
融合商品流行度与信任度的混合推荐算法
2022-08-29 10:52虞慧群范贵生
华东理工大学学报(自然科学版) 2022年4期
段 琼, 虞慧群, 范贵生
(华东理工大学信息科学与工程学院,上海 200237)
在大数据时代,如何准确地推送项目或产品已经成为学术研究中的一个焦点。然而,随着信息技术和互联网的迅速发展,数据量呈爆炸式增长,信息超载已经成为一个日益严重的互联网问题。一些冗余信息会干扰用户做出正确的选择,并且成为用户的障碍。解决这些问题的有效方法之一就是个性化推荐,即根据用户的需求为用户推送新闻、商品和服务等。个性化推荐系统不仅可以为用户提供个性化服务,还可以与活跃用户建立长期的信任关系[1]。
目前协同过滤算法在推荐系统中的应用比较广泛,但由于其依赖于用户评分信息,数据稀疏性也是推荐系统中的一大难题[2-3]。近年来,随着社交信任网络的发展,信任度在推荐系统中发挥了重要作用[4-5]。最近的研究表明,通过挖掘用户信任关系来提高推荐性能是一种有效的方法。在通过融入信任信息来缓解数据稀疏性方面,Duan等[6]通过对间接信任的计算方法进行优化,考虑服务的受欢迎程度,设计了一种动态的信任调整方法,形式化了高级信任关系,并在此基础上设计了服务推荐机制,提出了一种新的服务推荐算法。Li 等[7]提出了一种信任扩展策略模型,通过信任扩展策略挖掘信任网络中与目标用户具有相似偏好的信任邻居。此外利用用户信任邻居的信任评级来计算用户之间的信任相似度,并在此基础上采用信任加权方法生成预测结果。除了正向搜索目标用户的信任好友外,Zhou 等[8]还提出了一种逆向搜索好友的推荐方法。该算法首先搜索目标用户的“敌人用户”;然后根据社会平衡理论间接推断目标用户可能的朋友;最后根据衍生出的目标用户的可能好友,向目标用户推荐最优服务。在通过融入信任值来解决冷启动方面,何利等[9]提出了一种基于用户多维度信任的冷启动推荐模型。该模型利用用户的信任信息获取目标用户的可信好友集合后,再利用传统评分计算公式来衡量用户间的评分相似度。在对于传统的评分相似度的改进方面,陈功平等[10]考虑了传统皮尔森系数在计算用户评分相似度时的缺点,通过融合流行项目惩罚系数与共同评分项目占比来对皮尔森相关系数进行改进和修订。但该方法在计算用户间的相似度时,只考虑用户评分的维度,相对单一。尽管上述方法使用信任关系来提高项目预测精度或针对商品流行度来提高评分相似度的准确性,但通常有以下缺点:(1)在描述用户间的信任关系时,容易忽视信任关系的复杂性与全局性;(2)在计算用户评分相似度时采用传统的皮尔森相似性系数等,忽视了用户共同评分项占比所带来的影响;(3)只考虑用户间的信任交互关系来提升综合相似度精度,忽视了推荐项目热门程度惩罚。
为了克服这些不足,本文提出了一种融合商品流行度与信任度的混合推荐算法(TPRA),重新定义了信任关系,考虑了项目的流行度,结合改进的评分相似度公式进一步提高推荐精度。
(1)通过引入信任关系数据来解决数据稀疏带来的问题,在缺乏用户评分数据的情况下,通过挖掘用户的直接信任好友和间接信任好友,得到目标用户的信任好友集;
(2)为了克服传统推荐算法因忽视商品流行度带来的问题,引入了基于商品流行度和用户共同评分项占比的评分相似度计算公式,将不同流行度的项目分别设置不同的贡献权重;
(3)将信任维度与基于流行度的商品维度相结合,从而更准确和全面地为目标用户推荐目标项目。
1 融合商品流行度与信任度的混合推荐算法
图1 示出了TPRA 算法的整体架构,图中U代表用户,i代表项目。该算法主要从信任度与基于商品流行度的评分相似度两个维度衡量用户间的综合相似度,并在此基础上为目标用户预测评分和项目推荐,从而实现个性化推荐过程。
1.1 用户信任度量模型
信任度是指目标用户对其他用户的信任程度。推荐系统中存在着用户信任网络,其中目标用户与其他用户存在一定的社会关系。图2 示出了用户U1的一个社交网络图。
在该网络中,用户被定义为节点,用户之间的信任链接用有向边表示。换句话说,U1对U2的信任程度与U2对U1的信任程度是不同的。有向边箭头所指端为此信任关系的被信者,有向边末端的用户为信托者。在社交关系中存在两种信任关系,一种为直接信任,另一种为间接信任。例如,在图2 中,U1直接信任U2,则认为U1与U2间存在直接信任关系;U2又直接信任U4,则认为U1与U4之间存在间接信任关系。

图1 TPRA 算法框架图Fig. 1 Framework of TPRA algorithm
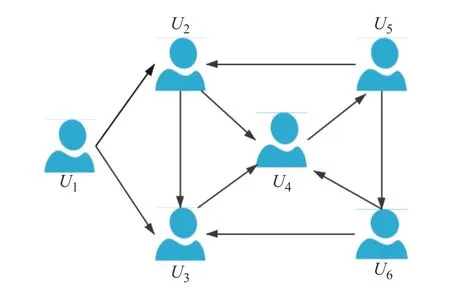
图2 用户U1 的社交网络图Fig. 2 Social network diagram of user U1
1.1.1 直接信任度 在一个社交网络中,当用户间存在直接信任行为时,用直接信任度来衡量两个用户间的信任值。用直接信任度0 表示用户间不存在直接信任关系,如图2 中U1与U4之间不存在直接信任关系,则直接信任度Dt(u1,u4)=0 ;U1与U2之间存在直接信任关系,则Dt(u1,u2)=1 。本文中,用户社交网络中的信任数据转化为用户间关于信任度的有向邻接矩阵,从而获取用户间的直接信任度取值。
1.1.2 间接信任度 在用户信任网络中,任何两个社交用户都可以通过六度分割(Six Degrees of Separation)模型进行链接。本文用间接信任度表示两用户间是否存在间接信任关系。在一个信任网络中,若存在可达信任链路route=(u,n1,n2,n3,n4,···,v),其中n1,n2,n3,n4,···表示此信任链路的中间用户,且链路长度大于1 时,称用户u与用户v之间有间接信任关系。根据信任传播机制,较短的路径可以使间接信任估计更加准确,用户的信任关联性会随着路径的增长而减弱。在信任网络中,可能有多个路径将信任从同一源头传播到目标用户,因此,间接信任度的计算如下:

1.1.3 直接信任概率 直接信任概率dp(u,v)是指当两用户间存在直接信任关系时,用户u直接信任用户v的概率。本文在考虑了信任双向性的基础上定义用户间的直接信任概率。考虑到两用户的共同直接信任好友集为空、导致直接信任概率为0 的情况,定义用户本身也是自己的一个好友。因此,直接信任概率表示如下:

其中:Fu为用户u的直接信任好友集;Fv为用户v的直接信任好友集;Fu∩Fv为用户u和用户v的共同直接信任好友集。在社交网络中,当用户间存在直接信任行为时,用直接信任度来衡量两用户间的信任值。
1.1.4 间接信任概率 间接信任概率idp(u,v)是指目标用户u的间接信任好友在信任社交网络中被其他用户信任的概率。根据社会学的研究,一个用户的信任入度(信任该用户的用户数目)越高,其被其他非直接信任好友信任的概率也越大。因此,本文将间接信任概率表示为
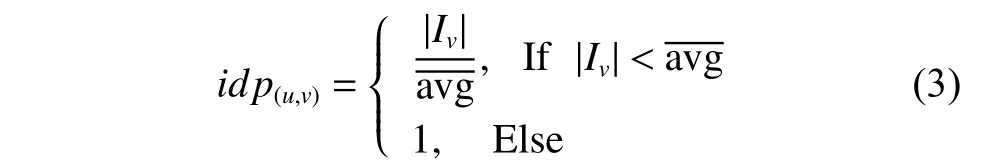
式中: |Iv| 为用户v的信任入度;为用户v所处信任关系网中用户的平均信任入度;当 |Iv| ≥时,用户v的全局可被信任概率为1。
1.1.5 综合信任度 用直接信任概率和间接信任概率分别对目标用户的直接信任度和间接信任度进行加权得到目标用户的综合信任度T(u,v),如式(4)所示。

1.2 基于商品逆流行度的用户评分相似度量
1.2.1 改进的评分相似度 传统的协同过滤推荐算法中常采用Jaccard 相似系数(JSC)和皮尔森相关系数(PCC)来衡量两用户之间的评分相似性。PCC 主要根据用户间共同评分项目的集合来计算评分差异,从而获得用户的评分相似性,如式(5)所示:

然而,PCC 忽略了用户共同评分项占比所带来的影响。例如,用户A 和用户B 收听了40 首相同的歌曲,但对歌曲的评分较少;用户A 与用户C 收听了2 首相同的歌曲,且对这两首歌曲的评价比较一致[11-12]。通过PCC 计算到的用户A 与用户C 之间的相似度比用户A 与用户B 之间的相似度要高,但在实际情况中用户A 与B 有更高的相似性,因此PCC不适合在数据稀疏以及分布不均的情况下使用。
JSC 主要用于计算有限集合中样本间的相似度,适用于稀疏度过高的数据集合。两用户共同评价的项目所占的比例越大,相似性越高。但JSC 不考虑用户对项目的评分取值,仅关注用户是否对该项目评过分,从而影响用户间相似性的准确度。
本文将PCC 与JSC 融合来计算用户间的评分相似性,融合后的评分相似性公式结合了两种方法的优点,既考虑了用户间重叠评分项数量对相似度的影响,又考虑了用户对各项目评分对相似度的影响。定义用户间的评分相似性系数如下:

其中:Nu表示用户u评过分的项目集合;Nv表示用户v评过分的项目集合。
1.2.2 融入热门商品惩罚的评分相似度 除了JCS和PCC 因为过于依赖评分信息而带来的数据稀疏难以处理和评分项占比的问题,大多数算法还忽视了一个问题,即在用户-物品评分矩阵中,不同物品对相似度的影响不同。在生活中存在一种现象,2 个对冷门事物感兴趣的人比2 个对流行事物感兴趣的人更有可能成为朋友,他们的相似度也更高。例如,两个用户都听过歌曲《最炫民族风》,不能据此表明他们的兴趣是相近的,可能是因为该音乐的市场宣传到位; 但如果两个用户都听过歌曲《水边的阿狄丽娜》这首冷门歌曲,则更能说明他们的品味较接近。因此,用户间若对冷门产品有过共同的观看(购买)行为,则更能反映其兴趣偏好的趋同性。就事物本身而言,事物流行程度越低,对其感兴趣的用户的兴趣权重分配值会越高。
商品流行度指的是所有用户中有多少用户对该商品实施了评分操作。一个项目被越多的人进行评分操作,代表该项目的流行度越高,因此本文提出了逆流行度的概念。逆流行度代表了项目的冷门程度,逆流行度越大,商品的冷门程度越高。逆流行度( u npopi)的计算公式如下:

其中:max(count)、min(count)分别代表所有物品中被评分的频率最大值和最小值; c ounti表示项目i被评分的频率。物品的逆流行度越大,物品的冷门程度越大,其对兴趣的潜在影响也越大。
基于项目逆流行度将项目分为热门项目集H(i)和冷门项目集C(i)两类集合,在这两类项目中设置不同的评分相似度贡献权重优化评分相似度。设置流行度阈值 ψ ,当 u npopii≥ψ 时,认为该项目属于冷门集C(i),否则认为该项目属于热门集H(i)。
本文在 S imuv的基础上进一步改进用户间的评分相似度,先将共同评分项目按照流行度划分为热门、冷门项目集合,再对不同项目集合在相似度衡量中的贡献上分别设定不同的价值权重,以此优化用户间的评分相似性。改进后的用户间评分相似度为:

其中:δ为热门项目对用户评分相似性度量的贡献权重,后续实验将确定该参数的最优取值。
1.3 评分信息与信任信息融合
从信任度和评分相似度两个维度来提升推荐性能,因此将用户的信任度与商品的流行度加权从而得到用户的综合相似度,提高预测精度。综合相似度CS(u,v)表示为
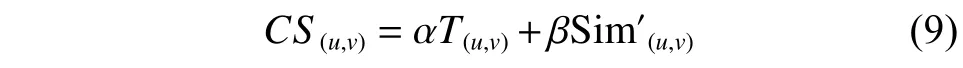
其中:T(u,v)表示用户u与v的综合信任度;表示用户u与v间改进后的评分相似度;α和β分别表示T(u,v)和的权重,且满足α+β=1。
1.4 评分预测
建立了用户的信任关系以及得到用户间的评分相似度之后,就可以筛选出值得信任的用户与评分相似的用户,从而实现对项目评分和推荐行为的预测。由综合相似度计算出与目标用户相似度最高的Top-K个最近可信邻居作为目标用户的最近可信邻居集,然后根据最近邻居好友的历史评分数据运用评分预测公式为目标用户进行评分预测。预测用户u对项目i的评分R(u,i)为
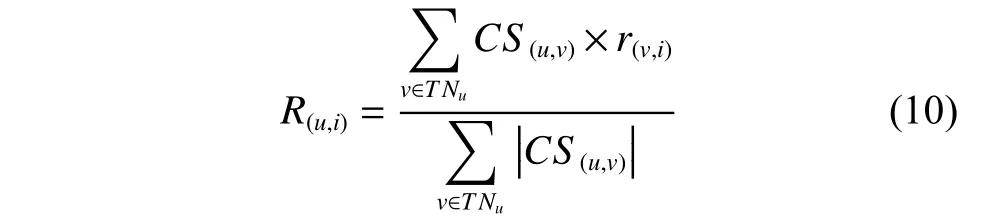
其中:R(u,i)表示用户u对项目i的评分;r(v,i)表示用户v对项目i的真实评分。
TPRA 算法描述如下:

2 仿真实验
实验采用一个真实数据集(Epinions)来预测该模型的性能,然后采用两个常用的评价指标,将本文方法的推荐结果与其他模型的推荐结果进行比较。
2.1 数据集及实验环境
Epinions 数据集包含75 888 个用户、29 000 个项目和681 213 个评级数据。Epinions 是一个真实的消费点评类网站,用户可以在此对视频、产品、音乐和服务通过评分的方式(评分为1~5 的整数)发表意见,也可以通过将其他人添加到自己的信任列表的方式与其他用户建立信任关系,信任值是0 或1(1 表示信任,0 表示不信任)。实验采用留一交叉验证法进行推荐效果评价。该方法通过隐藏一项评分,利用剩余评分数据和信任数据来对这项评分进行预测,而后对隐藏的实际评分和预测评分进行比较和评价。如此循环,对所有评分项进行预测,继而进行比较和评价。
实验环境设置如下:操作系统为Windows10,64 位系统旗舰版,CPU 为Intel Corei7-7500U,2.70 GHz,内存为8 GB,开发语言为Python。
2.2 评价指标
为了更好地评估推荐的质量,选择了两个度量指标:平均绝对误差(MAE)、均方根误差(RMSE)。
MAE 计算了所有预测评分与真实评分误差值的绝对值和的平均值(式(11)),故它可以衡量推荐算法的预测评分与真实评分之间的平均差异,其数值越小,说明预测的准确度越高。

其中:Ru,i为用户u对物品i的实际评分;为推荐算法给出的预测评分; |I| 为用户进行打分物品的个数。
RMSE 计算了所有预测评分值与真实值之间误差的平方和的均值的平方根(式(12)),其加大了对预测偏差较大的评分项的惩罚,对算法的评测要求更加苛刻,其值越小,说明算法的预测准确度越高。
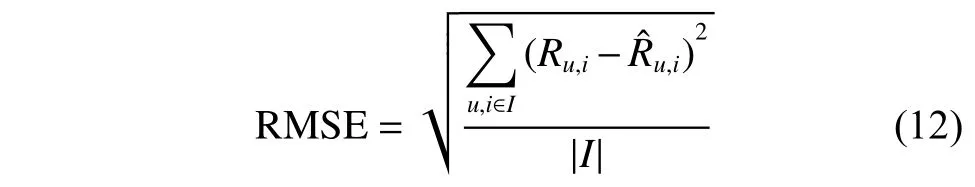
2.3 参数设定
针对Epinions 数据集,本文结合其数据分布不均和稀疏性问题,在交叉验证之后,参数设置如表1所示。其中d为信任网络中寻找间接信任好友的步长,结合计算成本和数据集中信任信息的分布情况,设置d的最大值为3; ψ 为区分项目为热门集还是冷门集的阈值,结合数据集分布不均和稀疏性的现状以及商品逆流行度的定义,将 ψ 的取值设置为0.9;δ为计算用户评分相似度时对热门项目的贡献权重。考虑到热门项目在计算用户评分相似度时要比冷门项目的贡献小,所以对热门项目的贡献权重从0.5 开始,以步长0.1 的速率递减。即分别设置 δ 为0.5、0.4、0.3、0.2、···(最小值为0.1)进行实验,对比不同取值情况下对推荐系统评价指标的影响,直到 δ 取0.4 时,该系统获得最好的推荐性能,所以设置 δ 的取值为0.4; α 为计算用户融合信任度与评分相似度的综合相似度时对信任度的权重。本实验从0.9 开始,以步长0.1 的速率递减。即分别取 α 为0.9、0.8、0.7、0.6、···(最小值为0.1)进行实验,对比不同取值情况下的评价指标,直到 α取0.8 时,该系统获得最好的推荐性能,所以设置 α 的取值为0.8。

表1 TPRA 模型参数设置Table 1 Parameter setting of TPRA
2.4 实验分析
2.4.1 实验一(不同推荐算法的评价指标对比) 为了验证TPRA 算法的推荐效果,在同一数据集(Epinions)下,对UCF(User-based Collaborative Filter)、DLM (Deep Learning Model)[13]、 FTM (Fuzzy-based Trust Model)[14]、ITRA (Implicit Trust Recommendation Approach)[7]、 TLSM-CDR (Trust-aware Latent Space Mapping Approach for Cross-Domain)[15]这4 个算法进行对比。
UCF 为传统的基于用户的协同过滤算法,该算法未考虑用户信任网络且采用传统的皮尔森相似性系数计算用户间的评分相似度。DLM 为基于神经网络的预测模型,该模型通过嵌入语义信息学习得到用户和项目的低维向量,此外,该模型利用前馈神经网络来表示用户和项目之间的交互。FTM 是一种基于模糊的信任模型,该模型对移动网络中用户节点的行为不确定性进行评估并预测每个用户对推荐的信任值。ITRA 为一种信任扩展策略模型,该模型通过信任扩展策略挖掘信任网络中与目标用户具有相似偏好和品味的用户信任邻居集,然后通过挖掘到的信任等级计算用户间的信任相似度,最后通过信任加权生成预测结果。TLSM-CDR 为基于信任感知映射的跨域推荐算法,该算法采用概率矩阵分解(PMF)来生成用户矩阵和项目矩阵,通过深度神经网络(DNN)和拉普拉斯矩阵将信任感知非线性映射,挖掘桥连接用户与非桥连接用户间的潜在空间关系,从而实现跨域推荐。
实验结果如图3 所示。根据定义,MAE 和RMSE衡量了预测评分与真实评分之间的差异,因此MAE和RMSE 的值越小,算法的预测准确度越高。可以看出,与其他4 种算法相对比,TPRA 的MAE 与RMSE 值均小于其他4 个算法的值。
由图3 可以看出:(1)FTM、ITRA、TLSM-CDR与TPRA 算法都在推荐算法中融入了信任机制,与传统的UCF 算法相比,MAE 与RMSE 值均有降低,推荐准确度明显提升,说明融入信任机制可以有效缓解推荐系统中的数据稀疏性问题;(2)TPRA、TLSMCDR 算法与ITRA 算法相比,推荐准确度有明显的提升,表明在信任机制中考虑信任双向性的重要性。TLSM-CDR 算法与TPRA 算法均考虑了信任的双向性,对于信任关系的量化更为准确;(3)TPRA 算法考虑了不同流行度的项目对于用户评分相似度的贡献不同,进一步提升了推荐效果的准确度。综上所述,TPRA 算法能够有效地提升推荐准确度,缓解了数据稀疏性问题。
2.4.2 实验二(不同子数据集下TPRA 算法的评价指标对比) 结合Epinions 数据集的数据分布以及TPRA算法中信任搜索的工作机制,将Epinions 数据集按照目标用户的直接信任好友数量进行划分,分别为Data1、Data2、Data3、Data4、Data5。这5 个子数据集中包含的目标用户的直接近邻个数分别为10、20、30、40、50。在5 个子数据集上分别进行实验,探究目标用户不同的直接近邻个数对MAE 和RMSE 值的影响,实验结果如图4 所示。
由图4 可以看出:当目标用户的直接近邻数为10,即实验数据集为Data1 时,信任机制中可挖掘的信息较少,不能有效地缓解Epinions 数据集中的数据稀疏性问题,此时的推荐准确度较低,MAE 和RMSE 值较高,推荐效果较差; 随着目标用户的直接近邻数逐渐增加,目标用户所处社交网络中的信任信息逐渐完善,MAE 和RMAE 值逐渐降低,推荐效果随着近邻数量的增加逐渐提高且趋于稳定。
3 结束语

图3 不同推荐算法的MAE(a)和RMSE(b)对比结果Fig. 3 MAE (a) and RMSE (b) comparison of different recommendation algorithms

图4 TPRA 算法在不同子数据集下的指标对比Fig. 4 Indexes comparison of TPRA algorithm in different subdata sets
为了解决现有基于信任关系的推荐方法中对信任关系定义不完整以及对商品流行度考虑不全的问题,提出了一种融合商品流行度与信任度的混合推荐算法。该算法重新定义了间接信任的计算方法,考虑了项目的流行度并结合改进的评分相似公式进一步提高推荐精度。实验结果表明:与对比算法相比,该算法提高了推荐质量,能够提供更准确的推荐结果。在Epinions 数据集上进行的实验结果表明,该算法在MAE 和RMSE 指标上相较于对照算法能获得更好的效果。由于本文对影响信任关系的时效性和地理位置影响因素考虑较少,在接下来的工作中将进一步优化信任关系模型, 考虑更多的因素, 如用户的地理位置以及动态信任,进一步提高推荐精度。
猜你喜欢
小雪花·初中高分作文(2019年10期)2019-02-12
环球时报(2018-01-23)2018-01-23
杂文月刊(2017年20期)2017-11-13
桃之夭夭B(2017年2期)2017-02-24
高中生·青春励志(2014年11期)2014-11-25
IT经理世界(2014年5期)2014-03-19
小雪花·成长指南(2009年10期)2009-12-04
