
基于数据增强视觉Transformer 的细粒度图像分类
2022-11-11 11:31胡晓斌彭太乐
西华大学学报(自然科学版) 2022年6期
胡晓斌,彭太乐
(淮北师范大学计算机科学与技术学院,安徽 淮北 235000)
与传统的图像分类不同,细粒度图像分类(fine-grained vision classification,FGVC)是指将下级类别分类到基本类别下,例如鸟和狗的种类、飞机和汽车的型号等。由于类内差异较大以及低类间方差,属于同一类别的物体经常呈现出完全不同的形态,不同类别的物体之间也可能非常相似。其次,由于训练数据的局限性,对细粒度类别进行标记通常需要大量的专业知识,因此细粒度图像识别被认为是一项更具挑战性的任务。
大多数先前的工作[1-4]是使用卷积神经网络(convolutional neural network,CNN)作为主干网络来提取图像中的细微特征。但是此类方法随着网络层数的加深,计算复杂程度增大,在提取深层的特征时容易受到非特征区域噪声的干扰。近年来,Transformer 在一般图像分类[5]、图像检索[6]和语义分割[7]方面都展现出了优越的性能。视觉Transformer(ViT)[5]通过其固有注意力机制能够自动识别出图像中有判别性的特征区域,在图像分类领域证明了自身巨大的潜力。然而,ViT 无法直接在FGVC 上发挥其优势,例如,ViT的感受无法有效扩展,其像素块标记的长度不会随着编码器层数的增加而改变。此外,ViT 输入固定大小的像素块不利于网络捕获关键性的区域注意力信息。
本文提出一种新颖的数据增强视觉 Transformer(DAVT)用于细粒度图像分类。它能够汇聚各个层级有判别性的特征信息并进行分类,其层级注意力选择HAS 通过在各个层级之间筛选关键标记并融合,以补偿局部和层级之间缺失的信息。其次,本文还使用注意力引导的图像裁剪来减少固定大小像素块带来的部分噪声干扰,增强图像表达关键特征的能力。
1 相关工作
1.1 细粒度图像分类
目前主流细粒度分类的方法有基于定位的方法[2-4,8]和特征编码方法[9-11]。前者利用注意力机制、聚类等手段来发现区别性区域。后者则是通过计算高阶信息来捕获更多区域细微的特征。
强监督定位的方法需要昂贵的人工标注,而弱监督定位的方法不需要部件标注,仅通过分类标签即可完成训练;因此,弱监督定位的方法受到了更多的关注。注意力机制的诞生进一步提升了弱监督图像分类的性能,主流的分类模型更加聚焦于多样的注意力引导的方法。CAL[2]利用反事实干预促使网络学习更多的注意力区域。特征增强和抑制方法[3]则通过对关键部分和局部区域进行增强或抑制,以迫使网络挖掘潜在的信息。基于特征编码的方法专注于捕获细微的局部特征,以提高分类精度。构建对比输入批次的方法[9]通过计算不同特征之间的线索,从而加强特征包含判别信息的能力。而跨层双线性池化[12]则通过捕获层间局部特征关系,以提高多个跨层双线性特征的表示能力。本文将基于注意力机制的图像增强方法扩展到Transformer 中,利用数据裁剪擦除无关的图像噪声,达到特征增强的效果。
1.2 Transformer
随着Transformer 在计算机视觉领域取得突破性进展[5,13-14],图像识别也在Transformer 的基础上迎来了新的热潮。ViT 是第一个采用纯Transformer结构的图像分类模型。它包含嵌入层和编码器,编码器由多头自我注意力机制(MSA)和多层感知模块(multi-layer perceptron,MLP)组成。训练时,嵌入层将图像分割成固定大小的像素块,并将其输入Transformer 的编码器进行分类,像素块依次通过MSA 和MLP 进行训练和分类。最终,ViT 利用最后一个编码器层的第一个标记作为全局特征的表示,并将其转发给MLP 模块的分类器头以获得最终分类结果,而不考虑存储在其余层标记中的潜在信息。为解决ViT 潜在的问题,AFTrans[15]通过自适应注意力多尺度融合Transformer 来捕获区域注意力。文献[16]提出了一种峰值抑制模块惩罚最具判别性的区域来学习不同的细粒度表示。TransFG[17]和FFVT[18]分别将ViT 扩展到大规模和小规模FGVC 数据集。然而,这些工作忽略了层级之间的部分局部特征和固定大小的像素块带来的噪声影响。受到FFVT 模型的启发,本文将关键标记筛选延伸到ViT 模型的各个层级,使用层级交叉相乘的方法逐层提取局部特征,更加强调各个层级之间的标记关联性。
2 数据增强Transformer 的分类方法
由于ViT 网络模型深层的输入标记难以关注图像局部的细微特征,也很难聚集各层级之间的重要标记信息。针对这一问题,本文提出层级注意力选择和数据增强的方法强制网络选择判别性的标记信息以弥补各个层级之间缺失的特征信息。将增强后的图像从新输入网络进行循环,促使网络生成多尺度特征对判别区域进行学习。DAVT 总体结构如图1 所示。
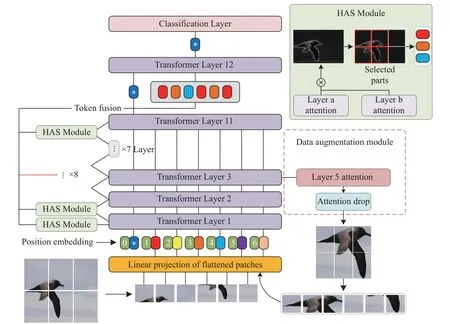
图1 DAVT 网络框架图
2.1 层级注意力选择机制
原始ViT 中经过嵌入层的标记信息判别性较弱,由于固定大小的像素块引发的噪声影响,高层次的输入标记不一定能保留原始标记相对重要的特征信息。为此,本文提出了层级注意力选择机制,将层级间的注意力权重融合并对标记进行筛选。DAVT 网络模型中前几层的注意力权重表示为:

式中:K表示模型中多头自我注意力机制中自我注意力头的数量,l表示模型的层数,但仅依靠自我注意力头部和尾部在各个层级内部提取标记信息,容易造成层级间的部分局部信息的遗漏,为了充分利用各个层级间的标记信息,通过如下方式整合层级间的注意力权重:
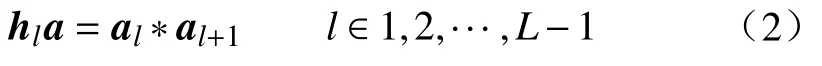
式中:hla代表第l层融合后的注意力权重。将此方法应用于除去最后一层的所有Transformer 层。具体来说,通过将第l层和第l+1 层的注意力权重通过矩阵乘法进行融合,其中l∈(0,L-1)。随后利用Max()函数选取K个不同注意力头的最大值指标A1,A2,···,AK,这些位置被用作模型的索引,以提取层级之间判别性的标记。使用HAS 方法选择的关键标记表示为
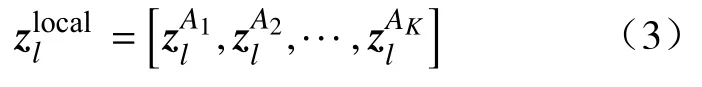
式中:AK表示注意力权重选定特征的数量。最后,将分类标记连接到各层筛选后的判别性标记,融合后输入最后一个Transformer 层进行分类,此过程可表示为
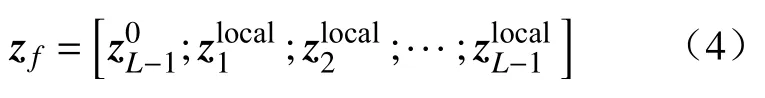
层级注意力选择方法直接聚合各层级之间判别性标记,并将分类标记和融合后的标记作为输入连接到最后一个Transformer 层,不仅保留了各个层级间的本地信息,还充分利用层级间的注意力权重,捕获丢失在深层的局部信息。
2.2 注意力引导的数据增强
在训练过程中,ViT 将原始图像分割成固定大小的像素块,随着数据量的增加,像素块带来的图像噪声也会增加。例如:某一个像素块中,没有鸟的头部、翅膀、颈部等关键信息,只有天空、云等环境背景信息。注意力引导的数据增强能削弱图像噪声带来的影响,并增加训练部分的数据量。
训练过程中,通过ViT 中多头自我注意力机制生成的第 ξ层的注意力图aξ来指导数组增强的过程,并将其归一化为,使其更具有代表性。归一化过程如下:


目的是寻找能覆盖整个Ck选定的Mask(元素值为1)区域的最小边界框,用该边界框裁剪原图,并放大到原始图像大小作为增强后的输入数据。由于对象部分的比例增加,因此模型能更好地定位对象位置,方便提取更具有判别性的特征。
由于引入了数据增强后的新图像,因此,在训练阶段,损失函数由多个部分组成。其表示为
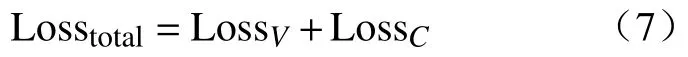
式中:LossV、LossC分别表示原始图像的交叉熵损失以及注意力裁剪后的交叉熵损失。这两种损失在反向传播过程中共同作用,从而优化模型的性能。
3 实验
本文在CUB-200-2011[19]、Stanford Dogs[20]数据集上对模型进行评估。CUB-200-2011 是一个关于鸟类的数据集,它包含11 788 张鸟类图片,其中训练集、测试集分别包含5 994 张和5 794 张图片,共计200 个鸟类类别。Stanford Dogs 包含来自世界各地的120 种狗类的图片,其中训练集、测试集分别包含12 000、8 580 张图片。两个数据集不仅包含图像标签,还包含边界框和零件注释。实验中使用Top-1%表示细粒度图像的分类的准确率,利用损失函数的变化率来测试训练过程是否发生过拟合。
3.1 实验细节
在所有实验中加载官方在ImageNet21k 上进行预训练的ViT-B_16 模型的权重对网络进行训练,将原始图像大小调整为448×448 并对图像进行分割,使其变为16×16 的像素块。每个数据集的训练周期设置为10 000。实验采用随机水平翻转对图像进行数据扩充。在训练阶段,使用随机梯度下降(SGD)以0.9 的动量值来优化网络,初始学习率设置为0.02,使用余弦退火对学习率进行有序调整。批处理大小设置为6。超参数K的值设置为12,超参数ζ设置为5。使用Pytorch 框架作为实验平台,通过APEX工具包以FP16 的数据格式加速训练。本文使用单张NVIDIA TESLA T4 显卡进行实验。
3.2 实验结果及对比分析
本文在CUB-200-2011 和Stanford Dogs 数据集上对DAVT 进行了消融研究,以分析所提出的方法对细粒度分类精度的影响。如表1 所示,通过使用层级注意力选择(HAS),使模型在两个数据集上的性能分别得到了1.1%和0.7%的提升,因为HAS 以各个层级之间的注意力权重作为引导,筛选出有判别性的标记并丢弃一些不重要的标记,迫使网络从重要部分进行学习。通过引入数据增强模块,使得模型再次提升了0.3%和0.5%的准确率,这是因为注意力裁剪后的图像去除了部分背景噪声。数据增强的方法在提高分类精度的同时引入了新的增强图像,因此在训练过程中随着训练数据的增加,参数量和分类时间都会不同程度地增大。

表1 CUB-200-2011 和Stanford Dogs 数据集下的消融研究
表2 展示了不同Transformer 层注意力图引导的数据增强在CUB-200-2011 数据集上的效果。ζ表示以第几个Transformer 层的注意力图作为引导。由表2 可知,选择第5 层注意力图作为引导时效果最佳,随着层数逐渐降低或升高效果均变差,因为层数偏低或偏高时,容易造成选择的特征停留在低级或偏高级的局部区域。因此,选择中间部分的Transformer 层提取注意力图,以获得较为均衡的特征信息。
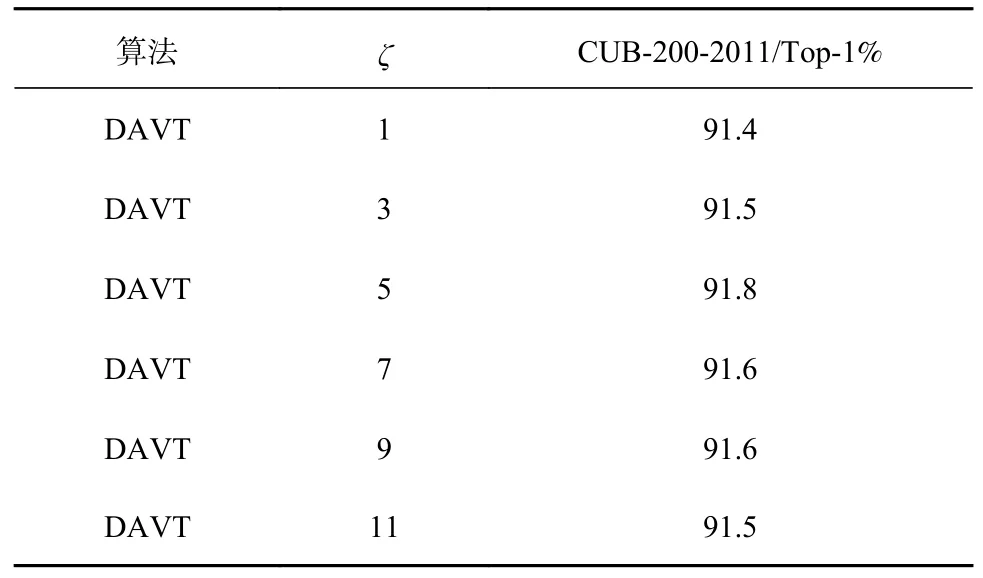
表2 CUB-200-2011 数据集下注意力提取层ζ 的消融实验
如表3 所示,本文的方法在CUB-200-2011和Stanford Dogs 数据集上的性能优于所有以ViT和卷积神经网络为底层网络的方法。在CUB-200-2011 数据集上与迄今为止最佳算法相比,DAVT在Top-1%指标上实现了0.2%的提升,与原始框架ViT[5]相比,提高了1.4%。在Stanford Dogs 数据集上与迄今为止最佳结果相比,DAVT在Top-1%指标上实现了0.4%的提升,与原始框架ViT 相比,提高了1.6%。与其他主流的CNN 相比,DAVT在两个数据集上的性能也有大幅提升。此外,为了探究不同类别样本特征表示之间的距离对模型性能的影响,本文对比了模型在不同损失函数下的性能,如图2 所示。
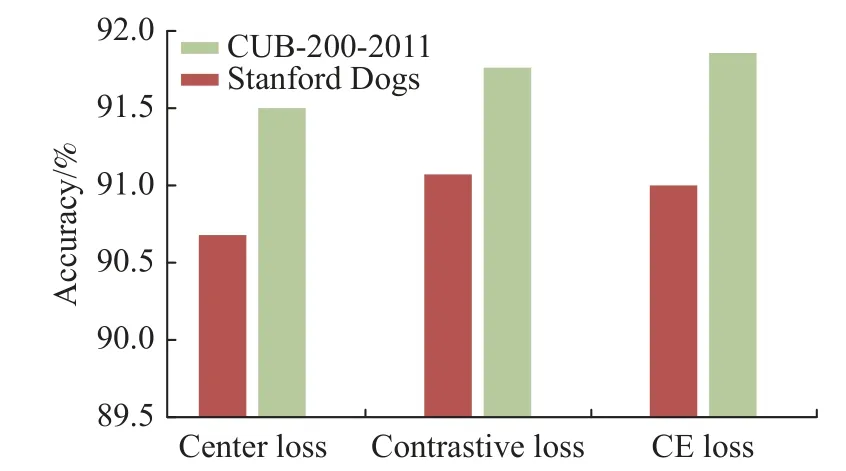
图2 损失函数对比图
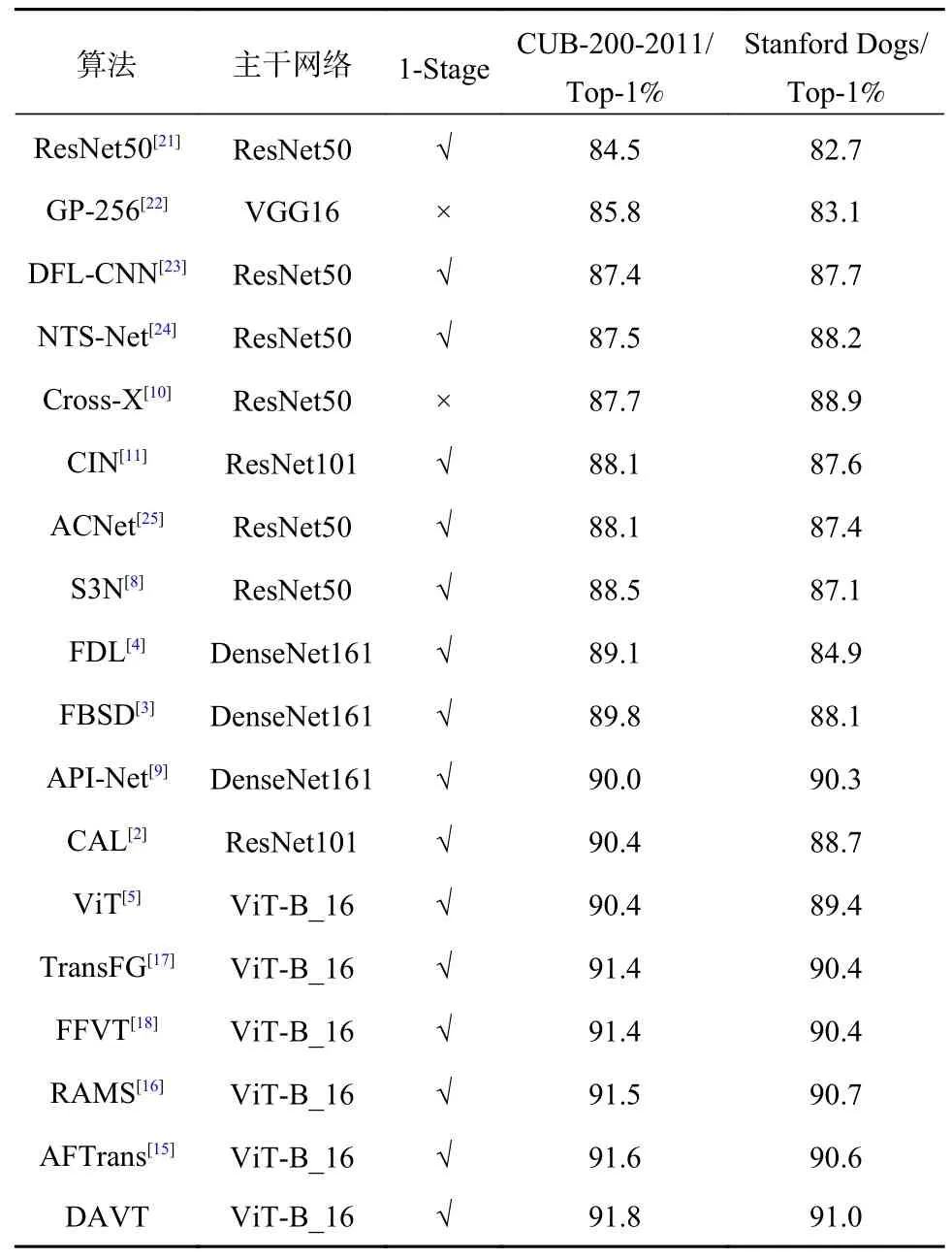
表3 CUB-200-2011 和Stanford Dogs 数据集下不同算法的比较
通过在两个常见的FGVC 数据集上对模型进行评估,将本文方法与现有的Transformer 分类方法相比,DAVT 的性能优于现有的以ViT 模型为底层网络的方法,如图3 所示。
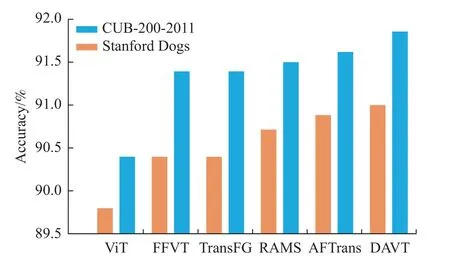
图3 最先进算法的性能对比
图4 为损失和准确率的变化曲线。橙色曲线表示损失和准确率的变化趋势。曲线由Tensorboard生成,浅色部分代表真实数据的曲线。本文通过改变平滑系数获得一条深色曲线,以更好地展示准确率和损失的变化。如图4(a)和图4(b)所示,所提方法在两个数据集上的训练损失都能稳步降低。由于使用预训练ViT-B_16 模型的权重训练网络,测试精度在前2 000 个周期得到了快速的改善,如图4(c)和图4(d)所示。同时,测试精度曲线无下降趋势,证明没有拟合现象发生。
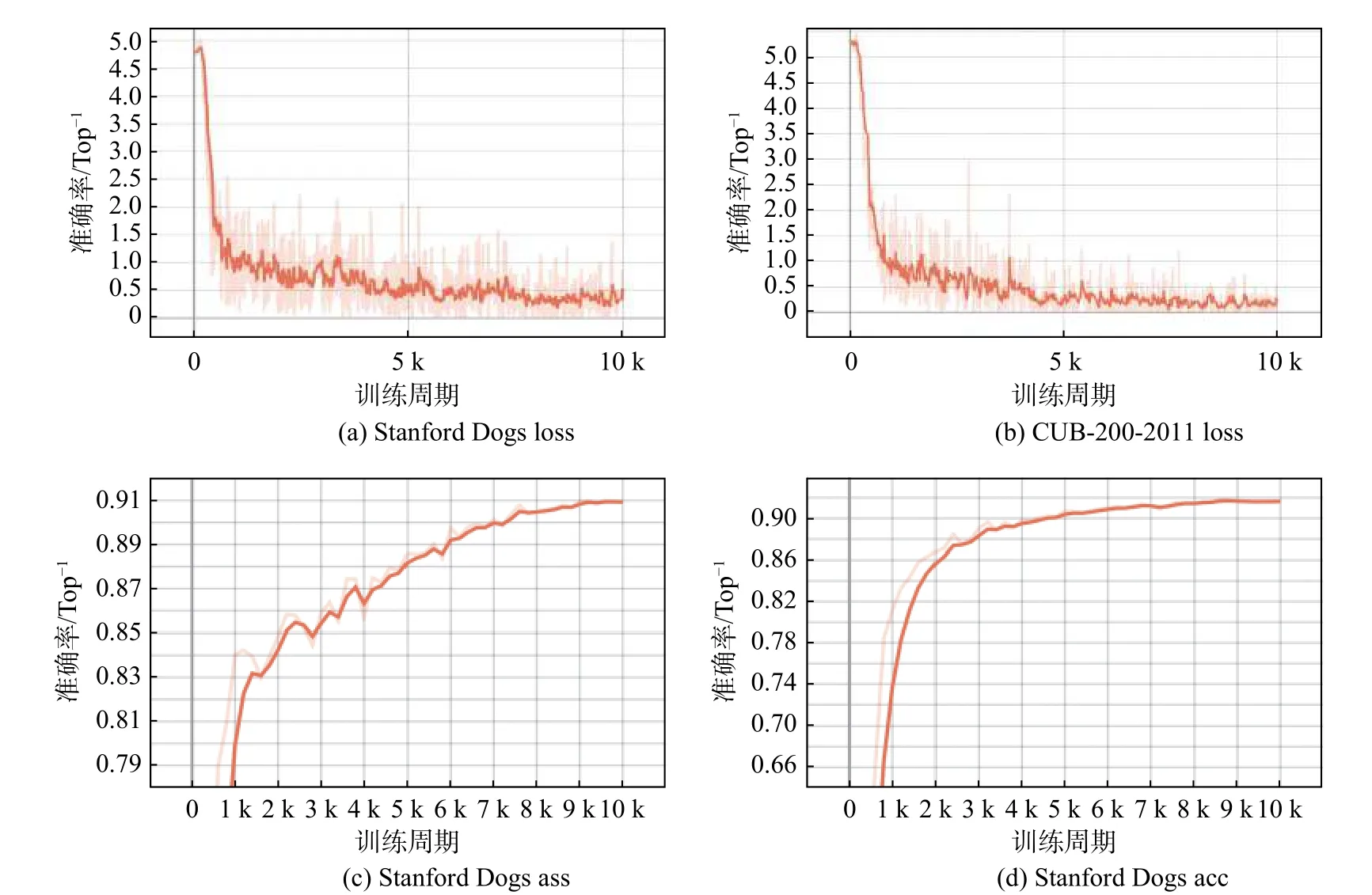
图4 CUB-200-2011 和Stanford Dogs 数据集下的训练损失和测试准确率
图5 显示了模型在两个数据集上的可视化结果。具体来说,图5 的第1 行展示了数据集的原始图像。第2 行显示了图像的注意力图,图中重要区域的颜色通过浅色表示。图5 的第3 行和第4 行显示了数据增强后图像。第4 行深色区域表示注意力裁剪的背景噪声,如图5 所示,注意力引导的图像裁剪能够去除绝大部分背景噪声。第3 行显示了裁剪后的图像,并对物体的关键区域进行了放大,促使网络提取更细微的局部特征。图5 的第5 行显示了模型定位的关键标记的位置,其中红色方框代表注意力强调的特征区域,它由Visualizer可视化工具生成。如图5 所示,在复杂的环境下DAVT 模型成功地捕捉到了物体的关键区域,即鸟类的头部、翅膀和尾巴和狗的耳朵、眼睛、腿。

图5 注意力可视化及数据增强的结果
4 结论
针对原始ViT 模型中输入的像素块引发背景噪声和无法有效地提取层级间细微特征的问题。本文提出了层级注意力选择和注意力引导的数据增强方法,减少了背景噪声对网络的干扰,迫使网络学习层级间判别性的特征信息。
猜你喜欢
红外技术(2022年11期)2022-11-25
中国典型病例大全(2022年13期)2022-05-10
小雪花·成长指南(2022年1期)2022-04-09
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
安阳工学院学报(2020年2期)2020-06-05
廉政瞭望(2019年5期)2019-06-10
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
传媒评论(2017年3期)2017-06-13
