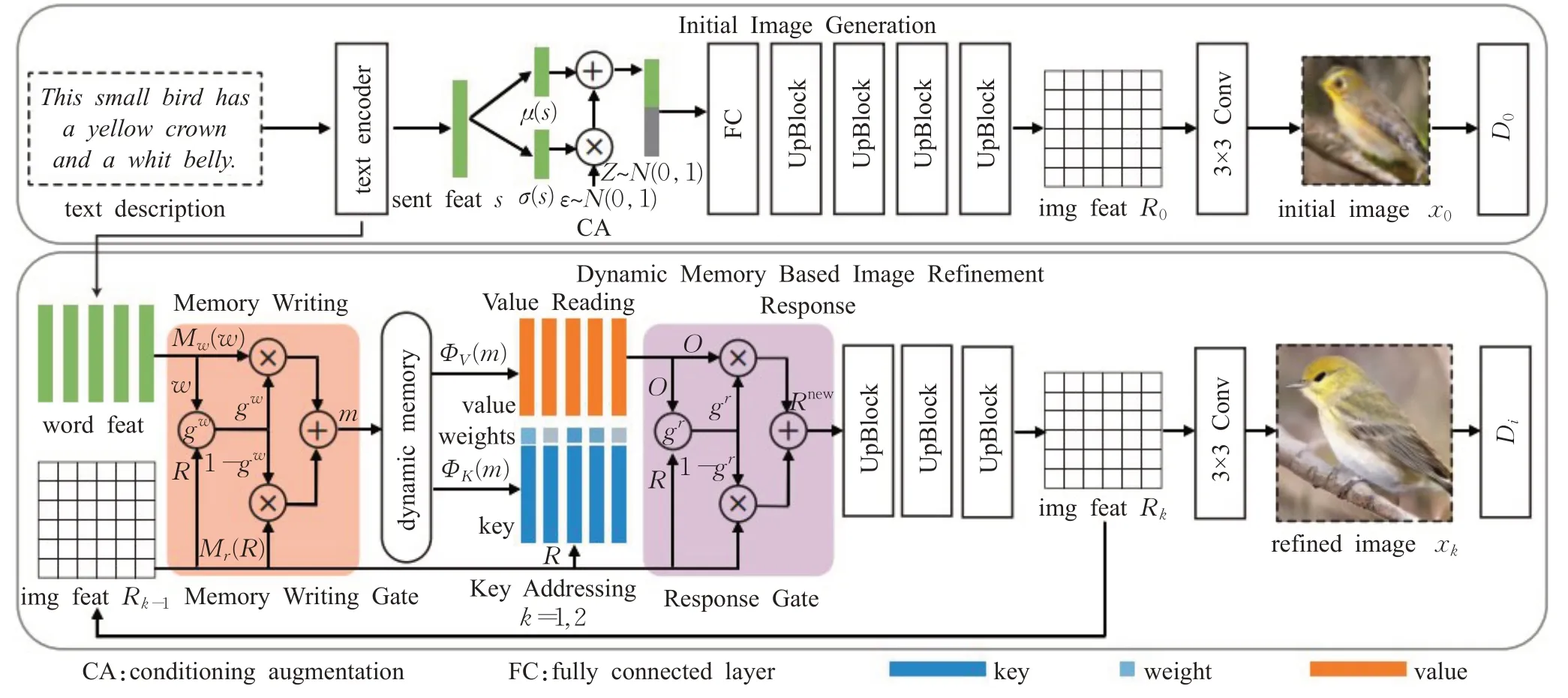
图10 DM-GAN模型架构图Fig.10 Architecture diagram of DM-GAN
综上所述,周期一致性法具有改善数字生态系统的潜力,它们能够将信息从一种表示形式转换为另一种表示形式,信息表现具备灵活转换能力,支持明确风格表达描述,且拥有模型接入动态灵活的特点,同时支持更高采样质量和采样多样性的图像输出。但该类方法在处理训练源数据时,会出现独立目标的任意变化现象,导致风格混淆问题出现,需要使用更广泛和更多样化的数据集缓解该问题发生;另外非色彩信息的几何更改会导致图像的几何信息的异常变化。
2.5 自适应非条件模型法
随着无条件图像生成技术的研究发展,该技术已经被成功应用到文本到图像生成方法中,通过自适应方式灵活构建文本描述,能够通过无附加条件的方式增强各环境下的模型适应性表达。通过权重加权语义方式结合噪声向量,去除信息干扰并增强核心信息表达,同时采用跨模态形式丰富信息表达是增强图像高质量合成的方式。文本到图像的模型Text-Style-GAN[50]方法在StyleGAN基础上进行扩展,能够获得比其他文本生成图像模型更高分辨率的图像,并支持语音分析。该模型架构如图11所示,其类似于AttnGAN[35]使用的预先训练的文本到图像匹配网络来计算文本和单词嵌入,在执行线性映射产生中间隐藏空间之前,先将嵌入句子与噪声向量相互连接。采用注意力机制引导在生成器中使用文字和图像特征,除了鉴别器中的有条件和无条件损失外,还使用跨模态投影匹配(cross-modal projection matching,CMPM)和跨模态投影分类(cross-modal projection classification,CMPC)的损失估计,将输入的文字标记与生成图像相匹配。由于文字属性堆叠生成缺乏真实性的图像,通过残差结构设计创新的注意力机制网络[51],并采用铰链损失稳定训练过程,结合跨模态投影机制通过细粒度辨别信息,增强图像分辨率。在该方法中会出现不自然的局部细节扭曲现象和生成缺陷图像,通过嵌入残差块特征金字塔引入多尺度特征融合[52],通过自适应融合方式生成高质量图像。

图11 Text Style GAN模型架构图Fig.11 Architecture diagram of Text Style GAN
构造过渡映射空间和共享信息的额外损失估计是解决文本描述与图像一致性问题的重要手段。利用中间网络将文本嵌入和噪声映射到一个过渡映射空间,同时构造的第一损失估计将计算中间的隐藏空间与输入文本嵌入之间的相互信息差,以保证文本信息存在于过渡空间。第二种损失估计将计算生成的图像与输入文本之间的相互信息差,以提高图像与输入文本之间的一致性。获得制约文本描述的潜在因素,为进一步的可解释表示学习提供依据,Bridge-GAN[53]在训练过程中采用了类似PGGAN(progressive growing GAN)[54]的生成器和鉴别器的方案,建立了一个过渡空间作为提高内容一致性的桥梁,通过关键视觉信息来学习可解释性表达;并设计了三元互信息目标优化过渡空间,增强视觉真实感和内容一致性。在解决合成图像与文本描述的一致性方面,Wang等人[55]提出了两个语义增强模块和一个新的文本视觉双向生成对抗网络(textual-visual bidirectional GAN,TVBi-GAN),通过语义增强的注意模块和语义增强的批处理归一化模块,注入随机噪声来稳定基于语言线索的尺度及变化操作,引入精确的语义特征来提高合成图像的一致性。
通过无条件作用实现多样性控制在文本到图像生成的方法中具有重要意义,能够增强表达的丰富性,对于文本描述的形容性词语或定语等语言表达具备更准确的图像生成能力。BigGAN[56]采用了数据截断和正交正则化技术,将正交正则化应用于生成器。该模型采用截断技术,通过一种简单的采样方法,能够在样本的逼真性和多样性之间做显性的细粒度控制。另外,通过减少生成器输入的方差,允许对样本保真度和多样性之间的权衡进行精细控制,保障了大型生成对抗网络训练过程的稳定性,采用矩阵的奇异值分析生成对抗网络训练的稳定性。基于DM-GAN[49]创建了类似记忆门的机制,在应用注意力机制之前计算单词特征和语义特征之间的量化权重。进一步构建从图像中提取语义特征的编码网络,在对抗性过程中,编码器可以引导生成器探索描述深层的相应特性,提升模型目标生成过程的表达性。
综上所述,自适应非条件模型法具备多样性表达特点,能够构造过渡映射空间并提供共享信息的额外损失估计,无需附加监督条件而自适应地开展模型训练,提供可解释性表示的学习依据,模型具有鲁棒性和适用性。但该类方法的图像生成的输入信息大多是句子向量,缺少风格层信息,生成图像缺少实例级别的纹理特征;在图像生成过程中,生成器容易忽视同场景之间的空间交互关系,整体图像存在移位、重叠和遮挡等问题。此外,判别器难以提供细粒度的训练反馈信息,对词级的实例视觉属性判别难度大。模型生成的描述对象的属性特征存在不同程度误差,图像生成的综合准确度和真实性有待提升。
2.6 附加监督法
上文讨论的文字到图像生成方法,其核心内容是围绕文字描述的信息生成与之相关图像。然而,存在一些方法将标题、对话、场景图和语义掩模等内容作为监督条件构建的模型,在模型的训练中会增加额外的标注信息,通过附加监督信息生成图像。
通常数据集中的单幅图像包含多个标题,通过多个标题能够提供更丰富的信息描述整个场景。在附加监督法的基础上结合注意力机制可将两种方法的优势充分结合,使模型既能实现多场景的I2T应用,又能减少外部依赖,突出内部固有特征,增强有效的细粒度表达。例如C4Synth方法[57]研究了多个标题生成图像,该方法使用混合标题描述的形式,通过跨标题循环保证了生成的图片和语义描述信息的一致性,并引入一个循环结构消除体系结构中标题数量的限制,能够合并多个标题内容的描述信息以生成单个图像。类似地,RiFeGAN(rich feature GAN)方法[58]作为一种具备丰富特征从文本到图像合成技术,利用了基于注意力机制的标签匹配模型,能够从先验知识中选择并提炼出兼容的候选标题,并利用多组注意力算法提取丰富的特征,合成高质量的图像。
一个句子难以提供足够的信息来描述包含多个关联物体的场景,通过场景对话产生的信息数据能够生动地生成图像。VQA-GAN(visual question answering GAN)[59]在本地构建的文字集合中,通过使用VQA2.0(visual question answering 2.0)中的问题和回答文字对话内容训练图像生成器。该方法在AttnGAN-OP(attentional GAN object pathways)[60]的基础上扩展了三个关键组成:第一是问题对话的编码器,把对话文字内容当作输入;第二是构建具备问题和回答条件的GAN网络,把之前输出的内容作为文字描述生成一个图片;第三是采用外部VQA损失增强问题对话和生成图片之间的关联。典型的VQA模型以图像和问题为输入,并开展模型训练,通过使负对数似然损失最小化来提升正确答案概率。
从布局到图像生成任务中每个对象都由边界框和类标签定义,能够为生成器提供更多的结构,有助于在图像中准确地定位对象,并且具有允许研究者通过更改布局控制生成的优点,结合布局信息的文本可实现更好的生成图像。例如OP-GAN(object pathways GAN)[61]通过在物体的位置添加生成器和鉴别器通道在重要的文字标记点位置上生成独立图片,一个全局通道生成一个能够适应整个图片描述和布局的位置。OC-GAN(object-centric GAN)[62]类似于AttnGAN中的DAMSM的场景图相似模型(scene graph similarity module,SGSM)来处理合并对象,构建一个能够理解单个对象和对象之间的关系生成复杂场景的模型,其模型架构如图12所示。该方法以对象为中心的生成对抗网络(OCGAN),根据SGSM,该模型能够学习场景中物体之间的空间关系的表示,使得该模型的布局保真度得到提升。同时,还提出对生成器的调节机制进行改变,以增强其对象实例感知能力,并取得显著效果。
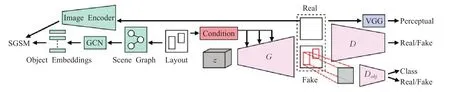
图12 OC-GAN模型架构图Fig.12 Architecture diagram of OC-GAN
针对生成图像算法中常出现的对象重叠和缺失问题,可有效利用掩模生成网络对数据集进行预处理,为数据对象提供分割掩模向量解决。将分割掩模向量作为约束条件,训练布局预测网络得到场景布局中对象的具体位置和尺寸,通过网络模型完成图像的生成。例如Hong等[63]通过两个步骤获取语义掩码,模型架构如图13所示,分别预测物体形状和其他信息。若直接完成输入文本空间到生成图像像素空间映射,数据具有高维度特性,难以找到合适的映射方式,因此从文字到图像像素直接增加了多个任务分解,实现生成匹配复杂文本描述的复杂图像。通过修改生成的场景布局,允许标注生成的图像、用户控制生成的过程,具备更好的灵活性。
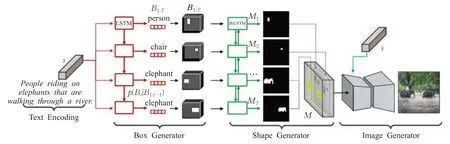
图13 语义掩码模型架构图Fig.13 Architecture diagram of semantic mask model
为利用网络对抗性学习来加强语义一致性和视觉效果,LeicaGAN(learn,imagine and create GAN)[64]方法将多先验学习阶段描述为文本-视觉共嵌入(textual-visual co-embedding,TVE)。该TVE包括用于学习语义、纹理和颜色先验的文本图像编码器以及用于学习形状和布局先验的文本掩码编码器。然后通过组合这些互补的先验并为多样性添加噪声,将想象阶段表示为多先验聚集(multiple priors aggregation,MPA)。最后使用级联注意力生成器(cascaded attentive generator,CAG)从粗略到精细逐步绘制一幅图画。GAN-CL(GAN contextual loss)[65]由一个网络组成,该网络经过训练可以生成掩码,从而提供细粒度信息,如物体的数量、位置、大小和形状。作者采用了真实和生成掩模之间的多尺度损失方法,并采用额外的感知损失和全局一致性损失,计划将图像掩模作为循环自动编码器的输入,以生成真实逼真的图像。
文本到图像的生成方法在特定对象,如动物或花卉的描述中可表现出较好的实验结果,但对于具有许多对象和关系的复杂句子的理解及图像生成的效果较差。通过基于场景图的文本到图像的生成方法,能够有效地突破对象的限制以及对复杂句式的理解,同样能够明确地推理对象及其关系,通过预测对象的边界框和分割掩模设计场景布局,将其转换为具有级联精化网络的图像。Pavllo等人[66]提出了一种用于复杂场景条件图像生成的弱监督方法(weakly-supervised approach,WSA),利用稀疏语义映射来控制对象形状和类,以及通过文本描述或属性来控制局部和全局样式,能够很好地控制场景中出现的物体。为了使该模型以文本描述为条件,引入了一个语义注意模块,该模块的计算代价与图像分辨率无关。为了进一步增强场景的可控性,提出了两步生成方案,将背景和前景分解,用于训练模型的标签映射是由一个大词汇量对象检测器生成的,它允许访问未标记的数据并提供结构化的实例信息。
在附加监督法的研究中,需要重点突破关键问题区别于其他方法,这类方法可以从生成图像控制、场景图精准匹配、语义结构及边界问题分离等方面着手,充分引用可视化关系布局、生成过程动态调整及对象关系融合等附加手段实现高质量图像的生成。例如SGGAN(scene graphs GAN)方法[67]使用了分割掩码技术,模型架构如图14所示。它将布局嵌入与外观嵌入分离开来,使研究者能够更好地控制和生成图像,从而更好地匹配输入场景图,外观属性支持从预定义的集合中选择或者来自另一个图像的复制。Stacking-GANs方法[68]中场景图被用来预测物体的初始边界,该边界框中每个独立的主语、谓语和宾语关系都由边界框的关系单位预先定义。由于每个实体可以参与多个关系,所有关系单元都被统一,并使用卷积LSTM(long short-term memory)[69]转换成可视化的关系布局。视觉关系布局反映了对象和关系的结构信息,在有条件的、堆叠的GAN架构中使用可视化的关系布局来渲染最终的图像。PasteGAN[70]使用场景图和对象来指导图像生成过程。当场景图编码空间排列和交互时,每个对象的外观由给定的对象物提供。对象物和关系表达融合在一起,最后输入到图像解码器生成输出图像。
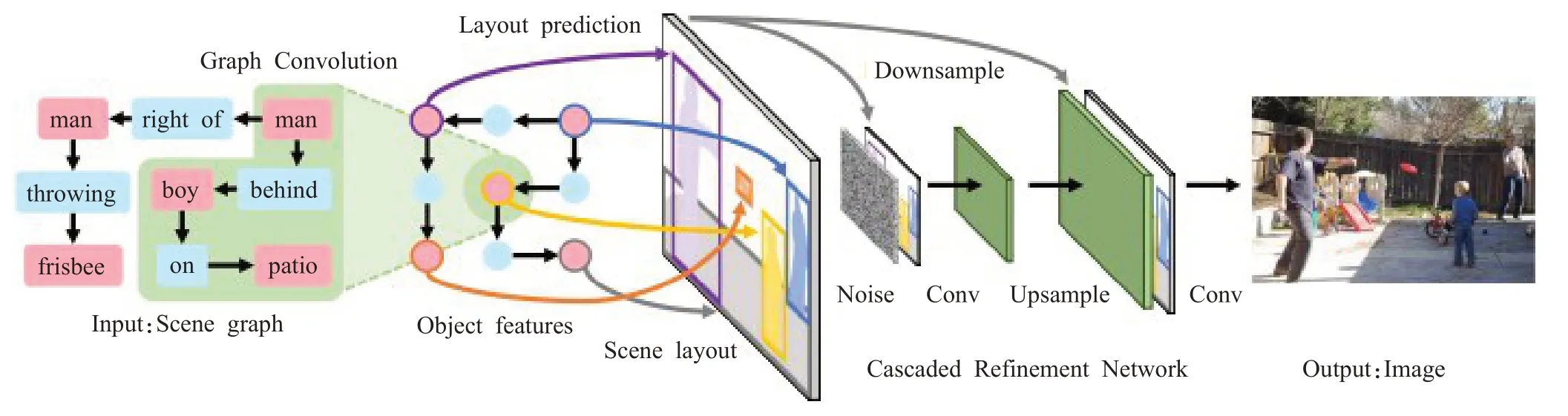
图14 SGGAN模型架构Fig.14 Architecture diagram of SGGAN
综上所述,附加监督法构建模型时充分将标题、对话、场景图和语义掩模等内容作为监督条件,增加了丰富的附加额外标注信息来生成图像。具备多标题表达、多模型结构、分割掩模向量约束、多阶段先验学习等特点,拥有生成图像的目标定位、布局控制、复杂句式理解、对象关系推理等优点。减少句子的复杂性和歧义性表达,使生成器能学习到实例的细粒度特征,判别器能提供准确的属性反馈信息,满足生成图像的高分辨率、实例形状约束、属性特征与描述的一致性体现等。但该类方法的缺点在于多结构模型的适应性以及附加监督信息的依赖性问题,例如针对不同类型目标生成应用,附加信息需要根据目标特点重新调整嵌入;对于同类不同物的目标描述存在不稳定现象,存在特征属性像元混叠或错误融合的情况;由于该方法涵盖的模型对象属性具有特殊针对性(如布局、对话、场景等),单模型缺乏多样性表达能力。
3 评价指标
对合成图像的质量开展量化评估工作存在较大的挑战,早期RMSE(root mean square error)等类似的评估指标并不十分精准,因为合成图像和真实图像之间并没有绝对的一对一的对应关系。AMT(Amazon mechanical turk)是常用的主观指标,它根据观察主观认知判定图像的逼真程度,对合成图像和真实图像进行评分。然而不同观察者对主观评价结论存在差异,因此也需要结合客观的指标来评估图像的质量。
在图像分类中,将数据放入预先训练的图像分类器模型,IS(inception score)根据分类概率分布的信息墒评估图像质量,Inception评分准则是图像x越好,条件分布p(y|x)的信息熵越低,意味着分类器对图像的内容有很高的评价。边际分布p(y)=∫p(y|x=G(z))dz应该具有较高的信息熵,代表模型可生成更多类别的图像。IS由exp(E x~G(z)DKL(p(y|x)||p(y)))计算得到,Lucic等人[71]在研究中讨论了Inception评分的缺点,指出它对标签的先验分布不敏锐,难以检测过拟合现象,并且初始得分还会受到类内模式崩溃的影响,不能够测量类内的变化情况。因为模型只需要为每个类别生成一个完整的样本就可以获得较高的初始得分,所以它不太适合评估更复杂的数据集,尤其是数据集图像中包含多种对象的数据。
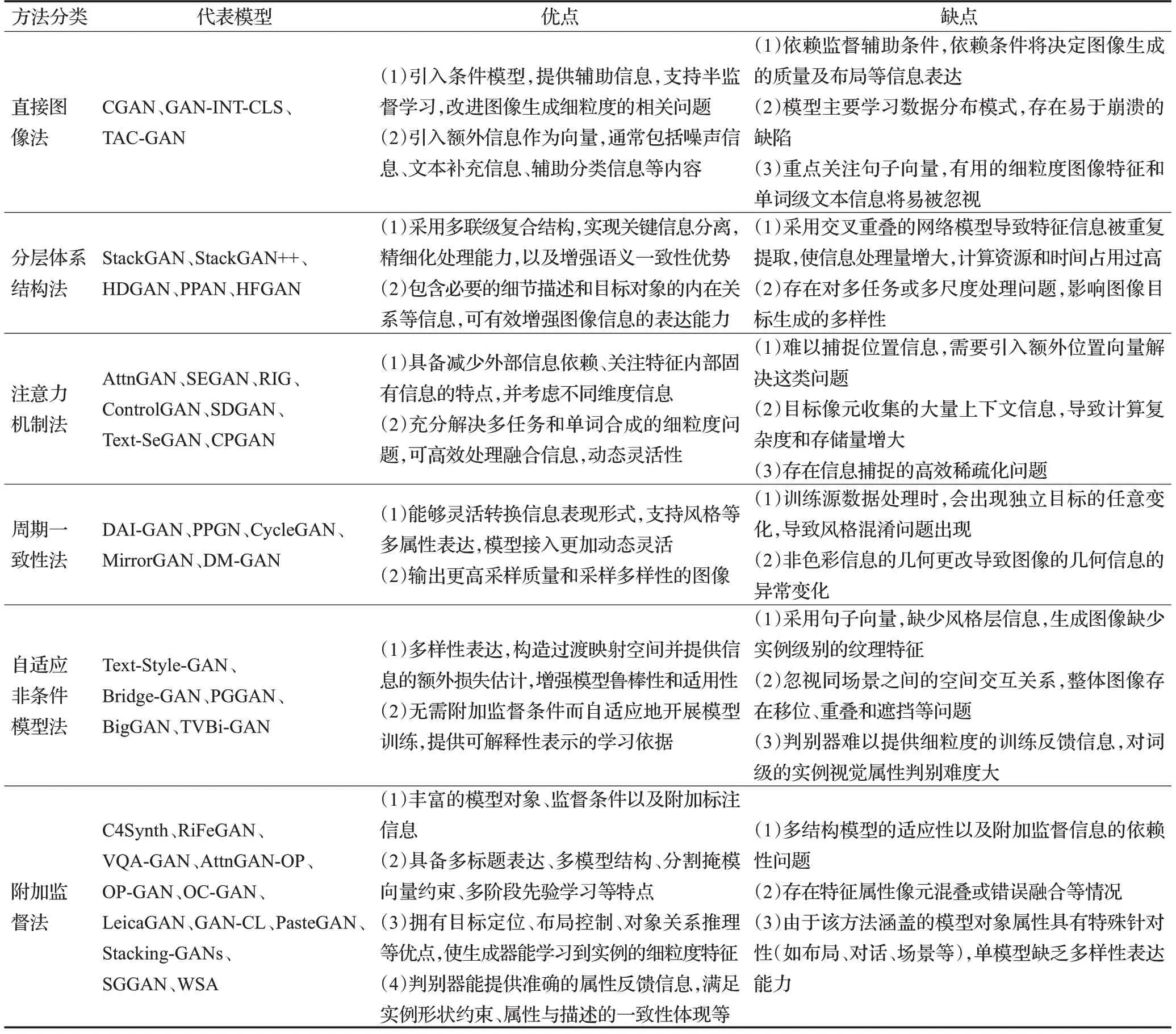
表1 各文本到图像生成方法的优缺点总结Table 1 Summary of advantages and disadvantages of each text-to-image method
与Inception评分类似,FCN-score[72(]fully convolutional network score)采用的思想是若合成图像是真实的,在真实图像上训练的分类器就能够正确地对合成图像进行分类。然而,图像分类器并不对输入图像的清晰度做要求,这意味着基于图像分类器的度量指标可能无法准确区分存在微小细节差异的两幅图像。另外,对抗性例子的研究[73]表明,分类器会受到人眼不可见的噪声影响,使该度量的准确度下降。
FID(Fréchet inception distance)[74]提供了一种不同的评估技术,主要是测量评估真实图像与生成图像之间的特征距离分布。首先生成的图像被嵌入到Inception网络所选层的潜在特征空间中,将生成的图像和真实图像的嵌入处理为两个连续的多元高斯样本,以方便计算其均值和协方差。生成图像的质量可以通过两个高斯函数之间的Fréchet距离来确定:
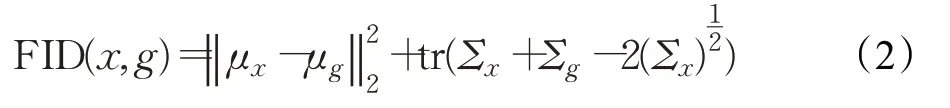
式中,(μx,μg)和(Σx,Σg)分别为真实数据分布和生成器学习分布中样本的均值和协方差。
除了IS、FCN和FID之外,还有GPW(Gaussian Parzen window)[75],GAM(generative adversarial metric)[76]和MS(mode score)[77]等指标。但Inception评分是定量评估合成图像研究中应用最广泛的一项指标。Heusel等[74]研究发现FID与人的判断较为一致,且FID与生成图像的质量之间存在很强的负相关关系。此外,FID对噪声的敏感度低于IS,能够检测类模式崩溃,且能更好地限制对各种干扰因素的评估[71]。
以下分类归纳了文本到图像生成的六种方法中具有代表性的模型评估指标,这些方法主要采用CUB、Oxford-102和COCO数据集开展研究和评价。直接图像法结果评估如表2所示,相比而言,在Oxford-102数据集中TAC-GAN较GAN-INT-CLS的IS评估结果更高,而FID评估具有相同的水平,对于其他数据集TACGAN缺少实验结果。分层体系结构法评估如表3所示,对于主流的数据集,HFGAN相比其他方法,在IS和FID指标评估中均表现出明显的优势;HDGAN在Oxford-102数据中的FID评估结果最好,为40.02±0.55。注意力机制法评估如表4所示,这类方法的研究者们均采用IS开展评估,SDGAN表现出了最好的效果,对于CUB数据集,SEGAN与其表现一致,均达到了4.67。周期一致性法结果评估如表5所示,这类方法也主要采用IS评估,DM-GAN在CUB和COCO数据集中的评估值分别为4.75和30.49,表现出了最好的效果,而DAI-GAN的评估结果最差。自适应非条件模型法结果评估如表6所示,对于CUB数据集TVBi-GAN的IS评价结果最佳,为5.03;而COCO数据集中Text-Style-GAN表现最好,达到33.00±0.31。附加监督法结果评估如表7所示,因为涉及到如多标题、布局、语义掩码、场景图等特点,这类方法的数量最多,但仍缺少某些数据集的评估实验。根据IS评估得知,Oxford-102数据集中LeicaGAN效果最好,为3.92±0.02,CUB和COCO数据集中RiFeGAN表现最佳,评估值分别为5.23和31.70;FID评估主要在COCO数据集中开展,WSA的生成图像具有最高质量,达到19.65。

表2 各直接图像法结果评估Table 2 Evaluations of direct text-to-image methods
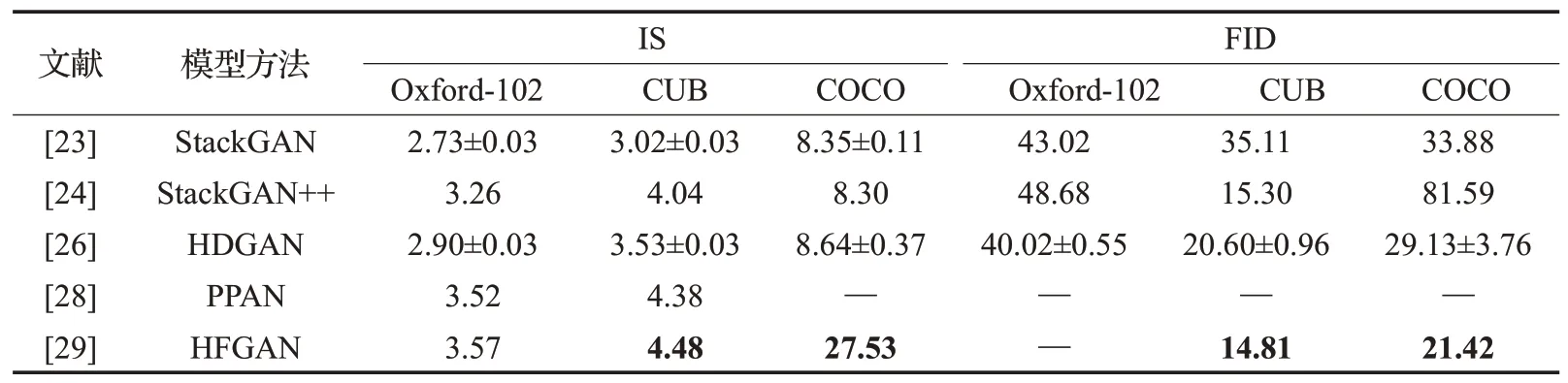
表3 各分层体系结构法结果评估Table 3 Evaluations of stacked architecture methods
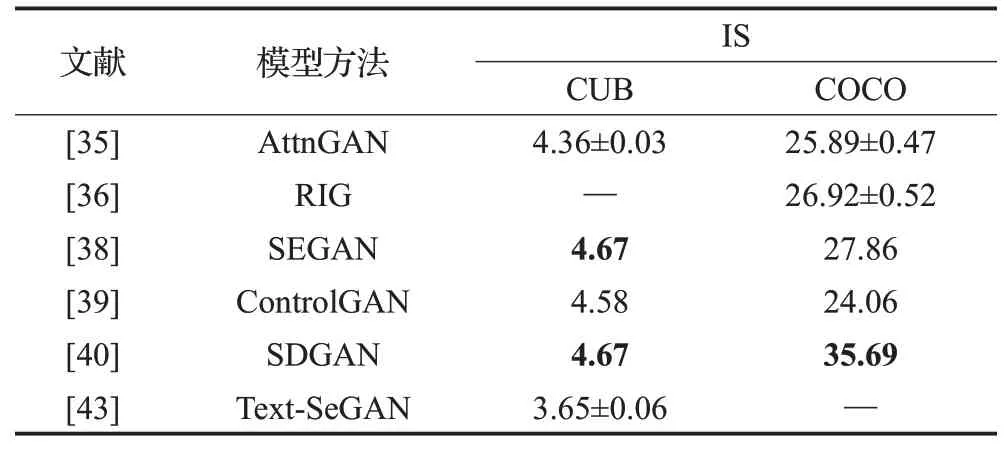
表4 各注意力机制法结果评估Table 4 Evaluations of attention mechanism methods
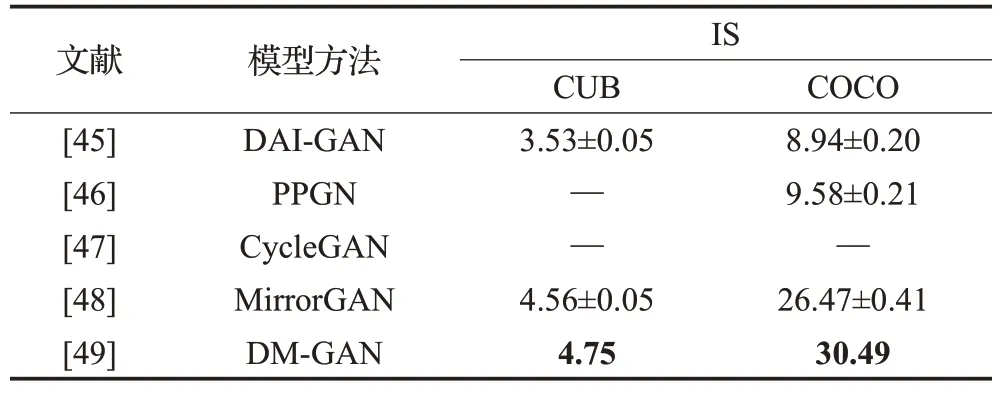
表5 各周期一致性法结果评估Table 5 Evaluations of cycle consistency methods
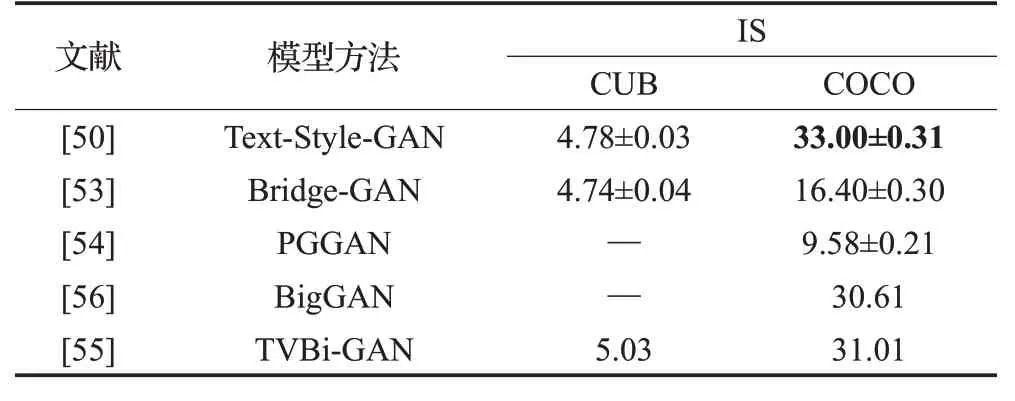
表6 各自适应非条件模型法结果评估Table 6 Evaluations of adapting unconditional model methods
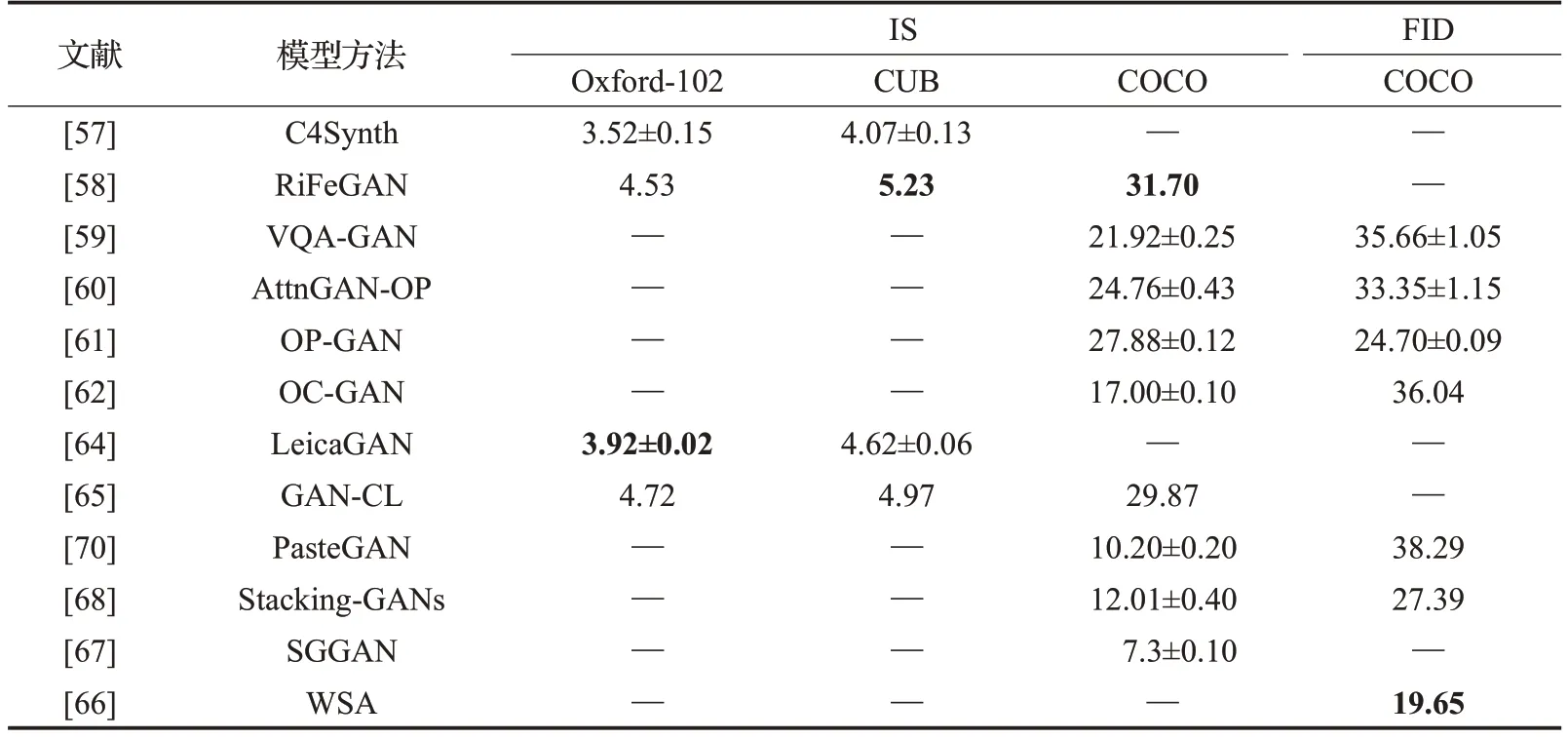
表7 各附加监督法结果评估Table 7 Evaluations of additional supervision methods
4 研究展望
4.1 模型方法
从文本到图像生成的方法已经历了长时间的发展和进步,与2016年提出的基于深度学习的初期体系结构相比,当前主流的方法是采用多个阶段式通道和损失评估函数构成的模型,如由生成器和鉴别器组成的GAN模型的损失评估。并且在低分辨率的图像生成到高分辨率的多种类型目标生成方面,已得到尤为突出的发展,但生成的目标图像的细粒度和清晰度仍然具有较大的挑战。例如采用句子级的描述来表达图像信息,则生成图像将缺乏细粒度表现,为生成高质量图像,模型及数据集对句子和词语的混合多层次映射关系具有较高要求。
模型对场景和对象的理解非常重要,目前的研究大多是基于单一目标图像开展,能够根据文字描述获得高质量的生成图像,但针对多个目标的复杂场景的图像生成难度较大。单句描述不能够满足模型对复杂场景的理解,尤其涉及到生成多对象、相互关联、复杂的场景图像等情况,未对场景的目标对象合理分解并准确理解。尽管已有部分研究开始注重多目标对象和融合场景的分析,但仍处于初期研究阶段,因此在多语句关联句式描述、丰富标签样本、场景对象生成等方面的研究工作值得进一步深入和拓展。
尽管目前使用的数据集提供了多文本的图像描述,但针对实际应用中存在的复杂场景的图像生成,标签样本数据难以支撑其模型生成。例如自然语言描述的句子或词语在模型中将被标注成向量,而向量与图像之间的映射关系可能存在多对一或一对多的情况,因此数据集中的文本描述与图像属性的信息丰富度,将决定模型的泛化性、复用性、精准性及适用性。
近些年文本到图像的生成方法大量集中到GAN模型的研究,尽管已经取得显著进展,但该模型仍然存在自身应用的局限,例如模型准确度问题,深度卷积神经网络模型本身所具备的特点导致模型的可解释性差,模型权重值的偏差分布没有显式表达,模型训练过程中捕捉到的重要视觉细节的文本特征表示会对模型准确性造成影响,并存在生成图像与真实性之间的偏差。因此鼓励拓展其他模型及研究方法,例如变分自动编码模型[16,78]、自回归模型[79-81]、流转模型[82-83]、分数匹配网络[84-86]和基于变压器模型[87-89]。
4.2 评价方法
评价生成图像的质量、多样性和语义准确度等标准是具有较大挑战的难题,也是一个开放性问题[90]。对公开数据集中的真实图像进行IS、FID、FCN-score等指标评估,这些指标均存在不同程度的缺陷。IS可能存在过拟合的情况,需要通过设置更大的Batch-size来改进[91]。Zhang等人[92]已经观察到模型生成的图像要比真实图像的FID评估分数高,原因是目前的训练模型与评估方法存在相同的文本编码器,模型在训练期间就已经过度拟合了该度量。IS和FID都使用了在ImageNet上预先训练过的Inception-v3网络,这在应用到多个目标对象的复杂场景图像时会存在问题。Hinz等人发现[60]IS对拥有多个目标的图像评估时其多样性和客观性较差,例如该方法会将同一类目标分配给不同图像和场景,并且其输出层具有较高的熵,解决该问题的一种方法是分别对单一场景开展评估。Sylvain等人[62]训练了一个从布局到图像的生成器,并提出了SceneFID(scene Fréchet inception distance,SceneFID)方法,它与FID类似,将应用参数输入边界框识别的目标中,且适用于未将布局作为条件输入的模型,其特点是能够使用预先训练的目标检测器来定位目标。
目前的许多文献表明了相同的模型可能会存在不同的评估分数,经过统计多篇论文中的模型评估结果,分析发现即使采用同样的方法评估同样的模型,不同的实验也将导致指标结果不一致。分数的变化取决于实现方式、图像分辨率、样本数量等因素。常见的问题是评估过程没有得到准确的解释,并且开源代码未包含评估代码。另外,部分研究在不断更新研究方法的源代码,存在评估结论与论文结果不一致的情况,为了保障论文方法的可重现性,本研究同样鼓励研究人员开源评估方法所用的代码,并提供精确描述。
发展具有较好适应性的度量指标存在一定困难,且生成模型会展开各方面的配置优化,难以获得具备普遍良好共识的评估效果。在未来的研究中,可以考虑研究能够将各项指标综合对比的评估方法,将充分考虑其图像高保真度及多样性、解耦表达、明确界限、尺度转化不变性、与人类主观评价的高一致性、计算简化性等特点。
综合以上讨论,创建一种新颖的、全面的且精准的评估方法存在很大的挑战,如何更好地使用现有的评估指标开展文字到图像生成的质量评估工作,给出以下建议:
(1)建议使用FID评估图像视觉质量并测量真实图像的距离分布;
(2)若图像中的目标位置已知,建议使用SceneFID进行目标评估;
(3)建议提供关于研究模型参数设置的详细描述,包括样本、模型、默认参数的数量等具体说明;
(4)建议研究人员不仅开放模型的源代码,并且开放生产结果的评估代码,并附上实现方式及版本号。
5 总结与展望
本综述介绍了当前基于深度学习的文字合成图像的方法及核心特点,并讨论这些技术所面临的挑战。本文将现有的文字生成图像方法分为直接图像法、多层体系结构法、注意力机制法、周期一致性法、自适应非条件模型法和附加监督法,并对这些方法进行了总结归纳,举例了已有方法的构建思路、模型特点、优势及局限性,突出基于深度学习的方法在文本到图像生成方面的重要性和先进性。
尽管近些年在基于深度学习的文本到图像的生成方法研究中已取得重大进展,但技术研究仍然存在进一步突破和改进的潜力,包括生成高分辨率图像、生成图像与文本描述的一致性、多场景适应性应用、生成图像质量评价标准及评估技术精准度的突破等。在模型架构方面,建议开展文本嵌入的重要性和结果质量分析,并探索文本到图像的生成模型对不同场景的理解与应用。另外,为实现文字到图像生成的场景应用,对图像生成过程进行细粒度控制尤为重要。因此,在采用模型实现图像生成的基础上,未来研究工作还应侧重于成果迭代及智能交互的实现。
本研究参考了当前主流的图像生成评估技术评价文字到图像的生成质量,随着IS、FID、FCN-score等评估指标技术的提出,能够更有效地采用定量指标评估图像生成的模型质量。除了客观指标评价,研究者的主观评价也尤为重要,但没有统一的标准存在,同样面临进一步的突破。期望本综述有助于研究者了解当前文本到图像生成技术所面临的挑战,并为该领域未来的研究发展提供参考。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
大学(2021年2期)2021-06-11
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
开放教育研究(2020年2期)2020-03-31
中国修辞(2017年0期)2017-01-31
长江学术(2016年4期)2016-03-11
中国卫生(2014年3期)2014-11-12
浙江人大(2014年5期)2014-03-20
