
利用深度神经网络并结合配价信息的语义角色标注
2022-08-29 01:57袁里驰
小型微型计算机系统 2022年9期
袁 里 驰
(江西财经大学 软件与物联网工程学院,南昌 330013)
E-mail:yuanlichi@sohu.com
1 引 言
语义角色标注即识别谓词和给定谓词的参数并为其分配语义角色标签.由于具有对语义信息进行编码的能力,语义角色标注(SRL)已被应用于自然语言处理的许多任务,例如自动问答、信息提取和机器翻译等.语义角色与语法紧密相关,因此,传统的 SRL 方法在很大程度上依赖于句子的句法结构,这些内在的复杂性限制了系统只能基于特定领域.SRL 的传统方法通常从句子中提取大量手工特征,甚至是它的解析树,并将这些特征提供给统计分类器.然而传统方法还存在另外2个主要问题:首先,它们的性能在很大程度上依赖于特征工程,这需要领域知识和繁重的特征提取和选择工作.其次,虽然设计了复杂的特征,但很难对句子中的长距离依赖进行建模.
深度神经网络[1-7]能够自动获取特征,明显地降低特征工程的工作量,近年来,它在语言信息处理领域得到了广泛的应用.Transformers 的双向编码器表示(BERT)[8]已变得非常流行,并在最近的 NLP 研究中被证明是有效的,该研究利用大规模未标记的训练数据并生成丰富的上下文表示,显示出其在各种自然语言处理任务上的强大性能.近年来,没有句法输入的 SRL 端到端模型取得了可喜的成果[9,10].Zhou and Xu[9]引入了堆叠长短期记忆网络并取得了当时最好的结果.He等[10]使用具有约束解码的深度高速双向长短期记忆网络和循环dropout,将语义角色标注视为BIO 标记问题.该方法由公开可用的代码和模型支持,能够处理结构一致性和长距离依赖关系,进一步改进了语义角色标注的性能.这些涉及端到端模型[11,12]的成功揭示了LSTM 处理句子底层句法结构的潜在能力.
本文应用BERT语言模型提取上下文特征信息,结合BERT预训练模型与双向LSTM神经网络模型进行语义角色标注.长短时记忆模型能够有效地利用序列数据中的长距离相关信息,在序列标注任务中显示出强大的优势.配价语法[13,14]能够更好地描述语句的语义组成和语法结构,因而,本文在语义角色标注中增加谓词本身的配价数作为特征.利用条件随机场模型(CRF)计算相邻标签的转移概率,改进语义角色标记的效果.
本文的其余部分安排如下:第 2节介绍BERT语言模型;第 3节介绍配价语法和利用配价信息的语义角色标注;第 4节讨论基于BERT-BiLSTM-CRF并结合配价信息的语义角色标注方法;实验结果和分析在第 5 节中介绍;最后,结论和未来的工作在第 6节.
2 BERT语言模型
2018年,google团队Jacob Devlin等人提出了BERT预训练语言模型,该模型刷新了当时11种语言信息处理任务的最佳结果.BERT 的模型架构是一个基于原始实现的多层双向Transformer 编码器.BERT的关键结构是Transformer,Transformer是一个基于“自我关注机制”的深度结构,图1是它的编码器网络结构.

图1 Transformer编码器Fig.1 Transformer encoder
Transformer编码器的关键结构是自我注意机制,主要是利用同一句子中单词之间的关联度来校正权重系数矩阵以获得单词的表示形式:
(1)
其中,Q,K,V是字向量矩阵,dk是Embedding维度.多头注意力结构使用几个不一样的线性变换来投影Q,K和V,并最终把不同的注意力结构连接起来.计算如式(2)、式(3)所示:
MultiHead(Q,K,V)=Concat(head1,…,headn)WO
(2)
(3)
其中W是权重矩阵.集成位置信息,字符和单词信息以及段落信息的特征向量被输入到多层双向Transformer编码器中,编码器在位置l处输出向量Dl,sigmoid概率层使用它来推测位置l处的原始单词.然后在位置l输出标记yl的概率为:
Pr(yl)=sigmoid(WDl+d)
(4)
其中b、W分别是sigmoid概率层的偏差及权重矩阵,需要利用BERT模型实施预训练.
3 配价语法和基于配价信息的语义角色标注
3.1 配价语法
与依存文法类似,配价文法也发源于法国语言专家Tesnier的语言学理论.Tesnier 在语法中引入了“价”的概念来解释一个动词可以支配名词短语的个数.配价文法属于动词中心论,认为语句的中心是动词.动词根据它联系的动元(动词所联系的强制性语义成分即语义角色)的数量来分类,即动词的“价”分类,可分为一价动词、二价动词和三价动词三类.动词的配价结构与动词的语义角色标注尤其是核心语义角色标注有关,因而配价文法与语义分析密切相关.现在,对配价的研究不只包含动词,许多人还在研究名词和形容词的配价.在朱德熹对中文动词配价进行研究的带动下,袁毓林开始研究中文名词的配价[13].名词的配价结构与名词性谓词的语义角色标注尤其是内部角色标注有关.动名词性谓词的配价数可以参考基于配价理论开发的语义词典,也可以通过统计学习的方法从语义角色标注语料中获得.
3.2 利用配价信息的语义角色标注
通常的语言处理工作(词性标记、语法分析、语义分析、信息提取等)一般是按顺序实施的,即后一个工作是在完成前一个工作后开展的.比如,语义角色分析需要利用语法结构分析的信息.顺序开展任务并不是仅有的选择,通常存在以下不足:之前处理中的错误可能在后面处理中累积和放大,严重制约后续处理的结果;执行上一个工作时,不能使用后面工作的有用信息,一般来说,因为这两个工作密切相关,所以后续工作的信息在一定程度上对之前的工作是有益的.因此,如果两个或多个处理工作能够并行进行,那么这些处理工作就可以利用彼此的信息,进而从中受益.本文并行处理语法结构分析、融合配价结构的语义信息标记及分析,基本思想是:在句法分析的过程中,每当形成一条新的产生式p→c1,c2,…,cn时,(其中p为祖先结点,c1,c2,…,cn为子结点.)进行配价结构等语义信息标注及分析.同时将标注的语义信息融入产生式的概率计算.
设P为非终结符,H表示中心成分,L1表示左边修饰成分,R1表示右边修饰成分.hw,lw,rw均是成分的核心词,ht,lt,rt分别是它们的词性,P(h)表示句法树上当前核心词h所依赖的上层核心词.进一步假设,首先由P产生核心成分H,然后以H为中心分别独立地产生左右两边的所有修饰成分.这样,在本文的句法分析模型中,每一条文法规则写成如下形式:
P(ht,hw|P(h))-Lm(ltm,lwm)…L1(lt1,lw1)·H(ht,hw|P(h))R1(rt1,rw1)…Rn(rtn,rwn)
(5)
形如式(5)的文法规则的概率为:
(6)
其中,Lm+1和Rn+1分别为左右两边的停止符号.式(6)中的概率:
Pi(Ri(rti,rwi)|Ri-1(rti-1,rwi-1),…,R1(rt1.rw1),(ht,hw),P(h))
可分解为两个概率的乘积,如式(7)、式(8)所示:
Pi(rti|rti-1,rti-2,…,rt1,ht,rwi)
(7)
Pi(rwi|rwi-1,rwi-2,…,rw1,hw,P(h))
(8)
记S(rwi)表示词rwi-1,rwi-2,…,rw1,P(h)中与当前词rwi有语义搭配关系的词(由句子分析树标注的配价结构确定),则有:
Pi(rwi|rwi-1,rwi-2,…,rw1,hw,P(h))
=Pi(rwi|hw,Δr(i-1),S(rwi))
(9)
再假定hw,S(rwi)关于rwi条件独立有:

(10)
4 基于BERT-BILSTM-CRF并结合配价信息的语义角色标注方法
4.1 基于BERT的词嵌入层
利用神经网络模型处理语义角色标注任务,首先必需对文本进行向量化,利用一定维度的特征向量来表示单词.词向量能够描述词之间的语法和语义关系,作为词的特征输入神经网络.首先,以单词为单位切分句子,通过BERT模型预处理生成单词xi的基于上下文信息的单词矢量,得到D维词矢量,构成D×N词矩阵,其中N是训练语料中有效词的个数.其次谓词采用谓词本身、谓词词性、谓词的配价;当前词采用当前词本身、当前词的词性、当前词到谓词的距离及是否为候选论元的头节点(0/1)等特征.并为当前词和词性两个特征设置一个长度为3的窗口,即当前词、左一词、右一词及其词性作为特征.然后拼接上述特征为当前单词xi构建单词嵌入向量ei.
4.2 BILSTM层
传统的循环神经网络存在梯度消失或爆炸的问题,这意味着很难对长距离依赖进行建模.长短期记忆网络LSTM[15]旨在缓解这个问题.LSTM 单元由一个记忆单元、一个输入门、一个遗忘门和一个输出门组成.记忆单元携带 LSTM 单元的记忆内容,而门控制记忆内容的变化量和暴露量.设et表示时刻t的输入向量,ht-1表示LSTM单元的时刻t-1隐藏状态的输出,ct-1代表t-1时刻的细胞状态.LSTM 在时间 t 的工作流程能够表示为公式(11)-公式(16):
it=σ(Wiht-1+Uiet+bi)
(11)
ft=σ(Wfht-1+Ufet+bf)
(12)
ot=σ(Woht-1+U0et+bo)
(13)
(14)
(15)
ht=ot⊙tanh(ct)
(16)
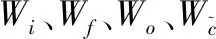
ht不仅包含局部信息,还包含来自先前输出状态ht-1的信息,因此可以捕获句子中的依赖关系.长短期记忆模型(LSTM)的门机制使模型能够获取到远距离的历史信息.因为向前和向后的依赖关系对于标记语义角色都很重要,所以本文用双向方法扩展了 LSTM,导致:
(17)

4.3 标记推理CRF层
根据之前的工作,本文将中文 SRL 视为序列标记的任务,它为序列中的每个单词分配一个标签.为了识别语义角色的边界信息,本文采取IOB标签方式.在序列标记任务中,相邻词的标记之间有着较明显的依赖关系.例如,标签B_ARG1 后面应该跟I_ARG1标签或者B_X标签,其余的标签都是非法的;而标签I_ARG1之前只能是B_ARG1或I_ARG1.因而,不是利用ht独立做出标记选择,而是利用条件随机场模型来联合建模标记序列.
给定语句X=(x1,x2,…,xn)和对应的语义角色预测标签Y=(y1,y2,…,yn),其中xi表示词,预测评估分数定义如下:
(18)
其中:θ是利用学习获得的模型参数,A是一个语义角色标签转换分数矩阵,Ai,j表示角色标签i到j的分数;Qi,yi表示句中第i个词xi标为角色标签yi的得分.h表示谓词,k∈M表示句子X=(x1,x2,…,xn)中与谓词h有配价关系或语义依存关系rel的词集合.Qi定义如下:
Qi=Wsht+bs
(19)
其中:ht是输入数据xt在BiLSTM中时刻t的隐藏状态;Ws为权重矩阵;bs为偏移矢量.
在条件随机场模型层,语句X被标注为角色标签序列Y 的概率如式(20)计算:
(20)
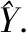
在深度神经网络模型训练过程中,损失函数如式(21)所定义:
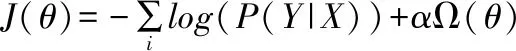
(21)
其中:X和Y分别为训练语料中的语句及相应的标记序列,Ω(θ)表示避免神经网络模型的过拟合而增加的正则项.
5 实验结果及分析
试验部分数据取自中文PropBank2.0和中文NomBank1.0.CTB是语言数据联盟发布的一个中文公开语料库,为中文语法分析研究提供了公开的训练、测试语料.PropBank2.0是University of Pennsylvania基于Penn TreeBank 5.1发布的的语义角色标记语料库,带有动谓词标记.而中文NomBank1.0是为了弥补PropBank只以动词为谓词的限制而发布的.它在Penn树库5.1中标记了名词谓词和其语义角色.为了在训练集、开发集和测试集中平衡各种语料来源,参照Xue[16]的实验数据划分,分别取中文PropBank2.0和NomBank1.0中的各648个文件共1296个文件用作训练语料,各40个文件共80个文件用作开发语料,各72个文件共144个文件用作测试语料.其中,开发语料、训练语料和测试语料分别拥有2060,31361和3599个动词谓词;训练语料、开发语料和测试语料所拥有的名词谓词个数分别为8642,731和1124.在本文这部分实验中使用SVM分类器,SVM分类器使用多项式核函数,模型的参数都是从训练集中采用极大似然法估计出来的;训练参数的调整设置均在开发集上进行;而模型和语义角色标注方法的性能评测在测试集上进行.
测试的结果采取了常用的3个评测指标,即精确率P、召回率R、综合指标F1值.其定义如下:
精确率(Precision)用来衡量语义角色标注系统分类器预测的语义角色总数中正确标注的语义角色的比例.
召回率(Recall)用来衡量语义角色标注系统分析出的所有正确语义角色在测试数据中的语义角色总数中的比例.
综合指标:F1=(P×R×2)/(P+R).
表1对比了应用自动/正确语法树和自动/正确动词谓词的各种角色的识别结果.其中第2列是在语法树正确、动词谓词正确的条件下得到的结果F1值;第3列是在自动谓词和自动语法树情况下获得的结果F1值.
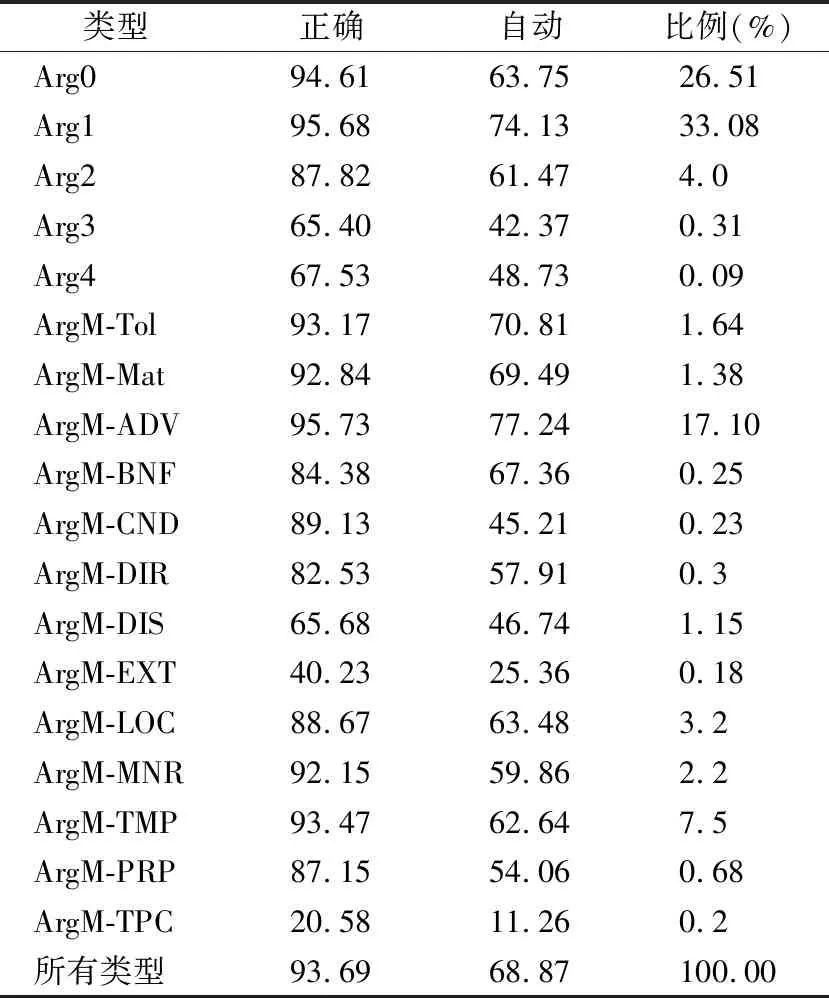
表1 各类动词性谓词语义角色的标注性能Table 1 Labeling performances of all types of semantic roles for verbal predicates
表2显示了基于正确语法树的各种角色的识别结果,分别是基于正确的名词谓词和自动的名词谓词条件下识别结果.

表2 主要名词性谓词语义角色在测试集上性能Table 2 Performance on the test data for main semantic roles of nominal predicates
本文的另一部分实验语料取自CoNLL-2005 共享任务和 CoNLL-2012 共享任务的常用数据集.CoNLL-2005 数据集以华尔街日报(WSJ)语料库的第 2-21 节作为训练集,第24节作为开发集.测试集由 WSJ 语料库的第 23部分以及来自 Brown语料库的 3 部分组成.CoNLL-2012 数据集是从 OntoNotes v5.0 语料库中提取的.
本文模型的主要参数设置如下:词嵌入和谓词掩码嵌入的维度设置为 128,Transformer层数设置为12.本文将隐藏单元的数量设置为 768.本文实验学习率取值0.001;实验采用了Dropout机制来防止神经网络过拟合,实验中Dropout设置为0.5.
表3列出了 CoNLL-2005 开发集和测试集上的语义角色标注精确率、召回率和综合指标 F1,并与前人工作进行了对比.
在表3中,本文给出了本文方法(DNN Utilizing Valence Information,利用深度神经网络并结合配价信息的语义角色标注方法)与以前方法在CoNLL-2005开发和测试集上的结果比较.Emma Strubell等提出了基于语言的自注意力(LI-SA)神经网络模型,将多头自注意力与跨依赖解析、词性标注、谓词检测和 SRL的多任务学习相结合,在WSJ、Brown数据集上的F1值分别为86.90%、78.25%;Zhixing Tan等提出了一个简单有效的基于 self-attention的SRL 架构,它可以直接捕获两个标记之间的关系,而不管它们的距离如何,在WSJ、Brown数据集上的F1值分别为86.1%、74.8%;而基于BERT-BiLSTM-CRF并结合配价信息的语义角色标注方法在WSJ、Brown数据集上的F1分数分别达到了87.00%、78.63%.同时在CoNLL-2005、CoNLL-2012开发和测试集上进行了消融实验,即在CoNLL-2005、CoNLL-2012 开发和测试集进行仅基于深度神经网络(BERT-BiLSTM-CRF)的语义角色标注和仅使用配价信息的语义角色标注两种方法的实验.
表4列出了 CoNLL-2012 开发集和测试集上的语义角色标注精确率、召回率和综合指标 F1,并与前人工作进行了对比.
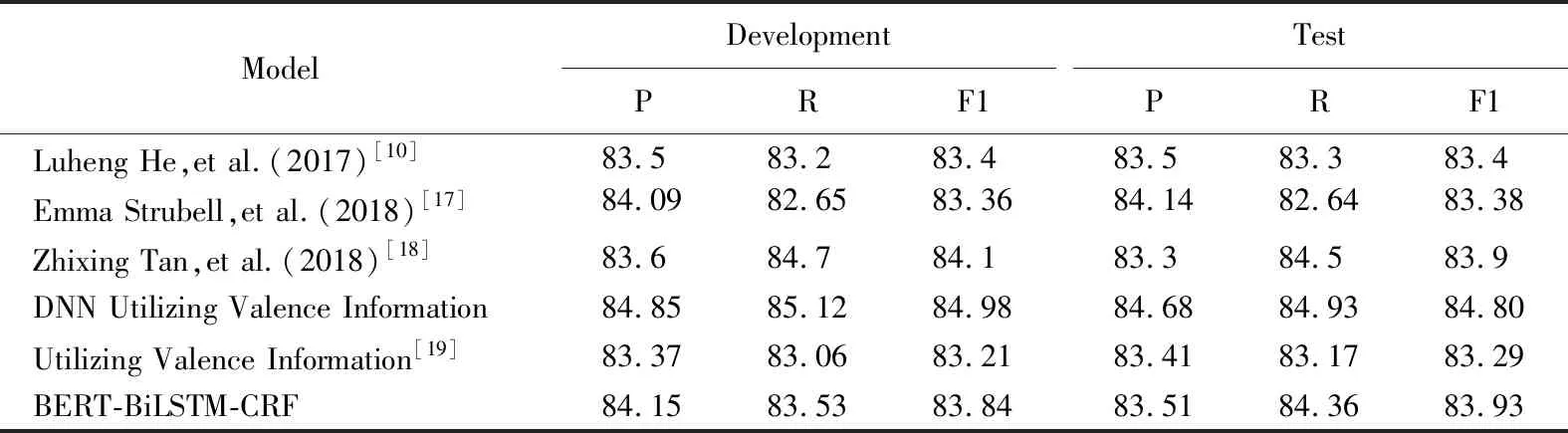
表4 CoNLL-2012 开发和测试集上的精确率、召回率和综合指标 F1Table 4 Precision,recall and F1 on the CoNLL-2012 development and test sets
在表4中,本文给出了本文方法与以前方法在CoNLL-2012开发和测试集上的结果比较:Emma Strubell et al提出的基于语言的自注意力(LISA)神经网络模型取得了83.38%的F1值;Zhixing Tan et al提出的基于 self-attention的SRL 架构取得了83.9%的F1值;而本文提出的基于BERT-BiLSTM-CRF并结合配价信息的语义角色标注方法取得了84.80%的F1值,大幅度提高了语义角色标注系统的性能.
比较表3、表4的语义角色标注测试结果,能够看到:配价语法能够更好地描述语句的语义构成和语法结构,将配价信息融入基于BERT-BiLSTM-CRF的语义角色标注模型能够显著提升系统的性能.
6 结 论
本文提出了一种融合配价信息的深度神经网络模型,它有效地结合了丰富的语言配价信息以进行语义角色标记,并在 CoNLL-2005 共享任务数据集和 CoNLL-2012 共享任务数据集上对其进行了评估,在两个基准 SRL 数据集上比以前的工作取得了更好的结果.
语义角色标记属于一种浅层语义分析.其本质是在语句层面实施浅层语义分析,语义角色分析通常要基于句法分析的结果.配价结构可以较好地刻画句子的句法结构和语义构成关系,本文提出了结合配价信息的句法分析与语义角色标注联合学习模型,本文实验验证了联合学习模型对提高语义角色标注性能的有效性.
猜你喜欢
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
文苑(2015年9期)2015-09-10
长江学术(2015年1期)2015-02-27
新课程学习·中(2013年3期)2013-06-14
教学与管理(理论版)(2009年9期)2009-11-04
中学数学研究(2008年3期)2008-12-09
