
递归最小二乘循环神经网络
2022-08-30 13:51张春元欧宜贵
自动化学报 2022年8期
赵 杰 张春元 刘 超 周 辉 欧宜贵 宋 淇
循环神经网络(Recurrent neural networks,RNNs)作为一种有效的深度学习模型,引入了数据在时序上的短期记忆依赖.近年来,RNNs 在语言模型[1]、机器翻译[2]、语音识别[3]等序列任务中均有不俗的表现.但是相比前馈神经网络而言,也正因为其短期记忆依赖,RNNs 的参数训练更为困难[4-5].如何高效训练RNNs,即RNNs 的优化,是RNNs能否得以有效利用的关键问题之一.目前主流的RNNs 优化算法主要有一阶梯度下降算法、自适应学习率算法和二阶梯度下降算法等几种类型.
最典型的一阶梯度下降算法是随机梯度下降(Stochastic gradient descent,SGD)[6],广泛应用于优化RNNs.SGD 基于小批量数据的平均梯度对参数进行优化.因为SGD 的梯度下降大小和方向完全依赖当前批次数据,容易陷入局部极小点,故而学习效率较低,更新不稳定.为此,研究者在SGD的基础上引入了速度的概念来加速学习过程,这种算法称为基于动量的SGD 算法[7],简称为Momentum.在此基础上,Sutskever 等[8]提出了一种Nesterov 动量算法.与Momentum 的区别体现在梯度计算上.一阶梯度下降算法的超参数通常是预先固定设置的,一个不好的设置可能会导致模型训练速度低下,甚至完全无法训练.针对SGD 的问题,研究者提出了一系列学习率可自适应调整的一阶梯度下降算法,简称自适应学习率算法.Duchi 等[9]提出的AdaGrad 算法采用累加平方梯度对学习率进行动态调整,在凸优化问题中表现较好,但在深度神经网络中会导致学习率减小过快.Tieleman 等[10]提出的RMSProp 算法与Zeiler[11]提出的AdaDelta算法在思路上类似,都是使用指数衰减平均来减少太久远梯度的影响,解决了AdaGrad学习率减少过快的问题.Kingma 等[12]提出的Adam 算法则将RMSProp 与动量思想相结合,综合考虑梯度的一阶矩和二阶矩估计计算学习率,在大部分实验中比AdaDelta 等算法表现更为优异,然而Keskar 等[13]发现Adam 最终收敛效果比SGD 差,Reddi 等[14]也指出Adam 在某些情况下不收敛.
基于二阶梯度下降的算法采用目标函数的二阶梯度信息对参数优化.最广泛使用的是牛顿法,其基于二阶泰勒级数展开来最小化目标函数,收敛速度比一阶梯度算法快很多,但是每次迭代都需要计算Hessian 矩阵以及该矩阵的逆,计算复杂度非常高.近年来研究人员提出了一些近似算法以降低计算成本.Hessian-Free 算法[15]通过直接计算Hessian 矩阵和向量的乘积来降低其计算复杂度,但是该算法每次更新参数需要进行上百次线性共轭梯度迭代.AdaQN[16]在每个迭代周期中要求一个两层循环递归,因此计算量依然较大.K-FAC 算法(Kronecker-factored approximate curvature)[17]通过在线构造Fisher 信息矩阵的可逆近似来计算二阶梯度.此外,还有BFGS 算法[18]以及其衍生算法(例如L-BFGS 算法[19-20]等),它们都通过避免计算Hessian 矩阵的逆来降低计算复杂度.相对于一阶优化算法来说,二阶优化算法计算量依然过大,因此不适合处理规模过大的数据集,并且所求得的高精度解对模型的泛化能力提升有限,甚至有时会影响泛化,因此二阶梯度优化算法目前还难以广泛用于训练RNNs.
除了上面介绍的几种类型优化算法之外,也有不少研究者尝试将递归最小二乘算法(Recursive least squares,RLS)应用于训练各种神经网络.RLS 是一种自适应滤波算法,具有非常快的收敛速度.Azimi-Sadjadi 等[21]提出了一种RLS 算法,对多层感知机进行训练.谭永红[22]将神经网络层分为线性输入层与非线性激活层,对非线性激活层的反传误差进行近似,并使用RLS 算法对线性输入层的参数矩阵进行求解来加快模型收敛.Xu 等[23]成功将RLS 算法应用于多层RNNs.上述算法需要为每个神经元存储一个协方差矩阵,时空开销很大.Peter等[24]提出了一种扩展卡尔曼滤波优化算法,对RNNs 进行训练.该算法将RNNs 表示为被噪声破坏的平稳过程,然后对网络的状态矩阵进行求解.该算法不足之处是需要计算雅可比矩阵来达到线性化的目的,时空开销也很大.Jaeger[25]通过将非线性系统近似为线性系统,实现了回声状态网络参数的RLS 求解,但该算法仅限于求解回声状态网络的输出层参数,并不适用于一般的RNNs 训练优化.
针对以上问题,本文提出了一种新的基于RLS优化的RNN 算法(简称RLS-RNN).本文主要贡献如下:1)在RLS-RNN 的输出层参数更新推导中,借鉴SGD 中平均梯度的计算思想,提出了一种适于迷你批样本训练的RLS 更新方法,显著减少了RNNs 的实际训练时间,使得所提算法可处理较大规模数据集.2)在RLS-RNN 的隐藏层参数更新推导中,提出了一种等效梯度思想,以获得该层参数的最小二乘解,同时使得RNNs 仅要求输出层激活函数存在反函数即可采用RLS 进行训练,对隐藏层的激活函数则无此要求.3)相较以前的RLS优化算法,RLS-RNN 只需在隐藏层和输出层而非为这两层的每一个神经元分别设置一个协方差矩阵,使得其时间和空间复杂度仅约SGD 算法的3 倍.4)对RLS-RNN 的遗忘因子自适应和过拟合预防问题进行了简要讨论,分别给出了一种解决办法.
1 背景
1.1 基于SGD 优化的RNN 算法
RNNs 处理时序数据的模型结构如图1 所示.一个基本的RNN 通常由一个输入层、一个隐藏层(也称为循环层)和一个输出层组成.在图1 中,Xs,t∈Rm×a,Hs,t∈Rm×h和Os,t∈Rm×d分别为第s批训练样本数据在第t时刻的输入值、隐藏层和输出层的输出值,其中,m为迷你批大小,a为一个训练样本数据的维度,h为隐藏层神经元数,d为输出层神经元数;Us-1∈Ra×h,Ws-1∈Rh×h和Vs-1∈Rh×d分别为第s批数据训练时输入层到隐藏层、隐藏层内部、隐藏层到输出层的参数矩阵;∈R1×h和∈R1×d分别为隐藏层和输出层的偏置参数矩阵;τ表示当前序列数据共有τ时间步.RNNs 的核心思想是在模型的不同时间步对参数进行共享,将每一时间步的隐藏层输出值加权输入到其下一时间步的计算中,从而令权重参数学习到序列数据不同时间步之间的关联特征并进行泛化.输出层则根据实际问题选择将哪些时间步输出,比较常见的有序列数据的分类问题和预测问题.对序列数据预测问题,输出层每一时间步均有输出;对序列数据分类问题,输出层没有图1 虚线框中的时间步输出,即仅在最后一个时间步才有输出.

图1 RNN 模型结构Fig.1 RNN model structure
RNNs 通过前向传播来获得实际输出,其计算过程可描述为

其中,1 为m行全1 列向量;φ(·) 和σ(·)分别为隐藏层和输出层的激活函数,常用的激活函数有sigmoid 函数与tanh 函数等.为了便于后续推导和表达的简洁性,以上两式可用增广矩阵进一步表示为

RNNs 的参数更新方式和所采用的优化算法密切相关,基于SGD 算法的RNNs 模型优化通常借助于最小化目标函数反向传播完成.常用目标函数有交叉熵函数、均方误差函数、Logistic 函数等.这里仅考虑均方误差目标函数


式中,◦为Hadamard 积,为输出层非激活线性输出,即

则该层参数更新规则可定义为

其中,α为学习率.


则该层参数更新规则可定义为
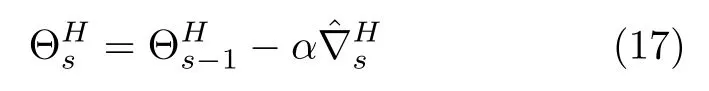
1.2 RLS 算法
RLS 是一种最小二乘优化算法的递推化算法,不但收敛速度很快,而且适用于在线学习.设当前训练样本输入集Xt={x1,···,xt},对应的期望输出集为.其目标函数通常定义为

其中,w为权重向量;λ∈(0, 1] 为遗忘因子.
令∇wJ(w)=0,可得

整理后可表示为

其中,

为了避免昂贵的矩阵求逆运算且适用于在线学习,令

将式(21)和式(22)改写为如下递推更新形式

由Sherman-Morrison-Woodbury 公式[27]易得

其中,

其中,gt为增益向量.进一步将式(23)、(25)和(26)代入式(20),可得当前权重向量的更新公式为
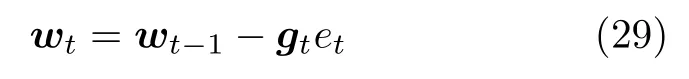
其中,

2 基于RLS 优化的RNNs 算法
RLS 算法虽然具有很快的学习速度,然而只适用于线性系统.我们注意到在RNNs 中,如果不考虑激活函数,其隐藏层和输出层的输出计算依旧是线性的,本节将基于这一特性来构建新的迷你批RLS 优化算法.假定输出层激活函数σ(·)存在反函数σ-1(·),并仿照RLS 算法将输出层目标函数定义为

其中,s代表共有s批训练样本;为输出层的非激活线性期望值,即

因此,RNNs 参数优化问题可以定义为

由于RNNs 前向传播并不涉及权重参数更新,因此本文所提算法应用于RNNs 训练时,其前向传播计算与第1.1 节介绍的SGD-RNN 算法基本相同,Hs,t同样采用式(3)计算,唯一区别是此处并不需要计算Os,t,而是采用式(12)计算.本节将只考虑RLS-RNN 的输出层和隐藏层参数更新推导.
2.1 RLS-RNN 输出层参数更新推导

将式(35)代入式(36),得

类似于RLS 算法推导,以上两式可进一步写成如下递推形式


2.2 RLS-RNN 隐藏层参数更新推导




其中,η为比例因子.理论上讲,不同迷你批数据对应的η应该有一定的差别.但考虑到各批迷你批数据均是从整个训练集中随机选取,因此可忽略这一差别.根据式(16)可知,且将式(59)代入式(55),得

其中,

式(61)的递归最小二乘解推导过程类似于输出层参数更新推导.令,同样采用上文的近似平均求解方法,易得

综上,RLS-RNN 算法如算法 1 所示.


3 分析与改进
3.1 复杂度分析
在RNNs 当前所用优化算法中,SGD 是时间和空间复杂度最低的算法.本节将以SGD-RNN 为参照,来对比分析本文提出的RLS-RNN算法的时间和空间复杂度.两个算法采用一个迷你批样本数据集学习的时间和空间复杂度对比结果如表1 所示.从第1 节介绍可知,τ表示序列数据时间步长度,m表示批大小,a表示单个样本向量的维度,h表示隐藏层神经元数量,d表示输出层神经元数量.在实际应用中,a和d一般要小于h,因而RLS-RNN的时间复杂度和空间复杂度大约为SGD-RNN 的3 倍.在实际运行中,我们发现RLS-RNN 所用时间和内存空间大约是SGD-RNN 的3 倍,与本节理论分析结果正好相吻合.

表1 SGD-RNN 与RLS-RNN 复杂度分析Table 1 Complexity analysis of SGD-RNN and RLS-RNN
所提算法只需在RNNs 的隐藏层和输出层各设置一个矩阵,而以前的RLS 优化算法则需为RNNs 隐藏层和输出层的每一个神经元设置一个与所提算法相同规模的协方差矩阵,因而所提算法在时间和空间复杂度上有着大幅降低.此外,所提算法采用了深度学习广为使用的迷你批训练方式,使得其可用于处理较大规模的数据集.
3.2 λ 自适应调整
众多研究表明,遗忘因子λ的取值对RLS 算法性能影响较大[28],特别是在RLS 处理时变任务时影响更大.由于本文所提算法建立在传统RLS 基础之上,因而RLS-RNN 的收敛质量也易受λ的取值影响.在RLS 研究领域,当前已有不少关于λ自适应调整方面的成果[28-29],因此可以直接利用这些成果对RLS-RNN 作进一步改进.
在文献[29]基础上,本小节直接给出一种λ自适应调整方法.对第s迷你批样本,RLS-RNN 各层中的遗忘因子统一定义为

其中,λmax接近于1,κ>1 用于控制λs更新,一般建议取2,通常κ取值越小,λs更新越频繁;ξ是一个极小的常数,防止在计算λs时分母为0;qs,和定义为

其中,μ0建议取 7/8;μ1=1-1/(ς1m),通常ς1≥2;μ2=1-1/(ς2m),且ς2>ς1.
当然,采用以上方式更新λs将会引入新的超参数,给RLS-RNN 的调试带来一定困难.从使用RLS-RNN 的实际经验来看,也可采用固定的λ进行训练,建议将λ取值设置在0.99 至1 之间.
3.3 过拟合预防
传统RLS 算法虽然具有很快的收敛速度,但也经常面临过拟合风险,RLS-RNN 同样面临这一风险.类似于第3.2 节,同样可以利用RLS 领域关于这一问题的一些研究成果来改进RLS-RNN.
Ekșioğlu[30]提出了一种L1正则化RLS 方法,即在参数更新时附加一个正则化项.对其稍加改进,则在式(50)和式(65)的基础上可分别重新定义为
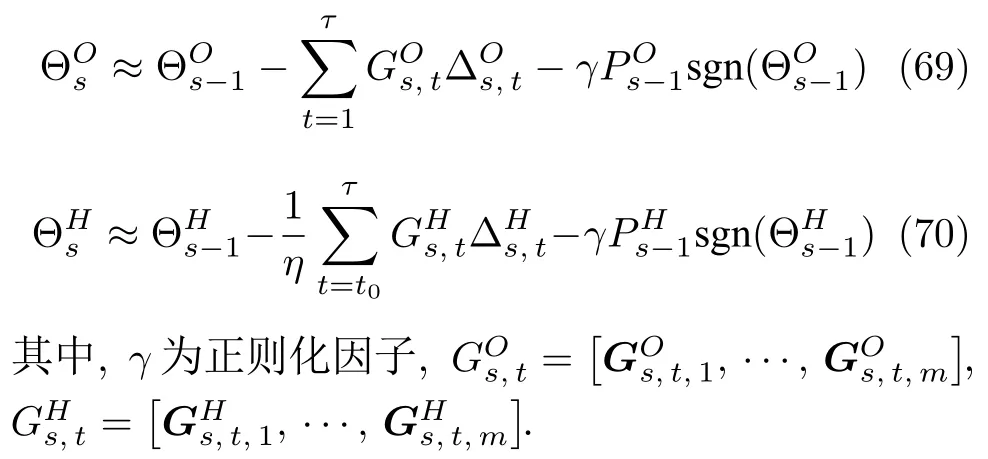
实际上,除了这种方法外,读者也可采用其他正则化方法对RLS-RNN 作进一步改进.
4 仿真实验
为了验证所提算法的有效性,本节选用两个序列数据分类问题和两个序列数据预测问题进行仿真实验.其中,两个分类问题为MNIST 手写数字识别分类[31]和IMDB 影评正负情感分类,两个预测问题为Google 股票价格预测[32]与北京市PM2.5 污染预测[33].在实验中,将着重验证所提算法的收敛性能、超参数α和η选取的鲁棒性.在收敛性能验证中,选用主流一阶梯度优化算法SGD、Momentum和Adam 进行对比,所有问题的实验均迭代运行150 Epochs;在超参数鲁棒性验证中,考虑到所提算法收敛速度非常快,所有问题的实验均只迭代运行50 Epochs.为了减少实验结果的随机性,所有实验均重复运行5 次然后取平均值展示结果.此外,为了观察所提算法的实际效果,所有优化算法在RNNs 参数更新过程均不进行Dropout 处理.需要特别说明的是:对前两个分类问题,由于时变性不强,所提算法遗忘因子采用固定值方式而不采用第3.2节所提方式;对后两个预测问题,所提算法遗忘因子将采用第3.2 节所提方式;所提算法对4 个问题均将采用第3.3 节所提方法防止过拟合.
4.1 MNIST 手写数字识别分类
MNIST 分类问题的训练集与测试集分别由55 000和10 000 幅 28×28 像素、共10 类灰度手写数字图片组成,学习目标是能对给定手写数字图片进行识别.为了适应RNNs 学习,将训练集和测试集中的每张图片转换成一个28 时间步的序列,每时间步包括28 个像素输入,图片类别采用One-hot 编码.
该问题所用RNN 模型结构设置如下:1)输入层输入时间步为28,输入向量维度为28.2)隐藏层时间步为28,神经元数为100,激活函数为tanh(·).3)输出层时间步为1,神经元数为10,激活函数为tanh(·).由于 tanh-1(1)和 tanh-1(-1)分别为正、负无穷大,在具体实现中,对 tanh-1(x),我们约定:若x≥0.997,则 tanh-1(x)=tanh-1(0.997);若x≤-0.997,则 tanh-1(x)=tanh-1(-0.997).RNN 模型权重参数采用He 初始化[34].
在收敛性能对比验证中,各优化算法超参数设置如下:RLS 遗忘因子λ为0.9999,比例因子η为1,协方差矩阵初始化参数α为0.4,正则化因子γ为0.0001;SGD 学习率为0.05;Momentum 学习率为0.05,动量参数0.5;Adam 学习率0.001,β1设为0.9,β2为0.999,ϵ设为 10-8.在超参数α和η选取的鲁棒性验证中,采用控制变量法进行测试:1)固定λ=0.9999,γ=0.0001 和η=1,依次选取α=0.01,0.1,0.2,···,1 验证;2)固定λ=0.9999,γ=0.0001和α=0.4,依次选取η=0.1,1,2,···,10 验证.
在上述设定下,每一Epoch 均将训练集随机划分成550 个迷你批,批大小为100.每训练完一个Epoch,便从测试集中随机生成50 个迷你批进行测试,统计其平均分类准确率.实验结果如图2(a)、表2 和表3 所示.由图2(a)可知,RLS 在第1 个Epoch 便可将分类准确率提高到95%以上,其收敛速度远高于其他三种优化算法,且RLS 的准确率曲线比较平滑,说明参数收敛比较稳定.表2 和表3记录了该实验取不同的α和η时第50 Epoch 的平均分类准确率.从表2 中不难看出,不同初始化因子α在第50 Epoch 的准确率都在97.10%到97.70%之间波动,整体来说比较稳定,说明α对算法性能影响较小.从表3 中可知,不同η取值的准确率均在97.04%到97.80%之间,波动较小,η取值对算法性能的影响也不大.综上,RLS 算法的α和η取值均具有较好的鲁棒性.

图2 收敛性比较实验结果Fig.2 Experimental results on the convergence comparisons

表2 初始化因子 α 鲁棒性分析Table 2 Robustness analysis of the initializing factor α

表3 比例因子 η 鲁棒性分析Table 3 Robustness analysis of the scaling factor η
4.2 IMDB 影评情感分类
IMDB 分类问题的训练集和测试集分别由25 000和10 000 条电影评论组成,正负情感评论各占50%,学习目标是能对给定评论的感情倾向进行识别.为了适应RNNs 学习,首先从Keras 内置数据集加载训练集和测试集的各条评论,选取每条评论前32个有效词构成一个时间步序列,然后对该评论中的每个有效词以GloVe.6B 预训练模型[35]进行词嵌入,使得每个时间步包括50 个输入维度,评论的正负情感类别采用One-hot 编码.
该问题所用RNN 模型结构设置如下:1)输入层输入时间步为32,输入向量维度为50.2)隐藏层时间步为32,神经元数为100,激活函数为 tanh(·).3)输出层时间步为1,神经元数为2,激活函数为tanh(·).tanh-1(x)问题和RNN 模型权重参数的初始化按第4.1 节方式同样处理.
在收敛性能对比验证中,各优化算法超参数设置如下:RLS 遗忘因子λ为0.9999,比例因子η为1,协方差矩阵初始化参数α为0.4,正则化因子γ为0.001;SGD 学习率为0.05;Momentum 学习率为0.05,动量参数0.5;Adam 学习率0.0001,β1设为0.9,β2设为0.999,ϵ设为 10-8.在超参数α和η选取的鲁棒性验证中,同样采用控制变量法进行测试:1)固定λ=0.9999,γ=0.001 和η=1,依次选取α=0.01,0.1,0.2,···,1 验证;2)固定λ=0.9999,γ=0.001 和α=0.4,依次选取η=0.1,1,2,···,10验证.
在上述设定下,每一Epoch 均将训练集随机划分成250 个迷你批,批大小为100.每训练完一个Epoch,便从测试集中随机生成50 个迷你批进行测试,统计其平均分类准确率.实验结果如图2(b)、表2 和表3 所示.由图2(b)可知,SGD 与Momentum 的收敛不太稳定,波动比较大,而Adam的准确率曲线则比较平滑,这三者在训练初期的准确率都比较低.相比之下,RLS 在训练初期的准确率已经比较接近后期预测准确率,前期收敛速度极快,整体准确率也明显优于其余三种优化算法.表2和表3 记录了IMDB 实验取不同的α和η时第50 Epoch 的平均分类准确率.由表2 易知不同α的情况下准确率浮动范围比较小,因此不同α对算法的影响比较小.由表3 可知,采用不同η时其准确率在72.86%到73.82%之间浮动,可见η的取值对算法性能影响较小.综上,RLS 算法的α和η取值在本实验中同样都具有较好的鲁棒性.
4.3 Google 股票价格预测
Google 股票价格预测问题的数据源自Google公司从2010 年1 月4 日到2016 年12 月30 日的股价记录,每日股价记录包括当日开盘价、当日最低价、当日最高价、交易笔数及当日调整后收盘价五种数值,学习目标是能根据当日股价预测调整后次日收盘价.为了适应RNNs 学习,首先对这些数值进行归一化处理,然后以连续50 个交易日为单位进行采样,每次采样生成一条5 维输入序列数据,同时将该次采样后推一个交易日选取各日调整后收盘价生成对应的一维期望输出序列数据,取前1 400条序列数据的训练集,后续200 条序列数据为测试集,并将训练集和测试集的样本分别随机置乱.
该问题所用RNN 模型结构设置如下:1)输入层输入时间步为50,输入向量维度为5.2)隐藏层时间步为50,神经元数为50,激活函数为 tanh(·).3)输出层时间步为50,神经元数为1,激活函数为identity(·).RNN 模型权重参数采用高斯分布随机初始化.
在收敛性能对比验证中,各优化算法超参数设置如下:RLS 遗忘因子采用第3.2 节自适应方式,其参数κ=1.5,λmax=0.9999,q0=10,μ0=7/8,ς1=6,ς2=18,ξ=10-15,鲁棒性实验中自适应参数与此相同,RLS 的比例因子η为1,协方差矩阵初始化参数α为0.3,正则化因子γ为0.000001;SGD 学习率为0.05;Momentum 学习率为0.05,动量参数0.8;Adam 学习率0.001,β1设为0.9,β2设为0.999,ϵ设为 10-8.在超参数α和η选取的鲁棒性验证中,采用控制变量法进行测试:1)固定γ=0.000001 和η=1,依次选取α=0.01,0.1,0.2,···,1验证;2)固定γ=0.000001 和α=0.3,依次选取η=0.1,1,2,···,10验证.
在上述设定下,每一Epoch 均将训练集随机划分成28 个迷你批,批大小为50.每训练完一个Epoch,便从测试集中随机生成50 个迷你批进行测试,统计其均方误差(mean square error,MSE).实验结果如图2(c)、表2 和表3 所示.由图2(c)可知,Adam 在前期误差较大,但是很快降低到SGD 与Momentum 的误差之下,Momentum 则比SGD 稍强一些,RLS 则在迭代初期就几乎收敛.表2 和表3记录了该实验取不同的α和η时在第50 Epoch 的平均MSE.由表2 可知,在不同α取值下,实验结果都比较接近,波动较小,这说明α的取值对于RLS 算法性能的影响较小.由表3 可知,当η取不同值时,MSE 值变化不大,因此η对算法影响较小.综上,RLS 算法的α和η取值在本实验中也具有较好的鲁棒性.
4.4 北京市PM2.5 污染预测
北京市PM2.5 污染预测问题的数据源自2010年1 月1 日至2014 年12 月31 日每小时的监测记录.每条记录由PM2.5 浓度、露点、摄氏温度、气压、组合风向、累计风速、降雪量、降水量共8 个属性值组成,学习目标是能根据当前小时的监测记录预测两个小时后的PM2.5 浓度值.为了适应RNNs 学习,首先对风向数据按序编码,然后对属性数值归一化,接着以连续24 小时为单位进行采样,每次采样生成一条8 维输入序列数据,同时将该次采样后推两个小时选取各小时的PM2.5 浓度值生成一条对应的一维期望输出序列数据,并取前35 000 条序列数据为训练集,后续8 700 条序列数据为测试集.需要说明的是,由于这一问题比较简单且训练集较大,所提算法和Adam 运行一个Epoch基本即可收敛,为了更好地对各算法性能进行区分,只取训练集前7 000 条和测试集前3 700 条数据并分别随机置乱进行训练和测试.
该问题所用RNN 模型结构设置如下:1)输入层输入时间步为24,输入向量维度为8.2)隐藏层时间步为24,神经元数为50,激活函数为 tanh(·).3)输出层时间步为24,神经元数为1,激活函数为identity(·).RNN 模型权重参数的初始化按第4.3 节方式同样处理.
在收敛性能对比验证中,各优化算法超参数设置如下:RLS 遗忘因子采用第3.2 节自适应方式,其参数κ=2,λmax=0.9999,q0=10,μ0=7/8,ς1=6,ς2=18,ξ=10-15,鲁棒性实验中自适应参数与此相同,RLS 的比例因子η为1,协方差矩阵初始化参数α为0.4,正则化因子γ为0.000001;SGD 学习率为0.05;Momentum 学习率为0.05,动量参数0.8;Adam 学习率0.001,β1设为0.9,β2设为0.999,ϵ设为 10-8.在超参数α和η选取的鲁棒性验证中,同样采用控制变量法进行测试:1)固定γ=0.000001和η=1,依次选取α=0.01,0.1,0.2,···,1验证;2)固定γ=0.000001 和α=0.4,依次选取η=0.1,1,2,···,10 验证.
在上述设定下,每一Epoch 均将训练集随机划分成140 个迷你批,批大小为50.每训练完一个Epoch,便从测试集中随机生成50 个迷你批进行测试,统计其均方误差损失.实验结果如图2(d)、表2和表3 所示.由图2(d)可知,SGD、Momentum、Adam 的损失初期均较大,收敛速度较缓慢;而RLS 的曲线几乎在第1 个Epoch 就收敛完成,因此其收敛速度要优于3 个对比优化算法.表2 和表3记录了该实验取不同的α和η时在第50 Epoch的平均MSE.表2 中在取不同α时,其MSE 上下波动幅度较小,且没有明显的变化趋势,因此我们认为α对算法性能影响较小.由表3 可知,对η取不同值时,其平均MSE 在 1.50×10-3到1.59×10-3间波动,整体来说浮动范围较小.综上,RLS 算法的α和η取值都具有较好的鲁棒性.
5 结论与展望
在RNNs 优化训练中,现有一阶优化算法学习速度较慢,而二阶优化算法和以前的RLS 类型优化算法时空复杂度又过高.为此,本文提出了一种新的RLS 优化算法.该算法吸收了深度学习中广为应用的迷你批训练学习模式,在推导过程中我们将研究重点放置在隐藏层和输出层的非激活线性输出上,通过等价梯度替换,最终得到各层权重参数的递归最小二乘解.所提算法只需在RNNs 的隐藏层和输出层各添加一个协方差矩阵,解决了长期以来RLS 优化算法应用时需要为隐藏层和输出层的每一神经元设置一个协方差矩阵的问题,极大地降低了时空复杂度,使得RLS 可以适用于较大规模的RNNs 训练.在此基础上,采用遗忘因子自适应调整和正则化技术对所提算法作了改进,进一步提高了所提算法的性能.4 组仿真实验表明,所提算法在收敛性能、稳定性以及超参数选取的鲁棒性等方面均要明显优于主流一阶优化算法,能够有效加快RNNs 模型的训练速度,降低超参数的选择难度.此外,在实验过程中我们还发现所提算法可缓解梯度消失导致RNNs 无法训练的问题.如何将本算法扩展到RNNs 以外的其他深度学习网络以及如何进一步降低所提算法的时空复杂度将是我们下一步工作的重点.
猜你喜欢
科技研究·理论版(2021年22期)2021-04-18
成都信息工程大学学报(2021年6期)2021-02-12
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
农业机械学报(2020年2期)2020-03-09
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
读与写·教育教学版(2017年10期)2017-11-10
电脑知识与技术(2016年28期)2016-12-21
科技视界(2016年16期)2016-06-29
火控雷达技术(2016年3期)2016-02-06
南都周刊(2015年4期)2015-09-10
