
临床研究数据分析原则、要点和统计软件实现
2022-07-06 14:27王瑞平李斌
上海医药 2022年11期
关键词:临床研究
王瑞平 李斌
摘 要 临床研究数据分析是呈现研究结果的方式,是评估临床研究干预措施效果的重要参考和依据。研究者选择合适的数据采集工具收集数据,进行数据质量控制和清理后,便可以开展统计分析工作。本文主要介绍了临床研究数据统计分析的原则、统计分析过程中须注意的事项和要点,以及如何应用SPSS软件实现数据的统计分析等内容,以期为今后临床研究人员开展数据统计分析提供参考。
关键词 临床研究 意向性分析 检验水准 统计学描述 统计推断
中图分类号:R-3 文献标志码:C 文章编号:1006-1533(2022)11-0036-06
引用本文 王瑞平, 李斌. 临床研究数据分析原则、要点和统计软件实现[J]. 上海医药, 2022, 43(11): 36-41; 79.
Principles, elements and statistical software implementation for the analysis of clinical research data
WANG Ruiping, LI Bin
(Clinical Research & Innovation Center, Shanghai Skin Disease Hospital, Shanghai 200443, China)
ABSTRACT The analysis of clinical research data is a way of presenting the results of a study and is an essential reference and basis for assessing the effectiveness of clinical research interventions. After researchers have selected an appropriate data collection tool to collect the data and performed data quality control and cleaning, statistical analysis can then be carried out. This article introduces the principles of statistical analysis of clinical research data, the key points to note in the process of statistical analysis, and how to apply SPSS software to achieve statistical analysis of data so as to provide a reference for clinical researchers to carry out statistical data analysis in the future.
KEY WORDS clinical research; intention to treat analysis; testing level; statistical description; statistical reference
本刊2022年第43卷第1期“臨床研究规范”栏目刊发的《临床医学研究数据统计分析思路概述》[1]基于临床研究数据分类,解读了临床医学研究的统计分析思路,主要包括统计学描述和统计学推断2个部分。然而,在临床研究数据分析实践中,仍会存在研究者不清楚统计分析数据库的选择原则、统计分析中须要注意细节和易错点等情况。因此,为帮助研究者理清临床研究数据分析的原则和要点,本文将重点介绍临床研究数据统计分析的原则、统计分析过程中须注意的事项和要点,以及如何应用SPSS软件实现统计分析等内容,以期为研究人员开展数据统计分析提供依据和参考。
1 临床研究数据集选择
广义的临床研究包括描述性研究(现况研究、纵向研究、病例系列研究等)、分析性研究(病例对照、队列研究)、临床试验研究(社区试验研究、个体试验研究等)和数理研究(统计学建模、疾病转归预测等),而狭义的临床研究是指随机对照临床试验研究(randomized control trial, RCT)。无论是广义临床研究还是狭义临床研究,项目组完成研究数据的采集、清理和质量控制后,都会产生数据库,也即是统计分析数据集。描述性和分析性临床研究均属于观察性研究范畴,研究者未对研究对象实施干预措施,而仅通过观察和测量收集研究对象的人口学、生活行为、疾病特征等数据信息。除前瞻性队列研究外,其他类别的观察性临床研究的研究周期短,项目完成后通常仅形成一个数据库,后续统计分析将基于该数据库(数据集)开展,研究者只须描述清楚研究对象的应答率、在队列研究随访过程中的失访情况,而对于因失访而导致的数据缺失无须填补,后续通过比例风险回归分析等展示即可。
在临床试验研究中,研究者的目标为验证病因假设或评估干预措施的疗效和安全性,并综合考量研究周期、经费、伦理等方面问题,其研究对象的规模相比于观察性临床研究往往要小很多,而且在研究对象筛选方面也十分严格,因此须要对入组的每一个研究对象给予充分重视。在研究对象招募阶段及整个研究全过程均须要与其保持密切沟通和联系,尽可能避免研究对象的脱落和失访,从而提高研究数据的完整性。鉴于临床试验研究的特殊性,理想的研究数据集应是包含所有入组对象在全研究周期内的所有数据,无漏填缺项,无失访与脱落。但在临床研究实践中,由于种种原因还是会出现研究对象脱落、数据采集不完整等情况,所以在研究项目结束后,须对最后形成的数据库进行判定和必要的技术修正,保证项目产生的有效数据的利用最大化。为此,临床研究专家和统计学家对RCT的数据库进行分类,包括意向性分析集(intention-to-treat population, ITT)、全分析集(full analysis set, FAS)和符合方案集(per-protocol analysis, PP)。
如图1所示,①ITT纳入了所有随机化分组后的受试者进入分析,而不仅是实际完成的受试者。须注意的是,如果某受试者被随机分配到了A组,后续ITT分析中该患者也必须一直在A组,即便该受试者后来接受的是B组的治疗方案或没有接受任何治疗。这样做的目的是要保持两组间的基线特征均衡可比,使得除研究因素以外的其他变量完全均衡和匹配,能够充分观察干预效果。②FAS是ITT的子集,是指对所有随机化受试者的数据做最少和公正的剔除后所得到的数据集,为的是保持原始数据集的完整性,减少偏倚。③PP则是FAS的一个子集,是指研究对象均依从干预措施的数据集,即该子集内的受试者在纳入与排除标准、接受治疗、主要指标测量等方面不存在严重违背方案的情况。一般情况下,临床试验研究优先选择FAS进行统计分析,不过研究者也应报告基于PP的分析结果,将其作为补充材料(supplementary material)放在文章附件中。相比于PP,基于FAS的数据分析更容易得到无统计学差异的结果,在非劣性或等效性临床研究设计时将会导致Ⅰ类错误风险的增加,研究者应给予充分关注,尽可能同时应用PP和FAS分析,综合评估临床研究中干预措施的疗效和安全性。

2 臨床研究数据分析原则
临床研究数据统计分析至少应包括4个方面的内容:①对临床研究数据库中的变量定义或分类处理给出解释说明。如“吸烟率”“饮酒率”“治疗有效率”等应给出定义和计算方法;“年龄”“文化程度”“收入”等分类变量给出具体的分组和依据。②统计学描述内容,应对临床研究数据库中的定量变量和定性变量的给出详细描述方案。例如:定量变量如符合正态分布,用均数±标准差描述,如不符合正态分布,用中位数和四分位数间距描述;定性变量一般用率、构成比或百分比描述。③统计学检验和推断内容,同样应根据变量类型的不同,给出具体的统计分析方案。例如:定量变量如符合正态分布且方差齐,两组之间的比较采用t检验,多组之间的比较采用方差分析;如方差不齐,两组之间的比较采用t’检验,多组之间的比较先进行数据转换(对数变换、平方根变换、平方根反正弦变换等)再采用方差分析;如不符合正态分布,则选择非参数检验分析组间的差异。而对于定性变量,通常选择χ2检验、趋势χ2检验进行单因素分析,探讨两组或多组变量之间的差异;应用logistic回归开展多因素分析,探索研究变量的独立危险因素。④交代清楚数据分析所使用的统计学分析软件及检验水准。常用的统计学分析软件包括SPSS、SAS、Epi-info、Stata和R软件等,检验水准一般设定为0.05或0.01,描述为“本研究以P<0.05提示差异有统计学意义”或“本研究以P<0.01提示差异有统计学意义”。在优效性设计、非劣性设计中,因统计学检验为单侧,检验水准调整为0.025或0.005。
在临床研究数据分析结果呈现的内容方面,观察性临床研究(现况研究、病例对照研究、队列研究等)一般应包括3个方面内容:①研究对象的一般人口学特征,以及与不同暴露组或不同病例分组研究对象一般人口学特征比较;②暴露因素和结局变量(疾病、死亡等)之间的单因素分析,包括潜在混杂因素与暴露因素和结局变量之间的单因素分析结果;③暴露因素和结局变量之间的多因素分析,以控制混杂因素,评估暴露因素与结局之间的单独效应。相比观察型临床研究,RCT呈现的分析结果则更加“固定”,一般包括1张图和3个表,研究者可参考本专栏往期刊登的文章《随机对照临床试验CONSORT声明解读》[2]。其中,1张图为“随机对照临床研究各实施阶段流程图”(图2),3个表分别为:①受试者一般情况表,包括试验组和对照组;②主要疗效指标和次要疗效指标评估表;③安全性和不良反应情况表。

3 临床研究数据分析要点和在SPSS软件中的实现
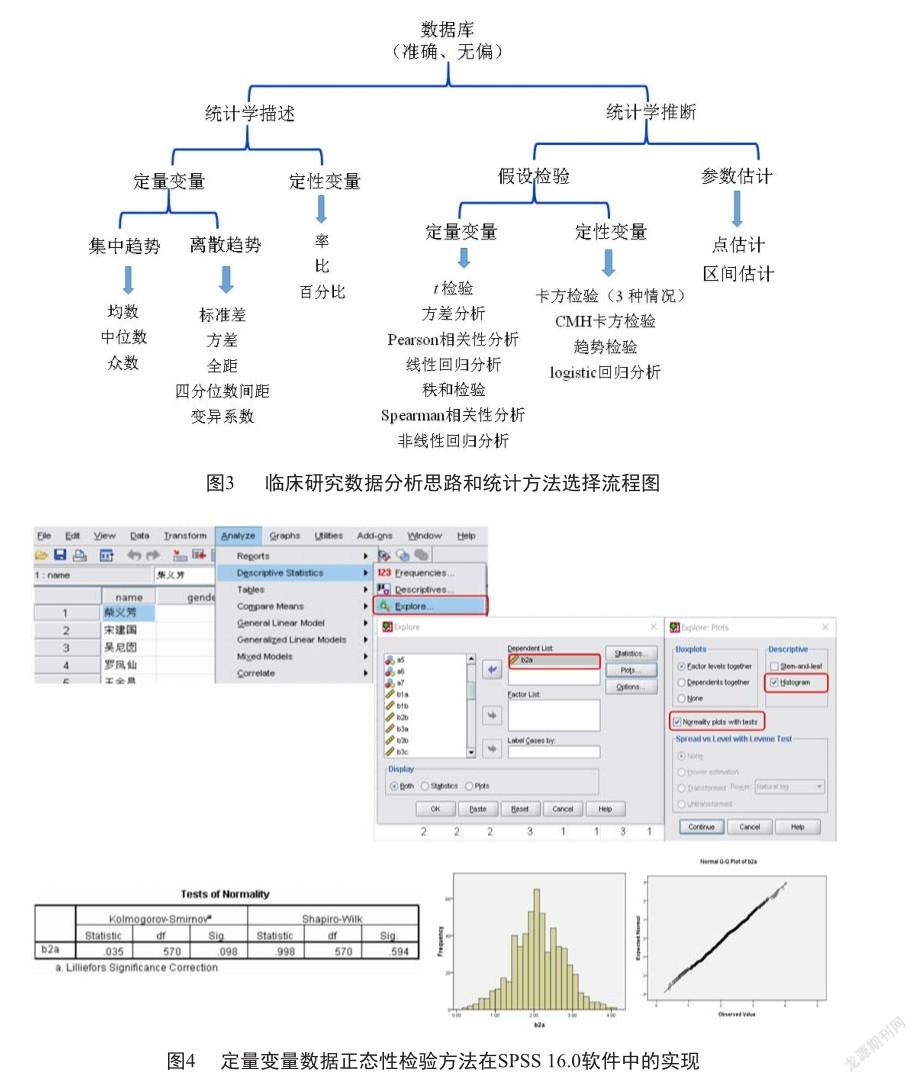
临床研究中,不同类型的设计其数据统计分析的整体思路实则一致,均包括统计学描述和统计学推断两个部分。如图3所示,临床研究数据统计分析方法的选择均基于变量类型,同时不同变量类型还须要根据其自身分布特点来进一步选择合适的指标和分析方法。统计分析方法选择这部分内容研究者可参考本专栏往期发表的《临床医学研究数据统计分析思路概述》[1]或查阅其他统计学书籍,不再赘述。本文将重点介绍临床研究数据统计过程中,研究者容易疏忽的细节,以及须注意的核心内容和易错点。
1)定量变量分布的正态性 临床研究数据统计分析实践中,许多研究者对定量变量直接选择均数±标准差进行描述,并应用t检验或方差分析进行组间差异的统计学检验。如前文所述,对于定量变量统计分析方法的选择须首先考虑其是否符合正态分布,随后才能相应地选择合适的指标和统计学检验方法。正态性检验在SPSS软件中可以用“explore”模块实现。具体操作如图4所示,选择“analyze→descriptive statistics→explore”后,在“dependent list”放入须要分析的变量(例如“b2a”),然后点击“plots”按钮,在“descriptive”处勾选“histogram”,并将“normality plots with tests”勾选上,最后再选择“continue→ok”即可。分析结果主要通过Sig值来判定,Shapiro-Wilk检验法对应的Sig值>0.05时,数据符合正态分布,频数图呈现“中间高,两边低,左右对称”的特征。当Shapiro-Wilk对应的Sig值<0.05时,数据将不符合正态分布。而Kolmogorov-Smirnov检验法则常用于样本量n>2 000时变量的正态性检验。
2)重复测量方差分析 RCT中,研究者常常设置多个疗效评价时间点,对于这种类型的定量变量数据,不能简单地使用不同评价时点测量值与基线测量值之间开展t检验来评估疗效,这时候应该选择重复测量方差分析,来分析不同组别、不同评估时间点干预措施临床疗效差异的“组间效应”“时间效应”和“组间与时间交互效应”。具体操作如图5所示,选择“analyze→general linear model→repeated measures”,在“define factors”中定义重复测量变量名称和次数,完成后点击“define”按钮,在“within subjects variables”中放入重复测量变量,在“between subjects factors”中放入组别变量,点击“plots”定义绘图,在“post hoc”和“options”定义数据分析结果展现内容,最后再点击“ok”即可。
3)χ2检验结果解读 对于定性变量组间比较,通常采用χ2检验。具体操作如图6所示,选择“analyze→descriptive statistics→crosstabs”,在“rows”和“columns”处放入要分析的变量,点击“statistics”按钮,勾选“chi-square”,然后点击“continue→ok”即可。这些操作过程对于研究者来说都比较熟悉,但须注意的是:不能把四格表χ2检验结果的第一行直接拿来使用,而是应该先看一下分析结果下方提示(“a.”“b.”“c.”)。其中,第1条提示四格表中每个格子期望值的大小,进而可以帮助研究者选择合适的统计量和P值:①当样本量n≥40,同时格子期望值T≥5,选择“Pearson chisquare”对应的统计量和P值;②当样本量n≥40,但有格子期望值1≤T<5时,采用连续性校正χ2检验,选择“continuity correction”对应的统计量和P值;③当总样本量n<40,或格子期望值T<1,采用Fisher确切概率法检验,即选择“Fisher’s exact test”对应的统计量与P值。


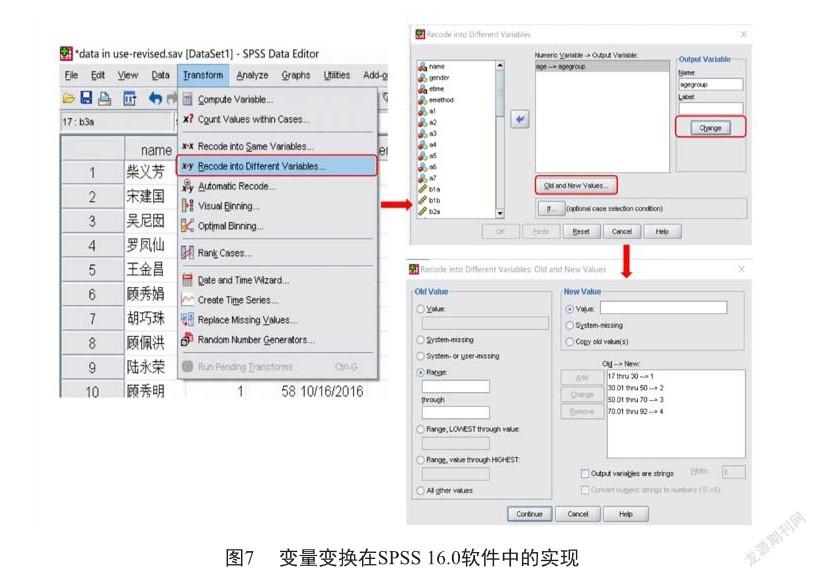
4)定量变量转换为定性变量 数据统计分析过程中,有时候须要将定量变量转换为定性变量进行分析,如将患者的“实际年龄”根据一定的规则转换为“年龄组”,这时候便要用到“transform”功能。具体操作如图7所示,选择“transform→x-y recode into different variable”,将须要进行转换的变量放入“numeric variable→output variable”框,在“output variable”中定义新的变量名称,点击“change”进行转换,然后再点击“old and new variable”打开一个新的对话框,在这个新对话框中,根据自己设定的规则,将定量变换转换为定性变量。须注意的是,尽管“transform→x-x recode into same variable”也可以使用,但這样的操作会覆盖掉原始变量值,无法恢复。因此,建议研究者优先使用“x-y recode into different variable”转换新变量。
5)logistic回归分析中多分类定性变量设置哑变量 在应用logistic模型进行回归分析时,如果自变量中包含多分类定性变量,须将其设置为哑变量放入模型,否则统计分析结果展示的将不是各分类之间的差别,而是1/2/3/4等数量之间的差异。具体操作如图8所示,选择“analyze→regression”,点击“binary logistic”打开对话框,在“dependent”框放入因变量,在“covariates”框放入自变量,然后点击“categorical”打开新的对话框,将须要设置为哑变量的变量名放入“categorical covariates”,在下方“contrast”设定“indicator”选择其余选项与第一个比(first)或其余选项与最后一个比(last),随后再选择“continue→ok”即可。

参考文献
[1] 王瑞平, 李斌. 临床医学研究数据统计分析思路概述[J].上海医药, 2022, 43(1): 7-9.
[2] Moher D, Hopewell S, Schulz KF, et al. CONSORT 2010说明与详述: 报告平行对照随机临床试验指南的更新[J]. 中西医结合学报, 2010, 8(8): 701-741.
[3] 王瑞平, 李斌. 随机对照临床试验CONSORT声明解读[J]. 上海医药, 2022, 43(5): 58-62.
猜你喜欢
中国民族民间医药·下半月(2016年12期)2017-01-19
风湿病与关节炎(2016年12期)2017-01-14
华夏医学(2016年4期)2016-12-12
中外医疗(2016年29期)2016-11-30
云南中医中药杂志(2016年9期)2016-11-29
医学信息(2016年29期)2016-11-28
中国实用医药(2016年17期)2016-07-26
饮食与健康·下旬刊(2016年7期)2016-05-10
中国实用医药(2016年11期)2016-05-04
中国实用医药(2016年8期)2016-03-30
