
基于级联分类的复烤片烟产地预测方法研究
2022-08-12 08:01帖金鑫何文苗李石头郝贤伟李永生张立立钟永健毕一鸣
轻工学报 2022年4期
帖金鑫,何文苗,李石头,郝贤伟,李永生,张立立,钟永健,毕一鸣
浙江中烟工业有限责任公司 技术中心,浙江 杭州 310008
0 引言
产地是一种在特定生态气候、土壤及种植方式下反映烟叶综合品质的属性标签,也是影响烟叶品质的重要因素。从农业角度看,产地溯源、原产地认定、法定保护等有助于农产品价格与品质区分。从烟草工业领域角度看,烟叶产地属性研究有助于工业企业深入了解各产区烟叶相似性及差异[1-2]。近红外光谱分析技术具有快速、简便、准确率高、成本低等特点,在农产品的定性定量分析中得到了广泛的应用[3-6]。但近红外模型的准确度依赖样本数量规模及样本的代表性,实际研究中近红外模型的深度学习往往需要投入大量的精力,而大量采集近红外数据并不容易实现。施丰成等[7]利用近红外光谱对四川、云南、重庆、福建4个产区烟叶分别建立产地判别模型,对各个产区内验证集样本预测精度大于90%。孙文苹[8]提出了一种改进的KNN算法对未知烟叶样品进行分类,提高了产区分类的正确率。束茹欣等[9]基于主成分分析及Fisher准则建立了烟叶生态产区和风格特征的投影分析模型,以生态产区模型的分析结果阐释了烟叶香型风格划分的合理性,取得了较好的结果。陈琦等[10]利用近红外分析结合元素分析对产业产地进行预测,近红外模型预测产地准确率75%,结合元素分析方法产地识别准确率提高到96%。白雁等[11]利用近红外光谱结合聚类分析法对不同区域连翘的鉴别研究结果表明,近红外光谱可以全面地反映连翘的整体质量信息,利用近红外聚类分析法对连翘进行产区鉴别是可行的。
我国地域辽阔,不同产地间的生态差异很大,烟叶的品质风格也千差万别。随着产地数目的增大,判别模型的复杂度升高,上述研究中模型精度随之下降[12]。现有分类方法主要用于识别类别差异最大的样本或者某一类别较多的样本,预测精度受限。如果依据人工经验,给定一个合理的方向(中间层),有助于在小样本量下实现层级分类。为解决多产地识别中分类模型复杂度高、预测精度低的问题,本文拟提出一种基于级联分类的复烤片烟产地预测方法,该方法首先通过近红外光谱判断样本的香型属性并构建香型模型作为中间层,再使用线性判别分析(LDA)或偏最小二乘分析(Partial Least Squares, PLS)方法对每种香型的产地进行细分,即在单一香型框架下构建产地模型进行产地预测,以期将多产地判定的复杂问题进行分解,降低算法的复杂度,进而实现多产地鉴别的目标。
1 样本的获取
本文所使用样本为全国主要烟叶产区的复烤片烟样本,共计232个,由浙江中烟工业有限责任公司提供。将样本按照烟草行业标准《烟草及烟草制品 试样的制备和水分测定 烘箱法》(YC/T 31—1996)[13]制备成烟末样本(粒径≥40目,水分含量5%~7%),密封保存。取适量烟末放入样品杯中(约占杯高度的1/3),取一固定质量砝码放置在样品上方,使其自然压实后,旋转样品杯,进行近红外扫描。近红外光谱由Antaris型傅里叶变换近红外光谱仪(美国Therom Fisher公司产)采集,采集范围为10 000~4000 cm-1,光谱分辨率为8 cm-1;扫描次数为72次。为避免散射影响,近红外光谱进行了Savitzky-Golay(SG)平滑和标准正态校正处理(SNV)[14]。
取194个复烤片烟样本近红外光谱数据作为建模样本,另取38个复烤片烟近红外光谱数据作为测试样本,建模及测试样本信息如表1所示。
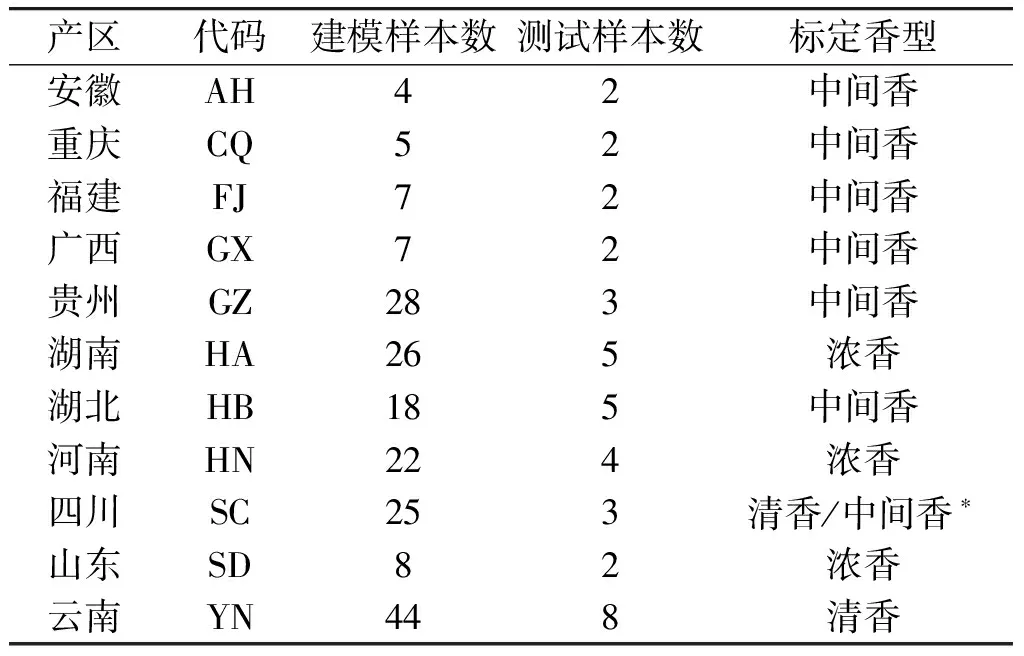
表1 建模及测试样本信息
2 基于级联分类的产地预测
2.1 产地预测思路
产地判定模型必须对每一类别都找出其独有特征,类别数增多会导致部分类别特征波数因重叠而被误判。专家利用感官评价对烟叶的产区风格进行判断时,除少数风格识别度较高的产区外,一般不直接捕捉其特定信息,而是采取循序渐进的方式,先确定一个大致范围,排除干扰后再在这个范围内确定该样本所属产区。受此启发,本文提出一种基于级联分类的复烤片烟产地预测方法,构建一个中间层(香型判定),利用中间层先将所有样本分类,再在每一个子类中进行产区判定,以避免类别过多导致的模型复杂度升高及判定结果不理想。
本文提出的级联分类模型流程示意图见图1。其中香型模型作为中间层,将香型模型下的产地模型作为第二层。香型模型将所有样本归类,其差异表现为大区域内的风格差异,如香韵、烟气状态等,采用三维数据给定标签,即清香[1 0 0],中间香[0 1 0],浓香[0 0 1],这种三维香型体系可在避免香型加和性的同时综合反映样本的香型。采用PLS分析方法进行香型模型建模[15],三维香型标签作为Y,根据PLS的预测值在3个维度上表征样本香型风格,这种量化形式有助于判断目标样本是否能明确地被判定为三类中的某一类。

图1 级联分类模型的流程示意图
第二层产地模型为每个香型风格下的细分归类,其差异表现为相近产地样本的品质差异,如地方性杂气等特点。第二层模型采用LDA或者PLS方法进行建模,输出结果为最终的预测产地。
模型涉及的算法通过Matlab 7.14平台实现,其中,LDA计算程序由Matlab的classify函数执行,在计算前用谱回归方法对数据进行降维[16]。其他算法由作者编程实现。
在PLS建模中,需要通过选择合适的潜变量数来避免模型欠定和过拟合。本文使用了Haaland提出的统计检验方法选择合适的潜变量数,通过计算交叉验证预测残量误差平方和(Prediction Error Sum of Squares, PRESS),利用F检验,当PRESS最小值不显著时,选择最少的潜在变量数[17]。
2.2 香型模型构建
香型模型构建的关键问题是其合理性。如果香型模型判断错误,则样本将被分到不属于其产地的大类中,从而导致误判。因此,香型模型构建必须有一定的理论支持和很高的判别正确率。文中采用定量分析中常用的交叉验证方式,利用抽样-建模-统计的方式考查香型模型的正确率及稳定性。对数据中香型模型的精度进行考查,未通过人工感官方式剔除样本,对每种香型随机抽取70%数据作为单次抽样中的训练集,其余30%作为验证集,进行一次建模分析。重复实验100次,确保每个样本都多次被选入测试集,每次抽样后,用PLS方法进行建模,对该次抽样中的测试数据进行预测,多次抽样实验中间层模型的训练集及测试集正确率结果见图2。由图2可以看出,训练集平均正确率高达93%(标准差为2.3%),测试集正确率高达88%(标准差为4.9%),实验结果与王一丁等[18]关于近红外光谱可以预测香型的结论一致,也说明了本文提出的中间层模型与专家经验判定结果相符,可用于预测复烤片烟产地属性。

图2 多次抽样实验香型模型的训练集及测试集正确率
基于上述合理性分析的结果,将所有训练集样本使用PLS方法进行香型建模,模型输出香型指数预测值,未出现两种香型指数同时高于0.5或者单个香型指数远高于1的情况,表明使用清香型、中间香型、浓香型3个维度,可以较好地概括样本的香型情况,不存在模型外推情况。在给出三维的香型指数后,按如下规则确定香型:若三维中有某一维指数值大于0.5,则以该维代表的香型作为样本香型;若三维指数均不大于0.5,则将该样本定为中间香型。模型的预测规则与传统经验中“非清非浓即为中”的准则相符。三维标签的优点在于,可以将中间香型突出和3种香型均不突出的样本在香型建模的环节体现出来。中间香型样本分布广泛,如果仅通过一种标签标注,可能使得样本间的物质差异(光谱差异)无法体现,导致模型的可解释性降低。基于PLS方法的香型模型中3种香型的回归系数如图3所示。由图3可以看出,3种香型在10 000~6000 cm-1区域内有显著的差异,在6000~4000 cm-1区域内,清香型和中间香型也有若干典型的吸收区域,说明了近红外光谱对烟叶香型的差异有较好的反应。在级联分类模型中,以该香型模型对38个测试样本的香型进行预测。

图3 香型模型中3种香型的回归系数图
2.3 产地模型构建
在第二层(产地模型)构建时,考虑到部分省份中有可能存在一种以上的不同香型,因此,在香型模型中分别予以考虑,不同产地的香型属性分布如表2所示。分别用LDA和PLS方法进行产地预测建模,在LDA方法中,对训练集中每一类赋予一个类别标签;在PLS方法中,根据每一香型下的产地类别数,构建一个产地类别数的向量,每个向量中仅有一个数值为1,表征特定的产地,其他元素均为0。在本文中,清香型、中间香型和浓香型产地标签的维数分别为二维、六维和四维。

表2 不同产地的香型属性分布表
以LDA方法为例,细分香型下的产地模型回归系数如图4所示。对于清香型烟叶,共有四川和云南两类标签,通过该回归系数与光谱进行计算,得到建模数据中的判定值。对每个测试样本,根据其模型计算的数值及判定确定是属于四川还是云南。同样由中间香型样本的训练数据给出阈值,根据阈值对测试样本进行产地分类。浓香型也是同样的步骤。

图4 细分香型下的产地模型回归系数(LDA方法)
3 产地预测结果与分析
将本文的级联分类模型与传统的LDA模型和PLS模型进行对比,多种方法对测试样本的产地预测结果(仅列举部分预测结果有差异的样本)见表3,预测结果统计见表4。
由表3和表4可知,传统的LDA模型预测的正确率为83.33%,在云南烟叶与四川烟叶辨别中出现较多错误,主要原因是两省接壤在气候上有一定的相似之处;传统的PLS模型预测的正确率为72.22%,误判样本中主要为山东和广西样本,与感官评吸专家认为山东和广西的香韵不典型有关。本文的方法引入了香型模型作为中间层,再使用LDA或PLS方法进行产地预测,基于LDA方法的级联分类模型预测正确率为94.44%,对绝大多数样本均表现良好,仅有的2个误判样本也都判别为地理上的临近产区;基于PLS方法的级联分类模型预测正确率为86.11%,错误样本主要来自广西等香韵特征不典型产区,说明中间层的引入使得两种模型的准确率都得到了较大提高。

表3 多种模型对测试样本的产地预测结果

表4 多种模型在测试样本中的预测结果统计
4 结论
本文提出了一种基于级联分类的复烤片烟产地预测方法,并将其用于复烤片烟的产地预测,该方法首先通过近红外光谱判断样本的香型属性并构建香型模型作为中间层,再使用LDA或PLS方法在单一香型框架下构建产地模型进行产地预测。该级联分类模型将原始的多产地分类问题分解为若干个少产地分类问题,从而大大降低了模型的复杂度。实际应用结果表明,通过引入香型模型作为中间层,基于LDA的分类模型预测准确率由原来的83.33%提升至94.44%;基于PLS的分类模型预测准确率由72.22%提升至86.11%。在有限样本数据和不引入新的模型参数的条件下,本文的级联分类模型可以有效地降低复烤片烟的产地误判比例。
猜你喜欢
休闲读品·天下(2022年2期)2022-07-13
核安全(2022年3期)2022-06-29
休闲读品·天下(2022年1期)2022-05-01
今日农业(2021年4期)2021-06-09
海峡姐妹(2020年2期)2020-03-03
中国外汇(2019年22期)2019-05-21
意林·全彩Color(2018年9期)2018-10-12
食品工业科技(2014年23期)2014-03-11
汽车与新动力(2014年4期)2014-02-27
原子能科学技术(2011年10期)2011-07-30
