
随机森林算法在消费品召回效果评估中的应用
2022-08-16 07:02黄国忠高学鸿
重庆理工大学学报(自然科学) 2022年7期
黄国忠,林 琳,高学鸿
(1.北京科技大学 土木与资源工程学院,北京 100083;2.北京科技大学 大安全科学研究院,北京 100083)
0 引言
随着市场竞争日趋激烈,产品创新性以及产品投放周期逐渐缩短,“缺陷产品”造成的伤害事故也越来越频繁[1]。作为产品安全管理的重要手段,缺陷产品召回制度在国外发展已经较为成熟[2],且召回立法也明确监管部门和专家对召回的效果进行评估[3],但缺乏一定依据和理论指导。消费品分类的复杂性决定了其召回率的不稳定,后召回管理阶段对于召回工作能否有效地降低或消除缺陷消费品的安全风险至关重要。
国内已有学者从不同角度对影响召回效果的原因展开研究,并提出了相应的措施优化召回流程。高芳等[4]就生产者召回的内外因素和缺乏召回动力的原因展开分析,并对召回行为对生产者产生的影响进行了研究。杨金晶[5]提出对参与缺陷产品召回的消费者进行补偿的想法,并根据召回成本和补偿限额等建立优化模型,以提升产品召回率,达到企业利益最优化。徐乾程和钱存华等[6-7]从政府监管视角运用模糊层次分析法构建评价缺陷消费品召回效果的模型。这些研究多从单一视角对召回效果优化进行分析,缺乏对整个召回周期的关键节点上生产者、消费者和监管机构的行为和反馈影响的讨论,在利用召回率对召回效果进行评定上存在探讨空间。
此外,目前效果评估主要运用AHP等依靠专家评分的方法进行重要度分析[8],而将机器学习算法模型应用于召回效果评估,可以减小经验性带来的误差。因此,笔者拟综合考虑召回流程中影响消费品召回效果的因素,结合改良CIRO层级模型建立召回效果指标体系。运用随机森林算法构建消费品召回效果评估模型,为消费品的召回效果评估提供理论依据。
1 评估指标体系的建立
1.1 影响因素分析
消费品召回效果评估指标体系的建立需要考虑流程中涉及的人为因素、产品特性及召回环境等外在因素。召回活动整个生命周期包括召回计划、召回发起、召回处理和召回效果评估4个阶段,缺陷产品的召回分为3个主体部分:生产者是主体、消费者是参与者、监管机构是召回的监管者[9]。召回活动产生的效果包括产品的退回和危险残留等直接效果以及对召回主体和召回环境等产生的增益效果。
CIRO评估模型的4项评估活动分别是:背景评估、输入评估、反应评估、输出评估。背景评估分析和确定培训需求;输入评估收集培训资源和相关信息;反应评估用于收集和分析培训对象的反馈信息,并进行分析和评估[10]。逻辑框架矩阵通过投入、产出、目的与目标的4个层次描述,实现各层目标的假设条件,判定项目实施成果的可验证指标[11]。
CIRO评估模型和逻辑模型与消费品召回整个动作逻辑相吻合,结合消费品召回评估的特点,将CIRO模型与逻辑模型结合得到消费品召回效果评估的层级模型,如表1所示。

表1 消费品召回效果评估的层级模型
筛选召回行为中召回完成度、召回后产品的残余风险及各方满意程度等产出层面影响因素,建立消费品召回效果评估指标体系。
1.2 指标体系构建
1.2.1召回效果评估
召回产品退回情况需要根据背景层面中各方的固有情况进行单独评估。由于消费品的特性,实际退回率很少超过30%,因此,需通过生产者提供的资料与数据,基于具体产品情况、行业整体召回水平、常规召回措施及消费者的基本情况等建立基准退回率指标体系。考虑退回这一行为主要来自购买了缺陷产品的消费者,消费者自身对缺陷的判断能力、日常环境对参与召回是否便捷及个人对召回活动本身的认可和积极性都对退回率有影响。因此从消费者退回意愿的角度,结合缺陷产品本身的特性建立判定基准退回率的指标体系,如表2所示。

表2 基准退回率指标体系
“4级评估模型”中产出层面从召回情况、残余风险和各方评价评估召回效果。结合前2个层面对召回率指标的影响,通过计算实际召回率与理想召回率的比值,综合判断一起消费品召回活动的效果。从影响层面来看,消费品的单次召回还会产生增益效果,包括对生产者自身的影响和召回活动的社会性影响。由此,建立由召回效果和增益效果组成的评估指标体系如表3所示。
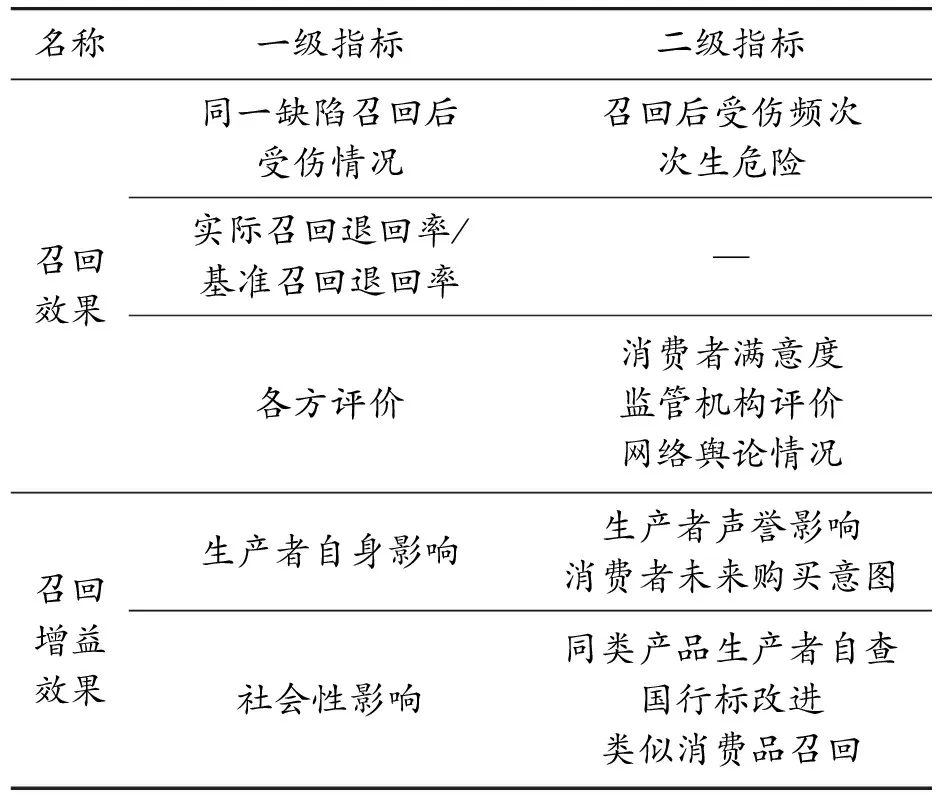
表3 召回效果和增益效果组成的评估指标体系
2 召回效果评估模型构建
随机森林是一种包含多棵决策树的机器学习模型,结合了bootstrap采样和随机属性选择的优点[12],通过分析目标值与各个影响因子之间的复杂关系,得出不同影响因子对目标值的重要度,具有调试参数少、不易过度拟合和分类速度快的优点,可以通过样本数据精确拟合各种复杂的非线性关系[13]。
消费品召回效果评估模型是需要利用随机森林算法将特征值的输入转化为召回效果的预测输出,即需要用随机森林中的随机回归森林。基于随机森林的消费者召回效果评估模型的建立,首先需要对原始数据作归一化预处理;其次调取数据,结合交叉验证方法求取设置不同参数值时的均方误差(MSE)的变化曲线,以此得出最适合该模型的参数;利用合适的参数计算得出不同特征值的权重,并建立效果评估模型。
2.1 数据来源及预处理
生产者与监管者负责对消费者采集数据与资料,主要途径包括公开发表的开放数据;调查:可采用查阅档案、电话访问、在线调查、问卷调查、短信评价、回访抽查等;现场采集:实时跟踪召回情况,采集有关数据;生产者通过填写材料表向监管部门提供相关的数据和资料。
不同的特征指标往往具有不同的量纲和单位范围,所以在进行模型计算前需要对数据进行一定的处理,常用的方法即为数据标准化(归一化)[14],以此来减轻和消除数据量纲不同对模型的分析和指标重要性分析的影响。根据消费品召回的数据特点选择线性函数归一化方法。选取来自国家市场监督管理总局缺陷产品管理中心的数据样本作为随机森林算法的样本集和训练集。
2.2 随机森林算法确定指标权重系数
利用Python语言建立随机森林参数选择函数,对模型建立过程中的参数进行调试。由于在建立召回效果评估模型时已确定需要考虑的特定指标,因此主要考虑n_estimators和max_depth两个对模型影响比较显著的参数,其对模型准确度影响的判断用MSE数值大小表示。
2.2.1随机森林的关键参数调试
1)确定最优n_estimators值
在确定最优n_estimators值时,具体步骤如下:① 将样本数据归一化。② 初始化训练集/测试集的MSE。③ 从1~500循环,依次利用交叉验证和随机森林训练该模型。输出结果如图1和图2所示。

图1 基准退回率模型的最优n_estimators值分布图
根据图1和图2可以看出,测试集和训练集的MSE均方误差均随着n_estimastors数值的增大而先呈现下坡式下降,后呈现平稳微上升的态势。因为MSE数值越小,该测试集与训练集之间的误差越小,该测试模型的准确度越高。因此,将测试集和训练集MSE差值最小点作为最优n_estimastors取值点。

图2 召回效果评估模型的最优n_estimators值分布图
2)确定最优max_depth值
参数max_depth决定随机森林中树木的最大深度,是影响随机森林模型在建立每一个决策树时准确度的重要参数。调试过程参考n_estimators值的确定。输出结果如图3和图4所示。

图3 基准退回率模型的最优max_depth值分布图

图4 召回效果评估模型的最优max_depth值分布图
同样地,将测试集和训练集MSE差值最小点作为最优max_depth取值点。
综合以上分析,基准退回率模型和召回效果评估模型的参数最优值如表4所示。

表4 随机森林参数值
2.2.2基于随机森林的指标权重系数确定
随机森林具有在生成每一棵树的过程中,其内部节点在每次分裂时都会从候选的属性里随机挑选一定数量的分裂属性的特点[15],利用这一点,在每次迭代中随机换掉其中的一个属性,利用换掉之后模型准确度的变化和变化幅度来预测该属性对整个模型的预测结果之间的影响程度和重要性,完成对每个特征属性重要度的判断。在对数据归一化处理并求得最优参数值后,利用 Python中的importance函数确定指标权重系数,结果如表5和表6所示。

表5 基准退回率指标体系的权重系数

表6 召回效果指标体系的权重系数
2.3 各项指标数值的量化标准
指标体系中需要量化的指标包含定量指标、半定量指标及定性指标。定量指标主要利用该指标的隶属度函数实现量化分级;半定量指标根据指标特点、法规规定等因素,利用语义赋值法实现量化分级;定性指标利用专家意见、消费者反馈等形式实现量化分级。
2.3.1指标量化原理
1)定量指标量化原理。定量指标的量化主要根据指标所对应的隶属度函数,根据召回效果评估结果的分级,分为好、较好、一般、差4个等级,即S(x)={S1,S2,S3,S4}。假设量化指标的指数为x,量化范围为[minx,maxx],其分布函数为:

(1)
2)半定量指标及定性指标量化原理。对于缺乏数据难以量化的指标,如:召回方式等指标,以及评价性指标,如:消费者满意度等指标,采用语义赋值和专家及消费者评判相结合的方式完成量化分级。目前已经实施的缺陷汽车产品召回效果评估指南[16]中,指标量化分级为10分制,但由于消费品与汽车产品相比,其大部分追溯系统尚未成熟,某些企业的召回管理过程中部分指标的数值只能进行模糊统计,因此需要简化量化分级。根据董红磊等[17]基于模糊综合评价法运用于汽车产品召回领域的方法和标准化研究院相关专家的意见,将消费品召回效果评价指标量化的评分等级设置为4级,如表7所示,其中半定量指标还需结合指标特点确定各等级评估说明。

表7 指标量化评分等级
2.3.2定量指标评级与量化情况说明
1)单值。按照消费品被投入市场时的单体价格,即单值划分。现设定单值a属于[0,10 000]的区间内,其隶属度函数如下:

(2)
式中:a为目标消费品的单值,元。
2)损耗比。损耗比包括固有价值损耗和寿命损耗。现定实施召回的时间点TA,被召回批次消费品的生产日期为TB(若存在多时间段生产消费品召回,以最远生产日期为准),行业内一般认为该消费品的使用周期为TI。此外,若生产者实施召回的时间点超过消费品使用周期时间段,则其损耗比为1。
a)固有价值损耗比。按照生产者实施召回的时间点处于该消费品使用周期时间段内固有价值损耗比计算,其隶属度函数如下:
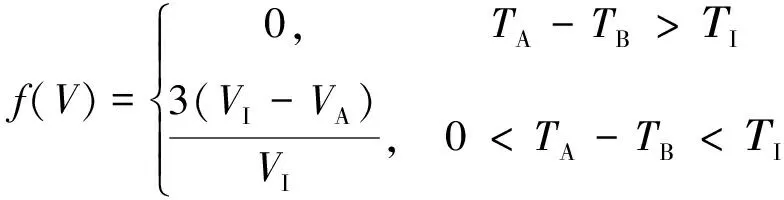
(3)
式中:VI为目标消费品的固有价值,元;VA为目标消费品的实际价值,元。
b)寿命损耗比。按照生产者实施召回的时间点处于该消费品使用周期时间段内使用寿命损耗比计算,其隶属度函数如下:
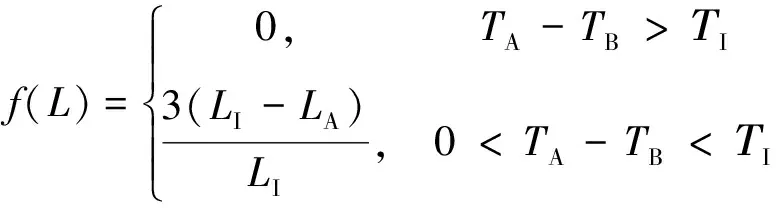
(4)
式中:LI为行业内一般认为该类消费品的使用寿命,天;LA为实施召回时该消费品的使用寿命,天。
3)实际召回退回率/基准召回退回率。根据基准召回退回率的评级和量化结果计算该次召回的基准退回率数值,并将实际召回退回率与其进行比较。该指标数值量化如下:

(5)
4)召回后受伤频次。召回是消除产品因缺陷造成伤害的行为活动,如果一个产品发生召回后仍出现受伤投诉,根据召回效果评估最严苛原则,可认定其召回效果差,赋值1分,未出现投诉赋值3分。
3 建立召回效果评估模型
3.1 召回效果优度值计算
对某一评价对象Oj,若评价指标集是Ei={E1,E2,…,En},Oj关于Ei的规范关联度是kij,Ei的权重是w(w表示评价指标Ei的相对重要程度),且0≤w≤1。优度是评级指标Ei的权重值w与对象Oj的规范关联度kij,即指标赋值的乘积[18],将优度定义为:
(6)
确定召回效果评语V={V1,V2,V3},利用等级比重法,根据召回效果优度值及残余风险量级分析,将召回效果分为好、一般和差3级,所对应的残余风险为低风险、可接受风险和不可接受风险,用数字1~3依次表示,并对等级由1~3进行区间赋值,以便召回效果量化评判。其赋值情况如表8所示。

表8 效果评估结果的赋值情况
由于增益效果评估指标为辅助性指标,其具体效果评定与直接效果相比,需要一段较长的反馈时间。因此,结合标准化领域相关专家的意见,使用打分法进行计算,不对指标体系进行权重确定,仅当每个指标的重要度相等。具体评分规则根据召回活动对指标产生的效果分为负面影响、无影响和正面影响,分别赋值-1、0和1分(此处赋值仅表示召回是否对该指标产生影响,不代表影响程度)。当总赋值得分大于0时,表示该召回活动产生了增益效果。
3.2 模型精确度验证
通过以上几节的分析,在构建基准退回率的最优模型时,选取参数如表4所示。目前,对于消费品召回的预期退回率没有严格的规定说明其误差范围和标准,根据经验得到一般预测数据与真实数据之间相差±10%均可接受。因此对比分析基于随机森林的评估模型,选取匹配度和相对误差2个指标对评估模型的准确性进行判断。
1)匹配度。该指标反映预测值和实际值之间的匹配情况,匹配度越接近,单个样本的预测效果越好,公式如下:
(7)
式中:i表示样本;Xi表示预测值;Yi表示真实值;pi表示样本i的匹配度。
2)相对误差。实际相对误差指测量造成的绝对误差与被测量真值之比,相对误差更能反映预测结果与真实值之间的差异,计算公式如下:
(8)
式中:Δ表示绝对误差,L表示真值。
采用的案例来源于国家市场监督管理总局缺陷产品管理中心提供的2010—2018年消费品召回数据,因篇幅原因此处只展示选取15个案例作为预测集数据的基准召回率模型,如表9所示。
通过表9的数据可以看到,在展示的预测集中的15个案例得到的预测值和真实值匹配度基本均接近1,5个样本数据的相对误差在±5%以内,14个样本数据的相对误差在±10%以内。

表9 基于随机森林的基准退回率评估预测结果
通过完整数据分析,随机森林运用在消费品召回效果评估模型时的拟合预测值中,93.33%的样本在合理的误差范围内。由此得出:随机森林算法运用于该召回效果评估模型的权重系数确定时具有较高的拟合度,可用于召回效果评估领域,解决专家打分主观性较强的缺点。
4 案例应用
4.1 案例信息
某品牌青少年运动夹克在设计过程中未能充分考虑到调节松紧的绳带在抽出后可能对儿童存在隐患,且无提醒标志和说明,有造成缠绕的风险,其召回信息如表10所示。

表10 某品牌青少年运动夹克召回信息
将以上案例应用于消费品召回效果评估模型,运用召回效果评估模型进行召回效果优度值计算,可得召回效果评估优度值为2.063,对应评级为好。
青少年运动夹克在召回后价格大幅下跌,可以看出消费者的未来购买意图不强,但由于该企业管理有限公司对本次召回活动的挽救较为及时,品牌影响未发生大幅度下跌,消费者对该品牌仍有较强的购买意图,且对该品牌声誉没有不良影响。同时,在该品牌召回完成后并未引起行业标准的更改和同类产品生产者的自查,但该消费品的召回结合监管部门对该类产品的消费预警,一定程度上引起消费者的重视和对同类消费品召回的促进,其召回增益效果评估打分如表11所示。

表11 召回增益效果评估打分
增益效果得分为2,结合国家市场监督管理总局缺陷产品管理中心提供的缺陷总结报告和召回评价、媒体评价,根据优度值和残余风险量级分析可以得出,当召回效果评估优度值为2.063时,其对应召回评估结果为“好”,其残余风险为低风险,与实际召回效果相符合。因该产品受单值、目标群体对缺陷判断能力等影响,导致其基准退回率和实际退回率较低,但该品牌及时发布召回信息、使用方便便捷的召回方式并有效减少甚至消除同一缺陷对消费者带来的安全隐患和伤害,同时监管部门监管合理到位,使得其召回效果较好,值得同类召回产品借鉴。
5 结论
1)结合改良CIRO层级评估建立召回效果评价分析指标体系,运用随机森林算法在数据案例的基础上确定指标权重,建立基于随机森林的消费品召回效果评估总模型。通过使用模型对案例的预测基准退回率进行计算,与实际预测退回率的相对误差在可接受范围内,证明该评估模型可以有效、准确地评价消费品召回效果。
2)所构建的评估指标体系考虑到召回活动参与的各个相关方的行为后果和影响,采用实际/基准召回率直观地评估召回效果,随机森林算法的运用能较好地弥补目前召回效果评估研究中主观性较强、指标定量化难等问题。
3)采用传统的随机森林算法构建模型,选择来自国内典型的召回案例,样本数据较为完整,但实际运用过程中,主观性指标的数据往往难以收集。因此,该方法对此类非平衡数据的处理仍不够理想。未来可引入NCL技术、应用代价敏感学习等对随机森林算法进行优化。
猜你喜欢
英语文摘(2022年8期)2022-09-02
第一财经(2022年6期)2022-06-15
中国水运(2022年4期)2022-04-27
建材发展导向(2022年5期)2022-04-18
产权导刊(2020年10期)2020-11-17
农产品市场周刊(2019年3期)2019-07-29
当代陕西(2019年10期)2019-06-03
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
