
基于FPGA的卷积神经网络并行加速设计
2022-07-21 04:11龚豪杰冯水春
计算机工程与设计 2022年7期
龚豪杰,周 海,冯水春
(1.中国科学院国家空间科学中心 复杂航天系统电子信息技术重点实验室,北京 101499; 2.中国科学院大学 计算机科学与技术学院,北京 101408)
0 引 言
随着卷积神经网络[1]算法在目标检测、目标跟踪[2]等领域的发展,卷积神经网络算法正在逐步取代传统算法。针对未来复杂多变的应用环境,空天领域也一直在推进智能化发展,发挥智能技术在空天领域建设中的引领作用[3],但由于卫星所处环境的特殊性,载荷在功耗、体积、材质等方面都有严格的限制,导致其存储、计算资源的稀缺性,如何将卷积神经网络模型部署到资源受限的嵌入式环境中成为了亟待解决的问题。
FPGA具有可重构、低功耗、可定制以及高性能等优势[4],可以高度并行地执行卷积神经网络模型中大量重复的乘加运算,并以较低的功耗完成高精度分类任务[5]。因此,FPGA在加速卷积神经网络方面具有自己独特的优势[6]。
基于FPGA的卷积神经网络优化加速是一个复杂的过程,设计方法也多种多样。Wang D设计流水线卷积计算内核来加速卷积计算[7];Eyeriss团队提出RS数据流以提高卷积计算的并行性[8];Liu等提出了一种大规模并行框架来提升卷积计算的吞吐量[9];张榜等通过双缓冲和流水线技术对卷积进行优化[10];Suda等提出一种系统化的设计空间探索算法以最大化吞吐量[11]。目前的研究虽然提出了多种技术来加速卷积神经网络,但都专注于某一方面的性能优化,并没有完全发挥FPGA的并行计算潜能。
本研究提出了一种卷积并行加速系统,利用层融合、数据分片、缓存设计、并行设计等多种优化策略加速卷积计算,与CPU、GPU平台以及其它FPGA平台设计方案相比综合性能有一定的提升。
1 卷积神经网络与层融合
1.1 卷积神经网络
为了提升卷积神经网络的性能,处理更复杂的任务场景,卷积神经网络的层级逐渐加深,结构也更加复杂。2012年,AlexNet奠定了卷积神经网络在图像处理领域的地位,网络层数只有8层;2014年,GoogLeNet通过不断复用inception结构来提升性能,卷积层数达22层;2016年,ResNet[12]利用残差结构将网络深度提升到152层。随着网络深度的增加,其特征表达能力会有一个实质性的突破。现如今,数千层的卷积神经网络已非常常见。
然后,深层网络也带来新的问题,首当其冲的就是训练难度加大,出现梯度消失和梯度爆炸,以及容易过拟合。因此,如今的深层网络通常都会在卷积层后加一层BN层,BN层可以有效加快网络的训练过程,防止梯度消失和梯度爆炸以及过拟合问题。
图1为ResNet(残差网络)的基础残差模块,包含两个主要部分:卷积层和BN层。卷积层是图形特征有效的提取器,BN层则可以解决隐藏层协变量偏移问题,使得非线性变换函数的输入值落入对输入比较敏感的区域,以防止梯度消失,并加快训练过程。
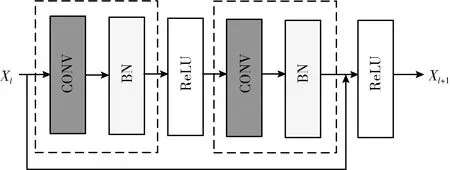
图1 残差模块
图2为卷积层的基本运算——卷积运算。卷积时将卷积核与输入特征图矩阵的局部做卷积运算得到输出特征图,局部大小取决于卷积核的大小,也即感受野的大小。其计算公式如下所示
(1)


图2 卷积运算
本文采用的卷积网络参数见表1。该网络结构包含6层卷积层,卷积核为3×3,移动步长为1。

表1 卷积网络配置参数
1.2 层融合
使用BN层是为了解决网络训练过程中的梯度消失和梯度爆炸问题并提高泛化性能,然而在前向推理过程中,使用训练后的数值固定的尺度因子γ和偏移因子β,以及每个通道的平均值μ与方差σ2的无偏估计计算BN层输出。卷积层与BN层在FPGA实现时很难共用同一套处理资源,导致BN层带来较大的额外资源开销,为了提升网络推理速度和降低资源消耗,可以将BN层与卷积层进行融合。BN层的计算公式如下
(2)
式中:μ表示输入数据的均值,σ2表示输入数据的方差。ε是分母添加的一个很小的值,防止分母为0。γ表示尺度因子,β表示偏移因子,是模型在训练过程中自动学习到的两个参数。将卷积式(3)带入到BN层计算式(2)中并展开得到式(4)
Y=W·X+b
(3)
(4)
由于BN层本身带有偏移因子,故卷积层的偏置b可以省略,因此融合后新卷积层的权重参数W′和偏置参数b′整理如下
(5)
(6)
融合卷积计算公式如下
Y′=W′X+b′
(7)
基于以上推理,将BN层在推理阶段完全融入到卷积计算中,而没有任何的精度损失,通过这种方式可以有效降低硬件计算量,减少资源消耗,加快推理过程。
2 基于FPGA的硬件设计
2.1 优化层级分析
随着网络的深度加深,结构更加复杂,将导致大量的特征图输入和权重输入,而片上存储器由于资源的限制不能存储所有的输入数据,因此需要较大的外部存储。本系统涉及3个层级存储模块:外部存储、片上缓存和寄存器级数据处理单元。外部存储器存储完整的网络模型数据,数据传输延迟是该部分主要的性能瓶颈,通过数据复用减少数据传输;片上存储器存储当前网络层的模型数据,存储资源限制是该部分主要的性能瓶颈,通过数据分片降低资源消耗;寄存器级存储单元存储处于计算状态的数据,计算并行性是该部分主要的性能瓶颈,通过循环展开提升计算并行性。系统数据调度如图3所示。

图3 数据流调度
输入数据流经过处理器端的处理和预加载,将输入图像和权重存入外部存储器DDR。PL端通过数据总线从外部存储读入当前卷积层和BN层的融合数据到片上缓存,然后输入到硬件加速模块,数据处理单元完成卷积运算,输出数据返回到片上存储,继续返回到外部存储器作为结果输出或作为下一层网络的输入。
2.2 加速器总体架构设计
加速器架构如图4所示,主要包括片上缓存、数据处理单元(PE)和控制器。片上缓存通过AXI总线与外部存储交流。

图4 加速器总体架构
由于卷积神经网络参数量大,FPGA片上存储资源有限,无法存储所有的参数。数据缓存操作包括数据加载和数据处理两部分,只有完成了数据加载之后才能对其中的数据进行后续处理。为了避免数据传输导致数据处理单元闲置的情况,本文采用双缓存机制,以图中权重缓存为例,当权重缓存1进行数据加载时,权重缓存2进行数据处理;当权重缓存2进行数据加载时,权重缓存1则进行数据处理。这种ping-pong RAM的工作模式可以保证在整个处理过程中,数据处理单元始终处于工作状态。同理,输入缓存也是如此,数据加载和数据处理完全并行操作,使数据处理模块的计算能力得到最大化利用。
卷积计算主要是权重矩阵与输入特征图进行乘累加运算得到输出特征图。相比于所有通道的输入卷积窗口参与卷积生成最终的输出通道数据,本设计使用部分通道的输入卷积窗口与所有的卷积核卷积生成中间结果,直到所有输入通道计算完成并累加到输出缓存生成最终输出通道数据,可以有效增加输入特征图的数据复用,减少其在BRAM和外部存储器之间的重复传输。
加速器处理流程如下,卷积层与BN层融合权重通过数据分片设计,输入到权重缓存。输入缓存生成多个通道的3×3卷积窗口,与权重同时输入到PE单元进行卷积运算,N个PE单元完全并行处理,控制器计算输出通道的索引值,通过索引值将运算结果输出到相应的输出缓存地址,由于输入特征图和权重进行了分片,计算结果是中间值,需要在输出缓存上进行累加。当所有的输入特征图计算完毕,输出缓存添加偏置,并通过控制器判断是否进行激活处理,激活函数使用ReLU函数。
2.3 层融合分片设计
本文采用的层融合分片设计如图5所示,矩阵代表完整的层融合输入权重矩阵,其中列数表示输入通道数,行数表示输出通道数,每个灰色框图表示一个3×3卷积核,实线框中矩阵即为数据分片后权重矩阵。本文在两个维度上进行数据分片,分别是输入通道N和输出通道M。在后续的卷积并行计算中,N表示输入通道并行度,M表示输出通道并行度。输入通道并行和输出通道并行在不同程度上影响计算资源的开销。在两个维度上设置分片参数,提升了数据分片和计算并行度的灵活性,能更充分利用平台的硬件资源。

图5 层融合数据分片
2.4 数据处理单元设计
数据处理单元结构如图6所示,每个虚线框代表一个数据处理单元,其内部为N个输入通道之间并行运算,需要N个不同的卷积核。虚线框之间为M个输出通道之间的并行运算,需要M组不同的卷积核。因此输入通道N和输出通道M决定了卷积计算的并行度。当N和M分别等于当前层的输入特征图数量和输出特征图数量时,卷积并行性达到理论最大值,但也会消耗大量的硬件资源。因此,可以利用设计空间探索,合理分配并行粒度以平衡计算性能和资源消耗。

图6 数据处理单元结构
2.5 数据复用和卷积计算优化
数据复用与卷积优化方案如图7所示,输入特征图按行顺序一行一行输入,每个像素值从第一次参与卷积计算到最后一次参与卷积计算,3×3卷积窗口会走过两个输入特征图行尺寸的距离,为了最大化输入特征值的复用机率,需要2倍特征图行尺寸大小的线性缓存存储访问过的特征值,这样当像素第二次进入卷积窗口时可以直接从线性缓存中顺序读取,降低了数据访问延迟。

图7 3×3卷积计算设计
本文采用3×3卷积核,卷积步长为1。卷积窗口向右滑动一个步长,只有最右边的一列需要更新,复用第一列和第二列的输入像素值,数据复用比例达66.7%。因此,本文采用两个线性缓存,分别是线性缓存1和线性缓存2,每个线性缓存的大小为输入特征图行尺寸大小。每个读数据阶段线性缓存工作流程如下:
(1)输入缓存输入一个数据到卷积窗口;
(2)同时线性缓存1按从左到右顺序存储该输入数据;
(3)如果线性缓存1数据存满,则从左到右依次更新数据,并将原始数据存入线性缓存2;
(4)如果线性缓存2数据存满,则从左到右依次更新数据,并丢弃原始数据。
如图7所示,线性缓存2负责更新卷积窗口第一行,线性缓存1负责更新第二行,每次从输入缓存读取的数据则负责更新第三行。卷积窗口的三行数据同时更新,读数据阶段需要两个时钟周期,一个时钟周期读地址,一个时钟周期读取数据,通过完全流水线结构,可以在每个时钟周期生成一个卷积窗口进行后续计算。
生成的卷积窗口与权重同时输入到卷积计算单元,卷积计算单元的乘法运算完全展开,之后输入到加法树,通过乘法阵列-加法树的模式最大化核卷积计算的并行性。
2.6 设计空间探索
由于不同的FPGA平台有不同的资源限制,为了更好匹配平台的资源限制,提升硬件资源利用率,本文提出了如表2所示的设计空间探索算法。

表2 设计空间探索伪代码
如伪代码所示,Cout表示输出特征图数量,Cin表示输入特征图数量。算法的输入是当前网络的参数和硬件资源约束,输出是网络的并行度,包括输入通道并行度N和输出通道并行度M。首先,初始化参数N和M,根据当前网络并行度参数运行网络,如果资源开销满足硬件资源约束,则继续判断网络的性能是否有提升,如果有提升则通过当前的并行度参数更新N和M,否则丢弃当前结果进入下一次迭代,直到找到最优的网络并行度参数,N和M确定了计算资源的使用量。通常情况下,卷积网络的通道数会随着网络加深而成倍增长,且本文卷积加速模块在不同卷积层间是复用的,因此在充分利用硬件资源情况下确定的初始卷积层的并行粒度可以沿用到后续网络层中。网络的并行粒度即为N×M。
3 实验结果
3.1 实验环境
本次实验使用Xilinx公司的ZCU104开发板作为实验平台,该芯片含有PL端1728个DSP48E单元,38 Mb RAM,以及PS端2 GB DDR4存储器件,完全可以满足本实验的硬件要求。实验数据位宽设定为浮点32位,FPGA主频设定为100 MHz。
此外还在CPU和GPU平台上进行计算性能测试,测试卷积网络模型为表1的卷积层2,CPU采用的是Inter Core i5-4210H,主频为2.90 GHz;GPU采用的是NVIDIA GTX1080ti,显存容量为11 GB,核心频率为1.582 GHz。
3.2 功能验证
本实验基于Vivado_hls 2020.1和Vivado 2020.1软件进行开发和仿真,仿真波形如图8所示。卷积的输入、权值和偏置都为32位浮点数据,输入时钟频率为100 MHz,时钟波形如图8中矩形框2所示。图8所示波形包括待测加速器的波形信号和Test Bench Signals,为验证加速器功能正确性,这里关注这两个信号的输出波形,即ofm波形。当输出波形的写使能信号ofm_we0和片选信号ofm_ce0置高位1时,输出数据信号ofm_d0有效。矩形框1为待测加速器的输出数据信号,矩形框3为理论输出数据信号,可以看到,加速器的卷积输出结果与理论输出值完全相等,从而验证了卷积加速器的功能的正确性。

图8 卷积模块仿真波形
3.3 资源使用
本次实验设计经过综合之后,Vivado HLS 2020.1给出了FPGA硬件资源使用情况。根据2.6节设计空间探索的结果,本文使用的输入通道并行度参数N=8,输出通道并行度参数M=4,卷积层在浮点32位运算下的资源使用情况见表3。FPGA工作在100 MHz下,由于输出缓存需要存储中间结果,分片后的部分权重和部分输入数据也存储在片上RAM,所以BRAM和URAM使用资源较高,分别达到53%和46%。乘法运算逻辑全部使用DSP资源,使用率达到83%;此外,LUT资源使用率也达到了93%,可以看出本文设计对资源的利用率已经很高。

表3 FPGA资源利用率
3.4 性能比较
由于不同文献使用的FPGA器件和网络结构不同,如果仅采用前向推理的时延和平台功耗,无法有效和公正地对比不同设计架构的优劣。此外,考虑到不同方法的资源利用效率存在差异,卷积运算过程主要是乘加运算。因此,本文提出DSP效率作为性能评估依据。DSP是卷积计算中使用的主要资源,通常情况下加速器的吞吐量与硬件平台的DSP数量呈正相关趋势,DSP效率表示单位DSP所能提供的GFLOPS,可以避免不同硬件平台DSP数量差异带来的影响,从而更有效比较不同设计方案的性能优劣。本文同时增加能效比参数以便全面对比不同方法的加速效果。
各卷积层的时延和性能见表4。时间延迟主要包括数据传输和卷积计算的延时。网络整体的平均性能为35.45 GFLOPS。

表4 各卷积层的性能对比
通过本次设计的板级测试,得到系统的性能和功耗等数据与其它文献的对比见表5。文献[13]使用循环展开并行处理和多级流水线加速卷积神经网络,但没有设计片上缓存结构来提升数据访问效率,在DSP效率和能效比上远低于本设计。文献[11]利用设计空间探索寻找最优的计算并行性来最大化系统吞吐量,但没有充分设计片上缓存的数据复用方案,DSP效率虽然高于本文,但是本文的能耗比更高,是其1.5倍,且本文使用32位浮点数表示,计算精度高于其16位定点数。综上所述,本文设计的加速方案在利用了缓存设计、并行设计、数据复用以及设计空间探索等多种优化设计的基础上,具有更高的综合性能。在硬件资源和功耗严格受限的嵌入式平台中,本设计相比表中其它方案,在单位能量上贡献更高的计算量。

表5 与其它文献方法的对比
在100 MHz的工作频率下,数据处理单元处理一次8×56×56的输入特征图,通过4×8×3×3的卷积核生成4×56×56的输出特征图的卷积计算,计算量为1 806 336 FLOPS,数据处理单元的运行时间为34.37 μs,卷积计算的峰值性能为52.56 GFLOPS。
表6为本文设计的卷积峰值计算性能与CPU、GPU以及文献[14]的对比,计算性能是CPU的4.1倍,功耗仅为GPU的9.9%。相比文献[14],本文利用设计空间探索充分挖掘卷积计算的并行性,本文设计的卷积计算性能是其1.4倍。

表6 卷积计算性能的比较
4 结束语
针对如何提升运行在嵌入式平台的深度卷积神经网络的速度和能效,本文提出了一种卷积并行加速架构。该架构首先利用卷积层和BN层融合算法降低计算复杂度,通过层融合的分片设计,降低片上存储的资源消耗。为了优化内存,本文提出了一种双线性缓存设计,有效提高了数据复用效率,并利用ping-pong RAM的缓存方式和数据并行计算提高数据吞吐量。同时,利用设计空间探索寻找最优的计算并行度,从而最大化资源利用率。
实验结果表明,与CPU、GPU和其它FPGA平台的实现对比,本文提出的方法在性能、能耗以及资源利用率方面具有更高的综合性能,对于在资源和功耗严格受限的嵌入式环境中部署深度卷积网络,实现航天电子系统的智能化处理具有意义。
猜你喜欢
词学(2022年1期)2022-10-27
计算机系统应用(2022年5期)2022-06-27
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2020年6期)2020-06-24
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
火控雷达技术(2018年4期)2019-01-15
北京航空航天大学学报(2018年1期)2018-04-20
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
