
一种类脑处理器片上网络的验证框架*
2022-05-27 02:05陈小帆杨智杰彭凌辉王世英李石明康子扬
计算机工程与科学 2022年5期
陈小帆,杨智杰,彭凌辉,王世英,周 干,李石明,康子扬,王 耀,石 伟,王 蕾
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
随着摩尔定律不断发展,计算机的计算能力与存储能力呈指数级提升,虽然存储与计算单元分离的冯·诺依曼体系结构推动了计算机计算性能的持续提升,但存储单元与计算单元之间的通信延迟瓶颈[1]依旧存在。在处理器时钟频率和性能不断上升的同时,存储器访问速度却增长缓慢,因此处理器与存储器之间的鸿沟越来越大,即造成“存储墙”瓶颈。此外,计算、存储和I/O的速度越来越不匹配,基于传统架构的平衡体系结构设计面临较大瓶颈[1]。同时,随着工艺特征尺寸的缩小以及片上设计复杂度的增加,芯片单位面积的功耗密度急剧上升,已经接近当前封装、散热以及底层技术所能支持的极限,即传统处理器也面临着“功耗墙”瓶颈。因此,亟需新的计算模式及体系结构来满足与日俱增的计算性能需求。
类脑计算(Neuromorphic Computing)[2]作为人工智能领域的重要分支,其目标是实现类脑智能和类脑计算系统[2]。通过仿真生物神经元和突触的信息处理结构和功能,类脑计算可实现大规模神经网络。类脑计算具有存算一体和高能效的特点,能够很好地解决“存储墙”和“功耗墙”问题。
类脑处理器作为新型的仿生架构,在弥补传统架构不足的基础上,面向生物神经网络来实现智能算法的高效部署。其中,基于超大规模集成电路系统来模拟脉冲神经网络SNN(Spiking Neural Network)功能的类脑处理器受到了学术界和工业界越来越多的关注,例如IBM研发了TrueNorth[3],Intel开发了Loihi[4],苏黎世联邦理工大学设计了DynapSE[5],曼彻斯特大学推出了SpiNNaker[6],清华大学研发了天机(Tianjic)[7]芯片,浙江大学提出了达尔文(Darwin)[8]芯片等类脑处理平台。此类处理器的一大基本特征是“存储与计算合二为一”,即其处理单元既可进行计算也可存储数据[2],从根本上避免了冯·诺依曼体系结构的存储墙问题。此外,类脑处理器凭借其较低的通信损耗,以及基于异步电路和脉冲数据的事件触发特性,在某些应用场景下其功耗甚至仅为通用处理器的千分之一[2],很好地避免了功耗墙问题。为计算机技术发展提供了新的突破点。
然而随着脉冲神经网络的发展,单核类脑处理器因为包含的神经元数量不足,已无法有效地支持规模渐增的应用,因此,正如传统微处理器的发展一样,片上多核互连技术成为实现类脑处理器的主流方案[9]。片上多核互连需要满足高并行度、高吞吐率和低延时的要求,而传统的总线结构(BUS)由于可扩展性差、延时高和信号串扰等问题,无法实现此类架构[1]。而片上网络技术凭借其多进程和多任务的信息交换、易于扩展的结构化设计和在多时钟域下面积和功耗优势,逐步成为类脑处理器中主流的互连结构[2]。
脉冲神经网络中海量的脉冲数据,高并发和高猝发的通信模式,以及较大的片上互连规模,都给面向类脑计算的片上网络NoC(Network on Chip)设计带来了挑战。目前针对这类片上网络的验证工作相对较少,本文主要从功能验证的角度提出了一个支持随机化激励生成的类脑处理器片上网络验证框架,用以辅助面向类脑计算的片上网络设计和性能测试。
本文的主要贡献包括2个方面:
(1)提出了一种针对类脑计算的随机化片上网络激励生成方法。通过设置网络规模、存储空间和通信模式等相关参数,可以获得类脑处理器片上网络行为级仿真和实际硬件测试所需的激励文件。
(2)构建了一种测试类脑处理器片上网络的软硬件环境,通过在片上网络的每一个处理单元上挂载发包模块Injector和收包模块Collector,以及设置相应的总线转接模块,借助结果比对的脚本工具,可以实现2D-mesh结构的片上网络功能验证。
2 背景和相关工作
2.1 片上网络技术
随着多核芯片复杂度的增加,总线结构的通信方式也逐步在面积、速度、功耗和数据吞吐量等诸多方面面临瓶颈[1]。
目前主流的互连结构包括总线结构(Bus)、交叉开关结构(Crossbar)和片上网络结构NoC。总线结构适用于节点数量较少的系统,当通信节点较多时易产生拥塞,成为系统瓶颈。Crossbar结构可以实现所有节点之间的互连,吞吐率极高,但设计难度较大,复杂难度均为O(N2)[1],此处N表示N输入和N输出的Crossbar网络。因此,Crossbar结构的扩展性较差,而且随着互连规模的扩大,系统的仲裁难度也大幅上升。相比带宽需求偏低的核间通信,数据交换更频繁的核内神经元互连则多采用Crossbar结构。为了实现更好的可扩展性,目前研究人员普遍采用片上网络作为神经形态核之间的互连结构。
一种典型的3×3 2D-mesh结构的NoC如图1所示[10]。其中,NoC由处理单元PE(Processing Element)、路由器R(Router)和链路(Link)3个主要部件构成。PE也称为计算结点,可以完成广义的计算任务。NoC工作时首先通过链路将源PE中的数据传输到路由器模块中,随后通过路由算法在网络中路由并辅以仲裁算法,使得数据包最终到达目的节点并由目的PE接收。

Figure 1 NoC architecture of 3×3 2D-mesh 图1 3×3 2D-mesh NoC架构
2.2 面向类脑计算的片上网络
类脑计算模型以脉冲神经网络SNN为代表。类脑计算模型运行时在每一个时间步内都会产生大量的脉冲数据,这些脉冲数据在网络模型中有着高并发和高猝发的特性[11],实现节点间高效的数据传输是一个严峻的问题。现在常用的数据传输方式有单播、组播和广播等[11]。对于大规模脉冲神经网络而言,类脑处理器需要实现大量处理结点之间的互连互通,其规模远超当前传统处理器的互连规模。例如,Intel的Loihi[4]芯片包含128个神经核,最多支持4 096核互连;IBM的TrueNorth[3]芯片支持4 096个神经核。在内部的互连规模方面,多核类脑处理器已超过传统多核通用处理器,所以针对类脑应用的NoC不仅需要适应高并发、高猝发的类脑通信模式,而且还需继续提升互连规模,以实现良好的可扩展性。
类脑处理器通常是由大量NoC互连的神经形态核(即计算单元)组成的大规模并行系统,其中NoC用以控制和优化处理单元之间的通信。类脑处理器的通信可分为核内本地通信和核间全局通信。
主流类脑处理器的NoC结构各异,如TrueNorth[3]和DynapSE[5]采用的是2D-mesh结构,Loihi[11]采用的是C-mesh结构,SpiNNaker[6]采用的是torus结构,CxQuad[12]平台则是基于NoC-tree结构的。目前,类脑处理平台大多采用了mesh结构的NoC设计来实现多核互连,而且每一个神经形态核都可同时支持多个神经元的计算。
2.3 片上网络的功能验证
在确定一个NoC的通信模式和基础架构后,需要结合应用建立系统参数和变量来对NoC系统进行功能和性能评估。但是,目前和NoC验证相关的系统较少。针对网络设计初期已有一些功耗评估和分析的工作[13 -16],此外,也有基于模拟器的片上网络的系统开发[17 -19]。Madsen等[20]提出了基于多处理器实时操作系统的NoC系统行为分析;Pande等[21]提出了基于不同体系结构的延迟、吞吐率和功耗的评估模型[21];Genko等[22]的研究是基于现场可编程门阵列FPGA(Field Programmable Gate Array)实现的NoC仿真环境。
然而,上述工作均是基于传统微处理器来开展的。对于上述类脑计算中的通信模式和NoC规模需求较大的类脑应用,相关功能验证的研究较少。文献[23]基于FPGA构建了硬件环境,基于Micro Blaze软核构建了软件环境,通过分别设置软硬环境的配置文件来实现NoC的快速硬件仿真。但是,此工作没有对不同激励的测试进行探讨,而且软硬交互部分较为复杂,无法将行为级仿真和硬件级测试的结果进行分离分析。
对此,本文提出支持随机化测试的验证框架,主要针对2D-mesh NoC的类脑应用,实现较为全面的测试激励覆盖,支持不同程度的负载压力测试,为NoC设计提供行为级和硬件级的初步评估。
3 类脑处理器NoC验证框架
本节主要从软件测试环境和硬件测试环境2个方面来介绍本文的面向类脑处理器的NoC功能验证框架。
3.1 验证框架设计
如图2所示,本文将NoC功能验证分为2个步骤:软件测试和硬件测试。其中,软件测试是基于仿真环境对待测设计DUT(Design Under Test)的测试:通过生成并输入行为级测试激励,收集和分析DUT产生的相应计算结果,结合预期结果来进行功能验证;若DUT行为级功能符合预期,就继续进行相应的硬件测试。在硬件测试中,首先将NoC设计部署到FPGA验证平台上,进而基于测试母板和外设高速互连PCIe(Peripheral Component Interconnect express)子卡来对FPGA验证平台进行数据包读写;随后将母板获取到的数据包通过串口工具输出到日志文件;最后,结合预期结果,基于FPGA进行上板功能验证。若从该日志文件中解析出的数据同行为级仿真中获得的数据一致,那么说明DUT上板后的功能同样符合预期。至此,DUT的功能验证就完成了。否则需要在DUT中定位问题并进行设计迭代。
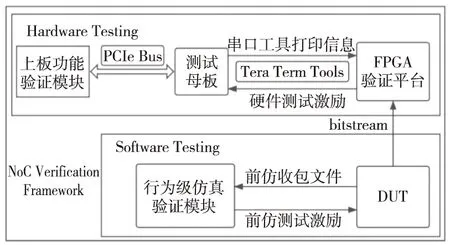
Figure 2 Framework of proposed NoC verification 图2 本文提出的NoC验证框架
3.2 软件测试环境
整个NoC验证平台的软件环境主要用于生成测试激励(Incentive Files)和预期结果(Golden Results),并且在DUT即规模为N×N的NoC设计[16]中内嵌发包模块(Injector)和收包模块(Collector)。Injector和Collector主要用于模拟PE单元数据的发送与接收,数据均存储在收发包模块所挂载的块随机存储器BRAM(Block RAM)中,如图3的PE所示。
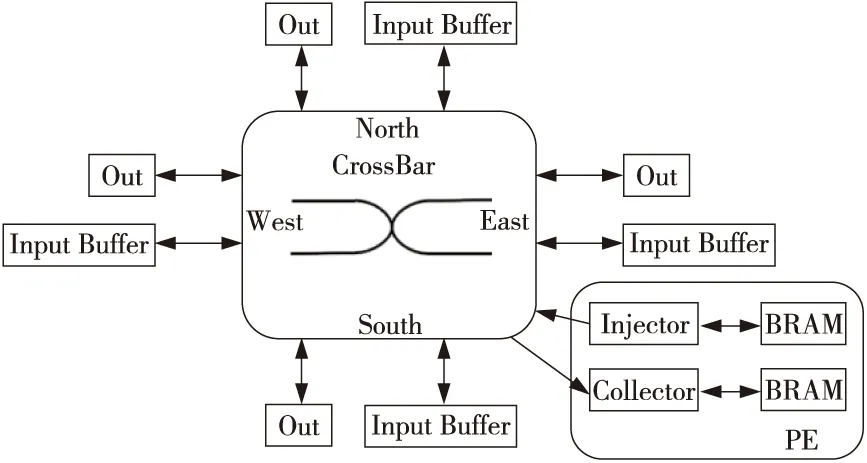
Figure 3 Structure of single NoC node图3 NoC单节点结构
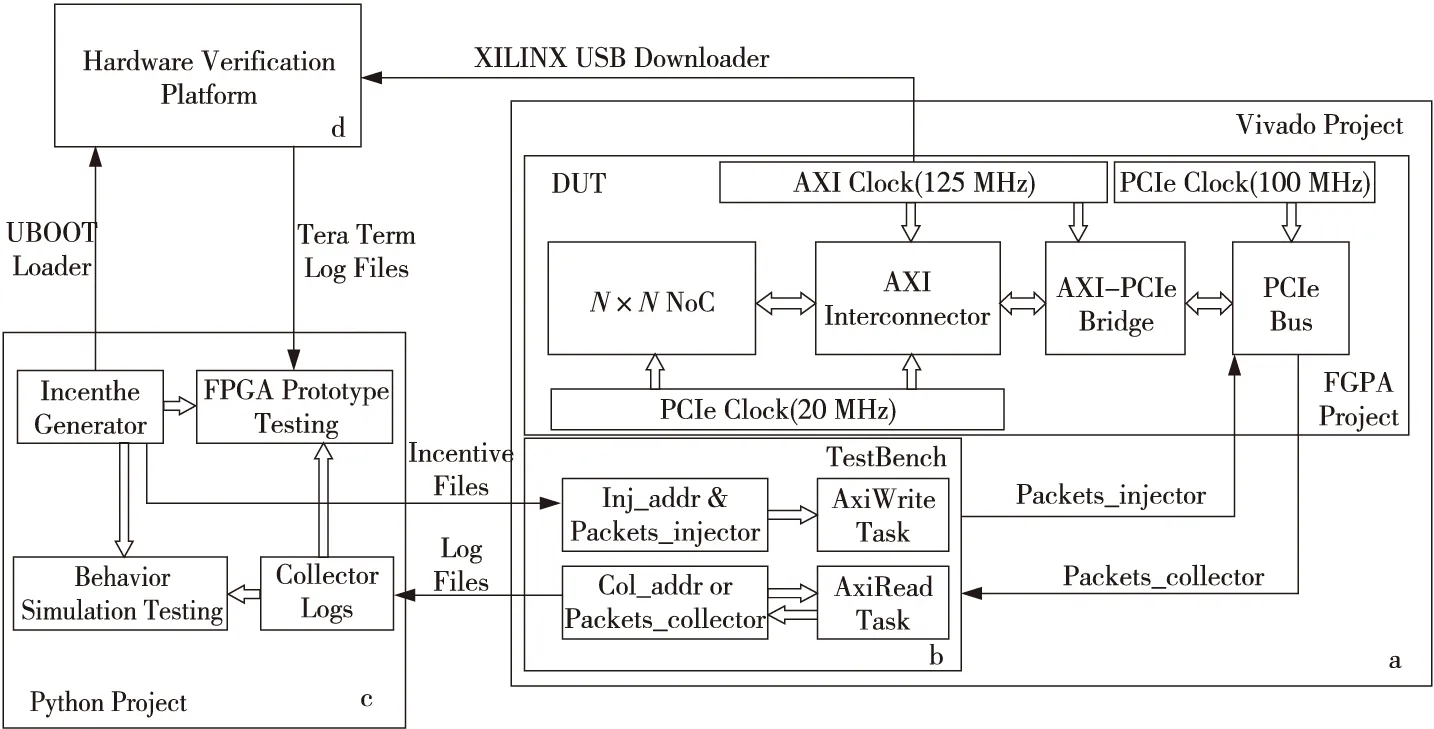
Figure 4 Software testing environment of NoC verification framework图4 NoC验证框架软件测试环境
此外,为了实现测试母板与FPGA验证平台之间的通信,本文在N×N的NoC设计外部加入了AXI Interconnector模块和AXI-PCIe Bridge模块,如图4a部分所示。
图4b部分是行为级仿真环境下激励输入部分,通过调用AxiWrite和AxiRead 2个任务,可从激励文件中读取所需的地址和数据包信息。前者负责将数据包保存在各个PE结点的Injector模块中,后者在整个NoC完成运算后从各PE结点的Collector模块中读取数据。图4c部分是基于Python来构建的激励生成与仿真/上板测试结果校验的测试环境:基于Golden Results、行为级仿真结果和FPGA硬件平台测试结果,本文可以结合2.3节所述的测试方法来验证该NoC设计是否符合预期要求。图4d部分则是通过UBOOT引导程序和串口调试工具,获取FPGA验证平台上的测试数据,以供图4c部分进行功能校验。
3.3 硬件测试环境
硬件测试环境是由FPGA验证系统、测试母板、调试上位机、XILINX USB下载器、异步收发传输器UART(Universal Asynchronous Receiver/Transmitter)数据线和PCIe子卡构成,如图5所示。一方面,调试上位机通过UART数据线对FPGA平台的全局时钟进行配置,并且将图4a部分所示的FPGA Project下载到FPGA验证平台上。同时,通过XILINX USB可以获取FPGA验证平台的某些关键信号,用以DUT调试。另一方面,通过Tera Term串口调试工具,调试上位机将UBOOT下的读写指令输入到测试母板上,测试母板进而通过PCIe总线将报文发送到FPGA验证系统,从中获取NoC PE单元中Collector模块所存储的数据,并通过串口工具将其保存到上位机中。

Figure 5 Hardware testing environment图5 硬件测试环境
3.4 激励生成
NoC单节点的主要结构[24]如图3所示。根据2D-mesh结构NoC节点可分为内部节点和边缘节点。该NoC的通信负载模式主要分为以下4种(源节点-目的节点):边缘-内部(e-i)、内部-边缘(i-e)、边缘-边缘(e-e)和内部-内部(i-i)。激励文件中对应的数据格式如图6所示,其中图6a和图6c表示行为级仿真中Testbench内AxiWrite任务的2个输入变量,该任务可将相应的数据存入到对应源节点的Injector BRAM中;图6b表示AxiRead任务中的输入参数,对应目的节点中Collector BRAM所需读出的数据地址,该任务可将Collector BRAM对应保存的数据读出到本地存储器。此外,Src和Des分别表示源和目的节点,Inj和Col分别表示Injector模块和Collector模块。根据这些数据格式的设置,本文可以针对这4种通信模式生成随机化激励。
此外,基于SNN硬件映射工具SNEAP(Spiking NEural network mAPping toolchain)[25],本文实现了SNN模型各神经元到NoC节点的映射,可获得SNN模型的NoC通信数据,进而获得基于真实应用场景下的NoC软件仿真和硬件测试所需的激励文件。
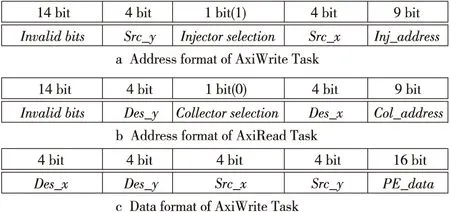
Figure 6 Format of incentive data图6 激励数据格式
如图7所示,生成测试激励前,需要输入相应的配置参数:片上网络规模(NoC_size)、脉冲神经网络的核间通信数据(SNN_trace)或者用于随机生成激励的通信模式(NoC_pattern,上述4种)、需生成的数据包数量(Packet_num)和单个Injector或Collector BRAM的深度(Mem_config)。激励生成方法会按照配置文件信息随机生成收发节点信息,或从基于Brian2模拟器[26]和SNEAP映射工具中获得的SNN_trace中选取数据包收发的节点信息,与此同时也会随机生成数据包中的NoCPE结点数据(PE_data),分别如图7中的Connection_random_list和Data_random_list所示。本文在随机生成PE_data的过程中保证了其各异性,使得一个数据包在PE_data字段被唯一标识,进而有利于随后的数据比对。最后按照数据包收发关系来生成Address参数。在生成数据包的过程中满足片上的存储边界条件,即单个Injector/Collector SRAM存储数据包不超过硬件所支持的最大数量,否则需重新生成测试数据。其中,Src和Des分别表示当前生成的连接中Injector和Collector的编号。

Figure 7 Generation method of incentive data 图7 激励数据的生成方法
至此,便生成了NoC行为级激励:AxiWrite/AxiRead Files。结合UBOOT指令格式,可进一步生成NoC硬件级测试所需的激励:Uboot Write/Read Files。

Figure 8 Verification process of incentive data 图8 激励数据验证流程
3.5 结果验证方法
对于NoC核间通信而言,由于拥塞和路由路径的长短各异,目的节点收包顺序和源节点发包顺序有可能不一致。但是,由于SNN所处理的内容是脉冲数据,而脉冲之间是同质的,即每个数据包到达目的神经元后都会引起同样的膜电压升高。脉冲神经元在单个时间步长内通过积累外界脉冲来触发新脉冲的发射,因此在一个时间步(1 ms)[3]内无损地完成相应数据包的传输就不会导致SNN模型产生计算误差。在获取该行为级仿真结果后需要对各Collector模块预期读出的数据进行顺/逆序的重排序操作,再同如图7所示的预期收包结果(Collector_golden_files)进行比对。此过程只对NoC进行了部分行为建模,即确保数据包按照如图6所示的数据格式进行收发。鉴于前文所述的SNN神经元高容错以及脉冲编码的计算特性[2],一个时间步内保证数据包均被传输到目的节点即可。
具体的验证流程如图8所示:行为级仿真结束后,将NoC行为级仿真中每一个Collector模块的数据包打印输出到各自的上日志(log)文件中,将这些日志文件统一记作仿真结果(Collector sim logs)。随后,将仿真结果中的数据包同样按照其PE_data段进行降序/升序重排列后,同上述的预期结果进行一一比对(如图8中的diff操作所示)。在逐Collector单元对所接收的数据包进行文本比对后,若各节点收包结果均符合预期,即可证明NoC行为级功能正确;在行为级功能正确的基础上,继续进行硬件测试,将图7所生成的 Uboot write files输入到部署了NoC的FPGA上,通过 Uboot read files获得UBOOT环境下的硬件测试结果(Tera_term log),将其与仿真环境下通过AxiWrite files和AxiRead files获得的仿真结果(Sim log)进行数据进制和格式转换(图8中convert操作)后获得比对结果(Uboot_result)。若硬件测试结果和行为级仿真结果保持一致,即可证明NoC上板后的功能符合预期要求。在如图8所示的NoC单次测试结果的验证中,由于Collector模块中的文件读写逻辑无法被部署到板上,所以我们在上板后对所有节点进行了遍历,读出数据包(Tera_term log)后进行比对,只需进行一次diff处理。
4 实验及结果分析
本文实验的测试对象是基于2D-mesh结构的16×16 NoC设计,其内部节点的架构如图3所示。该NoC采用了XY路由算法和轮询仲裁算法来实现数据包的传输。本节将详细介绍激励数据的生成,以及NoC相应的功能验证。
4.1 数据准备
本文采用一种主流的SNN模型——单液体层的液体状态机LSM(Liquid State Machine)模型[27]。LSM模型由于其较强的时空信息处理能力、简单的架构和较低的训练复杂度而受到了广泛的关注。LSM主要分为3部分[27]:输入层(Input Layer)、水库层(Reservoir)和读出层(Readout Layer)。水库层中包含兴奋型和抑制型2类神经元,这2类神经元之间存在一定的连接概率,脉冲信号经由该层的映射即可得到相应的输出向量,通过输出向量对读出层后的分类器模型进行训练,即完成对输入脉冲序列的特征学习。
实验所采取的LSM模型配置如下:液体层神经元总数为1 000,其中,激活型神经元个数为800,抑制型神经元个数为200,神经元连接概率分别为Pee=0.40,Pei=0.40,Pie=0.50(为激活-激活、激活-抑制和抑制-激活连接类型)。本文从4种SNN脉冲数据集中分别选取一个样本,送入LSM模型中运行得到每一个样本在液体层中所激活的脉冲数据,这些脉冲数据由Brian2模拟器[26]监控并保存为日志文件,该文件中包含了每一个脉冲被激发的时刻、源神经元编号和目的神经元编号。虽然多层液体状态机可以提取更加丰富的特征信息,但在本质上属于一个较大的单层液体状态机。此外,由于LSM是一种高度可配置的脉冲神经网络,可扩展性较好,所以此处只采取了一种LSM网络常用配置,把重点放在了不同通信模式带来的测试挑战上。
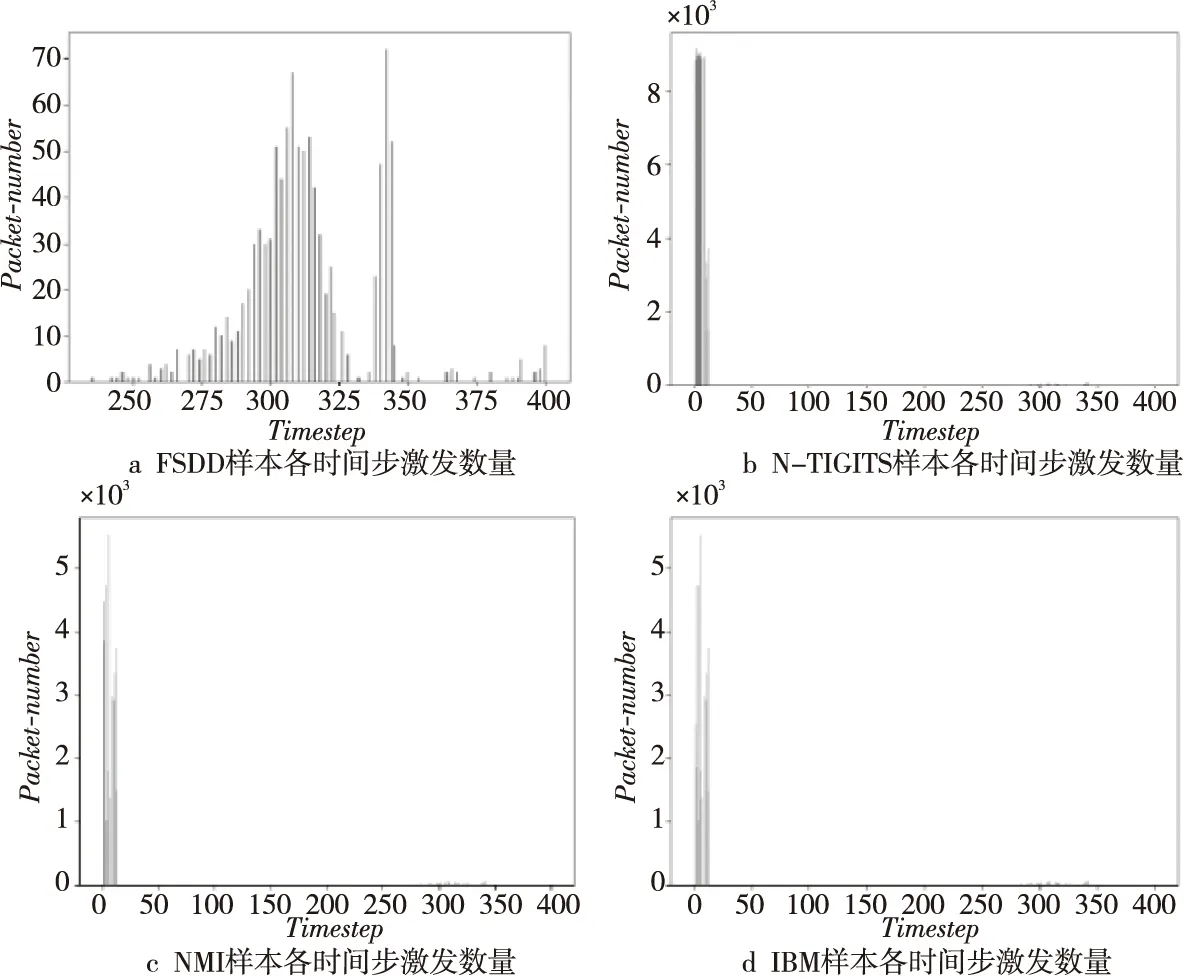
Figure 9 Packet number distribution within 400 timesteps图9 400个时间步内数据包数量分布情况
通过采用SNEAP映射算法,首先将1 000个神经元映射到规模为16×16 NoC即256个PE结点上;随后结合映射关系,将上述日志文件中属于核间通信的部分提取出来。单个数据样本的时间长度为0.8 s,而NoC需要满足的是一个时间步长度即1 ms内的核间数据通信需求,但为了增大通信负载,本文从每一个样本中截取了0.4 s即400个时间步的数据来进行一次NoC的测试。由于实验中所采取的FPGA资源限制,16×16是该FPGA平台支持的最大NoC规模。
4.2 测试激励的生成
首先,本文基于随机分布分别产生了4类不同负载类型的激励数据,随后基于LSM模型来对语音数字数据集FSDD(Free Spoken Digit Dataset)[28]、动态手势数据集IBM Gesture Dataset(IBM)[29]、手写数字数据集NMI(N-MNIST Dataset)[30]和语音数字数据集NTI(N-TIGITS Dataset)[31]进行分类,获得了Brian2模拟LSM实际运行单样本时的模型通信数据(SNN Traces)。为了保证数据包数量的合理性,本文先对上述4类数据集中单样本所分别生成的脉冲数据包数量进行了分析,结果如图9所示。其中,Timestep表示LSM模拟的时间步长,代表运行时间;Packet_number则是该LSM模型被映射到NoC上后,在每一个时间步对应产生的NoC节点间脉冲数据包数量。数据集FSDD在400个时间步长内产生的核间通信数据较为分散,其他数据集数据对应LSM激发的核间数据包较为集中,且集中在较早的时间步段内。经统计发现,FSDD,NMI、NTI和IBM数据集在单个时间步长内数据包最多分别为72,4 824,9 134和5 509个,这是由于不同的数据来源和类型会具有不同时空状态特征。
本文使得如图6c所示的PE_data各异,这样便能保证激励文件中Data参数的各异性。在满足不超过Injector和Collector BRAM的深度限制,即保证单个Injector和Collector的数据包数量不超过256的前提下,对于四种随机激励,根据如图9所示结果,本文设置数据包总数量为5 000;相应地,基于上述数据集来生成的激励,对于每一个样本,分别选取数据包数量为5 000,8 000和10 000来表示不同样本带来的通信差异性,共计生成16组测试激励如表1所示。
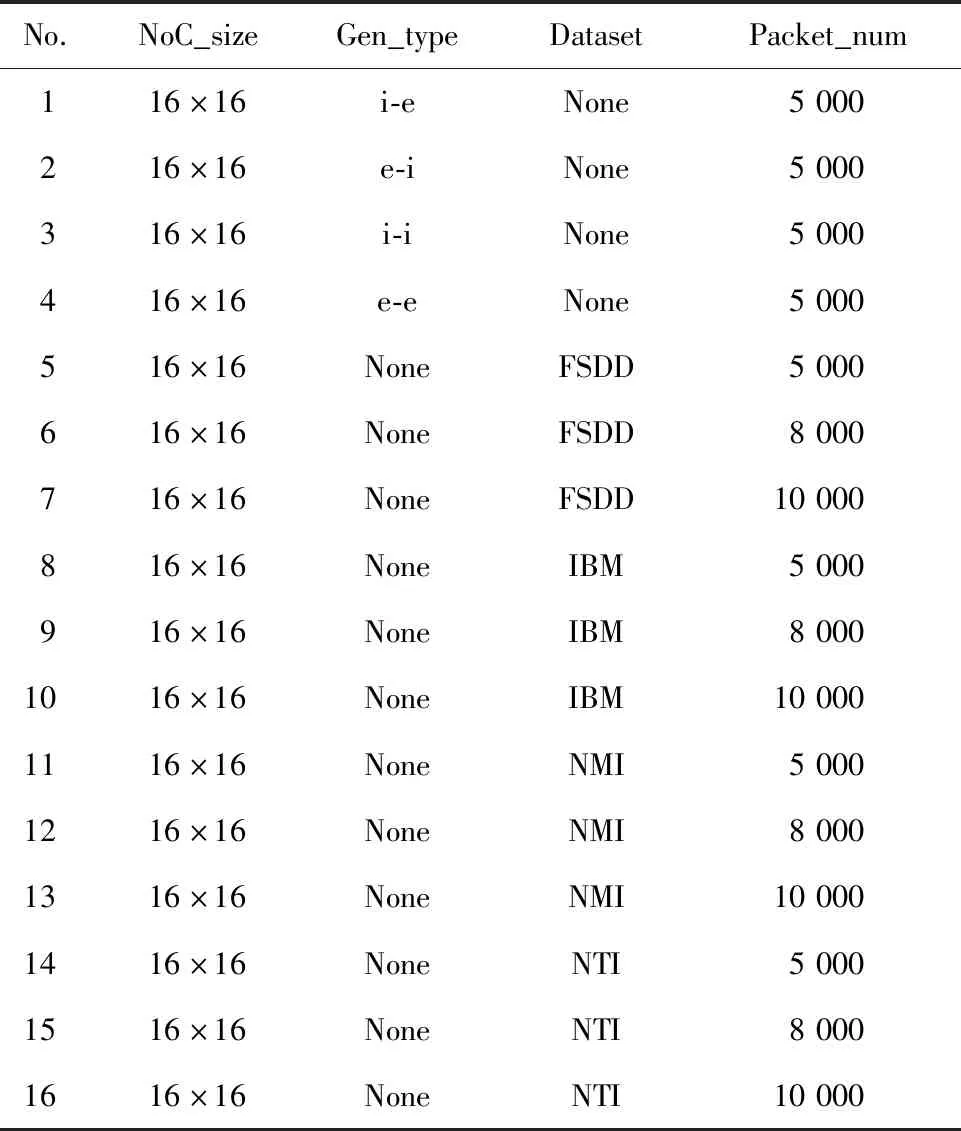
Table 1 Incentives generation setting表1 激励生成配置
4.3 实验结果
本文一共设置了4组随机生成的激励和12组基于SNN Traces生成的激励。通过脚本比对行为级仿真结果和预期的Golden Results,可知每个PE的Collector模块在收包数量和报文内容上均保持一致。其中,对非空的Collector日志文件进行内容比对,内容不一致的数据包总数量结果如表2中“Num of Errors”一栏所示。表2中的Avg_delay是指在一次行为级仿真过程中,自NoC开始进行工作直到最后一个数据包传输完毕所需耗费的时间。本文通过在Collector模块进行数据包写入操作时拼接了时间信息;Num of Errors指的是行为级仿真中Collector保存结果同预期结果之间存在差异的节点个数。结果表明,所有测试项中平均延时都在1 ms内,即满足了NoC实时性要求;而且对于每个Collector而言,Num of Errors均为零,即实际仿真结果与预期结果都保持了一致。

Table 2 Results of behavioral simulation表2 行为级功能验证结果
硬件上板的功能验证操作如下:首先从Tera Term串口终端日志信息解析各Collector模块日志信息;随后基于Python内建库difflib,将日志信息与仿真环境下所得的日志文件即图8中的Sim log进行比对,生成.html文件来保存比对结果,统计出2部分信息中是否有元素的增添(Added)、更替(Changed)或删减(Deleted)。结果如表3所示,可知16组数据的比对结果均达到了预期,即Added、Changed、Deleted数量全为0。说明NoC设计在上板后实际收发结果与软件模拟的结果完全一致,初步验证NoC功能符合预期。
5 结束语
本文提出了一种支持随机化测试的类脑处理器片上网络功能验证框架。通过在待测NoC的PE单元挂载Injector和Collector测试模块来完成基本的数据读写操作。结合预期结果来对规模为N×N的NoC的仿真结果数据进行离线分析,进而检测NoC在硬件设计上存在的问题。基于FPGA验证平台,本文通过串口工具实时读取Collector BRAM的值并利用比对工具验证了NoC实际硬件行为。
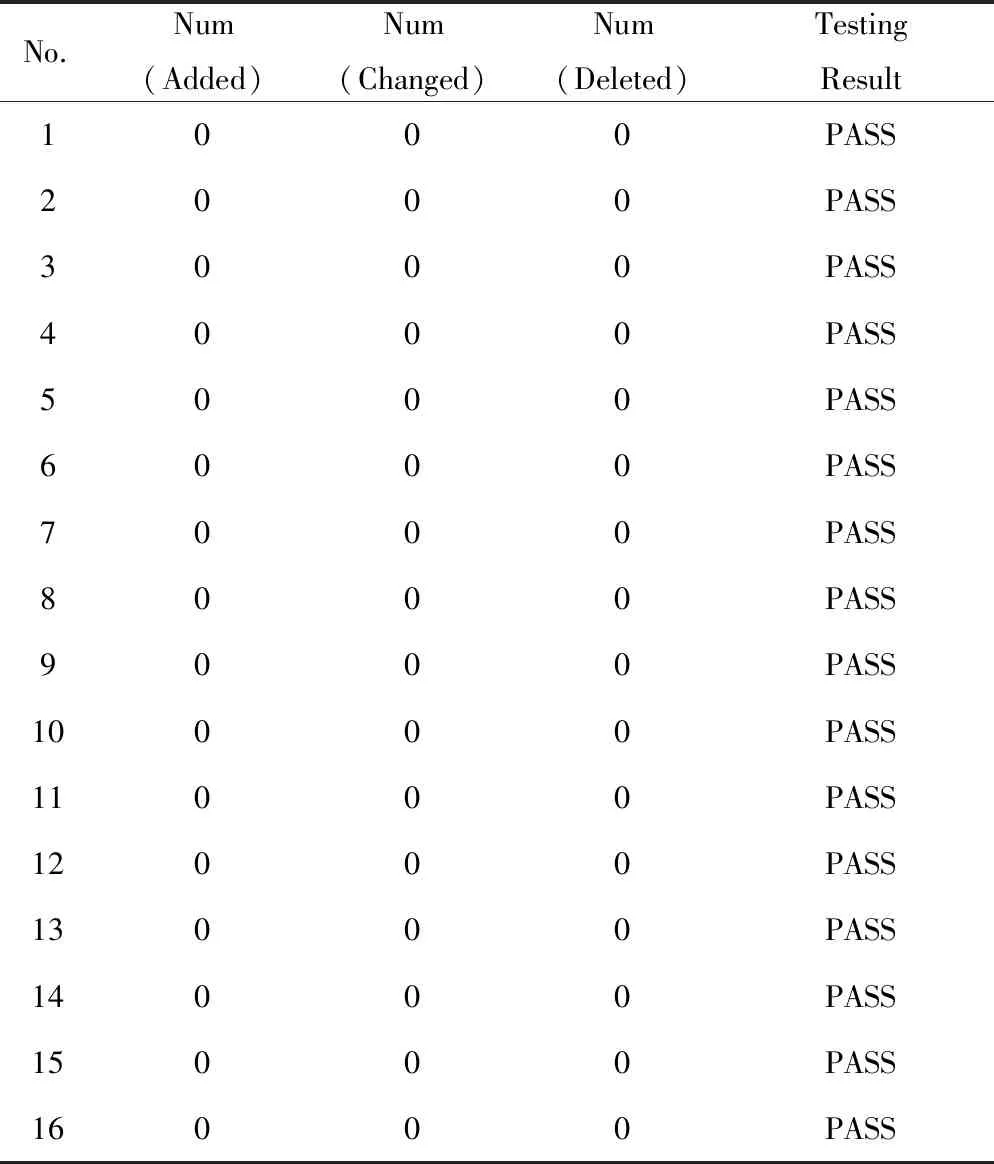
Table 3 Results of FPGA testing表3 FPGA上板功能验证结果
16组对于16×16 NoC的测试实验结果表明该验证框架可以适应多种不同通信模式和负载应用。现阶段针对类脑处理器的NoC测试平台较少,本文在这一方向上进行了有益的尝试。为了扩展该测试平台功能,在下一阶段将继续探索其他结构(如环网结构)的设计验证;通过加入针对不同测试需求的内嵌模块,并提供对NoC实时通信性能和均衡性的分析,使得测试多样化和细粒度化。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
有色设备(2021年4期)2021-03-16
民用飞机设计与研究(2020年4期)2021-01-21
科学24小时(2021年1期)2020-12-24
科学导报(2020年67期)2020-11-02
物联网技术(2018年8期)2018-12-06
中成药(2017年12期)2018-01-19
中小学信息技术教育(2017年6期)2017-06-23
弹箭与制导学报(2015年1期)2015-03-11
汽车与新动力(2013年3期)2013-03-11
