
基于BLSTM-CTC的语音特征的音素识别研究
2022-07-23 15:51吴丹丹夏秀渝
现代计算机 2022年10期
吴丹丹,夏秀渝
(四川大学电子信息学院,成都 610065)
0 引言
音素作为自然语言体系中的最小单位,可以构成更复杂的字、词或者句子,根据此特性可以将它应用于关键词的识别和语音识别。音素相比于其它字词单元来说,其规模较小、更易训练,对训练设备的要求更低。音素识别可以用在关键词识别之中,通过音素先判断该语音流中是否可能存在该词,通过对音素的定位快速判断该词可能出现的位置,进而快速地找到关键词。除此之外也可以应用于语音识别中,通过识别出的音素来构建字词,可以和目前的语音识别方法进行融合从而提高识别性能。
总而言之,音素识别因其自身的规模小、泛型高的特点,可以应用在许多场合。所以音素识别的研究价值和应用领域还是值得研究者们花大量精力去探索。
传统的语音识别模型大部分都是利用高斯混合-隐马尔科夫模型(Gaussian Mixture Model-Hidden Markov Model,GMM-HMM),该系统性能的提升随着应用需求的加大受到了限制;随着深度学习的兴起,深层神经网络与隐马尔可夫的结合(Deep Neural Network-Hidden Markov Model,DNN-HMM)相比于传统的系统模型,其性能上有了很大的提升;针对深层神经网络无法解决序列上下文的问题,研究者们提出了循环神经网络(Recurrent Neural Network,RNN);但由于循环神经网络会存在梯度消失问题,长短时记忆网络(Long Short-Term Memory,LSTM)以及双向长短时记忆网络(Bi-directional Long Short-Term Memory,BLSTM)也随之被提出。之前的语音识别系统的过程是将声学模型和语言模型分开训练,并且在训练过程中会出现音频与标签的对齐问题,为了解决这一问题,研究人员提出了端到端模型。相比于目前兴起的注意力机制(attention)、时序联接机制(Connectionist Temporal Classification,CTC),其规模更小,对数据量和网络训练设备的要求更低。语音识别是将提供给系统的音频数据经过一系列的处理之后,得到人们能明白的语言文本,即将语音翻译为文字。音素识别的过程与之大体相同,只是最后翻译得到的文本为音素,因此语音识别的技术也可以用于音素识别。
传统语音识别的关键技术大概分为三个部分:①语音信息的提取及处理;②声学建模;③语言模型的建立。本文搭建的系统为端到端模型,因此没有第三个语言模型的搭建。本文结合双向长短时记忆网络(BLSTM)和时序联接机制(CTC)搭建音素识别系统,在系统建立的过程中,先后分别加入DNN网络优化网络。除此之外,在特征数据处理方面主要利用基于幅度信息和相位信息对音频数据提取特征,然后对数据进行规范化处理,最后对比实验效果。
1 语音特征
语音特征在语音识别系统中占据着很重要的地位,因此对语音特征的研究一直也是语音识别的热门方向之一,不同的语音特征可能有不同的效果,对网络模型的契合度可能也有所不同。所以在进行语音特征的选取和改进实验时,需要对所研究的内容和语音有一定的了解分析。
1.1 特征提取
目前常用的语音特征参数为梅尔倒谱系数(Mel Frequency Cepstral Coeffificients,MFCC),该特征在语音研究的各个领域都很流行。本文所采用的基于幅度的频谱根倒谱系数(Magni⁃tudebased Spectral Root Cepstral Coeffificients,MSRCC)和基于相位的频谱根倒谱系数(Phase⁃based Spectral Root Cepstral Coeffificients,PSRCC)。与MFCC相比,这一组特征主要使用了幂律非线性技术,其可以将比较低的幅度信号的响应归于零,而不像MFCC趋近于负无穷,除此之外还提取到了相位特征,对幅度特征补充了语音信息,综合发现该组特征具有较好的分类效果。该组特征提取的原理如图1所示。
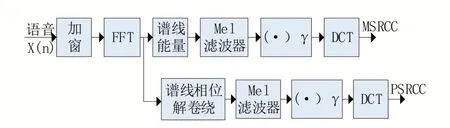
图1 MSRCC和PSRCC特征原理图
通过图1可以看出,MSRCC与MFCC特征的主要不同是梅尔谱能量逆变换取次方得到次方,离散余弦变换(DCT)将个实数系数通过逆变换得到q个实数独立的倒谱系数,即可以获得语音信号的主要信息,如公式(1)所示:

梅尔谱如公式(2)所示:
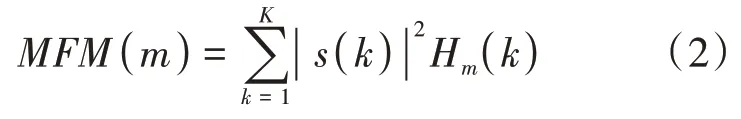
其中,()代表时域信号()的点DFT,H ()代表Mel滤波器的频率响应。
PSRCC特征是利用时域信号的短时傅里叶变换的相位信息,与MSRCC特征不同的是将MSRCC特征中的能量系数用相位系数代替,如公式(3)所示:

梅尔频率相位如公式(4)所示:

1.2 动态语音特征
动态语音特征如对特征参数取一阶差分或二阶差分,其对神经网络的识别性能有不小的提升,一阶差分或者二阶差分在现实生活中有实际的物理意义,即速度和加速度,计算方式很简单。所以本文也研究语音特征的动态性。
一阶差分就是离散函数中连续相邻两项之差,原理如公式(5)所示:

其中()为原始信号,Δ()为一阶差分信号。物理意义就是当前语音帧与前一帧之间的关系,体现帧与帧(相邻两帧)之间的联系;在一阶差分的基础上,提取二阶差分,原理如公式(6)所示:

其中Δ()为一阶差分信号,Δ()为二阶差分信号。二阶差分表示的是一阶差分与一阶差分之间的关系,即前一阶差分与后一阶差分之间的关系,体现到帧上就是相邻三帧之间的动态关系。
1.3 特征向量归一化
数据规范化是数据处理常用的一种技术,目前常用的规范化方法有最大值-最小值规范化、零均值规范化、小数定标规范化,本文采用零均值规范化,规范的方式如公式(7)所示:
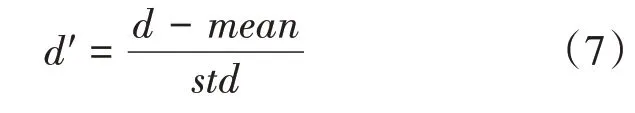
其中,,std,'依次代表原始数据、原始数据的均值、原始数据的方差及规范后的数据。该过程可以将提取的语音特征数据统一尺度,有利于之后网络模型参数的调节,加快训练和网络的收敛。
2 模型构建
声学建模是本文搭建的音素识别系统的一个重要分支,其系统的构建极大地影响着识别性能,本文主要是结合双向长短时记忆网络(BLSTM)和联接时序分类(CTC),该模型的构建简化了音素识别的过程且能更好地利用时序上下文的信息。
2.1 双向长短时记忆网络(BLSTM)
RNN利用序列信号的上下文信息,将过去的输入和现在的输入一起映射到现在的输出,从而改善网络的性能,一定程度上提升音素识别系统的性能,但是循环神经网络由于误差信号在后向计算时存在梯度爆炸和梯度消失的问题,导致RNN很难较好地处理长期依赖的序列信号。LSTM的提出较好地解决了循环神经网络中的问题,LSTM网络引入门的概念来控制网络的输入与输出,优化了网络模型。LSTM网络的结构如图2所示。LSTM网络有三个门,输入门、忘记门和输出门;通过门来控制和维护单元状态。,,,分别代表遗忘门、输入门、输出门和cell状态。

图2 LSTM单元结构图
LSTM的工作原理如下:
(1)忘记门决定从细胞单元中遗忘的东西,过程可由公式(8)表示,其中是激活函数,h 是隐藏值向量,代表各个部分的偏移量,是权重。

(2)输入门控制哪些信息可以输入到输入门中,这一过程由两个部分共同决定,一部分通过激活函数,另一部分通过tanh层得到一个新的候选值向量,如公式(9)和公式(10)所示:

(3)更新单元状态,C 变为C ,把原来的单元状态与f 相乘,丢弃无用的信息,随后将更新的状态C 与输入信号i 相卷积之后与之相加,据此可以得到新的候选向量,如公式(11)所示:

(4)计算输出信号的大小,输出值依赖于cell单元各个部分的状态,且是经过过滤的值,先通过激活函数得到输出信号部分,之后再将cell单元通过tanh层,最后将这两个值相乘得到我们需要的有用的输出信号信息,如公式(12)和公式(13)所示:

由以上可知,LSTM网络可以很好地解决循环卷积网络的梯度消失和爆炸的问题,但它只考虑了当前时刻和过去时刻信号的信息,未能利用将来时刻的信号,没有很好地处理长期依赖的信号。BLSTM针对这一问题提出双向传递的概念,通过前向传播和后向传播,使网络能够充分利用输入信号各个时刻的值来训练调节网络,更好地学习模仿信号的特点。BLSTM网络结构如图3所示。此网络利用两个单向的LSTM网络叠加在一起,可以较好地应用序列信号过去和未来时刻的信息,即上下文信息来优化网络的结构。

图3 BLSTM网络结构图
2.2 联接时序分类(CTC)
在端到端模型被提出之前,音素识别系统的建立大部分都是将语音按音素切分好,然后再分帧打标签,这个过程十分繁琐,而且误差也受切分音素的操作误差影响,费时费力。CTC目标函数的提出极大地简化了音素识别系统的步骤,使整个网络不再需要语言模型,标签可以不需要按帧对齐,系统可以输入整句语音直接识别出整句话的音素,这对语音研究带来了里程碑式的影响。CTC目标函数的工作原理是在网络模型的预测过程中加入空白标签来使输入序列和输出序列对齐,然后在最后阶段删除重复的字符和空白标签来得到准确的输出信号。


其中,为所有标签个数(CTC网络输出层节点个数),CTC目标函数学习得到的长度为的标注序列,是由63个音素和blank构成的,那么整个序列的概率为:

对于给定的目标序列,由于其他标注的重复性存在以及blank插入的位置不同,与存在多对一的关系,所以可以把上述关系重写如下:
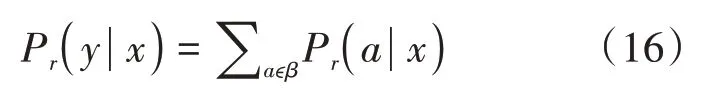
其中,是→的映射,表示的逆过程。映射函数先将重复相邻的标签合并,然后再去除空标签,最后确定,CTC目标函数如公式(17)所示:

CTC目标函数最后的输出表示转换概率,该网络在连续的时间里除去了映射重复的标签,这样使得网络变得更加复杂,所以将空白结尾的对齐和标签结尾的对齐分开,CTC目标函数的最佳结果就是找到概率最大的输出序列,由公式(18)表示:

其中为T帧输入序列的后验概率最大的输出标签序列。
3 实验
3.1 实验数据
本文是采用TIMIT语音数据集进行实验评估。该数据集来自美国8个主要方言地区的630位说话者,说话者大部分为白人男性,每个说话人讲10个句子,TIMIT库主要设计了三种类型的句子:①SA-方言句子,该句子体现了不同地区方言的差别,该句子不适合音素识别;②SX-音素紧凑的句子,由MIT设计,里面的句子音素分布平衡;③SI-音素发散的句子,目的是增加句子类型和音素文本多样性。因本实验为完成连续语音的音素识别,所以舍弃SA-方言句子,利用训练集中的所有SX和SI句子,总计5040句。测试集使用测试数据集中的200条句子,即每个区域随机选取25句。
3.2 实验评测标准
本文使用训练和测试网络分开的原则,先将模型完全训练之后再进行测试。评价指标采用CTC损失函数(CTC-loss)和音素标签识别错误率(LER)。
3.2.1 CTC损失函数
CTC损失函数是衡量CTC网络是否优良的一个常用指标,用来表示在给定当前的参数下的网络模型和理想模型的差距,将此用来调整网络模型的参数,从而调整网络。CTC损失函数的表示如公式(19)所示:

其中P (|)是输入序列为时输出为序列的概率,为训练集。()为给定输入序列时输出序列的每个样本概率之和,但在实际中,输出的标签概率并不是相互独立的。本文主要是利用双向长短时记忆网络和CTC网络组合构建网络模型,所以在整个系统中并没有用到语言模型或者字典,在网络中利用空白标签将音素与音素分开,从而计算音素的错误率,然后利用网络中构造的音素字典对其解码获得与之相对应的音素。
3.2.2 音素标签识别错误率
本文基于音素进行网络建模,所以选取音素标签的错误率(Label Error Rate,LER)用作网络准确度的评价指标,音素错误率的计算原则如公式(20)所示:

其中,,分别为插入,替换,删除的音素的个数,代表输出序列的音素个数。
3.3 实验结果分析
3.3.1 不同特征参数的实验对比
语音特征参数的提取方式的不同会较大地影响识别性能。第一组实验将对比不同特征参数对音素识别系统性能的影响。
从表1可以看出,基于MFCC特征的音素识别率和基于MSRCC特征的音素识别率两者较好,MSRCC特征最高,识别准确率可以达到80%,相比于MFCC高出3%,基于PSRCC特征的效果最差;且在训练过程中,基于MSRCC特征的损失最小,相比于其它两种特征,其更能拟合理想模型,训练的效果更好;对于PSRCC特征其效果不是很理想,可能对于连续的语音来说其相位信息不能完全表征信号,所以其效果不如另两种特征,但如果能与提取过程相似的MSRCC特征结合可能会有不一样的效果。总而言之,从表1可以发现,基于MSRCC特征的效果各方面考虑来看均优于基于MFCC特征。

表1 基于不同特征参数的实验结果
3.3.2 基于MSRCC特征的动态性
语音特征的动态性也极大地影响着识别系统的好坏,对于特征的维数的探究也是研究音素识别系统的一个重要方面,接下来将从MSRCC特征的不同维数考察该特征的优劣。
从表2可以看出,MSRCC特征加二阶差分的效果最好,可以达到86%的识别准确率,一阶差分与其相比低了1%,静态特征低了6%,更高阶的差分相加的识别效果也不如二阶动态特征,说明动态特征的取值也需要适当的选择。特征的动态性也是影响识别性能的因素之一。静态的特征不能反映不同时刻之间的相关性,将其取差分可以将特征的动态性融入到需要送入的数据中,更有利于序列信号的训练。相比于传统的MFCC特征来说,音素识别率的准确率提高了很多。

表2 基于MSRCC不同维数的实验结果
3.3.3 基于MSRCC与不同特征参数的融合
从表3可以看出MSRCC特征结合PSRCC特征实验效果最好,测试集的识别率可以达到83%,其次是结合MFCC特征,识别率可以达到81%,相比结合相位特征低了2%,但总的来说都比单独使用MSRCC特征效果好,但缺点是结合其它特征训练的代价上升了,它与理想模型的差距更大了,所以在选择特征时需要考虑实际环境和需求,如果准确率要求高的环境,则可以使用融合特征;如果要求损失小且速度快,则可以选择性能较好的单一特征。
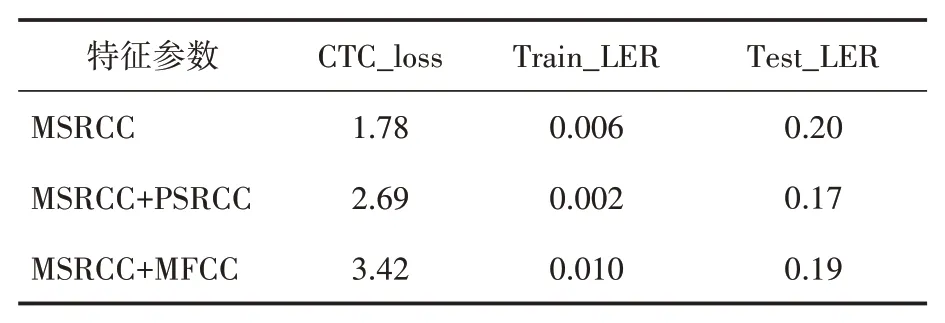
表3 基于MSRCC与不同特征参数的融合实验结果
3.3.4 针对不同声学模型的实验
本组实验主要研究了几种常用网络模型的对音素识别系统性能的影响,实验中语音特征参数采用静态MSRCC特征。
从表4可以看出,相比传统模型DNNHMM,RNN-CTC的训练错误率和测试错误率分别降低了7%和13%,说明模型的优化可以很好地改善系统性能。在后三组实验中可以发现,BLSTM-CTC的实验性能最好,训练错误率和测试错误率分别为2%和20%,相比于其它两组实验效果都有一定的改善,验证了BLSTM在一定的环境下能提升LSTM和RNN的性能。
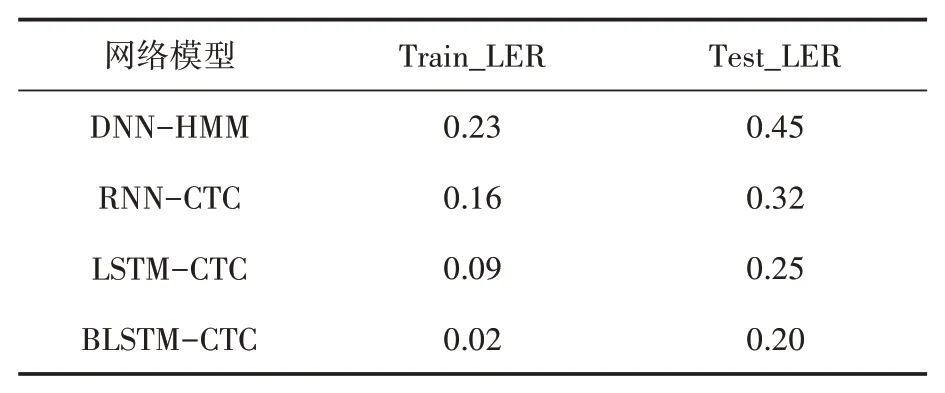
表4 基于不同网络模型的实验结果
4 结语
本文主要研究了语音特征参数和BLSTMCTC的音素识别系统性能,采用最新的语音特征参数MSRCC和PSRCC进行了一系列实验研究,表明这两种参数具有较好的分类功能,PSRCC参数的提出可以利用语音信号的相位信息,之前语音的相关研究都忽略了相位信息,但是在本文中使用PSRCC特征参数结合MSRCC特征具有较好的性能,音素识别声学网络模型的建立也十分关键,本文使用了BLSTM网络和CTC网络的结合,该模型简化之前复杂的识别系统的构建,不需要对语音流做切分和标签对齐工作,大大地节约了识别系统构建的时间。该实验也存在不足,只选取了一个语音数据集,在数据集的选用上可以使用多种数据集,除此之外,对MSRCC特征还可以进一步改进,可以尝试考虑把特征提取过程中的Mel滤波器换成gammatone滤波器;网络模型也还可以尝试利用融合卷积神经网络等。目前新提出了一些端到端的编码解码网络,新的端到端网络与BLSTM结合也是值得探索的方向,接下来我们会从以上几点出发,开展进一步深入的研究实验。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
北京教育·普教版(2020年9期)2020-10-09
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
校园英语·中旬(2019年11期)2019-11-26
广西教育·D版(2019年6期)2019-07-11
速读·中旬(2018年8期)2018-10-23
上海师范大学学报·自然科学版(2018年3期)2018-05-14
计算机应用(2016年10期)2017-05-12
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
