
基于单哈希计数布隆的DDS自动发现算法
2022-07-21 04:11樊智勇刘哲旭李伯宁
计算机工程与设计 2022年7期
樊智勇,张 同,刘哲旭,李伯宁
(1.中国民航大学 工程训练中心,天津 300300; 2.中国民航大学 电子信息与自动化学院,天津 300300)
0 引 言
数据分发服务DDS(data distribute service)[1,2]是由对象管理组织OMG(object management group)制定的以数据为中心的发布/订阅通信模型规范,其采用简单发现协议SDP(simple discovery protocol)来交换Publisher与Subscriber之间的实体数据[3]。在中小型分布式仿真系统得到良好应用,但当系统规模较大、数据交互较多时,SDP会造成网络传输量高、内存消耗大等问题。针对这一问题,文献[4]提出SDPBloom(Bloom filter simple discovery protocol)自动发现算法,通过将端点描述信息存储到Bloom过滤器中发送给其他参与者,可以减少网络传输量与内存消耗,但是该算法不支持元素删除操作,且在运算过程中需要较多的哈希函数,时间消耗成本较大。文献[5]提出一种单哈希阈值布隆过滤器DDS自动发现算法,通过调整阈值θ和判定阈值T进行端点信息的查询匹配,降低了DDS在自动发现过程中的误报以及网络传输量。文献[6]将可压缩布隆过滤器应用到DDS自动发现算法中,在一定程度上降低了网络传输量与内存消耗。文献[7]提出一种基于分层布隆过滤器的DDS自动发现算法,通过改进原有的链式储存结构以及增加节点删除操作,有效降低内存消耗。
在以上研究基础上,本文提出一种基于单哈希计数布隆过滤器的自动发现算法(simple discovery protocol_one hash counting Bloom filter,SDP_OHCBF),该算法通过使用计数布隆过滤器[8]来支持元素删除操作,同时使用单个哈希和取模运算来代替标准布隆过滤器中的多个哈希函数,减少哈希运算成本,从而加快DDS的自动发现过程,实现对分布式仿真系统的实时性优化。
1 基于DDS的简单发现协议
1.1 DDS
DDS中的域是指在逻辑上将应用系统进行隔离的通信网络,其不受其它应用程序的影响,域参与者(domain participant)作为域中数据通信互动的进入点,主要包括发布者(publisher)、订阅者(subscriber)和主题(topic),它们又包括数据写入者(data writer)和数据读取者(data reader)[9]。只有在同一个域中的参与者,且当数据的主题名称、主题类型相同且QoS策略相互兼容时,数据写入者与数据读取者才可以相互通信,其中全局数据空间GDS主要负责完成发布者与订阅者、主题与QoS策略的管理与匹配工作,即自动地将发布者发布的数据有效地传送给感兴趣的订阅者[10,11],DDS的通信结构如图1所示。

图1 DDS的通信结构
1.2 简单发现协议
DDS通过匹配主题信息以及QoS策略是否兼容,从而将发布者发布的信息发送到订阅者,这一过程的实现需要复杂的内部数据结构、高效的发布/订阅匹配技术以及自动发现算法做支撑,其中简单发现协议是DDS的核心技术,其可以分为两个阶段:简单参与者发现协议阶段(simple participant discovery protocol,SPDP)和简单端点发现协议阶段(simple endpoint discovery protocol,SEDP)[12]。
简单参与者发现阶段:主要负责完成同一域中的本地参与者与远程参与者的自动发现。本地域参与者通过DDS内置的数据写入者将参与者数据包发送给其远程域参与者,同时通过内置的数据读取者接收其他远程参与者的数据包,这个参与者数据包包含域参与者的唯一标识号GUID、地址、端口号以及QoS策略等信息,这些信息通过高效(best effort)组播方式进行传输。
简单端点发现阶段:在参与者相互发现的基础上,主要负责交换本地参与者与远程参与者的数据写入者的发布端点描述信息与数据读取者的订阅端点描述信息,这些端点描述信息包括设置的标识号GUID、QoS策略等,经DDS全局数据空间进行匹配,若匹配成功,则通过可靠(reliable)传输方式进行端点之间的发布和订阅,DDS的简单发现协议过程如图2所示。

图2 SDP自动发现过程
在DDS简单发现协议过程中,每个参与者都需要将自己所有的发布/订阅端点信息发送给域中其他参与者,同时也要接收其他参与者发送的所有发布/订阅端点信息,然而参与者只关心与自己主题相关以及QoS策略相互兼容的发布/订阅端点信息,这就造成网络传输量高、内存消耗大的问题,故本文提出一种基于单哈希计数布隆过滤器的DDS自动发现算法。
2 OHCBF的设计与理论分析
2.1 OHCBF的设计

OHCBF将散列映射过程分为两个阶段[15]:
哈希阶段:通过使用单哈希函数h(x)将集合U中的元素xi映射成机器字W;
取模运算阶段:通过取模运算 |T|(h(x) modmi) 将机器字W映射成向量组中的目标元素T,同时将该分区内相应位置的计数器加1。
OHCBF的结构如图3所示,其中假设k=3,n=3,m1=5,m2=7,m3=11,即3个元素 (x1,x2,x3) 通过单个哈希函数h(x)映射和取模运算存储到布隆过滤器OHCBF中。当存储元素x1时,首先应用哈希函数h(x)将其映射成机器字,设h(x1)=1987, 然后对其进行取模运算,g1(x1)=h(x1)modm1=2,g2(x1)=h(x1)modm2=3,g3(x1)=h(x1)modm3=4, 则向量组中对应分区的第2位,第3位,第4位计数器加1,同理元素x2,x3的插入过程类似。

图3 OHCBF结构
2.2 OHCBF的理论分析
2.2.1 OHCBF的计数器大小设定
OHCBF通过多占用存储空间给Bloom过滤器增加了元素删除操作,但为使占用空间最小,需要计算出OHCBF中的计数器大小[16]。设OHCBF中的计数器大小为j,则第i个计数器被映射j次的概率为P(c(i)=j), 其中
(1)
(2)

(3)
当j=16,即计数器为4位时,计数器会溢出,其概率为
(4)
这个概率值很小,所以当计数器位数为4时,对大多数程序来说足够使用。
2.2.2 OHCBF的独立性约束
在OHCBF中,k个哈希值全都来自于同一个哈希函数以及取模运算,大大减少了哈希计算时间,但为了使OHCBF和SDPBloom产生相同的误报效果,保证哈希函数的原有性能,需要保证OHCBF中的单哈希函数在散列过程中生成的k个哈希值和在标准布隆过滤器中由k个哈希函数映射生成的k个哈希值具有相同的独立性,即在OHCBF中,需要保证每个分区大小为互质,这样才会产生独立的取模结果,更确切地来说,让gi(x)=h(x)modmi, 1≤i≤k, 如果 (mi,mj)=1, 1≤i 若每个分区大小不是相对素数,则在取模运算阶段会产生一定的相关性。如在OHCBF中设其有两个分区,其大小分别为m1=4,m2=6,则经过哈希映射和取模运算后,发现当g2(x)=0或2时,g1(x)=0, 当g2(x)=1或3时,g1(x)=1, 即g1(x) 与g2(x) 具有一定的关联性,这将达不到独立的取模效果。 2.2.3 OHCBF的误报分析 在标准布隆过滤器中,通过使用k个哈希函数将集合U中的n个元素映射到m位数组中时,某一位数组仍为0的概率为[17] (5) (6) (7) (8) (9) 同理可得取模余数发生碰撞导致的误报率为 (10) 通常情况下由于机器字的空间范围要远远大于位向量,即2L≫m, 所以只要机器字的存储空间足够大,则机器字发生碰撞的概率会很小,在实际操作过程中P(A)近似为零,因此,OHCBF的误报率近似为 (11) 本文将OHCBF应用到DDS的自动发现过程中,以远程参与者B向本地参与者A订阅端点信息为例,具体说明DDS的自动发现过程,如图4所示。 图4 SDP_OHCBF的自动发现过程 在SDP_OHCBF的参与者发现阶段,本地参与者A和远程参与者B创建OHCBF向量;将端口变量数据的端点描述信息经过单个哈希函数和取模运算映射到k个不均匀分区的mi(1≤i≤k) 位OHCBF中,其中k个位置的位向量计数器加1,如果该位置被多次映射,则进行累加,将自己所包含的端点描述信息存储到OHCBF向量中;本地参与者A的端点描述信息通过参与者数据包一起发送给远程参与者B,用来宣布本身存在信息,同时接收远程参与者B发送的包含端点描述信息的OHCBF向量,本文使用主题名称作为参与者端点描述信息的唯一标识符,从而进行端点信息匹配;当远程参与者B获取到包含本地参与者A端点描述信息的OHCBF向量时,通过单个哈希函数和取模运算进行数据查询,判断k个位置的位向量是否为非0,若为非0,判断该元素在本地参与者A中,则将OHCBF添加到本地信息库中,进入到端点发现阶段,否则忽略该信息;同理,当本地参与者A获得远程参与者B的信息时,执行相同步骤。至此,本地参与者A与远程参与者B交换了彼此的端点描述信息并对其进行存储,完成了参与者发现过程。 在端点发现阶段,远程参与者B通过对存储的本地参与者A端点描述信息的OHCBF向量进行查询,这一阶段通过参与者创建的数据写入者与数据读取者分别进行匹配,远程参与者B将获得的本地参与者A发布的端点描述信息与自身需要订阅的端点信息进行匹配,若匹配成功,则向本地参与者A发送订阅请求;本地参与者A将被订阅的包含主题以及QoS服务质量的端点具体信息发送到远程参与者B进行再匹配;若匹配成功,则远程参与者B的订阅端点与本地参与者A的发布端点建立数据通信,若匹配不成功,则发生误报,向远程参与者B的订阅端点发送“本地没有相关端点信息”。通过此种方式改变了DDS参与者之间的对话方式,即不需将自己拥有的所有信息全部发送给其他参与者,只需告诉其他参与者自己拥有哪些信息即可。 将端点描述信息存储在OHCBF向量中,设置主题名称进行参与者之间的通信,假定域中参与者个数为P,其包含的端点总数为E,默认在每个参与者中拥有同样多的端点数,即每个参与者均有E/P个端点,且不考虑心跳机制。定义ME(match endpoint)为Bloom过滤器中每个参与者匹配的端点数与端点总数的平均比率,MEBF为SDPBloom中匹配的端点总数,MEOHCBF为SDP_OHCBF中匹配的端点总数,MEBF和MEOHCBF决定了参与者在端点发现阶段需要发送和接收的端点信息数。由于在SDP中每个参与者需要向其他参与者发送自己所有的发布/订阅端点信息,所以其发送的消息数为E,而在SDPBloom与SDP_OHCBF中,每个参与者通过将端点描述信息存储到BF和OHCBF向量中,可以筛选掉因主题不匹配的端点信息,所以E远大于MEBF和MEOHCBF。 在不使用多播情况下,SDP、SDPBloom、SDP_OHCBF这3种算法中每一个参与者需要发送和接收的端点消息为 (12) (13) (14) 在SDP过程中,每一个参与者需要存储域中其他参与者的所有端点信息,而在SDPBloom、SDP_OHCBF中,每一个参与者不仅需要保存本身自带的端点信息和在参与者发现阶段附带的过滤器向量信息,还要存储通过布隆过滤器向量匹配上的端点信息,所以在这3种自动发现算法中,每个参与者所占用的消耗内存为 MSDP=E (15) (16) (17) 由式(15)~式(17)可知,SDPBloom、SDP_OHCBF与SDP相比,通过使用布隆过滤器可以大大减少自动发现过程中的网络传输量与内存消耗,同时SDPBloom和SDP_OHCBF的网络传输量与消耗内存与端点匹配数相关。 基于RTI_DDS的分布式仿真平台具有10个仿真节点,同时含有利用Matlab/Simulink、AMESim、Flightsim、C/C++等专业仿真软件建立的仿真模型。在该平台上将本文提出的改进算法SDP_OHCBF与SDP、SDPBloom算法在网络传输量、内存消耗、误报率以及查询时间4个方面进行仿真实验验证。 在本实验中,一个仿真模型作为一个参与者,一共有P个参与者,每个仿真模型有100个模型端口变量(端点),一共有100*P个端点。每个端点信息为6000字节,端点描述信息为4字节,在SDPBloom与SDP_OHCBF中,用来存储端点描述信息的布隆过滤器位向量为64字节。 在端点发现阶段,当端点匹配率为ME=0.1、ME=0.2、ME=0.5时,SDP、SDPBloom和SDP_OHCBF的网络传输量随参与者数量的变化情况如图5所示。 图5 网络传输量 随着参与者数量增加,端点数也增加,SDP、SDPBloom和SDP_OHCBF的内存消耗也随着参与者数量增加而发生变化,图6与图7分别为匹配端点率为ME=0.1、ME=0.2的内存消耗变化情况。 图6 ME=0.1的内存消耗 图7 ME=0.2的内存消耗 从图5~图7可以看出: (1)SDP在整个自动发现过程中的网络传输量较SDPBloom和SDP_OHCBF大,且发送的信息数不随端点匹配率ME的变化而变化,所以SDP需要更大的消耗内存来存储远程端点信息;当端点匹配率越小,SDPBloom和SDP_OHCBF的优势就越明显; (2)无论端点匹配率ME如何变化,SDPBloom和SDP_OHCBF的内存消耗都近似相同且远远小于SDP,说明通过使用布隆过滤器可以大大减少端点存储信息,减少不必要的内存消耗。 本实验负责对SDPBloom与SDP_OHCBF的误报率与查询时间进行仿真验证,与以上实验条件相同,每个参与者都有100个端点描述信息映射到SDPBloom和SDP_OHCBF向量中,每个端点描述信息为4字节。令n=100,k=3,mt为SDPBloom的位向量长度,ms为SDP_OHCBF的位向量长度,其中SDP_OHCBF的哈希函数设置为MD2,SDPBloom的哈希函数设置为MD5、MD2和SHA-1,表1为SDPBloom和SDP_OHCBF的误报率。 由表1可得,随着布隆过滤器位向量m的变化,SDP_OHCBF的误报率与SDPBloom的误报率近似相等,且随着m逐渐增大,SDPBloom与SDP_OHCBF的误报率越来越小。 表1 SDPBloom和SDP_OHCBF的误报率 当SDPBloom与SDP_OHCBF查询100个成员元素,端点匹配率ME=0.5时,随着布隆过滤器位向量m长度变化,其所需查询时间如图8所示。 图8 随m位向量变化所需查询时间 当SDPBloom位向量长度m为1000,SDP_OHCBF位向量长度m为1009时,随着100个元素中端点匹配率ME从0到1的变化,SDPBloom与SDP_OHCBF所需查询时间对比如图9所示。 图9 随端点匹配率ME变化所需查询时间 由图8、图9可以看出,无论是随着布隆过滤器的位向量大小变化还是查询成员与非成员的比例变化,SDP_OHCBF与SDPBloom相比,都花费较少的哈希运算时间,因此SDP_OHCBF具有更好的实时性,这大大提高了DDS自动发布/订阅的过程。 本文在对DDS的自动发现算法SDP以及常规改进算法SDPBloom的研究基础上,提出一种DDS自动发现算法SDP_OHCBF,通过将标准布隆过滤器升级为计数布隆过滤器,使之无需重新构建布隆过滤器以支持元素删除操作,同时使用单个哈希函数以及简单取模运算代替标准布隆过滤器中的多个哈希运算。通过仿真实验验证,SDP_OHCBF与SDPBloom在网络传输量、内存消耗以及误报率基本保持一致的情况下,大大减少了哈希运算时间,提高了DDS自动发现过程的实时性。该算法在多电飞机分布式仿真系统中得到良好应用,加快了机电系统模型分布式仿真的数据交互过程,为接下来优化飞机机电系统分布式协同仿真提供了良好的实时性。但是该算法目前没有将QoS考虑进去,无法预先在参与者发现阶段完成对QoS的判断,接下来将深入研究如何在SDP_OHCBF的基础上加上对QoS的判断,进一步提高其应用价值。
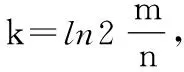

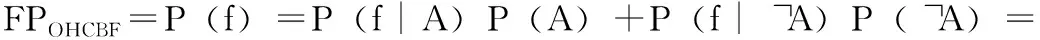


3 用于数据分发服务的SDP_OHCBF
3.1 基于SDP_OHCBF的自动发现过程

3.2 基于SDP_OHCBF的性能分析
4 实验验证与结果分析
4.1 网络传输量与内存消耗



4.2 误报率与查询时间



5 结束语
猜你喜欢
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
语数外学习·高中版中旬(2020年8期)2020-09-10
文萃报·周二版(2020年32期)2020-09-02
中学生数理化·教与学(2019年8期)2019-09-18
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电脑爱好者(2015年13期)2015-09-10
