
基于WGAN-GP的微多普勒雷达人体动作识别
2022-05-23 06:38屈乐乐王禹桐
雷达科学与技术 2022年2期
屈乐乐, 王禹桐
(沈阳航空航天大学电子信息工程学院, 辽宁沈阳 110136)
0 引言
人体动作识别技术已广泛应用于智能安防、智慧养老和人机交互等多个领域。与其他传感器相比,雷达在人体动作识别上的优势主要表现在:可对人体进行全天候的监测,可以有效地防止外界因素的干扰和避免目标的隐私泄露问题。微多普勒效应指的是雷达探测物除平动多普勒频率之外因振动、旋转等微运动而产生的额外频率调制的物理现象,由目标运动产生的微多普勒效应可有效地应用于人体动作识别。
目前,随着深度学习的快速发展,各种深度学习方法被广泛应用于基于雷达图像的人类动作识别,其中深度卷积神经网络(Deep Convolutional Neural Network, DCNN)已成为人类动作识别的首选方法。但DCNN大都需要充足的雷达数据进行训练实现人体动作识别,但是在实际工作中,由于雷达数据采集成本过高,数据量往往有限,因此无法有效训练 DCNN。针对雷达数据过少而导致深度学习模型训练受限制的问题,目前主要的方法有三种:采用迁移学习技术对基于微多普勒特征的人体动作识别、采用动作捕捉(Motion Capture, MOCAP)合成微多普勒雷达数据和采用生成对抗网络(Generative Adversarial Network,GAN)进行雷达数据增强。但微多普勒雷达图像与光学图像有根本的不同,基于光学图像的迁移学习技术能否有效地应用于雷达图像上还有待于进一步的研究。采用MOCAP合成微多普勒雷达数据仍然受到人力、时间和数据收集成本的限制,并且合成的数据未考虑到周围复杂环境的影响。利用GAN进行雷达数据增强同样可以解决雷达图像数据过少的问题,但是需要注意生成图像的质量和多样性。文献[8-9]采用深度卷积生成对抗网络(Deep Convolutional GAN,DCGAN)进行雷达图像数据增强,提高动作识别准确率。文献[10-11]提出采用辅助分类器生成对抗网络(Auxiliary Classifier GAN,ACGAN)和DCNN对不同环境下的人体动作进行识别,识别准确率得到提升。 虽然 DCGAN 和 ACGAN 可以解决雷达数据不足的问题,但是其训练过程并不稳定,常常需要训练多次才能达到平衡,并且需要平衡网络结构和调整超参数。本文提出利用基于梯度惩罚的沃瑟斯坦生成对抗网络(Wasserstein Generative Adversarial Network-Gradient Penalty,WGAN-GP)进行微多普勒时频谱图像增强。相较于 DCGAN和ACGAN,WGAN-GP提供了一个更稳定的训练过程,对于模型架构和超参数的选择不敏感,生成的图像质量更高,多样性更强。
本文首先对5种不同的人体动作线性调频连续波雷达回波数据进行预处理获得相应的微多普勒时频谱图像,然后介绍了基于GAN的时频谱图像增强方法,并对比了DCGAN、ACGAN 和WGAN-GP 对微多普勒时频谱图像的数据增强效果。最后实验结果表明,使用WGAN-GP对微多普勒时频谱图像进行数据增强,可有效地解决DCNN 由于数据量有限导致的过拟合问题,提高动作识别准确率。
1 雷达信号采集与预处理
实验数据使用格拉斯哥大学提供的公开雷达数据集,该数据集通过中心频率为5.8 GHz,带宽为400 MHz的线性调频连续波雷达采集不同人体动作的回波数据得到。本文使用的数据包含40名男性志愿者,分别进行喝水、拾取物体、行走、站立、坐下五种人体动作,每个动作重复测量3次,其中行走的动作测量时间为10 s,其余动作为5 s。每个动作共得到120个雷达回波数据,共计120×5=600个数据。对5种人体动作的原始回波数据进行预处理,得到相应的微多普勒时频谱图像,回波数据预处理流程如图1所示。
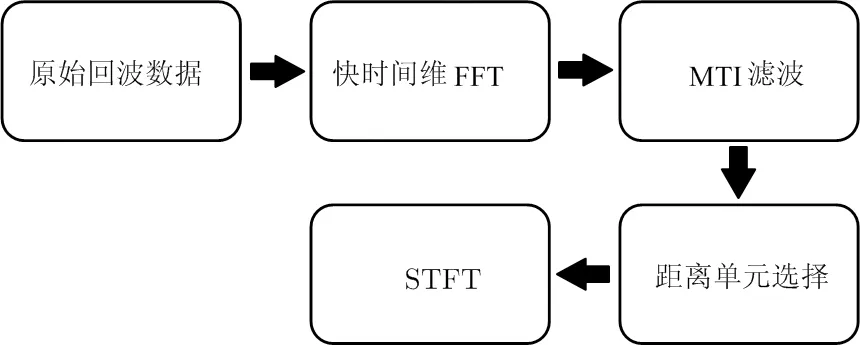
图1 回波数据预处理流程
将每个动作对应的回波样本数据表示为×维矩阵,其中为快时间采样个数,即为每个调频周期对应的数据采样点数,为慢时间采样个数,即为每个动作样本数据对应的 chirps数量。首先对数据矩阵的每一列在快时间维进行快速傅里叶变换(Fast Fourier Transform,FFT)得到距离像信息。然后使用4阶截止频率为0.007 5 Hz的Butterworth高通滤波器作为MTI滤波器对背景杂波进行抑制。根据人体目标与雷达之间的距离选择的距离单元范围为10~30,对每一个距离单元沿慢时间维进行短时傅里叶变换(Short Time Fourier Transform,STFT),然后对每个距离单元的STFT结果进行相干叠加得到微多普勒时频谱图像,其中STFT采用长度为 0.2 s,重叠系数为95%的Hamming窗。
得到的微多普勒时频谱图像大小为464×400像素,为了降低网络训练的计算复杂度,将时频谱图像统一缩放为64×64像素,如图2所示。

图2 人体各动作微多普勒时频谱图像
2 基于GAN的微多普勒时频谱图像增强2.1 DCGAN
GAN最早由Ian Goodfellow在2014年首次提出。GAN是一种有效的数据生成网络,其中包括生成器(Generator, G)和判别器(Discriminator, D),通过生成器和判别器的对抗训练可以生成效果相当逼真的图像数据,解决数据量不足的问题。GAN的结构如图3所示,其优化过程则是一个极大极小博弈过程,最终使判别器和生成器达到纳什均衡。
生成器和判别器的对抗训练优化过程可用式(1)表示:


(1)


图3 GAN结构
DCGAN是将卷积神经网络和GAN的一种结合。相较于原始的GAN,DCGAN主要对生成器和判别器的网络结构进行改进,一方面通过采用卷积神经网络结构替代GAN中的多层感知机从而提高判别器判别图像的能力,另一方面通过采用转置卷积神经网络提升生成器生成图像的效果。
2.2 ACGAN
ACGAN将噪声和相关的类别标签混合作为生成器的输入,并使判别器既判断真假又判断类别。 通过对生成图像类别的判断,可以使得生成器更加准确地找到类别标签对应的噪声分布。其生成器和判别器的网络结构使用深度卷积网络结构。ACGAN的目标函数包括两部分:
=[log(=|)]+
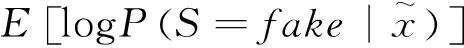
(2)
=[log(=|)]+

(3)
式中,为数据样本来源判别正确的最大似然估计,为数据样本类别判别正确的最大似然估计。判别器最大化+,生成器最大化-。 ACGAN通过添加标签约束来提高生成数据的质量。
2.3 WGAN-GP
如果 GAN 中的生成器生成数据的概率分布与真实数据的概率分布几乎是没有重叠部分或者两分布重叠部分可以被忽略,则JS散度无法衡量生成数据分布和真实数据分布的距离,这时通过优化JS散度训练GAN将导致找不到正确的优化目标,容易产生训练梯度不稳定和模式坍塌的问题。
为解决上述问题,沃瑟斯坦生成对抗(Wasserstein GAN , WGAN)网络提出使用Wasserstein距离作为训练GAN的优化方法。 为了满足Lipschitz连续性,WGAN使用了将权重限制在一定范围内以强制满足Lipschitz连续性的方法,但这会导致生成结果不佳。WGAN-GP是基于梯度惩罚的 WGAN。WGAN-GP改善了Lipschitz连续性约束条件,使用梯度惩罚代替WGAN中的权重裁剪。
WGAN-GP的目标函数为

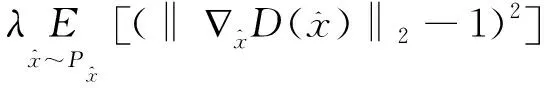
(4)

(5)

2.4 微多普勒时频谱图像数据增强
本文采用的WGAN-GP网络中判别器和生成器使用DCNN结构,具体的网络结构如表1所示。

表1 WGAN-GP结构
本文使用的深度学习框架为TensorFlow,CPU为AMD R9 3900X,同时使用NVIDA GTX 2060和CUDA加速训练。WGAN-GP模型中所有的参数初始化服从均值为0,标准差为0.2的正态分布,判别器和生成器的学习率设置为0.000 2,采用Adam优化算法,带泄露修正线性单元斜率设置为0.2,批大小设置为32,梯度惩罚项系数为10。
将原始数据划分成训练集和测试集,训练集每个动作包含96幅时频谱图像,共计96×5=480幅图像。测试集每个动作包含24幅时频谱图像,共计24×5=120幅图像。使用WGAN-GP对训练集中的每个动作分别进行时频谱图像增强,WGAN-GP的判别器和生成器损失值曲线如图4所示,虽然损失值曲线在一定程度上反映了判别器和生成器的训练进程,但是其并不能衡量生成图像的质量,需通过视觉分析生成图像的质量。为了进一步对比WGAN-GP生成图像的质量,在同等条件下,使用DCGAN和ACGAN对雷达图像数据进行生成,其判别器和生成器结构与表1类似。

(a) 判别器损失值曲线
图5展示了3种不同GAN的生成图像。对比图5和图2可以看出,WGAN-GP生成的图像与真实的微多普勒时频谱图像在宏观上非常相似,并且训练过程较为稳定,未发生模式坍塌。DCGAN和ACGAN生成的图像质量低于WGAN-GP,特别是躯干对应的低频部分很模糊。DCGAN和ACGAN在训练过程中均发生了模式坍塌,生成了大量相同的图像,并且ACGAN生成了很多错误类别的图像,例如行走类别的生成图像里含有许多其他动作的生成图像。
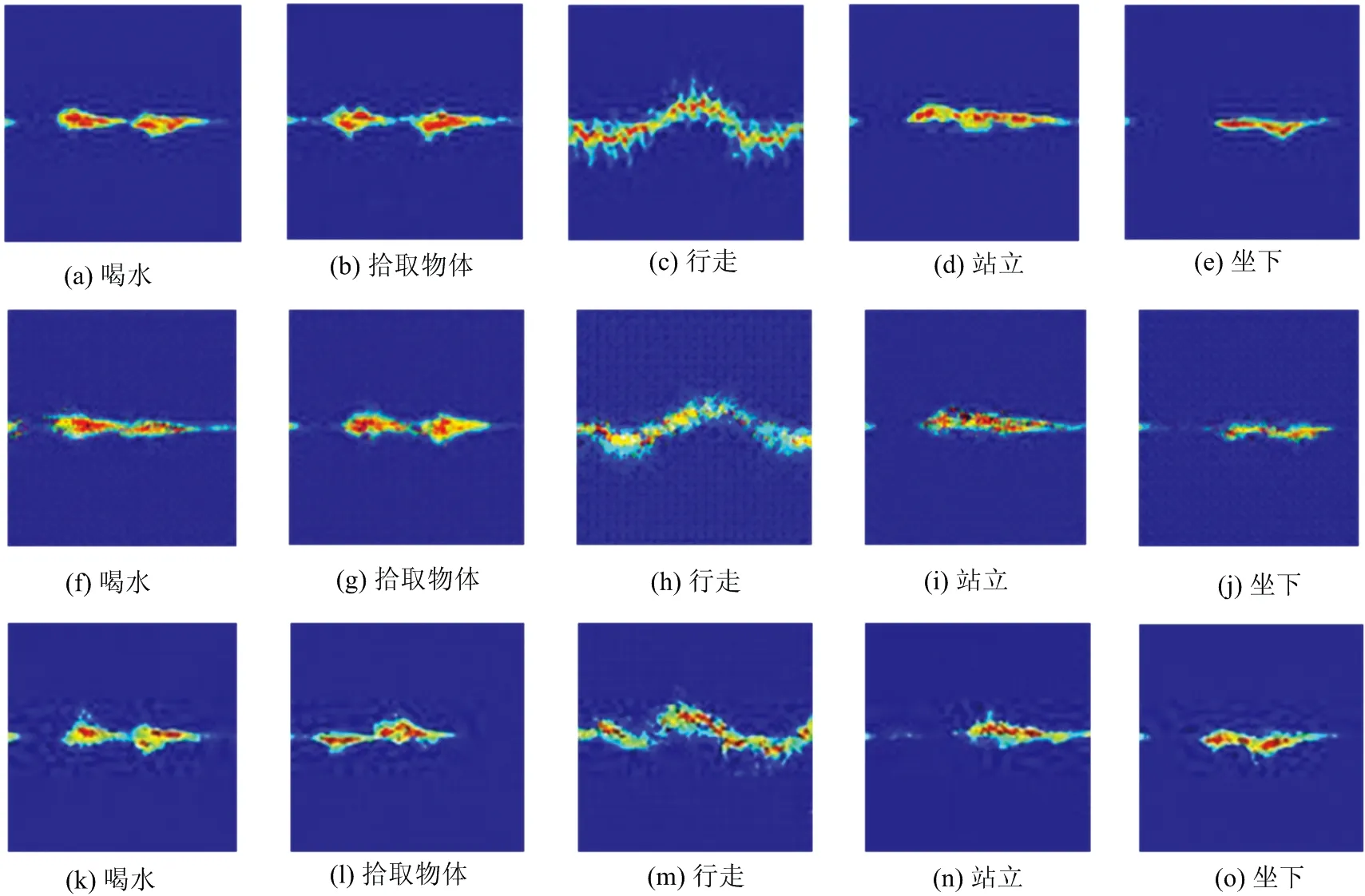
图5 WGAN-GP,DCGAN和ACGAN生成图像((a)~(e) 为WGAN-GP生成图像,(f)~(j)为DCGAN生成图像,(k)~(o)为ACGAN生成图像)
DCGAN和ACGAN需要平衡生成模型和判别模型的训练进程,避免模式坍塌,达到纳什平衡,并且需要经过大量的可视化分析筛选出符合运动特征的生成图像,这将导致工作量的激增。而WGAN-GP拥有更稳定的训练过程,并能生成更高质量的样本图像。
3 基于DCNN的人体动作识别
目前,DCNN在图像分类上显示了巨大潜力。DCNN具有独立学习图像特征并建立分类边界的能力。本文采用DCNN-10来验证WGAN-GP在人体动作识别中的性能。DCNN-10包括7个卷积层和3个全连接层,每一个卷积层后都包含有批标准化和修正线性单元,具体的网络结构如图6所示。训练时采用Adam优化算法,批大小设置为32,学习率设置为0.000 5。

图6 DCNN-10网络结构
首先使用原始训练集(96×5=480)训练DCNN-10,使用测试集测试DCNN-10的准确率。测试集准确率曲线如图7所示,当迭代轮次超过120后,测试集准确率趋于稳定,达到93.3%。

图7 仅使用原始训练集时测试集准确率
为了测试添加的生成图像数量对于DCNN-10准确率的影响,接下来将原始训练集分别与不同数量的WGAN-GP生成图像混合在一起,组成新训练集,使用混合后的新训练集分别重新训练DCNN-10,并用相同的测试集测试DCNN-10的分类准确率,测试结果如图8所示。

图8 各比例生成图像的测试集准确率
向原始训练集中添加4倍数量的生成图像时测试集准确率最高,达到95.8%。但当加入6倍的生成图像时准确率骤降为86.7%。这是因为生成图像与真实的微多普勒雷达图像虽然看起来十分相似,但图像质量仍不如真实的微多普勒雷达图像,如果训练集中的生成图像超过一定数量时会影响DCNN-10对微多普勒雷达图像特征的学习,导致测试集准确率降低。当原始训练集中加入的生成图像在一定数量内时,随着加入的生成图像越多,DCNN-10的分类准确率越高,生成图像可有效地增强DCNN-10的泛化能力,提高识别准确率。
为了对比不同生成对抗网络的生成图像对于DCNN-10准确率的影响,向原始训练集中分别加入4倍数量的DCGAN和ACGAN的生成图像,组成新训练集,分别重新训练DCNN-10,使用相同的测试集测试其准确率。测试集准确率曲线如图9所示,当迭代轮次超过120后,加入DCGAN生成图像后的测试集准确率稳定在91.7%左右,加入ACGAN生成图像后的测试集准确率稳定在90.8%左右,加入WGAN-GP生成图像后的测试集准确率稳定在95.8%左右。测试集中每种动作的准确率如表2所示。

图9 不同生成对抗网络的测试集准确率

表2 DCNN-10测试结果 %
利用DCGAN和ACGAN进行数据增强后,测试集的准确率相比于仅使用原始训练集均有所下降,其中加入ACGAN的生成图像后准确率最低。这是由于加入的DCGAN和ACGAN的生成图像质量和多样性过低所导致的,并且ACGAN的生成图像里混有错误标签影响了分类准确率。而利用WGAN-GP进行数据增强后,训练出的DCNN-10在测试集上的准确率相比于仅使用原始训练集明显提高。
4 结束语
本文基于生成对抗网络提出采用WGAN-GP对微多普勒时频谱图像进行数据增强。实验结果表明,相比于DCGAN和ACGAN,使用WGAN-GP对微多普勒时频谱图像数据增强,可有效地增强DCNN的泛化能力,提升测试集识别准确率。在下一步工作中,将结合自动筛选方法继续完善基于GAN的雷达图像增强技术,提升生成图像的质量,提高人体动作的识别准确率。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
大众科学·中旬(2019年5期)2019-09-10
通信产业报(2018年29期)2018-11-24
通信产业报(2018年40期)2018-01-22
移动通信(2017年3期)2017-03-13
物理教学探讨(2014年5期)2014-09-18
现代电子技术(2009年13期)2009-08-31
