
融合混沌对立和分组学习的海洋捕食者算法
2022-11-20 14:00曾国辉
计算机工程与应用 2022年22期
马 驰,曾国辉,黄 勃,刘 瑾
上海工程技术大学 电子电气工程学院,上海 201600
随着人工智能技术的发展,优化求解问题越来越复杂,导致了相当大的计算成本。传统的牛顿法、梯度下降法等局部搜索方法效率低下,容易陷入局部最优,已不能满足实际需求[1-2]。元启发式群智能优化算法的核心思想主要源于动物行为或者物理现象,其核心环节是探索和开发,探索用于在解空间中寻找新的解,以获得全局最优值并避免陷入局部收敛。该算法根据全局最优值进行局部搜索,得到最优解,其简单易行,对初始值不敏感,运行时间短,近年来得到了广泛重视[3-4]。群智能算法能够有效解决人工智能领域中许多复杂且具有挑战性的优化问题,主要应用于组合优化、特征选择、图像处理、生产制造与调度[5]等领域。近年来提出的元启发式算法包括粒子群算法(particle swarm optimization,PSO)、灰狼优化算法(gray wolf optimization,GWO)、飞蛾扑火算法(moth flame optimization,MFO)、鲸鱼优化算法(whale optimization algorithm,WOA)、蝴蝶优化算法(butterfly optimization algorithm,BOA)、海洋捕食者算法(marine predator algorithm,MPA)、多元宇宙优化算法(multi-verse optimizer,MVO)、原子搜索算法(atom search optimization,ASO)等。
MPA算法是2020年由Faramarzi等提出的模拟海洋捕猎行为的元启发式算法,该算法的灵感来自于海洋捕食者和猎物的运动方式。其寻优过程分为三个阶段,捕食者和猎物在这三个阶段中按照莱维运动或者布朗运动进行位置更新[6]。同时,猎物在被捕食的同时也充当捕食者身份,使得算法更具有动态特性。且MPA算法独有的海洋记忆存储阶段与海洋漩涡影响阶段,可以进一步提高更新后的种群质量,相对粒子群、差分进化等经典算法以及上述多数算法,具有更快的收敛速度和收敛精度。
虽然基本MPA算法在优化问题方面具有显著的优势,但是仍然存在着群智能算法容易陷入局部最优、收敛速度较慢的问题,仍需进行改进以提高其优化性能。Elaziz等人提出了一种混合MPA和MFO的MPAMFO算法[7],用MFO代替了MPA的局部搜索方法,提高了MPA的开发能力,但是收敛速度仍有待提高。Abdel等人提出了一种改进的MPA(improved marine predator algorithm,IMPA)[8]。该算法引入了基于排序的多样性减少策略,以最佳个体位置直接替换适应度持续不良的搜索个体的位置,提高了MPA的性能并加快了收敛,但是种群多样性的减少,可能进一步增加陷入局部最优的风险,使算法的可靠性降低。Fan等人提出了基于新的位置更新规则、惯性权重系数和非线性步长控制参数策略的改进MPA(modified MPA,MMPA)[9]。MMPA表现出优越的性能,在精度、收敛速度和稳定性方面得到了有效的提升,但是改进的位置更新规则在捕食者和猎物的每个运动阶段均需按照概率分成两段,分段匹配正余弦函数,规则过于繁琐。Elaziz等人提出了一种增强型MPA(enhanced marine predator algorithm,MPA)[10],将差分进化算子(DE)引入MPA算法中,利用差分进化算子加强MPA的探索阶段,以便于高效地发现搜索空间,降低陷入局部最优的概率,算法结构简单,但是通过文中实验测试对比可知,该EMPA算法对寻优精度的提升十分有限。
为了更好地提升MPA算法寻优精度和收敛速度,本文将混沌对立初始化与分组维度学习策略结合,同时引入t分布变异算子,提出了一种多策略改进的MPA算法(improved MPA for multi-strategy,MSIMPA),使算法同时获得了寻优精度和收敛速度上的显著提升。
1 海洋捕食者算法
海洋捕食者算法(MPA)是一种模拟海洋猎物和捕食者在自然界中生物行为的元启发式算法。猎物位置初始化在解决空间上均匀分布,适应度最佳的作为顶级捕食者用于构造精英矩阵,矩阵定义为:其中,每一行均为顶级捕食者的位置向量,n是种群数量,d是个体维度值。捕食者和猎物均被认为是搜索个体,因为每一个个体在捕食的时候,也同样面临着被捕食的可能。在每次迭代结束时,如果顶级捕食者被更好的捕食者取代,精英将被更新。
另一个是猎物矩阵,捕食者基于这个矩阵更新它们的位置。因此,初始化创建了最初的猎物,其中最合适的一个猎物(捕食者)构建了精英。猎物矩阵如式(2)所示。
MPA通过三个阶段模拟海洋捕食者及其猎物的生活,总结如下:
阶段1猎物比捕食者移动得快或在高速比时(v≥10)。这个阶段发生于迭代初期。捕食者的最佳策略是根本不移动,该阶段数学模型表述如下:
其中,RB表示布朗运动随机向量,P是等于0.5的常数,R表示[0,1]之间的随机均匀分布值。Iter表示当前迭代次数,MaxIter描述最大迭代数,RB与猎物的点乘模拟了猎物的运动。
阶段2猎物和捕食者以相接近的速度或单位速度比移动(v=1)。该策略发生在迭代中期,种群被分为两部分,一部分被指定用于探索,另一部分用于开发。这时,捕食者做布朗运动,猎物做莱维运动。该阶段数学模型表述如下:
其中,RL表示莱维运动随机向量,CF表示控制捕食者移动步长的自适应参数。
阶段3捕食者比猎物移动得快或在低速比时(v=0.1)。该阶段发生在迭代时期,该阶段主要与局部高开发能力相关,此时捕食者的最佳策略为莱维运动,该阶段数学模型表述如下:
其中,RL与精英矩阵的点乘模拟了捕食者的莱维运动,并通过增加精英的步长,将捕食者的运动模拟为猎物位置的更新。
除了上述阶段之外,涡流的形成和鱼类聚集装置(fish aggregating devices,FADs)对捕食者也有影响,该阶段数学模型表述如下:
其中,pf=0.2表示优化过程中受FADs影响的概率,U是通过在[0,1]中生成一个随机向量来构造的,表示包含0和1的二进制向量数组。如果数组小于0.2,则将数组更改为0,如果大于0.2,则更改为1。r是[0,1]中的均匀随机数,r1和r2下标表示猎物矩阵的随机索引。MPA算法具有海洋记忆功能,其本质类似于贪婪策略,在算法迭代开始和位置更新结束都需要进行适应度对比,将更好的解替换先前的解。
2 改进海洋捕食者算法MSIMPA
2.1 加入混沌对立学习策略
2.1.1 Tent混沌映射
混沌映射是一种非线性理论,具有非线性、普适性、遍历性和随机性的特点,可以按自身的特性在一定范围内不重复地遍历所有状态,在智能算法优化中能帮助生成新的解,增加种群多样性,因而被广泛应用[11]。Tent映射迭代速度快,混沌序列在[0,1]之间均匀分布,其表达式如下:
其中,λt是第t次迭代时产生的混沌数,T是最大迭代次数,α是介于[0,1]的常数,本文选取α=0.7。
图1为Tent映射迭代500次,划分20个区间时的序列分布直方图。由图1可以看出,Tent映射在0~1之间均匀分布。
2.1.2 对立学习
在解决问题的时候,考虑到无效解决方案的对立侧可能存在更好的解决方案,Tizhoosh提出了对立学习策略(opposition-based learning,OBL)[12]。近年来OBL已经有效地应用于各种群智能算法中。在群智能算法初始化种群的过程中,随机生成的部分个体往往会分布在远离最优解的无效区域和边缘区域,进而降低了种群的搜索效率。采用OBL策略,在种群初始化中引入一个随机解及其对立解要比引入两个独立的随机解更能提高初始种群的质量。假设某个d维个体位置为:
设其个体位置的下界和上界分别为lb、ub,则其对立侧位置可以表示为:
但是,在目标函数上下界限对称的时候,由式(16)可看出,所生成的反向解为原来解的完全镜像(取负),对部分具有偶函数特性的函数,完全镜像解与原解目标值一致,不适合将两个种群做适应度排序,无法有效获得高质量种群。
2.1.3 混沌对立策略
本文将Tent混沌映射与OBL相结合,提出了一种新的TOBL(Tent and opposition-based learning)机制。TOBL的数学模型如下:
其中,为第i个猎物对立位置的第j维分量。
TOBL策略相当于以目标函数上下界限的和为中心,利用Tent的均匀变化,来动态压缩原初始种群的分布范围,并在压缩的同时尽量让种群均匀。
图2为不同策略下30个个体在[-20,20]的二维平面初始化分布图,由图2(a)、(b)可以看出,两种方式的初始化分布呈现完全的中心对称,这种镜像现象会制约对立解的有效性。图2(c)的TOBL初始化分布虽然不如图2(a)中的个体分布均匀,但是两种方式的初始化分布差异很大,更适合将两者合并,然后按照适应度将个体排序,择优选取与原来相同数量的个体,作为新的初始化种群,进而提高初始化种群的质量。
假设海洋捕食者(猎物)种群数量为n,该策略的具体步骤为:首先通过随机分布生成n个位置,再通过TOBL生成n个混沌对立位置,这些对立位置很有可能更加接近于目标猎物,最后将这2n个位置按照适应度排序,取适应度最佳的前n个猎物位置,作为初始化种群。
2.2 加入自适应t分布
t分布又称为学生分布[13],它的分布函数曲线形状与其自由度n密切相关。
图3为自由度为5的t分布、标准正态分布和标准柯西分布的函数分布图像对比。由图3可知,t分布大致介于标准正态分布和标准柯西分布之间,其自由度n越小,曲线的双尾就翘得越高,中间峰值越小,整体越加平滑。当n=1时,t分布变为标准柯西分布。反之,自由度n越大,中间峰值越大,整体越加陡峭。当n趋于无穷时,t分布变为标准正态分布。
基本MPA中,猎物更新完位置以后,需要检测和更新顶级捕食者的位置,并进行一次海洋记忆存储,接下来再考虑FADs的影响,对猎物的位置做进一步更新。
为了保证此次记忆存储更加有效,引入自适应t分布算子,在模拟FADs的影响之前,对猎物的位置进行变异,如果变异后的位置更佳,则代替原来的位置。数学模型如下:
其中,Xi′为第i个猎物变异后的位置,t(Iter)为以当前迭代次数为自由度的t分布。在迭代初期,迭代次数较少,t分布近似于柯西分布,分布得更加平滑。此时,t分布算子在大概率上取到较大值,位置变异所采取的步长较大,算法具有良好的全局探索能力,与MPA第一阶段的全局搜索特性形成正反馈;在迭代中期,一半的捕食者用于全局探索,另一半的捕食者用于局部开发,而此时t分布介于柯西分布和正态分布之间,t分布算子在大概率上取值相对折中,同时兼顾了MPA第二阶段的全局搜索和局部开发,使捕食者更容易返回到猎物丰富的地区并成功觅食,进而对算法性能形成正反馈;在迭代后期,t分布近似于标准正态分布,分布得更加集中,t分布算子在大概率上取较小值,致变异所采取的步长较小,兼顾了MPA第三阶段的局部开发特性。
2.3 加入分组维度学习策略
在算法迭代过程中,有些猎物位置的某些维度实际上可能早已达到了最优维度,由于其中个别维度的影响,使得这些猎物位置的适应度变差[14]。为了能在海洋里生存下去,位置差的猎物(捕食者)需要向位置好的猎物(捕食者)学习捕食本领,基于这个思想,提出了一种分组维度学习的策略。将FADs影响后的猎物按照适应度排序平均分成两组,适应度好的一组称为精英组,适应度差的一组称为学习组[15]。
2.3.1 学习组维度交叉策略
因为精英组的维度各有优劣,所以将精英组的位置维度取平均值,学习组的每一个猎物都向精英组平均维度进行学习。该策略将学习组每个猎物的每一维度同精英组平均维度值做差,按照绝对差异大的优先交叉原则,取绝对差异大的前H1个对应维度逐一交叉,如果交叉后猎物的适应度更好,则交叉对应维度,反之则不交叉。该策略的数学模型为:
其中,XL,i表示学习组第i个猎物位置,Xk,crossL,i表示与精英组平均维度值第k维交叉后的第i个猎物位置,ΔXkL,i表示学习组第i个猎物第k维和精英组平均维度第k维的绝对差异,XkJAVG表示精英组平均值的第k维。图4为H1=2时学习组维度交叉示意图。
以图4学习组第2个个体为例,其第1维交叉以后适应度更好,交叉成功。第3维交叉后适应度变差,故交叉失败。当H1取值越大,所交叉的维度就越多,对学习组个体而言,会使得学习组的个体大程度上接近精英组平均值,减小了学习组个体之间的差异。此时,虽然种群平均适应度减小,加快了收敛速度,但是个体差异性的减少会带来陷入局部最优的风险,即使收敛精度相比原算法有提升,但仍有一定概率使改进算法寻优精度降低。当H1取值越小,交叉次数越少,相比于未交叉之前的个体差异微小。虽然个体多样性得到保持,但是较少维度的交叉大大减弱了改进算法跳出局部最优的能力,同样有陷入局部最优的风险。而且交叉过少,个体之间得不到很好的学习,会降低收敛速度,因此,H1的选取要折中考虑。经过大量仿真测试,选取个体维度一半左右进行交叉效率最高,本文实验中,选取H1等于个体维度数的一半。
学习组向精英组平均值进行维度学习的过程中,质量较差的学习组个体就不至于跨越太大的步长,以免越过全局最优点及其邻域。因此,学习组的平均维度学习会大大减少该部分个体向最优值迭代的次数,提升了收敛速度。
2.3.2 精英组维度交叉策略
精英组整体离全局最优点相对较近,因此不适合全部维度的扰动变异,这样会导致精英在最优解附近徘徊,影响收敛精度。令精英组的猎物相互之间取长补短,在保留自己优势维度的前提下,向相邻的猎物进行学习。该策略交叉原则和学习组猎物交叉原则相同,只是将交叉对象,由精英组平均维度值更换为与该猎物相邻的前一个猎物。设精英组每个猎物取绝对差异大的前H2个相邻对应维度逐一交叉,图5为H2=4时精英组维度交叉示意图。
以图5精英组第3个个体为例,其第1、5维和倒数第2维交叉以后适应度更好,交叉成功。第7维交叉后适应度变差,故交叉失败。有关H2的选取规则,同理于H1的选取规则。本文实验中,选取H2等于个体维度数的一半。
该策略相当于原来质量较高的个体,仅朝着所交叉的维度方向步进,仍保留其他优势维度。相比于整个个体的变异,这种策略的择优性更强,可以有效增强算法维度的纵深挖掘性能,提高原算法的收敛精度。
2.4 MSIMPA算法实现步骤
步骤1由式(14)~(17)对猎物的位置进行混沌对立初始化,并设置种群规模、最大迭代次数、FADs等相关参数。
步骤2计算每个猎物适应度值,并将适应度值进行比较、替换,由最佳猎物构成顶级捕食者矩阵,并进行海洋记忆存储。
步骤3由式(3)~(11)更新猎物位置和移动步长。
步骤4由式(18)的t分布变异算子进行位置扰动更新,并保留最佳位置。
步骤5重新计算每个猎物适应度值,并将适应度值进行比较、替换,由最佳猎物构成顶级捕食者矩阵,并进行海洋记忆存储。
步骤6考虑FADs和漩涡的影响,由式(12)进一步更新位置,并保留最佳位置。
步骤7将更新后的种群按照适应度优劣均分成学习组和精英组,由式(19)~(20)进行维度交叉,交叉后适应度变好则交叉对应维度,反之则不交叉。
步骤8判断算法是否满足迭代条件,若满足,则算法终止,否则转至步骤2。
2.5 MSIMPA复杂度分析
算法的复杂度主要取决于算法语句的重复执行次数,MPA中循环次数主要受最大迭代次数T、种群规模N和个体维度D的影响[16]。根据上节步骤分析MISMAP:步骤1混沌对立初始化种群数量翻倍,增加O(N×D)运算量,但复杂度仍为O(N×D);步骤2和步骤5搜寻顶级捕食者以及海洋记忆存储的复杂度为O(N×T);步骤3位置更新复杂度为O(N×D×T);步骤4对每个个体位置扰动,复杂度为O(N×T);步骤6对整体位置统一增加一个步长,复杂度为O(T);步骤7对每个个体的一半维度进行维度学习,复杂度为O(N×D×T)。综上,略去低次项,原算法复杂度为O(N×D×T),MSIMPA复杂度增加体现在步骤1、步骤4和步骤7,运算量虽然稍有增加,但是总体复杂度不变,不影响算法执行效率。
2.6 MSIMPA收敛性分析
原始海洋捕食者算法按照迭代次数分为三个寻优阶段。阶段2为阶段1和阶段3的整合,其局部开发遵循阶段1的收敛性,全局搜索阶段遵循阶段3的收敛性,故无需对其单独分析。文献[17]中,算法的提出者已经详细证明了阶段1和阶段3的收敛性,下面仅给出结论。在阶段1,原算法收敛性取决于φ1:
由上式可知,当φ1<1时,MPA在阶段1收敛,否则发散。而阶段1原本就是用来全局搜索,因此它按概率发散也无关紧要。
在阶段3,MPA收敛,且收敛于顶级捕食者构成的精英矩阵E,即全局最优位置:
综上,MPA在整个迭代过程中,最终是呈现出收敛的。在MSIMPA中,主要加入了三个策略。其中,混沌对立策略仅参与一次初始化种群,不参与算法的迭代过程,不对算法收敛性造成影响,无需单独分析。自适应t分布以及分组学习,本质上都是引入随机变异,来对原来的种群进行扰动,然后遵循贪心策略保留精英。
根据数列基本定理,有:
定理1单调不升且存在下界的数列{}fn必收敛于其极限inf{fn},即inf{fn}。
文献[17]对混合优化算法的全局收敛性进行了详细的分析,证明得出如下定理:
定理2如果某种算法同时具备以下两个条件,则该算法最优序列依概率1全局收敛。
条件1在迭代最优解时,采用贪心策略保留精英,即:
其中,fBestk为比较k次后的最优适应度,X为第k+1次迭代后用来与fBestk比较的解。
条件2从任意一个非全局最优点X′转移到与之对应的水平集L(Xr)={X|f(X)<f(Xr),X∈S}的概率不为0,S表示整个搜索空间。
假设MSIMPA的目标函数f为求极小值,随机采样序列为,采样点最优序列为,全局最优点为fBest。
证明MSIMPA不论原算法还是改进后的策略均遵循贪心策略,满足定理2的条件1。
由定理1可知fkBest有极限,设nBest=inf{fBestk}≠fBest,则有fBestn>fBest,且∀k∈Z+,fBestk≥fBestn。因为原算法MPA最后收敛于顶级捕食者构成的精英矩阵,所以当X取值到精英周围足够小的邻域时,必有P{L(X′)}=P{X|f(X)<f(X′),X∈S}≠0(此处P{}·表示概率),故满足条件2。
综上,MSIMPA算法依概率1全局收敛,即P{Best}=1。其收敛速度受t分布随机取值以及维度交叉有效性的影响,有效性越高收敛越快。
3 函数测试与数值分析
3.1 函数测试
为了检验本文提出的MSIMPA算法的有效性,选取了15个测试函数与MPA、MVO、PSO、MFO、WOA、GWO、ASO这7种算法进行求极小值仿真对比。测试函数中含有6个多维单峰函数F1~F6、6个多维多峰函数F7~F12和3个固定维度多峰函数,具体函数信息见表1。所有算法迭代次数均设置为500次,种群数量均为30个。多维测试函数维度为30、50维,固定维度函数F13为2维,F14、F15为4维。将8种算法分别独立运行30次,分别计算30次运行的平均最佳适应度值和最佳适应度值的方差。优先根据平均适应度值(寻优精度)对算法性能进行排序,如果平均适应度相同,再根据方差和收敛速度排序。

表1测试函数Table 1 Test functions
本文绘制出50维时8种算法在5个单峰测试函数、5个多峰函测试数和2个固定维度测试函数下的迭代收敛曲线图,见图6。
如图6所示,在求解F6、F8、F10、F11等函数时,MSIMPA的初始适应度更佳,表明混沌对立初始化可以有效提高初始种群质量。在求解多维函数F1、F2、F4、F7、F8和F10时都达到最优,精度显著提升。其中F11具有多个局部最优峰值,且波谷内较为平缓,大多数算法很难找到其全局最小值,MPA算法虽然相对于其他几种算法有略微优势,但是寻优精度不够,可见原算法考虑FADs的位置扰动并不能满足需求。而MSIMPA在迭代开始阶段,t分布变异含有全局搜索成分,收敛曲线迅速下降,迭代到90次左右时,结合和分组维度学习的作用,迭代曲线迅速收敛。由F8可知,MPA和WOA虽然也达到理论最小值,但是收敛速度明显不如MSIMPA。F14~F15是固定维度函数,最优值非0,MSIMPA和MPA平均适应度均为最佳,但收敛速度上MSIMPA更快。同样,在F9上也能进一步明显体现出MSIMPA寻优精度高、收敛速度快的优势。
3.2 数据分析
表2为30维时F1~F12的最终测试结果,表3为50维时F1~F12和固定维度时F13~F15的最终测试结果。通过表2和表3数据分析可知,无论是30维还是50维的情况下,MSIMPA算法的方差和平均适应度指标相较其他算法具有明显优势。
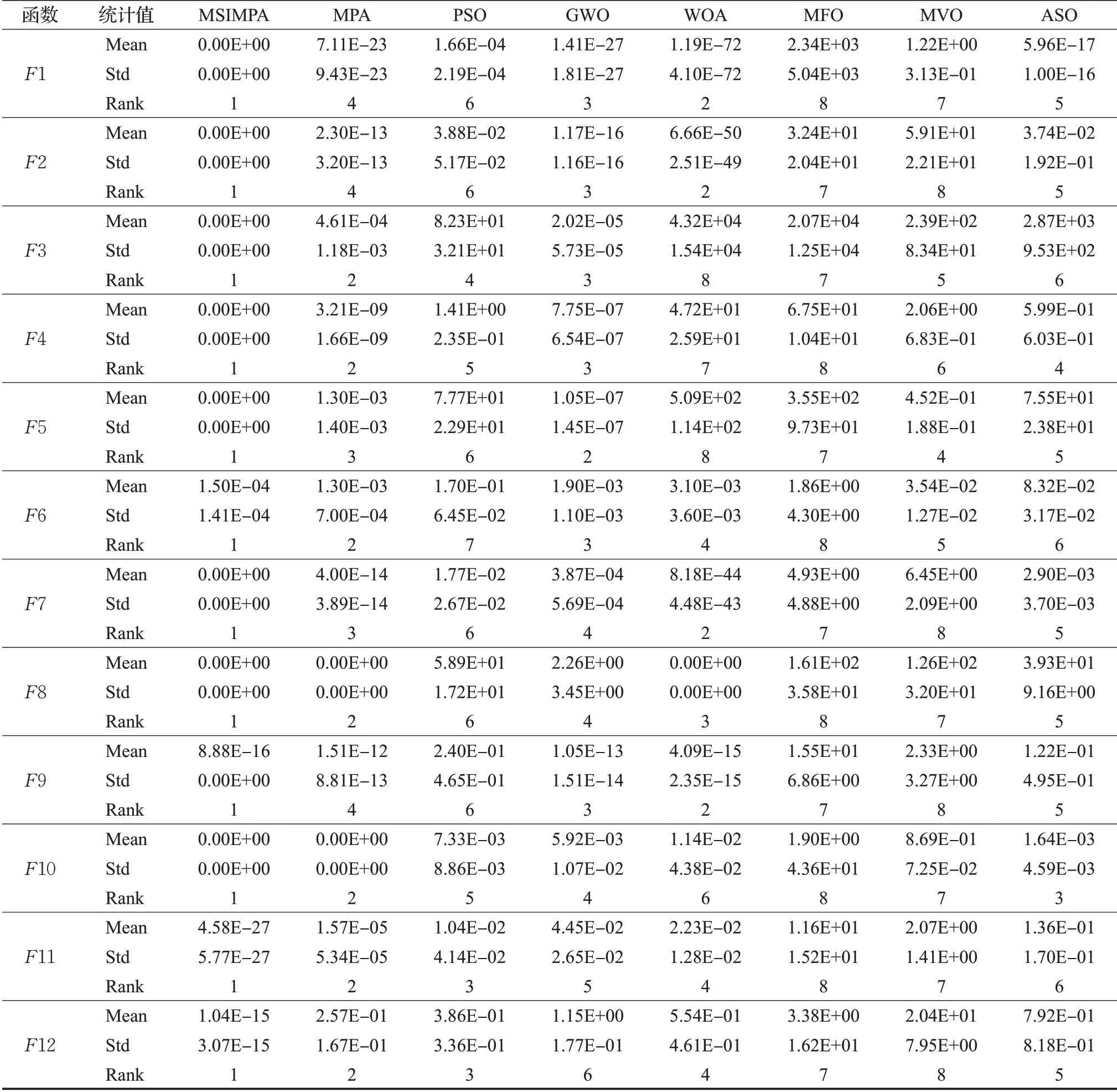
表2 30维函数测试数据Table 2 Test data of 30 dimensional functions

表3 50维及固定维度函数测试数据Table 3 Test data of 50 dimensional functions

表3 (续)
维度由30维提升到50维时,其余7种算法整体寻优性能均相对变差,而对于MSIMPA算法,维度变高以后,分组维度学习范围也按比例变宽,在较大程度上可以减弱高维带来的影响,在F1~F5、F7~F8和F10上依然可以达到理论极小值0,寻优精度远高于MPA。虽然在少数几个函数上,升高到50维时的MSIMPA寻优精度也有所降低,但仍然要优于其他对比算法。标准差体现出算法在求解中的稳定性,算法GWO、ASO随着求解维度的增高,标准差明显增加,说明这两个算法求解高维度问题时稳定性较差。而MISCSA算法标准差相较于MPA、PSO、WOA等都低,说明算法的稳定性更好。
在30维和50维情况下,各算法排名差异不大,保持在前列的为MSIMPA、MPA、GWO,性能较差的为MVO、MFO。为了更直观地分析各算法的寻优能力,绘制出图7的排序雷达图,算法性能曲线越靠近中间,则性能越优越。
由图7可知,忽略MSIMPA算法,MPA算法在F1、F2、F5、F7、F9、F12、F13上分别被不同的算法超越,排名在2~4之间,可见原MPA算法虽然性能较佳,但仍存在一定的不足,而MSIMPA算法在15个测试函数中性能均为最佳。值得一提的是MVO在F13上表现出色,寻到了理论最优值,且收敛速度排在了第2位,方差排在第3位。
3.3 统计检验
Derrac等人在文献[18]中指出,仅依靠平均值和标准差来比较算法的差异不够严谨。独立运行得到的平均适应度值和标准差,仍有一定概率出现较好的数据,从而影响算法之间的性能比较。想要对改进算法性能做评估,需要在统计学层面上来判断不同算法整体指标的显著性区别。因此,将8种算法分别在15个测试函数上独立测试30次的结果作为样本,在0.05的显著性水平下分别对30维和50维以及固定维度函数的测试结果进行Wilcoxon统计检验,判断7个对比算法的结果与MSIMPA的结果的显著性区别。检验结果见表4和表5。
根据文献[18],当P<0.05时可以被认为是拒绝零假设的有力验证,说明所对比的两种算法具有显著性差异,P>0.05则说明两种算法的寻优结果在整体上是相同的。根据表4和表5中的结果,因为MPA求解函数F8、F10以及WOA求解函数F8,均与MSIMPA同时搜索到全局最小值0,所以该统计检验不适用,记为“NaN”。其中,50维情况下,MSIMPA与WOA只有在求解F10时可以认为无明显差异,求解其余测试函数时均与其余所有对比算法有显著区别。30维情况下,MSIMPA的P全部小于0.05,表明了算法的优越性在统计上是显著的。

表4 30维时Wilcoxon统计检验结果Table 4 Wilcoxon statistical test results in 30 dimensions

表5 50维及固定维度时Wilcoxon统计检验结果Table 5 Wilcoxon statistical test results of 50 dimensions and fixed dimensions
4 MSIMPA优化无线传感器网络覆盖
假设在边长分别为L1和L2的矩形无线传感器WSN检测范围内,随机分布N个同构传感器的节点,假设节点Zi的位置坐标为,每个节点的感知范围是以该节点为中心,Rs为半径的圆形区域,则将该圆形区域称感知圆盘,Rs称为感知半径。为了便于建模计算,将感知圆盘离散为m×n个待覆盖的目标点,目标点Cj的位置坐标为( )xj,yj,则目标点和传感器节点的距离定义为:
若存在某个节点与目标点的距离小于或等于感知半径Rs,则代表目标点已被传感网络覆盖。基于0/1模型,将目标点被传感器节点Zi感知的概率定义为[19]:
其中,Re为节点感知误差;λ为感知衰减系数。当目标点被多个传感器感知,则目标点的联合检测概率为:
该区域的覆盖率为全部节点所覆盖的目标点总数与区域内目标点总数的比值,定义为:
通过函数测试对比,MSIMPA和MPA算法的综合能力领先于其他对比算法,且考虑到本文主要测试MPA算法的改进性能,故本文的WSN覆盖优化只选择MSIMPA和MPA算法进行对比。具体的实施步骤与第2.4节算法实施步骤基本相似,将覆盖区域边界长度设置为第2.4节算法中的寻优边界,设种群中的个体维度为2N,则种群中的每个个体位置构成N个二维平面坐标,代表N个传感器节点。算法逻辑上为搜寻最小值,欲求最大覆盖率,将式(28)改为:
选取式(29)作为适应度函数,捕食者在搜寻猎物的时候不断更新自己的位置,并在位置更新以后采用分组维度学习的方式对位置维度取长补短,可以较大程度上提升最优个体的位置精度。算法迭代结束后,得到式(29)的最小值,即可反向求出传感器节点的最大覆盖率。实验参数设置如表6。

表6 参数设置Table 6 Parameter setting
当传感器节点为30个时,MSIMPA和MPA的初始化覆盖情况如图8,红点代表节点,圆圈代表感知圆盘。MPA采用随机分布初始化,初始覆盖率为53.92%,而MSIMPA算法采用混沌对立初始化,初始覆盖率为65.23%,提高了约11个百分点,反映出混沌对立初始化的种群质量更高。
算法优化后的传感器区域覆盖结果如图9所示。图9(a)、(b)为30个节点时的覆盖情况,MPA算法优化的覆盖率为81.15%,MSIMPA算法优化的覆盖率为87.03%。从图9(a)中可以清楚地看到,MPA优化时覆盖区域的边缘和中心部位都有明显的空缺,各个节点感知范围重叠较为密集,图9(b)中MSIMPA优化覆盖的区域则更加均匀。图9(c)、(d)为40个节点时传感器区域的覆盖情况,此时图9(c)中MPA优化后的覆盖率为90.61%,原点附近仍有较大盲区且重叠部分略多,图9(d)中MSIMPA优化后的覆盖率为96.55%,重叠部分有所改善且无明显盲区。
为了使实验更加准确,算法分别独立运行30次,平均覆盖率见表7。通过表7可知,MSIMPA的覆盖率和初始覆盖率都高于MPA。

表7 平均覆盖率Table 7 Average coverage 单位:%
迭代曲线如图10所示。图10(a)中30个节点时,MSIMPA由于初始化质量更高,迭代曲线起点高且迅速上升,在120代时趋于稳定,MPA迭代曲线还处于上升阶段,此时覆盖率相差最大。在迭代到400代时,MSIMPA优化精度略微提高后再次稳定,这时处于迭代后期,t分布变异着重于局部开发,配合个体之间的维度学习,使得寻优精度进一步提高。40个节点时,相当于个体维度增加,MSIMPA的分组维度学习策略依然有效,无论是收敛速度还是覆盖范围,均明显高于MPA算法的优化效果。
综上所述,通过与不同节点在同等测试条件下的实验结果对比,MSIMPA算法实现了更高的平均覆盖率,节点分布更加均匀,覆盖盲区和感知范围重叠区面积更少,验证了所提出改进策略的有效性。
5 结束语
为了进一步改进海洋捕食者算法的寻优性能,本文提出了MSIMPA算法。首先,在MPA算法中加入了混沌对立初始化,提高了初始种群质量。其次,加入了自适应t分布变异算子,增加算法逃逸出局部最优的能力。最后,对位置更新完毕的种群进行分组维度学习,增加算法的收敛速度和精度。将MSIMPA与其他7种算法在15个测试函数上测试对比,MSIMPA在求解高维单峰和多峰函数以及固定维度函数时,求解精度与收敛速度均有明显优势。并将MSIMPA在WSN覆盖优化问题上与MPA算法进行对比,实验结果进一步验证了所提出改进策略的有效性。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
作文大王·笑话大王(2021年11期)2021-12-16
百科探秘·海底世界(2020年11期)2020-12-31
第二课堂(小学版)(2019年7期)2019-07-16
动漫星空(兴趣英语)(2018年4期)2018-10-30
疯狂英语·新读写(2018年3期)2018-09-07
阅读与作文(小学高年级版)(2017年10期)2017-10-11
当代旅游(2016年10期)2017-04-17
中外文摘(2016年13期)2016-08-29
财经理论与实践(2015年2期)2015-04-16
