
基于BERT与BiGRU-CRF的交通事故文本信息提取模型
2022-06-02 06:35樊海玮秦佳杰张丽苗鲁芯丝雨
计算机与现代化 2022年5期
樊海玮,秦佳杰,孙 欢,张丽苗,鲁芯丝雨
(长安大学信息工程学院,陕西 西安 710064)
0 引 言
统计数据显示,我国每年约7万人丧生于交通事故,受伤人数更是高达约25万人[1-2]。充分利用交通事故文本信息,提取其中的关键异构数据,分析交通事故成因和事故发生规律,为数字交通建设和交通安全管理提供科学参考依据,是当前的重要课题。
目前,对交通事故文本信息中的异构数据处理的方法,大多采用人工借助词典的手段设计规则,提取语言特征等方式进行数据的结构化处理。该过程在规则性强的实体信息上能够取得良好的效果,但仍存在耗时严重,且对词典中未出现的词识别率不高及移植性较差等问题。也有研究者使用基于静态词向量表示模型的深度学习命名实体识别方法提取文本中关键信息,该方法虽然提升了信息提取的效率,对词典中未出现过的词也有较好的识别表现,但用于交通事故文本信息抽取仍达不到事故关键信息提取的精确率要求。
针对上述问题,本文采用预训练语言模型BERT并融合双向GRU与CRF的命名实体识别方法对交通事故文本的关键信息进行抽取,通过实验对比分析,验证本文模型在处理交通事故文本数据方面的有效性。
1 相关研究
文本挖掘,即从文本中提取关键信息,并基于这些信息进行分析,得到有意义的结果。此概念于1995年由Feldman等人[3]最早提出,随后,在各领域展开研究[4]。其中,在国外的交通领域研究中,Nayak等人[5]通过抓取一定量的城市交通事故报告文本,设计规则并提取了事故文本中的关键信息,并对城市交通事故进行了主要原因分析。Gao等人[6]提出了一种verb-based的方法挖掘网页版的密苏里州公路的交通事故报告文本,并提取了文本报告中的汽车交通事故的原因和结果。You等人[7]对交通广播网中的非结构化报告文本采用文本挖掘技术进行分析,通过设计规则抽取了道路名称、地点、时间等因素,并分析了交通事故对驾驶员的影响因素。
Gopalakrisknan等人[8]基于机器学习神经网络方法挖掘交通报告文本,构建预测模型辅助交通决策,建立了一种自动挖掘文本报告系统,表明文本挖掘技术在交通运输中的重要地位。随着深度学习的出现,出现了一些基于长短时记忆网络LSTM的文本挖掘模型[9],虽考虑了文本中的前文信息特征,对信息识别精度有一定的提高,但单向的LSTM没能有效地考虑上下文信息,在识别精度上仍有所欠缺。Graves等人[10]提出双向的长短时记忆网络模型BiLSTM,改进了单向模型的缺点,证明了该模型的有效性。赵瑞晨[11]构建了基于Word2Vec+BiLSTM+CRF的铁路事故文本命名实体识别模型,实现了铁路事故文本数据的结构化,并基于此模型分析挖掘美国铁路设备事故,实现了铁路事故结构化数据的原因分析、统计分析以及可视化等工作。然而,BiLSTM模型由于参数比较多,在面对大量数据训练时,会消耗很长计算时间。
通过上述研究发现,在交通事故文本数据处理方面,提取文本中的关键信息仍依赖规则提取特征的方式。对于其中混杂的关键异构信息,需要通过对规则的反复修订和完善,才能获得良好的提取结果,对于不同风格的交通事故文本,其识别能力较差,而且可移植性不高,并且该过程平均占用了大量的研究时间。
随着深度学习方法的崛起,提供了交通事故文本结构化处理的新角度,无需人工提取文本的语言语法等特征,很大程度上节省了人工成本并提高了效率。但在文本处理过程中仍存在文本一词多义问题考虑不充分、上下文依赖不强等问题,影响了信息提取的精确度。本文方法是以前人研究成果为基础,采用BERT模型充分利用交通事故文本上下文之间的字词关系,有效提取文本特征;采用结构简单、计算小、所需内存小的BiGRU模型并结合CRF模型进行特定的实体识别,得到最优的标记序列。
2 BERT-BiGRU-CRF融合模型
基于BERT与BiGRU-CRF融合的交通事故文本信息提取模型的架构主要包含文本标注BIO[12]输入层、字向量映射层BERT、文本特征提取层BiGRU、条件概率输出优化层CRF及模型输出层。模型整体架构图如图1所示。

图1 BERT-BiGRU-CRF模型架构图
2.1 文本标注与字向量映射层
依据抽样验证的交通事故文本数据中的7个实体类型,使用BIO标注法对文本数据的各字符进行标注,将该标注语料作为BERT词向量转换层的输入原始语料。利用预训练模型BERT将标注的原始语料映射为向量形式,以便后续的BiGRU层进行上下文特征的学习。
基于BERT的交通事故文本词向量生成具体如下:
针对交通事故文本标注的文字序列,在自然语言处理任务中,文本序列无法直接被识别与计算。因此,首先需要对文本序列进行向量表达,才能作为深度神经网络的输入特征。
预训练语言模型[13]是一种深层网络架构,该网络的所有权重参数都是由大量原始文本语料训练后获得。由于该模型学习到了很多语言经验知识,因此可以很好地对文本进行向量化表示。传统的Word2Vec模型和Glove模型为早期代表的静态词向量表示模型,这些模型所得到的字向量没有很好地考虑上下文信息,没法解决一词多义等问题,导致对后续特征提取任务有一定影响。基于LSTM网络的预训练语言模型ELMO被提出后[13],由于LSTM网络能够考虑上下文的特性,该方法具有比静态词向量表示模型更好的效果。但该模型使用的编码器在上下文依赖的问题处理上,使用效果不如基于Attention机制的Transform编码器[14]。随着基于Transfrom的BERT模型在2018年被Google提出,该模型在处理文本任务中的表现取得了最好的效果。因此本文使用基于BERT的预训练模型,该模型通过33亿的中文语料训练而成,包含更多的语言经验知识,以及大多数的词汇与场景,很适合交通事故文本混杂异构信息提取的应用。
BERT模型的网络结构如图2所示。该模型将文本中的每个字符输入到双向的Transformer编码器中,根据其内部的自注意力机制(self-attention)获得融合上下文信息的字符向量。此过程能够有效避免交通事故文本特征提取中的一词多义问题。其将15%词随机掩盖,然后预测这些词的上下文信息。该过程能够学习到原始文本中的词之间的相关性。最后只计算被掩盖词的Loss值。

图2 BERT网络结构
Transformer编码器使用自注意力机制来计算一个序列中每个单词与该序列中所有单词的相互关系,然后利用这些相互关系来调整每个单词的权重。这样得到的每个单词的向量不仅包含单词本身的含义,还隐含了其它词与该词的关系,这种方式可以学习到序列内部的长距离依赖关系。计算公式为:
(1)
其中,Q表示查询向量,K表示键向量,V表示值向量,dk表示输入向量维度。由于自注意力机制只能捕捉一个维度的信息,所以Transformer编码器采用了多头注意力机制。它先将Q、K、V进行h次不同的线性映射;然后分别对映射后的Q、K、V计算attention;最后将得到的h个attention矩阵拼接起来,这样就可以获得多个维度的信息。具体公式为:
(2)
MultiHead(Q,K,V)=Concat(head1,…,headh)
(3)
BERT模型可以根据语料文本的输入,生成融合当前字、当前字所在句子以及所在位置的3个特征向量组合,如图3所示。其中,字向量第一个字用[CLS]进行标识,代表了当前字的特征向量。句向量表示前词所在句子位置的特征。位置向量表示当前词属于的句子在文本中的位置特征。

图3 BERT输入向量表示
2.2 BiGRU网络层
通过构建BiGRU网络模型对经过BERT模型处理后的交通事故文本词向量进行特征提取,随机初始化该网络的众多参数,然后对文本进行序列预测。输出层为文本向量特征提取结果序列的最大概率。
由于LSTM内部结构复杂计算量大,在模型训练上不仅需要消耗大量的时间,而且模型需要的参数也比较多。2014年GRU模型被提出,该模型合并了LSTM的隐层状态和单元状态,仅由更新门和重置门这2个门控单元组成,因此该模型相比于LSTM结构简单,收敛性好,需要的参数更少,并且效果不低于LSTM模型。BiGRU是由2个方向相反的GRU构成。每一时刻,2个方向相反的GRU同时处理输入,共同决定当前时刻的输出。一个沿着时间展开的BiGRU网络,其中每个时间步t的输入为Xt。BiGRU网络模型结构如图4所示。

图4 BiGRU模型结构
BiGRU网络在训练完成以后,会出现对特定的交通事故文本中输入的特征提取表现过于良好,而对其它输入表现不佳的现象,该现象称为网络的过拟合。为了避免该现象的影响,本文在网络输入与输出层分别加入了Dropout机制。
Dropout的核心是构造了二项伯努利分布,该分布能够在模型训练过程中,随机分配部分GRU单元不参与网络的权重参数更新,以提高模型的泛化能力。Dropout的工作结构如图5所示。

图5 Dropout结构图
引入Dropout处理后,BiGRU网络的l+1层第i个神经元输出为:
(4)

2.3 CRF层
基于BiGRU模型提取到的交通事故文本中的特征结果,可能会存在输出不合理的现象,比如会输出文本中连续的2个字符,如B-LOC,I-TIME的这种组合。
CRF模型对BiGRU网络层输出的序列进行条件约束,其能够学习到实体之间的依赖性特征,通过模型训练自动调整CRF层的参数,达到限制BiGRU层输出无效序列的效果,提高模型的识别精确度,从而提高交通事故文本实体信息抽取的准确率。
CRF层的输入是BiGRU层训练后的特征向量,将第i个向量的特征记为fi,将fi的特征权重值记为λi,λi的值由之前模块获得。将每个句子记为S,句子中词的位置记为j,各标记序列记为L,则标记序列在句子的得分为:
(5)
式(5)中,score(L|S)为各标记序列在每个句子中得分,lj是当前词的标记,lj-1是上一词的标记,句子长度为m,各标记序列对应的特征数为n。经公式(6)处理,得到各标记序列在每个句子中的得分值,并归一化转化为概率,归一化公式为:
(6)
其中,∑jexp[score[L|S]]表示所有标注序列之和,P(L|S)为归一化后的概率。输出的概率值最大的L为最终的标记序列。
2.4 模型输出层
将模型输出的序列与训练集标注序列进行比对,并计算两者之间的误差,通过模型的反向传播机制调整CRF层、BiGRU层、BERT层的参数,使得误差最小,直至不再降低,则此时该模型为最优。
3 实验结果与分析
在对交通事故文本进行标注前,需要定义交通事故文本中的各实体类型。本文使用抽样验证的方法分析出在交通事故文本中,有超过90%的信息为事故发生地点、时间、交通方式、事故形态和伤亡结果等实体信息,有约60%为道路类型,约40%为事故原因描述信息。基于此分析结果,本文标记了事故文本中事故发生地点(LOC)、事故发生时间(TIME)、事故原因(REASON)、事故类型(TYPE)、交通方式(TSP)、伤亡结果(RES)、道路类型(ROADTYPE)这7种实体类型。
本文采用BIO标记法对交通事故文本中的实体类别进行标注。BIO标记规范分别为实体开始(B)、实体中间(I)、非实体(O)。根据交通事故文本中的所蕴含的事故发生地点、事故发生时间、事故原因、事故类型、交通方式、伤亡结果、道路类型7个实体,通过BIO标记法分别定义各实体类别的标签,即可得到符合词向量生成层的输入语料标准。BIO标记法的最终标记结果见表1。
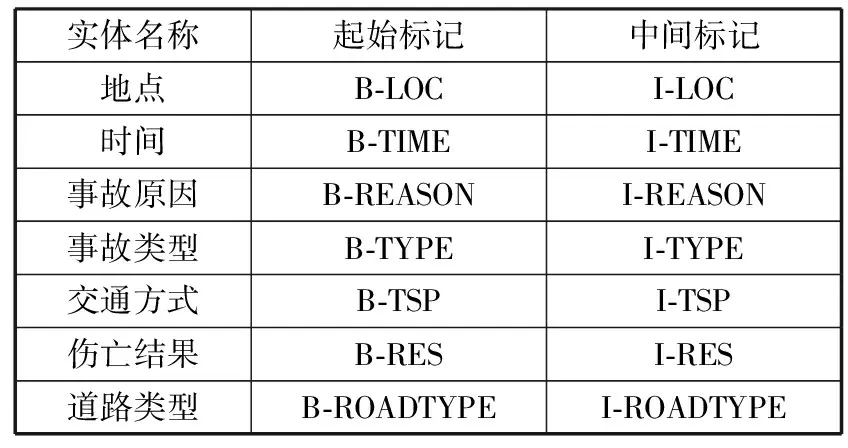
表1 交通事故实体类型定义
交通事故文本数据主要由标题、发布来源、发布日期、事故描述构成。本文使用精灵标注工具对原始交通事故文本语料进行标注,然后通过编写Python脚本对数据进一步处理,获得基于BIO标注的交通事故文本数据序列,基于BIO标注的交通事故文本序列示例见表2。

表2 基于BIO标注的交通事故文本序列
实验采用安全管理网站[16]中发布的交通事故信息数据,通过八爪鱼采集器采集交通事故文本数据4446条。根据表3设计的标注规范进行数据标注,生成511038个BIO标记序列。实验以7∶2∶1的比例划分训练集、测试集、验证集,即BIO标记序列个数分别为357726、102208、51104。实验参数设置如表3所示。

表3 BiGRU模型的主要参数
模型损失值逐渐下降,通过迭代175次后,趋于稳定,准确率变化如图6所示。

图6 训练过程中的准确率变化图
由图6可以看出准确率随着迭代次数增多而稳步上升,在经过175次的迭代后,能够趋于稳定。模型选取准确率P(precision)、召回率R(recall)与F1(F-measure)值作为模型评价指标,各指标计算公式为:
(7)
(8)
(9)
其中,c_num表示识别正确实体数,t_num表示识别实体总数,s_num表示总标注数。
为证明BERT预训练语言模型能够更好地解决引言中所指出的问题,本文分别使用静态词注入预训练模型Word2Vec、Glove,自回归语言预训练模型ELMO,统一预训练语言模型UniLM和BERT模型对交通事故文本生成向量表示,并送入BiGRU-CRF进行训练。对比结果见表4。

表4 基于不同预训练模型的实验结果对比
模型序列标注性能对比结果见表5。通过对比实验可以看出,BERT-BiGRU-CRF模型获得的F1值最高,为0.925;其次为BiGRU-CRF方法,F1值为0.847。而CRF与BiGRU方法相差9个百分点左右,证明BiGRU提取文本特征的性能优于CRF。可以得出本文使用的BERT-BiGRU-CRF模型对交通事故文本命名实体识别的整体模型性能优于其他3种方法。
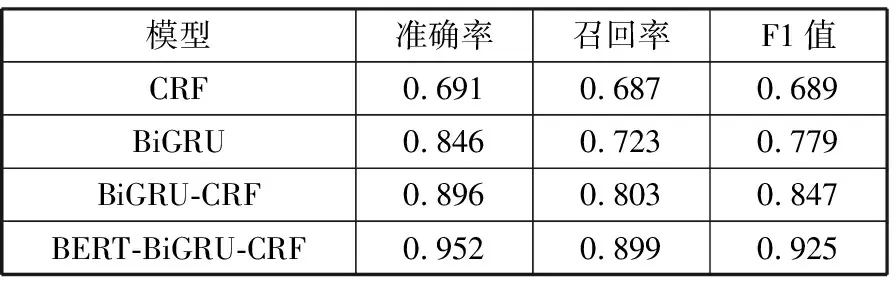
表5 模型序列标注性能对比
选取BiGRU-CRF模型与加入预训练语言模型的BERT-BiGRU-CRF模型对交通事故各个序列标注的F1值作细化对比,结果见表6。

表6 模型各标签F1值对比
从表6中可以看出:
1)在LOC(事故发生地点)、TIME(事故发生时间)的标注序列中,本文提出的模型F1值高于对比模型12.3个百分点和4.1个百分点,证明了模型能够更好地识别事故文本中数字与汉字混杂的目标实体。
2)在TYPE(事故类型)、TSP(交通方式)标签的序列标注中,模型相差11.5个百分点和5.3个百分点的F1值,归因于本文使用的模型能够充分考虑上下文信息,能更好地解决一词多义问题。
3)在REASON(事故原因)、ROADTYPE(道路类型)标签的序列标注中,上述模型均表现不佳,F1均为90%以下,归因于事故原因以及道路类型在交通事故文本中出现的次数相对其他数据较少,模型未学习到足够的特征。
4)在RES(伤亡结果)的标签序列标注中,模型相差8.1个百分点的F1值,但模型均表现良好,都达到89%以上,归因于伤亡结果表达相对固定,且出现频率较高,模型能更容易学习到更多的特征。
基于对比实验可知,使用BERT-BiGRU-CRF模型可获得对交通事故文本中的关键信息更优的提取效果。
4 结束语
本文构建了BERT-BiGRU-CRF的融合模型用于提取交通事故文本中的异构信息,与传统模型在交通事故文本中提取信息的平均准确率为0.952,F1为0.925,比基于Word2Vec的融合模型准确率与F1值分别提高了6.3个百分点和7.9个百分点。证明融合BERT后的深度学习模型可以有效提高交通事故文本异构信息提取的准确率。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小雪花·成长指南(2020年2期)2020-10-12
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
