
基于弱信号的潜在竞争对手识别方法研究
2022-06-06 02:22史敏张圆罗建
现代情报 2022年6期
史敏 张圆 罗建

摘 要:[目的/意义]识别企业未来的竞争对手,对于企业当前决策非常重要。潜在竞争对手一旦转变为直接竞争对手,往往会给企业带来巨大的冲击,甚至危及企业市场地位。为了尽早识别潜在竞争对手,本研究提出一种基于弱信号的潜在竞争对手识别方法,以期为企业开展潜在竞争对手识别提供方法支持。[方法/过程]以专利数据为信息源,构建三阶段的潜在竞争对手识别方法:第一阶段通过LDA模型对文本进行主题分类;第二阶段采用弱函数对主题进行过滤,获得弱信号主题;第三阶段将弱信号主题分类,采用平均语义量衡量企业的技术竞争力,并结合企业成长速度以识别潜在竞争对手。[结果/结论]本研究以台积电公司作为焦点企业对方法进行验证,识别出三星为其晶圆代工市场的潜在竞争对手,说明了方法的有效性。该方法将弱信号引入潜在竞争对手识别领域,既丰富和完善了竞争对手理论,也对弱信号在新领域的应用进行了深入拓展。
关键词:潜在竞争对手;专利;语义分析;弱信号
DOI:10.3969/j.issn.1008-0821.2022.06.010
〔中图分类号〕G250.25 〔文献标识码〕A 〔文章编号〕1008-0821(2022)06-0104-08
Abstract:[Purpose/Significance]Identifying future competitors of an enterprise is very important for the current decision-making of an enterprise.Once a potential competitor turns into a direct competitor,it will often bring a huge impact to the enterprise,and even endanger the market position of the enterprise.In order to identify potential competitors as early as possible,this research proposes a method for identifying potential competitors based on weak signals,in order to provide methodological support for companies to identify potential competitors.[Method/Process]Patent data were used as the information source to construct a three-stage method for identifying potential competitors:In the first stage,the text was classified by subject through the LDA model;in the second stage,a weak function was used to filter the subject to obtain a weak signal subject;in the third stage,weak signal topics were classified,the average semantic quantity was used to measure the technological competitiveness of enterprises,and potential competitors were identified in combination with the growth rate of enterprises.[Result/Conclusion]This study validates the method with TSMC as the focal enterprise,identifies Samsung as a potential competitor in the foundry market,and illustrates the effectiveness of the method.This method introduces weak signals into the field of potential competitor identification,which not only enriches and perfects the theory of competitors,but also expands the application of weak signals in new fields.
Key words:potential competitors;patents;semantic analysis;weak signal
潛在竞争对手是那些现在不被管理者关注,但将来某个时候可能给公司致命一击的竞争对手[1]。企业由于经营惯性往往将更多的精力聚焦于当前的竞争对手,从而忽视了未来可能动摇自己领先位置的潜在竞争对手。为了提升应对和防范这种风险的能力,企业需要不断收集外部环境信息,尤其是技术信息,依据信息中的早期微弱信号,识别潜在竞争对手并预测未来的发展和变化。为顺应这一需求,本研究将弱信号引入潜在竞争对手识别领域。由于“弱信号”包含了未来事件的最初征兆,而潜在竞争对手识别恰恰也是要透过早期模糊的信息来发现未来的竞争对手,因此,潜在竞争对手识别与弱信号识别具有一致性。潜在竞争对手引发的商业竞争,首先从技术层面显现,只有在技术上有所布局,才会推出源源不断的新产品。而技术的获取和识别往往需要挖掘海量的期刊、报告和专利等数据库。其中,专利作为技术宝库具有内容可靠、格式规范等优点,被广泛应用于学术和工业研究[2]。因此本研究以专利信息为数据源,构建涵盖LDA主题模型建立、弱信号主题筛选和潜在竞争对手识别三阶段的潜在竞争对手识别方法,并以半导体领域的台积电作为焦点企业开展实证分析,验证基于弱信号的潜在竞争对手识别方法的有效性。C3BEA568-E82D-4BD0-B478-AA3735F67E0E
1 文献回顾
1.1 潜在竞争对手研究
学界关于竞争对手的研究较多,但关于潜在竞争对手的研究较少。潜在竞争对手的研究大多源于Chen M J的研究,由于市场和资源(或战略)方面的差异,企业将经历不同程度的竞争紧张,为了从焦点企业的角度来评估公司之间的竞争紧张关系,建立了基于市场共性和资源相似性两个维度的竞争对手分析框架[3]。Bergen M等[4]借鉴了Chen M J的分析框架,提出了两阶段的竞争对手识别和分析框架,将竞争对手划分为直接竞争对手、间接竞争对手(替代者)和潜在竞争对手。刘志辉等在Chen M J建立的资源与市场二维框架的基础上,将表征企业创新活动的技术威胁加入评估维度中,从而建立了包括资源、市场及创新能力在内的三维企业竞争威胁测度模型[5]。吴菲菲等[6]基于专利信息,构建了两阶段三维度潜在竞争对手识别模型,第一阶段从技术应用维和知识维视角测度企业间技术关联强度;第二阶段从技术行业维视角判定技术关联类型,用于区别竞争对手特征,实现对竞争对手的技术竞争力评价。史敏等[1]基于专利说明书语义分析,开展了潜在竞争对手识别研究。
1.2 弱信号相关研究
弱信号最早是由Ansoff H I[7]于1975年提出。Ansoff H I等[8]将弱信号定义为未来可能发生变化的症状,是警告信号或新可能性的迹象。Saul P[9]认为,弱信号隐藏在噪声中,模糊且具有争议性,它们逐步汇集形成一种情报模式,用于提醒领导者改变博弈选择。董尹等[10]认为,弱信号是一个持续的意义构建过程,首先从当前经验流的异常中注意到模糊且不确切的提示,随后抽取出线索并进一步润色和细化,指引可能会产生的变化和趋势,最终通过事后的反思确定效果。弱信号意味着环境中变化的初步迹象,能为未来的预测提供重要线索。近年来,弱信号识别越来越多地受到国内外学者重视。在基于专利等非结构化数据开展弱信号识别的研究中,国外研究主要分为以词为基础[11-14]、以主题识别[15-19]为基础,以及词和主题相结合的弱信号识别研究。其中词和主题相结合的研究主要由Akrouchi M E等[20]提出,这是一种包含主题过滤和术语过滤的全自动弱信号检测方法。国内则主要基于隐含语义索引[21]、主谓宾结构[22]和专利分类号共现[23]展开弱信号识别。国内学者杨波等[24]也基于Akrouchi M E等提出的词和主题相结合的方式,再运用深度学习模型对弱信号进行语义拓展,以检测弱信号。
1.3 研究述评
综上所述,目前关于潜在竞争对手的研究较少,更无基于弱信号开展潜在竞争对手识别的研究。本研究采用主题和词相结合的方式发现技术主题的弱信号,并结合潜在竞争对手识别情境,将技术主题弱信号进行归类,形成弱信号技术主题集,统计弱信号主题中排位靠前的专利权人的专利数量,并计算专利权人的平均语义量,以此表征企业技术竞争力,通过比较技术主题集内企业技术竞争力初步识别潜在竞争对手,最后结合企业成长速度等,确定焦点企业的潜在竞争对手。本研究基于弱信号开展潜在竞争对手识别方法研究,既丰富和完善了竞争对手理论,也对弱信号理论在新领域的应用进行了方法上的拓展,具有一定的创新性。
2 研究设计
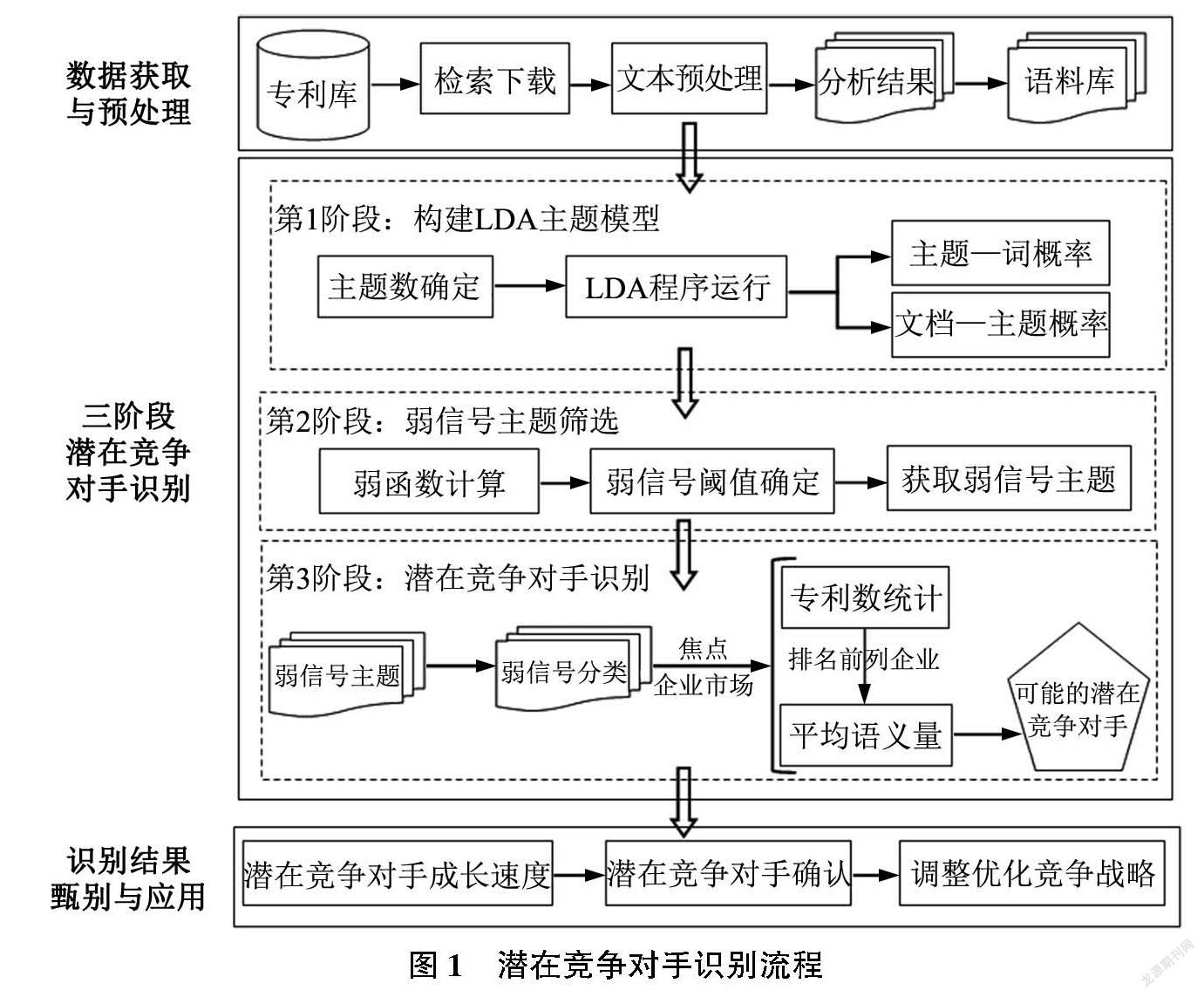
基于弱信号的三阶段潜在竞争对手识别流程包括3个环节:数据预处理、三阶段潜在竞争识别以及识别结果甄别与应用,具体如图1所示。其中三阶段潜在竞争对手识别是核心,主要包括:①第一阶段构建LDA主題模型,通过模型对语料库进行语义分析,获得技术主题,并得到文档—主题分布和主题—词分布两个矩阵;②第二阶段弱信号主题筛选,通过计算弱函数和设置弱信号阈值,获得弱信号主题;③第三阶段潜在竞争对手识别,根据焦点企业主营业务的特点,结合行业的发展情况对弱信号主题进行分类,采用平均语义量衡量企业的技术竞争力,通过分析企业技术竞争力和成长速度识别潜在竞争对手。三阶段潜在竞争对手识别方法的优势在于将弱信号识别与潜在竞争对手识别很好地融合,能对弱信号主题进行分类,从而增强潜在竞争对手发出的弱信号,提升识别的精准性。
2.1 主题分析
2.1.1 LDA主题模型
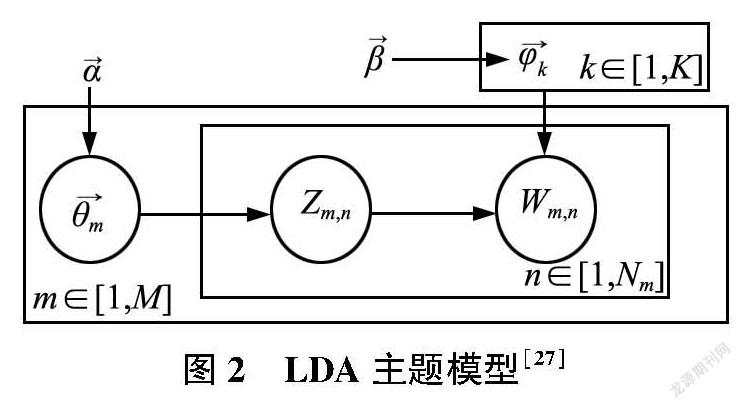
2003年,Blei D M等[25]提出一种无监督的机器学习技术LDA(Latent Dirichlet Allocation),是用于文本语料库等离散数据集合的生成性概率模型,如图2所示。它采用了词袋(Bag of Words)的方法,不考虑文档中的词语顺序,将每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。每个单词都是从单个主题生成的,文档中的不同单词可以从不同的主题生成[26]。因此,每个文档被表示为这些混合成分的混合比例列表。LDA常用于挖掘文本的隐藏主题,现在已经被应用于弱信号探测领域。
LDA主题模型如图2所示,其中α和β均为Dirichlet先验参数,M为文档的数量,K为设定的主题数,Nm为第m篇文档中单词的总数。θ为一个M*K的矩阵,θm代表第m篇文章的文档—主题分布,由参数α控制,φ是一个K*V的矩阵,V为词袋的长度,φk代表编号为k的主题—词分布,由β控制。Wm,n为第m篇文档的第n个词,是可以被观测的参数变量,Zm,n为文档m中第n个词被观测到的隐藏主题。
2.1.2 主题数确定方法
在LDA主题建模中,如何确定合适的K值一直是最具挑战性和争议性的问题之一。一般情况下,确定主题数的方法有3种:困惑度计算[28]、层次狄利克雷过程(HDP)[29]、弯头法[30]。过多的主题容易造成结果分散,会加大弱信号识别中噪音的干扰。由于弯头法可以有效地减少主题数,因此本研究采用弯头法来确定最佳主题数。该方法通过计算不同主题数的专利对之间的平均余弦相似度值来确定最佳主题数。专利对之间的平均余弦相似度,将随着主题数的增加而迅速下降,直到出现某个合适的主题数后,其相似度趋于平缓。C3BEA568-E82D-4BD0-B478-AA3735F67E0E
弯头法确定主题数K涉及到余弦相似度指标,利用β矩阵中主题在V维词空间的分布p(wv|Zi)来表示主题向量,主题i与主题j按下列公式计算余弦相似度[31]:
cos(Zi,Zj)=cos(βi,βj)=∑Vv=0βivβjv∑Vv=0(βiv)2∑Vv=0(βjv)2(1)
在此基础上,所有主题间的平均余弦相似度公式如下:
avg_cos(structure)=∑K-1i=1∑Kj=i+1cos(Zi,Zj)K*K(K-1)/2(2)
2.2 弱信号程度计算
本研究借鉴Akrouchi M E等的研究采用Logistic函数构造弱函数。Logistic函数是在传统线性回归模型的基础上,添加逻辑转换函数后的一种变体,其逻辑映射函数能够确保模型的结果保持在[0,1]之间[32]。Logistic函数常用于分类,如信用评估模型,判定违约概率。采用Logistic函数构造弱函数,并通过设置合理的阈值,将主题划分为噪音、弱信号和强信号3类。弱函数中涉及3个参数,分别为接近中心度、主题权重和自相关系数。
接近中心度,为主题t与其他主题之间的距离之和的倒数。主题t距离其他主題越近,那么它的中心度越高,越是核心主题。常见的距离计算方法有:余弦距离、欧几里得距离、Hellinger距离。由于Hellinger距离常被用来衡量概率分布之间相似度,并且满足距离的非负性[33],因此采用该距离公式计算每个主题与其余主题之间的距离。接近中心度计算公式为:
CC(t)=1∑id(t,ti)(3)
式(3)中d(t,ti)为两个主题之间的Hellinger距离。
主题权重,是基于主题的一致性分数(Coherence Score)进行计算的。主题拥有更高的一致性意味着主题更有意义。主题权重由主题t的一致性分数除以所有主题一致性分数之和获得,具体计算公式为:
W(t)=Coh(t)∑Coh(4)
式(4)中Coh(t)为主题t的一致性分数。
自相关系数表示一个信号在不同时间点的相关性程度,可用于找出被噪声掩盖的周期信号。自相关描述了同一类数据在不同时间段的关系,因为专利数据会随着时间的推移而发生变化,为了过滤掉不含弱信号的主题,采用自相关系数作为衡量工具。自相关系数,是主题t在滞后k时的协方差与其方差的比值,具体计算公式为:
AC(t)=Cov(t)kVar(t)(5)
式(5)中Cov(t)k为主题t在滞后K时的协方差,Var(t)为方差。基于上述(3)~(5)3个公式,构造主题过滤函数WK(t),见式(6)。
WK(t)=W(t)*CC(t)1+exp-(AC(t))(6)
综合前人研究,将概率低于1%的主题作为噪音,将介于1%到10%之间的界定为弱信号,将高于10%的作为强信号[34]。
2.3 潜在竞争对手识别
2.3.1 弱信号主题分类
弱信号本身具有微弱、模糊的特点,因此如果仅仅针对某个弱信号主题进行潜在竞争对手分析,很可能将一些偶尔出现的企业纳入,致使识别结果存在偏差。为此,本研究首先对识别出来的弱信号主题进行分类,由于本研究是针对焦点企业开展的潜在竞争对手识别,因此依据焦点企业主营业务的特点,结合行业的发展情况对弱信号进行划分,以便对弱信号进行增强,为后续潜在竞争对手打下基础。弱信号主题的类别确认主要根据LDA主题模型获得的主题—词分布,并通过文档—主题分布查阅部分有代表性的专利原文后进行综合判断。
2.3.2 专利权人平均语义量计算
将一个专利属于某个技术主题的概率视为专利对技术主题的语义量,语义量由文档—主题概率获得。企业在某个主题中竞争力的强弱,可以通过企业在该主题中拥有的专利平均语义量进行评判。为了简化计算,采用二八法则选择专利。二八法则认为在任何一组东西中,最重要的只占其中小部分,约20%,其余80%尽管是多数,却是次要的。根据二八法则,筛选出每个弱信号主题中主题语义排位在前20%,且专利权人为企业的专利。再对每个专利权人拥有的专利数量和语义量进行统计,然后计算各专利权人拥有的平均语义量,具体计算如式(7)所示,其中e表示某家企业,P(e)表示该企业拥有的某专利的语义量,由LDA主题模型获得的文档—主题分布决定,N表示该企业在该主题下前20%语义量中的专利数量。
S(e)=∑Ni=1P(e)N(7)
2.3.3 获得潜在竞争对手
对每个弱信号主题的专利权人专利数量从高到低排序,获得专利权人专利数量排名前10的企业名单。针对与焦点企业相关的弱信号主题集,统计专利权人出现的频次。进一步将频次较高的企业与焦点企业的技术竞争力进行对比,初步发现可能的潜在竞争对手。其中企业的技术竞争力采用平均语义量表征。最后,结合候选企业的战略、市场、研发和成长速度等进行综合判断,以最终识别潜在竞争对手。
3 实证分析
3.1 案例企业选择
台积电创立于1987年,是一家专门从事晶圆代工的企业。半导体行业有三大商业模式:IDM、Fabless、Foundry。IDM(垂直集成)是全包半导体的产业链,Fabless(无厂)专注于设计,而Foundry(代工)专注于制造。台积电的成立开创了半导体集成电路行业的Foundry商业模式。据半导体市场研究公司IC Insights的最新报告显示,台积电公司拥有56%的晶圆代工市场份额。本研究以台积电作为焦点企业,开展潜在竞争对手识别,以对潜在竞争对手识别方法进行验证。C3BEA568-E82D-4BD0-B478-AA3735F67E0E
3.2 数据获取与预处理
智慧芽数据库包含美国、欧洲、世界知识产权组织、中国、日本、韩国、挪威和全球法律专利数据库,可以为研究提供优质的原始数据来源。本研究通过智慧芽数据库检索2002—2018年的半导体行业的专利,检索式为:IPC:(H01L) AND TAC_ALL:(半导体) AND APD:[20020101 TO 20181231]AND LEGAL_STATUS:(3),过滤掉空白摘要和重复摘要文本,得到262 338份有效文本。在预处理阶段,编写Python程序对各年份中文专利摘要文本进行切割分词处理。首先利用TF-IDF算法对文本中的名词和动名词进行关键词提取,然后利用Jieba工具包去除特殊符号,并去除过于高频和无意义的停用词(如:半导体,实用新型,方法等)。得到分词结果后对词频进行统计,将阈值设置15,大于等于该阈值的为特征词,进而将特征词转化为结构化的向量空间模型,建立语料库。
3.3 三阶段潜在竞争对手识别
3.3.1 LDA主题分析
利用Python编写LDA主题分析程序,采用弯头法确定每年的主题数为9,根据已有研究,设定超参数α和β的初始值分别为“Asymmetric”和0.61,模型迭代次数为1 000,共获得153个主题。表1列出了部分主题—词分布情况。
3.3.2 弱信号主题筛选
针对每个主题计算弱函数所需的3个参数:①采用Hellinger距离计算各主题间的相似性,据此计算接近中心度;②使用Gensim计算每个主题的一致性分数,从而获得主题权重;③根据各个主题的专利数量计算专利自相关系数。在计算3个参数的基础上,计算弱函数WK(t),将结果处于1%~10%区间的主题作为弱信号主题,共获得18个弱信号主题,其年度分布情况如表2所示。表2中主题名称是根据主题—词分布,并结合文档—主题分布中排位靠前的专利内容进行命名。根据半导体集成电路行业的特点,将其划分为设计、制造和封装测试3个细分领域,将每个弱信号主题分别归类到3个领域中,如表2所示。
3.3.3 潜在竞争对手识别
鉴于台积电的主要业务是晶圆代工,属于制造领域,因此针对10个制造领域的弱信号主题进行分析。根据二八法則,对每个弱信号主题中主题语义排位在前20%,且专利权人为企业的专利数量和语义量进行统计,获得各弱信号主题下的主要企业的专利数量和平均语义量。表3呈现了制造领域弱信号主题专利数量TOP10的企业名单。
由于表3中,仅三星电子在10个弱信号主题中均位于TOP10名单中,且在2003—2008年和2011年的5个主题上超过台积电,因此重点对三星电子和台积电的平均语义量进行对比分析,如图3所示。在制造领域弱信号主题中,三星电子平均语义量在2003—2009年均高于台积电,2011—2014年略低于台积电,2016年和2018年又高于台积电,说明三星电子一直在深耕半导体制造领域,且不断推陈出新。根据表3和图3所呈现的数据,在2003—2009年,三星电子有成为台积电潜在竞争对手的可能性。
3.4 识别结果甄别
以下结合三星电子的战略、市场、研发,以及成长速度等对识别结果进行甄别。2005年,三星电子宣布进入晶圆代工行业。据当时Barrons采访三星电子半导体事业部总裁黄昌圭的报道显示,三星代工的产品主要是面向高端的芯片产品,与台积电的市场定位并不相同,可见当时的三星电子虽然进入了晶圆代工行业,但与台积电处于不同的细分市场,还尚未成为其竞争对手。2005—2009年,三星代工业务的年营收额均未超过4亿美元。而在2010—2012年,三星的晶圆代工业务有了飞速发展,从2009年的3.25亿美元跃至2012年的43.3亿美元,如图4所示。从企业的成长速度这一关键变量来判断,这个阶段三星已经成为台积电的潜在竞争对手。随着2017年,三星正式宣布将晶圆代工业务部门独立为纯晶圆代工企业,并计划在5年内获得代工市场25%的份额,三星正式成为台积电的竞争对手。2018年,三星在全球晶圆代工行业跃居第二,且表示未来要争夺晶圆代工领域的龙头。
以上以台积电为焦点企业,基于弱信号主题发现三星电子可能成为其潜在竞争对手,再结合三星电子在晶圆代工行业的成长速度等,确认三星电子为其潜在竞争对手,且在随后5年就迅速发展成为直接竞争对手,说明了潜在竞争对手识别方法的有效性。
4 结 论
鉴于弱信号检测与潜在竞争对手识别具有一致性,本研究将弱信号引入潜在竞争对手识别领域,构建了基于弱信号的三阶段潜在竞争对手识别方法。该方法具有3个特点:一是充分运用LDA语义分析所获得的主题—词分布和文档—主题分布,通过这两个矩阵不仅开展了弱信号检测,还利用文档—主题分布获得专利权人平均语义量,以表征企业的技术竞争能力;二是结合焦点企业所处行业的特点对弱信号进行分类,由于弱信号本身的模糊性,仅仅依靠单一的弱信号主题开展识别,容易出现偏差,因此将检测的弱信号主题根据细分领域进行划分,形成弱信号主题集,以便通过时间的变化发现候选潜在竞争对手;三是本研究是基于领域内处于领先地位的焦点企业开展的潜在竞争对手识别,除了在新技术研发方向上发现可能对自己产生威胁的企业之外,还结合企业成长速度这一关键因素来做进一步判断,以提高识别的准确性。本研究以台积电为焦点企业,识别出三星电子为其潜在竞争对手,说明了方法的有效性。期望本研究能够为领先企业开展潜在竞争对手识别提供理论与实践支持。下一步将在更多行业采用该方法识别潜在竞争对手,以进一步总结和完善该方法。
参考文献
[1]史敏,罗建,蔡丽君.基于专利说明书语义分析的潜在竞争对手识别研究[J].情报学报,2020,39(11):1171-1181.
[2]杨辰,王楚涵,陶琬莹,等.基于专利的技术机会识别:深度学习领域的案例分析[J].科技管理研究,2021,41(12):172-176.C3BEA568-E82D-4BD0-B478-AA3735F67E0E
[3]Chen M J.Competitor Analysis and Interfirm Rivalry:Toward a Theoretical Integration[J].Academy of Management Review,1996,21(1):100-134.
[4]Bergen M,Peteraf M A.Competitor Identification and Competitor Analysis:A Broad-based Managerial Approach[J].Managerial and Decision Economics,2002,23(4-5):157-169.
[5]劉志辉,李辉,李文绚,等.基于多维框架的企业竞争威胁测度方法研究[J].情报学报,2017,36(7):654-662.
[6]吴菲菲,杨梓,黄鲁成.基于专利信息的企业潜在竞争对手识别——以OLED技术为例[J].情报学报,2017,36(9):954-963.
[7]Ansoff H I.Managing Strategic Surprise By Response to Weak Signals[J].California Management Review,1975,18(2):21-33.
[8]Ansoff H I,Mcdonnell E J.Implanting Strategic Management[M].New York:Prentice-Hall International Inc.,1984
[9]Saul P.Seeing the Future in Weak Signals[J].Futures Studies,2006,10(3):93-102.
[10]董尹,刘千里,宋继伟.基于系统动态学方法的弱信号生命周期建模与仿真[J].图书情报工作,2019,63(13):75-84.
[11]Yoo S H,Park H W,Kim K H.A Study on Exploring Weak Signals of Technology Innovation Using Informetrics[J].Technology Innovation,2009,17(2):109-130.
[12]Yoon J.Detecting Weak Signals for Long-term Business Opportunities Using Text Mining of Web News[J].Expert Systems with Applications,2012,39(16):12543-12550.
[13]Kim J,Lee C.Novelty-focused Weak Signal Detection in Futuristic Data:Assessing the Rarity and Paradigm Unrelatedness of Signals[J].Technological Forecasting & Social Change,2017,120:59-76.
[14]Griol-Barres I,Milla S,Cebrián A,et al.Detecting Weak Signals of the Future:A System Implementation Based on Text Mining and Natural Language Processing[J].Sustainability,2020,12(19):7848.
[15]Pépin L,Kuntz P,Blanchard J,et al.Visual Analytics for Exploring Topic Long-term Evolution and Detecting Weak Signals in Company Targeted Tweets[J].Computers & Industrial Engineering,2017,112:450-458.
[16]Gutsche T.Automatic Weak Signal Detection and Forecasting[D].University of Twente,Faculty of Behavioral Management and Social Sciences,2018.
[17]Maitre J,Ménard M,Chiron G,et al.A Meaningful Information Extraction System for Interactive Analysis of Documents[C]//2019 International Conference on Document Analysis and Recognition.Sydney.IEEE.2019.92-9.
[18]Krigsholm P,Riekkinen K.Applying Text Mining for Identifying Future Signals of Land Administration[J].Land,2019,8(12):181.
[19]Klbl L,Grottke M.Obtaining More Specific Topics and Detecting Weak Signals by Topic Word Selection[J].Springer Series in Reliability Engineering,2020:193-206.C3BEA568-E82D-4BD0-B478-AA3735F67E0E
[20]Akrouchi M E,Benbrahim H,Kassou I.End-to-end LDA-based Automatic Weak Signal Detection in Web News[J].Knowledge-Based Systems,2021,212:106650.
[21]顧伟,傅德胜,蔡玮.基于语义Web挖掘的宽范围扫描环境弱信号识别[J].科学技术与工程,2013,13(29):8791-8797.
[22]翟东升,夏军,张杰,等.基于专利新兴技术弱信号识别方法研究[J].情报杂志,2015,34(8):31-36.
[23]贾军,魏洁云.新兴产业核心技术早期识别方法与应用研究[J].科学学研究,2018,36(7):1206-1214.
[24]杨波,邵婉婷.面向企业竞争情报的弱信号识别研究[J].现代情报,2021,41(9):53-63.
[25]Blei D M,Ng A N,Jordan M I.Latent Dirichlet Allocation[J].Machine Learning Research,2003,3(4/5):993-1022.
[26]邱均平,沈超.基于LDA模型的国内大数据研究热点主题分析[J].现代情报,2021,41(9):22-31.
[27]杜景玮.基于LDA主题模型的情感分析研究[D].广州:暨南大学,2020.
[28]关鹏,王曰芬.科技情报分析中LDA主题模型最优主题数确定方法研究[J].现代图书情报技术,2016,(9):42-50.
[29]Teh Y W,Jordan M,Beal M,et al.Hierarchical Dirichlet Processes[J].American Statistical Association,2006,101(476):1566-1581.
[30]Jeong B,Yoon J.Competitive Intelligence Analysis of Augmented Reality Technology Using Patent Information[J].Sustainability,2017,9(4):1-22
[31]曹娟,张勇东,李锦涛,等.一种基于密度的自适应最优LDA模型选择方法[J].计算机学报,2008,(10):1780-1787.
[32]张润驰,张谊浩,赵辉,等.银行信用评估模型效果的量化比较[J].金融监管研究,2021,(1):66-85.
[33]赵亮,刘建辉,王星.基于Hellinger距离的混合数据集中分类 变量相似度分析[J].计算机科学,2016,43(6):280-282,307.
[34]Thorleuchter D,Poel D V D.Weak Signal Identification with Semantic Web Mining[J].Expert Systems With Applications,2013,40(12):4978-4985.
(责任编辑:陈 媛)C3BEA568-E82D-4BD0-B478-AA3735F67E0E
猜你喜欢
水运工程(2022年7期)2022-07-29
传感器世界(2019年4期)2019-06-26
中国洗涤用品工业(2019年4期)2019-05-11
软件导刊(2017年1期)2017-03-06
电子技术与软件工程(2016年22期)2016-12-26
科技视界(2016年18期)2016-11-03
湖南大学学报·自然科学版(2016年2期)2016-03-15
化学分析计量(2013年1期)2013-03-11
轴承(2010年2期)2010-04-04
