
注意力金字塔卷积残差网络的表情识别
2022-11-20 13:57陈加敏
计算机工程与应用 2022年22期
陈加敏,徐 杨,2
1.贵州大学 大数据与信息工程学院,贵阳 550025
2.贵阳铝镁设计研究院有限公司,贵阳 550009
近年来人脸表情识别在情感分析方面的研究取得了较大的进步,成为情感分析的关键技术之一。面部表情中含有丰富的特征信息,Mehrabian等人[1]的研究表明,在人类的日常沟通与交流中,表情所占有的信息高达55%,而语言所占有的信息仅含7%。因此,高效地提取表情特征更有利于人机交互过程。面部表情是指通过脸部肌肉块的变化而表现出来的情绪,不同运动单元的变化产生了不同的情绪。Ekman等人[2]将表情分为愤怒、厌恶、惊讶、高兴、悲伤、恐惧。在其研究基础上,基于运动单元的面部动作编码系统(facial action coding system,FACS)被提出,FACS主要通过分析运动单元的运动特征来说明与之联系的相关表情。
人脸表情识别的关键步骤可分为图像获取、人脸检测、特征提取、特征分类。其中特征提取是人脸表情识别中最为关键的一步,直接影响表情识别的效果。Gu等人[3]提出了全局特征与局部特征相结合提高整体特征表现力的表情识别方法。Yan等人[4]将原始人脸图像与LBP图像结合,将其输入连续卷积提取高级语义特征,并将提取的特征进行下采样处理提高表情识别准确率。Zeng等人[5]建立了深度稀疏自编码(deep sparse autoencoder,DSAE),通过学习鲁棒性和判别性特征,实现了对人脸表情的高精度识别。亢洁等人[6]将特征分组并建立空间增强注意力机制,突出表情特征重点区域。柳璇等人[7]将灰度图、局部二值模式特征、Sobel特征进行融合提高特征表现力。由此可见,现有的深度学习模型大多从特征提取维度进行改进来提高表情识别准确率。
近年来,随着深度学习的不断发展,卷积神经网络在图像特征提取方面展现了显著的优势,可通过增加网络的深度或者宽度来提取更为高级的语义特征。Wang等人[8]通过增加卷积神经网络的深度和宽度来增强特征提取能力,将高层次与低层次的特征行融合,取得了较好的表情识别效果。不同的表情之间具有细微的差异信息,若模型只关注人脸表情的少数特征,就很可能预测出错误的类别。因此,融合多尺度特征尤为重要。具有竞争力的多尺度特征融合方法如下:早期的网络架构AlexNet[9]和VGGNet[10]通过堆叠卷积运算符,但是过度地堆叠网络的层数会出现梯度消失以及梯度爆炸[11-12]等问题;InceptionNets[13]通过使用不同内核大小的卷积,增加网络的宽度,提高多尺度特征提取的能力,增加宽度能在一定程度上提高效率,但是仍存在局限性,过度增加宽度会出现过拟合等问题;ResNet[14]通过使用残差模块的跨层连接有效地解决了网络梯度消失和梯度爆炸的问题,使得网络的层数可以达到上千层;金字塔卷积(pyramidal convolution,PyConv)[15]通过堆叠不同大小的卷积核扩大感受野,具备细化特征的优势,在图像分类、目标检测等图像识别的基本任务中都取得了显著的优势。注意力机制将关键部分分配较高的权重,SENET[16]作为最后一届ImageNet分类比赛的冠军,只是在通道维度上标注注意力权重;卷积块注意模块(convolutional block attention module,CBAM)[17]是一种从通道和空间维度进行双重特征权重标定的卷积注意力机制模块,其依据多方向的特征增强改善网络识别效果。
为了更好地提取面部表情中眼、眉、口等部位的局部变换特征,本文以残差网络为主要框架,融合金字塔卷积模块和CBAM模块中的通道注意力(channel attention,CA)以及空间注意力(spatial attention,SA),提出一种注意力金字塔卷积残差网络(attention PyConv ResNet,APRNET)。该网络分为两个子模块,分别是PyConv-CAblock和PyConv-CSneck模块,在网络中将PyConv-CAblock替换残差网络中的基础模块(basicblock),将PyConv-CSneck替换残差网络的瓶颈模块(bottleneck)。该网络将金字塔卷积、通道注意力和空间注意力融合在一起,在提取多尺度全局信息的同时有效地突出重点区域。实验证明该模型有效地提高了表情识别的性能,在CK+[18]和FER2013[19]数据集上准确率可达94.949%和73.001%,相比于现在的表情识别方法具有较大的优势。本文的主要贡献如下:
(1)在表情识别中,结合金字塔卷积的不同大小和深度的卷积核获取具有细节信息的全局特征,捕获面部表情图像的细微差异。
(2)嵌入通道注意力以及空间注意力机制模块来学习具有判别性的局部特征,突出了表情识别的重点特征区域。模型在公共数据集CK+和FER2013上进行实验,验证注意力金字塔残差网络的竞争性。
1 金字塔卷积
金字塔卷积(PyConv)包含不同大小和深度的卷积核,可提取多尺度信息。如图1所示,从Level 1到Leveln卷积核大小依次增大,深度依次减小,为了能够在PyConv的每个级别上使用不同深度的内核,借鉴分组卷积,如图2所示,将输入特性映射分成不同的组,并为每个输入特性映射组独立地应用内核。与标准卷积图3相比,标准卷积仅包含单一的核,卷积核的空间分辨率为K21,而深度则等于输入特征通道数FMi。那么执行FMo个相同分辨率与深度卷积核,得到FMo个输出特征。因此,标准卷积的参数量与计算量分别为:
金字塔卷积将输入的特征划分为不同的组独立地进行卷积计算。假设金字塔卷积的输入包含FMi个通道,PyConv每一层卷积核尺寸为K21,K22,…,K2n,深度为FMi,FMi/(K22/K21),…,FMi/(K2n/K21),对应的输出特征维度为FMo1,FMo2,…,FMon基于上述的描述,可以得出,金字塔卷积的参数量和计算量分别为:
FMo1+FMo2+…+FMon=FMo时,式(3)中每一行表示PyConv中某个Level的参数量和计算成本,如果每个Level输出相同参数量的特征映射,则PyConv的参数数量和计算代价沿每一级金字塔均匀分布。在这个公式中,无论PyConv的Level有多少,无论核空间大小K21持续增加到K2n,其计算代价和参数数量都与单个核大小K21的标准卷积相似。
2 本文方法
本文以ResNet网络作为基础网络,将通道注意力和空间注意力融入金字塔卷积模块,得到注意力的金字塔卷积残差网络。受文献[12]的启发,本文在PyConv之后依次加入通道注意力和空间注意力构成PyConv-CSblock和PyConv-CSneck模块,PyConv-CSblock由一个金字塔卷积、通道注意力、空间注意力以及1×1卷积构成,PyConv-CSneck由一个金字塔卷积、通道注意力、空间注意力以及两个1×1卷积组成,如图4所示。
在本文中,模型的框架分为4个Layer,每个Layer由不同参数的PyConv连接构成,根据参数的不同将其分为PyConv18和PyConv50,具体参数情况如表1所示。
若金字塔卷积提取的特征为F∈RH×W×C(H为高度,W为宽度,C为通道数),对其在通道和空间上分配注意力权重,使得所提取的人脸表情特征能够聚集于眼睛、眉毛、嘴巴等人脸表情的关键部位,提升表情识别的特征提取能力,从而提高表情识别的准确率。将模型APRNET应用于表情识别具体结构如图5所示(以APRNET50为例)。首先,使用一个7×7的卷积提取图像的特征信息。其次,参照ResNet的网络结构,用PyConv-CSblock替换ResNet中的basicblock,用PyConv-CSneck替换残差网络中的bottleneck,PyConv-CSblock和PyConv-CSneck中的PyConv提取多尺度特征信息,CA和SA分别在通道维度与空间维度分配注意力权重,获取具有判别性的局部细节信息,突出人脸表情关键部位的特征表现力。分别通过4个不同的Layer堆叠构成APRNET18和APRNET50,不同Layer的PyConv由不同尺度的卷积核堆叠而成,具体参数如表1所示,最后使用一个全连接层作为分类器进行表情识别。

表1 金字塔卷积模块参数Table 1 Pyramid convolution module parameters
2.1 融入通道注意力
在人脸表情识别中,表情与特定区域的特征有较大的相关性。金字塔卷积可以很好地将人脸表情图像中的特征提取出来,注意力模型可以提高特定区域特征的表征能力,聚焦重要的特征,抑制不必要的特征。为进一步提高表情识别准确率,本文将通道注意力融入金字塔卷积之后,将金字塔卷积所提取的特征在通道维度标注权重,提高了通道维度具有判别性的局部特征的表现力,通道注意力模块如图6所示。假设金字塔卷积提取的特征为F∈RH×W×C,首先将金字塔卷积特征经过最大池化以及平均池化后得到两个不同的空间描述特征Fcmax和Fcavg,然后将两个空间描述特征经过一个共享网络后将其相加得到通道注意力权重系数Mc∈RC×1×1,共享网络由包含一个隐层神经元的三层感知机组成,然后将Mc与F相乘得到通道注意力图。
其中,F为金字塔卷积输出的特征,σ为sigmoid操作,Mc为通道注意力权重。
2.2 融入空间注意力
空间注意力是对通道注意力的一个补充,利用特征间的空间关系生成空间注意图,如图7所示。首先利用池化操作的聚合功能在通道轴上应用最大池化和平均池化各生成一个有效的特征描述符,分别为F′max和F′avg,然后使用torch中的cat函数将两者进行横向拼接后将其放入7×7的卷积降为一个通道,在经过sigmoid生成空间注意力权重Ms∈RC×1×1,再将Ms与F′相乘得到F′。
其中,Ms为空间注意力权重,F′是经过通道注意力模块后的特征输出,F′是经过空间注意力模块后的特征输出图。
将空间注意力模块嵌入通道注意力之后,该方法可将金字塔卷积提取的特征依次在通道和空间维度推断注意力图,增强表情中具有判别性的局部特征的通道维度信息和空间维度信息,从而提高表情识别准确率。
3 实验结果及分析
本文对所提方法进行了对比实验验证,实验平台是Ubuntu16.04 LTS系统,实验环境python3.5,在深度学习框架PyTorch1.0上使用具有11 GB显存的NVIDIA GeForce GTX 1080Ti实现。本文在FER2013和CK+公开人脸表情数据集上对所提模型进行实验,并与之前的工作进行对比分析。
3.1 数据集与实验设置
本文选择FER2013、CK+数据集。FER2013数据集是由International Conference on Machine Learning(ICML)2013挑战产生,是目前较大规模的表情识别数据集,包含28 709张图片,7种表情分类标签,其中测试集分为公有测试集和私有测试集,数量均为3 589。CK+数据集包含从123个对象中提取的593视频序列,这些序列持续时间从10帧到60帧不等,展示了从中性脸表情到高峰表情的转变,选择带有标记的327个序列的最后3帧共981张图片。FER2013、CK+的像素值均为48×48,它们的数据分布图分别如图8所示。
3.2 模型性能分析
表2为本文所提方法在FER2013公有数据集(Public)和私有测试集(Private)上的实验结果。在训练过程中,数据的扩充采取随机裁剪以及水平翻转操作,其中裁剪大小为44×44,权重更新使用随机梯度下降,动量设置为0.9,初始学习率为0.1,从迭代50次开始每增加5次学习率以0.9的速率下降,总迭代次数为250。

表2 FER2013实验结果Table 2 FER2013 experimental result
PyConv18是将金字塔卷积模块融入ResNet18,PyConv18+CA是在PyConv18的基础上嵌入通道注意力,PyConv18+SA是在PyConv18的基础上嵌入空间注意力,APRNET18是在PyConv18的基础上同时嵌入通道注意力和空间注意力。
PyConv50是将金字塔卷积模块融入ResNet50,PyConv50+CA是在PyConv50的基础上嵌入通道注意力,PyConv50+SA是在PyConv50的基础上嵌入空间注意力,APRNET50是在PyConv50的基础上同时嵌入通道注意力和空间注意力。
将APRNET18、APRNET50在私有数据集测试结果用混淆矩阵表示,如图9所示。
从表2可以看出:APRNET18在私有测试数据集上表情识别准确率相比于PyConv18增加了2.953个百分点,相比于PyConv18+CA和PyConv18+SA分别增加了2.229个百分点和2.730个百分点。APRNET50在私有测试数据集上表情识别准确率相比于PyConv50增加了2.062个百分点,相比于PyConv50+CA和PyConv50+SA分别增加了1.198个百分点和0.139个百分点。本文所提出的APRNET50获得了较好的表情分类结果,达到73.001%。由此可见,本文选取金字塔卷积作为特征提取部分,能够获得较好的分类结果。这是由于金字塔卷积能够提取多尺度的细节特征信息,注意力模块能够提取具有判别性的局部特征,残差结构能够将层间的相关性很好地结合起来。
从图9可以看出,高兴和惊讶的表情识别结果明显高于其他,而悲伤、害怕、厌恶、生气的准确率较低,因为这四者在一定程度上存在相似的特征,在生活中,人眼也很难区分。其中害怕的准确率最低,出现这个问题的原因可能是数据集的分布不均匀,从数据分布图来看,害怕类的数据明显低于其他。
为验证本文所提网络模型的有效性,将FER2013私有测试集中训练的模型保存,并在网上随机选取图像运用该模型进行人脸表情识别,识别结果如图10所示。
3.3 对比实验
为证明本文所提方法的有效性,将本文所提模型应用于CK+数据集,结果如表3所示。在训练过程中,数据的扩充采取随机裁剪以及水平翻转操作,其中裁剪大小为44×44,权重更新使用随机梯度下降,动量设置为0.9,初始学习率为0.1,从迭代20次开始每增加5次学习率以0.9的速率下降,总迭代次数为100。

表3 CK+实验结果Table 3 CK+experimental result
从表3可以得出,APRNET18相比于PyConv18的识别准确率提高了3.535个百分点,APRNET50相比于PyConv50的识别准确率提高了5.050个百分点。
为进一步说明本文所提方法的有效性,选取了近几年最新的表情识别算法在FER2013上进行对比分析,这些方法包括SHCNN[20]、Zhou[21]、Gan[22]、Parallel CNN[23]、CNN[24]、Liang[25]。文献[20]通过一个含有三个卷积层的浅层网络来抑制过拟合以及梯度爆炸等问题,在训练FER2013数据集时采用0.001的学习率;文献[21]通过对Softmax函数的改进来提取更加具有区分力的特征,在训练过程中动量设置为0.9,权值衰减为0.000 5,批处理大小为512,初始学习率设置为0.1;文献[22]在卷积层嵌入注意力模块进行识别;文献[23]设计两个并行卷积池化结构,并行提取三种不同图像特征;文献[24]在VGG的基础上卷积核的大小从3改为8,一种卷积核的数量设置为固定值32,另一种卷积核的数量设置为变量,分别为32、16、8,通过对卷积核大小和数量的更改提出了两种网络结构;文献[25]将深度可分离卷积和压缩激发模块相结合,提出了一种轻量型的卷积神经网络结构提取特征,在训练过程中批处理大小为32,初始学习率为0.1。将文献[26-28]的结果与本文所提方法在CK+数据集进行对比。文献[26]提出了一种新的人脸表情识别方法,该方法利用图像预处理技术去除不必要的背景信息,并将深度神经网络ResNet50与传统的支持向量机多类模型相结合进行人脸表情识别;文献[27]提出一个重点发现感兴趣区域的表情识别框架;文献[28]提出一个新的DNN模型识别表情。对比结果如表4所示。
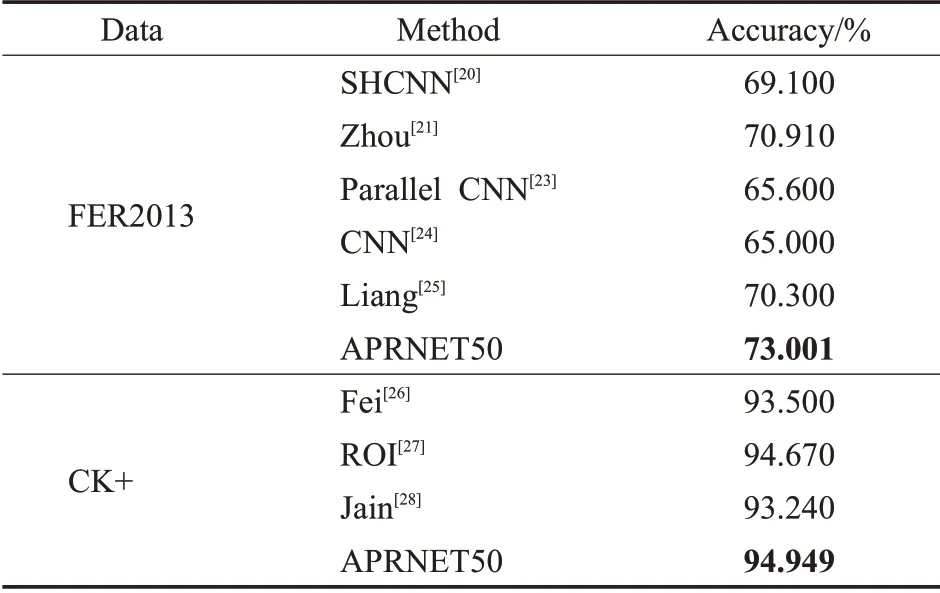
表4 对比结果Table 4 Comparison result
从表4可以看出,本文所提的方法在FER2013数据集上比CNN方法提高了8.001个百分点,比Zhou等人所提的方法也高出了2.091个百分点,在CK+上识别准确率相比于Fei提高了1.499个百分点,相比于ROI提高了0.279个百分点,相比于Jain提高了1.709个百分点。可见本文方法的识别准确率具有竞争性的优势。
4 结束语
本文提出了一种新的网络模型APRNET50用于人脸表情识别,该方法可以实现多尺度特征融合以及定位人脸表情的关键部位。其中金字塔卷积可以很好地提取多尺度特征信息,注意力模块可以定位人脸的关键部位,充分地利用关键部位的详细信息对于人脸表情识别来说尤为重要。以端到端的方式在公开人脸表情数据集FER2013以及CK+上设计了对比实验来评估本文模型,结果表明,本文方法有效地提高了表情识别的效率。
接下来,将考虑如何将特征深入地进行融合,以及对表情识别进行深入的研究,将本文方法应用到现实场景中进行表情识别,以提高表情识别的利用率。
猜你喜欢
环球时报(2022-09-19)2022-09-19
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
考试与评价·七年级版(2020年4期)2020-10-23
小学教学研究·新小读者(2017年9期)2017-10-25
