
基于数据挖掘方法的瓦斯事故调查报告关键因素分析
2022-06-21 10:08杨超宇
哈尔滨商业大学学报(自然科学版) 2022年3期
潘 杰, 杨超宇
(安徽理工大学 经济与管理学院,安徽 淮南 232000)
瓦斯事故是煤矿生产过程中的重要隐患之一,当瓦斯达到某种极限值浓度时将会导致人员呼吸停止,而且其爆炸浓度的区间范围较广,遇火极易发生爆炸.随着我国经济快速发展以及对煤炭需求依赖大,在此过程中需不断地增加煤矿采量,而瓦斯气体爆炸所引起灾害的危险概率也越来越高,经近年来的研究,井下安全事故不再频发,尽管如此,一旦井下发生安全事故,死亡率还是比较高的,所以需要采取有效的措施来防止瓦斯事故的发生,保障煤炭安全开采[1-3].
近年来,在生产生活中的各大领域,数据挖掘技术都得到了广泛的应用.煤矿瓦斯的治理工作具有重大的现实意义,采用数据挖掘方法对瓦斯事故调查报告进行分析并找出其中关键因素,能够保障煤矿的安全开采[5-6].
1 数据挖掘方法
对瓦斯事故调查报告采用数据挖掘方法进行分析,其基本流程如下:字符识别,结巴分词,关联规则分析.如图1所示.

图1 基本流程Figure 1 Basic process
1.1 场景文本识别(STR)
在对瓦斯事故调查报告进行字符识别之前,需要导入pymupdf,fitz这两个库将其pdf格式转化为图片格式,方便之后的字符识别.
本文采用了场景文本识别(STR)技术对图片格式的瓦斯事故调查报告进行字符识别,场景文本识别是在自然场景中识别文字,与传统的光伏字符识别(OCR)相比较,STR需应对自然场景中字体多样、多方向和背景复杂等多种因素,具有强稳定性和鲁棒性,而且基于深度学习的STR在识别中具有精度高和效率快的特点.
1.1.1 场景文本识别(STR)模型
现大多数的场景文本识别模型都是基于解码-编码框架,此框架主要能够解决序列-序列(Sequence-sequence)的问题.如图2,首先Encoder编码是将原始序列(x1,x2,...)转变为一个长度不变的语义编码,最后Decoder解码是将其再转化为终指序列(y1,y2,...).本文瓦斯事故调查报告的图片文字识别就是一个序列-序列的典范.
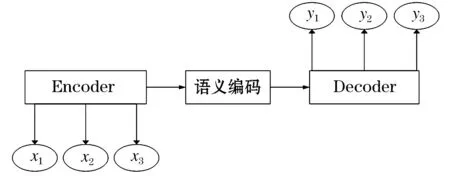
图2 编码-解码框架Figure 2 Encoder-Decode frame
通常编码-解码框架的文本识别模型是基于CRNN模型的,主要是由CNN(卷积神经网络)和RNN(循环神经网络)构成的,先是利用CNN,接着利用一个双向RNN来特征编码,最后利用一个单向RNN来进行解码操作.CRNN网络模型结构如图3所示.

图3 场景文本识别代表模型Figure 3 Representative model of scene text recognition
1.1.2 STR的评价标准
对于场景文本识别,采用的识别评价指标是正确率(accuracy),其计算公式:
(1)
其中:M代表数据集中正确识别的样本数目,N代表数据集中所有样本数目.
1.1.3 STR中的Attention机制
在场景文本识别中采用Attention机制可以大幅增强识别的准确率.注意力机制是指在编码时采用局部来替代全局注意力,再通过单向长短记忆网络来解码.在解码时,假设图片输入的序列帧为S={h0,h1,…,ht},长度为T.在解码t-th时,解码层输出结果的计算:
yt=Generate(st,gt)
(2)
其中:st为递归网络中隐节点的时间状态,st的计算公式为:
s1=RNN(yt-1,gt,st-1)
(3)
其中:gt代表一些编码序列H={ht-1,ht,ht+1}加权卷积后的平均输出,gt的计算公式为:
gt=Average(W1⊗[at,j-1hj-1,αt,jhj,αt,jhj+1],…,
Wk⊗[at,j-1hj-1,αt,jhj,αt,jhj+1])
(4)
其中:αt为attention机制的权重因子,计算为:
ei,j=vTtanh(Wst-1+Vhj+b)
(5)
(6)
其中:W,V,b都是可训练参数,W和V为权值矩阵,v为一个向量.
编码器所输出的每项内容都具有重要性,其可通过注意权重来正确反映.通过将权重作为系数,解码器将H的列线性组成一个向量aglance.
(7)
(8)

1.2 结巴分词
本文使用的字符切割方法是哈工大语言技术平台(LTP)提供的结巴分词,分词就是将图片中识别好的字序列按照规则划分为词序列,是为了之后更好的对关键词进行关联规则分析,其过程主要包含了词性标注、依存句法分析、语义角色标注等步骤.
1.2.1 切词采用了结巴分词原理
结巴分词是一种中文分词的方法,其主要支持精确模式、全模式和搜索引擎模式.以下是结巴分词技术路线,如图4所示.

图4 结巴分词技术路线Figure 4 Technical route of stuttering word segmentation
1.2.2 结巴分词的过程
结巴分词基于Python语言,其过程分为三步:
1)加载字典,生成trie树;
2)对于要操作的句子,使用正则方法来获取连续的中英文字符,是将整个句子切分成一个个短语,对每个短语使用DAG(查字典)和动态规划方法,得到最大概率路径,将那些没有查到的字组合成一个新的句子,再使用HMM模型对其进行分词,就能够正确识别出字典之外的新词;
3)使用Python的yield语法来编成一个词语生成器,逐词返回.
1.3 词的关联规则分析
关联规则分析是一种精简且有效的方法,用于分析词之间的关联性,Agrawal等人首先提出其概念以及Apriori算法[7].对于Apriori算法效率低,时间和空间复杂度高的特点,2000年Han等基于Apriori算法提出了FP-Growth(Frequent Pattern-growth)算法[8].把瓦斯事故调查报告中切好的词以及权重值所组成的数据作为输入事务数据库,得到每个事务的频繁项,按其置信度降序排列,之后再保存到FP-tree中.在检索频繁模式的过程中,就不需再次搜索数据集了,只需在FP-tree中进行查找,大幅提高了效率[9-10].通过FP-growth关联规则算法来识别出瓦斯事故中的频繁项集,设置支持度以及置信度数来得出因素之间的强关联规则,能够分析出造成瓦斯事故发生的关键因素[11-12],来预防瓦斯事故的发生.
根据频繁项集可以得到既满足最小支持度又满足最小置信度的强关联规则,支持度的计算公式为:
support(A⟹B)=p(A∪B)
(9)
其中:support(A=>B)表示项集A和项集B的记录数在全部记录数中同时出现的概率.
置信度的计算公式为:
support(A⟹B)=P(A/B)=
(10)
其中:support_count(A∪B)是指包含项集(A∪B)的全部记录数,support_count(A)是指包含项集A的全部记录数.从瓦斯事故调查报告中获得频繁项集可采用FP-growth算法,其主要步骤如图5所示.

图5 瓦斯事故报告的频繁项集获取流程Figure 5 Acquisition process of gas accident reports′frequent itemsets
2 应用实例
本文以瓦斯事故报告为例,介绍字符识别技术在瓦斯事故pdf格式报告处理中的应用.
2.1 瓦斯事故报告识别流程
2.1.1 利用Python将瓦斯事故报告pdf转化为图片
pdf格式的瓦斯事故报告在进行字符识别之前,需对pdf进行预处理,将pdf转化为图片,以提高字符识别效率和质量.需要导入pymupdf,fitz这个库,利用Python将pdf格式转化为图片格式.
# 打开pdf文件,生成一个对象
doc=fitz.open('D:论文瓦斯事故报告2.pdf')路径,瓦斯事故报告pdf格式如图6所示.

图6 瓦斯事故调查报告pdfFigure 6 Gas Accident Investigation Report pdf
pdf转化为png格式,运行结果如图7所示.

图7 瓦斯事故调查报告pngFigure 7 Gas accident investigation report png
2.1.2 对转化好的图片进行字符识别
通过场景文本识别(STR)来对转化好的图片进行字符识别[13-15].先创建lmdb数据集.然后再下载好lmdb数据集进行训练,验证和测试.紧接着下载好的预训练模型,添加图片demo_image路径进行运行.运行结果如图8和表1所示.

表1 字符识别部分结果和可信度表Table 1 Results and reliability of character recognition

图8 字符识别Figure 8 Character recognition
2.1.3 将识别好的字符进行分词,提取关键词信息
结巴切词的目的是将图片中识别好的单个字分割成词[16-18],方便下一步分析词与词之间的关联性.切词的过程是通过词性标注,依存句法分析和释放模型等对已经识别好的字符进行切割,运行部分结果如图9所示.

图9 切词部分结果Figure 9 Results of word segmentation
2.1.4 分析这些关键词之间的关联性,并找出潜在的致因
利用Pycharm软件,基于python来运行Apriori和FP-Growth算法,来找出瓦斯事故调查报告关键字的频繁项集以及各关键词与瓦斯事故之间的关联关系.最小支持度minsup设置为0.25,以瓦斯事故报告为例,运行结果如图10、11所示.

图10 频繁项集部分结果Figure 10 Partial results of frequent itemsets

图11 项集的所有条件模式基分析Figure 11 All conditional pattern basis analysis of itemset
如图10,从运行代码结果可以看出,{‘瓦斯事故’: [120, None], ‘通风不畅’: [72, None], ‘人员违规操作’: [58, None], ‘掘进障碍’: [47, None], ‘设备损坏’: [43, None], ‘井下爆破不当’: [45, None], ‘停电’: [34, None], ‘断面缩小’: [30, None]等等.因为设置的最小支持度为0.25,过滤了支持度小于0.25的项集,从这些瓦斯事故调查报告中可以看出,在经过大量删选词的总篇数中有72篇频繁出现‘通风不畅’一词,有58篇频繁出现‘人员违规操作’,有47篇频繁出现‘设备损坏’等等.之后开始递归查找这个一项集的所有条件模式基,比如分析‘通风不畅’这个项集的所有条件模式基,如图12所示.
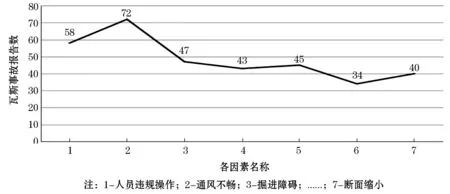
图12 各因素与瓦斯事故数关系图Figure 12 Relationship between various factors and the number of gas accidents
从图12可以看出‘通风不畅’这个词出现的频率较广,从表2中可以看出‘通风不畅’对‘瓦斯事故’的置信度最高,为0.965 57,说明'通风不畅'导致'瓦斯事故'发生的可能性为0.965 57.基于关联规则分析,表明其与‘瓦斯事故’之间存在强关联性,由此可以得出'通风不畅'问题可能是导致瓦斯事故发生的关键原因,因此建议多注意通风问题,及时完善通风设备,检测通风状况以及配备专职的通风技术人员等措施,才能有效地预防瓦斯事故的发生,保障煤矿的安全开采.

表2 各因素与瓦斯事故之间的关联关系Table 2 Correlation between various factors and gas accidents
3 结 语
本文基于数据挖掘方法对瓦斯事故报告进行分析,主要利用字符识别技术找出瓦斯事故发生的原因.通过场景文本识别(STR)、结巴切词、FP-growth关联规则算法等技术来分析瓦斯事故报告,找出瓦斯爆炸的关键因素,对预防瓦斯事故的发生以及煤矿的安全生产起到一定的积极作用.另外,本文的研究存在不足,在利用FP-growth关联规则分析时,需要大量的瓦斯事故调查报告,本文基于的样本较少,不能够准确的得出导致瓦斯事故发生的关键因素,下一步对FP-growth算法进行改进使其更加适用于实际应用.
猜你喜欢
计算机应用与软件(2022年7期)2022-08-10
哈尔滨理工大学学报(2021年4期)2021-10-07
考试与评价·高二版(2021年1期)2021-09-10
计算机应用(2021年8期)2021-09-09
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
学苑创造·B版(2016年8期)2016-07-02
作文世界(小学版)(2008年4期)2008-06-05
中学生英语·外语教学与研究(2008年4期)2008-03-18
