
面向教育领域的基于SVR-BiGRU-CRF中文命名实体识别方法
2022-09-05 09:00张召武高克宁王同庆张乔乔
中文信息学报 2022年7期
张召武,徐 彬,高克宁,王同庆,张乔乔
(东北大学 计算机科学工程学院,辽宁 沈阳 110179)
0 引言
中文命名实体识别(Chinese named entity recognition)是中文自然语言处理中的一项基本任务。通常,将中文命名实体识别看作是一种序列标注任务,对实体的边界和类别标签进行预测。在教育领域中,相关实体主要是知识点实体和法则实体。随着近些年来自然语言处理技术的不断发展,在教育领域中使用自然语言处理技术得到人们的重视,例如,将命名实体识别应用到诸如机器自动提问和智能问答等相关任务中。
随着近些年来互联网技术的高速发展,数据出现爆炸式的增长,从数据中抽取有用的信息是非常有必要的,而作为信息抽取的重要环节,命名实体识别的发展在最开始是通过人工制定一些规则和设置对应的词典[1]进行,需要大量的人力物力,并且模型适用的范围较小,不能够应用到不同的领域中。基于传统的机器学习的方法(如条件随机场CRF[2]、支持向量机SVM[3]和隐马尔可夫HMM[4]等)进行命名实体识别需要对不同的领域进行不同的特征工程,相对繁琐,模型缺乏一定的泛化能力。深度学习的方法不需要手动地设置规则和提取特征,并且在性能上远远优于传统的命名实体识别方法,特别是针对序列标注任务的RNN网络在近些年来得到广泛关注。Hammerton[5]使用LSTM网络来进行命名实体识别,取得了很好的效果,Lample[6]等使用LSTM-CRF将神经网络与条件随机场结合起来,在命名实体识别上取得了显著的性能提升,Huang[7]等发现使用BiLSTM-CRF模型来进行命名实体识别能够有效结合上下文的信息,在这一方面要优于LSTM-CRF网络,并且在性能上也优于LSTM-CRF网络。Collobert[8]等使用CNN代替LSTM的CNN-CRF模型也取得了不错的效果,同时相较于LSTM,CNN网络有着更快的模型训练速度。
对于教育领域的命名实体识别来说,能够采用上述模型,但是效果较差,并且中文不同于英文,对于英文来说有着明确的单词分隔符号和一些词组的固定搭配,而中文不仅没有明确的分隔符号,并且中文的词也不是固定的,同时教育领域的命名实体识别要求对实体边界的识别要十分精确。中文进行分词还会带来OOV(中文溢出词)问题,Chen[9]等的研究发现分词的好坏会直接影响命名实体识别的最终效果。He和Wang[10]等人发现,对于中文采用基于字符的方法可以避免分词上的错误,Chen[11]和Yang[12]等使用字符和双字符进行结合,使单纯的基于词的中文命名实体识别方法在性能上有着一定的提升。但是单纯的基于字的方法会损失掉大量的词汇信息。Huang[13]等采用了外部词汇信息,将词汇特征加入到基于字的模型中。Zhang和Yang[14]等提出了字词融合的Lattice LSTM模型,加入了外部词典,充分地使用词信息,在中文命名实体识别上取得了巨大的性能提升,但是由于网络结构的特殊,Batch size只能设为1,不能够并行地进行训练,所以模型的训练速度非常慢。Zhu[15]等提出了一个不依赖于外部词典的带有局部注意力层的基于字符的卷积神经网络和一个具有全局注意力层的GRU网络组成的模型,用来捕捉相邻字符和句子的上下文信息,该模型不依赖任何外部资源,性能上也要优于Lattice LSTM网络。
对于教育领域命名实体识别来说,融合字词信息是非常重要的,但是Lattice LSTM网络设计得十分复杂。而且由于网络结构限制无法进行并行训练,如果一个字符同时与多个词对应还会产生冲突,难以得到正确的标签。对于以上问题,Gui[16]等提出了带有Rethinking机制的CNN网络进行中文命名实体识别,解决模型训练速度慢和词冲突的问题。Sui[17]等提出了字符级的协作图网络LGN,分为编码层、构图层、融合层和解码层,通过各个节点的相连结构来实现局部语义信息的融合,增加一个全局节点实现全局信息的融合,不断地递归融合其传入节点和全局节点,实现节点信息更新,从多角度全方位地融合词信息。中文命名实体识别另一个关键点在于词向量的表示上,改进输入层的向量特征对于基于深度学习的方法是至关重要的。现有的预训练模型如BERT[18]对一些自然语言处理任务也有显著的性能提升。但是对于教育领域的命名实体识别来说,要想融合字和词信息,需要设计一种全新的向量表示层,Ma和Peng[19]等提出了一种SoftLexicon的分词方法,用来对输入的文本进行分词,并且能够融合字词信息,取得了较好的结果。
1 相关工作
对于教育领域的命名实体识别,传统方法效果差,并且费时费力,所以本文采取主流的深度学习模型,将模型分为向量表示层、序列建模层和标签层。
向量表示层将每个字与词的相关信息和位置信息融合起来,我们使用了和Lattice LSTM相同的中文词典和中文字符,在Word2Vec[20]上进行训练,得到对应的词向量,将字在句中的位置进行归一化处理,得到对应的位置向量表示,将字和字对应的词的词向量还有字的位置向量进行拼接得到一个新的向量表示作为序列建模层的输入。我们的模型SVR-BiGRU-CRF主要分为三个部分: SVR(Simple Vector Representation)在向量表示层对字、词和位置信息进行融合,在不改变网络结构的基础之上更好地将字、词和位置信息进行融合。BiGRU作为序列建模层,BiGRU相对于BiLSTM结构上更简单,由三个门合并成两个门,并且减少了相应的矩阵参数,计算量比BiLSTM降低,加快了模型训练速度。通过向量表示层和序列建模层得到特征信息,采用CRF层来判别标签是否符合规则,从而得到合理的标签标注。
我们使用的教育数据集(Edu)来源于诸如百度百科、百度文库、维基百科等包含学科知识点的语句,收集了中学数学相关领域的知识点语句,对知识点语句中的实体进行标注。
本文的主要贡献可以概括为以下两方面:
(1) 在向量表示层上对字、词的信息和字的位置信息进行融合,无须改变网络结构,避免了网络结构变化带来的计算复杂度的增加,使得计算效率更高。
(2) 使用传统的BiGRU和BiLSTM代替Lattice LSTM作为网络层来处理文本的向量表示,降低序列建模层复杂程度,提升模型的训练速度。
2 中文命名实体识别模型
2.1 模型结构
本文提出的模型由三个部分组成,分别是向量表示层、序列建模层和标签层。向量表示层将字词信息和位置信息相融合,得到对应的向量表示;序列建模层为BiGRU,标签层使用CRF得到最终的输出,图1为模型结构。

图1 模型结构
本文使用的数据集为Resume和教育数据集(Edu),训练集的标注有BMES(四位序列标注法)和BIO(三位序列标注法)两种形式,对于Resume数据集是BMES标注形式;对于教育数据集(Edu),是BIO标注形式。同时对向量表示层做了两种设计,一种是针对BIO标注的数据集,另外一种是针对BMES标注的数据集,并且为了证明该模型的泛化能力,在两个数据集上进行了实验。
2.2 向量表示层
向量表示层将输入语句中的字、词和位置信息进行融合,从而避免单纯地使用字作为输入,不仅能充分地使用文本中的词信息,也能避免基于词的方法需要进行分词所带来的OOV问题,最大程度上将输入语句中的信息输入到序列建模层中。同时将位置信息融入向量表示层中,能更好地界定实体的边界。
向量表示层对字、词和位置信息的融合,能够有效识别实体的边界和实体类型,对于字词信息的融合, Lattice LSTM模型通过改变LSTM网络的架构,将词信息融入模型中,但是网络结构复杂带来了训练速度变慢的问题。本文从词向量表示层入手,对字、词和位置信息进行融合,避免构造复杂的网络,实现一种通用的字、词和位置信息融合的方法,提升模型的训练速度和准确率,本文提出的方案如下。
2.2.1 字向量表示
输入的句子S是由多个字符{c1,c2,c3,…,cn}等组成的序列,对于每个字符ci,我们可以通过预训练的字向量得到对应的向量表示,如式(1)所示。
(1)
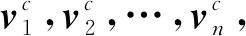
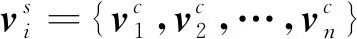
(2)
2.2.2 词向量表示
该部分考虑到由于中文分词带来的OOV错误和数据集的两种标注方式,对于BMES标注和BIO标注使用两种词向量获取方式,对于输入到词向量表示层的句子S={c1,c2,…,cn},为尽可能匹配到句子中所有出现的词,使用了通过Word2Vec得到的预训练的词向量文件,并根据Peng[19]等提出的SoftLexicon方法采用词标注的类别对得到的词进行分类,类别中未存在的词我们使用None表示,分词方法如图2所示。

图2 SoftLexicon分词方法
在获取词信息的同时,还统计该字位于句中的位置信息,位置信息的pi,如式(3)所示。

(3)
通过字在词中的不同位置对词进行分类,由于存在两种标注方式,下面分别给出这两种形式的分词方式,如式(4)、式(5)所示。
2.2.3 字词向量和位置信息融合
通过上面两部分可以得到输入文本的字向量、词向量和字的位置信息。考虑到每个字对应的词集合中各类别中的词数量的不同,我们需要对各个类别中出现的词集合进行一下处理,得到对应的类别向量。
对于词集合的处理,我们使用加权融合的方式。对于每个词在所给数据集中出现的频率和对应词所在类别中词的数量在整个词集合中所占的比重对词向量进行加权融合,将每个类别下的多个词的词向量通过加权融合的方式最终得到对应类别的向量,加权融合如式(6)和式(7)所示。
式(6)用来统计该词位于的类别中包含的词的个数在整个词集合中所占的比重,Cs中“s”代表对应的类别,将对应类别中的词的数量相加除以词集合中所有词的数量得到对应的类别权重,分别给出了BIO标注和BMES标注公式。
(6)
对于词集合中的每个类别中的词向量进行融合,我们考虑到该类别中词在数据集中出现的频率作为融合词向量的权重,统计词w在数据集中出现的次数得到频率权重O(w),如式(7)所示。
(7)
通过上面两部分得到了词集合对应类别权重和词的权重,将该类别中每个词与其对应的频率权重O(w)相乘,得到每个词的向量表示,然后对应类别中词的词向量相加,再乘以类别权重Cs,最终得到对应类别的加权向量表示,如式(8)所示,这里给出了两种标注方式的计算方法。
(8)
通过上面三部分,将输入语句中的字信息、词信息和位置信息进行拼接,得到该字符的最终向量表示,如式(9)所示。该方法考虑了词出现的频率,词对应类别在词集合中所占的比重,对同类别下的词向量进行融合,得到该类别对应的向量表示。这样就能够在不改变网络结构的情况下,对字、词和位置信息进行融合,最大化地利用输入语句中给出的信息。
(9)
2.3 序列建模层
序列建模层使用BiGRU网络,相较于基线模型Lattice LSTM对LSTM网络进行更改,BiGRU并不需要修改网络。Lattice LSTM网络通过对LSTM网络进行修改增加了cw单元来处理词信息,更改了LSTM网络的结构,Lattice LSTM网络结构如图(3)所示。

图3 Lattice LSTM网络结构
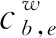
(10)
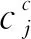
(11)
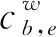
相对于复杂的Lattice LSTM需要改变网络结构来引入词信息,在本模型中,GRU并不需要进行网络结构上的修改,因为在向量表示层就将字、词和位置信息进行结合,GRU只需处理向量表示层输入的信息,就能够将词信息融入到网络中,GRU网络的定义如式(12)所示。
(12)
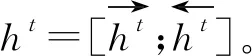
2.4 标签层


(13)

(14)
3 实验与分析
3.1 数据集
本实验使用了两个中文命名实体识别数据集,其中Resume数据集[14]是BMES标注,教育数据集(Edu)是BIO标注,使用两种标注数据集能够验证模型的泛化能力。数据集的具体信息如表1所示。

表1 数据集信息
3.2 实验设置
3.2.1 参数设置
本文中使用了和Lattice LSTM相同的词典ctb.50d.vec,该预训练词向量使用Word2Vec模型进行训练,包含5 700个单字词、129 000个双字词和278 000个三字词和一些其他字词,字向量使用的是也是与Lattice LSTM相同的预训练字向量Giga-Word,该预训练字向量也使用word2vec模型进行训练,ctb.50d.vec和Giga-Word都是50维向量。
模型使用单层的BiGRU作为序列建模层,初始学习率learning rate设置为0.015,学习率衰减learning rate decay设置为0.05,梯度裁剪clip设置为5.0,dropout设置为0.5,batch size设置为1,迭代次数设置为100,详细信息如表2所示。
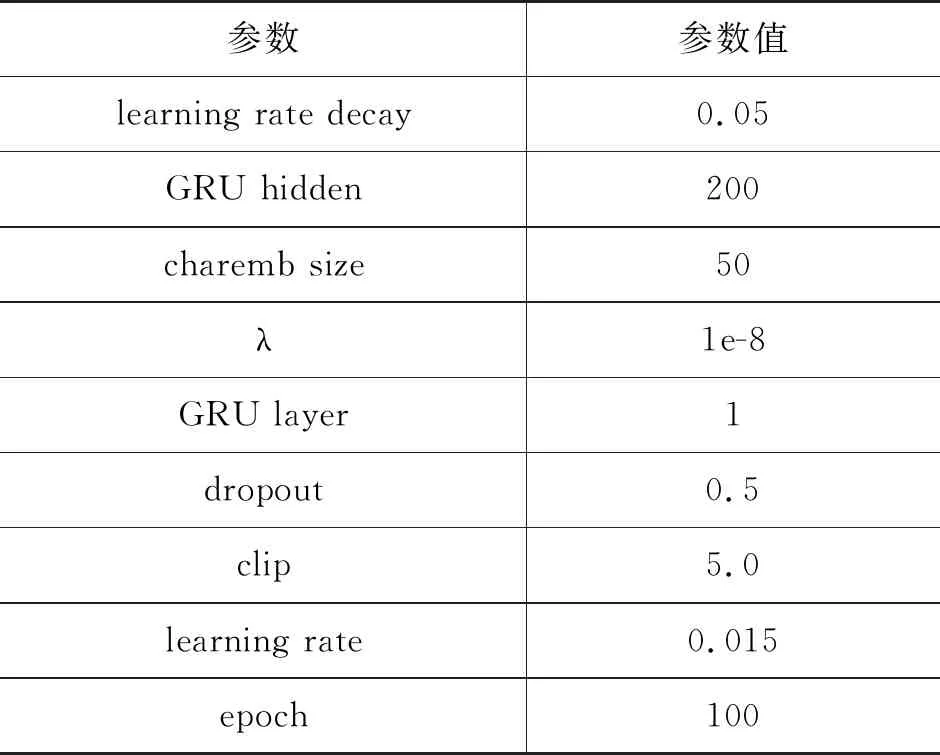
表2 超参数设置
3.2.2 评价指标
实验中使用的数据集被划分为训练集、验证集和测试集。使用精确率P(Precision)、召回率R(Recall)和F1值(F1Score)作为模型的评价指标。
3.3 实验结果
3.3.1 Resume数据集实验结果与分析
Resume数据集包含国家(CONT)、教育机构(EDU)、地点(LOC)、人名(PER)、机构(ORG)、职业(PRO)、种族(RACE)和职业(TITLE)八种类别,采用BMES标注。在该部分将本文的模型与基线模型Lattice LSTM进行对比,Lattice LSTM提出了一种词格结构,将词信息融入网络中,避免分词对模型性能带来的影响,但是Lattice LSTM对网络结构进行了修改,导致模型的训练速度变慢,但是相比较于基于字符和基于词的模型,Lattice LSTM在性能上得到了提升。Resume数据集中文命名实体识别实验结果如表3所示。
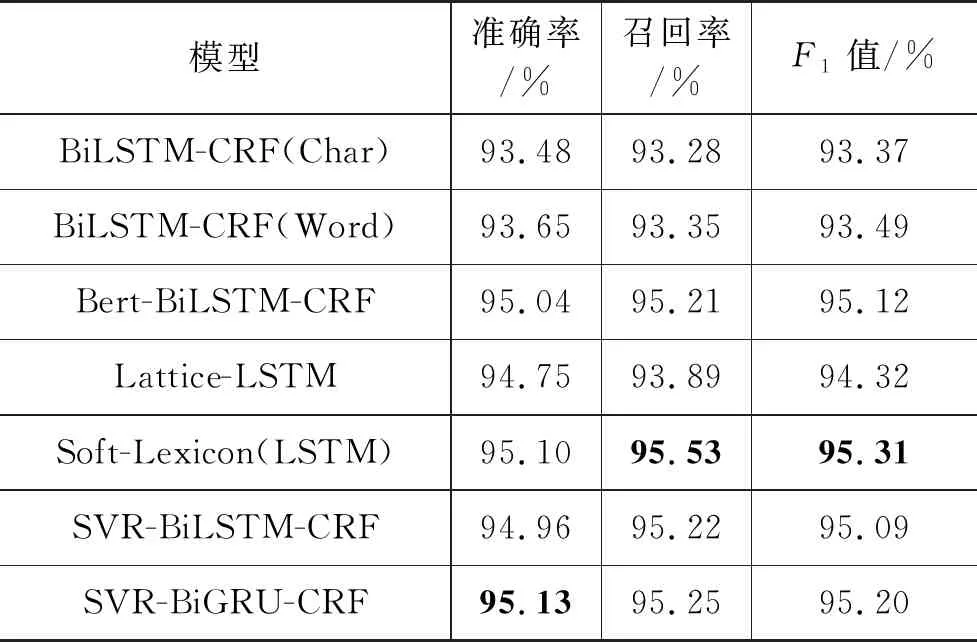
表3 Resume数据集实验结果
通过对基于字符的BiLSTM-CRF和基于词的BiLSTM-CRF进行对比。我们发现,采用基于词的中文命名实体识别模型在性能上要优于基于字的模型,说明融入词信息对于中文命名实体识别是十分重要的。Bert-BiLSTM-CRF模型在性能上要优于基线模型Lattice LSTM,考虑到Resume数据集较小,包含的句子和实体相对较少,Lattice LSTM模型依赖外部词典的原因,在性能上出现差距是正常的。在Resume数据集的实验中Peng[19]等提出的SoftLexicon(LSTM)在召回率和F1值上达到了最优,而本文提出的模型在准确率上达到了最优,说明采用SoftLexicon方法对输入的文本进行分词处理,可以更好地将词信息融合到向量表示层中。
3.3.2 教育数据集实验结果与分析
教育数据集(Edu)包含知识点实体(KNOW)实体、法则实体(PRIN)和非实体(O),采用的是BIO标注的方式。在这一部分我们使用了BERT-BiLSTM-CRF、SVR-BiLSTM-CRF、SVR-BiGRU-CRF、SoftLexicon(LSTM)和基线模型进行实验,教育数据集(Edu)中文命名实体识别实验结果如表4所示。

表4 教育数据集实验结果
实验结果显示: 在教育数据集上,本文提出的模型SVR-BiGRU-CRF在召回率和F1值上取得了最优结果,在准确率上低于SVR-BiLSTM-CRF。同时,该数据集是通过BIO进行标注的,不同于Resume数据集BMES的标注方式。BIO分别代表词的开头、词的中间部分和非实体部分。并且本文提出的模型在三个评价指标上得到了最优结果,本文考虑到教育领域的实体对实体边界的识别要求十分精确,采用本文提出的方法能够对字、词和位置信息进行融合,相比于其他的方法,能够更好地区分实体边界,取得较好的效果。
实验部分采用了两个数据集,本文提出的模型在这两个数据集上均能取得较好的结果,并且本文提出的模型在教育领域数据集上取得了最优的F1值,表明模型是有效的。本文模型在两个不同标注的数据集上也取得了较好的结果,证明了模型具有一定的泛化能力。
3.4 对比实验
本节为了验证模型的有效性,我们分别在两个数据集上进行对比实验,主要是对模型的训练速度、不同的序列建模层和向量层的融合方式对模型产生的影响进行对比实验。
3.4.1 模型训练速度对比实验
该部分我们以基线模型Lattice LSTM的训练速度作为标准,分别对Bert-BiLSTM-CRF、SVR-BiGRU-CRF和SVR-BiLSTM-CRF三个模型进行对比,因为基线模型Lattice LSTM网络结构的原因,我们对以上三个模型的batch size均设为1,模型训练速度对比如图4所示。

图4 训练速度对比
以基线模型Lattice LSTM模型训练时间作为基准,分别在两个数据集上进行模型训练,BERT-BiLSTM-CRF在两个数据集上的训练速度是基线模型的3倍左右。本文模型的训练速度是基线模型的4倍左右。并且使用BiGRU作为序列建模层比使用BiLSTM作为序列建模层在训练速度上有一定的提升。
3.4.2 序列建模层对比实验
在这里我们对BiGRU和BiLSTM作为序列建模层进行实验,通过上面的模型训练速度的对比实验我们能够看出,BiGRU相比于BiLSTM有着更快的模型训练速度。在这一部分,我们对两种不同的序列建模层的实验效果进行对比,实验结果如表5所示。
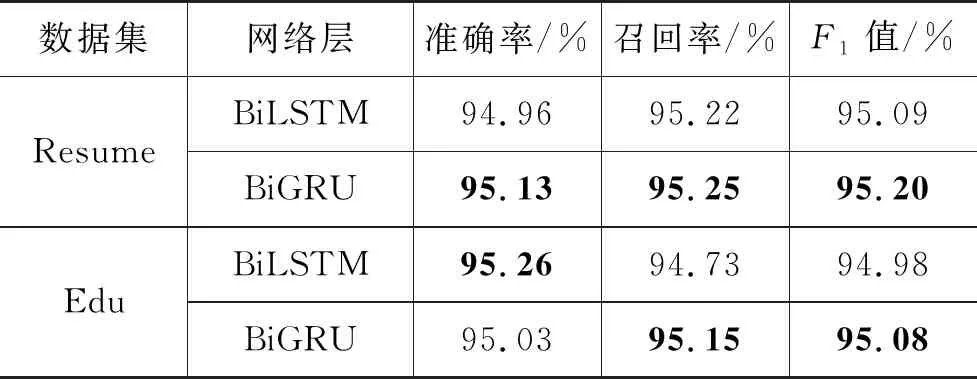
表5 序列建模层对比结果
通过该对比实验得知,两者在性能上并无太大的差距,使用BiGRU不仅能够加快模型的训练速度,同时模型的性能也不会有较大的损失。
3.4.3 融合方式对比实验
在向量表示层中,基于SoftLexicon分词方法得到字对应的词集合。针对这一部分字词向量的融合,本文给出了加权融合的方式,为证明该方法的有效性,在这里我们对使用加权融合的和直接进行相加融合的Resume数据集和Edu数据集进行对比实验,实验结果如表6所示。

表6 融合方式对比结果
通过对比实验我们发现使用加权融合的方式在准确率、召回率和F1值上都要优于直接相加融合的方式,这也表明本文提出的字、词和位置信息融合的方法是有效的,在两种不同标注方式的数据集上都能够取得最优的性能。
4 结论
在本文的工作中,我们提出了一种针对教育领域中文命名实体识别的方法,并通过将字、词和位置信息融合。该方法能够将文本输入的信息最大限度地融入向量表示层中,丰富了特征信息;能够有效地将字信息、词信息和位置信息进行融合;能够很好地解决教育领域数据对实体边界识别的问题。使用BiGRU作为序列建模层替代Lattice LSTM,能够加快模型的训练速度。对不同标注方式的两个数据集进行实验,验证了模型的泛化能力。实验结果表明,本文提出的模型在训练速度和性能上都取得了一定的提升,优于基线模型,在教育数据集上取得了较好的结果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
成都信息工程大学学报(2021年5期)2021-12-30
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
电子制作(2018年17期)2018-09-28
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
