
基于图模型的高光谱图像分类算法
2022-10-26 04:29黄炟鑫蒋俊正
桂林电子科技大学学报 2022年3期
黄炟鑫, 蒋俊正
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
高光谱图像(hyper spectral image,简称HSI)最先应用在卫星遥感技术上,现已在军事、医学、地质、农业等领域得到广泛应用[1-5]。成像仪对待测目标进行多窄波成像,而后把成像结果进行组合,得到一个多频带的数据块,该数据块即为HSI。在HSI的成像过程中,同一物质在接收到不同波长的电磁波时,会因内部材料结构等因素的影响而呈现出不同的反射效果,相比于普通图像只包含空间信息,HSI的成像特点使其携带了更多的频谱信息。对HSI数据的研究较为广泛,有端元提取[6]、端元解混[7-8]、分类[9]等,其中分类是最为基础的研究内容。分类的目的是对HSI数据中每个像素点进行类别标记,所得结果对HSI待测目标的识别与监测等任务而言有很大的参考价值[10]。
HSI分类问题可使用监督学习[11-12]算法求解。这类算法在分类时需使用大量已标记数据,然而在实际情况中,几乎没有原始数据是已标记数据,而对原始数据进行标记需要消耗大量的人力与物力。因此,能有效利用少量已标记数据与海量无标记数据进行分类任务的半监督学习算法就受到了许多关注[13]。而在分类问题中,维度过高的特征会引起“休斯现象”“维数灾难”等问题,进而影响分类结果[14]。图半监督学习先使用图模型对数据进行降维,再进行问题建模并优化出分类结果,其中比较具有代表性的有最小割算法[15]、局部全局一致算法[16]和高斯域与调和函数算法[17]。这些算法均为直推式学习算法[13],相比于推导式学习算法在优化过程中优化的是分类器的参数[13],直推式学习算法目标函数的优化直接计算出分类结果,因此图半监督学习算法在计算速度上有一定优势。经过十几年的发展,图半监督学习具有坚实的理论支撑,且在不同的应用背景下的实用性都得到了验证[18-19]。
在数据规模较大时,图半监督学习算法的计算复杂度也随之提升,针对此问题,提出一种分类算法,从分解优化问题出发,在保证原有的分类精度情况下降低求解所需的时间,且该算法可以分布式实现。在该算法中,用一种较为简单的方式近似计算目标函数Hessian矩阵的逆,然后通过迭代求出优化问题的解。仿真结果表明,与现有的图半监督学习算法相比,该算法能在较短时间内获得较好的分类结果。
1 基础知识
1.1 高光谱图像简介
与人眼的成像系统类似,传统成像仪内部感光元器件只能感应到可见光频段(360~830 nm)内的电磁波,且成像时只能进行单宽波段成像,因此对成像结果的直观感受是一张尺寸为m像素×n像素(以下简写为m×n)的彩色图像。由于可见光频段上的电磁波均可以由红绿蓝(RGB)三色光组合表示而成,传统图像也被称为RGB图像,并在处理时通常使用对应RGB三个颜色分量的3张灰度图对其进行表示,此时成像结果即为一个数据块,由3张尺寸为m×n的图片重叠而成[2]。RGB图像低频率分辨率的成像特点,使得相关研究极度依赖图像内包含的空间信息。因此,对于RGB图像而言,空间分辨率是最为重要的特性。相比于RGB图像成像仪,HSI成像仪所能感应到的电磁波频段更为宽广,覆盖范围通常为紫外波段到近红外波段。此外,HSI成像仪的另一重要特性是能进行多窄波段成像,即成像仪在成像过程中,把待测物体反射回的电磁波切分成多个波段,接着使用每个波段的电磁波进行成像,最后将多个成像结果合成为数据块。这样的成像方式使得HSI以尺寸为m×n×d的数据块形式呈现,其中,m×n是成像仪对单个波段响应的成像结果尺寸,d是成像时切分的波段数,同一个像素点在d个频率上的不同响应构成像素点的频率特性。高光谱图像频率特性如图1所示。成像的特性不同,使得HSI相比RGB图像拥有更为丰富的频谱信息与更为精细的频率分辨率。正因如此,大多数对HSI数据的研究主要从其频率信息出发。

图1 高光谱图像频率特性
1.2 分类问题与建模
在HSI各项研究中,分类是较为重要的研究内容。其根据HSI数据的频率信息,对每个像素点进行类别标记。如前所述,HSI表示为一个尺寸为m×n×d的数据块,该数据块由d张对应不同波段的图片组成。由于d张图片都是对同一个目标进行成像,不同图片上的相同位置像素点的值实际上就是该点对于不同频率电磁波的响应,而d个响应就构成该像素点所对应物体的光谱特性。在HSI分类问题中,光谱特性是分类时的一个重要参考。光谱特性在引入更多信息的同时,也带来了特征的维数问题,而维度过高会导致分类精度下降。因此,先使用图建模算法对其进行降维,接着建立优化问题,进而求解得出分类结果。图是一种常见的数据结构,目前已在无线传感器网络、社交网等场合中得到应用[20]。图由节点与边组成,通常表示为G={V,E,W},V与E分别为图的节点集与边集,W为图的权矩阵,权矩阵内为图上权重值。节点之间通过边相连接,边描述节点间的邻接关系与相似关系,边上权重即为权矩阵中的元素,两节点越相似,二者之间的权重值越大。此外,还常用拉普拉斯矩阵L=D-W、归一化图拉普拉斯矩阵Ln=D-1/2LD-1/2来表示图的相关特性,其中D为度矩阵,其定义为
(1)

一个像素点数为N,频段数为d的HSI数据通常用特征矩阵
X=[x1,x2,…,xN]∈RN×d
表示,矩阵中的每一行为对应像素点的频谱特征。根据该特征矩阵,用图对HSI数据进行建模,所建模图使用k近邻图(kNN图)。在建模时,首先计算第一个节点与余下所有节点的欧式距离(这一距离由频谱特征确定),接着选择最相近的k个节点作为邻居并与之相连,而后重复这2个步骤直到所有的节点都与其最近的k个邻居相连,再用每个节点与其的距离计算出权重值:
(2)
该值用于描述边所连接的节点的相似程度,其中,xi∈R1×d与xj∈R1×d分别为第i个与第j个像素点的频谱特征。通过以上步骤,便得到一个kNN图G。像素点上的标签用y=[yl;yu]表示,yl代表已知标签,yu代表未知标签,值为0。在实际的分类问题中,yl≪yu。在图半监督分类问题中,根据已知部分标签yl与所建模图刻画的数据特性学习出yu的标签,完成分类。
2 分类问题求解
根据所建立的图模型G={V,E,W},关于HSI的c分类问题可归结为
(3)
其中:yj为标签one-hot编码矩阵Y的第j列,表示第j类标签在数据中的分布情况,Y的定义为
(4)
Ln为图G的归一化拉普拉斯矩阵。优化问题可以理解为学习出一个比较符合所建模图的标签one-hot编码矩阵F。得到F后,通过下式来取得最终的分类结果。
(5)
不难看出,图半监督学习的主要任务是在对F,即f1,f2,…,fc的求解上。c个向量f1,f2,…,fc的求解过程相同,因此仅对任一fj的求解进行分析,令f=fj,
(6)
显然,目标函数是一个关于f的凸函数,且有解析解,解为f*=(I+α-1Ln)-1y。但在数据规模变大时,集中式求解矩阵的逆会变得困难。
2.1 优化求解
式(6)可用牛顿法来求解。其一阶与二阶梯度信息分别为
(7)
即目标函数的Hessian矩阵H为αI+Ln。在牛顿法求解过程中,需要在每步迭代中计算Hessian矩阵的逆以求出步长sk=H-1▽φ(fk),而这在矩阵规模较大的情况下会相当耗时,在此提出一种近似牛顿法。
对于图归一化拉普拉斯Ln,有Ln=I-Wn,其中Wn为图的归一化权矩阵,可进一步分解为2个部分;对角部分Wnd与非对角部分Wnu,其中Wnd=diag(Wn),且Wn=Wnd+Wnu。基于此,同样可将Hessian矩阵H分割为对角部分与非对角部分,即
H=A-B,
(8)
其中:
(9)
其中,θ≥0为控制矩阵分解的参数,设置为1。此外,所建模的图都不带自环,因此其归一化权矩阵的对角部分均为0,即Wnd=0。基于此,取θ=1时,式(9)可进一步更新为
(10)
此时,式中目标函数在第k次迭代中时的牛顿步长为sk=-(A-B)-1▽φ(fk)。根据文献[21],可用
sk=-(I-QB)A-1▽φ(fk)
(11)
对其进行近似。由文献[21]可知,Q与Hessian矩阵的逆等效,并可通过泰勒公式对其进行近似,令P=Wn-αI,则
Q=(I-P)-1≈I+P,
(12)
式(11)中A为对角矩阵,因此无需进行矩阵求逆即可计算出步长,进而降低了计算复杂度。迭代过程为
(13)
2.2 分布式求解
因所建图是kNN图,基于图的局部特性,上一小节提出的求解思路可用分布式的方式来实现。在分布式计算中,优化问题被分解为多个子问题并分配到计算节点上,此时复杂度较大的优化问题转换为多个复杂度较低的小问题。分布式计算可充分有效地利用计算资源,且能降低计算复杂度。分布式算法中,计算节点除计算能力外,还具有一定的通信与存储能力,且每个节点都已存储了图节点的邻居信息与已知标签信息。计算节点可存储多个图节点信息,在此假设一个计算节点仅存储一个图节点,则式(6)可转换为
(14)
其中,fj、yj分别为f、y在图中第j个节点上的值。显然,式(14)的前半部分即为式中匹配项的分解,将匹配项分解为N个相互独立的部分并分配到每个节点上。分解后,节点i上的一阶梯度信息为
(15)
其中,wij为Wn中第i行j列的元素,在图上则对应节点i与节点j之间的权重值。由此,节点i上进行的第k次迭代则为
(16)
在迭代完成后,所有节点输出的fi便可组合为one-hot编码矩阵F的对应列。通过式(15)与式(16)可看出,节点i在迭代过程中仅需获得其周边邻居上f、e以及u的值即可完成迭代。对于节点i,分布式算法如下:
while (j≤c) do
令y=Y:,j,k=0,f0=0,f1=1
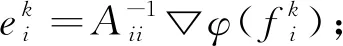
4)计算
6)计算步长

end while
令Fij=fi;
end while

对算法过程分析可知,每个节点在一次迭代过程中需要与周边邻居节点进行3次通信。
3 仿真结果与分析
对Kennedy Space Center(KSC)与Indian Pines数据集[22]进行分类仿真。KSC数据内有202个波段图片,可分为13类,类别分布不平均。Indian Pines内保留了200个波段数据,图片内像素分为16类,其类别分布更不平均,各类样本数差距更大。
仿真时,设置单样本已知个数分别为5、10、15、20,IndianPines的第7与第9类的已知数据最多为10个,且每种设置下均随机生成30组待学习数据,最后将30组数据的学习结果取平均作为最终结果。参数的设置如表1所示。为了更好衡量分类效果,仿真使用总体精度(OA)、平均精度(AA)以及Kappa系数三者的平均值作为评价指标。

表1 参数设置
图2、3分别为不同算法在不同数据下的OA曲线。从图2可看出,在KSC数据中,本算法的分类效果与文献[19]算法大致相同,优于文献[20]中算法。从图3可看出,在Indian Pines数据中,本算法结果与文献[19]中算法一致,且明显优于文献[20]算法的结果。

图2 KSC数据下不同算法OA曲线

图3 Indian Pines数据下不同算法OA曲线
表2与表3分别为在各类已知样本数为15的情况下,各算法在不同数据下的运行时间和各项分类评估参数。由于在不同已知样本数下的结果分布一致,仅选取数量为15的仿真结果。由表2可看出,在KSC数据中,本算法比文献[19]算法所用时间大大减少,虽然耗时高于文献[20]算法,但本算法各项评估参数都表明分类效果要更好。而表2表明,在Indian Pines数据中,本算法的分类效果远超文献[20],且所消耗的计算时间与文献[20]几乎一致。文献[19]算法基于各类样本分布均衡,且类别数较少的前提,因此会在Indian Pines数据中出现分类效果恶化的情况。
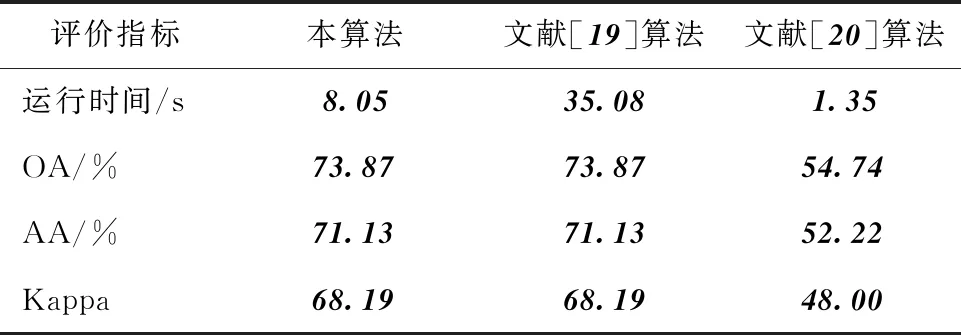
表2 KSC数据仿真结果

表3 Indian数据仿真结果
图4、5分别为本算法在不同数据下分类时的迭代情况。由于在每个类别迭代的趋势一致,任选其中一条做展示。通过2图可发现,本算法在不同数据下均能较快收敛。而由之前算法分析可知,本算法每步的迭代都需要与邻居进行3次通信才能完成信息交换。显然,该算法以单步迭代的多次通信换取了较快的迭代速度。

图4 KSC数据分类迭代曲线
以上2个数据的仿真结果及算法分析表明,本算法在数据量较大时更能体现出其优势,更适合数据量较大、类别数较多的HSI分类任务。

图5 Indian数据分类迭代曲线
4 结束语
针对HSI分类中未标记数据多、数据维度高、计算复杂度高等问题,提出一种基于图模型的分类算法,且该算法可以分布式运行。该算法把分类任务归结为一个无约束的优化问题,首先对优化问题进行拆分,并将拆分后的子优化问题分配到各个节点上,再用多计算单元对小优化问题迭代求解。仿真结果表明,本算法在数据规模大、类别多的分类任务下具有较大优势。后续工作将通过把图信号处理理论应用到数据建模中,克服其对于样本数分布不均衡的局限性,使其能更好地处理HSI分类问题。
猜你喜欢
数理化解题研究·综合版(2021年11期)2021-12-22
小学教学研究(2021年5期)2021-09-29
课程教育研究(2021年27期)2021-04-13
初中生世界·九年级(2020年2期)2020-04-10
现代电子技术(2018年18期)2018-09-12
软件导刊(2018年4期)2018-05-15
电脑知识与技术(2018年35期)2018-02-27
读与写·教育教学版(2017年10期)2017-11-10
科学家(2017年12期)2017-08-10
南都周刊(2015年4期)2015-09-10
