
水文预报业务非结构化数据库选型探索
2022-10-27 02:18陈真玄孟庆学
水利信息化 2022年5期
陈真玄,王 琳,张 怡,孟庆学
(1.水利部信息中心,北京 100053;2.北京金水信息技术发展有限公司,北京 100053;3.北京沛海科技有限公司,北京 100083)
0 引言
在大数据、人工智能时代背景下,水利信息化建设飞速发展,水利行业中产生了大量的多源异构数据,这些数据既包含了各业务积累的结构化数据,也包含了文本、图片等非结构化数据。
结构化数据主要基于关系型数据库存储,将业务数据保存到关系表中,便于查询统计且易于维护。而非结构化数据具有格式多样、内容繁多、读取速率高、实时性高、交换性强,以及规模性、多样性和高速性等特点[1],无法使用关系型数据库存储,目前只能通过不同文件形式存放。鉴于非结构化数据的特点,对非结构化数据进行存储、检索难度较大。
水文预报业务作为水利行业的核心业务,具有业务重要性高、时效性要求高、非结构化数据体量大等特点,如何更加高效地存储和处理海量非结构化数据,已成为水文预报业务亟待解决的难题。
1 水文预报业务非结构化数据的特点
水利部信息中心承担着国家防汛抗旱防台风的水文及相关信息收集、处理、监测、预警,全国江河湖泊和重要水库的雨情、水情、汛情及重点区域的旱情分析预报,水利部水旱灾害防御和水工程调度的相关技术支撑等工作。
近年来,我国洪水灾害频发且严重,水文预报业务工作已由过去为大江大河防汛指挥部署、洪水预报提供技术支撑,延伸到为水工程调度、山洪防治、城市防洪、台风防御、突发应急等众多领域提供关键决策支持,对水文降水预报的时效性、预报预见期、时空精准度都提出更高的要求。
数据是防汛决策的重要支撑,其中绝大部分数据是非结构化数据。水文降水预报非结构化数据的特点如下:
1)数据体量大。水利部信息中心每日接收和生成的各类气象信息总量达到500GB 以上,其中,每日接收各类气象数据450GB 以上(包括数值预报、气象卫星、天气雷达、气象水文观测等数据),每日处理生成各类雨情气象产品50GB 以上(包括雨情、形势场、卫星云图、雷达分析等产品数据)。
2)数据增长快。每日存入 Oracle 数据库中的数据量约为10GB,每年数据增量约为4TB;每日存入 NAS 上的气象业务产品数据量约为53GB,每年数据增量约为19TB;每日存入 NAS 上的气象监测原始数据量约为359GB,每年数据增量约为128 TB。
非结构化数据包括 FY4 在内的2颗高精度静止气象卫星观测和产品数据,70 多部天气雷达基数据和各类产品数据,欧洲、德国、美国等5家全球模式预报数据等。
2 水文预报业务非结构化数据的存储现状及需求
现有水文预报业务系统存储了大量的结构化与非结构化数据,采用关系型数据库+文件系统方案,主要是 Oracle 数据库结合 NAS 方案,即:结构化及非结构化索引元数据存放于 Oracle 关系型数据库中,非结构化数据(在线业务、原始历史数据)存放于 NAS 中。水利部水文预报业务数据库存储架构如图1所示。
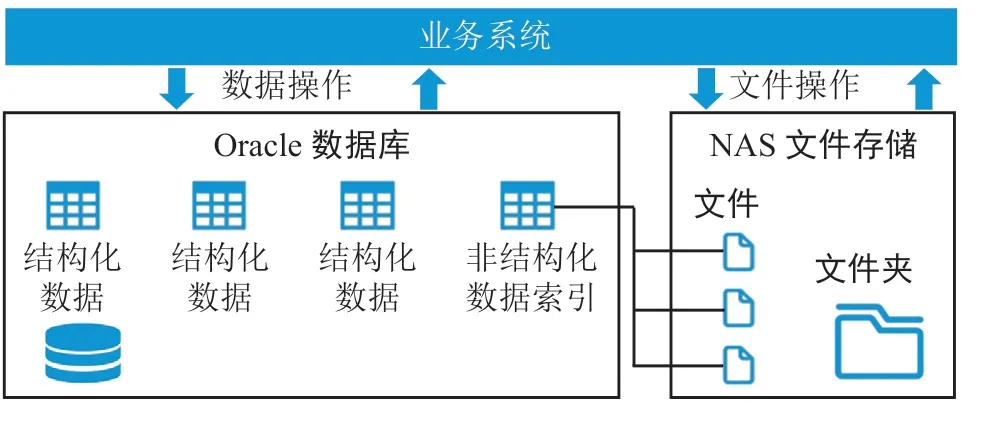
图1 水利部水文预报业务数据库存储架构
目前水利部现有水文预报业务系统在数据库存储方面面临着以下挑战:
1)Oracle 数据库非结构化数据量已接近50TB,接近集中式数据库数据存储的上限。
2)关系型数据库 + 文件系统方案查询效率低,特别在非结构化数据量不断增大的情况下,Oracle 数据库和 NAS 文件系统的性能随之下降,在高并发场景下会影响整体业务系统的响应时间。
3)结构化与非结构化数据难以统一管理,结构化与非结构化数据在业务上存在必然的联系,但底层 Oracle 数据库和 NAS 又各自独立,难以实现统一运维与管理,如统一生命周期管理,面向业务应用统一划分数据存储区域,统一备份归档/恢复等。
结合水利部水文降水预报业务的特点,需要将非结构化数据存储在数据库中,并且单个数据库系统同时支持结构化和非结构化数据,能够实现结构化和非结构化数据的统一存储、处理、管理、运维。
为满足水文降水预报业务数据库建设需要,现阶段要求数据库至少能支撑非结构化数据年增量22TB左右、实时运行容量100TB 左右;未来考虑到更高精度、更多模式计算的需求,要求数据库能支撑年存储增量700TB,3 a 数据存储需求约为2PB。因此,集中式数据库已不能满足要求,须选择可动态扩展的分布式架构数据库。
3 非结构化数据库主流技术路线
结合水文预报业务数据存储需求,能够支撑100TB 以上海量数据存储,并能实现单个数据库系统对结构化和非结构化数据统一管理的技术路线,主要有数据库结合 NAS、数据库大字段、多模数据库 3种存储方式。
3.1 数据库结合 NAS 方式
数据库结合 NAS 方式将结构化数据存放到数据库中,大量非结构化数据存放在 NAS 中,将 NAS 中的文件位置信息存放在数据库表字段中。应用系统在写入非结构化数据时,先将数据写入 NAS,然后将位置信息写入数据库表的文件位置列;读取非结构化数据时,先从表中读出文件位置信息,然后根据文件位置信息从 NAS 中读取数据进行处理。应用系统要分别读取数据库和 NAS 才能获取非结构化数据。
大部分数据库都支持数据库结合 NAS 方式,如 OceanBase 和 TDSQL 等数据库。以 OceanBase 数据库为例:OceanBase 数据库是完全自研的原生分布式关系数据库软件,可在普通硬件上实现金融级高可用,可实现“三地五中心”城市级故障自动无损容灾,具备卓越的水平扩展能力,集群规模可超过1500个节点。产品具有原生分布式、强一致性、高度兼容 Oracle/MySQL 等特性,OceanBase 数据库支持多模型,NoSQL 的 API 和 SQL 可以同时操作同一份数据[2]。
这种存储方式只存放文件位置信息,访问速度比较快,整个非结构化数据访问速度主要取决于 NAS 性能,而 NAS 在处理海量小文件时通常性能不佳。另外,由于数据分布在 NAS 和数据库2个系统上,数据的一致性容易出现问题。因此,此方式适合存储几十 MB 及以上的 FY4 气象卫星图像、GB 级的数值预报 DB-NWP 等大文件,且对数据一致性要求不高的场景。对于海量的、大小在几百 kB 的 GIS shp 等类型数据,读写性能较差,对时效性要求较高的应用不建议采用此方式存储。
3.2 数据库大字段存储方式
3.2.1 集中式数据库实现方式
目前大部分传统数据库都支持以大字段方式存储非结构化数据,典型产品如 Oracle 和 PostgreSQL等数据库。
以 Oracle 数据库为例:大对象(LOB)数据类型是 Oracle 数据库提供的一组数据类型,用于存储大的数据,如图片、文档和声音,可以由数据库有效使用和操作[3]。
Oracle 实现 LOB 字段存储有以下 3种方式:
1)storage in row inline 方式。将 LOB 数据存储在行内,访问方式同结构化数据,性能最好,最大支持3964个字节。
2)storage in row out-of-line 方式。将 LOB 数据存放在专门的 LOB 段上,在行内存储最大48字节的指针指向相应 LOB 段,需要额外1次 I/O 才能读取 LOB 字段。
3)disable storage in row 方式。在行内存储一个定位器,指向一个独立的索引段(B 树),索引的叶节点指向 LOB 段上的数据,可以支持非常大的 LOB 字段,但需要额外多次 I/O 才能读取 LOB 字段,性能最差。
LOB 字段内部结构如图2所示。

图2 LOB 字段内部结构
将非结构化数据存储在数据库中,可以通过SQL 进行处理,充分利用数据库的性能、事务、安全等能力,可简化系统架构,降低应用开发成本。但传统数据库设计目标更倾向于处理结构化数据,非结构化数据处理并非重点,因此不适合处理大量非结构化数据。例如:Oracle 数据库在高并发写入 LOB 字段时,如果字段没有设置 cache 属性,则性能不佳,但设置 cache 属性又会给 buffer cache 带来很大压力。另外,Oracle 等集中式数据库可扩展性不强,通常数据库容量在几十 TB 左右,超过50TB 后性能和运维将会面临极大挑战。
3.2.2 分布式数据库实现方式
对于几十 TB 及以上的非结构化数据处理可采用分布式架构数据库实现,典型产品如 TBase,GoldenDB,AntDB 等数据库。
以 TBase 数据库为例:TBase 数据库具备高扩展性、高 SQL 兼容度、完整的分布式事务支持、多级容灾及多维度资源隔离等能力,采用无共享的集群架构,将数据按分片键划分为多个分片,分布到多个数据节点(DN),具有更好的扩展性,适用于 GB~PB 级的海量 HTAP 场景[4]。
TBase 数据库使用 bytea 和 text 类型存储非结构化数据,元组不能跨页,较长数据采用 TOAST(The Oversized-Attribute Storage Techniques)存储。TOAST 有多种策略实现压缩、线外存储等功能,TOAST 表上 chunk_id 和 chunk_seq 列建有索引,可快速读取数据。
TBase 数据库支持1GB 以下非结构化数据写入、读取、删除,但超过1GB 的非结构化文件需要通过程序拆分后进行存储[5]。
针对水文降水预报业务场景,对 TBase 数据库进行了性能测试,测试环境为2台鲲鹏920服务器,配置为64核 ARM 架构 CPU、190 GB 内存、SAS 硬盘、千兆网卡,非结构化数据写入读取测试结果如表1所示。
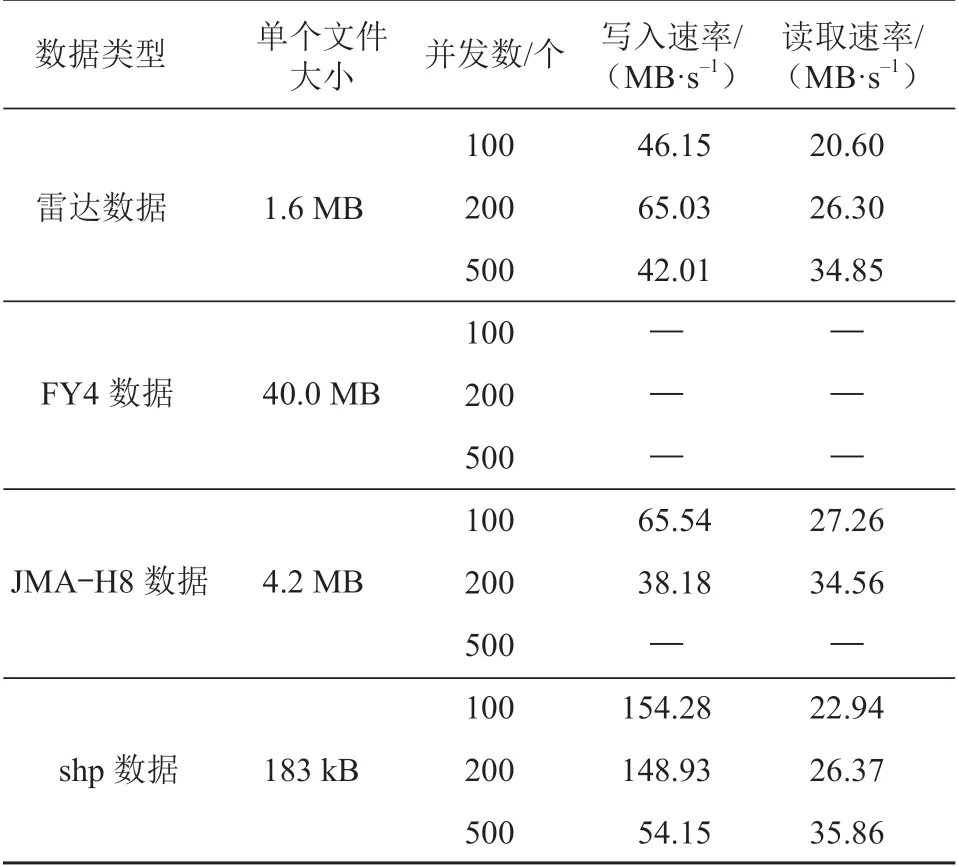
表1 TBase 数据库性能测试结果
数据库大字段提供多种灵活的存储方式,以适应不同大小的非结构化数据,既能存储 kB 级的 GIS shp 数据,也能存储 MB 级的 FY4 卫星图像。得益于可扩展的分布式架构,数据处理的时效性较好,在几百个并发的情况下,单个文件的平均读写响应时间大部分在 ms 级。
不论是传统的 Oracle 数据库还是分布式的 TBase 数据库,其重点还是处理结构化数据,对于 GB 级的 DB-NWP 数值预报等需要拆分,且不是主要处理的数据类型,不推荐采用此方式存储。
3.3 多模数据库存储方式
MongoDB 等非结构化数据库对文档等数据具备很好的处理、存储能力,但不支持 SQL 和关系表,而支持 SQL 的大部分关系型数据库不擅长处理非结构化数据,多模数据库能很好地融合、处理结构化和非结构化数据。
多模数据库内置多个不同引擎以处理不同类型的数据,将多种类型的数据集中统一存储,如使用对象、KV 等引擎处理非结构化数据,使用关系引擎处理结构化数据。这种方式可简化应用系统架构,降低系统开发、运维成本。典型产品如巨杉、ClickHouse 等数据库,广义上,Oracle 等数据库支持非结构化数据模型也属于多模数据库,本研究多模数据库只限于通过多个引擎实现的多模数据库。
以巨杉数据库为例:巨杉数据库是新一代国产原生分布式数据库,采用多模数据库存储引擎,实现结构化、半结构化、非结构化数据的统一存储管理,同时支持结构化的 MySQL、非结构化的MongoDB 等实例,业务场景覆盖联机交易、海量数据中台、分布式内容管理、在线数据服务等方面。
巨杉数据库对图片、音频和视频等非结构化数据采用 LOB 存储。每个 LOB 有1个 OID(Object Identifier)标识,LOB 数据由 LOBM元数据和LOBD 数据 2种文件组成。1 个 LOB 数据被均匀切分为若干个页(4~512 kB)存放在 LOBD 文件中,每个页有1个 ID。LOBM 文件包括 LOBD 文件的页分配情况和数据页 ID 的散列桶,用以查找数据页。当 LOB 写入时,数据切分为页,根据 OID 和页 ID 将每个页散列到多个分区,每个分区再次进行散列决定散列桶的位置,然后将数据写入最近空闲页,将页 ID 写入分配的散列桶;读取 LOB 时,根据OID 及读取区间,确定相应页,从分区中根据散列桶位置读取数据,最后按顺序合并返回[6]。
由于每个 LOB 数据被切分为若干个块并打散到多个分区,分布到所有数据节点[7],因此可以充分利用集群能力进行并发处理,吞吐量可以随着集群的扩充几乎无限增长,如果硬件可以支持,理论上可以存放近乎无限数量的对象文件。
针对水文降水预报业务场景,对巨杉数据库进行了性能测试,测试环境同 TBase 数据库测试环境,测试结果如表2所示。
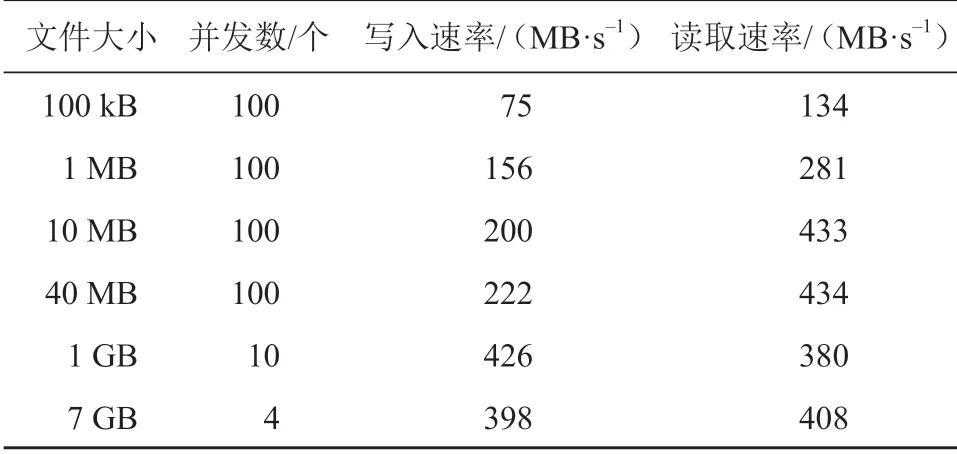
表2 巨杉数据库性能测试结果
测试结论如下:
1)巨杉数据库的 LOB 数据(文件)写入和读取性能很高,尤其是数值预报 DB-NWP 等稍大的文件,在几百个并发情况下,单个文件的平均读写响应时间大部分在 ms 级,最终性能瓶颈是网络带宽。如果增加压力机数量,可以有效提升总体吞吐量。
2)对于 GIS shp、雷达等数据较小的文件,由于网络交换次数较多,测试程序效率不高,限制了最后的性能表现。如果硬件环境提升,继续提高并发度,小文件的写入和读取总体吞吐量依然可以大幅度提升。
3)得益于多引擎架构,MongoDB 引擎可以高效存储、处理半结构化文档数据。从数据复杂度看,巨杉等多模数据库能很好地将结构化、半结构化数据和不同大小的非结构化数据融合在一起,实现复杂数据的统一管理。
总体而言,巨杉数据库的 LOB 数据写入和读取性能很高,可较好地满足时效性要求。数据库性能主要受服务器硬件及网络环境制约,各种制约因素中,网络带宽、磁盘类型和数量是最主要因素。
4 水利非结构化数据库选型建议
结合水利部水文预报业务非结构化数据库选型探索,建议水利行业非结构化数据库选型如下:
1)对于数据查询效率要求不高、不需要结构化与非结构化数据统一管理及联合查询的场景,可以选择数据库结合 NAS 的存储方式。
2)对于以结构化数据为主、非结构化数据为辅的场景,可以选择数据库大字段存储方式,其中:非结构化数据量不大的业务可以选择 Oracle 等传统关系型数据库,数据量几十 TB 以上的可以选择TBase 等分布式关系型数据库。
3)对于以非结构化数据为主,非结构化数据体量较大的,且对非结构化数据处理性能要求较高的场景,建议选择巨杉等多模数据库存储方式。
5 结语
根据对 3种类型非结构化数据库的分析和相关性能测试,结论如下:对于水利行业中单纯处理非结构化数据的场景,NoSQL 数据库可满足需求;对于类似水文预报业务,具有100TB 以上数据量、结构化与非结构化数据混合存储、非结构化数据占比较高的场景,目前数据库大字段和多模数据库是比较好的方案;随着 NewSQL 等新数据库技术的不断发展,未来会有更多适合同时处理海量结构化和非结构化数据的数据库出现,需要进一步探索研究。
猜你喜欢
湖南电力(2022年3期)2022-07-07
区域治理(2021年13期)2022-01-01
陕西档案(2021年2期)2021-05-21
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
制导与引信(2017年3期)2017-11-02
黄河黄土黄种人·水与中国(2017年2期)2017-03-16
燕山大学学报(2015年4期)2015-12-25
