
面向跨架构恶意软件的函数相似性检测和衍变分析
2022-06-29 03:43王晓磊马琳茹施江勇宋焱淼
陆军工程大学学报 2022年3期
王晓磊, 杨 林, 马琳茹, 穆 源, 施江勇, 宋焱淼
(1.61660部队,北京 100093;2.军事科学院 系统工程研究院,北京 100141;3.国防科技大学 计算机学院,湖南 长沙 410073)
众所周知,恶意软件一直在衍变以增加新功能、提升隐蔽性,从而产生一系列不同版本的样本,这些样本在功能上并非都是独一无二的。例如,同一个物联网恶意软件样本往往针对不同体系架构(x86,mips,arm等)编译出不同的可执行文件[1-2]。
恶意软件衍变分析主要研究恶意样本之间的演化关联关系,对于恶意软件分析和取证具有重要的应用价值。给定一个恶意软件的样本集合,衍变分析要解决的一个重要问题是获取这些样本之间的偏序关系,这里的偏序关系是指两个先后出现的样本之间存在继承或演化关系。基于衍变分析,安全人员可以了解恶意软件的发展趋势,判断不同的恶意代码是否源自同一套恶意代码或是否由同一个作者、团队编写[3]。同时,针对某一特定恶意软件家族的衍变分析还可以提取出此家族的核心特征(基因),便于后续的分类以及样本溯源等工作。
目前研究人员提出了许多恶意软件衍变分析方法,主要原理是两个代码高度相似甚至相同的样本很有可能是同一家族版本[4-10]。然而目前衍变分析中所用的代码相似分析技术存在缺陷,极大地限制了恶意软件衍变分析应用的准确性和拓展性。主要是:
(1) 相似性分析的时间开销较高。例如,BinHunt系统[11]基于控制流图进行比较并使用符号执行来进行语义相似性分析,尽管该方法提升了比较的准确性,但其方法时空复杂度很高,需要消耗大量时间。文献[5]的研究表明,使用BinHunt分析两个恶意程序版本需要30 min至1 h。
(2) 相似性分析的准确度不高。例如,文献[6]从代码中提取了12类特征,包括汇编代码的n-gram特征、静态程序块统计特征和动态执行指令的统计特征,然后借助Jaccard距离来分析代码之间的相似性。该方法时间开销不高,但是相似性分析的漏报率很高,导致最终的恶意软件衍变分析准确度只有不到72%。文献[5]中使用的基于小质数乘积的方法也面临着高漏报率、准确度不高的问题。
(3) 难以应对跨架构(平台)的恶意软件。尽管提出的许多方法尝试从准确性、高效性等不同方面提升恶意软件衍变分析的效果,但是这些方法都未充分考虑跨架构恶意软件的场景。而随着跨架构恶意软件尤其是IoT恶意软件的日益增加,其攻击目标往往针对多个不同架构的设备,已有的大部分代码相似性分析方法都不能有效解决相同代码跨架构编译的问题,难以在此类情况下准确地进行恶意软件的衍变分析。
针对当前恶意软件衍变分析存在的缺陷,本文提出了一种新的函数相似性检测方法,以进一步提升跨架构恶意软件衍变分析的准确性和拓展性。
1 研究动机和相关背景知识
1.1 研究动机
前面提到,研究人员已经提出了大量代码相似性方法用于分析恶意样本之间的衍变关系,具有代表性的是文献[5]提出的一种基于质数相乘的SPP-NOP函数哈希方法。具体来说,就是根据指令助记符,为不同的指令分配一个小的质数,然后将某个函数内包括的所有指令对应的质数相乘,其结果作为该函数的哈希值,这样不同样本之间相同的哈希值数量就可以作为度量它们之间函数相似性的依据。此方法以函数作为相似性比较的基本粒度,虽然具有很高的相似性比较效率,但是基于质数相乘的哈希方法准确度较低。除此之外,为了进一步验证SPP-NOP哈希方法是否能够有效分析跨架构样本的函数相似性,将获取的一款名为Lightaidra的公开物联网恶意软件源代码(其中包含49个函数),编译成面向不同架构(x86_32,mips,mipsel,arm,ppc)的二进制文件,然后使用SPP哈希方法来分析这些不同架构二进制文件之间的函数相似性,具体结果如图1所示。其中每个小格表示不同架构之间的相同函数的个数,越大表示相似度越高。可以发现,除了mips和mipsel架构之间函数相似度很高外,SPP哈希方法很难捕捉到其他架构样本之间的函数相似性,因此也就难以用于分析它们之间的衍变关系。和SPP函数哈希方法一样,其他很多方法也都存在此缺陷。
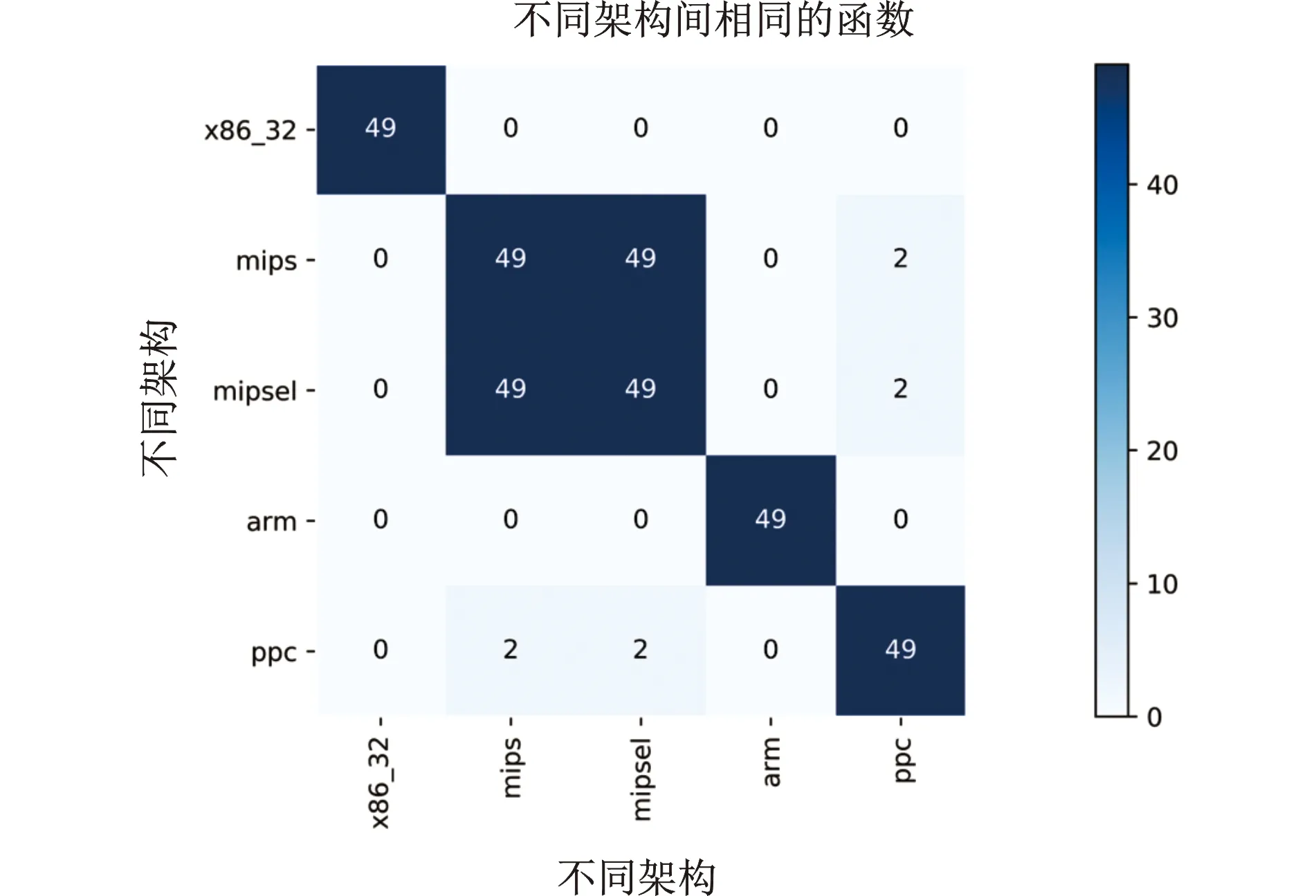
图1 基于SPP-NOP的跨架构函数相似性混淆矩阵
针对上述跨架构代码相似性分析问题,本文提出了一种基于Weifeiler-Leman图同构测试的跨架构函数相似性检测新方法WLHash。作为比较,图2显示了新方法WLHash检测跨架构Lightaidra代码相似性的结果。可以看出,所提方法极大地提升了不同架构之间的代码相似度,为后续更加准确地分析样本或文件之间的衍变关系,奠定了坚实基础。
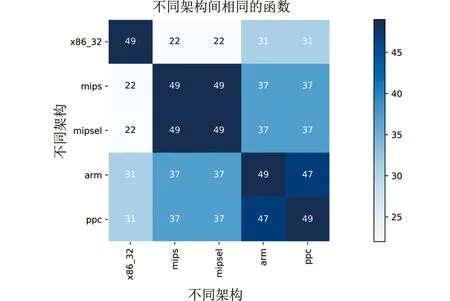
图2 基于WLHash的跨架构函数相似性混淆矩阵
1.2 相关背景知识
为了进一步提升代码相似性检测的准确度,目前主流方法是先将函数转化为控制流图(CFG)的形式,其中每个节点表示程序块,然后再进一步刻画该函数的语义和结构信息,最终通过图匹配来完成代码相似性检测。但是图匹配的比较开销比较大,这些方法在进行代码相似性分析时效率低下。为此,本文提出了一种相似性比较方法,结合了局部敏感哈希(locality sensitive Hash, LSH)和Weifeiler-Leman图同构测试。基本思路是根据程序块包含的指令,借助LSH将控制流图进行有效的哈希编码,然后基于哈希编码进行相似性度量,进而提升代码相似性分析的准确性和效率。
1.2.1 局部敏感哈希
局部敏感哈希其主要思想是,如果两个高维空间中的点距离很近,那么设计一种LSH哈希函数计算这两个点的哈希值,使得它们哈希值一样的概率很大;若两点之间的距离较远,则它们哈希值相同的概率会很小。LSH常见的实现算法是随机投影法,其思想是随机生成一些超平面,对空间进行分割,并根据与每个超平面的相对位置对每个输入进行编码,最终的编码即为LSH哈希值。通过随机投影,两个高度相似的输入对于不同的超平面大概率会有相同的相对位置,即最终落在同一空间分区,因此得到的LSH哈希值也一样。实际应用中,通过计算每个输入的LSH哈希值,当给定一个输入,可以快速检索其他相似输入。
1.2.2 Weifeiler-Leman图同构测试
基于控制流图的代码相似性分析涉及比较两个图是否同构的问题。两图同构指的是图中对应节点的特征信息(attribute)和结构信息(structure)都相同。图同构问题是一个NP-hard的问题,目前为止还没有多项式算法能够解决,而Weisfeiler-Leman图同构测试算法(以下简称WL算法)是一个能够适用于大多数情况的多项式解决算法。
WL算法同时考虑了图中的节点特征(attribute)和结构(structure)信息,节点的特征常常用特定标签表示,而结构信息指节点之间的拓扑连接关系。WL主要是通过聚合邻居节点的标签label,然后通过哈希函数得到节点新的标签,不断重复直到每个节点的标签稳定不变。
下面参照文献[12]来简单说明WL算法流程,如图3所示。
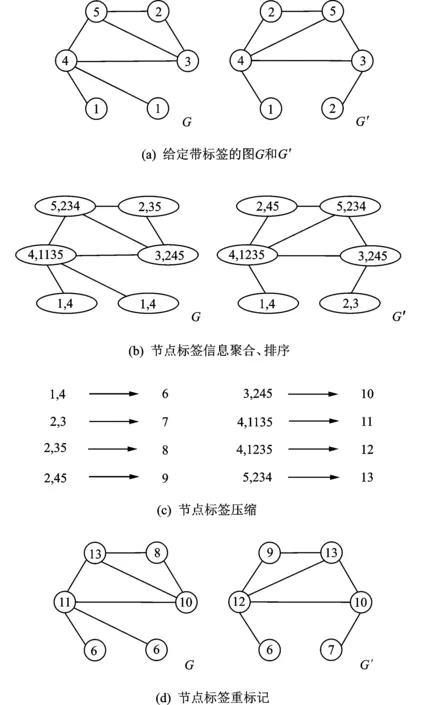
图3 WL的一轮迭代过程
WL算法实现步骤如下:
(1) 根据节点的特征信息,为其赋予标签。
(2) 对邻居节点标签信息进行聚合,每个节点将获得一个带标签的字符串,该字符串以逗号分隔为两部分,第一部分是该节点上一轮迭代的标签,第二部分是该节点的邻居节点标签按默认升序排序后连接形成的(例如对于节点5,其邻居节点为2,3,4,所以其结果为“5,234”)。
(3) 标签压缩,为了能够生成一个一一对应的字典,将每个节点的字符串哈希处理后得到节点的新标签。
(4) 重标记,将哈希处理过的标签重新赋给相应的节点,从而完成一轮迭代。
2 衍变分析系统
以函数作为衍变关系推断的基本粒度,提出一种新的函数相似性比较方法,并基于此进行衍变分析,整体架构如图4所示。
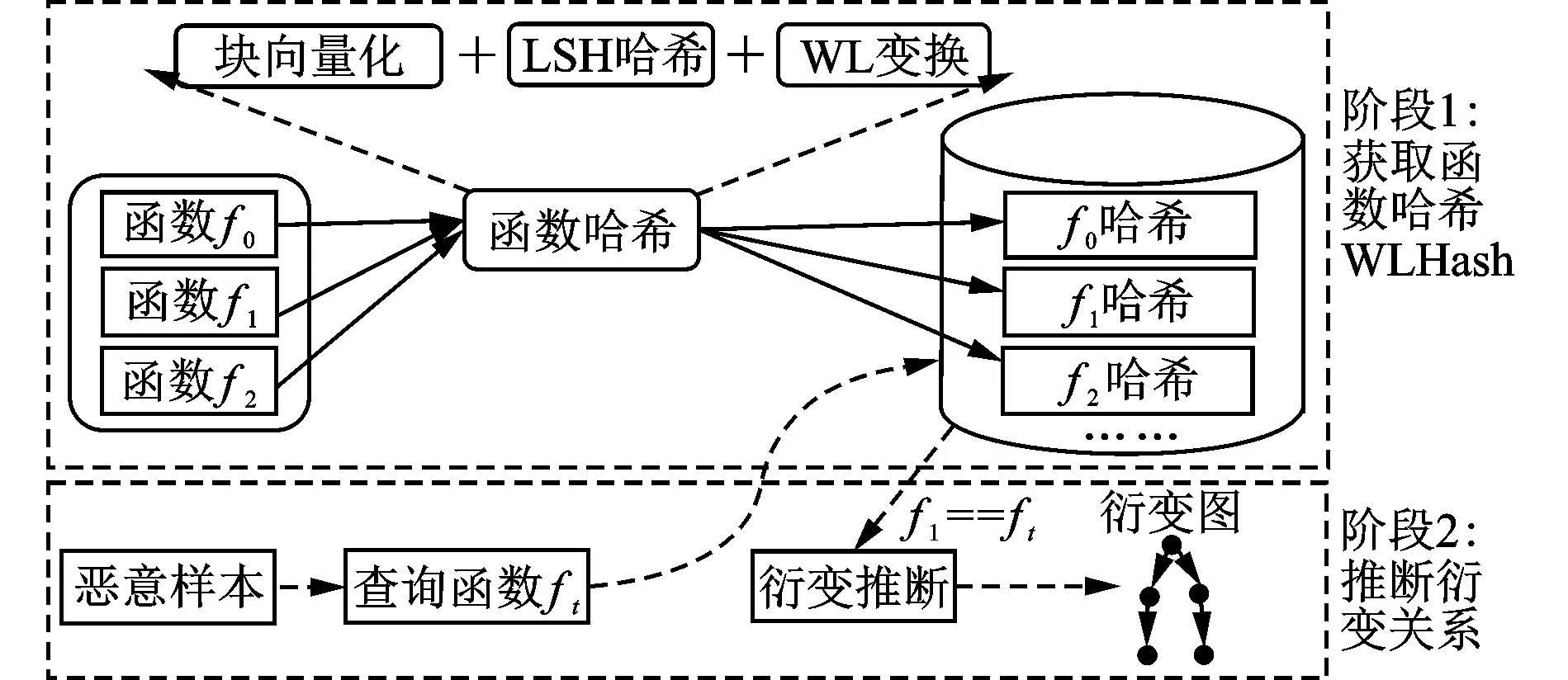
图4 衍变分析整体架构
衍变分析主要包括两个阶段。阶段1中提出了一种新的函数哈希算法WLHash,负责计算每个函数的哈希,并进行存储;阶段2则基于前期获取的函数哈希进行衍变分析推断。在阶段1中,初始输入为所有待分析样本和它们包含的函数,然后针对每个函数进行一系列操作,包括程序块向量化、LSH哈希和WL图同构测试,并获取最终的函数哈希。在阶段2中则充分利用阶段1获取的函数哈希,进行衍变关系推断,基本思路是根据一个待分析样本中包含的函数,逐个查找与该函数相似的其他样本中的函数,从而获得它们之间的衍变关系。如图4所示,某个样本中包含一个函数ft,通过查询前期存储的函数哈希,找到了与ft相似的函数f1,从而可以获得该样本与其他样本之间的关系。这里有两点需要额外说明,一是函数哈希计算过程中,两个高度相似的函数,它们最终的哈希值是相同的;二是在函数哈希计算中,除了存储函数与哈希的对应关系外,还存储了函数与样本之间的包含关系,便于后期衍变关系推断使用。
2.1 阶段1:函数哈希计算WLHash
提取每个函数的控制流图(CFG)来作为哈希计算的依据,其中控制流图的节点表示函数中的程序块,而边则表示程序块之间的跳转关系。为了更为准确地进行函数相似性比较,在计算函数哈希的过程中同时考虑程序块的语法特征和控制流图的结构特征。具体来说,就是通过对程序块中指令的进行正则化处理,得到程序块的向量化表示;在此基础上,使用局部敏感哈希来获取每个程序块的标签,从而可以将原始控制流图转化为一个节点带有标签的图,并最终经过WL图同构测试来获取最终的函数哈希。
2.1.1 程序块向量化
面向不同架构编译的相同源代码会输出不同的二进制代码,这些代码虽然语义上是等效的,但语法上往往差异很大。这种由跨架构编译带来的差异化因素主要包括:指令助记符、地址属性、寄存器使用、指令排序等。为此,程序块的向量化表示主要是为了消除这些可变因素,使得尽可能准确地度量两个程序块之间的相似性。
如图5所示,最左侧表示原始程序块包含的代码。为了消除跨架构编译带来的差异因素,中间的正则化(normalization)按指令助记符类型(stack,jump等)以及操作数类型(reg,mem等)对原始指令进行抽象简化,最右侧简化后,忽略指令顺序,统计不同指令抽象的数量,并转化为最终的向量化表示。本文采用的正则化将指令助记符分为6类,而操作数类型分为4类,这样一个指令助记符加上两个操作数的可能组合为96,因此每个程序块最终表示成一个96维的向量。
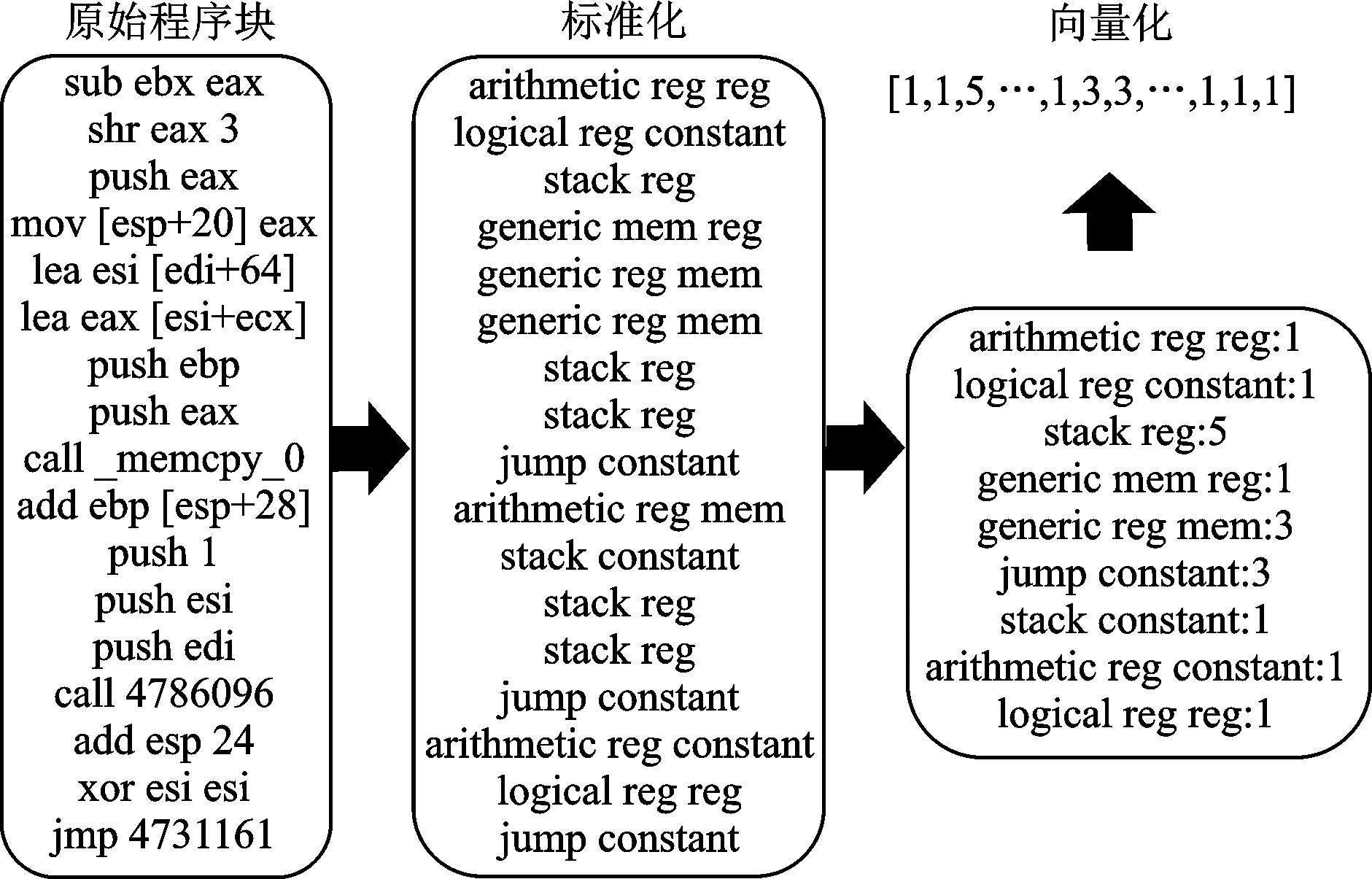
图5 程序块向量化表示
2.1.2 LSH哈希
LSH哈希的任务就是为相似的向量分配相同的标签,即为每个程序块分配标签。和许多LSH方案一样,本文也使用随机投影对空间进行划分,然后根据针对每个超平面的相对位置对每个输入进行二进制编码。如果产生两个超平面,则可将空间分为4个分区,分别编码为00,01,10和11。而相似的输入落在同一空间分区的概率更高,因为它们更可能与超平面具有相同的相对位置,这样相似的输入就很可能有相同的编码。例如,按照上面的分区,两个高度相似的输入同时落在了10分区,则可转化为十进制的2,即两个输入最终的LSH哈希为2。这样通过上述计算,就可以得到每个程序块对应的LSH哈希,并作为其节点标签。本文实际选择使用96个超平面,数量与每个程序块的向量维度相同。大多数LSH每次产生的超平面都是随机的,导致最终计算结果并不唯一,为了解决这个问题,本文保存了首次随机产生的超平面,后续一直使用这个超平面[13]。
2.1.3 WL图同构测试
经过上述两个步骤,可以将函数的控制流图转化为一个节点带标签的图,接下来采用WL图同构测试来将此带标签的图转化为一个哈希,这样可以对大量的函数控制流图进行预先计算,然后进行大规模比较和搜索。函数哈希核心思想是基于函数的控制流图,通过一系列的邻居节点标签聚合和节点重新标记来进行。
具体计算过程如表1所示。第1行是针对图中的每个节点,WL图同构测试收集节点的每个邻居标签信息(算法第4~6行),并将它们排序成一个有序列表(第7行),然后对节点的原始标签和其有序的邻居节点标签进行哈希操作(第8行),作为节点的新标签。最后,经过若干轮邻居节点标签聚合和重新标记(第10行),可以最终得到图中所有节点的最新标签(第11行)。最后,对排序后的节点最终标签进行合并和哈希操作(第12、13行)来计算图哈希,作为对应函数的哈希。这里有一点需要强调的是,实际研究发现WL图同构测试多轮迭代操作并未大幅提升后续相似性比较的准确性,但却导致巨大的计算开销,因此仅使用1轮迭代来计算图哈希。

表1 基于WL图同构测试的函数哈希算法
以图3为例,经过1轮WL图同构测试后,两图G和G′的有序节点标签列表分别为{6-6-8-10-11-13}和{6-7-9-10-12-13},因此两图最终的图哈希分别为hash(6-6-8-10-11-13)和hash(6-7-9-10-12-13)。
2.2 阶段2:建立衍变图
在计算完所有样本中函数的图哈希后,衍变关系推断的主要目标就是以这些图哈希和对应样本为输入,分析它们之间的衍变关系,并最终生成一个较为完整的衍变图。其中节点表示样本,边表示样本之间父子继承关系。根据前期每个函数计算的图哈希,继承关系的主要依据是样本插入衍变图的先后和它们之间的相似性,相似性度量的标准就是样本之间相同函数的个数。在软件开发过程中,常常出现软件版本的分叉和融合,版本分叉允许开发者在不影响其他版本的基础上修改和测试新功能,而版本融合则往往是为了结合若干版本的特定功能。如表2中算法所示,衍变图建立主要包括3个步骤:
(1) 根节点识别。
(2) 建立包含分叉的衍变图(对应算法中的Lineage_branch函数),这个阶段以选定的根样本为起始点,根据样本之间的相似性,不断地向图中插入剩余样本,在这个阶段一个父节点可能有多个子节点。
(3) 衍变图添加交叉边(对应算法中的Lineage_merge函数),这个阶段判断某个样本在功能函数上是否与其他样本有继承关系,即一个节点可能有多个父节点,然后向图中添加对应的交叉边。
2.2.1 根节点识别
衍变图在初始时是一棵空树,如何选择和插入第一个节点(根节点)至关重要。在软件工程领域,软件演化 (software evolution)是指对软件进行维护和更新的一种行为,它是软件生命周期中始终存在的变化活动。针对软件演化,Lehman等[14]提出了8条软件演化法则,其中第六条的功能持续增加法则声明在软件的生命周期中,软件功能必须持续增加,即程序会随着时间的推移而增长。受此启发,在表2算法中第3行,首先从初始样本集合中选取根节点,依据是它包含的功能函数最少而且到所有其他节点的平均相似度之和最大。
2.2.2 建立包含分叉的衍变图
在选定了根节点后,接下来需要遍历所有其他样本来建立包含分叉的衍变图,具体流程如表2算法中的函数Lineage_branch所示。对于每一个未插入衍变图的样本,首先需要确定它和衍变图中的哪个节点存在衍变关系,而此过程需要将待插入样本和衍变图中已有样本进行相似性比较(算法第10行),并将相似性最高的样本作为待插入样本的父节点,把待插入样本作为子节点(第13行),然后在父、子节点之间建立一条指向边(第14行),表示衍变关系。这里,两个样本之间的相似性程度是通过度量两者之间相似函数的个数,具体实现就是两个样本之间相同的函数哈希个数越多,相似程度越高。在通过相似性比较不断插入样本过程中,表2中算法能够处理两种特殊情况:

表2 衍变图建立算法
(1) 如果有多个已插入样本和待插入样本具有相同的函数哈希个数,则进一步通过细粒度的指令类型统计来比较样本之间的相似性程度,把函数哈希个数相同且指令类型统计更接近的样本作为最终的相似样本;
(2) 如果所有已插入样本与待插入样本的相似度都不高(算法第11、12行),则可能与待插入样本相似的样本还未插入,因此暂时跳过,先分析其他未插入样本。
基于函数相似性比较,表2算法中的Lineage_branch函数通过不断的比较、插入样本,最终可以得到一个包含多分叉的衍变图,其中每个子节点至多只有一个父节点,而一个父节点则可能有多个子节点。
2.2.3 衍变图添加交叉边
衍变图中,每个子节点最多只有一个父节点。然而,实际情况是一个样本往往可能和多个样本有继承和演化关系。因此,还需在建立的衍变图中添加额外的交叉边用以表示衍变关系,表2算法中的Lineage_merge函数描述的就是这个过程。添加交叉边的具体流程是,对于图中的某个节点v,首先确定其父节点(算法23行),及未能从父节点继承的新增函数(第24行,即该节点自身包含但父节点没有的函数)。基于节点v的新增函数,算法第27行主要任务就是从图中进一步搜索节点v可能的其他候选父节点,在搜索过程中首先排除节点v现有的父节点和子节点(第25行),然后从剩余节点中找出可能的父节点。之所以排除节点v的父节点,是因为它已经影响了当前节点,而排除其子节点,则是避免在衍变图中产生循环。候选父节点的搜索是一个迭代的过程,首先从剩余节点中找出和节点v共有最多新增函数的节点,作为一个候选父节点;然后,将这些发现的共有函数从最开始的新增函数集中删除,作为搜索下一个候选父节点所需的新增函数集,直至新增函数集大小小于某个阈值(本文设置为5)。最终,根据这些搜索到的候选父节点,在衍变图中添加它们和当前节点v之间的指向边(第30行)。
最终经过搜索其他父节点并添加额外交叉边,衍变图中某个节点可能存在多个父节点,能够更加准确地刻画样本间的衍变关系。值得注意的是,前面提出的面向函数的图哈希算法极大地提升了此阶段的运算效率,因为基于图哈希的搜索允许在O(1)的时间内迅速判断某个新增函数是否包含在某个样本中。
3 实验评估
实验评估主要包括3个部分:(1) 基于已知的正常程序衍变版本,评估提出的衍变分析方法的准确性;(2) 对跨架构的IoT恶意样本进行衍变分析,并对生成的衍变图进行统计;(3) 评估所提方法的性能开销。
3.1 实验环境与数据集
3.1.1 实验环境
实验在一个台式机上运行,其配置为Intel i5-4460,CPU主频3.1 GHz,内存16 GB;所有程序均由Python语言编写,使用IDA pro 7.0对二进制程序进行反编译;使用MongoDB存储程序所有的中间输出(例如函数哈希)。
3.1.2 数据集
由于缺乏可以直接用于评估恶意软件衍变分析准确性的数据集,故搜集了已知衍变关系的Putty系列程序,如表3所示,共计7个程序,24个版本,每个版本对应一个样本,总计168个样本,均为x86架构,从首个版本的发布到最近发布间隔18.5 a。
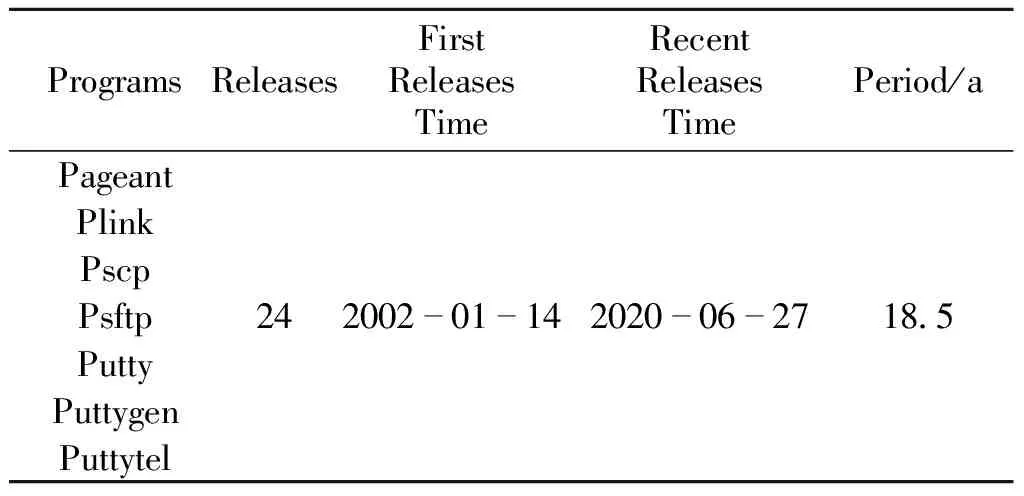
表3 Putty系列程序
同时也搜集了1 804个跨架构的IoT恶意样本用于衍变分析,如表4所示,第一列是家族名,其余的列分别是不同架构和所对应的样本数量。
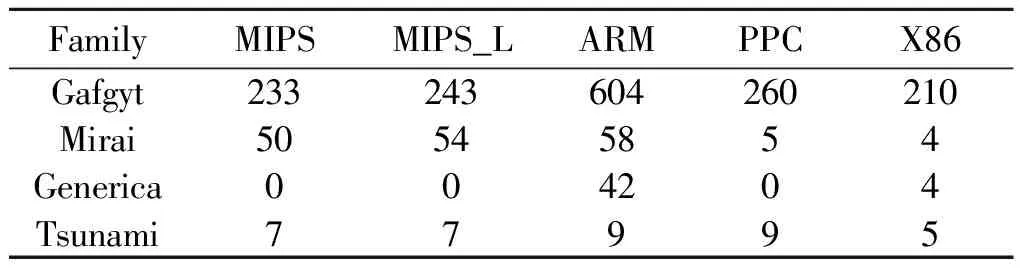
表4 跨架构IoT恶意样本
3.2 衍变分析的准确性评估
在进行衍变分析准确性评估之前,首先定义准确性评估标准。衍变图本身是一个有向图,通过边来表示样本节点之间的衍变关系,其实质是一个严格的偏序关系。假如4个样本a、b、c、d的真实衍变关系为a->b->c->d,将生成的衍变图与真实衍变关系进行对比,通过搜索偏序不一致的实例来评估其准确性。举个例子,假如生成的衍变图中上述4个样本的衍变关系为a->b->d->c,通过与这个真实的偏序衍变关系进行比较,可以发现存在一个偏序不一致实例,即d->c与c->d不符。本文定义,与真实衍变关系相比,最终生成的衍变图中存在的偏序不一致性(partial order inconsistency,POI)越少,则其准确性越高。
为了评估衍变分析的准确性,选取了Putty系列程序作为分析对象,这样做主要是因为它有多个衍变版本,而且衍变路线清晰且已知,便于评估衍变结果的准确度。如表3中提到的,这些Putty系列程序共计24个版本,从开始版本0.52到结束版本0.74,每个版本对应一个样本。通过衍变分析,最终得到每一个程序对应的有向衍变图,其中每个节点表示样本及其版本号,边的方向揭示了样本之间的衍变关系,边的颜色和粗细表示了样本之间相似的程序,例如图6是生成的putty程序衍变图,其中包含24个顶点,41条边。

图6 putty衍变图
图中较粗的边是在衍变图生成过程中由函数Lineage_branch生成,表示衍变的主体路线,而较细的边则是由函数Lineage_merge生成的交叉边。从图中可以看出,较粗的边清晰地表示了各个样本之间的主体衍变关系,而较细的交叉边则在一定程度上反映了样本之间功能的继承关联关系。
具体来说,对于生成的衍变图,准确性评估的方法是通过人工查看每个样本之间的前后继承关系,查看得到的衍变图是否准确遵循了真实版本演化过程。经过人工分析发现,图6的putty衍变图中,最终得到了putty-0.68->putty-0.69和putty-0.68->putty-0.70的衍变关系,与真实的衍变关系putty-0.68->putty-0.69 ->putty-0.70相比,偏序不一致性数量为1。在衍变分析过程中,出现偏序不一致性的主要原因是函数相似性计算过程中出现偏差。比如两个函数本来相似度不高,但是采用某些函数相似性计算方法导致两者高度相似,从而引入错误的衍变关系。
为此,针对搜集的7个Putty系列程序,分别计算了它们的衍变图,并手工分析了它们的偏序不一致性。同时为了与WLHash函数哈希方法进行对比,在衍变分析过程中,也尝试采用了文献[7]中的函数哈希方法SPP-NOP来计算最终的衍变图。结果如表5所示,其中|V|表示节点数,|E|表示边数,|C|表示添加的交叉边数,而|POI|表示偏序不一致数。从表5中可以看出,不论是SPP-NOP哈希,还是WLHash哈希,都会造成最终生成的衍变图出现一定的偏序不一致性,但是两者结果还比较接近,基于SPP-NOP的函数哈希方法产生了20个偏序不一致实例,而基于WLHash的方法产生了22个偏序不一致实例。出现偏序不一致性的根本原因是两个函数哈希方法在计算函数相似时会出现一定的误报。例如,pscp-0.69中的函数“sub_4337E3”的WLHash函数哈希和pscp-0.54中的函数“sub_4210A6”、“sub_40E958”和“sub_40B4E9”的WLHash函数哈希相同。但实际情况是,pscp-0.69中的函数“sub_4337E3”只和pscp-0.54中的函数“sub_4210A6”相似。与此同时,SPP-NOP的函数哈希方法也会出现一定的误报,例如putty-0.68中“sub_4210A6”的SPP-NOP函数哈希与putty-0.70中“sub_46419D”和“sub_4969E8”的SPP-NOP函数相同,但实际上,putty-0.68中的“sub_4210A6”函数只与putty-0.70中的“sub_46419D”函数高度相似。
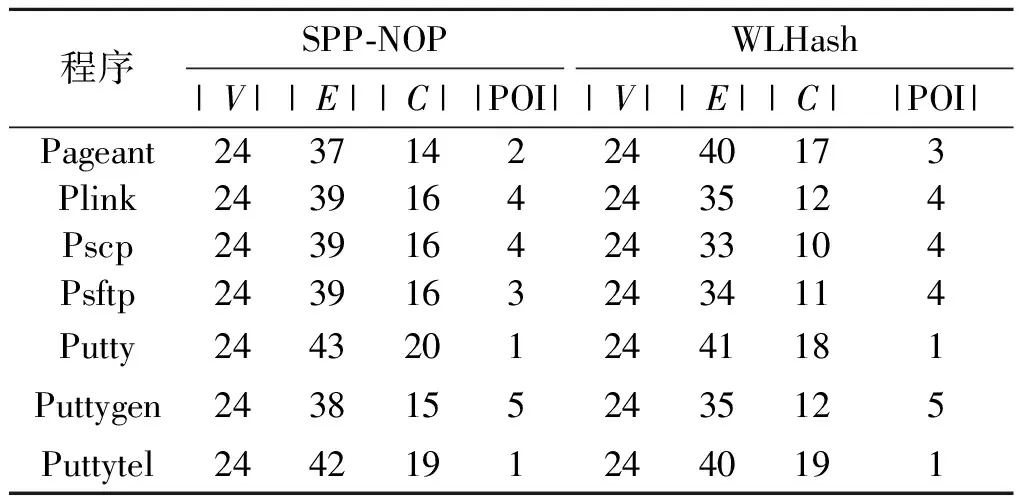
表5 Putty系列程序衍变图统计结果
3.3 跨架构恶意软件的衍变分析
按照前面的分析流程,对搜集到的跨架构IoT恶意软件(表4)也进行了同样的衍变分析,同样使用了文献[7]所提的SPP和WLHash两种函数哈希方法,并最终生成恶意样本对应的衍变图,衍变图的具体信息如表6所示。
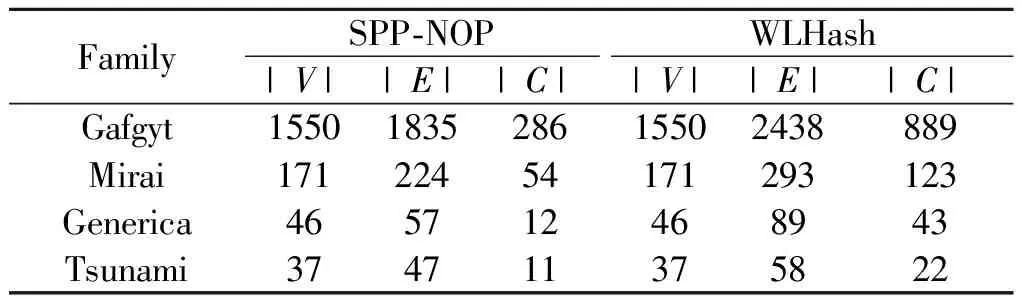
表6 恶意软件衍变图统计结果
从表6中的新增交叉边数|C|可以看出,基于WLHash函数哈希的衍变分析方法识别出更多跨架构样本之间的衍变关系。以Tsunami家族为例,基于SPP和WLHash的函数哈希所产生的衍变图分别包括47和58条边,以及11条和22条交叉边。接下来以Tsunami的衍变图进行比较说明,其中图7是基于SPP函数哈希所生成的衍变图,而图8是基于WLHash函数哈希所生成的衍变图中每个节点名称使用编号+架构来表示,例如节点0_x86表示0号样本,其架构为x86。
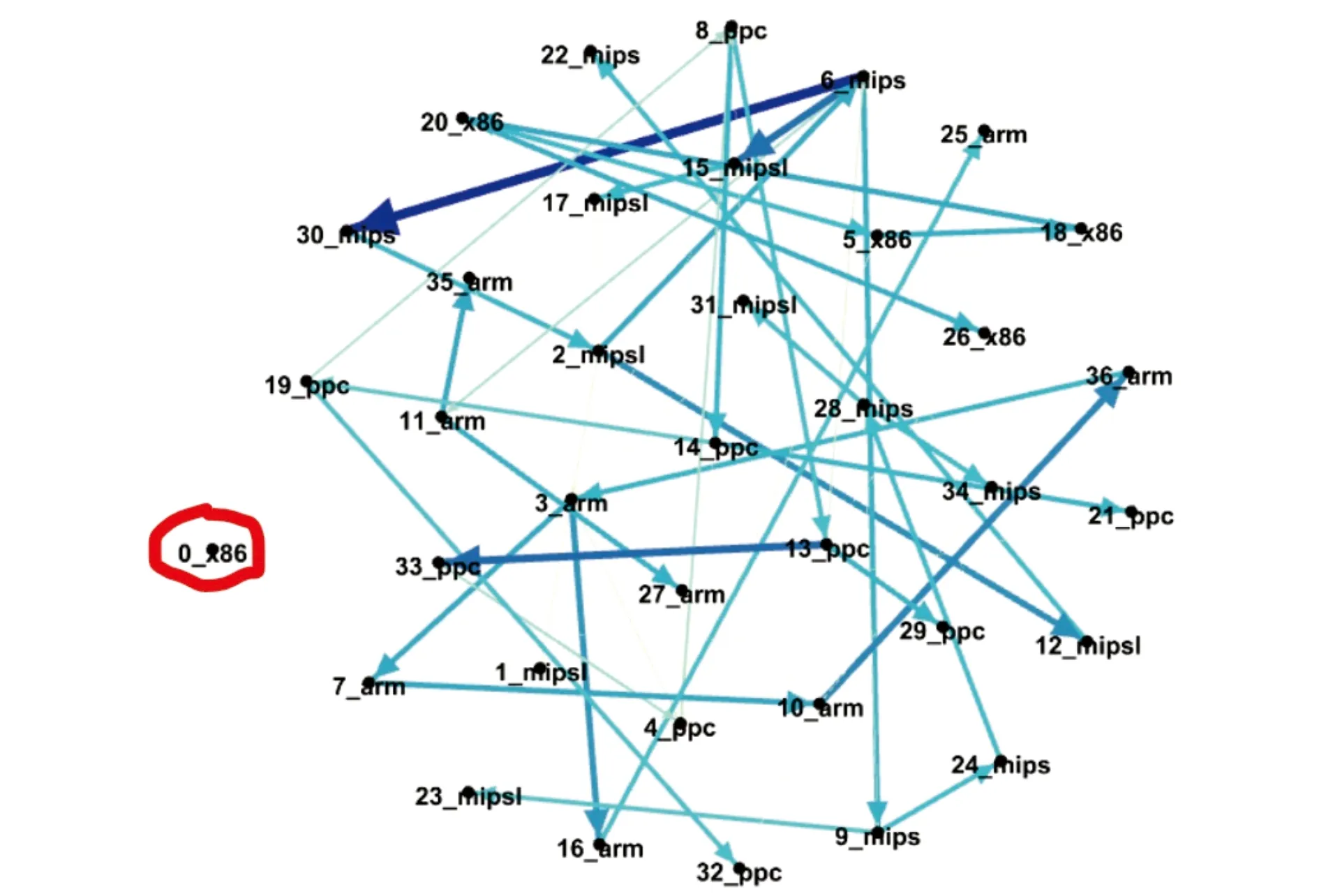
图7 基于SPP-NOP的Tsunami衍变图
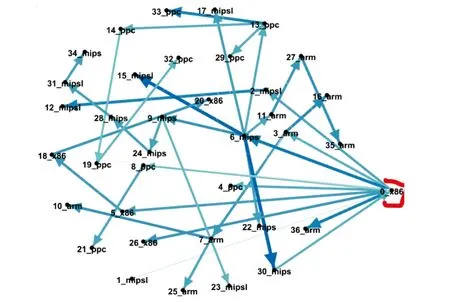
图8 基于WLHash的Tsunami衍变图
通过对比Tsunami的两个衍变图,可以很容易发现WLHash函数哈希能够捕捉更多跨架构样本之间的衍变关系,以样本0_x86为例,在图7中它是孤立节点,与其他节点没有衍变关系,而在图8中则与多个其他架构的样本具有衍变关系。
除了0号样本,通过对比发现WLHash函数哈希可以发现其他跨架构样本之间的衍变关系,因此可以有效辅助跨架构场景下的恶意软件分析。
3.4 WLHash函数哈希的性能开销
为了评估本文所提出的WLHash函数哈希的计算开销,对搜集到的1 804样本进行函数哈希计算,并统计每个样本的分析时间,时间分布如图9所示。平均每个样本的函数分析时间是2.45 s,95%的样本都能在4.14 s内计算完函数哈希。上述实验结果表明,WLHash函数具有较低的计算开销,适用于计算大规模恶意软件样本的函数哈希。
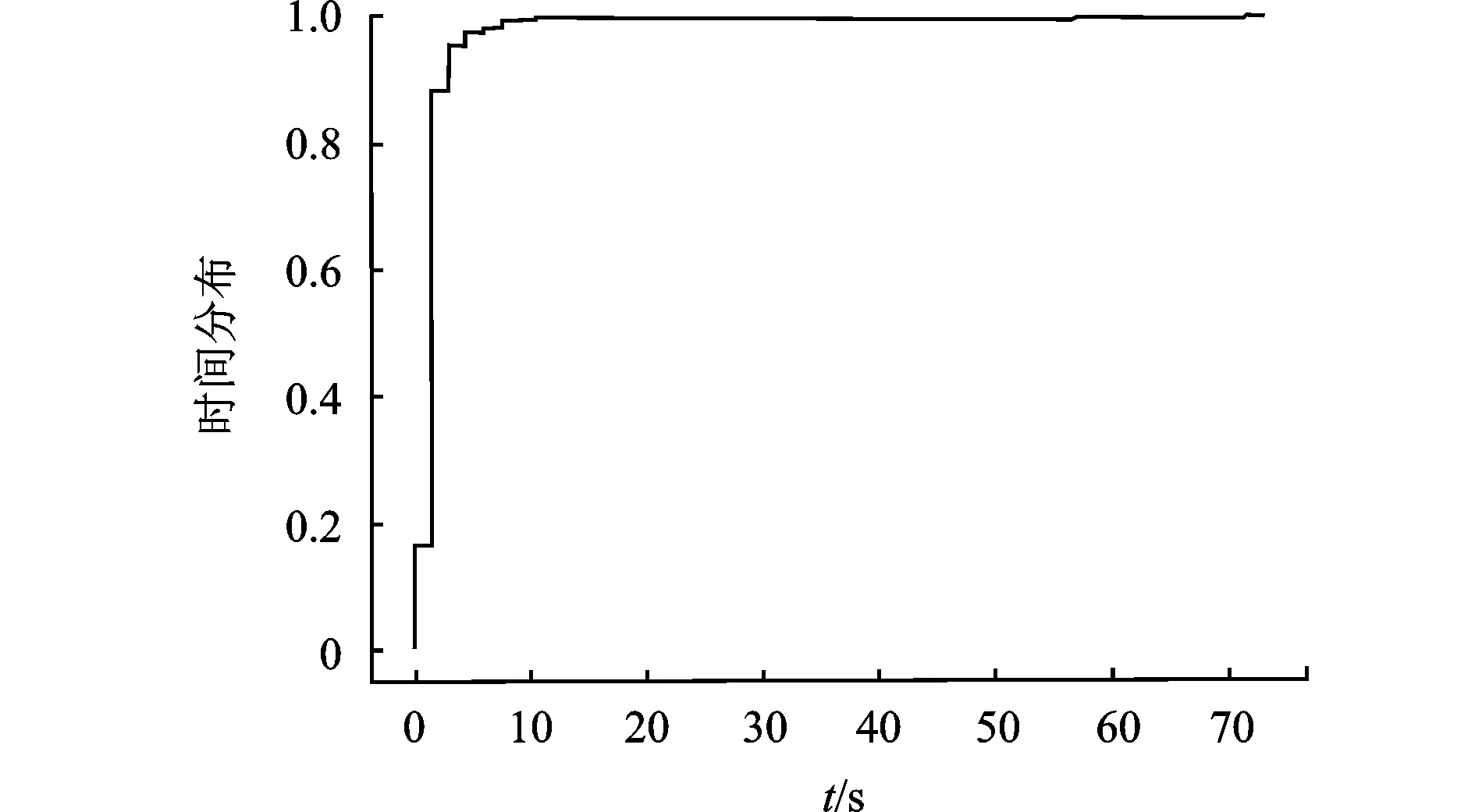
图9 WLHash计算时间CDF分布图
4 结果分析
4.1 代码相似性分析
作为程序分析领域的一个经典问题,代码相似性分析常常指的是在无法获得源码的情况下分析二进制函数的相似性,在安全和知识产权保护等领域中有重要应用,例如恶意软件分析,漏洞检测,版权纠纷等。截至目前,研究人员已经提出了大量代码相似性分析方法[15-27]。文献[28]对现有代码相似性分析工作进行了分类,根据提取的程序特征粒度,将已有方法分为4类:基于指令特征的方法、基于程序基本块特征的方法、基于程序函数特征的方法和基于整个程序特征的方法;根据相似性的类别,又可分为语法相似性、语义相似性和结构相似性3类。
作为较早的代码相似性比较方法,模糊哈希技术通过计算代码的哈希值来识别相似的恶意软件变种。比如最具有代表性的模糊哈希技术SSdeep[29],已被VirusTotal作为所有提交的恶意软件样本的文件属性之一。尽管SSdeep和大多数现有的模糊哈希工具提供了一定的代码相似性分析能力,但其鲁棒性较差,代码中的微小改动就会导致哈希变动,使得相似性程度大幅下降。
为了提升代码相似性比较的准确性,目前主流的方法是基于函数的控制流图来进行相似性分析,这样就能同时考虑代码的结构和语义信息。基于控制流图的相似性分析设计图同构分析问题是一个NP-Hard问题,因此研究人员提出了各种方法通过利用控制流图中的一些特征(例如有界度)来近似逼近控制流图的相似性。(1)最小权二部图匹配。Hu等[30]提出了一种基于编辑距离的图同构算法,原理是通过建立两个图中不同节点映射成本的成本矩阵,并使用匈牙利算法[31]找到节点之间的最优映射,从而使总成本(即编辑距离)最小化。根据邻居节点的相似性,文献[32]迭代地建立两个CFG节点之间的相似矩阵,并同样采用匈牙利算法来寻找两个图中节点之间的匹配,使得得到的相似性数值最高。(2)最大公共子图匹配。文献[33]设计了一个回溯搜索算法来得到两个图的最大公共子图。该思想已被用于设计高效的CFG相似度比较算法,并被用于二进制语义差异分析[11]和二进制代码搜索[34]场景中。在给定最大公共子图输出的情况下,图的相似度得分为公共子图节点的最大值除以两个图之间的所有节点的数目。(3)K-子图匹配。Kruegel等[35]设计了一种基于K阶子图(包含K个节点)挖掘的算法。他们为图中的每个节点生成一个生成树,使得每个节点的出度小于或等于2,然后通过考虑根节点下K-1个节点的所有可能分配,从生成树中递归地生成K阶子图。然后对每个K阶子图进行规范化处理,并通过连接其邻接矩阵的每一行提取出指纹。(4)基于仿真的图相似。文献[36]使用标记的转移系统对控制流图进行建模,给定两个控制流图,它们递归地从入口节点开始匹配最相似的出口节点,并求出匹配节点和边的相似度,然后用递推公式定义两个控制流图的总体相似性。尽管图匹配等方法在一定程度上提升了基于控制流图的代码相似性分析的准确性和效率,但是仍无法较好处理跨架构的代码。
为了能够进行跨平台架构的代码相似性分析,不同于传统的图匹配方法,近几年来研究人员提出了全新的代码相似性分析方法。例如,文献[37]提出基于中间表示的代码相似性分析方法,基本原理是首先将汇编代码转换为中间表示(IR)代码来解决语法差异,然后再基于中间表示来分析代码相似性。然而,现有的IR语言/平台仅限于处理少数架构(即mips、arm、x86),难以处理包含了多种不同架构的恶意软件数据集。另外有研究者提出将图嵌入技术应用于代码相似性分析。例如,文献[24]首先对控制流图中的每个块进行属性标记,然后借助神经网络进行图嵌入,将转化后的控制流图转化为数字向量,实现了跨平台的代码相似性比较,取得了较好的精度和效率。文献[38]则提出了一种新的基于自然语言处理的二进制函数相似性分析方法,二进制程序经过反汇编之后则为一条条汇编指令,主要思路是将一条汇编指令当作一个单词(word)而将一个程序块视为一个语句(sentence),通过训练神经网络挖掘出其中的语义表示,从而将本来代码相似比较问题转换为自然语言相似比较问题。除了上述方法,还有一些其他类似的基于图神经网络和图嵌入等深度学习算法的跨架构代码相似性分析方法[17-18,24,27],但这些方法的可拓展性和效率还有待提高,第一,训练过程需要大量标签代码数据;第二,图嵌入的运行开销会随着代码量的增加而增加。例如对于基于自然语言处理的文献[24]来说,训练数据集的大小十分重要,几十万条汇编指令的文本大小也不过几十MB,这对于模型训练来说是否足够是个问题,训练数据集小的一个重要后果就是在实际情况下表现可能会很差。
和上述工作相比,本文所提的方法在分析跨架构代码的同时也兼顾了准确性和效率,提升了跨架构恶意软件衍变分析的实用性。
4.2 恶意软件衍变分析
恶意软件衍变分析的本质是捕捉其演化过程,正如文献[3]中总结的,恶意代码存在两个方面的演化:功能特性演化和生成方式演化。(1) 从功能特性演化方面来说,与早期相比, 新一代恶意软件朝着定向性、持续性、隐蔽性和技术先进性等功能特性不断演化;(2)从生成方式演化方面来说,新的恶意软件很少从头开始创建,大多数是采用自动生成工具、第三方库以及借用现有的恶意软件代码生成,许多恶意软件都是已存在恶意软件的变体,超过98%的新恶意软件样本实际上是来自现有恶意软件家族的衍生产品(或变体)。恶意代码经过修改或者自行演化等途径后,往往会形成数十种甚至更多的变种,使得变体数量迅速增长。通过分析恶意软件间的衍变关系,可以迅速发现相似变种及其衍变关系,便于安全人员及时发现新型恶意变种及新特性。
针对恶意软件的衍变分析研究可以追溯到20多年前,Hull等首次对Stoned引导扇区计算机病毒的演化进行了系统的分析。文献[6]提到,软件衍生关系推理主要目标是推断程序之间的时间顺序和祖先/后代关系,软件衍变过程可以最终表示为一个衍变图。
截至目前,研究人员已经提出了大量恶意软件衍变分析方法[4-10,39-41]。例如部分文献采用基于距离的层次聚类方法来分析恶意软件之间的衍变分析。除了聚类方法外,文献[42]提出了一种新的图剪枝算法来建立不同恶意代码实例之间的继承关系,该算法主要考虑时间信息和恶意代码描述中识别的关键短语。通过建立恶意代码之间的继承关系,可以进一步了解这些年来恶意代码是如何演变的,特别是不同的恶意代码实例是如何相互关联的。文献[43]则提出在样本之间跟踪和识别单个特征(例如,小代码子集),然后训练分类器以正确识别衍变关系。作为两个比较经典的恶意软件衍变分析工作文献[5,6],文献[6]从代码中提取了12类特征,包括汇编代码的n-gram特征、静态程序块统计特征和动态执行指令的统计特征,然后借助Jaccard距离来分析代码之间的相似性,但是分析开销和漏报率比较高;而文献[5]提出使用小质数乘积的方法来分析函数相似性,并进而推断衍变关系,也存在准确度不高的问题。
与这些工作相比,本文最大的贡献在于提出了基于WLHash函数哈希的恶意软件衍变关系推断,极大地提升了分析准确性和效率,同时也适用于跨架构的恶意软件衍变分析。
5 结论
本文提出了一种基于WL图同构测试的函数哈希方法WLHash,用于函数相似性检测,并对正常应用和跨架构恶意样本进行了衍变分析,生成了衍变图。实验结果表明,与已有的函数哈希方法相比,本文所提的函数哈希方法在保证准确性和分析效率的前提下,能够刻画跨架构的函数相似性,从而捕捉到不同架构下样本之间的衍变关系,能够辅助安全人员更加准确地分析多架构恶意软件家族的演化关系,具有很高的实际应用价值。
虽然本文提出了一种较为准确的函数相似性检测方法,通过衍变分析也能够找出相邻两个样本之间函数的新增和删减。但是对于分析人员来说,仅仅知道函数的新增和删减情况并不能理解样本之间的功能变化。在接下来的工作中,希望能够进一步提取函数的语义摘要,从而能够辅助分析人员迅速把握样本之间在功能语义上的改变,以及功能新增或功能删减。
猜你喜欢
现代英语(2021年18期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
股市动态分析(2015年16期)2015-09-10
