
基于视觉Transformer的双流目标跟踪算法
2022-06-23 06:24江英杰宋晓宁
计算机工程与应用 2022年12期
江英杰,宋晓宁
江南大学 人工智能与计算机学院,江苏 无锡 214122
视觉目标跟踪技术在智能安防、人机交互、无人驾驶、行为识别和人流统计等实际场景下具有非常广泛的应用[1-5],逐渐成为计算机领域内的一个研究重点。根据需要跟踪的目标对象数量的不同,可以分为单目标和多目标跟踪。本文主要针对单目标跟踪开展研究。近些年来,基于深度孪生网络的目标跟踪算法[6-8]由于简洁高效的成对匹配形式和特征提取能力逐渐成为主流。其将跟踪表示为匹配问题,使用共享参数的孪生网络提取目标模板和搜索区域的特征并进行相似性衡量。在此基础上,许多基于锚点(anchor-based)或无锚(anchor-free)的方法被提出,代表性的如SiamRPN++[9]和Ocean[10]。这些方法在跟踪性能上取得了不错的进展,但是其对模板和搜索区域特征的融合依赖于相关操作,对全局信息的利用还不够充分。
最近随着Transformer[11]在计算机视觉领域的广泛应用,一些前沿的研究开始发掘Transformer在改进孪生网络跟踪算法中的巨大潜力。如TrSiam[12]利用Transformer来增强和传播深度卷积特征提高跟踪精度。TrTr[13]使用Transformer获得丰富的上下文信息来帮助孪生网络进行相关性计算。STARK[14]通过Transformer编码器-解码器建模目标与搜索区域全局依赖关系。
虽然上述基于Transformer的目标跟踪算法取得了不错的进展,但是其主要都是为了更好地融合或者增强从深度卷积网络如ResNet[15]中提取的目标和搜索区域特征,忽视了视觉Transformer本身在特征提取和解码预测方面的能力。针对这些问题,本文提出基于视觉Transformer的双流目标跟踪算法。首先利用基于注意力机制的Swin Transformer[16]作为孪生主干网络获得更加鲁棒的特征表示。接着通过Transformer编码器-解码器结构充分融合目标和搜索区域特征,并学习目标特定的信息。最后对学习到的双流信息分别进行预测后再进行决策层面的加权融合。通过本文这样的设计可以有效利用双流信息进行互补,能够有效应对遮挡、干扰和尺度变化等情况,实现准确的目标跟踪。另外,由于本文算法是端到端进行训练和测试的,避免了先前孪生网络算法中使用的余弦窗等复杂的后处理步骤,跟踪速度可达42 FPS(frame per second,FPS),具有巨大的潜力。
1 基于视觉Transformer的双流目标跟踪算法
本文算法整体框架如图1所示。首先使用一个共享权重参数的Swin Transformer作为孪生主干网络对第一帧目标模板(target template)图像和当前帧搜索区域(search region)图像分别进行特征提取。其次使用Transformer编码器对目标模板特征和搜索区域特征进行特征融合,再使用Transformer解码器学习目标查询中特定的目标位置信息。然后对编解码器输出的双流信息分别进行边界框预测。最后在决策层面上进行加权融合得到目标最终跟踪结果。

图1 算法整体框架Fig.1 Overall framework of the algorithm
1.1 视觉Transformer孪生主干网络
本文采用基于注意力机制的Swin Transformer作为孪生主干网络,具体结构如图2(a)所示。相比于经典的卷积神经网络,Transformer中的自注意力机制能够挖掘全局依赖关系,具有全局感受野,在许多视觉任务上取得了很好的效果。Swin Transformer是由微软在2021年提出的视觉Transformer模型,通过在不重叠的窗口进行自注意力计算和允许跨窗口连接来提高计算效率,使得其与视觉任务相兼容。

图2 Swin Transformer孪生主干网络Fig.2 Swin Transformer siamese backbone network
本文中Swin Transformer孪生主干网络的输入是一对图像,分别是初始帧的目标模板图像z∈RHz×Wz×3和当前帧的搜索区域图像x∈RHx×Wx×3。输出分别是模板特征和搜索区域特征为了降低计算成本,本文只使用Swin Transformer的前3个阶段(Stage)提取特征,所以此处的步长s为16。
Swin Transformer每个阶段由多个连续的Swin Transformer块(block)组成,其中每两个连续块的结构如图2(b)所示,由层归一化(layer norm,LN)、窗口多头自注意力(window based multi-head self-attention,W-MSA)、移位窗口多头自注意力(shifted window based multi-head self-attention,SW-MSA)和多层感知机(multilayer perceptron,MLP)通过残差连接组成。具体过程可表示为:

其中,Xl和X̂l分别表示第l个块中MLP和两种自注意力的输出结果。当固定每个局部窗口中所包含块的数量M×M时,W-MSA通过在不重叠的局部窗口计算多头自注意力可以将计算复杂度从块数量的二次方降低为线性复杂度。本文中M默认设置为7。同时SWMSA在保持非重叠窗口的有效计算的同时引入跨窗口连接,与前一层的窗口进行桥接,可以显著增强特征建模能力。这种策略具有较低的实际延迟,并且可以逐层聚合相邻窗口的特征表示,能够感知全局信息,为跟踪任务提供了更加鲁棒的特征表示。
1.2 Transformer编码器-解码器结构
Swin Transformer孪生主干网络输出的模板特征和搜索区域特征首先经过一个1×1卷积层将通道数从C降低到d,与后续Transformer编码器-解码器结构中的隐藏层维度保持一致。然后将两个特征分别展平,再沿着空间维度连接起来得到长度为的总特征表示F输入到Transformer编码器中。
(1)编码器。Transformer编码器由一系列连续的编码器层组成,每层包括多头自注意力MSA和前馈网络(feed forward network,FFN)。其中FFN包含一个两层的多层感知机和GELU激活函数。每层间的计算过程如下:
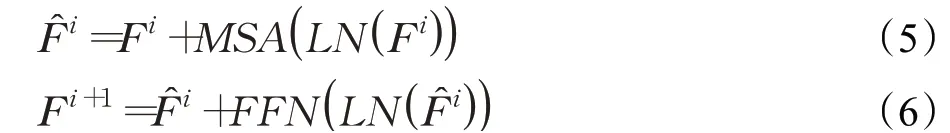
其中,Fi和F̂i分别表示第i层的输入和中间计算结果。
由于Transformer是序列到序列模型,具有排列不变性,因此在通过拼接方式自然地融合来自模板分支和搜索分支的特征之后,本文添加了正弦位置编码[11]到每个注意力层的输入序列中,以确保模型在计算注意力过程中知道特征标记所处的位置和分支。通过编码器层中的自注意力机制对总特征表示中的模板和搜索区域特征之间的依赖关系进行捕获,利用全局信息有效融合和增强特征的判别性,帮助网络更加准确地定位目标位置。
(2)解码器。Transformer解码器具有与编码器类似的结构,也是由连续的解码器层组成,每层包括多头自注意力、编码器-解码器注意力和前馈网络。
解码器的输入是编码器输出的增强后的总特征表示F̂和目标查询(target query)。不同于检测任务中采用的多个对象查询,本文只采用一个目标查询进行预测来降低计算成本。目标查询通过编码器-解码器注意力关注模板和搜索区域上的所有位置,建立全局关系,输出得到鲁棒的目标表示T用于后续边界框预测。与编码器类似,在解码器的每个注意力层的输入中也加入位置编码来传递位置信息。
1.3 双流信息预测与决策融合
总特征表示F经过整个编码器后输出得到增强的总特征表示F̂,然后将其按照原来的顺序分离重新得到增强后的模板特征f̂z和搜索区域特征f̂x。解码器输出的目标表示T与搜索区域特征f̂x一起构成了Transformer编码器-解码器输出的双流信息。
为了充分地利用双流信息中目标判别特征以及全局区域信息进行边界框预测,本文对双流信息进行融合与互补。具体地,如图1中所示,一边使用编码器边框预测头(box head)融合双流信息进行预测,另一边通过多层感知机对解码器信息进行预测。最后在决策层面进行融合进一步优化目标跟踪结果。
编码器边框预测头的结构如图3所示。搜索区域特征f̂x与目标表示T分别通过点积注意力机制和深度互相关(depth-wise cross correlation,DW Corr)操作进行特征增强,得到全新特征并进行拼接(concatenation)。然后重塑成方形特征图输入到全卷积网络(fully convolutional networks,FCNs)中进行角点热力图(corner heatmap)预测。最后计算角点概率分布的期望得到编码器流的边界框预测结果BE。

图3 编码器边框预测头Fig.3 Encoder box prediction head
与STARK[14]不同的是,本文考虑到深度互相关操作在孪生网络跟踪算法中的广泛应用[9-10],能够帮助找到搜索区域中与目标表示高度相关的位置,有利于后续的角点概率预测。因此将其与点积注意力机制进行互补,从两个角度共同衡量目标相似性来增强重点区域得到更具判别性的全新搜索区域特征进行预测。
对于解码器流信息使用三层的多层感知机MLP直接回归目标边界框坐标,得到解码器边界框预测结果BD。这样的设计能够以微量的计算成本来利用解码器学习到的目标表示T中丰富的目标信息进行显式的结果预测,避免了该信息只在编码器边框预测头中起到相似性度量的作用的情况,减少了目标信息的浪费。
在得到双流信息预测结果BE和BD之后,本文在决策层面使用了加权融合策略。通过两个线性层分别学习编码器流和解码器流预测结果的融合权重w1和w2,然后对结果进行加权融合得到最终优化的目标跟踪结果BF,具体计算过程如公式(7)~(11)所示:


其中,W1和W2分别为这两个线性层的权重矩阵,b1和b2为对应的偏置项,ŵ1和ŵ2为归一化之前的权重。
1.4 损失函数与多监督策略
本文算法是通过端到端的方式进行训练的,使用L1损失和GIoU(Generalized IoU)损失[17]对边界框预测结果进行监督。整个框体损失函数LBBox的计算公式如下:
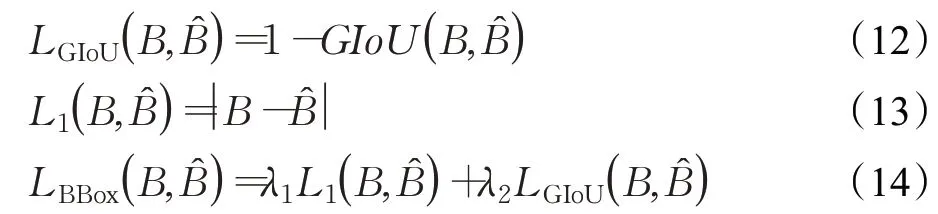
其中,B̂和B分别表示边界框真实标签和预测结果,λ1和λ2是每项的损失权重系数,在本文中分别设置为5和2。
考虑到恰当的监督策略对整体网络的收敛与性能起到了非常重要的作用,本文针对提出的双流信息预测与决策融合结构使用了多监督策略。即对双流信息预测结果和最终跟踪结果共同进行监督以保证充分的收敛性及性能提升。最终的损失函数如公式(15)所示:
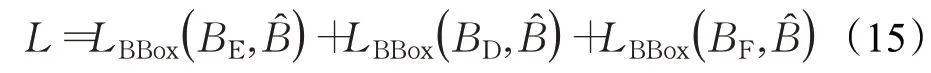
其中,BE、BD和BF分别代表编码器预测框、解码器预测框和最终预测框。
2 实验结果与分析
2.1 实验设置
本文算法是使用Python 3.6和Pytorch 1.5.1框架实现的。在具有两块RTX 2080Ti GPU的64 GB物理内存的服务器上进行实验。本文使用Swin-T[16]作为孪生主干网络,主干网络输出特征维度C为384,训练过程中使用在ImageNet[18]上预训练的参数进行初始化。Transformer编码器-解码器均为6层,其中多头注意力的隐藏层维度d和头数分别设置为256和8,前馈网络的隐藏层维度为2 048。Dropout[19]设置为0.1来减少过拟合。编码器边框预测中的全卷积网络由5层卷积块组成,解码器边框预测使用的三层MLP的隐藏层维度为256。
训练数据由LaSOT[20]、GOT-10k[21]和TrackingNet[22]数据集的训练部分以及COCO[23]数据集组成。目标模板图像及搜索区域图像分别被裁剪成128×128和320×320的大小送到主干网络中。数据增强采用了水平翻转和亮度抖动等策略。整体训练过程为500个周期(epoch),每个周期有60 000个样本,使用AdamW[24]优化器进行优化。整体网络的初始学习率为5E-5,权重衰减为1E-4。为了稳定训练保证收敛,采用梯度裁剪和学习率衰减策略,在400个周期后将学习率缩为原来的1/10。主干网络以其他部分1/10的学习率进行微调。
2.2 数据集及评价指标
本文在LaSOT[20]、TrackingNet[22]、UAV123[25]和NFS[26]四个通用目标跟踪数据集上验证算法的有效性。其中LaSOT数据集有1 400个视频序列,平均有2 512帧,共包含70个目标类别,每类有20个序列,涉及野外场景下的各种挑战。该数据集每帧都是手工标注并经过严格检查,提供了一个高质量的大规模目标跟踪基准。其中划分20%作为测试集,共包括280个视频序列。
TrackingNet是从大规模目标检测数据集中精挑细选出专门针对目标跟踪的视频片段并进行重新标注。总共30 643个视频片段,平均时长16.6 s。其中测试集包括511个视频和70个目标类别,并且没有给出真实标注,只能通过在线服务器进行评估以确保公平比较。
UAV123数据集中包括低空无人机平台采集的123个航拍视频,平均915帧。随着无人机的运动相机视角也在不断发生变化,因此目标长宽比的变化比较明显,对跟踪算法的状态估计能力提出了巨大的挑战。NFS数据集包括100个视频序列,使用高帧率摄像机从真实世界场景捕获并手动标注,为实际跟踪应用提供测试基准。
LaSOT和TrackingNet两个数据集均采用一次性评估(one-pass evaluation,OPE)策略,评价指标为精度(precision,P)、归一化精度(normalized precision,NP)和成功率(success,S)。UAV123和NFS数据集只包括精度和成功率两个指标。其中精度是通过比较预测结果跟真实结果之间的距离来计算,成功率是通过衡量两者之间的交并比来计算。由于精度指标对目标大小和图像分辨率非常敏感,因此归一化精度是根据真实目标框大小对精度进行归一化计算。最终跟踪算法通常根据成功率图的曲线下面积(area under curve,AUC)进行排名。
2.3 消融实验
为了降低训练成本,消融实验中比较的算法模型均统一训练250个周期,其余策略与实验设置中完全训练的模型保持一致。本文在LaSOT数据集上进行了消融实验,报告了各种算法的成功率结果以及模型的参数量(Parameters,Params)、浮点运算数(floating point operations,FLOPs)和跟踪速度(frames per second,FPS)。具体消融结果如表1所示。

表1 LaSOT数据集上的消融实验Table 1 Ablation study on LaSOT dataset
其中,基线(Baseline)为STARK-S50模型。模型一(Model1)表示移除解码器结构,直接使用编码器信息进行边框预测的模型。从模型一和基线的对比来看,基线中编码器学习到的信息由于只起到了空间注意力的作用,因此移除整个解码器对整体效果也不会带来明显的影响,反而节约了参数和计算量带来了速度的提升。从侧面反映出来基线结构中对解码器信息利用不够充分,这也启发了本文的改进。
模型二(Model2)表示使用本文改进的编码器边框预测头的模型。通过额外引入深度互相关操作帮助找到搜索区域中与目标高度相关的位置来得到更具判别性的搜索区域特征,在大规模跟踪数据集LaSOT上获得一定的性能提升,证明了这种模型结构改进的有效性。此外,该改进带来的额外参数和计算量仅约为1.2×106和4×108,跟踪速度达50 FPS,不影响算法实时性。
模型三(Model3)表示在模型二的基础上加入双流信息预测与决策层面融合的模型。与模型二相比,由于只增加了一个MLP和两个线性层,因此只增加了1.0×105参数和1.0×108计算量。这样的改动取得了0.5个百分点的成功率提升,说明融合后预测边界框与真实边界框的交并比获得提升,证明该方法能提高边界框预测的准确性,同时也反映出融合双流信息的必要性。相比只使用编码器的单信息进行预测,双流信息预测可以融合解码器中目标特定的判别信息,减轻干扰物的影响,进一步提高模型鲁棒性。从实时性来看,算法的跟踪速度保持在48 FPS,还是超过实时性要求(>20 FPS),并不影响其实际应用。
模型四(Model4)表示只把基线模型中主干网络ResNet50替换成Swin-T的模型。可以发现获得了1.4个百分点的成功率结果提升,证明基于注意力机制的视觉Transformer作为主干网络能够为目标跟踪提供更加鲁棒的特征表示。这一改进由于只影响了主干网络提取特征部分,因此对跟踪速度的影响也比较小。
模型五(Model5)表示同时使用Swin-T主干网络、改进的编码器边框预测头和双流信息预测与决策融合的最终模型。总体来说,通过4.7×106参数和1.3×109计算量获得了在大规模跟踪数据集LaSOT上2.2%的绝对性能提升。通过端到端的跟踪,整体跟踪速度仍能达到42 FPS,能够满足实时性的要求。
2.4 不同融合方法比较
对于编码器和解码器的双流信息预测结果,本文在决策层面使用了决策层面的自适应加权融合方法。为了进一步证明本文方法的有效性,本文在上述模型二的基础上,将几种融合方法进行实验比较,在LaSOT数据集上的成功率结果如图4所示。

图4 不同融合方法比较结果Fig.4 Comparing results of different fusion methods
其中,方法一为ATOM[27]算法中对多个边界框结果取平均的融合方式,即分别用0.5的固定权重对双流信息预测结果进行融合。方法二在方法一基础上参考目标检测领域的方法,先计算两个边界框的交并比,大于阈值0.8的情况下再取平均,否则采用编码器的预测结果。此举通过人工设计避免双流信息中低质量框对融合结果的影响。方法三与方法二不同的是,否则采用解码器的预测结果。
从图中结果可以看出,直接取平均这种固定权重的融合方式效果相比未融合的上述模型二提升0.2%,说明直接融合双流信息能够带来一定提升但是因为不同的跟踪环境下两者预测结果会有不同的表现,固定权重难以适应这种变化。
相比之下,方法二有所提升,这是由于通过交并比约束避免了一些较低质量的预测结果的干扰。方法三效果比方法一略高,但是比方法二略差,说明编码器流信息在一定程度上比解码器流信息更具有判别力,也反映出双流信息需要分配不同的融合权重。
本文方法取得了最好的结果,这是因为本文方法的融合权重是通过线性层自适应学习得到的,在不同跟踪场景下会根据双流信息的重要性和预测质量为其赋予不同的融合权重。当需要依赖编码器的全局信息获得更加准确的预测结果时,会为其分配更高的权重;当需要依赖解码器的判别信息时,则为解码器预测结果分配更高的权重。这样的融合方式可以使得最终融合结果更适应具体情况的变化,相比固定权重的方式更加合理,也更具有鲁棒性。
2.5 不同算法的结果比较
为了验证本文所提出算法的有效性,在LaSOT和TrackingNet两个大型数据集上与当前主流的多种目标跟踪算法进行实验结果比较。涉及的算法有SiamFC[7]、SiamRPN++[9]、Ocean[10]、TrSiam[12]、TrDiMP[12]、TrTr[13]、STARK[14]、ATOM[27]、MDNet[28]、SiamFC++[29]和DiMP[30]。LaSOT数据集上的结果如图5所示。

图5 LaSOT数据集上的结果Fig.5 Results on LaSOT dataset
可以看到本文算法(Ours)达到了最佳的67.4%的成功率和72.4%的精度,相比STARK-S50分别取得了1.6和2.7个百分点的提升,也超越了TrSiam和TrDiMP等基于Transformer的跟踪算法。除图中给出的结果外,本文算法在LaSOT上的归一化精度NP可以达到77.4%。证明本文提出的双流信息预测和决策融合能够有效利用来自Transformer编码器-解码器的双流信息并进行融合互补,使得算法具有很好的目标尺度估计能力。在目标旋转、形变和遮挡等各种困难场景下仍然能够获得较为准确的边界框预测结果,跟踪精度相比STARK-S50具有明显的提升。也证明视觉Transformer作为孪生主干网络能够通过注意力机制建模全局依赖关系,为跟踪任务提供优秀的特征表示。
表2给出了在TrackingNet数据集上的实验结果,其中“—”表示原始论文中未给出相关结果。从表中可以发现,本文算法分别取得了80.9%、77.8%和85.6%的成功率、精度和归一化精度结果。与STARK-S50相比,在各项指标上均有一定程度的提升,并且优于SiamRPN++、Ocean和DiMP等主流跟踪算法。得益于特征层面的主干网络改进,信息层面的充分利用和决策层面的有效融合,在如此大规模野外跟踪数据集上取得了优秀的成果,证明了具有强大的跟踪性能及泛化性。

表2 TrackingNet数据集上的比较实验Table 2 Comparative experiments on TrackingNet dataset
表3中给出了在UAV123和NFS数据集上不同算法的成功率曲线下面积AUC的比较结果。可以看出,本文算法分别取得了68.6%和66.0%的结果,均比基线STARK-S50取得提升。在UAV123上取得了最好的结果,证明了算法的有效性。在NFS上仅次于TrDiMP,相比基线已经获得了1.7%的提升。不过本文算法的跟踪速度可达42 FPS,超过TrDiMP的26 FPS,具有足够的实际应用潜力。

表3 UAV123和NFS数据集上的成功率Table 3 Success rate on UAV123 and NFS dataset%
2.6 跟踪结果可视化
为了进一步展示出不同算法在目标发生遮挡、干扰、形变和旋转等复杂情况下的实际跟踪效果。本文从大型真实场景跟踪数据集LaSOT上选取视频序列(飞机、鸟和自行车)进行跟踪结果的可视化,具体对比结果如图6所示。其中红色表示本文算法的跟踪结果,绿色和蓝色则分别表示DiMP和STARK算法的跟踪结果。

图6 跟踪结果对比Fig.6 Comparison of tracking results
从图6中可以看到在尺度变化、干扰、形变和遮挡等复杂跟踪场景下,本文算法依然能够获得准确的目标状态估计,得到高质量的跟踪结果,而DiMP和STARK算法则容易丢失目标或者尺度估计不够准确。
具体来看,在第一行飞机视频序列中目标的尺度发生了较大变化,DiMP算法依靠判别信息能够定位到目标,但是尺度估计还不够准确。STARK算法忽视了解码器流信息,预测结果偏大。而本文算法通过双流信息预测和决策融合,准确估计目标整体尺度,获得更优的跟踪结果。
在第二行鸟视频序列中,由于干扰物的存在导致DiMP和STARK算法将干扰物的部分也当作目标,产生误判。即使DiMP算法采用了在线更新策略,但是在其更新的间隔仍然容易被干扰而导致跟踪漂移。而本文算法通过自注意力机制有效捕获目标全局依赖关系,精确定位目标,避免了干扰物的影响。
在第三行自行车视频序列中,目标发生形变和遮挡的情况下本文算法依然能够准确跟踪,进一步体现出本文所提方法的有效性。
2.7 收敛性分析
为了进一步体现出本文使用的多监督策略的有效性,本文对所提跟踪算法的收敛性进行了分析。算法在训练过程中的L1损失和GIoU损失结果如图7所示,截取了其中300至500个周期部分。
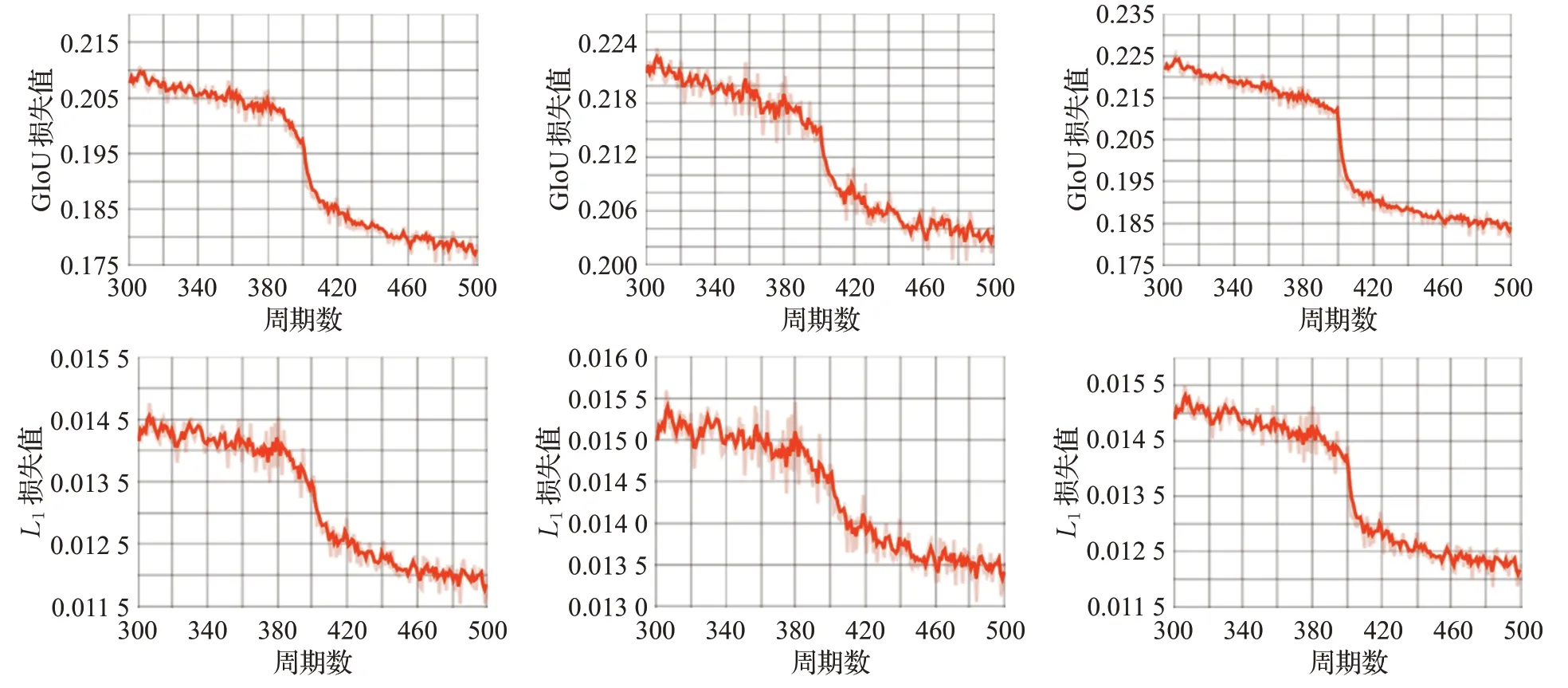
图7 损失函数曲线Fig.7 Loss function curve
其中第一行分别为最终融合后的边界框BF、编码器预测框BE和解码器预测框BD的GIoU损失,第二行分别为三者的L1损失。可以看到最终融合后的边界框,无论是从衡量交并比的GIoU损失还是衡量中心位置误差的L1损失来看,都成功收敛,并且取得了比融合前两部分更小的损失值。这主要得益于本文使用的多监督策略,将三个预测框共同进行监督训练,保证三者均成功收敛,并且获得了更优的融合结果。此举可以避免只对最终融合结果进行约束而导致编码器和解码器预测框不够准确的问题,具有明显的优势。
3 结论
本文提出一种基于视觉Transformer的双流目标跟踪算法。对现有基于Transformer跟踪算法进行改进,通过引入基于注意力机制的视觉Transformer作为孪生主干网络提高特征抽取能力。设计双流信息预测和决策层面的加权融合策略,简单有效地利用编码器-解码器结构的双流信息,以少量的计算成本获得了具有竞争力的大规模跟踪性能提升。并且在端到端的跟踪情况下,能够达到42 FPS的跟踪速度,具有巨大的潜力。
猜你喜欢
现代经济信息(2022年22期)2022-11-13
网络安全与数据管理(2022年1期)2022-08-29
中小学校长(2022年7期)2022-08-19
作文大王·低年级(2022年2期)2022-02-28
小学生必读(低年级版)(2021年10期)2022-01-18
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
家庭影院技术(2019年8期)2019-12-04
