
单词嵌入表示学习综述
2022-09-17 07:31刘建伟
控制理论与应用 2022年7期
刘建伟,高 悦
(中国石油大学(北京)自动化系,北京 102249)
1 引言
在自然语言处理的历史上,单词嵌入表示学习(word embedding)一直是人们研究的一个热点,它是自然语言处理(natural language processing,NLP)中语言模型与表示学习技术的统称,是将自然语言表示的单词转换为计算机能够处理的向量或矩阵形式的技术.与先前的独热表示(one-hot)、n-元文法(n-gram)[1]、共现矩阵(co-occurrence matrix)不同,单词嵌入表示保留了丰富的语义信息,能更好地完成NLP任务.NLP任务包括词类语法解析[2-3]、命名实体识别[4]和语义角色标注[5]、机器翻译[6],单词嵌入表示已被证明在各种任务中表现良好[7-10].Harris[11]在1954年提出的分布假设(distributional hypothesis)为单词向量表示提供了理论基础:上下文相似的单词,其语义也应该相似.Firth[12]在1957年对分布假设进行了进一步明确的阐述:单词的语义由其上下文决定.基于分布假设得到的表示均可称为分布表示(distributional representation),也就是单词嵌入表示(word embedding)[7].Bengio等人[13]在2003年提出了神经语言模型(neural language model,NLM),NLM是单词嵌入表示的基本模型,与n-gram通过联合概率分布考虑单词之间的位置关系不同的是,NLM利用单词向量表示进一步表示词语之间的相似性,比如,近义词在相似的上下文里的可替代性,或者同类事物的词可以在语料中出现频数不同的情况下获得相似的概率,从而克服维数灾难问题.Mikolov[14-15]在2013年提出了Word2Vec模型,包含了两个单词向量表示学习模型:Continuous Bagof-Words(CBOW)和Skip-Gram.为了更深入的理解单词嵌入表示,本文针对单词嵌入表示从不同的角度进行分类,如图1所示.本文结构安排如下:第1节为引言,简单介绍了单词嵌入表示的发展和现状;接下来两节都是单语言单词嵌入表示模型,第2节按照模型的输入的颗粒度分为字符级单词嵌入表示模型、单词级单词嵌入表示模型和短语级及以上的单词嵌入表示模型;第3节根据模型是否结合上下文,可以解决一词多义的问题,分为上下文无关的模型和考虑上下文信息的模型,由于第2节介绍的模型多为上下文无关的模型,这里就不多加赘述了,在第3 节主要介绍考虑上下文信息的模型;第4节介绍跨语言单词嵌入表示模型;第5节介绍的是单词嵌入表示模型与其它类型的模型的联合应用;第6节对单词嵌入表示模型未来趋势及发展方向进行了讨论;第7节是本文的总结.

图1 单词嵌入表示分类Fig.1 Classification of word embeddings
2 按模型输入颗粒度分类
单词嵌入表示是自然语言处理的重要方式,但单词嵌入表示通常使用神经网络学习并捕获关于单词的句法和语义信息.用单词嵌入表示学习单词表示时,通常会忽略有关单词形态和形状的信息.但对于词性标注这样的任务,特别是在处理形态丰富的语言时,单词内信息非常有用.字符级单词嵌入表示考虑到了上述问题,现对其介绍如下.
2.1 字符级单词嵌入表示模型
2.1.1 CharWNN
Dos Santos等人[16]在深度神经网络结构(deep neural network,DNN)基础上提出了字符级单词神经网络(character-level word neural network,CharWNN),CharWNN能够学习单词的字符级嵌入表示,并将它们与常用的单词级表示相关联,进行词性标注(partof-speech,POS)等任务.CharWNN新颖之处在于使用卷积层捕捉字符级嵌入表示,能够从任意长度的单词中提取有效的特征表示.比如,在进行词性标注时,卷积层为每个单词生成字符级嵌入表示,包括超出词汇表范围的词(out of vocabulary,OOV),实现过程如下.
网络的第1层是表示初始化,将单词转换为特征向量(嵌入表示形式),用于捕获关于单词的形态、句法和语义信息.假定W是与训练文本有关且单词数量固定的单词词汇表,单词由固定大小的字符词汇表Ccclr里的字符组成,给定一个由N个单词{w1,w2,···,wN}组成的句子,每个单词wn ∈W都被转换为一个向量un,nπ{rw,rotr},rw ∈为wn的单词级嵌入表示,rchr∈Rclu为wn的字符级嵌入表示.单词级嵌入表示旨在捕获语法和语义信息,字符级嵌入表示可捕获形态和形状信息,公式如下:
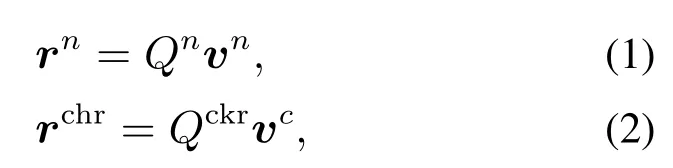
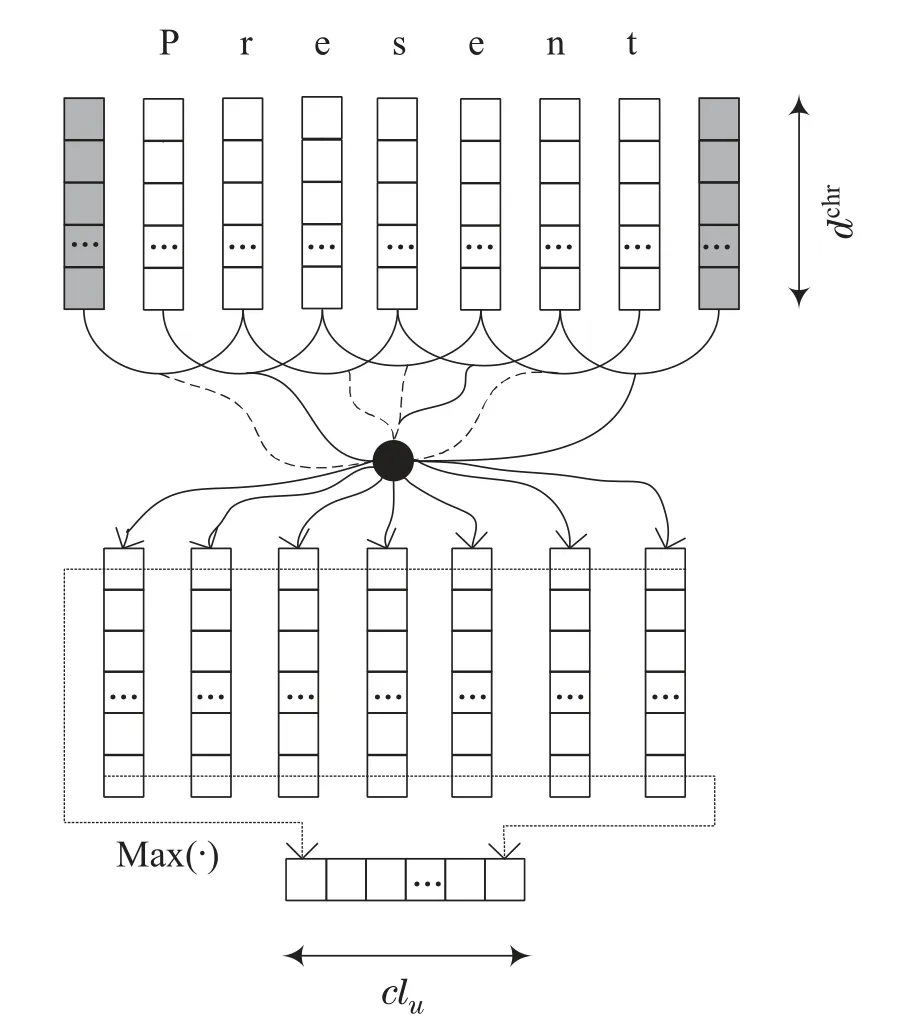
图2 字符级特征提取的卷积方法Fig.2 Convolution method for CharWNN


用卷积层计算单词wn的字符级嵌入表示rchr的第j个元素,即
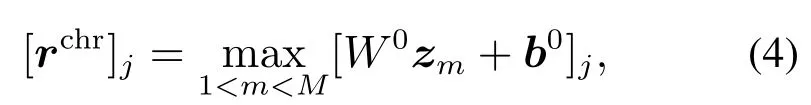
其中W0∈是卷积层的权重矩阵.用相同的矩阵提取给定单词的每个字符的局部特征,为单词提取固定大小的“全局”特征向量,其维数为该单词所有字符窗口中的最大值作为该向量的维数.矩阵Wchr和W0以及向量dchr是要学习的参数.字符向量的维数b0,卷积层单元的个数clu(即单词的字符级嵌入表示的维数)和字符上下文窗口大小kchr是由用户选择的超参数.之后再进行评分、结构化推理以及网络训练.
Dos Santos等人[16]的实验结果显示该方法在英语和葡萄牙语语料库中的词性标注上有明显改善.字符级表示的词性标注的主要创新之处有:1)提出了利用卷积神经网络提取字符级特征,并将其与单词级特征联合,用于词性标注的思想;2)证明使用相同的模型训练不同语言的POS标签是可行的,可自动学习特征,无需人工干预.这种策略也可应用到其它自然语言处理任务中.
2.1.2 CharNLM
Kim等人[17]提出了字符感知神经语言模型(character-aware neural language models,CharNLM),是 一个将只依赖于字符级的向量表示作为模型的输入,预测输出仍为单词级的神经语言模型,该模型包含卷积神经网络(convolutional neural network,CNN)[18]、高速公路网(highway network)[19]、长短时记忆(long short-term memory,LSTM)[20]和循环神经网络语言模型(recurrent neural network language model,RNNLM)[21].采用卷积神经网络(CNN)和高速公路网对输入的字符进行优化处理,处理后输出到长短时记忆(LSTM)递归神经网络语言模型(RNN-LM)中.
1) 字符级卷积神经网络CharCNN.


2) 高速公路网.
CharCNN的输出yw作为高速公路网[7]的输入,利用Srivastava等人[22]提出的方法,在多层感知器(multilayer perceptron,MLP)中的一层使用仿射变换,再利用非线性激活函数构造一组新的特征,即
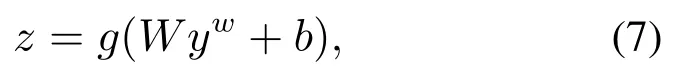
用高速公路网的其中一层实现以下变换:

其中:g是非线性激活函数,tσ(WTyw+bT)为变换门,(1-t)是移位门,构造的yw,z维数要一样,WH和WT是方阵,σ是作用在预激活函数的分量上的Sigmoid函数,⊙是向量的分量上的乘积运算.模型示意图见图3.

图3 字符识别的神经语言模型Fig.3 CharCNN
Kim等人[17]的实验结果表明,该模型在减少了很多参数的情况下,困惑度PPL(perplexity)性能仍优于之前大多数NLMs,这也证明了该模型能够仅从字符编码,得到丰富的语义和拼写特征(orthographic features),使用CharCNN和高速公路网络层进行表示学习仍然是未来研究单词嵌入表示的一个方向.
2.1.3 C2W
Ling等人[23]提出了基于双向长短时记忆网络LSTM(Bi-LSTMs)[24]的字符到单词的组合模型(character to word,C2W),Ling等人假设单词拼写间具有相似性,则其语义、句法功能也具有相似性,每个字符类型与向量表示相关联,利用长短时记忆(LSTM)非线性地学习序列的隐表示.这个模型学习的向量模型维数低,仅使用了双向LSTM来读取构成每个单词的字符序列,并将它们组合成单词的向量表示.
C2W能够学习序列模型中复杂的非局部依赖关系,图4是一个示例,C2W模型的输入(见下部分图)是一个单词w,希望获得用于表示单词w的d维向量.该模型共享同一个单词查找表的输入和输出(见上半部分图),定义字符表Cchr.对于英语,字符表包含每个字母的大写和小写,以及数字和标点符号.
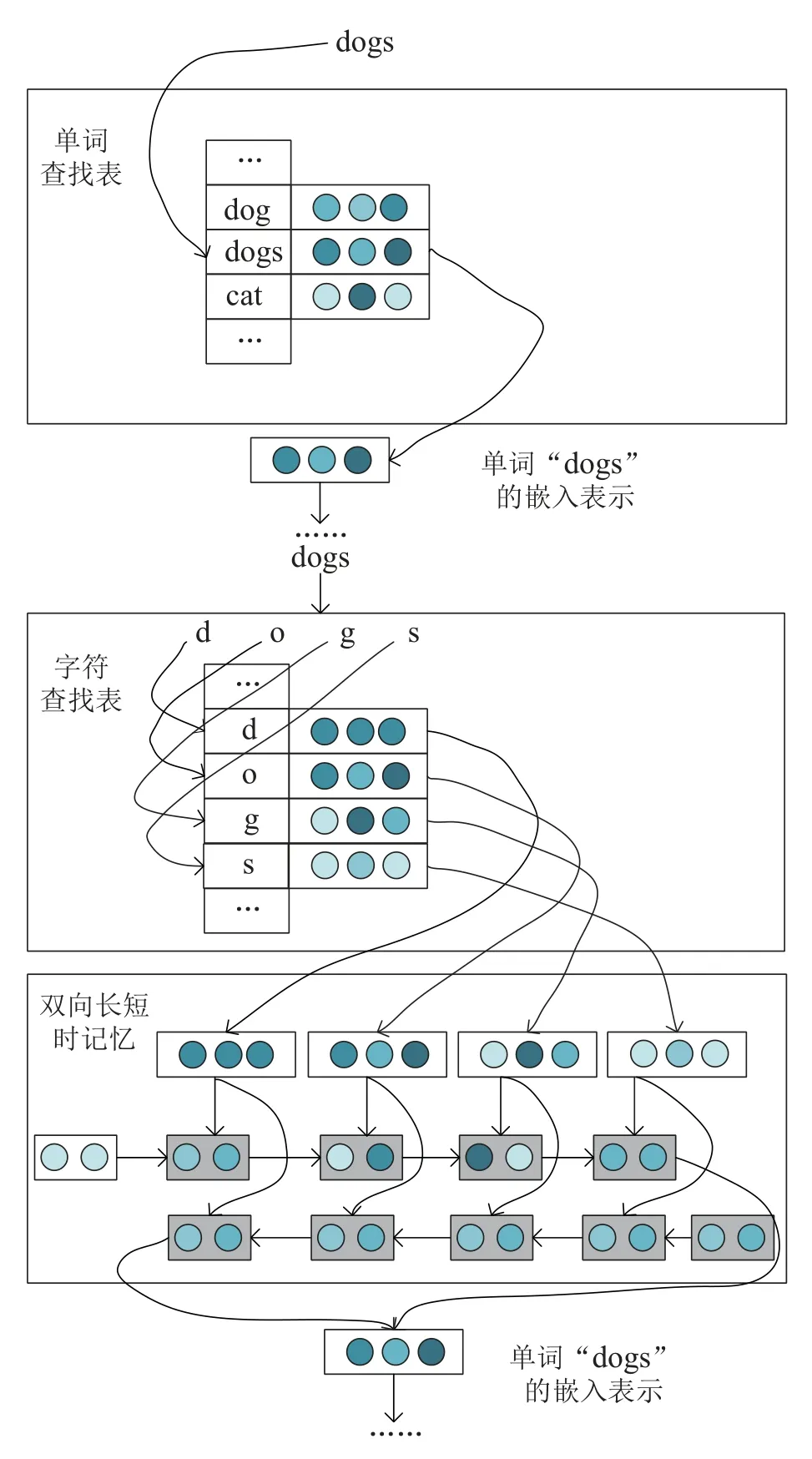
图4 字符到单词的组合模型Fig.4 C2W
该输入单词w被分解为字符序列{c1,c2,···,cl},其中l是输入单词w的长度.将每个ci定义为一个独热表示,表示字符ci出现在词汇表W位置为1,其余为0.定义投影层PC ∈其中dc是字符表Cchr中每个字符的隐表示的参数个数.则每个输入字符ci的投影可以写为

给定单词输入向量{x1,x2,···,xl},用LSTM计算状态序列{h1,h2,···,hl+1},即
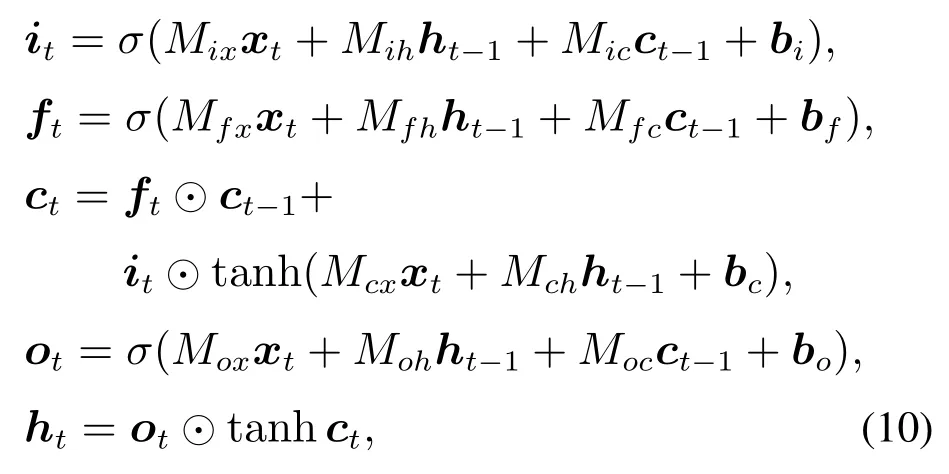
这里σ是作用在预激活函数分量上的Sigmoid函数,⊙是向量分量的乘积运算.LSTM定义一个额外的记忆存储器单元ct.从ct-1传播到ct的信息由it,ft,ot三个门控制,决定了包含输入xt哪些内容,包含从ct-1中要遗忘的内容,以及与当前状态ht有关的内容.用M表示LSTM中的全部参数(Mix,Mfx,bf···).给定一个字符表示序列作为输入序列,正向LSTM接收正向序列,产生状态序列的同时,反向LSTM接收反向序列,产生状态序列···,},两个LSTM使用一组不同的参数Mf和Mb.单词w的表示是通过组合前向和后向的状态获得的

这里Df,Db,bd是决定状态如何组合的参数.
Ling等人[23]的实验表明:C2W模型将字符作为基本单元来生成单词的嵌入向量表示,它可感知单词内的字符变化,在POS标记方面,使用单独字符的模型仍然可以获得与较先进系统相当或更好的结果,且无需人为进行特征选择.
2.1.4 小结与纵向分析
本节将输入为字符级的单词嵌入表示模型总结在一起,上述各模型的优缺点、评价方法、数据集和应用领域的总结如表1所示.
在NLP中,字符级单词嵌入表示对于改进表示学习的泛化能力非常重要,最重要的是向量空间模型,能够捕获语义和句法功能在几何特性方面的局部相似性.字符级嵌入表示是在NLM或LSTM模型基础上进行改进的,以组成单词的字符作为模型的输入,减少了模型的参数,同时在处理形态丰富的语言时,能够更好地利用单词内信息,能够更好地完成词性标注等自然语言处理任务.
这种利用字符级嵌入表示提高模型效率的方法还有很多,比如,Chen等人[25]提出的字符增强的单词嵌入模型(character-enhanced word embedding model,CWE),CWE为汉字歧义提供了一种有效的解决方案,同时也可将CWE扩展到英语等语言中.
2.2 单词级单词嵌入表示模型
2.2.1 Word2Vec模型
Mikolov等人在NLM,RNN-LM等模型的基础上,于2013年在文献[14]中提出了Word2Vec模型,包括Skip-Gram和CBOW两个模型,旨在得到更好的单词嵌入表示向量,使它们与之前的NLM模型相比,减少非线性隐层,大大降低模型的计算复杂度.
1) Skip-Gram模型.
Skip-Gram模型结构如图5右图所示,该模型旨在利用中心单词预测上下文单词.给定一个要训练的单词序列w1,w2,···,wT,Skip-Gram模型的目标是使以下平均对数概率最大化:
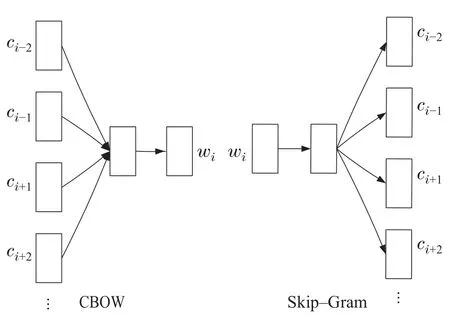
图5 CBOW和Skip-Gram模型结构Fig.5 CBOW&Skip-Gram

其中c是训练上下文的大小.

基本Skip-Gram模型中,假设中心单词是wI,它的一个相邻单词是wO,使用软最大函数定义P(wO|wI):其中:W表示词汇表,uw ∈Rd和vw ∈Rd表示单词w的d维输出、输入嵌入向量表示,所有单词的输入输出向量都是要学习的参数,即U{uw|w ∈W},V{vw|w ∈W},Skip-Gram模型是3层神经网络,其中U和V表示神经网络的两个连接边参数矩阵.
2) CBOW模型.
CBOW的模型结构如图5左图所示,其目标是在滑动窗口中给定上下文单词,预测目标单词.形式上,给定一个单词序列Dw{w1,···,wM},M为单词序列长度,CBOW的目标是使以下平均对数条件后验概率最大化:

这里K是目标单词的上下文窗口的大小.CBOW用软最大函数表示条件后验概率P(wi|c),c为目标查询单词wi前后各K个单词组成的上下文单词序列,即

其中:W是字典中所有单词集合,wi是目标单词的向量表示,wo是所有上下文单词向量的平均值:

2.2.2 Glove模型
CBOW模型和Skip-Gram模型是单词嵌入表示发展中的一个里程碑.后续有大量试图学习更好的单词嵌入表示的研究成果,比如,全局向量(global vector,Glove)[27].
为了充分利用语料库中的单词共现统计信息,Glove模型直接获取这些全局信息.用X表示单词共现计数矩阵,用Xij表示wj在wi上下文中出现的次数,则损失函数定义如下:

其中:|V|为词汇量的大小,g(x)为权重函数,用于缓解罕见词和常见词间的数据不平衡问题,矩阵C ∈R|V|×d作为映射,其中每一行表示单词w在词汇表V中的分布向量表示,记为C(w).但是这个模型仍然没有解决单词的一词多义的问题.
2.2.3 多原型单词嵌入表示学习的概率模型
Tian等人[28]提出了一种对一个多义词学习多个嵌入向量表示的有效方法,他们首先从概率的角度对单词的多义性进行建模,并将其与连续Skip-Gram模型相结合,称为多原型Skip-Gram模型(multi-prototype skip-gram model,MPSGM),类似于Skip-Gram模型[14],用条件后验概率P(wO|wI)表示多个原型的Skip-Gram模型,并使用输入输出矩阵对条件后验概率P(wO|wI)进行参数化,不同之处在于,给定输入单词wI,输出单词wO的条件后验概率为一个有限混合模型,其中每个混合分量对应于输入单词wI的原型.即,假设单词w具有Nw个原型,hw ∈{1,···,Nw}是单词w原型的索引.条件后验概率P(wO|wI)可展开为


其中:ζ(x)1/(1+exp(-x)),特指从二叉树根到叶子节点wO的第t个节点相关的d维参数向量.用式(20)代入式(18),得到更实用的概率形式,可以避免式(19)中复杂的软最大操作.之后再用EM算法训练这个多原型的Skip-Gram模型.MPSGM弥补了原有Word2Vec模型的不足,考虑了单词的多义性,同时与以前的基于聚类的多原型算法相比,该模型提出的概率框架除了能学习单词嵌入表示外,还避免了额外的聚类工作,算法复杂性大大降低.
MPSGM弥补了原有Word2Vec模型的不足,考虑了单词的多义性,同时与以前的基于聚类的多原型算法相比,该模型提出的概率框架除了能学习单词嵌入表示外,还避免了额外的聚类工作,算法复杂性大大降低.
2.2.4 基于神经张量Skip-Gram模型的主题词嵌入学习
Liu等人[31]提出了神经张量Skip-Gram模型(neural tensor skip-gram model,NTSG),该模型是Skip-Gram模型的扩展,可以同时对单词和主题之间的交互作用关系进行建模,在单词相似性和文本分类任务的实验中表现良好.为了提高单词嵌入表示学习的表示能力,引入了单词的潜在主题,并假设每个单词在不同的主题下具有不同的嵌入表示.具体实现过程如下.
NTSG用张量层替换了双线性层,对Skip-Gram模型进行扩展,以捕捉不同语境下单词与话题之间的相互作用关系.为了计算单词w和它的主题t在特定上下文c中的相似度,使用以下基于能量的函数:

其中(z)的每一项是由张量的每一个切片i1,···,k得到的

图6展示了NTSG模型结构.它的主要优点是能够同时考虑词语、话题和语境之间的潜在关系,即,引入的张量可以表示单词和主题之间的相互作用关系.

图6 NTSG模型说明图Fig.6 NTSG
为了避免过拟合,进行张量分解,将每个张量切片分解为两个低秩矩阵的乘积.每个张量切片M[i]∈Rd×d被分解成两个低秩矩阵P[i]∈Rd×r和Q[i]∈Rd×r,记为

其中r ≪d是因子个数.基于能量的函数变为

此时张量运算的复杂度是O(rdk).只要r足够小,分解后的张量运算就会比未分解的张量运算快得多,自由参数的数目也会小得多,这就防止了模型的过拟合.Liu 等人[31]的实验表明,NTSG 比单一的Skip-Gram模型在性能上提升很多,很好地将单词与在不同上下文主题中的嵌入表示结合起来,从而获得每个单词类型的上下文主题词嵌入表示,使用张量分解的方法也提高了模型的效率,在上下文相似度和文本分类两个任务中优于先前的多原型模型.
2.2.5 小结与纵向分析
与至少使用4个隐层(包括查找表层)的传统神经网络相比,Word2Vec模型大大减少了参数的数量,在训练效率方面带来了显著的改进,Glove模型也在NLP领域取得了巨大成功,但是因为在这些模型中,每个词都是用一个不随上下文变化的原型向量来表示的,所以多义词问题没有得到解决.在这种情况下,对于一个多义词来说,在给定上下文的情况下无法区分其确切的含义.何为多义词呢?多义词在表示学习中又是怎样体现的呢?比如,当单词bank指的是“河岸”时,观测到上下文单词可能是river,water 和slope等;然而,当bank指的是“银行”时,观测到的上下文单词有可能是money,account和investment等.
一些学者也试图通过聚类词的上下文窗口特征表示来训练单词的多个原型的嵌入表示,但训练参数庞大,数据集大时,算法的可扩展性有限,学习效率也不高,如文献[32]指出的那样.随后多原型Skip-Gram模型引入概率框架,摒弃了聚类思想,提高了模型的效率.而NTSG的目标就是判断出一个单词w和它的主题t在上下文c中能否很好的匹配.例如,(w,t)(apple,company)能在上下文ciphone下很好的匹配(w,t)(apple,fruit)能在上下文cbanana下很好的匹配.单词级单词嵌入表示的模型的介绍与总结如表2.
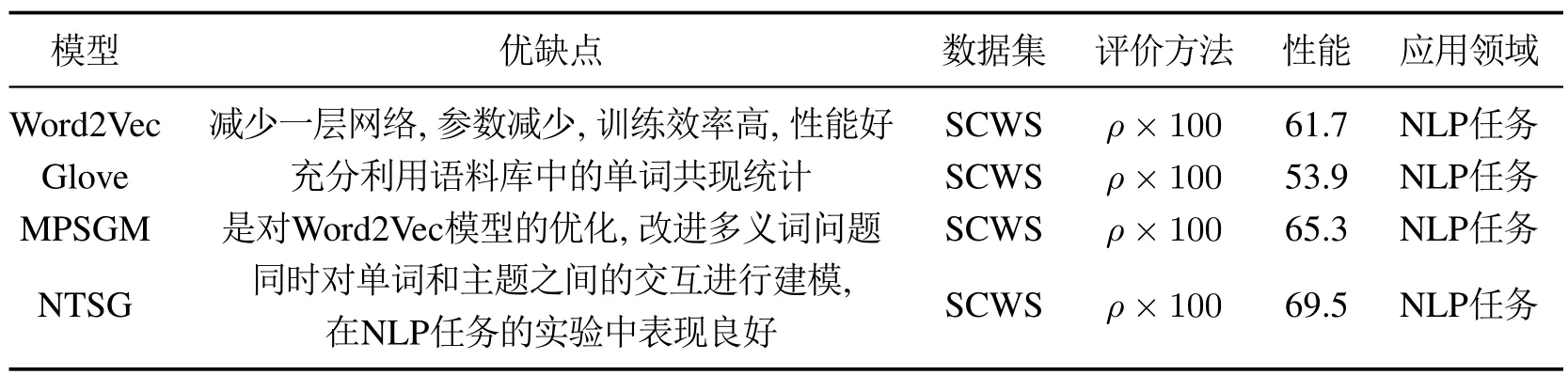
表2 单词级单词嵌入表示模型总结Table 2 Summary of word-level word embedding model
2.3 短语级及短语以上级的单词嵌入表示模型
2.3.1 基于句法依赖关系的单词嵌入表示
Skip-Gram模型具有很多优点,但是在Skip-Gram算法中,上下文词汇表C与词汇表W是相同的,在此基础上,Levy等人[33]提出的基于句法依赖关系的单词嵌入表示方法(dependency-based word embeddings,Deps),将线性BOW模型上下文单词转换为任意词语的上下文单词,使得上下文单词不只使用所学习的单词前后出现的单词,上下文类型的数量可以远远超过所要学习单词前后出现的单词的个数.
该基于句法依赖关系的模型利用单词袋子模型根据单词的句法关系得出语境相关的句子解析[16,24],对句子解析之后,得到单词的语境上下文单词.对于一个目标单词w,它修饰的单词记为m1,···,mk,修饰它的单词,记为头部h,则目标单词的上下文记为:(m1,lbl1),···,(mk,lblk),lbl表示目标单词与被修饰词的之间的句法依赖关系类型,如,nsubj,dobj,prep with,amod,lbl-1是lbl的倒数,表示修饰目标单词的修饰语与目标单词的依赖关系,即反向依赖关系.在这里,介词在提取上下文时就直接被包含在修饰词与被修饰词的依赖关系中.图7给出了考虑句法依赖关系后,上下文提取的一个例子.

图7 基于句法依赖关系的上下文提取示例Fig.7 Dependency-based context extraction example
基于句法依赖关系的模型比BOW模型包含更大范围的词语之间的依赖关系,并且还能过滤掉窗口内与目标词没有直接关系的单词.该模型能够利用句法上下文依赖关系产生更丰富语义信息,更全面的单词嵌入表示,捕获更多语义功能相似性,学习的语言模型包含更少的主题相似性.
2.3.2 段落向量模型PV-DM&PV-DBOW
Le,Mikolov等人在文献[34]中,提出了一种无监督的段落向量表示学习算法,它可以从句子、段落等长度可变的文本片段中学习固定长度的特征表示,该算法是用一个实数向量表示每个文档,经过训练的段落向量可以预测文档中的单词,这个算法可以克服BOW模型丢失单词的顺序和忽略单词的语义这两个缺点.初始模型为分布式记忆段落向量模型(distributed memory model of paragraph vectors,PV-DM),是将段落向量作为另一个向量插入到标准语言模型中,旨在捕获文档的主题,在这个模型中,单词列向量组成的矩阵W在各个段落中是共享的,利用随机梯度下降方法训练段落向量和单词向量,并通过反向传播得到梯度.在随机梯度下降计算的每一步中,都可以从随机段落中抽取一个固定长度的上下文样本,计算网络误差梯度,并用这个梯度来更新模型中的参数.
在预测时,通过梯度下降过程学习计算新段落的段落向量.在此时,剩余模型的参数,神经网络连接边矩阵W和软最大权重是固定的,为之前训练过程学习得到的值,虽然模型参数的个数可能很大,但是训练期间的更新通常是稀疏的,因此模型训练效率很高.
经过训练后,段落向量可以用作新输入文本的段落特征向量,将这些特征直接作为传统机器学习算法的输入,如逻辑斯蒂回归、支持向量机或K-均值聚类(K-means)算法,即让段落向量与局部上下文单词向量相关联,或用K-均值聚类方法,预测下一个单词.如图8所示.

图8 分布式存储段落向量模型Fig.8 A framework for learning paragraph vector
在预测任务中如果不使用局部上下文信息时,可以进一步简化段落向量,即分布式单词袋子版的段落向量模型(distributed bag of words version of paragraph vector,PV-DBOW),如图9所示.

图9 分布式无序袋子段落模型Fig.9 Distributed bag-of-words version of paragraph vectors
这个模型具有概念简单、参数少的优点,只需要存储软最大权值,比之前的模型中减少了单词向量的存储空间,利用反向传播对段落向量进行调优.
2.3.3 小结与纵向分析
Deps模型充分利用句法依赖关系,使单词嵌入表示更加全面.段落向量将单句扩展到多句子,采用无监督的框架,可以减少数据标记的工作.PV-DM和PV-DBOW算法用实数向量表示每个文档,该向量被训练用来预测文档中的单词,假定文章由段落组成,每一个段落又由向量表示,使得整个文章的各段落列向量组成矩阵D,段落中的单词列向量组成矩阵W,文章中的多个段落向量的平均或者叠加增广向量,以及段落中的多个单词向量的平均或者叠加增广向量,可以用来预测下一个上下文中的单词的向量表示,亦可作为后续分类或聚类算法的输入.这个方法可以在一定程度上克服了BOW模型的缺点,并且在实验中,段落向量在文本表示方面优于BOW模型和其它单词模型.像这种短语级及以上的单词嵌入表示还有很多,比如,短语嵌入的合成模型学习[35],在这里只是列举了两个,对比如表3.

表3 短语级及以上的嵌入表示模型总结Table 3 Summary of embedding models at phrase level and above
3 按上下文关系分类
3.1 上下文无关的单词嵌入表示模型
第2.1节和第2.2节中介绍的模型很多都没有引入上下文信息,如,Word2Vec,Glove,CharWNN等模型产生的单词嵌入表示都未考虑上下文信息,虽然它们在单词嵌入表示学习中都是里程碑的存在,解决了单词表示的语义相似性的问题,但是没能很好地解决多义词问题,这种单词表示学习模型,本文称为与上下文无关的单词嵌入表示模型.
3.2 考虑上下文信息的单词嵌入表示模型
一种有效解决多义词问题的方法是考虑上下文信息的嵌入表示,即表示随着上下文的变化而变化.下面本文介绍几个典型的上下文有关的单词嵌入表示模型.
3.2.1 CoVe
McCann 等人[36]提出了上下文向量(context vector,CoVe)模型,使用深度LSTM编码器为机器翻译任务训练一个序列到序列的模型,用于产生考虑上下文信息的单词嵌入表示,并应用到NLP任务中.CoVe模型的公式表示为
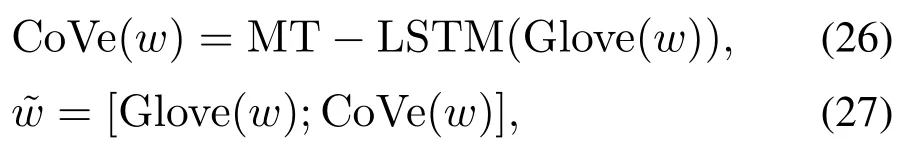
其中Glove(w)是单词w的Glove向量.
如图10和式(26)-(27)所示,该模型直接采用MTLSTM模型的两层单向LSTM编码器对预先训练的Glove嵌入表示进行编码,并将输出作为上下文向量与Glove向量拼接形成增广向量,并作为下游自然语言处理任务的输入.CoVe改进了许多自然语言处理任务的性能,包括情感分析、问题分类、问题回答等.更重要的是,它考虑了单词的上下文信息.

图10 CoVe模型示意图Fig.10 CoVe
3.2.2 ELMo
Peters等人[37]提出的语言模型的嵌入表示(embeddings from language model,ELMo)学习方法,是一个考虑上下文信息的单词嵌入表示深度模型,其单词嵌入表示是从深度双向语言模型(bidirectional language models,biLM)[20]的隐层提取的,需要在大规模未标记语料库中预先训练得到.介绍如下.
给定长度为N的单词序列(m1,m2,···,mN),其中历史序列为(m1,···,mk-1),biLM的前向语言模型计算目标单词mk的条件概率;给定未来上下文序列mk+1,mk+2,···,mN,biLM的后向语言模型计算目标单词mk的条件概率.biLM联合最大化前向和后向语言模型的对数似然函数
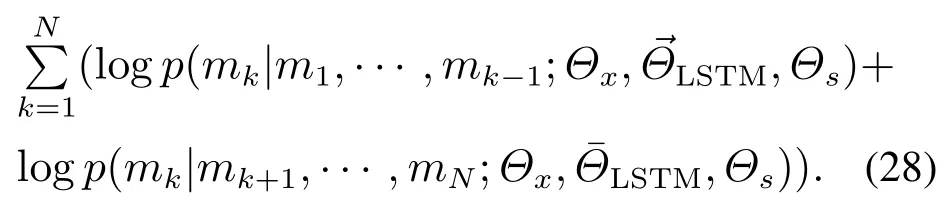
从图11所示的体系结构中可以清楚地看出,biLM首先用charCNN构造基于字符级的单词嵌入表示,biLM进一步应用两层双向LSTM来学习单词的隐表示,该隐表示考虑了单词的上下文信息,然后利用学习的隐表示,使用软最大层计算前向和后向语言模型的条件概率.
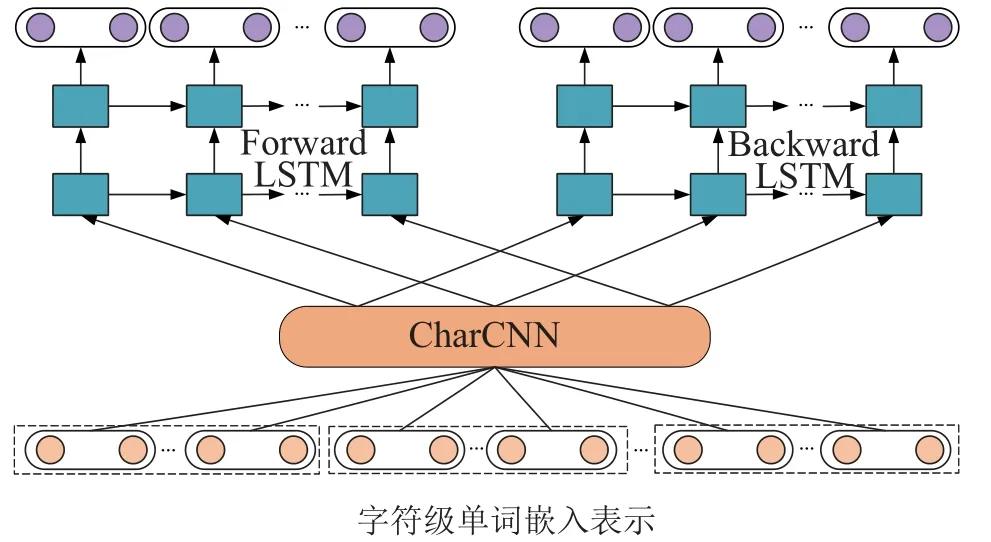
图11 ELMo的网络结构Fig.11 ELMo
ELMo是biLM层的线性组合.假设biLM具有L层LSTM,那么ELMo神经网络为目标单词mk产生2L+1个表示,即

其中stask是软最大归一化的权重,标量参数γtask可以控制任务模型缩放整个ELMo向量.
ELMo利用的是几乎无限的无标记文本数据来学习单词的动态表示,并显著提高了自然语言处理问题的预测性能.
3.2.3 BERT
Devlin等人[38]引入了带有变送器(transformer)的双向编码器表示(bidirectional encoder representations from transformers,BERT)语言模型.BERT框架分为两步:预训练和微调.在预训练期间,通过不同的预训练任务对未标记的数据进行模型训练.为了进行微调,首先使用预训练的参数初始化BERT模型,然后使用来自下游任务的标记数据对所有参数进行微调,每个下游任务都有单独的微调模型(如图12所示).
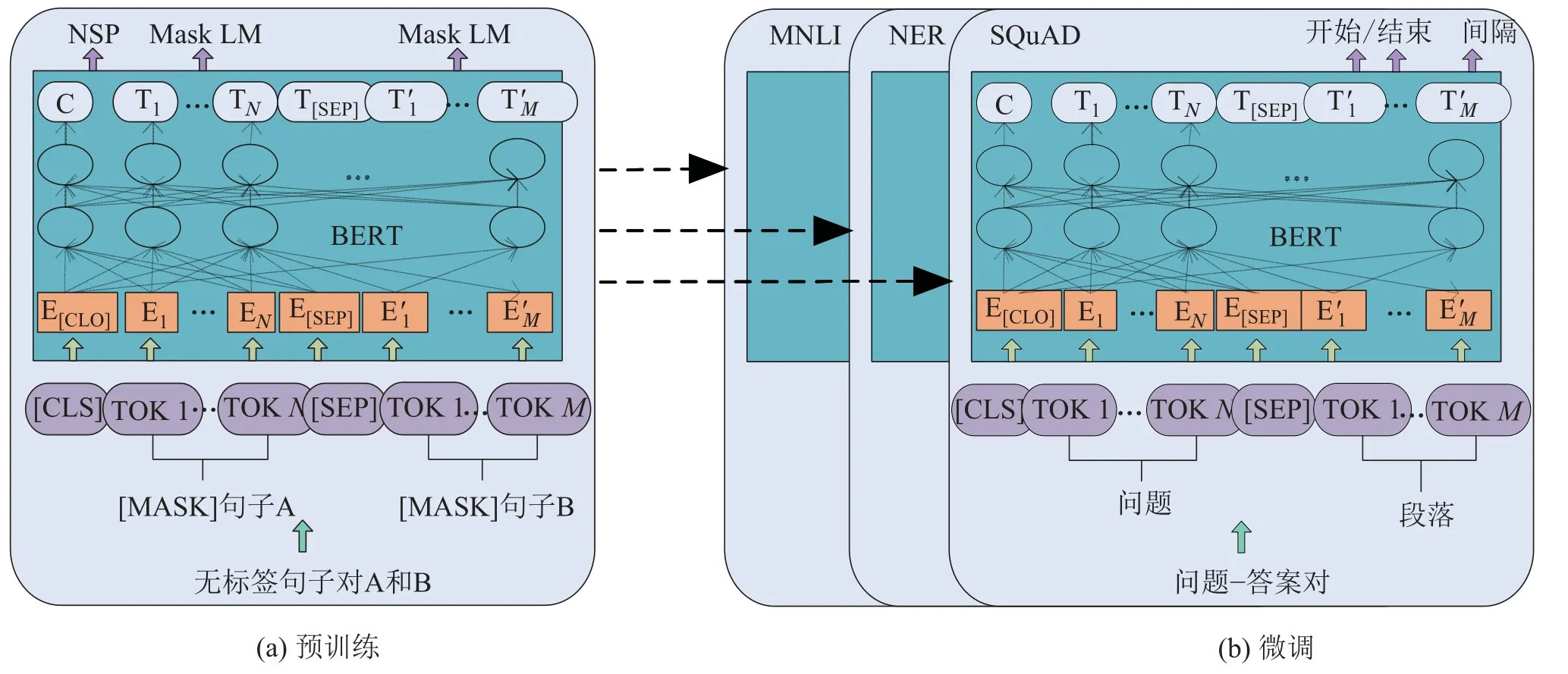
图12 BERT的总体预训练和微调过程Fig.12 Overall pre-training and fine-tuning procedures for BERT
BERT是使用多层双向变送器的编码器,而变送器使用双向自注意力机制.BERT的输入表示如图13所示(每个序列的第1个标记总是一个特殊的分类标记[CLS],用[SEP]分隔两个句子).

图13 BERT输入表示Fig.13 BERT input representation
BERT的两步介绍如下:
1) 预训练的BERT.
与Chelba等人提出的方法不同[39],Devlin等人没有使用传统的从左到右或从右到左的语言模型来预训练BERT,而是使用两个无监督任务对BERT进行预训练:掩码语言模型学习(masked LM)和下一个句子预测任务(next sentence prediction,NSP).如图12的左侧部分.
a) 掩码语言模型学习.
为了训练深度的双向嵌入表示,Devlin等人简单地随机遮蔽一定百分比的标记,称为“有掩码的语言模型”(masked LM,MLM),亦称为“完形填空任务”(cloze task).然后,使用特征嵌入表示的隐表示代入交叉熵损失,求解使得交叉熵损失最小的原始特征标记的预测值.
b) 下一个句子预测任务.
NSP任务的目标是预测句子之间的关系,如预测句子b是否真的在句子a之后,该任务的训练数据可以轻松地从任何单语语料库中得到.将NSP与MLM联合优化便能在机器问答(question answering,QA)和自然语言推理(natural language inference,NLI)等下游任务中取得很好的预测性能.c) 预训练数据.
BERT的预训练过程和通用的预训练过程一样.
2) 微调BERT.
BERT使用自注意力机制来统一输入和输出这两个阶段,对于每个任务,只需将特定于任务的输入和输出代入BERT,并端对端微调所有参数.经过预训练的两个句子作为BERT微调网络的输入是,在BERT预训练网络的输出处,将学习得到特征表示,输入到输出微调层中,如,在序列标记或机器问题回答任务中,将[CLS]表示输入到微调输出层中,执行特定的任务.
实验表明,BERT在11种自然语言处理任务上获得了很好的结果,Devlin等人主要贡献是将发现进一步推广到深层次的双向体系结构,从而使相同的经过预训练的模型能够成功解决各种NLP任务.
3.2.4 VIB
信息瓶颈(information bottleneck,IB)方法起源于信息论,令X表示所要学习映射关系的“输入”变量,例如句子,而Y表示所要学习映射关系的“输出”变量,例如语法分析.假设联合分布P(X,Y)已知,IB目标是在X已知情况下,学习某个压缩表示T的条件后验概率pθ(t|x)最大的参数θ和T,类似于学习统计学中充分统计量.定义目标函数(31),IB的目标就是学习使得式(31)最小化的压缩表示T
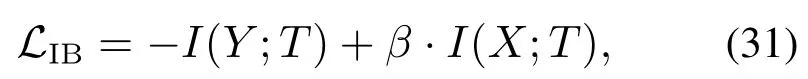
其中:I(·;·)是互信息.优化目标函数(31),即令T保留尽量少的与x有关的信息(第2项),但这些信息足以预测Y.两项之间的平衡关系由权衡参数β控制.通过增加β就可以使I(X;T)尽可能小,“压缩瓶颈”可以理解成通过压缩预测精度I(Y;T)换取更大程度的压缩隐表示.IB的目标是通过对T携带的有关X的信息施加一些约束来最大化T的预测能力[40].
像前面提到的ELMo和BERT模型,IB可以作为预训练的手段,以便得到单词的嵌入表示,该表示包含了丰富的语法和语义信息.Li等人[41]提出了一种快速的变分信息瓶颈方法(variational information bottleneck,VIB),对这些嵌入表示的信息进行非线性压缩,只保留有用的信息.VIB不是单纯地降维,它有效地避免了对压缩表示中的可用维数的不必要使用,利用随机性去除了不需要的部分信息.下面对这个模型进行介绍.
Li等人扩展了原来的IB目标(31),添加了

项,起到控制所提取的标签的上下文敏感性的作用.这里Ti表示与第i个单词相关联的标签,Xi是第i个单词的ELMo特征嵌入表示,而是同一单词的ELMo类型嵌入表示.扩展后的目标函数表示为

如图14所示,在依赖解析任务上应用VIB估计方法,将句子的单词嵌入表示Xi压缩为连续的向量值标签或离散标签Ti(“编码”),以使标签序列T保留预测依赖解析Y(“解码”)的最大信息.VIB使用相同的随机映射函数和信息损失变换结构,独立地压缩每个

图14 信息瓶颈示例Fig.14 VIB
IB方法通过定义条件分布pθ(t|x)引入了新的随机变量T,即X的压缩标签序列.选择pθ的参数θ使IB目标(32)最小.
Li等人巧妙地利用变换和重参数化技巧,提出了两种使用变分信息瓶颈的方法来压缩ELMo单词特征嵌入表示.可以将相同的训练方法压缩ELMo或BERT特征序列,执行其它学习任务,所需要的只是一个特定于模型的解码器.例如,在情感分析的情况下,该方法应仅保留情感信息,不需要保留无用的语法知识.序列为离散值时,自动压缩标签,形成一个侯选标签集,实验证明,这些标签可以捕获传统POS标签注释中的大多数信息,可以在相同标签粒度级别上更准确地解析出标签序列;序列为连续值时,实验证明,VIB方法适度地压缩单词嵌入表示,在9种语言中的8种中产生更准确的依赖解析,如表4所示.
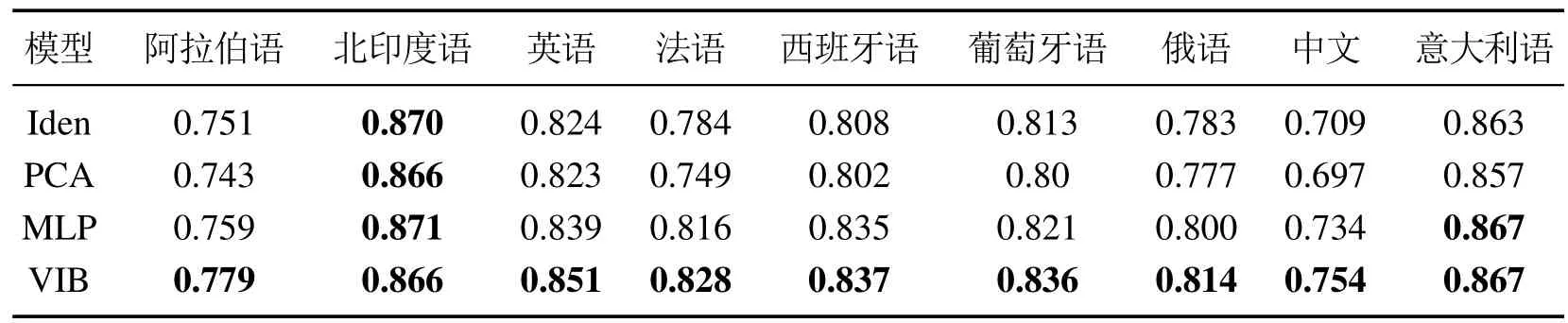
表4 解析9种语言的准确性Table 4 Parse the accuracy of nine languages
3.2.5 小结与纵向分析
上述的模型总结如表5-6所示.上文提到的下游任务包括:语言建模(language modeling,LM)[7,13]、分块(chunking)[7-8]、词性标注(part-of-speech tagging)[8]、命名实体识别(named entity recognition,NER)[8,27]、情感分析(sentiment analysis,SA)[42-43]、语义角色标注(semantic role labeling,SRL)[8]、依赖句法分析(ependency parsing)[3]、机器翻译(machine translation,MT)[44]、自然语言推理(nature language inference,NLI)[45-46]和机器阅读理解(machine reading comprehension,MRC)[47-48].本章介绍的模型都是近几年经典的模型,它们巧妙地应用了预训练等技术.

表5 解析9种语言的准确性Table 5 Parse the accuracy of nine languages

表6 加入预训练的单词嵌入表示Table 6 Add pre-trained word embedding
CoVe推进了NLP模型的发展,但是CoVe的一个不足是它依赖于有限标记的语言数据.此后的ELMo模型针对这一问题有所改进,利用的是几乎无限大的未标记数据,这不仅减轻了未登录词(OOV)问题,而且有效地减少了模型参数的个数.但是上述模型都仅限于单向训练,只利用训练目标左侧或者右侧的语境信息.BERT具有更强的双向捕获信息的能力,在很多个NLP任务上都取得了巨大的进步,也吸引了后续很多科研工作者,试图以不同的方式改进它.研究最多的问题是如何引入不同的预训练目标.BERT-wwm[49]和ERNIE(百度)[50]为了提高模型的泛化能力,预测被遮盖的整个词/实体,而不是词块.SpanBert[51]通过将多个单词“遮盖”为一个“区块”并预测一个“区块”内的整个内容,改进“区块”预测结果.ELECTRA[52]没有预测被“遮盖”的嵌入表示,而是用替换的嵌入表示检测任务预处理模型.Albert[53]用一个新颖的句子顺序预测任务取代了预测下一个句子的任务.这些更难的预训练任务更好地发掘了变送器(transformer)模型的潜力.
4 跨语言单词嵌入表示模型
世界上大约有几千种不同的语言,但只有少数语言有人为注释,而这些语言之间的对应关系在单词表示学习任务中并没有很好的得到应用,上文中提到的单词表示模型都是单语言模型,这就需要单词嵌入表示的跨语言迁移学习,在资源丰富的语言上训练的模型被应用到低资源语言中,帮助低资源语言单词的表示学习,单个语言的输入嵌入表示被投影到多个语言共享的语义空间中.这种嵌入表示学习方法被称为跨语言单词嵌入表示[54].根据使用的单语嵌入表示类型,跨语言嵌入表示学习方法可以分为静态表示学习和动态表示学习两种;根据训练目标的不同,可以分为在线表示学习和离线表示学习两种方式[55-56].而为什么又需要在平行语料上学习呢[57]? 因为一种语言中的多义词在另一种语言中可能有多个不同翻译,这样有利于解决前文中提到的一词多义的问题.
在本节中,笔者从众多跨语言模型中选择了以下两个有代表性的跨语言模型进行介绍.
4.1 BilBOWA
Guo等人[57]提出的无需词对齐的双语单词袋子(bilingual bag-of-words without word alignments,Bil-BOWA)模型,BilBOWA单词嵌入表示是一种无需考虑单词对齐关系的快速双语分布式嵌入表示学习方法,模型简单且计算高效,适用于大型单语数据集,直接对单语数据进行训练,并从一组较小的原始文本句子对齐数据中提取双语信息.
该模型的示意图如图15所示.

图15 BilBOWA模型体系结构示意图Fig.15 BilBOWA
BilBOWA模型的损失函数分为两个部分,目标是使总的联合损失函数最小:

其中:h是上下文,wt是目标单词,D是数据集,e和f表示两种语言,此处以英语和法语为例.
1) 学习单语言的特征:单语言隐表示的目标函数
BilBOWA采用负采样Skip-Gram模型,用于学习得到高质量的单语言隐表示,同时使损失最小.
2) 学习跨语言的特征:无需单词对齐的双语单词袋子模型的损失函数Ω.
一般的,在双语环境中,单词相似性可以表示为矩阵A,其中aij编码一种语言中单词i的翻译到另一种语言中单词j的得分.将K维单词嵌入表示作为行向量ri堆叠起来以形成(W,K)维矩阵R,则跨语言对齐部分的目标函数可以表示为

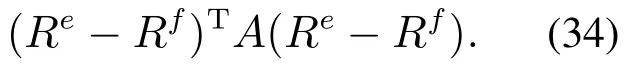
矩阵A捕获了英语字典We中所有的单词与法语字典Wf中所有的单词之间的关系,也是该模型学习的难点.但是词对齐的训练计算成本高、噪音大,所以利用平行训练数据获得局部单词共现统计近似式(34)中利用全局单词对齐统计得到的Ω(·)项,得到式(35),表示在第t步时,优化该近似的跨语言目标,过程如图16所示.
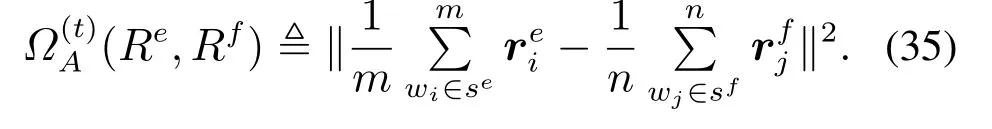

图16 全局单词对齐统计与局部单词共现统计关系图Fig.16 Diagram of global word alignment statistics and local word co-occurrence statistics
使用全局单词对齐来对齐跨语言嵌入表示式(34)过程麻烦且复杂,并且模型参数会随着两个语言词汇量的乘积而快速增长.相比之下,BilBOWA损失式(35)是通过对平行句子对的有限样本中的隐式的局部共现统计值求平均来近似全局损失函数.
综上所述,BilBOWA是一种计算效率高的模型,可直接从单语言原始文本和有限数量的平行数据中导出双语分布式单词表示形式,不需单词对齐,将训练单语单词嵌入表示的先进技术与采样式跨语言目标相结合.使得每个训练步骤所需的计算仅与句子中单词的个数成比例,从而可以进行高效的大规模跨语言训练.Gouws等人[58]的实验也证明考虑跨语言对齐关系的方法优于针对跨语言文档分类任务以及针对WMT11数据的词汇翻译任务的技术.
4.2 Trans-Gram
Coulmance等人[59]提出了Trans-Gram模型,简单且高效,可仅使用单语言数据和少量句子对齐数据,同时学习和对齐多种语言的单词嵌入表示,用这个方法计算以英语为中心语言的21种语言的对齐单词嵌入表示.
Trans-Gram是在Skip-Gram的基础上提出的,利用句子对齐关系而不是单词对齐关系构造隐表示,是一种学习跨多种语言对齐关系的单词嵌入表示学习方法,可以将单语言损失和跨语言损失的总和最小化.假设学习语言e(例如英语)和f(例如法语)的对齐的单词向量,用Skip-Gram表示单语言损失,记为Je和Jf.在平行对齐语料库Ae,f中,每个英语句子se与法语句子sf是对齐的.在Skip-Gram中,在句子se中为目标单词we选择的上下文是出现在以we为中心的固定大小的窗口中的单词的集合,记为se[we-l,we+l].在Trans-Gram中,在句子se中为目标单词we选择的上下文是句子sf中出现的全部单词cf.损失函数记为
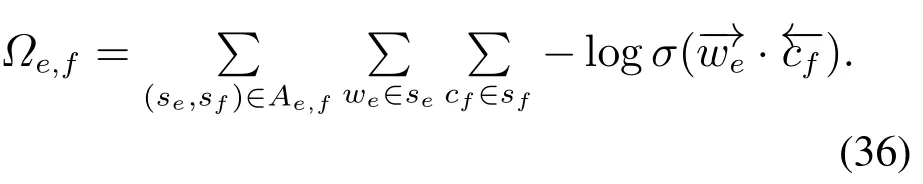
显然,这种损失相对于这两个语言是不对称的.因此,需要有两个跨语言的损失函数:Ωe,f表示语言e的目标向量和语言f的上下文向量之间对齐的损失,Ωf,e表示语言f的目标向量和语言e的上下文向量之间对齐的损失.图17表示了4种损失目标函数.
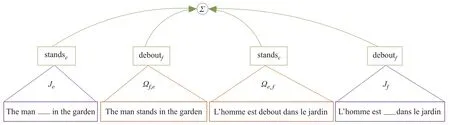
图17 有助于英语和法语对齐的4个部分目标Fig.17 The four partial objectives contributing to the alignment of English and French
假设单词的含义在整个句子中均匀分布,这个方法仅使用句子对齐的语料库,而不使用单词对齐的语料库.当要添加第3种语言i(例如意大利语)时,只需为全局损失添加3个新目标函数(Ji,Ωe,i和Ωi,e),简单高效.Upadhyay等人[56]提出的Trans-Gram在标准的跨语言文本分类和单词翻译任务上也取得了较好的结果,为跨语言任务提供了新的方法,推进了跨语言任务的发展.
4.3 小结与纵向分析
在本章中,将从众多跨语言模型中选择了上述两个跨语言模型进行介绍,在表7中,给出了这两个模型在英语/德语分类任务上的准确度,在表8中,给出了这两个模型在翻译任务中的一个表现,两个模型的优缺点总结如表9所示.
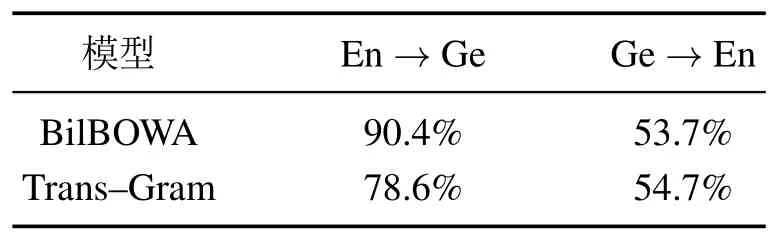
表7 模型在路透社英语/德语分类任务上的ACCTable 7 ACC of model on reuters English/German classification

表8 模型在翻译(英语-西班牙语)任务上的ACCTable 8 ACC of model on translation(English-Spanish)task

表9 跨语言单词嵌入表示模型总结Table 9 Summary of the cross-language word embedding model
对于跨语言嵌入表示,在线方法通常是学习源语言和目标语言的语言模型,并通过跨语言目标共同优化其目标.离线方法主要是学习投影矩阵(主要是线性变换矩阵),将源语言的向量空间转换为目标语言的向量空间.
在在线学习方面,Mulcaire等人[60]基于ELMo[37]模型,在多语言数据中捕获字符级的语义信息,提出了一种多语言考虑上下文信息的单词表示模型.Lample和Conneau[61]在BERT[38]基础上,改变预训练的目标,利用并行数据上的跨语言监督信息,学习跨语言语言模型,这些模型在几个跨语言任务上取得了不错的成果.他们进一步证明,大规模的预训练的多语言模型能够显著提高大量跨语言迁移任务的性能[62].在离线学习方面,Schuster等人[63]通过离线方法用线性投影对齐预训练过程,并考虑上下文信息,学习单词嵌入表示,使用考虑上下文信息嵌入表示的均值,作为每个单词的锚点,并学习锚点集合中的转换矩阵.Wang等人[64]提出在不同语境中直接学习变换关系,从而得到保留语义的跨语言动态嵌入表示.Mulcaire等人[65]评估了考虑上下文信息的跨语言嵌入表示方法,这些模型极大地促进了跨语言依赖分析的学习效果,与离线学习方法相比,在线学习方法能更好地编码词汇对应的跨语言嵌入表示.
5 引入其它模态或关联信息帮助学习单词嵌入表示
根据模态之间的对应关系,或引入句子中单词所起的语法作用,或引入句子中单词的上下文信息,或在视觉和文字模态之间,引入语义信息,都能够帮助更好地学习单词的向量表示.
5.1 联合单词-图像的嵌入表示模型
该小节介绍联合单词-图像双模态的嵌入表示学习方法.现在图像标注数据集变得越来越大,有数千万张图像和数万个标注.Weston等人[66]提出了一种高性能的方法,通过同时学习优化给定的图像和标注文字,并学习图像和文字标注的低维联合嵌入表示空间,即联合单词-图像的嵌入表示.
表示图像和文字标注的映射函数是不同的,但这两个映射函数需要被同时学习,所以可以利用有监督的学习,令损失函数最小化.将图像表示x ∈Rd和文字标注i ∈{1,···,Y},对应到图像和文字标注共有的词汇表中.
学习图像特征空间到联合空间RD的映射:ΦI(x):Rd →RD,同时学习文字标注映射:ΦM(i):{1,···,Y}→RD,采用线性映射,即ΦI(x)V x和ΦM(i)Mi,Mi是大小为D×Y矩阵的第i个索引列,可以使用任何非线性映射函数.对图像向量x使用视觉袋子模型的稀疏高维特征向量表示,每个标注都有自己的学习表示.
对于给定的图像,对可能的文字标注进行排序,选择排名最高的标注来描述图像的语义内容,表示为

其中根据fi(x)的大小对可能的文字标注i进行排序,从大到小,则模型族的范数约束为

将范数约束引入到模型的损失函数中进行训练,范数约束可以起到正则化项的作用.
Weston等人为了缩短训练时间,使用加权近似秩两两损失(weighted approximate-rank pairwise loss,WARP loss),类似于有序加权两两分类(ordered weighted pairwise classification,OWPC)[67],WARP使用随机梯度下降和一种新的抽样技巧来近似秩,从而得到一种有效的在线优化策略,作者通过实验证明该策略优于应用于在相同损失标准下的随机梯度下降算法,证明该方法不仅性能优于几种基准方法,而且计算速度更快,内存消耗更少.
5.2 引入文本语义信息学习图像对应的语义嵌入模型
Frome等人[68]提出了一种新的深度视觉语义嵌入模型(a deep visual-semantic embedding model,DeVi-SE),使用有文本标记的图像数据以及从未标注的文本中收集的语义信息训练该模型,从而识别视觉对象.模型实现过程如下.
这个模型的目标是利用在文本域中学习语义知识,将其迁移到视觉对象识别的模型的训练中.首先,预训练一个简单的神经语言模型[14];同时,预训练一个用于视觉对象识别的深度神经网络[69],该网络与传统的软最大输出层组合在一起完成训练;然后,对预训练的视觉对象识别网络的较低层重新训练,预测由语言模型学习的图像标签文本的向量表示,从而构造深度视觉语义模型.由两个预先训练的神经网络模型初始化深度视觉语义嵌入模型(DeViSE)如图18所示.

图18 DeViSE联合模型Fig.18 DeViSE model
Frome等人的实验表明:该模型能较好地实现有1,000个图像对象类的ImageNet目标识别任务,同时在零样本学习(zero-shot learning,ZSL)上也有不错的表现,利用语义知识改进了对这种未出现的图像的预测,在成千上万的视觉模型中对从未见过的新标签,实现18%的预测准确率.
5.3 引入单词结构内容学习单词隐表示
Kiros等人[70]提出了在多神经语言模型[71]基础上引入结构内容的神经语言模型(structure-content neural language models,SC-NLM),假定存在单词序列S{w1,···,wn},结构变量Tstr{t1,···,tN},这里,ti对应单词wi的词性,给定目标单词wi的上下文w1:n-1对应的隐表示u,目标是通过单词上下文w1:n-1和结构上下文tn:n+k(k是wi前面上下文单词的个数)来计算wi的分布式表示的条件后验概率P(wi|w1:n-1,tn:n+k,u).图19对多神经语言模型和SCNLM模型的预测问题进行了展示.可以发现引入单词在句子中起的结构作用变量有助于在生成短语模型时避免模型生成一些不必要的内容.

图19 3种神经语言模型Fig.19 Three neural network language models
SC-NLM可以理解为一个多神经语言模型,但是属性向量表示部分换成上下文向量u和结构变量Tstr的加性函数.假定,in,···,n+k是结构变量Tstr的嵌入向量表示,这些向量是学习获得的.引入G×G的结构上下文矩阵.令Tu为G×K的加性模型向量u的上下文矩阵.由结构变量Tstr和上下文信息组成的属性向量ˆu定义为
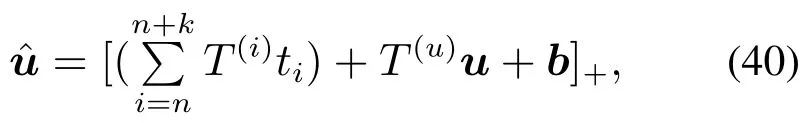
这里[·]+max{·,0}是ReLU非线性激活函数,b是偏置向量.向量ˆu替换多神经语言模型的向量u,并且模型的其余部分保持不变.Kiros等人[70]的实验表明,用LSTM编码器与SC-NLM解码器将Flickr30K数据集和Microsoft COCO数据集联合训练,获得了很好的结果,生成的语言描述很准确,也在DeViSE模型上提升了很多,实验结果对比见表10.

表10 在Flickr30K数据集上的实验Table 10 Experiments on Flickr30K data-sets
5.4 引入句法依赖解析信息学习特征嵌入表示
Chen等人[72]提出了将特征嵌入表示用于依赖解析的方法(feature embedding for dependency parsing,FEDP),能自动学习特征嵌入表示,解决句法依赖解析中特征稀疏的问题,模型介绍如下.
如图20所示,假定n个句子记为x1,···,xn,y1,···,yn ∈Y是与n个句子对应的语法(或者句法)解析树,假定第i个句子xiwi,1,···,wi,P包含P个单词,句子xi的任意某个单词wi,p的隐表示为fi,p,以下讨论中为了简化符号,去掉下标索引,简记为f,其对应的语法(或者句法)解析树中有依赖关系的节点的隐表示记为cf,在嵌入表示模型中使用当前基于依赖的特征表示来预测周围的特征表示,如图21所示.给定句子及其对应的依赖树Y,学习的目标是使上下文特征的对数条件似然概率最大化:

图20 输入特征集Fig.20 Input feature set
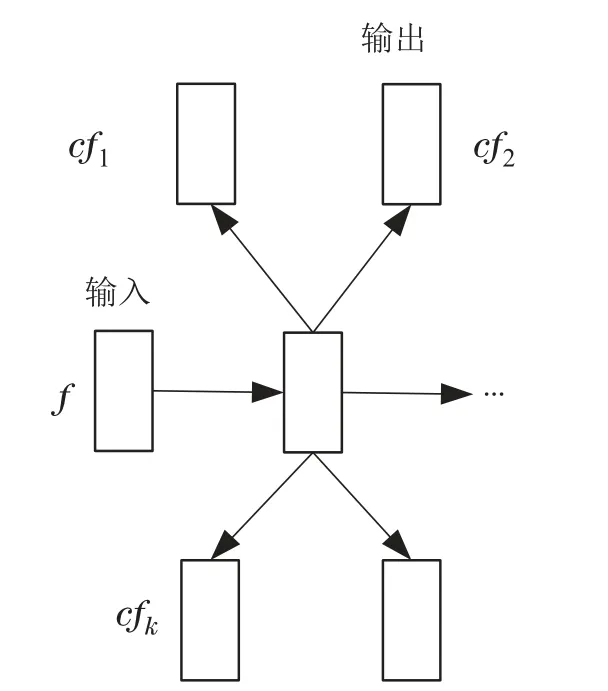
图21 特征嵌入表示模型Fig.21 Feature embedding model

其中:Fy是从树y生成的一组特征表示,CFf是特征表示f的M步(M-step)上下文中的周围特征隐表示的集合,cf ∈CFf.把条件后验概率P(cf|f)参数化为软最大函数[15]

其中:vf和uf分别是f的输入和输出单词向量表示,F是特征表中特征隐表示的个数.在处理大规模数据时,为了更好地计算概率,引入负采样方法,公式为
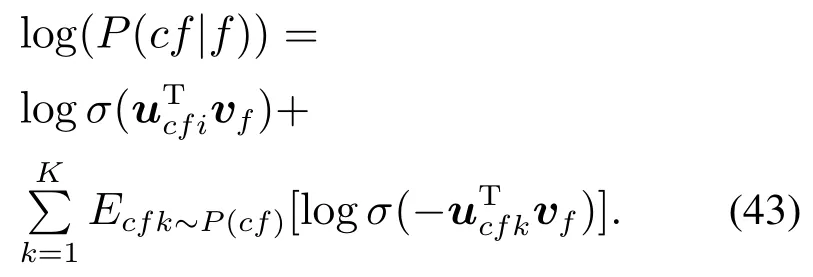
σ(z)1/(1+exp(-z)),P(f)是数据上的噪声分布,K取经验值5[15].逐一预测这些特征表示.在预测第i个特征表示后,用随机梯度上升方法进行迭代更新的公式为

其中:α是学习率,θ包括模型的参数和特征的向量表示.α的初始值是0.025.如果在一次更新后对数似然函数值没有显着改善,则将学习率α减半[73].
将句法依赖解析信息引入特征表示学习中,学习得到特征表示,可用于大规模依赖解析学习任务中.基于学习到的特征嵌入表示,作为一组新的特征,将它们与基于图模型的全局特征表示方法一起使用,在英语和中文测试(如表11)时,与基准方法相比,该方法显著地提高了性能表现.

表11 FEDP在中文数据集上的表现Table 11 FEDP performance on Chinese data-sets
5.5 小结与纵向分析
上述模型总结如表12所示,将图像与单词嵌入表示相结合,对于给定的图像,对可能的文字标注进行排序,可以更好地描述图像的语义内容.比如,DeViSE模型可以用于标签数目大得多的系统中,包括有类重叠或从未观察到的类别.更直接地利用所学的语言嵌入表示中已有的结构信息,大大降低联合模型的训练成本,并进一步扩展单词嵌入表示的应用场景.还有基于变送器的预训练语言模型,特别是BERT,以增强多模态表示的学习能力.例如,Lu等人[74]和Su等人[75]提出通过改进概念说明数据集(conceptual captions dataset)[76]上BERT的预训练模型,通过3个任务学习图像和自然语言的联合表示,即“遮盖”语言建模、“遮盖”视觉特征分类和句子-图像对齐建模.而Sun等人[77]将BERT 应用于视频领域,提出联合学习视频和语言表示,在各种有趣的文本视频相关任务中取得了很好的结果.鉴于这些工作已经取得的进展,期待共同学习多种模态表示,得到更多的研究.

表12 混合单词嵌入表示模型总结Table 12 Summary of mixed word embedding model
6 未来趋势与发展方向
综上所述,单词嵌入表示是自然语言处理任务的基础工作.嵌入表示是基于语义的单词向量表示,而这个向量表示的每一点改进都可能为后续工作提供很大的帮助.同时,单词嵌入表示与其它模型的融合可以使自然语言处理任务更加多元化,拓展自然语言处理应用范围,比如,可以有如下发展方向或应用方向.
1) 机器自动问答.
在当今的数字网络世界里,人们热衷于通过上网来搜索自己需要的知识,找到问题的答案,所以有越来越多的机器自动问答系统出现.尤其是随着预训练模型在一般自然语言处理任务中的成功应用,预训练模型也被引入到了生物医学领域,许多基于预训练模型的方法在生物医学机器自动问答任务中被证明是成功的.Peng等人[78]受迁移学习的影响,利用合适的单词嵌入表示,将命名实体识别应用到生物医学问答中,性能得到很大的提高.Hajiaminshirazi等人[79]针对社区问答(community question answering,CQA)存在信息不全面的问题,提出将跨语言嵌入表示用于资源较少的社区信息,方便进行跨语言问题检索,有效缩短翻译时间.所以针对不同应用场景的机器自动问答任务提升单词嵌入表示的性能仍是一个值得研究的方向,期待有更多领域的机器问答成果的出现.
2) 情感分析.
社交网络的发展离不开情感分析,近年人们也是对情感分析有很大的兴趣.Alharbi等人[80]利用单词嵌入表示和不同RNN变体对在线评论情感分析进行评价.Dovdon等人[81]提出Text2Plot方法,通过创建文本的二维情节表示来进行情感分析.Dong等人[82]提出了一种基于注意力的多任务学习网络,该网络利用共享单词嵌入表示向下游任务传递信息,允许提取和分类任务同时处理,不同于以前特定情境中的情感分析,避免了顺序模式导致的变换问题.在社交网络上,情感分析一直扮演着十分重要的角色,所以想要发展社交网络固然离不开情感分析的发展,故单词嵌入表示在情感分析领域的发展还是十分可观的.
3) 语义相似度.
微博、推特等在如今社会扮演着很重要的角色,需要在事件发生的同时实时更新重要时刻记录、个人评论等,而且大多数用户都更有兴趣阅读关于该事件最新进展的博文.然而,提取某事件的相关博文是一项具有挑战性的任务,大量噪音博文和社交媒体内容的词汇变异问题都是干扰推送性能的因素.为了应对这些挑战,Singh等人[83]提出了一种基于网页排名算法的计算博文语义相似度的方法.该方法利用Word2Vec模型,在博文图表示的邻接矩阵中包含基于词移动距离度量的语义相似度矩阵.其实验结果也表明,与基准方法相比,该方法生成的排名靠前的博文更简洁、更有新闻价值.单词嵌入表示在语义相似度上的应用还有Zhao等人提出的一种新的基于单词网络和词嵌入的语义相似度度量模型[84].
4) 词义消歧、多义词.
单词嵌入表示能够很好地表示词的语义信息,近年来也被广泛应用于词义消歧(word sense disambiguation,WSD)等任务中.但是,很多单词嵌入方法没有充分考虑词的同义性和多义性,致使它们的性能表现有限.Jia等人[85]提出了一种有效的基于主题词嵌入(topical word embedding,TWE)的WSD方法:TWE-WSD,该方法综合了隐狄利克雷分配(latent dirichlet allocation,LDA)模型和单词嵌入表示.TWE-WSD不是单纯地为每个单词生成一个单词向量表示,而是为每个主题下的每个单词生成一个主题词向量表示,同时设计了有效的集成策略来获得高质量的上下文向量,并获得了不错的性能表现.Li等人[86]也针对多义词进行了研究,提出了一种自适应跨语境词嵌入算法,是针对多义词问题的无监督主题建模.该方法在很多基准数据集上都取得了好的性能.所以,将单词嵌入表示应用于词义消歧也是一个很重要的研究方向,能够更好地完成搜素引擎、意见挖掘、文本理解与产生、推理等任务.
5) 语义信息丰富的语言.
汉语的单词嵌入表示最近引起了相当大的关注,汉字及其部首偏旁成分包含丰富的语义信息,都能用于学习汉语的单词嵌入表示.汉字包涵意思、结构和读音,现有的嵌入学习方法主要关注汉字的结构和意思.Yang等人[87]就提出了一个方法:语音增强的汉语单词嵌入表示,一种能够完全利用汉字所代表的信息,包括读音、形态、语义的嵌入表示学习方法,即将上下文字符和目标汉字的发音同时编码到嵌入表示中.在词语相似度评价、词语类比推理、文本分类和情感分析等任务上都验证了该方法的有效性.鉴于这些工作已经取得的进展,可以期待更多单词嵌入表示应用到其他语义信息丰富的语言中,已完成翻译等任务.
6) 多模态学习.
单词嵌入表示早已不是独立存在的个体,它已经在很多领域与其它模型方法相结合了,上文也有提及,比如,与图像相结合,提高图像识别的性能及应用领域等.Wang等人[88]将单词嵌入表示应用到遥感领域,提出基于单词嵌入表示和端到端深度学习的遥感图像描述相结合的方法,通过精确、简洁的自然语句描述,实现了复杂遥感图像中胡杨和柽柳的分类识别.笔者也期待单词嵌入表示应用于更多的行业中,如医学影像、气象遥感等.
7) 简化训练过程.
BERT模型的提出掀起了注意力机制的热潮,但是语言模型预训练方法往往需要大量的计算机资源,很多研究者和机构无法轻易拥有相应的资源,从而,阻碍了单词嵌入表示研究的发展.因此,简化模型、减少计算量、缩短训练模型的时间也是一件很有挑战很有意义的事情.
7 结论与展望
本文对一些基本单词嵌入表示的模型及其变体进行了分析和研究,对单词嵌入表示的方法和理论做了综述,将单词嵌入表示按照语言数量分为单语言单词嵌入表示和跨语言单词嵌入表示,在单语言中,针对是否考虑上下文信息,将单词嵌入表示模型再次分类,字符级和单词级的单词嵌入表示多数都没有考虑上下文信息,而后续的模型都注意到了多义词问题,考虑了上下文信息.
第2节主要阐述了字符、单词、短语、句子嵌入表示之间的关系,它们各有优缺点.单词嵌入表示是目前自然语言处理任务中常用的将单词向量化的方法,但是通常会忽略有关单词形态和形状的信息,对于像词性标注这样的任务,特别是在处理形态丰富的语言时,单词内信息不可忽视,所以有人研究提出了字符级模型,也有人将字符表示与单词相结合,如C2W模型.也有人认为单词组成的短语是不应该随便拆分的,学习短语更有助于语义的学习.Mikolov也发现当前的单词表示,会丢失单词的顺序,并且忽略了单词的语义,所以提出了一种无监督的段落向量算法,它可以从句子、段落和文档等长度可变的文本片段中学习固定长度的特征表示,在情感分析等任务中表现出色.Levy等人对Mikolov等人提出的负抽样的Skip-Gram模型进行扩展,引入基于依赖的上下文信息,进行实验,得到的模型主题性更少,功能相似性更好.
第3节主要介绍了考虑上下文信息的单词嵌入表示,CoVe模型为NLP任务带来了很大的改进,也为之后的预训练技术奠定了基础,而ELMo更是刺激了NLP的发展,后续有大量的考虑上下文信息单词表示的研究,也使人们的注意力从大的无标记文本中捕获语言信息转移到了下游任务,也是BERT模型和VIB模型的基础.VIB对嵌入表示的信息进行非线性压缩,针对依赖解析任务,只保留有助于鉴别依赖解析的信息,把每一个单词嵌入到一个离散的标签或者连续的向量中,避免了对压缩表示中的可用的维数的不必要使用,利用随机映射去除了不需要的部分信息.
第4节是对跨语言单词嵌入表示模型的介绍,由于世界上语言很多,但只有少数语言有丰富的注释资源,这就需要单词嵌入表示的跨语言迁移学习,在丰富资源语言上训练的模型应用到低资源语言上,输入嵌入表示被投影到共享的语义空间中,跨语言单词嵌入表示不仅仅能用于机器翻译,还能用于其它NLP任务,缩减翻译时间.
第5节是将多种方法或者多个模态进行组合,得到效果更好的模型,是对前面模型更深入的应用,不仅仅局限于单词短语的嵌入表示,还与多视图等其它研究融合,这也体现了当今机器学习,计算机视觉,语音信号处理和自然语言理解之间,共同发展相互融合的思想.
最后,本文的第6节详细阐述了单词嵌入表示的未来趋势及发展方向,进一步说明单词嵌入表示的研究价值和应用潜力.
总之,从本文总结的工作中可以看出,单词嵌入表示是目前研究的一个热点,目前已经取得了大量的成果,拥有重要的理论价值和应用价值,有力地推动着自然语言处理的研究及应用.随着理论研究的进一步深入和应用领域的进一步扩展,单词嵌入表示必将会发挥越来越重要的作用.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
汉字汉语研究(2020年2期)2020-08-13
开放教育研究(2020年2期)2020-03-31
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
