
基于改进SMOTE自适应集成的信用风险评估模型
2022-08-16 07:02于勤丽于海征
重庆理工大学学报(自然科学) 2022年7期
于勤丽,于海征
(新疆大学 数学与系统科学学院,乌鲁木齐 830000)
0 引言
随着大数据相关技术在金融行业的应用与普及,各种基于创新模式的互联网金融产品得以真正落地和大范围推广。作为互联网金融的重要技术应用,基于大数据的信用评估在消除潜在风险中发挥着巨大的作用。在此背景下,如何借助数据手段对违约用户进行高效、准确的识别,从而更好地规避风险,是要探讨的核心问题。
在数据层面对不平衡数据处理主要是通过重采样方法[1-3]。重采样按照采样方式大致可分为三大类,分别为过采样、欠采样和混合采样。Chawla等[4]在2002年提出SMOTE(synthetic minority over-sampling)过采样方法,该算法合成的少数类样本是通过在少数类样本和其近邻样本之间的随机插值得到的。SMOTE采样有效缓解了随机过采样方法重复增加相同样本的缺点,但合成的样本不可避免的在少数类样本聚集处合成更多的新样本。Han等[5]在2005年提出了Borderline-SMOTE算法,该算法是在生成新样本的过程中只针对危险样本进行过采样以增强分类边界,从而减少噪声样本的数量,Borderline-SMOTE算法相比于SMOTE算法考虑了边界样本学习困难的特点。He等[6]在2008年提出自适应过采样(adaptive synthetic sampling approach,ADASYN)算法,ADASYN算法与SMOTE算法不同,后者对每个少数类样本生成相同数量的新样本,而ADASYN是根据数据集特点自动决定每个少数类样本生成的新样本数量,该算法考虑了与多数类距离很近的少数类样本,并通过合成更多处于边界位置的样本来提高模糊样本的分类准确率,以实现提高分类精度的目的。SMOTE-D过采样方法是Torres等[7]在2016年提出来的,通过估算少数类样本的离散度(基于距离的标准偏差),以确定少数类中的每个样本周围应生成多少个样本,以及在每个样本和近邻样本之间应创建多少个样本。SMOTE-D是SMOTE的确定性版本,在数据集的不平衡率小于0.1时,性能要优于SMOTE 算法。王亮等[8]在2020年提出DB-MCSMOTE算法,该算法先对少数类样本进行DBSCAN聚类,然后在各个簇中进行采样。张家伟等[9]在2020年提出了一种过采样方法,通过确定每个样本的相对位置,然后根据样本权值决定生成的样本数量。该算法缓解了ADASYN算法过于关注模糊样本的缺点。
信用风险评估模型是基于数据构建模型来提高违约用户的识别率,从而减少企业的资金损失。Wiginton[10]在1980年提出建立基于Logistic回归算法的信用风险评估模型,该模型通过与传统线性判别作对比发现,Logistic准确性更高,实用性更强。丁岚等[11]在2017年基于Stacking集成模型对网贷违约状况进行了预测,并利用人人贷数据做了实证分析,发现所建模型能显著降低一类和二类错误概率。Han等[12]在2005年提出了基于Stacking的信用风险评估模型,将XGBoost基分类器的训练结果作为第二层的输入特征之一,元分类器是Logistic模型,模型第一层使用了交叉验证防止过拟合现象的出现。He等[13]在2018年提出了基于数据集不平衡率的集成模型,选择的基分类器是随机森林和XGBoost模型,并用粒子群算法对基模型进行参数优化。Guo等[14]在2019年建立了多阶段自适应分类器集成模型,所提出的模型可以分为3个主要阶段,并通过粒子群算法进行参数优化,提高了模型的调参效率。与单个分类器和其他集成分类方法相比,该模型具有更好的性能和更好的数据适应性,为相关金融机构提供了有效的决策支持。Abhijeet等[15]在2019年提出了两级信用风险评估模型,其基本思想是用第一级分类器选择出异常的信用卡用户,后将异常值在支持向量机上进行二次训练。两级数据挖掘模型是以最大限度减少误判为前提,其准确率较高,但训练过程相对比较复杂。
综上所述,利用过采样方法在模型训练之前进行平衡化处理是改善不平衡数据分类性能的重要方法,同时基于集成模型构建的信用风险评估模型可提高少数违约样本的识别率。
主要的研究工作如下:
1)针对 SMOTE 等过采样方法对每个少数类合成相同数量新样本以及合成边界噪声样本的缺点,提出改进的 SMOTE 过采样方法。首先根据每个少数类样本所处的位置来确定样本的质量;然后根据分类样本的质量计算其生成的新样本数;最后对生成新样本的位置做了调整,通过在近邻样本和类中心之间进行插值,实现新样本位置向类中心迁移,避免在分类模糊区域合成新样本。
2)根据数据集的特点自适应的为信用风险评估模型选择准确率高且互补性强的最佳基分类器,并使用最佳基分类器构建Stacking集成模型。
3)在模型验证方面,分别进行了两大类实验。第一类是SMOTE过采样和改进的SMOTE过采样方法在Stacking模型下的对比,结果显示,改进的 SMOTE过采样方法生成的少数类样本质量更高。第二类实验是针对不同基分类器构建的Stacking 模型,结果显示JC指标挑选出的基分类器所构成的Stacking集成模型性能更优。
1 理论知识
1.1 SMOTE算法
SMOTE是一种合成少数类样本的算法,具体思想是根据不平衡数据集的不平衡率确定采样率,然后根据插值公式合成新样本,具体过程如下:
步骤1根据数据集的不平衡率设置采样率;
步骤2确定少数类样本xi的k个近邻样本xij;
步骤3在样本xi和其k个近邻样本xij之间进行随机线性插值,插值公式如下:
xnew=xi+(xi-xij)*rand(0,1)
(1)
1.2 ADASYN算法
ADASYN算法的基本思想是根据少数类样本周围多数类样本的数量决定每个少数类样本合成的新样本数量。

步骤2计算合成的新样本总数N:
N=d×α,α∈[0,1]
(2)
步骤3根据欧氏距离计算少数类样本xi的K个近邻样本xij,并计算每个少数类样本的γi:
(3)
其中:Δi表示K个近邻样本中的多数类样本数;
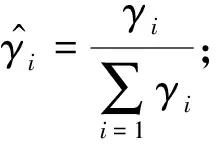
步骤5计算每个少数类样本合成的样本数量:
(4)
步骤6根据插值公式生成新样本。
1.3 Stacking集成模型介绍
Stacking模型由两层组成,第一层模型称为基模型,第二层模型称为元模型[16]。Stacking集成模型的思想是,组合多个基分类器的输出结果,并将其作为第二层元分类器的输入,以得到一个更好的输出结果。
Stacking集成模型的第一层基模型最好是强模型,也就是在选择基模型的时候尽量满足准确率高且模型差距大,这样既能保证模型的准确率,又能通过不同的基模型来提高模型的泛化性能。为了避免过拟合问题,可选用简单分类器作为第二层的元模型。如果直接使用基模型产生的输出作为元分类器的训练集,会加大过拟合风险。因此,一般使用K折交叉验证来产生元分类器的训练集。
以5折交叉验证为例来说明,首先将初始训练集分成5折,基分类器在前4折数据上进行训练,并在剩下的一折上进行预测,保证每一折数据都做了一次预测数据集,然后将预测结果拼在一起,得到元分类器训练集的一个特征,依此循环将每个基分类器的预测结果拼接,最终得到的元分类器训练集的维数跟基分类器的维数相等。
2 改进的SMOTE过采样方法
传统的SMOTE过采样方法不考虑数据集的分布,每个少数类合成相同数量的新样本。这会导致新合成样本聚集在少数类样本聚集的位置。再加上SMOTE过采样方法未考虑少数类样本的质量,不可避免地引入过多噪声样本,给后期的模型训练带来麻烦。针对SMOTE过采样方法的缺点,提出了一种改进的SMOTE过采样方法,它根据数据集的分布决定每个少数类样本合成的样本数,并通过迁移式插值减少噪声样本的生成。
2.1 计算新生成样本数步骤
设训练样本集为T={(x1,y1),…,(xn,yn)},每个样本有p个特征,其中少数类样本数为n1,多数类样本数为n2。
输入:训练集T;
输出:每个少数类样本生成的新样本数量;
Step 1:计算需要合成的少数类样本数N:
N=(n2-n1)*α,α∈[0,1]
(5)
Step 2:计算少数类样本的类中心xcenter1和多数类样本的类中心xcenter2的公式为:
(6)
Step 3:计算Di:

(7)
Step 4:归一化处理:
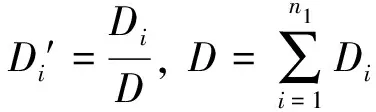
(8)

2.2 改进的SMOTE过采样算法步骤
设训练集为T={(x1,y1),…,(xn,yn)},y=(0,1)。其中,少数类样本集为T1={(x1,y1),…,(xn1,yn1)},多数类样本集为T2={(x1,y1),…,(xn2,yn2)}。
输入:合成的样本数量Mi,少数类样本集T1;
输出:新合成的少数类样本集Tnew;
Step 1:对第i个少数类样本数量xi,选择其Mi个k近邻样本xij,j=1,2,…,k;
Step 2:对Mi个近邻样本按照合成公式生成新样本xnew:
xnew=xij+(xij-xcenter1)×rand(0,1)
(9)
Step 3:将生成的新样本xnew加入少数类样本集T1中,得到新的少数类样本集Tnew。
合成新样本的过程如图1所示,通过在少数类中心跟xi的近邻样本之间进行随机插值产生。
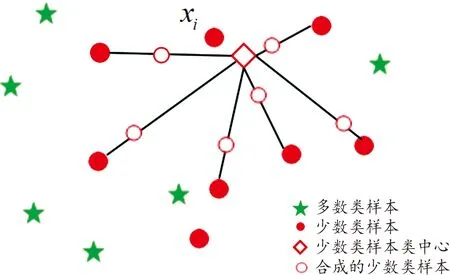
图1 合成少数类样本的插值过程示意图

2.3 评价指标
混淆矩阵是机器学习中总结分类模型预测结果的表格,其中行表示预测值,列表示真实值,以二分类为例,混淆矩阵元素如表1所示。
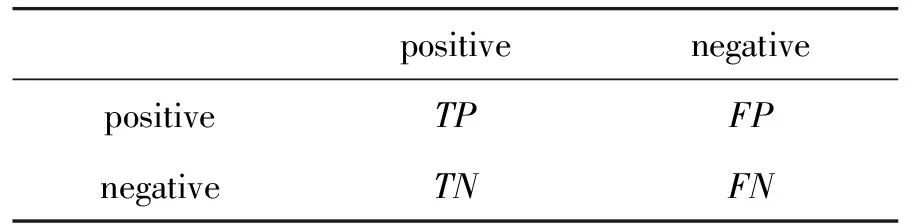
表1 混淆矩阵元素
基于混淆矩阵还可以产生很多指标,选用其中的AUC、accuracy和f1-score作为分类器性能的评价指标。AUC值是roc曲线下方的面积,AUC值不会随着类别分布的改变而改变,更好地反映不平衡数据的分类效果。AUC值越接近于1,分类效果越好。accuracy和f1-score的定义如下:
(10)
(11)
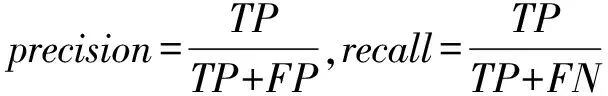
accuracy表示预测正确的样本数占样本总数的比例,是分类问题中最简单直观的评价指标。f1-score指标综合考虑了precision与recall。只有二者表现都很好时,f1-score值才大,才能对不平衡数据做出更合理的评价。
2.4 数据集
使用了UCI数据库的9个数据集对算法的有效性做出验证,表2描述了每个数据集的详细信息,即数据集的特征数、少数类样本数、多数类样本数和不平衡率。

表2 实验中使用的数据集
2.5 实验设计与结果分析
为验证本节改进的SMOTE算法的有效性,分别对9个数据集做SMOTE、Borderline-SMOTE和ADASYN平衡化处理,并对处理后的数据进行随机森林(RF)训练。对有多个类别的数据集,选择其中一类为少数类,其余剩下的所有样本作为多数类,训练集和测试集的样本数比例为7∶3。对比采用方法为SMOTE、Borderline-SMOTE和ADASYN采样方法,用Python现有的工具包,本文算法用Python编程实现。实验结果见表3,表中AUC、accuracy和f1-score的最优值用加黑粗体表示。通过实验结果可以得出如下结论:

表3 随机森林分类器实验结果
1)Vehicle和Ionosphere数据集维度高,Blood、CMC和Diabetes数据集维度相对较小,经过采样后,随机森林分类器在不同维度的数据集上分类情况并没有明显差别,可见维度对本文算法合成新样本的质量影响不大,可以提高少数类样本和整体样本的分类性能。
2)在Blood、Diabetes、Ionosphere和CMC数据集上本文算法性能较好,尤其是在Blood数据集上,随机森林分类器在AUC、f1-score和accuracy这3个指标上都达到了最优。而以上几个数据集相比于其他数据集,不同类别之间分布更加均衡,合成样本时引入噪声样本少,进而后续模型的训练准确率较高。但是在Vowel数据集上,本文算法在随机森林分类器上的训练结果没有明显提升,推测这与Vowel数据集不平衡率过高有关。
3 自适应集成的信用风险评估模型
3.1 自适应集成的信用风险评估模型
Stacking模型在实际应用中表现出很高的模型性能,但是仍有不足之处。利用K折交叉验证法在一定程度上能解决Stacking算法直接使用初级学习器预测结果作为训练集[17-19]所带来的模型过拟合问题。如果基模型之间差异太小,很难保证模型最终的泛化性能。因此,为最大程度提高模型的准确率和泛化性能,提出在模型训练之前,根据数据的特点为模型自适应的选择基模型,选择的基模型既要保证准确率,又要存在一定的差异性。
Jaccard系数用来比较样本集之间的相似性与差异性,在实际应用中,可用来比较布尔值属性对象之间的距离,Jaccard系数越大,两集合的相似度越高,反之越小。Jaccard系数定义为:
(12)
其中:A表示A集合,B表示B集合。
Jaccard距离是Jaccard系数的相反定义,Jaccard 距离越大,集合之间样本的相似度越低,用公式表示为:
(13)
余弦相似度度量可用来衡量2个对象之间的相似程度,余弦值越小,说明相似度越大,定义如下:
(14)
余弦相似度与欧式距离相比,从空间方向上对2个对象进行了区分,余弦相似度对绝对数值并不敏感,这正好与集合仅有0和1数值相契合。
Jaccard系数[20]这个指标的计算效率较高。通过组合Jaccard距离和余弦相似度来得到模型差异性度量指标,称其为JC指标,其中集合表示的是负类样本分类结果的集合。
JC=J(A,B)*cos(θ)
(15)
在模型训练之前,首先根据给定阈值,把准确率超过给定阈值的分类器保留下来,然后根据分类器之间的差异性度量也就是JC指标来选择基分类器。由于不同分类器在不同数据集上的表现不同,分类准确率差距较大,阈值的确定要根据不同数据的实际情况来考虑,金融背景之下的数据经过平衡化处理后在不同模型上的训练准确率较高,在3.3.2节中的给定阈值确定为0.85。
为了最大程度保证基分类器的差异性,在第二阶段要选择相似度最小的组合,然后再从其余未被选中的分类器集合中依次挑选分类器计算其相似度值,直到循环结束。基于模型差异性选择的Stacking的算法流程见图2。

图2 Stacking算法流程框图
基于模型差异性选择的Stacking模型算法步骤如下:
设训练样本集为T={(x1,y1),…,(xn,yn)},备选分类器为L1,L2,…,Lm。
输入:训练集T和备选分类器L1,L2,…,Lm;
输出:基于模型差异性选择的Stacking模型;
Step 1:在训练集T上训练m个备选分类器Li;
Step 2:计算m个备选分类器的准确率,将准确率高于给定阈值的备选分类器挑选出来;
Step 3:计算第一层所挑选分类器的JC指标,根据JC指标的值将差异度大的分类器作为基分类器,挑选出来的基分类器为为L1,L2,…,Lt;
Step 4:利用K折交叉验证训练基模型为L1,L2,…,Lt,并得到第二层元分类器的输入数据T′,T′用于下一步元分类器的训练;
Step 5:在输入数据T′上训练元分类器,得到最终模型。
3.2 数据集
本节采用Lending Club官网上的数据做实证分析,数据取自2019年第一季度,数据集中包含 115 675条样本,每个样本有150维特征,其中 loan-status为目标变量,本节是利用其他变量对目标变量情况做出预测,来决定样本是否能获得贷款。2.5节使用的9个数据集作为不平衡数据来验证改进的SMOTE算法的有效性,非信用风险方面的数据,不参与本节信用风险评估模型的验证。
在Lending Club原始数据集中,loan-status 有7种状态,其具体含义如表4所示。将其中的fully paid状态、current状态作为正常用户,其他状态作为违约用户。

表4 Loan-status的状态及含义
3.3 实验设计与结果分析
先对Lending Club原始数据做了预处理,对缺失数据根据缺失情况进行了相应处理,并进行两次特征选择,以最大化选择有效特征。
根据缺失数据的比例以及变量的重要性分别采用了删除法与填补法处理缺失值。对无意义特征和观测值相同的特征直接对其删除,由于特征缺失过多的数据所含信息过少,经过缺失值填补也会带来误差等问题,直接删除了缺失率大于50%的特征。对于缺失值大于等于8个特征的样本,也采用删除法直接剔除样本,共删除了85个样本。经过缺失值删除和无关变量剔除之后,数据集还包含 115 590个样本和83维特征,其中13个特征包含缺失数据,对这些数据进行缺失值填补。
特征选择采用了递归式特征消除,递归消除特征后挑选了40个特征。由于较多的变量可能会带来冗余信息,第二次特征选择采用主成分分析以实现最大程度减少信息冗余,提高模型的训练效率。
预处理后的数据集包含115 590条样本,特征维数为30,多数类样本数为106 715,少数类样本数为8 875,数据的不平衡率为0.083 2,属于较为严重的不平衡数据。
3.3.1过采样技术在Stacking分类算法下的比较
为了控制SMOTE过采样和改进的SMOTE过采样,对比实验的其他变量,更好地比较2种采样算法,这里把SMOTE和改进的SMOTE算法的采样倍数都设为1,SMOTE过采样后少数类和多数类的样本数都是106 715,改进的SMOTE过采样方法生成的少数类样本数为97 854。
Stacking模型的第一层基模型选用了朴素贝叶斯、决策树、逻辑回归,第二层元分类器选择逻辑回归。决策树采用CART算法,max-depth树最大深度设为39,max-leaf-nodes最大叶子节点数为30,逻辑回归的penalty正则化项默认为L2正则化项,正则化系数的倒数、迭代终止阈值等设为默认值,在SMOTE过采样和改进的SMOTE过采样后的数据上进行模型训练,模型训练过程中保持模型参数设置一致,模型训练结果如表5所示。

表5 不同过采样算法模型训练结果
改进的 SMOTE 过采样算法处理后的数据在 Stacking模型上的训练效果整体要优于SMOTE 过采样处理的数据,在accuracy、f1-score和AUC值上表现要优于SMOTE过采样算法。
3.3.2改进的SMOTE与基于模型差异性选择的 Stacking模型
为了挑选出更适合构建Stacking模型的基分类器,在3.3.1节实验所用的基分类器基础之上又加入了3个模型,这样基分类器池中就有了6个基分类器,分别为KNN、随机森林、支持向量机、朴素贝叶斯、决策树和逻辑回归模型。为了提高模型的训练效率,在这里随机抽取了30%的数据。
下面先单独训练6个基分类器,表6展示了6个模型的训练结果,可看出朴素贝叶斯的分类效果不如其他分类器,而随机森林模型分类效果明显优于其他模型。这与随机森林利用多个决策树共同分类决策密不可分。同时,随机森林因多棵决策树对多样性的保证提高了模型的泛化性能,因而分类效果要好于其他分类器。

表6 基模型训练结果
基于模型差异性选择的Stacking模型首先剔除在Lending Club数据集上分类情况较差的基分类器,根据实验结果是将朴素贝叶斯和决策树模型从基分类池中移除,根据JC指标挑选出的基分类器模型为KNN、随机森林、支持向量机,同时为了减少过拟合,集成所用的元分类器为逻辑回归模型,最后模型的训练结果如表7所示。

表7 基于模型差异性选择的Stacking模型训练结果
为了更好地展示基于模型差异性选择基分类器对Stacking整体模型的训练效果,下面将其与其他基分类器构建的Stacking进行对比实验,参数保持不变,只改变基分类器。对比实验所用的两组基分类器分别为KNN、逻辑回归和随机森林,逻辑回归、随机森林和支持向量机。以KNN、逻辑回归和随机森林为基分类器构造的Stacking模型记为Stacking 1,以逻辑回归、随机森林和支持向量机为基分类器构造的Stacking模型记为Stacking 2,根据JC指标挑选的基分类器构造的模型记为Stacking 3。
实验结果如表8所示,图中用黑色加粗标记同一指标下性能好的模型,Stacking 2模型在recall指标下的性能要优于Stacking 3模型,Stacking 3模型在accuracy、f1-score和AUC值上的表现要好于Stacking 1和Stacking 2模型,f1-score综合了recall与precision这2个指标,更具有说服力。基分类器池中剔除分类情况较差的基分类器保证了构成集成模型的基模型的准确率,同时根据JC指标挑选出的基分类器模型减少了过拟合现象。因此,实验结果表明根据JC指标挑选的基分类器对构建Stacking模型具有参考价值。

表8 3种Stacking模型实验结果
4 结论
基于SMOTE过采样和自适应集成模型对不平衡数据做出合理的分类预测将会给金融行业带来商业价值。不仅能帮助金融行业减少违约、欺诈用户带来的经济损失,还有助于留住行业内的正常用户,能有效提高行业竞争力。
在Lending Club数据集的实证分析中,改进的 SMOTE过采样方法处理后的平衡化数据在后期模型训练上表现优异,同时基于JC指标选择的基分类器在Stacking模型构建方面性能高。但改进的SMOTE过采样算法在不平衡程度过高的数据集上合成的新样本不能很好地遵循数据的原始分布,分类准确率提升效果一般,后期有待改进。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
软件导刊(2017年4期)2017-06-20
