
基于地形特征融合的卷积神经网络滑坡识别
2022-06-27 09:13蔡浩杰韩海辉张雨莲王立社
地球科学与环境学报 2022年3期
蔡浩杰,韩海辉,张雨莲,王立社
(1. 中国地质调查局西安地质调查中心,陕西 西安 710054; 2. 中国遥感应用协会黄河流域高质量发展遥感分会,陕西 西安 710054)
0 引 言
滑坡是在地球引力作用下,岩石、泥土或岩屑沿着斜坡滑移的一种地质灾害。滑坡发生时,会裹挟大量的岩石、泥沙等边坡物质倾泄而下,对滑坡带的地形地貌造成巨大的破坏,并塑造出新的滑坡地貌。滑坡地质灾害经常造成环境破坏和人员伤亡,灾区人民群众的生命财产安全受到严重威胁。中国山地众多,占国土总面积近70%,且强降雨多,地震活动频繁,面临众多的滑坡、泥石流等地质灾害。自然资源部发布的2021年全国地质灾害灾情显示,2021年全国共发生地质灾害4 772起,其中滑坡2 335起,占全国地质灾害总数的48.93%。滑坡发生后的地点、体量、范围等几何、属性信息是滑坡灾害应急反应、灾害损失评估和滑坡易发性分析、滑坡变化监测、滑坡治理等研究的重要资料。了解滑坡的成因和控制因素,对滑坡的空间和长时间序列变化趋势做出反应,识别已有的滑坡,建立详细的滑坡编录,对滑坡模型的开发和评价具有重要价值。
传统的滑坡调查与制图方法是以现场调查为主,属于研究区地貌分析的范畴。这种调查方法在山区难以实施,效率极低,而且调查成果不够全面和准确。随着对地观测技术的快速发展,灾害应急预警和区域测绘应用已与遥感相结合。遥感可以快速获取宏观的地表信息,遥感影像的时间、光谱和空间分辨率的提高为遥感应用提供了丰富的数据库。利用遥感技术对滑坡进行监测治理具有经济快捷的优点,遥感技术已被广泛应用于滑坡调查制图、监测和易发性分析。将遥感技术用于滑坡识别经历了目视解译和计算机解译两大阶段。目视解译是从遥感影像中提取滑坡信息最原始的方法,在滑坡、泥石流等地质灾害中取得了良好的效果。然而目视解译过于依赖解译人员的经验和知识能力,工作量大,工作周期长,信息实时更新慢,难以应急,结果有时也不可靠。随着数字图像处理技术和人工智能的发展,许多计算机解译方法结合遥感技术被用于地球信息提取任务。机器学习方法是一种用于数据分析的自动建模方法,可以学习数据中存在的基本关系,从而构建分析模型,并通过迭代学习过程产生准确的结果。目前,应用于滑坡易发性分析、识别和监测的机器学习方法有支持向量机、随机森林、旋转森林和集成学习。这些机器学习方法都需要设计解释逻辑或者提取图像中的特征,导致算法设计复杂。
近年来,随着计算机运算能力提升,深度学习的发展迎来了新的高峰。深度学习在图像分类、目标检测、自然语言处理等应用领域取得了巨大的成就。受这些成功应用的启发,基于像素和对象的深度学习方法被用于滑坡识别和易发性分析。卷积神经网络(Convolutional Neural Networks,CNN)是深度学习的代表算法之一。与传统方法相比,卷积神经网络的多层前馈神经网络结构可以自动获取图像的有效特征表示,能够自动学习滑坡的特征却不需要额外的特征工程。卷积神经网络在自然图像分类、识别、定位等任务中取得了巨大的突破,但在滑坡识别与制图领域中,卷积神经网络的应用案例不多。主要原因是:卷积神经网络的结构通常比较复杂,复杂的网络结构意味着更多的训练参数,许多在自然图像分类中表现优秀的模型参数达到千万级甚至亿级,复杂的网络结构对网络部署和训练平台性能要求高,而且如果要取得较好的效果,就需要大量的训练样本,否则网络只会在小部分数据集上学习,容易造成网络过拟合,泛化能力差;滑坡在地质灾害中属于小样本,在某一区域范围内,相比其他地物背景(如植被、水体、建筑等)相对较少;在实际情况中,滑坡大多数分布在山地中,存在样本难以获取的问题。即使利用遥感影像获取样本,但受成像技术和复杂地物的影响,仍然有许多滑坡在光学影像上无法辨认。如果不能获得足够的训练样本数据,卷积神经网络在滑坡识别上的能力反而会降低。
通过分析卷积神经网络在滑坡识别上面临的问题,本文设计了一种网络结构简单,层数较少的轻量级卷积神经网络。简化网络结构后,为了避免性能降低,考虑在数据方面进行改进来保证设计的卷积神经网络能够学习到足够多的滑坡特征。滑坡发生时会改变地表形态,这可以作为辅助特征来帮助识别滑坡。数字高程模型(Digital Elevation Model,DEM)特别适用于反映与滑坡有关的地表形态。因此,本文引入了高程、坡度、坡向、平面曲率、剖面曲率和地形起伏度6个地形因子;叠加地形因子后,设计的网络可同时学习滑坡在遥感影像和地形因子上的空间和光谱特征并进行融合,然后利用融合特征训练得到最优滑坡识别模型。
1 研究区概况与数据处理
1.1 研究区概况
本文选择以四川省汶川县银杏乡为主要研究区。2008年5月12日,四川省汶川县发生8.0级地震。地震波及范围极广,导致大量的人员伤亡,并造成一系列次生灾害。地震区位于四川西部的山地区域,形成了大量的崩塌、滑坡和泥石流地质灾害。研究区地处汶川县南部(图1),东与都江堰市交界,南与映秀镇相邻,行政区面积约为282.70 km,地处深山峡谷地带,境内山高坡陡,是震后滑坡最多的地区。通过解译和资料调查,滑坡数量约为178个,滑坡面积约22.36 km。

图1 四川省汶川县银杏乡位置Fig.1 Location of Yinxing Town in Wenchuan County of Sichuan Province
1.2 数据来源
本文所使用的数据主要有Landsat OLI遥感影像、ASTER GDEM数字高程模型、GIS数据库和研究区滑坡编录数据。Landsat OLI遥感影像用于提取滑坡,成像时间为2013年12月;对比影像与滑坡编录数据和Google Earth历史数据,2013年研究区的滑坡有少量被植被完全覆盖,大多数被植被部分或没有覆盖。ASTER GDEM数字高程模型用于生成坡度、坡向、地形起伏度、平面曲率、剖面曲率地形因子。GIS数据库主要是研究区各种自然条件,便于全面了解研究区的自然地理环境。遥感影像和地形因子的分辨率都为30 m,所有因子都采取连续变量。
1.3 样本生成
样本制作流程为样本标签制作和网络训练数据集制作。首先,将滑坡编录数据矢量化并添加属性数据;然后将滑坡矢量数据和研究区矢量合并,给研究区的滑坡和非滑坡数据添加标签;最后将处理好的矢量转换为空间分辨率为30 m的栅格图,栅格图里的像元值代表的是地物类别。栅格图共有3种类别:研究区外为背景,不属于研究对象;研究区内包含滑坡和非滑坡地物两种类别,用作训练数据的标签和模型结果评价。
训练数据由遥感影像和地形因子组成。利用收集到的数据提取出地形因子之后,首先进行预处理;预处理步骤为异常值校正、标准化和重采样。有些地形因子在研究区外的栅格会有超出正常范围的像元值,对后续的标准化计算产生影响。由于提取的因子类型不同,其栅格像元值变化范围大,不利于网络学习,所以在异常值校正之后,需要对高程、坡度、坡向、平面曲率、剖面曲率和地形起伏度6个地形因子进行标准化,使所有地形因子的均值为0,标准差为1,具有相同的分布。标准化采用的是零均值标准化,也被称为Z-score规范化。其计算公式为

(1)
式中:′为标准化后的数据;为原始数据;为样本平均值;为样本标准差。
标准化之后,由于和标签的分辨率不一致,所以需要重采样成和标签栅格同样的行列数,以确保每个像元都能够一一对应。由于滑坡的数量、规模在地形上的分布是不一致的,所以可以利用卷积神经网络学习这种差异,将这种差异放大,让分类器有评判的依据。将所有地形因子和遥感影像进行叠加,让卷积神经网络同时学习遥感影像和地形因子的特征,地形因子以这种方式参与到滑坡提取中。遥感影像上叠加地形因子后会生成一个××三维影像,、和分别是数据的高度、宽度和通道。在本研究中,进行过重采样的遥感影像和地形因子的高度与宽度分别为882和659,通道数为13。本研究以像元为基本单元,每个像元为一个样本,除去背景像元,研究区共有314 107个像元,也就是共有314 107个样本。其中,滑坡像元共有24 812个,占7.9%;非滑坡像元共有289 295个,占92.1%。制作样本时,采取的是以每个像元为中心,向四周扩充多个像元的正方形窗口。对于研究区边界上的像元,采取向外填充的方式使得边界像元也能向外扩充,填充方式为镜像对称方式。样本制作方式如图2所示。如果向外扩展的像元个数=2,则研究区整体向外扩充4行4列,每个样本高度和宽度为2+1,即为5,通道数保持不变,也就是说,生成样本高度和宽度都是5,通道数为13。将制作好的全部样本按3∶7的比例划分为训练样本和测试样本;样本选择方法为利用代码对全图进行简单随机抽样;模型训练完成后,计算整个研究区的滑坡制图精度。

r为向外扩展的像元个数;c为遥感影像的通道数图2 样本制作示意图Fig.2 Schematic View of Sample Making
为了验证引入的6个地形因子特征与滑坡之间的关系,在建模前分析了所有地形因子对滑坡的重要性,利用信息增益比(Information Gain Ration,IGR)对训练集进行了分析。某地形因子信息增益比越高,则该地形因子对滑坡发生的影响越大;某地形因子信息增益比为0,则该地形因子对滑坡的发生没有贡献。所选取的6个地形因子的信息增益比均大于0(图3),说明这些地形因子对研究区滑坡的发生都有影响。此外,本文还计算了6个地形因子的Pearson相关系数(图4)。从图4可以看出,虽然坡度和地形起伏度有较强的相关性,但不是完全相关,二者存在着信息差异,只有当Pearson相关系数绝对值等于1,即达到完全相关的情况下才会剔除其中一个地形因子。综合信息增益比和Pearson相关系数,上述6个地形因子全部保留。

图3 地形因子的信息增益比直方图Fig.3 Histogram of IGR of Terrain Factors

图4 相关系数热图Fig.4 Heatmap of Correlation Coefficient
2 分析方法
2.1 卷积神经网络
利用卷积神经网络进行滑坡提取的原理如下:卷积神经网络迭代地学习输入网络中包含滑坡的地物场景,并与给定的场景标签做相似性对比,当误差小于预先设定的某个阈值时即可停止学习,完成模型训练,然后利用训练好的模型,在相似的场景中预测滑坡发生的区域。卷积神经网络的核心模块为输入层、卷积层、激活层、池化层和输出层。
输入层是卷积神经网络输入样本的入口,可以有多个,也可以有不同的维度。卷积层是卷积神经网络的核心部分,负责学习输入样本的特征。卷积层的学习能力是通过卷积核与输入的卷积运算来实现的。这里的卷积核和空间域滤波器的作用相似,只不过特定的滤波器中的参数是已经设置好的,而卷积核的参数是通过网络迭代学习而来的。卷积核在输入的图像或者特征矢量上进行滑动,然后卷积核与其对应的输入区域进行卷积运算,得到一个特征值。卷积运算公式为
()=(()⊗(-1)+())
(2)
式中:()为第层的输出;(·)为激活函数;为权重矩阵;为偏置矩阵;⊗为矩阵乘法。
激活层作用是激活卷积运算得到的特征,通常位于卷积层后面,运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层神经网络。激活函数可以加入非线性因素,把激活的特征保留下来。目前卷积神经网络中常用的激活函数为修正线性单元(Rectified Linear Unit,ReLU),修正线性单元起源于神经科学研究。修正线性单元是分段线性函数,特征值为负的会被抑制为0,只激活特征值为正的神经元,这种操作被称为单侧抑制。单侧抑制原理与人类大脑类似,不同的神经元有不同的功能分区,当训练一个深度网络模型的时候,与目标有关联的特征并不多,因此,通过修正线性单元实现稀疏表达后的特征更加符合大脑神经元对特征的处理。池化层通常会在一个卷积模块后面,具有两个作用:一是降采样,用来减少特征层的大小,降低网络参数,防止过拟合;另一个是提取特征。其计算方式和卷积运算类似,利用池化窗口在特征图上进行滑动,然后计算这个窗口中的均值或最大值,计算结果代表这个区域的特征值。还有一种池化方式称为全局池化,采取计算整个特征图的平均值或最大值来代表整个特征图的特征,可以将三维特征图降低到一维,输出特征矢量。将提取好的特征图输入到网络最后的激活函数中,可得到一个激活值或概率值,最后的输出是输入样本属于每个类别的概率。卷积神经网络可以有多个输出,可以输出任意的中间特征层,用来分析各个卷积层的作用。
2.2 特征融合网络
本文设计的轻量级网络被称为特征融合卷积神经网络(Feature Fusion Convolutional Neural Network,FF-CNN),网络结构是在LeNet-5网络的基础上改进而来(图5),减少了一个卷积层,增加了一个光谱特征提取通道。特征融合卷积神经网络的网络结构包括两个分支。第一个分支提取空间特征,共有5层:第一层输入样本的高度和宽度都为23,通道数为13;接下来两层都为卷积层,主要提取输入样本的空间特征;第四层为池化层,可以提取特征和降低模型参数;最后一层是将三维特征展开成一维的特征层,便于特征融合。第二个分支总体结构和第一个分支相似,输入数据是长度为13的像元光谱向量,对光谱信息进行一维卷积,来获得像元的光谱特征。最后将两种特征进行连接,实现特征融合,将融合特征输入到分类器中,得到该像元属于每个类别的概率,取概率值最大的类别作为该像元的预测值。将预测的类别和真实标签对比,计算损失函数,不断调整参数,最终得到最佳分类模型。图5中,每层的数字代表对应层的大小,第一层数字代表输入样本的大小,其余层数字代表对应的特征层大小。特征融合卷积神经网络一共有4个卷积层,两个池化层,网络训练参数为0.34 M,而目前应用最广泛的分类网络ResNet-50共有训练参数约25.56 M,语义分割网络U-Net有7.85 M,这两种网络的训练参数都是百万级别的,且网络结构非常复杂。在滑坡识别应用中,由于缺乏足够的样本,所以这种复杂的网络结构很容易造成网络过拟合,而且遥感影像图幅较大,这样会造成网络迭代时间过长,而特征融合卷积神经网络就很好地解决了这两个问题。特征融合卷积神经网络中卷积核的大小、特征层的数量等超参数一方面参考了LeNet-5等网络的通用设置,另一方面根据模型在测试集上的表现进行调试。最终,特征融合卷积神经网络的学习率为0.000 1,优化器为Adam,损失函数为交叉熵,批次大小为50,迭代次数为30,提取空间特征的卷积核大小为3×3,两个卷积层的特征数为256和512,提取光谱特征的卷积核大小为1×3,两个卷积层的特征数为64和128。

图5 FF-CNN模型结构Fig.5 Structure of FF-CNN Model
3 结果分析
为了验证本文引入的地形因子和特征融合的有效性,设置了不同的对比实验。实验平台为个人计算机,配置为Intel i5-9300 CPU,8 GB RAM,NVIDIA GTX1650 4 GB。所有网络源码都是基于TensorFlow深度学习框架编写的。
3.1 特征融合验证
为了验证添加的光谱特征提取通道是否提高了模型的性能,共设置了3组实验,即使用地形因子和遥感影像数据,分别输入本文提出的特征融合卷积神经网络(FF-CNN)、只有空间特征提取通道的二维卷积神经网络(2-D-CNN)和只有光谱特征提取通道的一维卷积神经网络(1-D-CNN)。实验结果如图6所示。
图6(a)是FF-CNN模型提取的结果,总体来说大部分滑坡区域都被提取出来了,只遗漏了很少的滑坡区域,其识别结果与实际滑坡的范围最接近,滑坡区域内无噪点,一些比较靠近的滑坡也能准确地划分出边界;整个滑坡图识别完整,不同尺度的滑坡都能识别出来,将非滑坡识别为滑坡像元情况非常少。图6(b)是2-D-CNN模型提取的结果,与FF-CNN模型的提取结果相比,目视上整体识别效果差异不大,大多数滑坡都能够识别到;一些滑坡内部存在漏识别的现象,识别完整度不及FF-CNN模型。图6(c)为1-D-CNN模型的提取结果,整体上也能够识别出较多的滑坡,但是识别出的滑坡完整度不及FF-CNN模型和2-D-CNN模型;一些滑坡内部只识别出来部分像元,滑坡的召回率非常低,错误识别率太高,有许多非滑坡区域被分类为滑坡区域。

图6 3种模型滑坡识别遥感影像 Fig.6 Remote Sensing Images of Landslides Recognized by Three Models
对上述3种模型进行滑坡识别定量评价,评价指标选取常用的召回率()、准确率()、F1分数()和平均交并比(MIoU)。F1分数是准确率和召回率的调和平均值,F1分数越高,整体的分类结果就越好。F1分数计算公式为

(3)
MIoU是由交并比(IoU)计算而来,交并比是预测区域和实际区域交集除以预测区域和实际区域的并集,然后计算所有类别交并比的平均数,即可得到MIoU值。MIoU值越高,整体分类结果越好。F1分数和MIoU值反映的都是整体结果,因此,在二分类任务中较为常用,也最科学。评价结果如表1所示。FF-CNN模型的召回率最高,说明被识别出来的滑坡最多;2-D-CNN模型准确率是最高的,说明被正确识别出来的滑坡最多。FF-CNN模型的F1分数和MIoU值都是最高的,整体效果是这3个模型中最好的。相较于2-D-CNN模型,FF-CNN模型F1分数和MIoU值分别提升0.020 2和0.014 4。实验结果表明,增加的光谱特征是有效的。
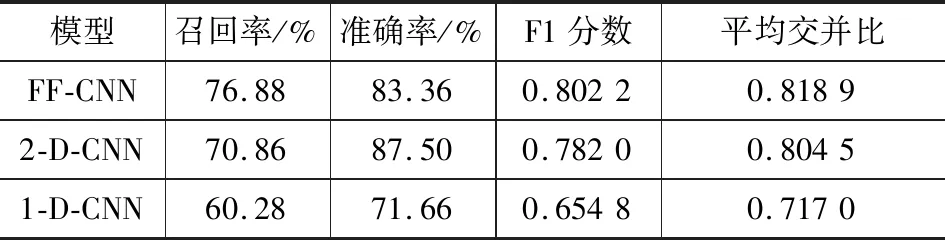
表1 3种模型滑坡识别评价结果Table 1 Evaluation Results of Landslides Recognized by Three Models
3.2 地形因子验证
为了验证添加的地形因子是否提高了模型的性能,共设置了3组实验,即将遥感影像、地形因子、遥感影像+地形因子输入到FF-CNN模型中。3种输入样本方式的FF-CNN模型滑坡提取结果如图7所示。图7(c)是只使用地形因子的提取结果。总体上观察,许多滑坡没有被提取出来,尤其是山谷里两侧的滑坡,没有一个滑坡区域被完全提取出来,且在实际滑坡区域内,提取的滑坡像元互相分离,没有连成一片,噪声现象严重,滑坡成片区域无法准确区分出边界。图7(b)展示了利用遥感影像的提取结果,与只使用地形因子的提取结果相比,模型的滑坡识别能力有了较大的提高,主要表现在滑坡识别得比较全面,大多数滑坡都能够识别出。图7(a)是叠加遥感影像和地形因子的提取结果。识别结果与实际滑坡范围最接近,识别的滑坡图斑没有空洞,边界几乎完全匹配。

图7 3种输入样本方式下的FF-CNN模型滑坡识别结果Fig.7 Landslides Recognized by FF-CNN Model with Three Types of Input Data Samples
上述3种输入样本方式的FF-CNN模型滑坡识别定量评价结果如表2所示。从表2可以看出:添加遥感影像+地形因子之后的FF-CNN模型4个评价指标都是最高的,F1分数和MIoU值相较于利用遥感影像的模型,分别提高了0.066 4和0.048 2;从召回率和准确率也可以反映出添加遥感影像+地形因子之后的FF-CNN模型,不仅识别的滑坡最完整,识别准确率也最高。

表2 3种输入样本方式下的FF-CNN模型滑坡识别评价结果Table 2 Evaluation Results of Landslides Recognized by FF-CNN Model with Three Types of Input Data Samples
3.3 方法讨论
在深度学习中,最常用的特征融合方式为按点逐位相加(Point-wise Addition)和向量连接(Concatenate)。本实验中所采用的融合方式为向量连接,原因是这两个通道提取的特征是两种不同类别的特征,如果通过按点逐位相加的方式,会改变原来特征。为了验证特征融合方式对网络模型性能的影响,设置了对比实验。按点逐位相加要求两种特征向量必须一一对应,因此,在原来网络的每个通道后面多增加了一个全连接层,将两种不同长度的特征向量都映射为相同长度。增加全连接层后,精度通常会有所上升,但也会带入大量的参数。两种特征融合方式的定量评价结果如表3所示。从评价结果可知,向量连接融合方式的MIoU值和F1分数都高于按点逐位相加融合方式,向量连接融合方式是较好的。

表3 两种特征融合方式评价结果Table 3 Evaluation Results of Two Feature Fusion Methods
机器学习方法在滑坡识别上具有广泛的应用。
实验选取了3种典型的机器学习方法,分别为支持向量机(Support Vector Machine,SVM)、随机森林(Random Forest,RF)和梯度提升决策树(Gradient Boosting Decision Tree,GBDT),训练样本的比例和FF-CNN模型保持一致。经过多次调试,支持向量机惩罚参数设置为4.0,核函数为径向基函数(Radial Basis Function,RBF)。随机森林的决策树为100个,最大深度为50。梯度提升决策树的决策数为100个,最大深度为20。评价指标选用F1分数和MIoU值,对比结果如表4所示。从定量评价结果来看,在只使用较少的训练样本下,支持向量机、随机森林和梯度提升决策树的性能远不及FF-CNN模型,这是因为3种机器学习方法在小样本中造成了过拟合。这3种传统机器学习方法中,表现最好的是随机森林,MIoU值和F1分数分别为0.713 0和0.645 3,但仍小于FF-CNN模型对应的指标值。

表4 FF-CNN模型与传统机器学习方法对比结果Table 4 Comparison of FF-CNN Model and Traditional Machine Learning Methods
3.4 适用性讨论
为了验证FF-CNN模型在其他类型滑坡上的效果,将FF-CNN、2-D-CNN、1-D-CNN模型应用到湖北省三峡库区主要滑坡带(图8)。所选区域面积约396 km,共有202个不同规模的滑坡,主要分布在长江及其支流沿岸,标记的滑坡主要为历史滑坡。遥感影像选取资源三号01卫星2013年4月的成像,影像上滑坡大多数已经被植被和其他地物覆盖。地形因子类型、训练样本和测试样本比例、对比实验设置与四川省汶川县银杏乡实验一致。5组对比实验滑坡制图结果如图9所示,定量评价结果如表5所示。

图8 湖北省三峡库区滑坡分布Fig.8 Distribution Map of Landslides in Three Gorges Reservoir Area of Hubei Province

表5 3种输入样本方式下的3种模型滑坡识别评价结果Table 5 Evaluation Results of Landslides Recognized by Three Models with Three Types of Input Data Samples
从最终的制图效果可以看出:融合地形因子和遥感影像特征的FF-CNN模型滑坡识别效果最好,不同规模的滑坡都可以识别出来,滑坡边界准确;2-D-CNN模型也能识别出大部分滑坡,但部分滑坡识别不完整,小型滑坡无法识别出来;1-D-CNN模型识别效果最差,几乎没有正确识别出任何滑坡;只利用遥感影像的FF-CNN模型滑坡识别效果也较差,大部分滑坡无法识别出来,而只使用地形因子的FF-CNN模型却可以识别出更多的滑坡,由此可见在滑坡有覆盖物的情况下,地形因子可以起到积极的作用(图9)。

图9 3种输入样本方式下的3种模型滑坡识别结果 Fig.9 Landslides Recognized by Three Models with Three Types of Input Data Samples
从定量评价结果可以看出:FF-CNN模型在湖北省三峡库区滑坡识别的召回率、准确率、F1分数和MIoU值都是最高的,评价结果基本和四川省汶川县银杏乡实验一致。定性和定量评价结果都表明,融合地形因子和遥感影像特征的FF-CNN模型在不同类型、不同地区的滑坡识别上都可以取得较好的效果,尤其在提取被植被或者其他地物覆盖的滑坡上具有明显的优势。
利用FF-CNN模型在四川省汶川县银杏乡和湖北省三峡库区都取得了较好的效果,有必要进一步通过实验来验证训练好的模型在不同空间域的迁移能力。本文选取四川省都江堰市虹口乡进行实验,遥感影像和四川省汶川县银杏乡为同一时期,大多数滑坡无植被覆盖,只有少量被植被所覆盖。实验将在银杏乡训练好的FF-CNN模型直接应用到未调查过的四川省都江堰市虹口乡来提取滑坡,滑坡提取结果如图10所示。从整体提取结果来看,FF-CNN模型在四川省都江堰市虹口乡能够识别出绝大多数的滑坡体,目视对比Landsat遥感影像的真实滑坡范围,滑坡区域位置基本能够准确定位,能够较完整地识别出大部分滑坡范围。从图10(a)可以看出,四川省都江堰市虹口乡的滑坡主要分布在北部和中部山区,南部较少。从图10(b)、(c)可以看出,还有许多较小的滑坡没有识别出来,小型滑坡的漏识别率较高。结合四川省都江堰市虹口乡Google Earth历史影像,在Landsat遥感影像上共解译出198个滑坡,模型识别结果准确定位出位置的滑坡数量有169个,可以识别出大部分滑坡发生位置。定量和定性评价结果表明,将FF-CNN模型迁移应用到具有相同的滑坡成灾机理条件的区域,其识别结果可以满足应急救灾的滑坡定位需求。

图10 基于FF-CNN模型的四川省都江堰市虹口乡滑坡识别结果Fig.10 Landslides Recognized by FF-CNN Model in Hongkou Town of Dujiangyan City, Sichuan Province
4 结 语
(1)相关性和重要性分析实验结果表明,高程、坡向、坡度、地形起伏度、平面曲率和剖面曲率6个地形因子对滑坡的发生都有影响。其中,剖面曲率和平面曲率的影响最大,坡向、坡度、高程和地形起伏度的影响依次降低。各个地形因子之间都存在着信息差异,结合对比实验结果,本研究提出在遥感影像上叠加地形因子构建滑坡训练样本的方法,可以增强卷积神经网络的滑坡识别能力。
(2)本文设计的轻量级特征融合卷积神经网络(FF-CNN)可以提取滑坡样本的空间与光谱特征,并实现空间与光谱特征融合、光学影像与地形因子特征融合。实验结果表明,这两种特征融合方式在较少的训练样本情况下可以有效提升卷积神经网络的滑坡识别能力,可为卷积神经网络的滑坡识别研究提供新的思路。
西安地质调查中心组建六十周年的重要时刻,也是我正式就职于西安地质调查中心的第一年,谨以此文祝贺!六十年来,西安地质调查中心创造了许多辉煌的业绩,在矿产、能源、生态保护、城市群规划等方面做到很好的支撑作用,为国家实现“两个一百年”奋斗目标贡献了力量!很高兴加入西安地质调查中心这个大家庭,祝愿西安地质调查中心在新时代地质调查事业和科技创新中取得更大的成就!
猜你喜欢
农业工程学报(2022年12期)2022-09-09
地球科学与环境学报(2022年4期)2022-08-25
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
科海故事博览·中旬刊(2022年4期)2022-04-23
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
软件(2017年6期)2017-09-23
中国新通信(2017年9期)2017-05-27
