
轻型金字塔池化注意力机制网络实现图像超分
2022-10-17 11:08方金生朱古沛
计算机工程与应用 2022年20期
方金生,朱古沛
1.闽南师范大学 计算机学院,福建 漳州 363000
2.数据科学与智能应用福建省高校重点实验室(闽南师范大学),福建 漳州 363000
图像超分辨率重建(super-resolution reconstruction,SR)技术是由低分辨率(low-resolution,LR)图像重建出高分辨率(high-resolution,HR)图像,在医学、多媒体等领域有诸多应用,是近几年的研究热点[1]。然而SR是一个典型的病态问题,即一幅LR图像对应多幅HR图像[2]。为解决这个问题,研究人员先后提出了诸多基于先验信息来限制重建的解空间的数值法[3]和基于学习的方法[4],但这些方法都无法获得令人满意的效果。如何有效地从LR图像中恢复HR图像且不出现失真是该领域的研究重点。
近年来,深度学习在计算机视觉和自然语言处理等领域都展现出了强大性能[5],国内外研究团队由此提出了诸多基于深度学习的SR模型[6-11]。Dong等人提出了第一个基于卷积神经网络(convolutional neural network,CNN)的图像SR方法SRCNN[12],该方法首先对LR图像进行双三次插值[13]上采样预处理,再经过三层卷积神经网络进行图像重建过程。由于该算法速度较慢,Dong等人提出加速模型FSRCNN[14],该算法采用卷积层代替双三次插值,使用更小的卷积核以及更多的特征通道,同时在最后一层引入反卷积进行上采样,有效地加快了网络速度。He等人提出残差学习网络ResNet[15],其中的残差学习方法能够有效地解决深层网络的梯度消失和梯度爆炸问题,并且能加快网络的收敛速度。由此,残差网络成为研究人员加深网络来提高性能的重要方法。随后,Kim等人首次将残差学习引入SR领域,构建一个深层网络模型VDSR[16],提高了重建精度且实现多尺度重建。Lim等人将原残差模块中的批归一化层去除并在残差支路乘以一个小的系数,由此提出了EDSR[17],该方法实现了多尺度的精确重建,但也使得网络参数量高达43×106。然而,SR技术是为从LR图像中恢复更多细节,即高频信息,然而大多数网络模型[14,17-18]对每个通道特征进行相同权重处理,则会导致对低频特征进行不必要的计算,从而降低深层网络的性能。因此,Zhang等人提出了RCAN[19],将通道注意(channel attention,CA)加入到嵌套的残差结构中,构建出超过四百层的大规模网络,大幅提高峰值信噪比(peak signal to noise ratio,PSNR)。
上述方法均通过加深或加宽网络以获得更优的网络性能。但是,规模过大的网络模型会消耗更大的存储空间以及计算负担,不适合应用于计算能力受限的设备以及对实时性要求高的场合。所以,在设计网络时需要考虑模型大小与重建性能之间的权衡问题[20-24]。
因此,设计轻量化的SR模型成为了重要的研究方向。Lai等人通过设计拉普拉斯金字塔结构提出LapSRN[20];Ahn等人通过设计级联模块提出CARN[21];Hui等人通过设计蒸馏模块提出IDN[22];Hui等人进一步设计出信息多蒸馏块提出IMDN[23];Liu等人对信息多蒸馏模块继续改进,构建出残差特征蒸馏块,提出了RFDN[24]。这些轻量级网络模型均能以相对较低的模型参数量和计算复杂度获得优异的重建性能,但均存在不足。LapSRN[20]逐步进行图像上采样使得网络中会产生大尺度的特征映射,从而造成网络计算量显著增加;CARN[21]提出的级联机制可以融合各层的信息,与此同时也因为使用稠密连接增加参数量和计算量;IDN[22]中的蒸馏结构不能有效筛选出需要进一步提炼的重要特征;IMDN[23]中的逐步细分模块不够高效以及通道分离操作缺乏灵活性;RFDN[24]在权衡参数和性能之间是相对较好的,但由于直接对各蒸馏模块特征进行拼接融合,没有充分利用网络中的低、高频信息,模型性能还有进一步提升的空间。
为此,本文提出一种轻量级的基于金字塔池化注意力机制网络(light-weighted pyramid pooling-based attention network,LiPAN),实现以较小的参数量和计算量获得更优的SR效果。该网络包括特征提取和重建两个阶段,特征提取阶段中包含信息蒸馏块(information distillation block,IDB)、金字塔池化模块(pyramid pooling module,PPM)以及反向注意力融合模块(backward attention fusion module,BAFM)。IDB对特征进行提取操作,然后将各层特征蒸馏出来进行融合,再经过注意力模块提取特征中关键的信息,该结构充分利用各层不同特征的信息,实现对特征的有效提取。PPM对特征进行不同尺度的池化,该模块通过获取更大的感受野得到更多的上下文先验信息。BAFM对不同层次的特征进行融合,在融合前需经过注意力模块对特征的空间信息进行关注度区分,相比于RFDN中简单地将不同层次的特征进行跳跃拼接操作,BAFM能够更加有效地融合不同层次的信息,从而重建出更加清晰的图像。
综上所述,本文的主要贡献有三点:(1)提出了一种轻量级的基于金字塔池化注意力机制网络,与其他轻量型网络相比,在参数量相当的情况下本文的网络可以得到更好的SR性能;(2)在信息蒸馏块之后引入金字塔池化模块,金字塔池化模块能够获得更大的感受野以及更多的先验信息,实验证明该模块能恢复更真实、尖锐的细节信息;(3)设计了一个反向注意力融合模块,它将所有金字塔池化模块之后的特征进行空间重要度区分之后进行融合,该设计在引入少量参数的情况下能够进一步提高SR性能。
1 相关工作
1.1 残差特征蒸馏块
RFDB是RFDN的核心模块[24],如图1(a)所示,RFDB由3个1×1卷积(Conv-1)和3个浅残差块(SRB)组成,而SRB仅由一个3×3卷积(Conv-3)和一个恒等连接分支组成,如此设计能够让RFDB在不增加参数量的情况下更好地利用残差学习的能力。在RFDB中,使用1×1卷积进行信息蒸馏,参数量和运算量都明显得到了降低。
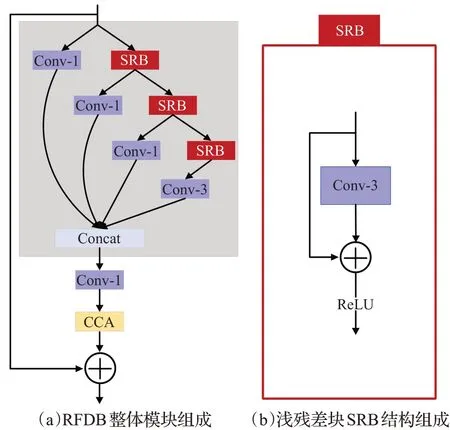
图1 原始RFDB结构Fig.1 Structure of original RDFB
1.2 金字塔池化结构
金字塔池化结构多用于图像分割任务中,He等人提出了基于空间金字塔池化(SPP)结构的SPPNet[25],生成不同层次的特征图,实现了CNN输入图像尺寸可变;Zhao等人构建金字塔池化模块(PPM),提出PSPNet[26]方法,PPM是一个有层次的全局先验结构,包含不同尺寸、不同子区域间的信息,比起SPP,PPM能够进一步减少不同子区域间上下文信息的丢失,能够在深层神经网络的最终层特征图上构造全局场景先验信息。PPM首先将输入图像经过金字塔得到N个不同的子区域,金字塔池化模块中不同层级的输出包含不同大小的特征映射,在每个级别后使用1×1卷积,将对应级别的通道数量降为原本的1/N,然后通过双线性插值直接对低维特征图进行上采样,得到与原始特征映射相同尺寸的特征图,最后,融合各个层级的输出特征,作为最终的金字塔池化全局特性。PPM通过不同尺度的池化层得到多尺度图像特征,再将这些特征融合以获取不同的图像细节。
PPM的具体结构如图2所示,若采用四阶的金字塔池化模块,即{1×1,2×2,4×4,8×8}的平均池化层,设i×idown表示尺度为i×i的自适应平均池化操作,up_i指第i层的上采样操作,将输入特征记为Fin,池化层的输出Fpool_i可以表示为:

图2 PPM结构图Fig.2 Structure of PPM

其中,Fup_i和Fdown_i分别代表第i阶段特征的上采样和下采样函数,Fr定义为1×1特征降维卷积。因此,PPM的输出可以描述为:
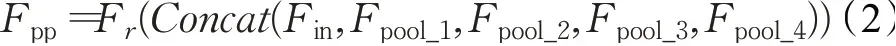
式中,Fr表示1×1卷积的降维函数,Concat表示在特征通道维度上进行拼接操作。
1.3 注意力机制
近年来注意力机制被广泛应用于计算机视觉研究中,比如图像分类、目标检测以及图像超分辨率等。SENet[27]算法成为ImageNet 2017竞赛分类任务上的冠军模型,该模型引入通道注意力,它可根据通道特征上不同的权重响应进行区分特征重要性。Hui等人在IMDN中进一步提出了CCA,与CA模块相比,该模块对通道权重依据进行了调整,由原来的均值升级为标准差与均值之和。Liu等人在RFANet[28]中提出增强的空间注意力(ESA),ESA先是进行1×1卷积减小通道维度,保证该结构的轻量化,然后设计步长为2的3×3卷积,再用大小为7×7,步长为3的最大池化操作进一步扩大感受野,从而能更大范围地关注到特征中重要的空间信息。
2 本文方法
本章主要介绍LiPAN算法的网络结构及主要功能模块IDB以及BAFM的具体实现方法。
2.1 LiPAN总体网络结构
如图3所示,本文提出的网络模型LiPAN由浅层特征提取、信息蒸馏块IDB、金字塔池化模块PPM、反向注意力融合模块BAFM和上采样模块组成。IDB由蒸馏结构和ESA模块组成,ESA能够使特征信息更集中于感兴趣区域,因而该结构在控制参数量的情况下能够提取到更多的高频信息,使得重建图像的纹理更加以及边缘更加尖锐[28];PPM进一步扩大感受野,提取不同尺度的上下文特征信息[26];最后,BAFM对不同层次的各种尺度特征进一步提取和融合,利用ESA对特性有效提取的优势,可更为准确地重建图像。
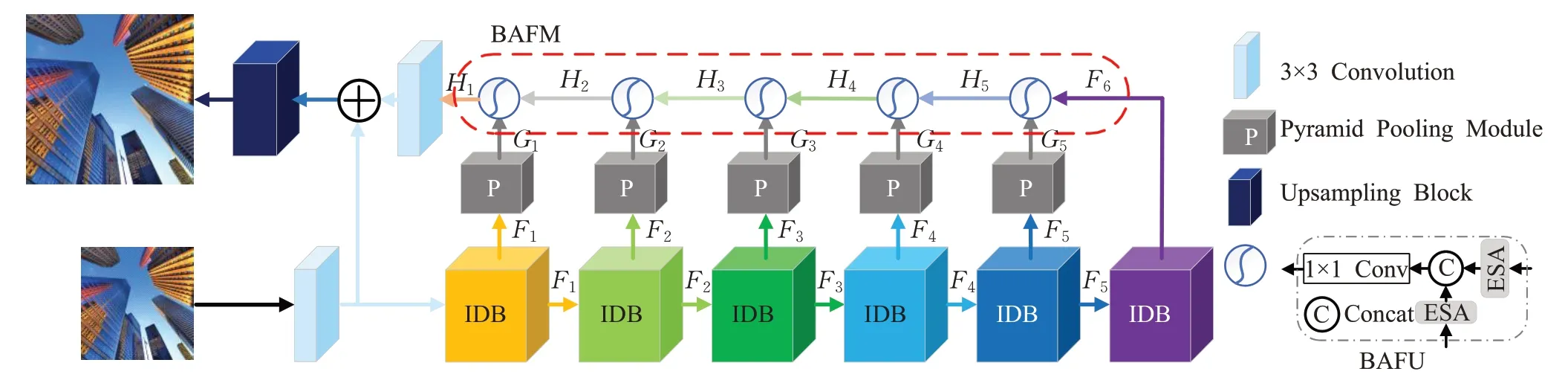
图3 LiPAN结构图Fig.3 Architecture of LiPAN
将输入的LR图像和输出的HR图像分别记为X和Y。首先,输入的LR图像X经过一个3×3卷积层得到浅层特征F0,然后F0经过n个IDB逐步提取特征,该过程记为:

其中,Rk表示第k个IDB函数,Fk-1和Fk分别表示第k个IDB的输入和输出特征。将IDB的输出特征分别输入金字塔池化模块(第n个IDB的特征除外),则输出特征为:

其中,Gk为第k个IDB经过PPM函数的特征输出为第k个PPM函数。接着将所有的中间特征经过BAFM进一步融合各层次频率信息:

其中,Ff和Rf分别代表融合后的输出特征和BAFM函数。最后采用亚像素卷积上采样层生成SR图像Y:

其中Rup为上采样函数。
2.2 信息蒸馏模块
图4显示了IDB的具体结构,由渐进细化模块(progressive refinement module,PRM)和ESA组成。如图4(a)所示,红色虚线内为PRM,其中,SRB为浅残差模块,PRM由4个用于细化特征的SRB与4个用于蒸馏特征的1×1卷积Conv-1组成,最后将所有蒸馏特征进行融合。假设输入特征为Fin,则4个阶段的信息蒸馏过程如下[24]:

其中,DLi表示第i个阶段的蒸馏层,RLi表示第i个阶段的SRB块,Fdistilled_i表示第i个阶段的蒸馏特征,Frefined_i表示第i个阶段的细化特征,最后将所有阶段的蒸馏特征拼接起来作为PRM的输出:

其中Concat表示在通道维度上进行拼接操作。
最后,如图4(b)所示,ESA首先使用1×1卷积将输入特征进行降维,再依次连接步长为2的卷积层、最大池化层,然后经过2个3×3卷积层、1个上采样层、1个1×1卷积层,最后经过Sigmoid激活层产生的结果与原始输入特征进行相乘得到最终结果。另外,将第一个1×1卷积降维后的特征与上采样后的特征相加。若ESA运算记为Fesa,则IDB的输出为:

图4 IDB的结构Fig.4 Structure of IDB

其中Fr表示1×1卷积的降维函数。
2.3 反向注意力融合模块
如图3所示,图右下角表示反向注意力融合单元(backward attention fusion unit,BAFU),本文由5个BAFU组合而成BAFM模块。该模块将高层特征H5逐层向低层特征H1融合,对相邻层的特征经过注意力机制ESA后进行融合,这样可以有效地利用不同层次提取到的特征信息,并且可以获得更多的上下文信息[8]。
BAFU主要由ESA和1×1卷积层组成,采用向后注意力融合策略,先经过ESA获取关键重要的空间特征信息,再经过1×1卷积对不同层次的信息进行融合。这里定义第i个IDB函数的输出为Fi,Fi再经过PPM函数的输出定义为Gi,因此融合操作可以用公式表述为:

其中,Fesa为增强的空间注意力单元,Concat表示对相邻层次的特征进行拼接,Conv为对特征进行融合并降维的1×1卷积。将中间层的特征从后往前依次进行特征融合,直到最终生成的融合特征H1。最后将H1与浅层的特征F0相加并传播到上采样层得到SR图像。
3 实验
3.1 数据集
本文算法的训练数据集为DIV2K,该数据集包括800张高质量的训练图像和100张纹理丰富的验证图像[29]。LR图像由对HR图像进行双三次下采样操作获取。本文在4种公共的数据集上进行模型的评估:Set5[30]、Set14[31]、BSD100[32]、Urban100[33],这4种测试集来源于自然景观、人物等真实图像,数量分别为5张、14张、100张和100张。以峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(structural similarity,SSIM)作为评价度量。
3.2 实验设置
LiPAN的实验设置与经典算法EDSR[17]、RCAN[19]等保持一致,训练图像的大小为48×48像素的LR图像块,采用随机的水平翻转和90°旋转方式实现数据增强,并将所有训练图像减去均值图像。使用Adam优化器,其参数设定为β1=0.9,β2=0.999和ε=10-8,批数据量为16,损失函数为平均绝对误差(MAE)。在LiPAN网络中,IDB的蒸馏率设为1/2,PPM的池化尺寸分别为{1,2,4,8},ESA单元中的缩小因子设置为4,LiPAN的特征通道维度设置为48;初始学习率为5E-4,数据总的训练轮次(epochs)为1 000,每经过200个轮次,学习率减半。该网络使用PyTorch框架实现,并使用GTX 3090的GPU进行训练。
3.3 消融实验
为了更好地研究LiPAN各个模块的作用,在4个测试数据集上分别测试含有各个功能模块的网络性能,并计算相应的平均PSNR值及网络参数量,结果如表1所示。Base指基准网络,由6个IDB以及无注意力机制的反向特征融合模块(BFM)组成;网络Base_PPM指在Base基准网络引入PPM;网络Base_BAFM指在Base基准网络引入BAFM;而本文提出的网络LiPAN在基准网络同时引入Base_BAFM和PPM。

表1 在4个测试集上的消融实验(3倍采样率)Table 1 Ablation study on 4 testing dataset(with sampling scale of 3)
从表1可以看出,在基准网络Base上应用PPM模块后,PSNR值提升了0.01 dB,证明了PPM模块的有效性,通过对输入特征进行多尺度特征融合,增强了特征表达能力;在基准网络Base上应用BAFM模块后,PSNR值提升了0.04 dB,说明BAFM模块有效地融合了相邻层次的特征信息,从而提升了网络性能;Base_BAFM比Base网络的参数量有所增加,主要在于Base_BAFM运用了ESA机制。本文提出的LiPAN在Base_BAFM基础上引入PPM,可以在仅增加35×103参数的情况下进一步将PSNR值提升0.06 dB。
LiPAN训练的收敛过程如图5所示,Base、Base_PPM、Base_BAFM以及LiPAN在3倍采样率下,在Set5测试数据集上得到的PSNR与训练轮次的关系曲线图。由此可知LiPAN模型收敛速度更快,且损失值更低,这表明BAFM和PPM模块可以帮助LiPAN网络很好地收敛以及获得更佳的重建性能。

图5 不同模型的PSNR值收敛过程Fig.5 Convergence of PSNR of different models
3.4 BAFU与PPM数量对网络性能影响
BAFU与PPM作为LiPAN重要的模块,二者的数量决定着网络的性能。因此,本节在其他条件保持一致的情况下,仅改变二者模块数进行实验,评估对结果的影响。实验结果在采样率为3的4个测试集上得到,如表2所示,当数量设为n时,表示在前n个IDB后面连接PPM和BAFU。
从表2可知,当BAFU和PPM数量小于6时,随着数量的增加,PSNR也随之提高,参数量也呈线性增加。当BAFU和PPM数量为6时,网络参数量继续增加,但PSNR反而减少,主要原因在于第6个IDB提取出来的是高频信息,PPM中使用了全局池化操作,会一定程度地平滑边缘信息,导致网络的性能下降。因此,BAFU和PPM数量为5时能够在网络规模与性能之间达到最好的平衡。

表2 BAFU与PPM数量对网络性能的影响(3倍采样率)Table 2 Effectiveness of number of BAFU and PPM
3.5 与主流轻量级网络的性能比较
为了验证本文LiPAN方法的性能,将其与Bicubic[13]、SRCNN[12]、FSRCNN[14]、VDSR[16]、LapSRN[20]、MemNet[34]、CARN[21]、IDN[22]、IMDN[23]、RFDN[24]等经典轻量级SR方法进行比较。表3、表4和表5分别显示了LiPAN与其他轻量级模型在2倍采样率、3倍采样率及4倍采样率时,在不同测试数据集上的客观评价。与对比算法相比,大多数情况下,LiPAN具有较优的PSNR和SSIM值。由此表明,在相近的网络参数量和乘加运算量情况下,LiPAN的综合性能优于对比算法。

表3 尺度因子为2时不同模型的定量指标比较Table 3 Quantitative comparison of different methods under sampling scale of 2

表4 尺度因子为3时不同模型的定量指标比较Table 4 Quantitative comparison of different methods under sampling scale of 3

表5 尺度因子为4时不同模型的定量指标比较Table 5 Quantitative comparison of different methods under sampling scale of 4
图6和图7分别显示了本文模型LiPAN与SRCNN[12]、VDSR[16]、LapSRN[20]、CARN[21]、IMDN[23]和RFDN[24]模型的视觉效果比较。如图6所示,LiPAN的重建图像能够有效地抑制图像的伪影,其得益于IDB能够恢复出更尖锐的边缘信息;同时,BAFM对不同层次信息的有效融合,使得本文方法重建图像的细节和纹理更加清晰。如图7所示,由于降采样使得高频信号缺失导致建筑斜顶端的窗户出现错误的预测,而本文方法通过PPM融入了全局场景信息,有效地利用周边的信息,重建的结果更接近于真实图像。

图6 不同算法在3倍采样率下的视觉效果比较Fig.6Qualitativecomparisonofdifferentmethodsundersamplingscaleof3

图7 不同算法4倍采样率下的视觉效果比较Fig.7 Qualitative comparison of different methods under sampling scale of 4
表6显示了LiPAN与其他算法的重建实时性比较,与VDSR和MemNet相比,LiPAN具有更少的参数、乘加数以及运行时间;与CARN相比,LiPAN具有更少的参数以及乘加数,但运行时间略有增加;与RFDN相比,LiPAN在参数、乘加数以及运行时间三者均有所增加,这主要因为BAFM和PPM的引入增加了网络的深度,以及ESA在具有强大的空间特征重要度判别能力的同时,也增加了其结构的复杂性。
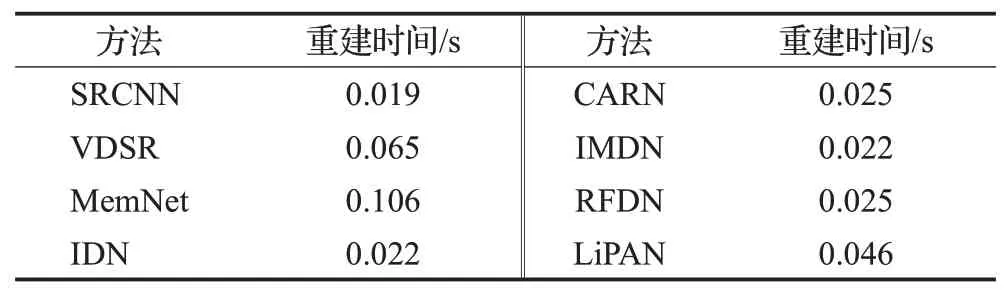
表6 模型实时性比较Table 6 Real-time comparison with other methods
图8显示了LiPAN与对比网络的参数量、乘加数和网络性能对比,LiPAN具有与IDN、IMDN和RFDN等算法相近的参数量级,但拥有最高的PSNR值;同时,在乘加数方面,LiPAN的乘加数少于一些主流轻量级网络但具有较高的PSNR值。综上所述,LiPAN的网络性能均优于其他主流网络。

图8 不同网络模型的性能比较Fig.8 Performance comparison of different network models
4 结语
本文提出了一种基于IDB模块、金字塔池化结构及注意力机制的轻量级超分辨重建网络LiPAN。该网络通过注意力机制及多层次提取不同尺度特征信息方式,能够有效提取丰富的图像细节,从而获得较优的重建性能。相比于其他基于CNN的轻量型算法,LiPAN能在相同量级的网络规模上,以相对较低的计算量获得更优的主观和客观结果。然而,由于LiPAN的结构较为复杂而需要更多的重建时间,因而,提高LiPAN的实时性是接下来的研究内容。
猜你喜欢
环球时报(2022-09-19)2022-09-19
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
考试与评价·七年级版(2020年4期)2020-10-23
上海师范大学学报·自然科学版(2019年5期)2019-12-13
初中生世界·九年级(2018年12期)2018-12-22
小学教学研究·新小读者(2017年9期)2017-10-25
读者(2015年9期)2015-05-04
初中生世界·八年级(2014年2期)2014-03-15
